WO2016075327A2 - Production of pufas in plants - Google Patents
Production of pufas in plants Download PDFInfo
- Publication number
- WO2016075327A2 WO2016075327A2 PCT/EP2015/076632 EP2015076632W WO2016075327A2 WO 2016075327 A2 WO2016075327 A2 WO 2016075327A2 EP 2015076632 W EP2015076632 W EP 2015076632W WO 2016075327 A2 WO2016075327 A2 WO 2016075327A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- plant
- desaturase
- content
- dna
- oil
- Prior art date
Links
Classifications
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23K—FODDER
- A23K20/00—Accessory food factors for animal feeding-stuffs
- A23K20/10—Organic substances
- A23K20/158—Fatty acids; Fats; Products containing oils or fats
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K36/00—Medicinal preparations of undetermined constitution containing material from algae, lichens, fungi or plants, or derivatives thereof, e.g. traditional herbal medicines
- A61K36/18—Magnoliophyta (angiosperms)
- A61K36/185—Magnoliopsida (dicotyledons)
- A61K36/31—Brassicaceae or Cruciferae (Mustard family), e.g. broccoli, cabbage or kohlrabi
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8241—Phenotypically and genetically modified plants via recombinant DNA technology
- C12N15/8242—Phenotypically and genetically modified plants via recombinant DNA technology with non-agronomic quality (output) traits, e.g. for industrial processing; Value added, non-agronomic traits
- C12N15/8243—Phenotypically and genetically modified plants via recombinant DNA technology with non-agronomic quality (output) traits, e.g. for industrial processing; Value added, non-agronomic traits involving biosynthetic or metabolic pathways, i.e. metabolic engineering, e.g. nicotine, caffeine
- C12N15/8247—Phenotypically and genetically modified plants via recombinant DNA technology with non-agronomic quality (output) traits, e.g. for industrial processing; Value added, non-agronomic traits involving biosynthetic or metabolic pathways, i.e. metabolic engineering, e.g. nicotine, caffeine involving modified lipid metabolism, e.g. seed oil composition
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23D—EDIBLE OILS OR FATS, e.g. MARGARINES, SHORTENINGS, COOKING OILS
- A23D7/00—Edible oil or fat compositions containing an aqueous phase, e.g. margarines
- A23D7/02—Edible oil or fat compositions containing an aqueous phase, e.g. margarines characterised by the production or working-up
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23L—FOODS, FOODSTUFFS, OR NON-ALCOHOLIC BEVERAGES, NOT COVERED BY SUBCLASSES A21D OR A23B-A23J; THEIR PREPARATION OR TREATMENT, e.g. COOKING, MODIFICATION OF NUTRITIVE QUALITIES, PHYSICAL TREATMENT; PRESERVATION OF FOODS OR FOODSTUFFS, IN GENERAL
- A23L33/00—Modifying nutritive qualities of foods; Dietetic products; Preparation or treatment thereof
- A23L33/10—Modifying nutritive qualities of foods; Dietetic products; Preparation or treatment thereof using additives
- A23L33/115—Fatty acids or derivatives thereof; Fats or oils
- A23L33/12—Fatty acids or derivatives thereof
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/185—Acids; Anhydrides, halides or salts thereof, e.g. sulfur acids, imidic, hydrazonic or hydroximic acids
- A61K31/19—Carboxylic acids, e.g. valproic acid
- A61K31/20—Carboxylic acids, e.g. valproic acid having a carboxyl group bound to a chain of seven or more carbon atoms, e.g. stearic, palmitic, arachidic acids
- A61K31/202—Carboxylic acids, e.g. valproic acid having a carboxyl group bound to a chain of seven or more carbon atoms, e.g. stearic, palmitic, arachidic acids having three or more double bonds, e.g. linolenic
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/0071—Oxidoreductases (1.) acting on paired donors with incorporation of molecular oxygen (1.14)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/93—Ligases (6)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6888—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for detection or identification of organisms
- C12Q1/6895—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for detection or identification of organisms for plants, fungi or algae
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y114/00—Oxidoreductases acting on paired donors, with incorporation or reduction of molecular oxygen (1.14)
- C12Y114/19—Oxidoreductases acting on paired donors, with incorporation or reduction of molecular oxygen (1.14) with oxidation of a pair of donors resulting in the reduction of molecular oxygen to two molecules of water (1.14.19)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y114/00—Oxidoreductases acting on paired donors, with incorporation or reduction of molecular oxygen (1.14)
- C12Y114/19—Oxidoreductases acting on paired donors, with incorporation or reduction of molecular oxygen (1.14) with oxidation of a pair of donors resulting in the reduction of molecular oxygen to two molecules of water (1.14.19)
- C12Y114/19003—Linoleoyl-CoA desaturase (1.14.19.3)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y114/00—Oxidoreductases acting on paired donors, with incorporation or reduction of molecular oxygen (1.14)
- C12Y114/19—Oxidoreductases acting on paired donors, with incorporation or reduction of molecular oxygen (1.14) with oxidation of a pair of donors resulting in the reduction of molecular oxygen to two molecules of water (1.14.19)
- C12Y114/19006—DELTA12-fatty-acid desaturase (1.14.19.6), i.e. oleoyl-CoA DELTA12 desaturase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y602/00—Ligases forming carbon-sulfur bonds (6.2)
- C12Y602/01—Acid-Thiol Ligases (6.2.1)
- C12Y602/01003—Long-chain-fatty-acid-CoA ligase (6.2.1.3)
Definitions
- Section A has the title "MATERIALS AND METHODS FOR PUFA PRODUCTION, AND PUFA- CONTAINING COMPOSITIONS"
- Section B has the title "BRASSICA EVENTS LBFLFK AND LBFDAU AND METHODS FOR DETECTION THEREOF"
- Section C has the title "MATERIALS AND METHODS FOR INCREASING THE TOCOPHEROL CONTENT IN SEED OIL",
- Section D has the title "STABILISING FATTY ACIDS COMPOSITIONS"
- each section (with the corresponding Examples) is a complete section with definitions, tables, examples and embodiments.
- any reference to a figure is a reference to a figure as listed below BRIEF DESCRIPTION OF THE FIGURES for all sections
- Figure 1 Schematical figure of the different enzymatic activities leading to the production of ARA, EPA and DHA
- Figure 2 Formulas to calculate pathway step conversion efficiencies.
- S substrate of pathway step.
- P product of pathway step.
- Product was always the sum of the immediate product of the conversion at this pathway step, and all downstream products that passed this pathway step in order to be formed.
- DHA 22:6n-3 does possess a double bond that was a result of the delta- 12-desaturation of oleic acid (18:1 n-9) to linoleic acid (18:2n-6).
- Figure 3 Strategy employed for stepwise buildup of plant expression plasmids of the invention.
- Figure 4 Stabiliy of binary plant expression plasmids containing the ColE1/pVS1 origin of replication for plasmid recplication in E.coli/Agrobacteria.
- Left Panel Stability in Agrobacterium cells by isolating plasmid DNA from Agrobacterium cutures prior to usage of this culture for plant transformation, and subjecting the plasmid DNA to a restriction digest. An unexpected restriction pattern indicates disintegration/instability of the plasmid either in E.coli or in Agrobacterium.
- Figure 5 Plasmid map of VC-LJB2197-1 qcz indicating the position of genetic elements listed in table 1 (and in table D1 ).
- Figure 6 Plasmid map of VC-LJB2755-2qcz rc indicating the position of genetic elements listed in table 2 (and in table D2).
- Figure 7 Plasmid map of VC-LLM306-1 qcz rc indicating the position of genetic elements listed in table 3.
- Figure 8 Plasmid map of VC-LLM337-1 qcz rc indicating the position of genetic elements listed in table 4(and in table D4) .
- Figure 9 Plasmid map of VC-LLM338-3qcz rc indicating the position of genetic elements listed in table 5.
- Figure 10 Plasmid map of VC-LLM391 -2qcz rc indicating the position of genetic elements listed in table 6 (and in table D6).
- Figure 1 1 Plasmid map of VC-LTM217-1 qcz rc indicating the position of genetic elements listed in table 7.
- Figure 12 Plasmid map of RTP10690-1 qcz_F indicating the position of genetic elements listed in table 8.
- Figure 13 Plasmid map of RTP10691 -2qcz indicating the position of genetic elements listed in table 9.
- Figure 14 Plasmid map of LTM595-1 qcz rc indicating the position of genetic elements listed in table 10.
- Figure 15 Plasmid map of LTM593-1 qcz rc indicating the position of genetic elements listed in table 1 1 .
- Figure 16 Comparative transcript analysis o3Des(Pi_GA2) driven by the VfUSP promoter during seed development of single copy event of four different construct combinations.
- Figure 17 Comparative transcript analysis of o3Des(Pir_GA) during seed development of single copy event of four different construct combinations.
- VC-LJB2755-2qcz and VC-RTP10690- 1 qcz_F the gene was driven by the LuCnl promoter while in VC-LLM337-1 qcz rc the gene was driven by the VfUSP promoter and was expressed at a lower level than the LuCnl o3Des(Pir_GA) combination.
- Figure 18 Comparative transcript analysis of o3Des(Pir_GA) driven by the BnSETL promoter during seed development of single copy event of VC-RTP10690-1 qcz_F.
- Figure 19 Comparative transcript analysis of d4Des(PI_GA)2 driven by the LuCnl promoter during seed development of single copy event from VC-RTP10690-1 qcz_F and VC-LTM217-1 qcz rc, which was present with VC-LJB2755-1 qcz. The other constructs lacked this particular d4Des.
- Figure 20 Comparative transcript analysis of d4Des(Tc_GA) driven by the ARC5 promoter during seed development of single copy event of four different construct combinations.
- Figure 21 Comparative transcript analysis of d4Des(Eg_GA) driven by the LuCnl promoter during seed development of single copy event of two different construct combinations; VC-LJB2755- 2qcz, VC-LLM391-2qcz rc and VC-LJB2197-1 qcz, VC-LLM337-1 qcz rc.
- Figure 22 Half Kernel Analysis of segregating T1 seeds of Event LANPMZ. A total of 288 seedlings where analysed. 71 of those seedlings were found to produce no significant amount of VLC-PUFA (dark grey diamonds) while containing >49% Oleic acid and ⁇ 28% Linoleic acid.
- 71 seed of 288 seed correspond to 24.65% of the total analysed seed. All remaining seed were capable of producing DHA, indicating the presence of both T-DNA from construct VC-LJB2197- 1 qcz and VC-LLM337-1 qcz rc. Among those seeds producing DHA, one can discriminate a group of 146 seeds showing medium VLC-PUFA levels (open diamonds), and a group of 71 seed showing high VLC-PUFA levels (light grey diamonds).
- the ratios of these three groups is 71 :146:71 , which corresponds to the Medelain 1 :2:1 ratio (NULL:HETEROZYGOUS:HOMOZYGOUS) expected for a phenotype when all genes conveying this phenotype (in this case the two T-DNAs of plasmid VC-LJB2197-1 qcz and VC-LLM337-1 qcz rc) integrated into one locus in the genome.
- Figure 23 Half Kernel Analysis of segregating T1 seeds of Event LBDIHN. A total of 288 seedlings where analysed.
- the levels of first substrate fatty acid of the pathway was plotted on the x-axis, the levels of the sum of two products of the pathways (EPA+DHA) was plotted on the y-axis.
- This segregation of the phenotype according to the first Mendelian law demonstrates a single locus insertion of the T-DNA of construct RTP10690-1 qcz_F into the genome of B.napus cv Kumily.
- Figure 24 Examples of Desaturase Enzyme Activity Heterologously Expressed in Yeast.
- [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using Instant Imager.
- panel A Delta-12 Desaturase (Ps), c-d12Des(Ps_GA), activity was demonstrated by comparison of enzyme activity present in yeast microsomes isolated from a strain expressing the c-d12Des(Ps_GA) protein relative to microsomes isolated from a control strain containing an empty vector (VC).
- FIG. 26 Examples of Desaturase Enzyme Reactions Showing Specificity for Acyl-lipid substrates.
- ME's Fatty acid methyl esters
- Ps Delta-12 Desaturase
- c-d12Des(Ps_GA) desaturated enzyme products were only detected in the phosphatidylcholine fraction indicating the enzyme was specific for an acyl-lipid substrate.
- [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions containing microsomes obtained from a yeast strain expressing the protein of interest, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using Instant Imager.
- panel A was in situ labeled with substrate according to the method for determining lipid linked desaturation.
- Delta-9 Desaturase (Sc), d9D(Sc), desaturated enzyme products were very low in the phosphatidylcholine fraction, except for in the control reaction (none in situ labeled PC), indicating the enzyme cannot desaturate an acyl-lipid substrate.
- the incubation was done according to the method for determining acyl-CoA linked desaturation.
- FIG. 28 Examples of Elongase Enzyme Activity Heterologously Expressed in Yeast.
- [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using Instant Imager. All FAME'S shown had similar Rf's as authentic standards. In the absence of [14C]malonyl-CoA no radioactive fatty acids were observed in any of these elongase reactions.
- delta-6 elongase (Tp), c-d6Elo(Tp_GA2) activity was demonstrated by comparison of enzyme activity present in yeast microsomes isolated from a strain expressing the c- d6Elo(Tp_GA2) protein relative to microsomes isolated from a control strain containing an empty vector (VC).
- delta-6 elongase (Pp), c-d6Elo(Pp_GA2) was demonstrated by comparison of enzyme acitivity from yeast microsomes isolated from a strains expressing c- d6Elo(Pp_GA2) protein to microsomes isolated from a control strain containing an empty vector (VC), as shown in panel A.
- delta-5 elongase (Ot), c-d5Elo(Ot_GA3) activity was demonstrated by comparison of enzyme activity present in yeast microsomes isolated from a strain expressing the d5E(0t) protein relative to microsomes isolated from a control strain containing an empty vector (VC).
- Figure 29 Examples of Elongase Activity in transgenic Brassica napus.
- [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using Instant Imager.
- ME's Food methyl esters
- Panels A-D Desaturation was represented as %Conversion vs Growth Time (hours) and Product and Substrate levels are represented as %Total Fatty acid vs Growth time (hours).
- Panel A pertains to samples supplied with DHGLA immediately after induction.
- Panel B is overnight induction (22hrs) before feeding.
- Panel C is for cultures supplied with 3X normal DHGLA level.
- Panel D is for cultures supplied with normal rate of DHGLA (0.25 mM) daily.
- Figure 31 Representative time course graphs for all desaturases and elongases. Yeast cells expressing each enzyme were supplied with 0.25 mM of preferred fatty acid substrate, and fatty acid profiles were obtained by GC at the indicated time points. In Panels A-J, Desaturation and Elongation were represented as %Conversion vs Growth Time (hours), and Product and Substrate levels were represented as %Total Fatty acid vs Growth time (hours).A. c- d5Des(Tc_GA2) + DHGLA B. c-d6Des(Ot_febit) + ALA C. c-d4Des(PI_GA)2 + DTA D.
- Figure 32 Conversion efficiencies of delta-12-desaturation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. Shown are average conversion efficiencies of various plant populations, as well as the conversion efficiencies observed in a seedbacth of event LBFDAU having highest EPA+DHA levels, and those efficiencies observed in a single seed of that seedbatch, where this single seed had highest EPA+DHA levels among all 95 measured single seeds. Data were taken from Example 10 to Example 18. TO and T1 designates the plant generation producing the seeds (all grown in the greenhouse except for the two LBFDAU data points)
- Figure 33 Conversion efficiencies of delta-6-desaturation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
- Figure 34 Conversion efficiencies of delta-6-elongation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
- Figure 35 Conversion efficiencies of delta-5-desaturation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
- Figure 36 Conversion efficiencies of omega-3 desaturation (excluding C18 fatty acids) in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
- Figure 37 Conversion efficiencies of omega-3 desaturation (including C18 fatty acids) in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
- Figure 38 Conversion efficiencies of delta-5-elongation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
- Figure 39 Conversion efficiencies of delta-4-desturation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
- Figure 40 The sum of all pathway fatty acids was negatively correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 41 The sum of all pathway fatty acids was negatively correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 42 The sum of all pathway fatty acids was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
- Figure 43 The sum of all pathway fatty acids was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
- Figure 44 The conversion efficiency of the delta-12-desaturase was negatively correlated with seed oil content. Shown are data of 3 generations of event LANPMZ.
- one marker corresponds to one seed batch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 45 The conversion efficiency of the delta-12-desaturase was negatively correlated with seed oil content. Shown are data of 4 generations of event LAODDN.
- one marker corresponds to one seed batch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 46 The conversion efficiency of the delta-12-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFGKN.
- one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
- Figure 47 The conversion efficiency of the delta-12-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
- Figure 48 The conversion efficiency of the delta-6-desaturase was negatively correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 49 The conversion efficiency of the delta-6-desaturase was negatively correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 50 The conversion efficiency of the delta-6-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
- Figure 51 The conversion efficiency of the delta-6-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
- Figure 52 The conversion efficiency of the delta-6 elongase was not negatively correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 53 The conversion efficiency of the delta-6 elongase was not negatively correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 54 The conversion efficiency of the delta-6 elongase was not negatively correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
- Figure 55 The conversion efficiency of the delta-6 elongase was not negatively correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
- Figure 56 The conversion efficiency of the delta-5-desaturase was not correlated with seed oil content. Shown are data of 3 generations of event LANPMZ.
- one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 57 The conversion efficiency of the delta-5-desaturase was not correlated with seed oil content. Shown are data of 4 generations of event LAODDN.
- one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 58 The conversion efficiency of the delta-5-desaturase was not correlated with seed oil content. Shown are data of 2 generations of event LBFGKN.
- one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
- Figure 59 The conversion efficiency of the delta-5-desaturase was not correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
- Figure 60 The conversion efficiency of the omega-3-desaturase was not correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 61 The conversion efficiency of the omega-3-desaturase was not correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 62 The conversion efficiency of the omega-3-desaturase was not correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
- Figure 63 The conversion efficiency of the omega-3-desaturase was not correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
- Figure 64 The conversion efficiency of the delta-5-elongase was not correlated with seed oil content. Shown are data of 3 generations of event LANPMZ.
- one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 65 The conversion efficiency of the delta-5-elongase was not correlated with seed oil content. Shown are data of 4 generations of event LAODDN.
- one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 66 The conversion efficiency of the delta-5-elongase was not correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
- Figure 67 The conversion efficiency of the delta-5-elongase was not correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing one plot.
- Figure 68 The conversion efficiency of the delta-4-desaturase was negatively correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 69 The conversion efficiency of the delta-4-desaturase was negatively correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 70 The conversion efficiency of the delta-4-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
- Figure 71 The conversion efficiency of the delta-4-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
- Figure 72 The sum of all pathway fatty acids was not correlated with seed oil content in wildtype canola, but differs between greenhouse and field. Shown are data of three seasons. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 73 The total fatty acid percentage of 20:5n-3 (EPA) correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- EPA fatty acid percentage
- Figure 74 The total fatty acid percentage of 20:5n-3 (EPA) correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- Figure 75 The total fatty acid percentage of 20:5n-3 (EPA) correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
- Figure 76 The total fatty acid percentage of 20:5n-3 (EPA) correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
- Figure 77 The total fatty acid percentage of 22:6n-3 (DHA) correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- DHA 22:6n-3
- Figure 78 The total fatty acid percentage of 22:6n-3 (DHA) correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
- DHA 22:6n-3
- Figure 79 The total fatty acid percentage of 22:6n-3 (DHA) correlated with seed oil content. Shown are data of 2 generations of event LBFGKN.
- one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches
- one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
- Figure 80 The total fatty acid percentage of 22:6n-3 (DHA) correlated with seed oil content. Shown are data of 2 generations of event LBFLFK.
- one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches
- one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
- Figure 81 The levels of EPA+DHA (20:5n-3 and 22:6n-3) correlated with seed oil content. Shown are data of homozygous plants (single plant: capital G or F, plots: lower case f, grown in greenhouses: G, grown in field trials: f and F). The data are described in more detail in Example 12 (event LANBCH), and Example 14 (all other events).
- Figure 82 The levels of ARA (20:4n-6) correlated with seed oil content. Shown are data of homozygous plants (single plant: capital G or F, plots: lower case f, grown in greenhouses: G, grown in field trials: f and F). The data are described in more detail in Example 12 (event LANBCH), and Example 14 (all other events).
- Figure 83 The levels of EPA (20:5n-3) correlated with seed oil content. Shown are data of homozygous plants (single plant: capital G or F, plots: lower case f, grown in greenhouses: G, grown in field trials: f and F). The data are described in more detail in Example 12 (event LANBCH), and Example 14 (all other events).
- Figure 84 The levels of DHA (22:6n-3) correlated with seed oil content. Shown are data of homozygous plants (single plant: capital G or F, plots: lower case f, grown in greenhouses: G, grown in field trials: f and F). The data are described in more detail in Example 12 (event LANBCH), and example 14 (all other events).
- FIG 85 Examples of Desaturase Enzyme Activity in Transgenic Brassica napus.
- [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using an Instant Imager. Duplicate reactions are shown for each enzyme activity in Panels A-C.
- delta- 6 desaturase (Ostreococcus tauri) activity was demonstrated by the presence of [14C]18:3n-6 ME using membranes isolated from transgenic Brassica napus. This desaturase activity was not present in membranes derived from a wild-type (Kumily) B. napus.
- Figure 86 Delta-12 desaturase (Phytophthora sojae), c-d12Des(Ps_GA), substrate preference.
- PC phosphatidylcholine
- FFA free fatty acid
- H20 H20
- n Panel A c- d12Des(Ps_GA) enzyme activity is shown using assay conditions to present the fatty acid substrate (18:1 (n-9)) in the acyl-phosphatidylcholine form.
- Desaturated enzymatic product (18:2(n-6)) is found predominantly in the phosphatidylcholine (PC) pool, relative to the free fatty acid (FFA) or H20 (CoA) pools, indicating c-d12Des(Ps_GA) utilizes 18:1 (n-9) attached to phosphatidylcholine as a substrate.
- c-d12Des(Ps_GA) enzyme activity is shown using assay conditions to present the fatty acid substrate (18:1 (n-9)) in the acyl-CoA form.
- Figure 87 Delta-9 desaturase (Saccharomyces cerevisiae), d9Des(Sc) substrate preference.
- PC phosphatidylcholine
- FFA free fatty acid
- H20 CoA, o
- n Panel A d9Des(Sc) enzyme activity is shown using assay conditions to present the fatty acid substrate (16:0) in the acyl-phosphatidylcholine form.
- desaturated enzymatic product (16:1 (n-7)) is not produced in the phosphatidylcholine (PC), free fatty acid (FFA), or H20 (CoA) pools indicating d9Des(Sc) does not utilize 18:0 attached to phosphatidylcholine as a substrate.
- d9Des(Sc) enzyme activity is shown using assay conditions to present the fatty acid substrate (16:0) in the acyl-CoA form.
- Desaturated enzymatic product (16:1 (n-7)) is isolated in both the free fatty acid (FFA) and H20 (CoA) pools, but not the phosphatidylcholine (PC) pool.
- Figure 88 Yield (kg seeds/ha) of canola plants grown in the field in 2014. Plants were either not treated (Yield) or were treated with 2x rate of imidazolinone herbicide (Yield w/herbicide).
- Figure 89 EPA plus DHA content in seeds of plants grown in the field with (Imazamox) or without (control) herbicide treatment. *** denotes a significant difference between herbicide treatment and control as calculated by ANOVA, p ⁇ 0.05.
- Figure 90 Oil content in seeds of plants grown in the field with (Imazamox) or without (control) herbicide treatment. *** denotes a significant difference between herbicide treatment and control as calculated by ANOVA, p ⁇ 0.05.
- Figure 91 Protein content in seeds of plants grown in the field with (Imazamox) or without (control) herbicide treatment. *** denotes a significant difference between herbicide treatment and control as calculated by ANOVA, p ⁇ 0.05.
- Figure 92 is a map of binary transformation vector VC-LTM593-1 qcz rc, used to generate Brassica plants comprising event LBFLFK and Brassica plants comprising event LBFDAU.
- Figure 93 shows the organization T-DNA locus 1 in the genome of a plant comprising Brassica event LBFLFK.
- SEQ ID NO:282 corresponds to the junction region of the Locus 1 T-DNA insert SEQ ID NO:281 and the right border flanking sequence SEQ ID NO:284.
- SEQ ID NO:283 corresponds to the junction region between the Locus 1 T-DNA insert SEQ ID NO:281 and left border flanking sequence SEQ ID NO:285.
- Figure 94 shows the organization of T-DNA Locus 2 in the genome of a plant comprising Brassica event LBFLFK.
- SEQ ID NO:291 corresponds to the junction region of the Locus 2 T-DNA insert SEQ ID NO:290 and the right border flanking sequence SEQ ID NO:293.
- SEQ ID NO:292 corresponds to the junction region of the Locus 2 T-DNA insert SEQ ID NO:290 and left border flanking sequence SEQ ID NO:294.
- Figure 95 shows the organization of T-DNA Locus 1 in the genome of a plant comprising Brassica event LBFDAU.
- SEQ ID NO:300 corresponds to the junction region of the Locus 1 T-DNA insert SEQ ID NO:299 and the right border flanking sequence SEQ ID NO:302.
- SEQ ID NO:301 corresponds to the junction region of the Locus 1 T-DNA insert SEQ ID NO:299 and left border flanking sequence SEQ ID NO:303.
- Figure 96 shows the organization of T-DNA Locus 2 in the genome of a plant comprising Brassica event LBFDAU.
- SEQ ID NO:309 corresponds to the junction region of the Locus 2 T-DNA insert SEQ ID NO:308 and the right border flanking sequence SEQ ID NO:31 1 .
- SEQ ID NO:310 corresponds to the junction region of the Locus 2 T-DNA insert SEQ ID NO:308 and left border flanking sequence SEQ ID NO:312.
- Figure 97 shows the EPA and DHA content of bulked seed batches produced in the field and in the greenhouse from event LBFLFK.
- Figure 98 shows the EPA and DHA content of bulked seed batches produced in the field and in the greenhouse from event LBFDAU.
- Figure 99 shows the distribution of combined EPA plus DHA content in 95 T2 single seeds of event LBFDAU.
- the invention generally pertains to the field of manufacture of fatty acids, particularly for large- scale production of very long chain polyunsaturated fatty acids (VLC-PUFAs, also called polyunsaturated fatty acids or PUFAs), e.g. eicosapentaenoic acid (EPA), omega-3 docosapentaenoic acid (DPA) and docosahexaenoic acid (DHA).
- VLC-PUFAs also called polyunsaturated fatty acids or PUFAs
- EPA eicosapentaenoic acid
- DPA omega-3 docosapentaenoic acid
- DHA docosahexaenoic acid
- the invention particularly is concerned with the production of VLC-PUFAs in plants and thus inter alia provides nucleic acids for transformation of plants to enable such transformed plants to produce VLC-PUFAs.
- the invention also provides transgenic constructs and expression vectors containing desaturase and elongase genes and host cells into which the constructs and expression vectors have been introduced.
- the present invention also relates to methods for the manufacture of oil, fatty acid- or lipids-containing compositions, and to such oils and lipids as such.
- the invention is concerned with methods for further improving the production of VLC-PUFAs in plants.
- Fatty acids are carboxylic acids with long-chain hydrocarbon side groups that play a fundamental role in many biological processes. Fatty acids are rarely found free in nature but, rather, occur in esterified form as the major component of lipids. As such, lipids/fatty acids are sources of energy (e.g., beta-oxidation). In addition, lipids/fatty acids are an integral part of cell membranes and, therefore, are indispensable for processing biological or biochemical information.
- VLC-PUFAs Long chain polyunsaturated fatty acids
- DHA docosahexaenoic acid
- EPA (20:5n-3 5,8,1 1 ,14,17) and also ARA (arachidonic acid, 20:4n-6 (5,8,1 1 ,14)) are both delta 5 (d5) essential fatty acids. They form a unique class of food and feed constituents for humans and animals.
- EPA belongs to the n-3 series with five double bonds in the acyl chain. EPA is found in marine food and is abundant in oily fish from North Atlantic.
- ARA belongs to the n-6 series with four double bonds. The lack of a double bond in the omega-3 position confers on ARA different properties than those found in EPA.
- ARA eicosanoids produced from ARA (sometimes abbreviated "AA”) have strong inflammatory and platelet aggregating properties, whereas those derived from EPA have anti-inflammatory and anti-platelet aggregating properties.
- ARA can be obtained from some foods such as meat, fish and eggs, but the concentration is low.
- GLA Gamma-linolenic acid
- GLA is the metabolic intermediate for very long chain n-6 fatty acids and for various active molecules. In mammals, formation of long chain polyunsaturated fatty acids is rate-limited by delta-6 desaturation. Many physiological and pathological conditions such as aging, stress, diabetes, eczema, and some infections have been shown to depress the delta-6 desaturation step. In addition, GLA is readily catabolized from the oxidation and rapid cell division associated with certain disorders, e.g., cancer or inflammation. Therefore, dietary supplementation with GLA can reduce the risks of these disorders. Clinical studies have shown that dietary supplementation with GLA is effective in treating some pathological conditions such as atopic eczema, premenstrual syndrome, diabetes, hypercholesterolemia, and inflammatory and cardiovascular disorders.
- VLC-PUFAs very long chain poly unsaturated fatty acids
- the invention is thus concerned with providing a reliable source for easy manufacture of VLC- PUFAs.
- the invention is also concerned with providing plants reliably producing VLC- PUFAS, preferably EPA and/or DHA.
- the invention is also concerned with providing means and methods for obtaining, improving and farming such plants, and also with VLC-PUFA containing oil obtainable from such plants, particularly from the seeds thereof. Also, the invention provides uses for such plants and parts thereof. According to the invention there is thus provided a T-DNA for expression of a target gene in a plant.
- the invention beneficially provides a system for transformation of plant tissue and for generation of recombinant plants, wherein the recombinant plant differs from the respective parental plant (for the purposes of the present invention the parental plant is termed a wild-type plant regardless of whether or not such parental plant is as such found in nature) by the introduction of T-DNA.
- the T-DNA introduced into the parental plant beneficially has a length of at least 30000 nucleotides.
- the invention also provides plants with a genotype that confers a heritable phenotype of high seed oil VLC-PUFA content in one or more of their tissues or components, preferably a high content of EPA and/or DHA in seed oil.
- the invention further provides material comprising a high VLC-PUFA content relative to their total oil content, preferably a high content of EPA and/or DHA.
- the invention provides exemplary events of Brassica plants. Most beneficially the invention provides oil comprising a high VLC-PUFA content, preferably a high content of EPA and/or DHA.
- the invention also provides methods of producing an oil, wherein the oil has a high VLC-PUFA content, a high content of EPA and/or DHA. In particularly preferred aspects these methods are for producing a corresponding plant oil. Thus, invention also provides methods of producing an oil.
- the invention also provides methods for creating a plant, such that the plant or progeny thereof can be used as a source of an oil, wherein the oil has a high VLC-PUFA content, a high content of EPA and/or DHA.
- the invention beneficially also provides methods for the production of plants having a heritable phenotype of high seed oil VLC-PUFA content in one or more of their tissues or components, preferably a high content of EPA and/or DHA in seed oil.
- the present invention also provides a method for increasing the content of Mead acid (20:3n-9) in a plant relative to a control plant, comprising expressing in a plant, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase.
- the invention also provides means for optimizing a method for creating plants according to the invention.
- the invention provides a system of methods for analyzing enzyme specificities, particularly for analyzing desaturase reaction specificity and for analyzing elongase specificities, for optimization of a metabolic pathway and for determining CoA-dependence of a target desaturase.
- PUFA polyunsaturated fatty acids
- VLC-PUFA long chain PUFA
- polyunsaturated fatty acids in the sense of the present invention are DHGLA 20:3 (8,1 1 ,14), ARA 20:4 (5,8,1 1 ,14), ETA 20:4 (8,1 1 ,14,17), EPA 20:5 (5,8,1 1 ,14,17), DPA 22:5 (4,7,10,13,16), DPA n-3 (7,10,13,16,19), DHA 22:6 (4,7,10,13,16,19), more preferably, eicosapentaenoic acid (EPA) 20:5 (5,8,1 1 ,14,17), and docosahexaenoic acid (DHA) 22:6 (4,7,10,13,16,19).
- DHGLA 20:3 8,1 1 ,14
- ARA 20:4 (5,8,1 1 ,14), ETA 20:4 (8,1 1 ,14,17)
- EPA 20:5 5,8,1 1 ,14,17
- the methods provided by the present invention pertaining to the manufacture of EPA and/or DHA.
- the intermediates of VLC-PUFA which occur during synthesis.
- Such intermediates are, preferably, formed from substrates by the desaturase, keto-acyl-CoA- synthase, keto-acyl-CoA-reductase, dehydratase and enoyl-CoA-reductase activity of the polypeptide of the present invention.
- substrates encompass LA 18:2 (9,12), GLA 18:3 (6,9,12), DHGLA 20:3 (8,1 1 ,14), ARA 20:4 (5,8,1 1 ,14), eicosadienoic acid 20:2 (1 1 ,14), eicosatetraenoic acid 20:4 (8,1 1 ,14,17), eicosapentaenoic acid 20:5 (5,8,1 1 ,14,17).
- Systematic names of fatty acids including polyunsaturated fatty acids, their corresponding trivial names and shorthand notations used according to the present invention are given in table Table 18 (and in table 181 ).
- the transgenic plants of this invention produce a number of VLC-PUFA and intermediates that are non-naturally occurring in wild type Brassica plants. While these VLC- PUFA and intermediates may occur in various organisms, they do not occur in wild type Brassica plants.
- These fatty acids include 18:2n-9, GLA, SDA, 20:2n-9, 20:3n-9, 20:3 n-6, 20:4n-6, 22:2n- 6, 22:5n-6, 22:4n-3, 22:5n-3, and 22:6n-3.
- cultivating refers to maintaining and growing the transgenic plant under culture conditions which allow the cells to produce the said polyunsaturated fatty acids, i.e. the PUFAs and/or VLC-PUFAs referred to above. This implies that the polynucleotide of the present invention is expressed in the transgenic plant so that the desaturase, elongase as also the keto- acyl-CoA-synthase, keto-acyl-CoA-reductase, dehydratase and enoyl-CoA-reductase activity is present. Suitable culture conditions for cultivating the host cell are described in more detail below.
- the term "obtaining" as used herein encompasses the provision of the cell culture including the host cells and the culture medium or the plant or plant part, particularly the seed, of the current invention, as well as the provision of purified or partially purified preparations thereof comprising the polyunsaturated fatty acids, preferably, ARA, EPA, DHA, in free or in CoA bound form, as membrane phospholipids or as triacylglyceride esters. More preferably, the PUFA and VLC-PUFA are to be obtained as triglyceride esters, e.g., in form of an oil. More details on purification techniques can be found elsewhere herein below.
- polynucleotide refers to a desoxyribonucleic acid or ribonucleic acid. Unless stated otherwise, "polynucleotide” herein refers to a single strand of a DNA polynucleotide or to a double stranded DNA polynucleotide.
- the length of a polynucleotide is designated according to the invention by the specification of a number of basebairs ("bp") or nucleotides ("nt"). According to the invention, both specifications are used interchangeably, regardless whether or not the respective nucleic acid is a single or double stranded nucleic acid.
- nucleotide/polynucleotide and nucleotide sequence/polynucleotide sequence are used interchangeably, thus that a reference to a nucleic acid sequence also is meant to define a nucleic acid comprising or consisting of a nucleic acid stretch the sequence of which is identical to the nucleic acid sequence.
- polynucleotide as used in accordance with the present invention as far as it relates to a desaturase or elongase gene relates to a polynucleotide comprising a nucleic acid sequence which encodes a polypeptide having desaturase or elongase activity.
- the polypeptide encoded by the polynucleotide of the present invention having desaturase, or elongase activity upon expression in a plant shall be capable of increasing the amount of PUFA and, in particular, VLC-PUFA in, e.g., seed oils or an entire plant or parts thereof.
- Whether an increase is statistically significant can be determined by statistical tests well known in the art including, e.g., Student's t-test with a confidentiality level of at least 90%, preferably of at least 95% and even more preferably of at least 98%. More preferably, the increase is an increase of the amount of triglycerides containing VLC-PUFA of at least 5%, at least 10%, at least 15%, at least 20% or at least 30% compared to wildtype control (preferably by weight), in particular compared to seeds, seed oil, extracted seed oil, crude oil, or refined oil from a wild-type control.
- the VLC-PUFA referred to before is a polyunsaturated fatty acid having a C20, C22 or C24 fatty acid body, more preferably EPA or DHA. Lipid analysis of oil samples are shown in the accompanying Examples.
- polypeptides having desaturase or elongase activity as shown in Table 130 in the Examples section of Section A (the SEQ ID Nos of the nucleic acid sequences and the polypeptide sequences are given in the last two columns).
- the content of certain fatty as shall be decreased or, in particular, increased as compared to the oil obtained or obtainable from a control plant.
- the choice of suitable control plants is a routine part of an experimental setup and may include corresponding wild type plants or corresponding plants without the polynucleotides as encoding desaturases and elongase as referred to herein.
- the control plant is typically of the same plant species or even of the same variety as the plant to be assessed.
- the control plant may also be a nullizygote of the plant to be assessed.
- Nullizygotes are individuals missing the transgene by segregation. Further, control plants are grown under the same or essentially the same growing conditions to the growing conditions of the plants of the invention, i.e. in the vicinity of, and simultaneously with, the plants of the invention.
- a "control plant” as used herein preferably refers not only to whole plants, but also to plant parts, including seeds and seed parts. The control could also be the oil from a control plant. Preferably, the control plant is an isogenic control plant. Thus, e.g. the control oil or seed shall be from an isogenic control plant.
- the fatty acid esters with polyunsaturated C20- and/or C22-fatty acid molecules can be isolated in the form of an oil or lipid, for example, in the form of compounds such as sphingolipids, phosphoglycerides, lipids, glycolipids such as glycosphingolipids, phos-pholipids such as phosphatidylethanolamine, phosphatidylcholine, phosphatidylserine, phosphatidylglycerol, phosphatidylinositol or diphosphatidylglycerol, monoacylglycerides, diacylglycerides, triacylglycerides or other fatty acid esters such as the acetylcoenzyme A esters which comprise the polyunsaturated fatty acids with at least two, three, four, five or six, preferably five or six, double bonds, from the organisms which were used for the preparation of the fatty acid esters.
- compounds such as sphingolipid
- the polyunsaturated fatty acids are also present in the non-human transgenic organisms or host cells, preferably in the plants, as free fatty acids or bound in other compounds.
- the various abovementioned compounds are present in the organisms with an approximate distribution of 80 to 90% by weight of triglycerides, 2 to 5% by weight of diglycerides, 5 to 10% by weight of monoglycerides, 1 to 5% by weight of free fatty acids, 2 to 8% by weight of phospholipids, the total of the various compounds amounting to 100% by weight.
- the VLC-PUFAs which have been produced are produced in a content as for DHA of at least 5,5% by weight, at least 6% by weight, at least 7% by weight, advantageously at least 8% by weight, preferably at least 9% by weight, especially preferably at least 10,5% by weight, very especially preferably at least 20% by weight, as for EPA of at least 9,5% by weight, at least 10% by weight, at least 1 1 % by weight, advantageously at least 12% by weight, preferably at least 13% by weight, especially preferably at least 14,5% by weight, very especially preferably at least 30% by weight based on the total fatty acids in the non- human transgenic organisms or the host cell referred to above.
- the fatty acids are, preferably, produced in bound form.
- these unsaturated fatty acids prefferably be positioned at the sn1 , sn2 and/or sn3 position of the triglycerides which are, preferably, to be produced.
- the polynucleotides and polypeptides of the present invention may be used with at least one further polynucleotide encoding an enzyme of the fatty acid or lipid biosynthesis.
- Preferred enzymes are in this context the desaturases and elongases as mentioned above, but also a polynucleotide encoding an enzyme having delta-8-desaturase and/or delta-9-elongase activity. All these enzymes reflect the individual steps according to which the end products of the method of the present invention, for example EPA or DHA are produced from the starting compounds oleic acid (C18:1 ), linoleic acid (C18:2) or linolenic acid (C18:3).
- these compounds are not generated as essentially pure products. Rather, small traces of the precursors may be also present in the end product. If, for example, both linoleic acid and linolenic acid are present in the starting host cell, organism, or the starting plant, the end products, such as EPA or DHA, are present as mixtures.
- the precursors should advantageously not amount to more than 20% by weight, preferably not to more than 15% by weight, more preferably, not to more than 10% by weight, most preferably not to more than 5% by weight, based on the amount of the end product in question.
- the end products such as EPA or DHA
- the precursors should advantageously not amount to more than 60% by weight, preferably not to more than 40% by weight, more preferably, not to more than 20% by weight, most preferably not to more than 10% by weight, based on the amount of the end product in question.
- EPA or DHA preferably only DHA, bound or as free acids, is/are produced as end product(s) in the process of the invention in a host cell.
- the compounds EPA and DHA are produced simultaneously, they are, preferably, produced in a ratio of at least 1 :2 (DHA:EPA), more preferably, the ratios are at least 1 :5 and, most preferably, 1 :8.
- Fatty acid esters or fatty acid mixtures produced by the invention preferably, comprise 6 to 15% of palmitic acid, 1 to 6% of stearic acid, 7-85% of oleic acid, 0.5 to 8% of vaccenic acid, 0.1 to 1 % of arachidic acid, 7 to 25% of saturated fatty acids, 8 to 85% of monounsaturated fatty acids and 60 to 85% of polyunsaturated fatty acids, in each case based on 100% and on the total fatty acid content of the organisms.
- DHA as a preferred long chain polyunsaturated fatty acid is present in the fatty acid esters or fatty acid mixtures in a concentration of, preferably, at least 0.1 ; 0.2; 0.3; 0.4; 0.5; 0.6; 0.7; 0.8; 0.9 or 1 %, based on the total fatty acid content.
- Chemically pure VLC-PUFAs or fatty acid compositions can also be synthesized by the methods described herein. To this end, the fatty acids or the fatty acid compositions are isolated from a corresponding sample via extraction, distillation, crystallization, chromatography or a combination of these methods. These chemically pure fatty acids or fatty acid compositions are advantageous for applications in the food industry sector, the cosmetic sector and especially the pharmacological industry sector.
- the term “desaturase” encompasses all enzymatic activities and enzymes catalyzing the desaturation of fatty acids with different lengths and numbers of unsaturated carbon atom double bonds. Specifically this includes delta 4 (d4)-desaturase, catalyzing the dehydrogenation of the 4th and 5th carbon atom; Delta 5 (d5)-desaturase catalyzing the dehydrogenation of the 5th and 6th carbon atom; Delta 6 (d6)-desaturase catalyzing the dehydrogenation of the 6th and 7th carbon atom; Delta 8 (d8)-desaturase catalyzing the dehydrogenation of the 8th and 9th carbon atom; Deta 9 (d9)-desaturase catalyzing the dehydrogenation of the 9th and 10th carbon atom; Delta 12 (d12)-desaturase catalyzing the dehydrogenation of the 12th and 13th carbon atom; Delta 15 (d15)-desaturase catalyzing the dehydr
- An omega 3 (o3)-desaturase preferably catalyzes the dehydrogenation of the n-3 and n-2 carbon atom.
- the terms “elongase” encompasses all enzymatic activities and enzymes catalyzing the elongation of fatty acids with different lengths and numbers of unsaturated carbon atom double bonds.
- the term “elongase” as used herein refers to the activity of an elongase, introducing two carbon molecules into the carbon chain of a fatty acid, preferably in the positions 1 , 5, 6, 9, 12 and/or 15 of fatty acids, in particular in the positions 5, 6, 9, 12 and/or 15 of fatty acids.
- elongase as used herein preferably refers to the activity of an elongase, introducing two carbon molecules to the carboxyl ends ⁇ i.e. position 1 ) of both saturated and unsaturated fatty acids.
- Tables 1 1 and 130 in the Examples section list preferred polynucleotides encoding for preferred desaturases or elongases to be used in the present invention.
- polynucleotides for desaturases or elongases that can be used in the context of the present invention are shown in Table 1 1 and 130, respectively.
- the SEQ ID NOs of these desaturases and elongases are shown in the last two columns of Table 130 (nucleic acid sequence and amino acid sequence).
- Table 130 nucleic acid sequence and amino acid sequence
- Polynucleotides encoding polypeptides which exhibit delta-6-elongase activity have been described in WO2001/059128, WO2004/087902 and WO2005/012316, said documents, describing this enzyme from Physcomitrella patens, are incorporated herein in their entirety.
- Polynucleotides encoding polypeptides which exhibit delta-5-desaturase activity have been described in WO2002026946 and WO2003/093482, said documents, describing this enzyme from Thraustochytrium sp., are incorporated herein in their entirety.
- the delta-6-desaturase is a CoA (Coenzyme A)-dependent delta-6-desaturase.
- CoA Coenzyme A
- Such enzymes are well known in the art.
- the delta-6-desaturase from Ostreococcus tauri used in the the example section is a Coenzyme A- dependent delta-6-desaturase.
- the use of CoA (Coenzyme A)-dependent delta-6-desaturase in combination with a delta-12-desaturase may allow for reducing the content of 18:1 n-9 in seeds, in particular in seed oil, as compared to a control.
- CoA-dependent delta-6-desaturase in combination with a delta-6-elongase may allow for reducing the content of 18:3n-6 in seeds, in particular in seed oil, as compared to using a phospholipid-dependent delta-6-desaturase in combination with a delta-6-elongase.
- Polynucleotides encoding polypeptides which exhibit delta-6-elongase activity have been described in WO2005/012316, WO2005/007845 and WO2006/069710, said documents, describing this enzyme from Thalassiosira pseudonana, are incorporated herein in their entirety.
- Polynucleotides encoding polypeptides which exhibit omega 3-desaturase activity have been described for example in WO2005012316 and WO2005083053, said documents, describing this enzyme from Phytophthora infestans, are incorporated herein in their entirety.
- Polynucleotides encoding polypeptides which exhibit delta-4-desaturase activity have been described for example in WO2002026946, said documents, describing this enzyme from Thraustochytrium sp., are incorporated herein in their entirety.
- polynucleotides encoding the aforementioned polypeptides are herein also referred to as "target genes" or "nucleic acid of interest".
- the polynucleotides are well known in the art.
- the sequences of said polynucleotides can be found in the sequence of the T-DNAs disclosed in the Examples section (see e.g. the sequence of VC-LTM593-1 qcz which has a sequence as shown in SEQ ID NO: 3).
- SEQ ID Nos for the preferred polynucleotide and and polypeptide sequences are also given in Table 130 in the Examples section.
- sequences of preferred polynucleotides for the desaturases and elongases referred to herein in connection with the present invention are indicated below. As set forth elsewhere herein, also variants of the polynucleotides can be used.
- the polynucleotides encoding for desaturases and elogases to be used in accordance with the present invention can be derived from certain organisms. Preferably, a polynucleotide derived from an organism (e.g from Physcomitrella patens) is codon-optimized. In particular, the polynucleotide shall be codon-optimized for expression in a plant.
- a codon optimized polynucleotide is a polynucleotide which is modified by comparison with the nucleic acid sequence in the organism from which the sequence originates in that it is adapted to the codon usage in one or more plant species.
- the polynucleotide, in particular the coding region is adapted for expression in a given organism (in particular in a plant) by replacing at least one, or more than one of codons with one or more codons that are more frequently used in the genes of that organism (in particular of the plant).
- a codon optimized variant of a particular polynucleotide "from an organism" (or "derived from an organism") preferably shall be considered to be a polynucleotide derived from said organism.
- a codon-optimized polynucleotide shall encode for the same polypeptide having the same sequence as the polypeptide encoded by the non codon-optimized polynucleotide (i.e. the wild-type sequence).
- codon optimized polynucleotides were used (for the desaturases).
- the codon optimized polynucleotides are comprised by the T-DNA of the vector having a sequence as shown in SEQ ID NO: 3 (see table 130).
- a delta-6-elongase to be used in accordance with the present invention is derived from Physcomitrella patens.
- a preferred sequence of said delta-6-elongase is shown in SEQ ID NO:258.
- said delta-6-elongase is encoded by a polynucleotide derived from Physcomitrella patens, in particular, said delta-6-elongase is encoded by a codon-optimized variant thereof (i.e. of said polynucleotide).
- the polynucleotide encoding the delta-6- elongase derived from Physcomitrella patens is a polynucleotide having a sequence as shown in nucleotides 1267 to 2139 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 257 (Thus, the polynucleotide encoding the delta-6-elongase derived from Physcomitrella patens preferably has a sequence as shown in SEQ ID NO: 257).
- a delta-5-desaturase to be used in accordance with the present invention is derived from Thraustochytrium sp..
- Thraustochytrium sp. in the context of the present invention preferably means Thraustochytrium sp. ATCC21685.
- a preferred sequence of said delta-5-desaturase is shown in SEQ ID NO:260.
- said delta-5-desaturase is encoded by a polynucleotide derived from Thraustochytrium sp.; in particular, said delta-5-desaturase is encoded by a codon- optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-5- desaturase derived from Thraustochytrium sp. is a polynucleotide having a sequence as shown in nucleotides 3892 to 521 1 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 259.
- a delta-6-desaturase to be used in accordance with the present invention is derived from Ostreococcus tauri.
- a preferred sequence of said delta-6-desaturase is shown in SEQ ID NO:262.
- said delta-6-desaturase is encoded by a polynucleotide derived from Ostreococcus tauri; in particular, said delta-6-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-6-desaturase derived from Ostreococcus tauri is a polynucleotide having a sequence as shown in nucleotides 7802 to 9172 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 261.
- a delta-6-elongase to be used in accordance with the present invention is derived from Thalassiosira pseudonana.
- a preferred sequence of said delta-6-elongase is shown in SEQ ID NO:264.
- said delta-6-elongase is encoded by a polynucleotide derived from Thalassiosira pseudonana; in particular, said delta-6-elongase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-6-elongase derived from Thalassiosira pseudonana is a polynucleotide having a sequence as shown in nucleotides 12099 to 12917 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 263.
- a delta-12-elongase to be used in accordance with the present invention is derived from Phytophthora sojae.
- a preferred sequence of said delta-12-elongase is shown in SEQ ID NO:266.
- said delta-12-elongase is encoded by a polynucleotide derived from Phytophthora sojae; in particular, said delta-12-elongase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-12-elongase derived from Phytophthora sojae is a polynucleotide having a sequence as shown in nucleotides 14589 to 15785 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 265.
- a delta-5-elongase to be used in accordance with the present invention is derived from Ostreococcus tauri.
- a preferred sequence of said delta-5-elongase is shown in SEQ ID NO:276.
- said delta-5-elongase is encoded by a polynucleotide derived from Ostreococcus tauri; in particular, said delta-5-elongase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-5-elongase derived from Ostreococcus tauri is a polynucleotide having a sequence as shown in nucleotides 38388 to 39290 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 275.
- an omega 3-desaturase to be used in accordance with the present invention is derived from Pythium irregulare.
- a preferred sequence of said omega 3-desaturase is shown in SEQ ID NO:268.
- said omega 3-desaturase is encoded by a polynucleotide derived from Pythium irregulare; in particular, said omega 3-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the omega 3-desaturase derived from Pythium irregulare is a polynucleotide having a sequence as shown in nucleotides 17690 to 18781 of SEQ ID NO: 3.
- this polynucleotide is also shown in SEQ ID No: 267.
- the T-DNA, construct, plant, seed etc. of the present invention shall comprise two (or more) copies of a polynucleotide encoding a omega 3-desaturase derived from Pythium irregulare
- an omega 3-desaturase to be used in accordance with the present invention is derived from Phytophthora infestans.
- a preferred sequence of said omega 3-desaturase is shown in SEQ ID NO:270.
- said omega 3-desaturase is encoded by a polynucleotide derived from Phytophthora infestans; in particular, said omega 3-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the omega 3-desaturase derived from Phytophthora infestans is a polynucleotide having a sequence as shown in nucleotides 20441 to 21526 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 269.
- the present invention it is in particular envisaged to express two or more polynucleotides encoding for omega 3-desaturases in the plant.
- at least one polynucleotide encoding an omega 3-desaturase from Phytophthora infestans and at least one polynucleotide (in particular two polynucleotides, i.e. two copies of a polynucleotide) encoding an omega 3-desaturase from Pythium irregulare are expressed.
- a delta-4-desaturase to be used in accordance with the present invention is derived from Thraustochytrium sp..
- a preferred sequence of said delta-4-desaturase is shown in SEQ ID NO:272.
- said delta-4-desaturase is encoded by a polynucleotide derived from Thraustochytrium sp.; in particular, said delta-4-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-4-desaturase derived from Thraustochytrium sp. is a polynucleotide having a sequence as shown in nucleotides 26384 to 27943 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 271 .
- a delta-4-desaturase to be used in accordance with the present invention is derived from Pavlova lutheri.
- a preferred sequence of said delta-4-desaturase is shown in SEQ ID NO:274.
- said delta-4-desaturase is encoded by a polynucleotide derived from Pavlova lutheri; in particular, said delta-4-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-4-desaturase derived from Pavlova lutheri is a polynucleotide having a sequence as shown in nucleotides 34360 to 35697 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 273.
- a delta-15-desaturase to be used in accordance with the present invention is derived from Cochliobolus heterostrophus.
- said delta-15-desaturase is encoded by a polynucleotide derived from Cochliobolus heterostrophus; in particular, said delta-15-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-15-desaturase derived from Cochliobolus heterostrophus is a polynucleotide having a sequence as shown in nucleotides 2151 to 3654 of SEQ ID NO: 9.
- the polynucleotide encoding a delta-6-elongase can be derived from Physcomitrella patens. Moreover, the polynucleotide encoding a delta-6-elongase can be derived from Thalassiosira pseudonana. In particular, it is envisaged in the context of the present invention to express at least one polynucleotide encoding a delta-6-elongase from Physcomitrella patens and at least one polynucleotide encoding a delta-6-elongase from Thalassiosira pseudonana in the plant. Thus, the T-DNA, plant, seed etc. shall comprise the said polynucleotides.
- a polynucleotide encoding a polypeptide having a desaturase or elongase activity as specified above is obtainable or obtained in accordance with the present invention for example from an organism of genus Ostreococcus, Thraustochytrium, Euglena, Thalassiosira, Phytophthora, Pythium, Cochliobolus, Physcomitrella.
- orthologs, paralogs or other homologs may be identified from other species.
- plants such as algae, for example Isochrysis, Mantoniella, Crypthecodinium, algae/diatoms such as Phaeodactylum, mosses such as Ceratodon, or higher plants such as the Primulaceae such as Aleuritia, Calendula stellata, Osteospermum spinescens or Osteospermum hyoseroides, microorganisms such as fungi, such as Aspergillus, Entomophthora, Mucor or Mortierella, bacteria such as Shewanella, yeasts or animals.
- Preferred animals are nematodes such as Caenorhabditis, insects or vertebrates.
- the nucleic acid molecules may, preferably, be derived from Euteleostomi, Actinopterygii; Neopterygii; Teleostei; Euteleostei, Protacanthopterygii, Salmoniformes; Salmonidae or Oncorhynchus, more preferably, from the order of the Salmoniformes, most preferably, the family of the Salmonidae, such as the genus Salmo, for example from the genera and species Oncorhynchus mykiss, Trutta trutta or Salmo trutta fario.
- nucleic acid molecules may be obtained from the diatoms such as the genera Thalassiosira or Phaeodactylum.
- polynucleotide as used in accordance with the present invention further encompasses variants or derivatives of the aforementioned specific polynucleotides representing orthologs, paralogs or other homologs of the polynucleotide of the present invention.
- variants or derivatives of the polynucleotide of the present invention also include artificially generated muteins. Said muteins include, e.g., enzymes which are generated by mutagenesis techniques and which exhibit improved or altered substrate specificity, or codon optimized polynucleotides.
- Nucleic acid variants or derivatives according to the invention are polynucleotides which differ from a given reference polynucleotide by at least one nucleotide substitution, addition and/or deletion. If the reference polynucleotide codes for a protein, the function of this protein is conserved in the variant or derivative polynucleotide, such that a variant nucleic acid sequence shall still encode a polypeptide having a desaturase or elongase activity as specified above. Variants or derivatives also encompass polynucleotides comprising a nucleic acid sequence which is capable of hybridizing to the aforementioned specific nucleic acid sequences, preferably, under stringent hybridization conditions.
- stringent hybridization conditions are known to the skilled in the art and can be found in Current Protocols in Molecular Biology, John Wiley & Sons, N. Y. (1989), 6.3.1-6.3.6.
- SSC sodium chloride/sodium citrate
- wash steps in 0.2X SSC, 0.1 % SDS at 50 to 65°C.
- the skilled worker knows that these hybridization conditions differ depending on the type of nucleic acid and, for example when organic solvents are present, with regard to the temperature and concentration of the buffer.
- the temperature under standard hybridization conditions ranges depending on the type of nucleic acid between 42°C and 58°C in aqueous buffer with a concentration of 0.1 to 5X SSC (pH 7.2). If organic solvent is present in the abovementioned buffer, for example 50% formamide, the temperature under standard conditions is approximately 42°C.
- the hybridization conditions for DNA: DNA hybrids are, preferably, 0.1X SSC and 20°C to 45°C, preferably between 30°C and 45°C.
- the hybridization conditions for DNA:RNA hybrids are, preferably, 0.1X SSC and 30°C to 55°C, preferably between 45°C and 55°C.
- the skilled worker knows how to determine the hybridization conditions required by referring to textbooks such as the textbook mentioned above, or the following textbooks: Sambrook et al., “Molecular Cloning", Cold Spring Harbor Laboratory, 1989; Hames and Higgins (Ed.) 1985, “Nucleic Acids Hybridization: A Practical Approach”, IRL Press at Oxford University Press, Oxford; Brown (Ed.) 1991 , “Essential Molecular Biology: A Practical Approach”, IRL Press at Oxford University Press, Oxford.
- stringent hybridization conditions encompass hybridization at 65°C in 1x SSC, or at 42°C in 1x SSC and 50% formamide, followed by washing at 65°C in 0.2x SSC. In another embodiment, stringent hybridization conditions encompass hybridization at 65°C in 1x SSC, or at 42°C in 1x SSC and 50% formamide, followed by washing at 65°C in 0.1 x SSC.
- polynucleotide variants are obtainable by PCR-based techniques such as mixed oligonucleotide primer based amplification of DNA, i.e. using degenerate primers against conserved domains of the polypeptides of the present invention.
- conserved domains of the polypeptide of the present invention may be identified by a sequence comparison of the nucleic acid sequences of the polynucleotides or the amino acid sequences of the polypeptides of the present invention.
- Oligonucleotides suitable as PCR primers as well as suitable PCR conditions are described in the accompanying Examples.
- DNA or cDNA from bacteria, fungi, plants or animals may be used as a template.
- variants include polynucleotides comprising nucleic acid sequences which are at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 98% or at least 99% identical to the nucleic acid coding sequences shown in any one of the T-DNA sequences given in the corresponding tables of the examples.
- the variants must retain the function of the respective enzyme, e.g. a variant of a delta-4-desaturase shall have delta-4-desaturase activity.
- the percent identity values are, preferably, calculated over the entire amino acid or nucleic acid sequence region.
- the percent identity between two amino acid sequences is determined using the Needleman and Wunsch algorithm (Needleman 1970, J. Mol. Biol. (48):444-453) which has been incorporated into the needle program in the EMBOSS software package (EMBOSS: The European Molecular Biology Open Software Suite, Rice, P., Longden, I., and Bleasby, A., Trends in Genetics 16(6), 276-277, 2000), a BLOSUM62 scoring matrix, and a gap opening penalty of 10 and a gap entension pentalty of 0.5.
- EMBOSS European Molecular Biology Open Software Suite
- parameters to be used for aligning two amino acid sequences using the needle program are the default parameters, including the EBLOSUM62 scoring matrix, a gap opening penalty of 10 and a gap extension penalty of 0.5.
- the percent identity between two nucleotide sequences is determined using the needle program in the EMBOSS software package (EMBOSS: The European Molecular Biology Open Software Suite, Rice, P., Longden, I., and Bleasby, A., Trends in Genetics 16(6), 276-277, 2000), using the EDNAFULL scoring matrix and a gap opening penalty of 10 and a gap extension penalty of 0.5.
- EMBOSS European Molecular Biology Open Software Suite
- Rice P., Longden, I., and Bleasby, A., Trends in Genetics 16(6), 276-277, 2000
- a preferred, non-limiting example of parameters to be used in conjunction for aligning two nucleic acid sequences using the needle program are the default parameters, including the EDNAFULL scoring matrix, a gap opening penalty of 10 and a gap extension penalty of 0.5.
- nucleic acid and protein sequences of the present invention can further be used as a "query sequence" to perform a search against public databases to, for example, identify other family members or related sequences.
- search can be performed using the BLAST series of programs (version 2.2) of Altschul et al. (Altschul 1990, J. Mol. Biol. 215:403-10).
- BLAST using desaturase and elongase nucleic acid sequences of the invention as query sequence can be performed with the BLASTn, BLASTx or the tBLASTx program using default parameters to obtain either nucleotide sequences (BLASTn, tBLASTx) or amino acid sequences (BLASTx) homologous to desaturase and elongase sequences of the invention.
- BLAST using desaturase and elongase protein sequences of the invention as query sequence can be performed with the BLASTp or the tBLASTn program using default parameters to obtain either amino acid sequences (BLASTp) or nucleic acid sequences (tBLASTn) homologous to desaturase and elongase sequences of the invention.
- Gapped BLAST using default parameters can be utilized as described in Altschul et al. (Altschul 1997, Nucleic Acids Res. 25(17):3389-3402).
- a variant of a polynucleotide encoding a desaturase or elongase as referred to herein is, preferably, a polynucleotide comprising a nucleic acid sequence selected from the group consisting of: a) a nucleic acid sequence being at least 70%, 80%, or 90% identical to the nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
- nucleic acid sequence encoding a polypeptide which is at least 70%, 80, or 90% identical to a polypeptide having an amino acid sequence as shown in SEQ ID NOs:
- nucleic acid sequence which is capable of hybridizing under stringent conditions to i) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257,
- nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258,
- the polypeptide encoded by said nucleic acid must retain the function of the respective enzyme.
- the polypeptide having a sequence as shown in SEQ ID NO: 270 has omega-3-desaturase activity. Accordingly, the variant of this polypeptide also shall have omega-3-desaturase activity.
- the function of desaturases and elongases of the present invention is analyzed in Example 22.
- a polynucleotide encoding a desaturase or elongase as referred to herein is, preferably, a polynucleotide comprising a nucleic acid sequence selected from the group consisting of:
- nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NO: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
- nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NO: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276 c) a nucleic acid sequence being at least 70%, 80%, or 90% identical to the nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
- nucleic acid sequence encoding a polypeptide which is at least 70%, 80, or 90% identical to a polypeptide having an amino acid sequence as shown in SEQ ID NOs
- nucleic acid sequence which is capable of hybridizing under stringent conditions to i) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257,
- nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258,
- LBFLFK comprises two T-DNA insertions, the insertions being designated LBFLFK Locus 1 and LBFLFK Locus 2.
- Plants comprising this insertion were generated by transformation with the T-DNA vector having a sequence as shown in SEQ ID NO: 3. Sequencing of the insertions present in the plant revealed that each locus contained a point mutation in a coding sequence resulting in a single amino acid exchange. The mutations did not affect the function of the genes.
- Locus 1 has a point mutation in the coding sequence for the delta-12 desaturase from Phythophthora sojae (d12Des(Ps)).
- the resulting polynucleotide has a sequence as shown in SEQ ID NO: 324.
- Said polynucleotide encodes a polypeptide having a sequence as shown in SEQ ID NO: 325.
- Locus 2 has a point mutation in the coding sequence for the delta-4 desaturase from Pavlova lutheri (d4Des(PI)).
- the resulting polynucleotide has a sequence as shown in SEQ ID NO: 326.
- Said polynucleotide encodes a polypeptide having a sequence as shown in SEQ ID NO: 327.
- polynucleotides are considered as variants of the polynucleotide encoding the delta-12 desaturase from Phythophthora sojae and the polynucleotide encoding the delta-4 desaturase from Pavlova lutheri.
- the polynucleotides are considered as variants and can be used in the context of the present invention.
- a polynucleotide comprising a fragment of any nucleic acid, particularly of any of the aforementioned nucleic acid sequences, is also encompassed as a polynucleotide of the present invention.
- the fragments shall encode polypeptides which still have desaturase or elongase activity as specified above.
- the polypeptide may comprise or consist of the domains of the polypeptide of the present invention conferring the said biological activity.
- variant polynucleotides or fragments referred to above preferably, encode polypeptides retaining desaturase or elongase activity to a significant extent, preferably, at least 10%, at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 80% or at least 90% of the desaturase or elongase activity exhibited by any of the polypeptide comprised in any of the T-DNAs given in the accompanying Examples (in particular of the desaturase or elongases listed in Table 1 1 and 130)
- aclytransf erases and transacylases are aclytransf erases and transacylases (cf. WO 201 1 161093 A1 ).
- One group of acyltransferases having three distinct enzymatic activities are enzymes of the "Kennedy pathway", which are located on the cytoplasmic side of the membrane system of the endoplasmic reticulum (ER).
- the ER-bound acyltransferases in the microsomal fraction use acyl-CoA as the activated form of fatty acids.
- Glycerol-3-phosphate acyltransferase GPAT catalyzes the incorporation of acyl groups at the sn-1 position of glycerol-3-phosphate.
- 1-Acylglycerol-3-phosphate acyltransferase also known as lysophosphatidic acid acyltransferase (LPAAT)
- LPAAT lysophosphatidic acid acyltransferase
- PAP phosphatidic acid phosphatase
- DGAT diacylglycerol acyltransferase
- PDAT phospholipid diacylglycerol acyltransferase
- DDAT diacylglyceroldiacylglycerol transacylase
- Lysophospholipid acyltransferase represents a class of acyltransferases that are capable of incorporating activated acyl groups from acyl-CoA to membrane lipids, and possibly also catalyze the reverse reaction. More specifically, LPLATs can have activity as lysophosphophatidylethanolamine acyltransf erase (LPEAT) and lysophosphatidylcholine acyltransferase (LPCAT). Further enzymes, such as lecithin cholesterol acyltransferase (LCAT) can be involved in the transfer of acyl groups from membrane lipids into triacylglycerides, as well.
- LCAT lecithin cholesterol acyltransferase
- WO 98/54302 and WO 98/54303 disclose a human LPAAT and its potential use for the therapy of diseases, as a diagnostic, and a method for identifying modulators of the human LPAAT.
- a variety of acyltransf erases with a wide range of enzymatic functions have been described in the documents WO 98/55632, WO 98/55631 , WO 94/13814, WO 96/24674, WO 95/27791 , WO 00/18889, WO 00/18889, WO 93/10241 , Akermoun 2000, Biochemical Society Transactions 28: 713-715, Tumaney 1999, Biochimica et Biophysica Acta 1439: 47-56, Fraser 2000, Biochemical Society Transactions 28: 715- 7718, Stymne 1984, Biochem.
- the polynucleotides shall be operably linked to expression control sequences.
- the expression control sequences are heterologous with respect to the polynucleotides operably linked thereto. It is to be understood that each polynucleotide is operably linked to an expression control sequence.
- expression control sequence refers to a nucleic acid sequence which is capable of governing, i.e. initiating and controlling, transcription of a nucleic acid sequence of interest, in the present case the nucleic sequences recited above.
- a sequence usually comprises or consists of a promoter or a combination of a promoter and enhancer sequences.
- Expression of a polynucleotide comprises transcription of the nucleic acid molecule, preferably, into a translatable mRNA. Additional regulatory elements may include transcriptional as well as translational enhancers.
- the following promoters and expression control sequences may be, preferably, used in an expression vector according to the present invention.
- the cos, tac, trp, tet, trp-tet, Ipp, lac, Ipp-lac, laclq, T7, T5, T3, gal, trc, ara, SP6, ⁇ -PR or ⁇ -PL promoters are, preferably, used in Gram-negative bacteria.
- promoters amy and SP02 may be used.
- yeast or fungal promoters ADC1 , AOX1 r, GAL1 , MFa, AC, P-60, CYC1 , GAPDH, TEF, rp28, ADH are, preferably, used.
- the promoters CMV-, SV40-, RSV-promoter Rosarcoma virus
- CMV-enhancer SV40-enhancer
- SV40-enhancer are preferably used.
- CaMV/35S Franck 1980, Cell 21 : 285-294]
- PRP1 Ward 1993, Plant. Mol. Biol. 22
- SSU SSU
- OCS OCS
- Iib4 usp
- STLS1 , B33 nos or the ubiquitin or phaseolin promoter.
- inducible promoters such as the promoters described in EP 0388186 A1 (i.e. a benzylsulfonamide-inducible promoter), Gatz 1992, Plant J.
- EP 0335528 A1 i.e. a abscisic-acid- inducible promoter
- WO 93/21334 i.e. a ethanol- or cyclohexenol-inducible promoter
- Further suitable plant promoters are the promoter of cytosolic FBPase or the ST-LSI promoter from potato (Stockhaus 1989, EMBO J. 8, 2445), the phosphoribosyl-pyrophosphate amidotransferase promoter from Glycine max (Genbank accession No. U87999) or the node-specific promoter described in EP 0249676 A1.
- promoters which enable the expression in tissues which are involved in the biosynthesis of fatty acids.
- seed-specific promoters such as the USP promoter in accordance with the practice, but also other promoters such as the LeB4, DC3, phaseolin or napin promoters.
- promoters are seed-specific promoters which can be used for monocotyledonous or dicotyledonous plants and which are described in US 5,608,152 (napin promoter from oilseed rape), WO 98/45461 (oleosin promoter from Arobidopsis, US 5,504,200 (phaseolin promoter from Phaseolus vulgaris), WO 91/13980 (Bce4 promoter from Brassica), by Baeumlein et al., Plant J., 2, 2, 1992:233-239 (LeB4 promoter from a legume), these promoters being suitable for dicots.
- promoters are suitable for monocots: lpt-2 or lpt-1 promoter from barley (WO 95/15389 and WO 95/23230), hordein promoter from barley and other promoters which are suitable and which are described in WO 99/16890.
- all natural promoters together with their regulatory sequences, such as those mentioned above, for the novel process.
- synthetic promoters either additionally or alone, especially when they mediate a seed-specific expression, such as, for example, as described in WO 99/16890.
- the polynucleotides encoding the desaturases and elongases as referred to herein are expressed in the seeds of the plants.
- seed-specific promoters are utilized to enhance the production of the desired PUFA orVLC-PUFA.
- the polynucleotides encoding the desaturares or elongases are operably linked to expression control sequences used for the the expression of the respective desaturases and elongases in the Examples section (see e.g. the promoters used for expressing the elongases and desaturases in VC-LTM593-1 qcz rc, Table 1 1 ).
- the sequence of this vector is shown in SEQ ID NO: 3.
- operatively linked means that the expression control sequence and the nucleic acid of interest are linked so that the expression of the said nucleic acid of interest can be governed by the said expression control sequence, i.e. the expression control sequence shall be functionally linked to the said nucleic acid sequence to be expressed.
- the expression control sequence and, the nucleic acid sequence to be expressed may be physically linked to each other, e.g., by inserting the expression control sequence at the 5 ' end of the nucleic acid sequence to be expressed.
- the expression control sequence and the nucleic acid to be expressed may be merely in physical proximity so that the expression control sequence is capable of governing the expression of at least one nucleic acid sequence of interest.
- the expression control sequence and the nucleic acid to be expressed are, preferably, separated by not more than 500 bp, 300 bp, 100 bp, 80 bp, 60 bp, 40 bp, 20 bp, 10 bp or 5 bp.
- Preferred polynucleotides of the present invention comprise, in addition to a promoter, a terminator sequence operatively linked to the nucleic acid sequence of interest.
- terminal refers to a nucleic acid sequence which is capable of terminating transcription. These sequences will cause dissociation of the transcription machinery from the nucleic acid sequence to be transcribed.
- the terminator shall be active in plants and, in particular, in plant seeds.
- Suitable terminators are known in the art and, preferably, include polyadenylation signals such as the SV40-poly-A site or the tk-poly-A site or one of the plant specific signals indicated in Loke et al. (Loke 2005, Plant Physiol 138, pp. 1457-1468), downstream of the nucleic acid sequence to be expressed.
- the invention furthermore relates to recombinant nucleic acid molecules comprising at least one nucleic acid sequence which codes for a polypeptide having desaturase and/or elongase activity which is modified by comparison with the nucleic acid sequence in the organism from which the sequence originates in that it is adapted to the codon usage in one or more plant species.
- the plant cell (or plant) of the present invention is an oilseed crop plant cell (or oilseed crop plant). More preferably, said oilseed crop is selected from the group consisting of flax (Linum sp.), rapeseed (Brassica sp.), soybean (Glycine and Soja sp.), sunflower (Helianthus sp.), cotton (Gossypium sp.), corn (Zea mays), olive (Olea sp.), safflower (Carthamus sp.), cocoa (Theobroma cacoa), peanut (Arachis sp.), hemp, camelina, crambe, oil palm, coconuts, groundnuts, sesame seed, castor bean, lesquerella, tallow tree, sheanuts, tungnuts, kapok fruit, poppy seed, jojoba seeds and perilla.
- Preferred plants to be used for introducing the polynucleotide or T-DNA of the invention are plants which are capable of synthesizing fatty acids, such as all dicotyledonous or monocotyledonous plants, algae or mosses. It is to be understood that host cells derived from a plant may also be used for producing a plant according to the present invention.
- Preferred plants are selected from the group of the plant families Adelotheciaceae, Anacardiaceae, Arecaceae, Asteraceae, Apiaceae, Betulaceae, Boraginaceae, Brassicaceae, Bromeliaceae, Caricaceae, Cannabaceae, Convolvulaceae, Chenopodiaceae, Compositae, Crypthecodiniaceae, Cruciferae, Cucurbitaceae, Ditrichaceae, Elaeagnaceae, Ericaceae, Euphorbiaceae, Fabaceae, Geraniaceae, Gramineae, Juglandaceae, Lauraceae, Leguminosae, Linaceae, Malvaceae, Moringaceae, Marchantiaceae, Onagraceae, Olacaceae, Oleaceae, Papaveraceae, Piperaceae, Pedaliaceae, Poaceae, Solanaceae, Prasinophy
- Examples which may be mentioned are the following plants selected from the group consisting of: Adelotheciaceae such as the genera Physcomitrella, such as the genus and species Physcomitrella patens, Anacardiaceae such as the genera Pistacia, Mangifera, Anacardium, for example the genus and species Pistacia vera [pistachio], Mangifer indica [mango] or Anacardium occidentale [cashew], Asteraceae, such as the genera Calendula, Carthamus, Centaurea, Cichorium, Cynara, Helianthus, Lactuca, Locusta, Tagetes, Valeriana, for example the genus and species Calendula officinalis [common marigold], Carthamus tinctorius [safflower], Centaurea cyanus [cornflower], Cichorium intybus [chicory], Cynara scolymus [artichoke], Helianthus annus [sunflower], Lactuca s
- Crypthecodiniaceae such as the genus Crypthecodinium, for example the genus and species Cryptecodinium cohnii
- Cucurbitaceae such as the genus Cucurbita, for example the genera and species Cucurbita maxima, Cucurbita mixta, Cucurbita pepo or Cucurbita moschata [pumpkin/squash]
- Cymbellaceae such as the genera Amphora, Cymbella, Okedenia, Phaeodactylum, Reimeria, for example the genus and species Phaeodactylum tricornutum
- Ditrichaceae such as the genera Ditrichaceae, Astomiopsis, Cer
- Elaeagnaceae such as the genus Elaeagnus, for example the genus and species Olea europaea [olive]
- Ericaceae such as the genus Kalmia, for example the genera and species Kalmia latifolia, Kalmia angustifolia, Kalmia microphylla, Kalmia polifolia, Kalmia occidentalis, Cistus chamaerhodendros or Kalmia lucida [mountain laurel]
- Euphorbiaceae such as the genera Manihot, Janipha, Jatropha, Ricinus, for example the genera and species Manihot utilissima, Janipha manihot, Jatropha manihot, Manihot aipil, Manihot dulcis, Manihot manihot, Manihot melanobasis, Manihot esculenta [manihot] or Ricinus communis [castor-oil plant],
- obtusifolia Funaria muhlenbergii, Funaria orcuttii, Funaria plano-convexa, Funaria polaris, Funaria ravenelii, Funaria rubriseta, Funaria serrata, Funaria sonorae, Funaria sublimbatus, Funaria tucsoni, Physcomitrella californica, Physcomitrella patens, Physcomitrella readeri, Physco-rnitrium australe, Physcomitrium californicum, Physcomitrium collenchymatum, Physcomitrium coloradense, Physcomitrium cupuliferum, Physcomitrium drummondii, Physcomitrium eurystomum, Physcomitrium flexifolium, Physcomitrium hookeri, Physcomitrium hookeri var.
- glabriusculum Capsicum frutescens [pepper], Capsicum annuum [paprika], Nicotiana tabacum, Nicotiana alata, Nicotiana attenuata, Nicotiana glauca, Nicotiana langsdorffii, Nicotiana obtusifolia, Nicotiana quadrivalvis, Nicotiana repanda, Nicotiana rustica, Nicotiana sylvestris [tobacco], Solanum tuberosum [potato], Solanum melongena [eggplant], Lycopersicon esculentum, Lycopersicon lycopersicum, Lycopersicon pyriforme, Solanum integrifolium or Solanum lycopersicum [tomato], Sterculiaceae, such as the genus Theobroma, for example the genus and species Theobroma cacao [cacao] or Theaceae, such as the genus Camellia, for example
- preferred plants to be used as transgenic plants in accordance with the present invention are oil fruit crops which comprise large amounts of lipid compounds, such as peanut, oilseed rape, canola, sunflower, safflower, poppy, mustard, hemp, castor-oil plant, olive, sesame, Calendula, Punica, evening primrose, mullein, thistle, wild roses, hazelnut, almond, macadamia, avocado, bay, pumpkin/squash, linseed, soybean, pistachios, borage, trees (oil palm, coconut, walnut) or crops such as maize, wheat, rye, oats, triticale, rice, barley, cotton, cassava, pepper, Tagetes, Solanaceae plants such as potato, tobacco, eggplant and tomato, Vicia species, pea, alfalfa or bushy plants (coffee, cacao, tea), Salix species, and perennial grasses and fodder crops.
- lipid compounds such as peanut, oilseed rape
- Preferred plants according to the invention are oil crop plants such as peanut, oilseed rape, canola, sunflower, safflower, poppy, mustard, hemp, castor-oil plant, olive, Calendula, Punica, evening primrose, pumpkin/squash, linseed, soybean, borage, trees (oil palm, coconut).
- oil crop plants such as peanut, oilseed rape, canola, sunflower, safflower, poppy, mustard, hemp, castor-oil plant, olive, Calendula, Punica, evening primrose, pumpkin/squash, linseed, soybean, borage, trees (oil palm, coconut).
- Very especially preferred plants are plants such as safflower, sunflower, poppy, evening primrose, walnut, linseed,
- the invention is also concerned with providing constructs for establishing high content of VLC- PUFAs in plants or parts thereof, particularly in plant oils.
- the invention provides a T-DNA for expression of a target gene in a plant, wherein the T-DNA comprises a left and a right border element and at least one expression cassette comprising a promoter, operatively linked thereto a target gene, and downstream thereof a terminator, wherein the length of the T-DNA, preferably measured from left to right border element and comprising the target gene, has a length of at least 30000 bp.
- the expression cassette is separated from the closest border of the T-DNA by a separator of at least 500 bp length.
- the expression cassette is separated from the closest border of the T-DNA by a separator of at least 100 bp in length.
- the expression cassette is separated from the closest border of the T-DNA by a separator of at least 200 bp in length.
- the invention relates to a construct comprising expression cassettes for various desaturase and elongase genes as described elsewhere herein in more detail.
- the T-DNA or construct of the present invention may comprise multiple expression cassettes encoding various, i.e. multiple proteins.
- the T- DNA or construct of the present invention may comprise a separator between the expression cassettes encoding for the desaturases or elongases referred to above.
- the expression cassettes are separated from each other by a separator of at least 100 base pairs, preferably they are separated by a separator of 100-200 base pairs. Thus, there is a separator between each expression cassette.
- a polynucleotide according to the present invention is or comprises a T-DNA according to the present invention.
- a T-DNA according to the present invention is a polynucleotide, preferably a DNA, and most preferably a double stranded DNA.
- a "T-DNA” according to the invention is a nucleic acid capable of eventual integration into the genetic material (genome) of a plant. The skilled person understands that for such integration a transformation of respective plant material is required, prefered transformation methods and plant generation methods are described herein.
- nucleic acids comprising a T-DNA or construct as defined according to the present invention.
- a T-DNA or construct of the present invention may be comprised in a circular nucleic acid, e.g. a plasmid, such that an additional nucleic acid section is present between the left and right border elements, i.e. "opposite" of the expression cassette(s) according to the present invention.
- Such circular nucleic acid may be mapped into a linear form using an arbitrary starting point, e.g.
- the additional nucleic acid section preferably comprises one or more genetic elements for replication of the total nucleic acid, i.e. the nucleic acid molecule comprising the T-DNA and the additional nucleic acid section, in one or more host microorganisms, preferably in a microorganism of genus Escherichia, preferably E. coli, and/or Agrobacterium. Preferable host microorganisms are described below in more detail.
- Such circular nucleic acids comprising a T-DNA of the present invention are particularly useful as transformation vectors; such vectors and are described below in more detail.
- the polynucleotides as referred to herein preferably are expressed in a plant after introducing them into a plant.
- the method of the present invention may also comprise the step of introducing the polynucleotides into the plant.
- the polynucleotides are introduced into the plant by transformation, in particular by Agrobacterium-mediated transformation.
- the plants are transformed with a construct or T-DNA comprising the polynucleotides and/or expression cassette as set forth in connection with the present invention such as the expression cassettes encoding for desaturase and elongase as shown in Table 1 1.
- the plant is (has been) transformed with a T-DNA or construct of the present invention.
- the construct or T-DNA used for the introduction preferably comprises all polynucleotides to be expressed.
- a single construct or T-DNA shall be used for transformation, in other words, the polynucleotides encoding for desaturases and elongases shall be comprised by the same T-DNA. It is to be understood, however, that more than one copy of the T-DNA may be comrprised by the plant.
- the T-DNA length is preferably large, i.e. it has a minimum length of at least 30000 bp, preferably more than 30000 bp, more preferably at least 40000 bp, even more preferably at least 50000 bp and most preferably at least 60000 bp.
- the length of the T-DNA is in a range of any of the aforementioned minimum lengths to 120000bp, more preferably in a range of any of the aforementioned minimum lengths to 100000bp, even more preferably in a range of any of the aforementioned minimum lengths to 90000 bp, even more preferably in a range of any of the aforementioned minimum lengths to 80000 bp.
- minimum lengths it is possible to introduce a number of genes in the form of expression cassettes such that each individual gene is operably liked to at least one promoter and at least one terminator.
- the invention makes use of such minimum length T-DNA for introducing the genes required for the metabolic pathway of VLC-PUFA production in plants, e.g. oil seed plants, preferably plants of genus Brassica.
- the length of the T-DNA is preferably limited as described before to allow for easy handling.
- the construct of the present invention may have a minimum length of at least 30000 bp, preferably more than 30000 bp, more preferably at least 40000 bp, even more preferably at least 50000 bp and most preferably at least 60000 bp.
- a separator is present setting the respective border element apart from the expression cassette comprising the target gene.
- the separator in 3' direction of the T-DNA left border element does not necessarily have the same length and/or sequence as the separator in 5' direction of the T-DNA right border element, as long as both separators suffice to the further requirements given below.
- the expression cassettes are separated from each other by a separator of at least 100 base pairs, preferably by a separator of 100 to 200 base pairs. Thus, there is a separator between the expression cassettes.
- the separator or spacer is a section of DNA predominantly defined by its length. Its function is to separate a target gene from the T-DNA's left or right border, respectively. As will be shown in the examples, introducing a separator effectively separates the gene of interest from major influences exerted by the neighbouring genomic locations after insertion of the T-DNA into a genomic DNA. For example it is commonly believed that not all genomic loci are equally suitable for expression of a target gene, and that the same gene under the control of the same promoter and terminator may be expressed in different inensity in plants depending on the region of integration of the target gene (and its corresponding promoter and terminator) in the plant genome.
- the mechanism of achieving the above mentioned benefits by the T-DNA of the present invention is not easily understood, so it is convenient to think of the spacer as a means for physically providing a buffer to compensate for strain exerted by DNA winding by neighbouring histones or chromosomal backbone or other scaffold attached regions. As a model it can be thought that to transcribe a target gene, the DNA has to be partially unwound.
- neighbouring regions of the target gene resist such unwinding, for example because they are tightly wound around histones or otherwise attached to a scaffold or backbone such that rotation of nucleic acid strands is limited, the spacer allows to distribute the strain created by the unwinding attempt over a longer stretch of nucleic acid, thereby reducing the force required for unwinding at the target gene.
- the separator has a length of at least 500 bp.
- the separator thus, can be longer than 500 bp, and preferably is at least 800 bp in length, more preferably at least 1000 bp. Longer spacers allow for even more physical separation between the target gene and the nearest genomic flanking region.
- the spacer has a length of at least 100 bp. Preferably, the spacer has a length of 100 to 200 base pairs.
- the separator preferably has a sequence devoid of matrix or scaffold attachment signals.
- the separator or spacer is does not comprise more than once for a length of 500 bp, preferably not more than once for a length of 1000 bp, a 5-tuple which occurs in the spacers described below in the examples for 20 or more times, summarized over all spacers given in the examples.
- Those tuples are, in increasing frequency in the spacers given in the examples: AGCCT, CGTAA, CTAAC, CTAGG, GTGAC, TAGGC, TAGGT, AAAAA, AACGC, TTAGC, ACGCT, GCTGA, ACGTT, AGGCT, CGTAG, CTACG, GACGT, GCTTA, AGCTT, CGCTA, TGACG, ACGTG, AGCTG, CACGT, CGTGA, CGTTA, AGCGT, TCACG, CAGCT, CGTCA, CTAGC, GCGTC, TTACG, GTAGC, TAGCG, TCAGC, TAGCT, AGCTA, GCTAG, ACGTA, TACGT.
- a further increase in expression of a target gene in the T-DNA can be achieved.
- the separator may contain a selectable marker.
- a selectable marker is a nucleic acid section whose presence preferably can be verified in seed without having to wait for the sprouting or full growth of the plant.
- the selectable marker conveys a phenotypical property to seed or to a growing plant, for example herbicide tolerance, coloration, seed surface properties (e.g. wrinkling), luminescence or fluorescence proteins, for example green fluorecent protein or luciferase. If for exhibiting the phenotypical feature an expression of a marker gene is required, then the separator correspondingly comprises the marker gene as selectable marker, preferably in the form of an expression cassette.
- the separator comprises an expression cassette for expression of an herbicide tolerance gene. Such separator greatly reduces the chance of having to cultivate a transformant where silencing effects are so strong that even the expression of the selectable marker gene is greatly reduced or fully inhibited.
- the separator preferably does not comprise a desaturase or elongase gene, and also preferably does not comprise a promoter or operatively linked to a desaturase or elongase gene.
- the T-DNA of the present invention in preferred embodiments is useful for effective separation of the desaturase and elongase genes essential for the production of VLC-PUFAs from any influence of effects caused by neighbouring genomic plant DNA.
- Another method of isolating T-DNAs from major influences exerted by the neighbouring genomic locations in is maximize the distance of the T-DNA insert from neighboring genes.
- disruption of neighboring genes could result in unexpected effects on the host plant.
- It is possible to determine the genomic insertion site of a T-DNA with various methods known to those skilled in the art, such as adapter ligation-mediated PCR as described in O'Malley et al. 2007 Nature Protocols 2(1 1 ):2910-2917.
- Such methods allow for the selection of transgenic plants where the T-DNA has been inserted at a desired distance away from endogenous genes. It is preferable to identify transgenic events where the T-DNA is more than 1000 bp away from a neighboring coding sequence.
- the T-DNA is 2500 bp away, and most preferably the T-DNA is 5000 or more bp away from the nearest coding sequence.
- the T-DNA or T-DNAs comprised by the plant of the present invention thus, does not (do not) disrupt an endogenous coding sequence.
- the T-DNA is (the T-DNAs are) more than 1000 bp away from a neighboring coding sequence. More prefereable, the T-DNA is (the T-DNAs are) 2500 bp away, and most preferably the T-DNA is (the T-DNAs are) 5000 or more bp away from the nearest coding sequence.
- the invention also provides a T-DNA or construct comprising the coding sequences of any single gene (in particular of the coding sequences for the desaturases and elongases) of the tables given in the examples, preferably comprising the coding sequences and and promoters of any single of the tables given in the examples, more preferably the coding sequences and promoters and terminators of any single of the tables given in the examples, and most preferably the expression cassettes of any single of the tables of the examples.
- the invention also provides a construct or a T-DNA comprising the coding sequences (in particular of the desaturases and elogases) as given in Table 1 1 and 130 in the examples, preferably comprising the coding sequences (in particular of the desaturases and elogases) and and promoters as given in Table 1 1 in the examples, more preferably the coding sequences (in particular of the desaturases and elogases) and promoters and terminators as given in Table 1 1 in the examples, and most preferably the expression cassettes for the desaturases and elongases as referred to in the context of the method of present invention as present in VC-LTM593-1 qcz rc (see Examples section, SEQ ID NO: 3).
- the invention provides a T-DNA for production of VLC-PUFAs in a plant, wherein the T-DNA comprises a left and a right border element and in between one or more expression cassette(s), wherein the length of the T-DNA, measured from left to right border element and comprising the one or more expression cassettes, has a length of at least 30000 bp.
- the expression cassette(s) closest to a left or right border element, respectively is (are) separated from said closest border element of the T-DNA by a separator of at least 500 bp length.
- the one or more expression cassette(s) each comprise a promoter, operatively linked to a target gene, and downstream thereof a terminator, wherein the target gene of a respective expression cassette is a desaturase or elongase gene as required for production of a VLC-PUFA.
- the target genes codes/code for a desaturase or elongase as given in any of the tables in the examples section, and further preferably at least one and most preferably all expression cassettes consist of a combination of promoter, desaturase/elongase gene and terminator as given in any of the examples below.
- a plant of the invention comprises one or more T-DNA of the present invention comprising one or more expression cassettes encoding for one or more d6Des (delta 6 desaturase), one or more d6Elo (delta 6 elongase), one or more d5Des (delta 5 desaturase), one or more o3Des (omega 3 desaturase), one or more d5Elo (delta 5 elongase) and one or more D4Des (delta 4 desaturase), preferably for at least one CoA-dependent D4Des and one Phospholipid-dependent d4Des.
- the T-DNA encodes also for one or more d12Des (delta 12 desaturase).
- the desaturases and elongases are derived from the organisms disclosed above.
- a plant of the invention thus comprises one or more T-DNA of the present invention comprising at least one polynucleotide encoding a delta-6-desaturase (preferably a CoA-dependent delta-6-desaturase), at least two polynucleotides encoding a delta-6-elongase, at least two polynucleotides encoding a delta-5- desaturase, at least one polynucleotide encoding a delta-12-desaturase, at least three polynucleotides encoding an omega-3-desaturase, and at least one polynucleotide encoding a delta-5-elongase, and at least two polynucleotides encoding a delta-4-desaturase
- Preferred polynucleotide sequences encoding for the desaturases and elongases referred to above are disclosed elsewherein herein (see also SEQ ID Nos in Table 130).
- the desaturases and elongases are from the organisms disclosed above.
- a plant of the invention thus comprises one or more T-DNA of the present invention comprising at least one polynucleotide encoding a delta-6-desaturase, at least two polynucleotides encoding a delta-6-elongase, at least two polynucleotides encoding a delta-5-desaturase, at least one polynucleotide encoding a delta-12-desaturase, at least three polynucleotides encoding an omega-3-desaturase, and at least one polynucleotide encoding a delta-5-elongase, and at least two polynucleotides encoding a delta-4-desaturase (preferably for at least one CoA-dependent D4Des and one Phospholipid-dependent d4Des).
- a plant of the invention comprises one or more T-DNA of the present invention comprising one expression cassette for a delta-6 elongase from Physcomitrella patens, one expression cassette for a delta-6 elongase from Thalassiosira pseudonana, two expression cassettes for a delta-5 desaturase from Thraustochytrium sp. (in particular from Thraustochytrium sp.
- a plant of the invention comprises one or more T-DNA, wherein the T-DNA comprises the expression cassettes for the desaturases and elongases of VC-LTM593-1 qcz (see e.g. Table 1 1 ).
- the plant of the present invention comprises one or more T-DNA of the present invention, wherein the T-DNA has the sequence of the T-DNA of the vector VC-LTM593-1 qcz. The position of the T-DNA in the vector is indicated in Table 1 1 .
- the vector has a sequence shown in SEQ ID NO: 3.
- the T-DNA, construct, or plant of the present invention comprises polynucleotides encoding for the following desaturases and elongases, in particular in the following order: Delta-6 ELONGASE from Physcomitrella patens; Delta-5 DESATURASE from Thraustochytrium (in particular from Thraustochytrium sp.
- T- DNA, construct, or plant of the present invention comprises two copies of a Delta-5 desaturase from Thraustochytrium and two copies of Delta-5 desaturase from Thraustochytrium. Also encompassed are variants thereof.
- the T-DNA preferably shall have a length of at least 30000 bp.
- the plant of the invention or a part thereof as described herein comprises one or more T-DNAs of the invention which encode for at least two d6Des, at least two d6Elo and/or, at least two o3Des.
- the present plant of the invention or a part thereof comprise a T-DNA comprising one or more expression cassettes encoding for at least one CoA- dependent d4Des and at least one phopho-lipid dependent d4Des.
- the activities of the enzymes expressed by the one or more T-DNAs in the plant of the invention or a part thereof are encoded and expressed polpeptides having the activities shown in column 1 of Table 19.
- the plant of the invention comprises at least one T-DNA as shown in columns 1 to 9 in Table 13.
- one T-DNA of the present invention comprises one or more gene expression cassettes encoding for the activities or enzymes listed in Table 13.
- the at least one T-DNA further comprises an expression cassette which encodes for at least one d12Des.
- the T-DNA or T-DNAs comprise one or more expression cassettes encoding one or more d5Des(Tc_GA), o3Des(Pir_GA), d6Elo(Tp_GA) and/or d6Elo(Pp_GA).
- Such plants of the present invention have shown particularly high amounts and concentrations of VLC-PUFAs over three or more generations and under different growth conditions.
- the T-DNA of the invention encodes for the activites of column 1 as disclosed in Table 19, preferably of gene combinations disclosed in Table 13, even more preferred for promoter-gene combinations as described in Table 13.
- the contribution from each desaturase and elongase gene present in the T-DNA to the amount of VLC-PUFA is difficult to assess, but it is possible to calculate conversion efficiencies for each pathway step, for example by using the equations shown in Figure 2. The calculations are based on fatty acid composition of the tissue or oil in question and indicate the amount of product fatty acid (and downstream products) formed from the subatrate of a particular enzyme.
- conversion efficiency values can be used to assess contribution of each desaturase or elongase reaction to the overall production of VLC-PUFA. By comparing conversion efficiencies, one can compare the relative effectiveness of a given enzymatic step between different individual seeds, plants, bulk seed batches, events, Brassica germplasm, or transgenic constructs.
- the plant is a Brassica napus plant.
- the plant comprises at least one T-DNA of the invention (and thus one or more T-DNAs).
- the T-DNA shall have a length of at least at least 10.000 base pairs, in particular of at least 30.000 bp.
- the T-DNA comprised by the invention shall comprise expression cassettes for desaturases and elongases.
- the T-DNA comprises one or more expression cassettes for a delta-5 desaturase (preferably one), one or more expression cassettes for a omega-3 desaturase (preferably three), one or more expression cassettes for a delta 12 desaturase (preferably one), one or more expression cassettes for a delta 4 desaturase (preferably one CoA-dependent d4des and one phospholipid dependent d4des), one or more expression cassettes for a delta-5 elongase (preferably one), one or more expression cassettes for a delta-6 desaturase (preferably one), and one or more expression cassettes for a delta-6 elongase (preferably two).
- the T-DNA comprises two expression cassettes for a delta- 5 desaturase from Thraustochytrium sp., two expression cassettes for an omega-3-desaturase from Phythophthora infestans, one expression cassette for an omega-3-desaturase from Pythium irregulare, one expression cassette for a delta-12 desaturase from Phythophthora sojae, one expression cassette for a Delta-4 desaturase from Pavlova lutheri, one expression cassette for a Delta-4 desaturase from Thraustochytrium sp., one expression cassette for a Delta-6 desaturase from Ostreococcus tauri, one expression cassette for a Delta-6 elongase from Physcomitrella patens, and one expression cassette for a Delta-6 elongase from Thalassiosira pseudonana.
- the SEQ ID Nos are given in Table 130. Further, it is envisaged that expression cassettes for variants of
- the plant has one or more of the following features:
- a delta 6 desaturase conversion efficiency in a single seed of greater than about 40% A delta 6 elongase conversion efficiency in bulk seed of greater than about 75%, or greater than about 82%, or greater than about 89%,
- T-DNA insert or inserts do not disrupt an endogenous coding sequence (as described elsewhere herein),
- the distance between any inserted T-DNA sequence and the nearest endogenous gene is about 1000, or about 2000, or about 5000 base pairs,
- the T-DNA insert or inserts do not cause rearrangements or any DNA surrounding the insertion location
- the T-DNA insert or inserts occur exclusively in the C genome of Brassica,
- each expression cassette comprising a gene coding for a delta-12- desaturase, delta-6-desaturase or omega-3-desaturase is separated from the respective closest left or right border element by a separator and optionally one or more expression cassettes.
- T-DNA of the present invention comprises more than one expression cassette comprising a gene of the same function, these genes do not need to be identical concerning their nucleic acid sequence or the polypeptide sequence encoded thereby, but should be functional homologs.
- a T-DNA according to the present invention may comprise, in addition to optionally a multiplicity of genes coding for delta-6-desaturases and/or omega-3-desaturases, two, three, four or more expression cassettes each comprising a gene coding for a delta-12- desaturase, wherein the delta-12-desaturase polypeptides coded by the respective genes differ in their amino acid sequence.
- a T-DNA of the present invention may comprise, in addition to optionally a multiplicity of genes coding for delta-12-desaturases and/or omega-3- desaturases, two, three, four or more expression cassettes each comprising a gene coding for a delta-6-desaturase, wherein the delta-6-desaturase polypeptides coded by the respective genes differ in their amino acid sequence, or a T-DNA of the present invention may comprise, in addition to optionally a multiplicity of genes coding for delta-12-desaturases and/or delta-6-desaturases, two, three, four or more expression cassettes each comprising a gene coding for a omega-3- desaturase, wherein the omega-3-desaturase polypeptides coded by the respective genes differ in their amino acid sequence.
- the T-DNA, construct or plant may also comprise, instead of one or more of the aforementioned coding sequences, a functional homolog thereof.
- a functional homolog of a coding sequence is a sequence coding for a polypeptide having the same metabolic function as the replaced coding sequence.
- a functional homolog of a delta-5- desaturase would be another delta-5-desaturase
- a functional homolog of a delta-5-elongase would be another delta-5-elongase.
- the functional homolog of a coding sequence preferably codes for a polypeptide having at least 40% sequence identity to the polypeptide coded for by the corresponding coding sequence given in the corresponding table of the examples, more preferably at least 41 %, more preferably at least 46%, more preferably at least 48%, more preferably at least 56%, more preferably at least 58%, more preferably at least 59%, more preferably at least 62%, more preferably at least 66%, more preferably at least 69%, more preferably at least 73%, more preferably at least 75%, more preferably at least 77%, more preferably at least 81 %, more preferably at least 84%, more preferably at least 87%, more preferably at least 90%, more preferably at least 92%, more preferably at least 95%, more preferably at least 96%, more preferably at least 97%, more preferably at least 98% and even more preferably at least 99%.
- a functional homolog of a promoter is a sequence for starting transcription of a coding sequence located within 500 bp for a proximal promoter or, for a distal promoter, within 3000 bp distant from the promoter TATA box closest to the coding sequence.
- a functional homolog of a plant seed specific promoter is another plant seed specific promoter.
- the functional homolog of a terminator correspondingly, is a sequence for ending transcription of a nucleic acid sequence.
- T-DNA or construct of the present invention preferably comprises two or more genes, preferably all genes, susceptible to a gene dosage effect.
- T-DNA When introducing T-DNA into plant cells, generally transformation methods involving exposition of plant cells to microorganisms are employed, e.g. as described herein. As each microorganism may comprise more than one nucleic acid comprising a T-DNA of the present invention, recombinant plant cells are frequently obtained comprising two or more T-DNAs of the present invention independently integrated into the cell's genetic material.
- the invention accordingly also provides a construct comprising a T-DNA according to the present invention, wherein the construct preferably is a vector for transformation of a plant cell by microorganism-mediated transformation, preferably by Agrobacterium-mediated transformation.
- the invention also provides a transforming microorganism comprising one T- DNA according to the present invention, preferably as a construct comprising said T-DNA.
- the microorganism is of genus Agrobacterium, preferably a disarmed strain thereof, and preferably of species Agrobacterium tumefaciens or, even more preferably, of species Agrobacterium rhizogenes.
- vector preferably, encompasses phage, plasmid, viral vectors as well as artificial chromosomes, such as bacterial or yeast artificial chromosomes. Moreover, the term also relates to targeting constructs which allow for random or site-directed integration of the targeting construct into genomic DNA. Such target constructs, preferably, comprise DNA of sufficient length for either homologous or heterologous recombination as described in detail below.
- the vector encompassing the polynucleotide of the present invention preferably, further comprises selectable markers for propagation and/or selection in a host. The vector may be incorporated into a host cell by various techniques well known in the art. If introduced into a host cell, the vector may reside in the cytoplasm or may be incorporated into the genome.
- the vector may further comprise nucleic acid sequences which allow for homologous recombination or heterologous insertion.
- Vectors can be introduced into prokaryotic or eukaryotic cells via conventional transformation or transfection techniques.
- transformation and “transfection”, conjugation and transduction, as used in the present context, are intended to comprise a multiplicity of prior-art processes for introducing foreign nucleic acid (for example DNA) into a host cell, including calcium phosphate, rubidium chloride or calcium chloride co-precipitation, DEAE-dextran-mediated transfection, lipofection, natural competence, carbon-based clusters, chemically mediated transfer, electroporation or particle bombardment.
- plasmid vector may be introduced by heat shock or electroporation techniques. Should the vector be a virus, it may be packaged in vitro using an appropriate packaging cell line prior to application to host cells.
- the vector referred to herein is suitable as a cloning vector, i.e. replicable in microbial systems.
- a cloning vector i.e. replicable in microbial systems.
- Such vectors ensure efficient cloning in bacteria and, preferably, yeasts or fungi and make possible the stable transformation of plants.
- Those which must be mentioned are, in particular, various binary and co-integrated vector systems which are suitable for the T DNA- mediated transformation.
- Such vector systems are, as a rule, characterized in that they contain at least the vir genes, which are required for the Agrobacterium-mediated transformation, and the sequences which delimit the T-DNA (T-DNA border).
- vector systems preferably, also comprise further cis-regulatory regions such as promoters and terminators and/or selection markers with which suitable transformed host cells or organisms can be identified.
- co- integrated vector systems have vir genes and T-DNA sequences arranged on the same vector
- binary systems are based on at least two vectors, one of which bears vir genes, but no T-DNA, while a second one bears T-DNA, but no vir gene.
- the last-mentioned vectors are relatively small, easy to manipulate and can be replicated both in E. coli and in Agrobacterium.
- binary vectors include vectors from the pBIB-HYG, pPZP, pBecks, pGreen series.
- Bin19, pB1101 , pBinAR, pGPTV and pCAMBIA are Bin19, pB1101 , pBinAR, pGPTV and pCAMBIA.
- An overview of binary vectors and their use can be found in Hellens et al, Trends in Plant Science (2000) 5, 446-451 .
- the polynucleotides can be introduced into host cells or organisms such as plants or animals and, thus, be used in the transformation of plants, such as those which are published, and cited, in: Plant Molecular Biology and Biotechnology (CRC Press, Boca Raton, Florida), chapter 6/7, pp. 71-1 19 (1993); F.F. White, Vectors for Gene Transfer in Higher Plants; in: Transgenic Plants, vol.
- the vector of the present invention is an expression vector.
- an expression vector i.e. a vector which comprises the polynucleotide of the invention having the nucleic acid sequence operatively linked to an expression control sequence (also called "expression cassette") allowing expression in prokaryotic plant cells or isolated fractions thereof.
- the invention also provides a plant or seed thereof, comprising, integrated in its genome, a T-DNA or a construct of the present invention.
- the construct or T-DNA shall be stably integrated into the genome of the plant or plant cell.
- the plant is homozygous for the T-DNA.
- the plant is hemizygous for the T-DNA. If the plant is homozygous for one T-DNA at one locus, this is nevertheless considered as a single copy herein, i.e. as one copy. Double copy, as used herein, refers to a plant in which two T-DNAs have been inserted, at one or two loci, and in the hemizygous or homozygous state.
- Stability of the T-DNA can be assessed by determining the presence of the T-DNA in two or more subsequent generations of a transgenic event. Determining the presence of a T-DNA can be achieved by Southern blot analysis, PCR, DNA sequencing, or other methods that are suitable for the detection of specific DNA sequences. Stability of the T-DNA should also include copy number measurements for transgenic events that contain more than one copy of the T-DNA. In this case, instability of a single copy of the T-DNA may not be detectable by selecting for the trait, i.e. VLC-PUFA conent, because the presence of one stable T-DNA copy may mask the instability of the other.
- T-DNAs of at least 30000 bp in length, and with multiple copies of certain sequences (for example two copies of the same promoter) it is especially important to confirm presence and copy number at multiple locations within the T-DNA.
- the borders of a long T-DNA have an increased likelihood of being in linkage equilibrium, and duplicated sequences increase the possibility of homologous recombination.
- T-DNA at least 30000 bp
- Such T-DNA or construct preferably allows for the expression of all genes required for production of VLC-PUFAs in plants and particularly in the seeds thereof, particularly in oilseed plants, and most beneficially in plants or seeds of family Brassicaceae, preferably of genus Brassica and most preferably of a species comprising a genome of one or two members of the species Brassica oleracea, Brassica nigra and Brassica rapa, thus preferably of the species Brassica napus, Brassica carinata, Brassica juncea, Brassica oleracea, Brassica nigra or Brassica rapa.
- Particularly preferred according to the invention are plants and seeds of the species Brassica napus and Brassica carinata.
- the plants of the present invention are necessarily transgenic, i.e. they comprise genetic material not present in corresponding wild type plant or arranged differently in corresponding wild type plant, for example differing in the number of genetic elements.
- the plants of the present invention comprise promoters also found in wild type plants, but the plants of the present invention comprise such promoter operatively linked to a coding sequence such that this combination of promoter and coding sequence is not found in the corresponding wild type plant.
- the polynucleotide encoding for the desaturases or elongases shall be recombinant polynucleotides.
- T-DNAs of the present invention allow for the generation of transformant plants (also called “recombinant plants") and seeds thereof with a high transformation frequency, with a high stability of T-DNA insertions over multiple generations of self-fertilized plants, unchanged or unimpaired phenotypical and agronomic characteristics other than VLC-PUFA production, and with high amounts and concentration of VLC-PUFAs, particularly EPA and/or DHA, in the oil of populations of such transformed plants and their corresponding progeny.
- VLC-PUFA amounts per seed are high even for identical clones cultivated side by side under identical greenhouse conditions. Also, it has now been found and is reported below in the examples that the contentration of VLC-PUFAs is negatively correlated with seed oil content in Brassica napus. The mere statement of VLC- PUFA concentration in %(w/w) of all fatty acids of a plant oil is not indicative of the VLC-PUFA amount achievable by agricultural (i.e. large scale) growing of corresponding clones.VLC-PUFA amounts or concentrations depends on which genes, promoters, gene-promoter combinations, gene-gene combinations etc. are beneficial for VLC-PUFA synthesis in oilseed plants.
- seed groupings based on the seeds used to generate that group are: (i) “individual seed” or “single seed” refers to one seed from one plant, (ii) seed derived from a “individual plant” refers to all seeds grown on a single plant without effort to select based on seed-to-seed variability, (iii) “batches of seed” or “seedbatches” refers to all of the seeds collected from a specific number of plants without selection based on plant-to-plant or seed-to-seed variability.
- the specific number of plants referred to in a batch can be any number, one or greater, where it is understood that a batch of one plant is equivalent to individual plant, (iv) "bulked seed” refers to all of the seed gathered from a large number of plants (equal to or greater than 100) without effort to select seeds based on plant-to-plant or seed-to-seed variability.
- VLC-PUFA amounts or concentrations can indeed be increased by increasing the number of expression cassettes of functionally identical genes.
- prior art documents purport to comprise applicable technical teachings, e.g. to combine desaturases having a particular property, e.g. CoA- dependence, it is not known how to reduce such alleged technical teachings to practice, particularly as such documents only teach requirements (i.e. functional claim features) but not solutions for these requirements (i.e. structural features).
- such prior art documents frequently comprise only one example of a single gene and leave the reader with the instruction to start a research program to find other enzymes satisfying the functional definition given therein, provided that any other enzyme exists that satisfies those functional requirements.
- a plant of the present invention comprising a T-DNA or construct of the present invention can also be a plant comprising a part of a T-DNA or construct of the present invention, where such part is sufficient for the production of a desaturase and/or elongase coded for in the corresponding full T-DNA or construct of the present invention.
- Such plants most preferably comprise at least one full T-DNA or construct of the present invention in addition to the part of a T-DNA of the present invention as defined in the previous sentence.
- Such plants are hereinafter also termed "partial double copy" plants.
- Event LBFDAU is an example of a plant comprising a part of a T-DNA of the present invention, and still being a plant of the present invention.
- the T_DNA is a full T-DNA.
- Preferred plants of the present invention comprise one or more T-DNA(s) or construct of the present invention comprising expression cassettes comprising, one or more genes encoding for one or more d5Des, one or more d6Elo, one or more d6Des, one or more o3Des, one or more d5Elo and one or more D4Des, preferably for at least one CoA-dependent D4Des and one Phospholipid-dependent d4Des.
- at least one T-DNA further comprises an expression cassette which encodes for at least one d12Des.
- the T-DNA or T- DNAs further comprise one or more expression cassettes encoding one or more d5Des(Tc_GA), o3Des(Pir_GA), d6Elo(Tp_GA) and/or d6Elo(Pp_GA), an explanation for the abbreviation in the brackets is given e.g. in Table 130, e.g. d6Elo(Tp_GA) is a Delta-6 elongase from Thaiassiosira pseudonana, d6Elo(Pp_GA) i a Delta-6 elongase from Physcomitrella patens.
- Such plants of the present invention have shown particularly high amounts and concentrations of VLC-PUFAs over three or more generations and under different growth conditions.
- Preferred plants according to the invention are oilseed crop plants.
- the plant of the present invention preferably is a "Canola" plant.
- Canola is a genetic variation of rapeseed developed by Canadian plant breeders specifically for its oil and meal attributes, particularly its low level of saturated fat.
- Canola herein generally refers to plants of Brassica species that have less than 2% erucic acid (Delta 13-22:1 ) by weight in seed oil and less than 30 micromoles of glucosinolates per gram of oil free meal.
- canola oil may include saturated fatty acids known as palmitic acid and stearic acid, a monounsaturated fatty acid known as oleic acid, and polyunsaturated fatty acids known as linoleic acid and linolenic acid.
- Canola oil may contain less than about 7%(w/w) total saturated fatty acids (mostly palmitic acid and stearic acid) and greater than 40%(w/w) oleic acid (as percentages of total fatty acids).
- canola crops include varieties of Brassica napus and Brassica rapa.
- Preferred plants of the present invention are spring canola (Brassica napus subsp. oleifera var. annua) and winter canola (Brassica napus subsp. oleifera var. biennis).
- a canola quality Brassica juncea variety which has oil and meal qualities similar to other canola types, has been added to the canola crop family (U.S. Pat. No.
- the invention also provides a plant or seed thereof of family Brassicaceae, preferably of genus Brassica, with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from progeny lines prepared by a method comprising the steps of i) crossing a plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant comprising a T-DNA or construct of the present invention and/or part of such T-DNA, with a parent plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant not comprising said T- DNA and/or part thereof, to yield a F1 hybrid,
- step (iii) identifying the progeny of step (ii) comprising the T-DNA of the present invention capable of producing seed comprising VLC-PUFA.
- the progeny are capable of producing seed comprising an oil as described elsewhere herein (in particular, see the definition for the oil of the present invention). More preferably, the progeny shall be capable of producing seed comprising VLC-PUFA such that the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 12% (w/w) and/or the content of DHA is at least 2% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w).
- the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 5%, in particular at least 8% (w/w) and/or the content of DHA is at least 1 % (w/w), in particular 1 .5% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w).
- This method allows to effectively incorporate genetic material of other members of family Brassicaceae, preferably of genus Brassica, into the genome of a plant comprising a T-DNA or construct of the present invention.
- the method is particularly useful for combining a T-DNA or construct of the present invention with genetic material responsible for beneficial traits exhibited in other members of family Brassicaceae.
- beneficial traits of other members of family Brassicaceae are exemplarily described herein, other beneficial traits or genes and/or regulatory elements involved in the manifestation of a beneficial trait may be described elsewhere.
- the parent plant not comprising the T-DNA or contruct of the present invention or part thereof preferably is an agronomically elite parent.
- the present invention teaches to transfer heterologous material from a plant or seed of the present invention to a different genomic background, for example a different variety or species.
- the invention teaches to transfer the T-DNA or part thereof (the latter is particularly relevant for those plants of the present invention which comprise, in addition to a full T-DNA of the present invention, also a part of a T-DNA of the present invention, said part preferably comprising at least one expression cassette, the expression cassette preferably comprising a gene coding for a desaturase or elongase, preferably a delta-12-desaturase, delta-6-desaturase and/or omega-3-desaturase), or construct into a species of genus Brassica carinata, or to introduce genetic material from Brassica carinata or Brassica nigra into the plants of the present invention comprising the T-DNA of the present invention and/or a part or two or more parts thereof.
- genes of Brassica nigra replacing their homolog found in Brassica napus or added in addition to the homolog found in Brassica napus are particularly helpful in further increasing the amount of VLC-PUFAs in plant seeds and oils thereof.
- the invention teaches novel plant varieties comprising the T-DNA and/or part thereof of the present invention.
- Such varieties can, by selecting appropriate mating partners, be particularly adapted e.g. to selected climatic growth conditions, herbicide tolerance, stress resistance, fungal resistance, herbivore resistance, increased or reduced oil content or other beneficial features.
- the invention provides a method for creating a plant with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from progeny lines prepared by a method comprising the steps of
- transgenic plant of the invention with a parent plant not comprising a T-DNA of the present invention or part thereof, said parent plant being of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, to yield a F1 hybrid,
- step (iii) identifying the progeny of step (ii) comprising the T-DNA of the present invention capable of producing seed comprising VLC-PUFA.
- the progeny are capable of producing seed comprising an oil as described elsewhere herein (in particular the oil of the present invention). More preferably, the progeny shall be capable of producing seed comprising VLC-PUFA such that the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 8% (w/w) and/or the content of DHA is at least 1 % (w/w) of the total seed fatty acid content at an oil content of 30% (w/w), preferably at an oil content of 35% (w/w), and more preferably at an oil content of 40% (w/w).
- the method allows the creation of novel variants and transgenic species of plants of the present invention, and the seeds thereof. Such plants and seeds exhibit the aforementioned benefits of the present invention.
- the content of EPA is at least 5%, more preferably at least 8%, even more preferably at least 10% by weight, most preferably at least 13% (w/w), of the total lipid content of the oil.
- the content of DHA is at least 1.0% by weight, more preferably at least 1.5%, even more preferably at least 2% (w/w), of the total lipid content of the oil.
- the present invention for the first time allows to achieve such high levels of VLC-PUFA in seed reliably under agronomic conditions, i.e.
- a plant of the present invention also includes plants obtainable or obtained by backcrossing (cross into the non-transgenic, isogenic parent line), and by crossing with other germplasms of the Triangle of U. Accordingly, the invention provides a method for creating a plant with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from a progeny line prepared by a method comprising the steps of
- transgenic plant of the invention also called “non-recurring parent”
- parent plant not expressing a gene comprised in the T-DNA of the present invention
- said parent plant being of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, to yield a hybrid progeny,
- step ii) crossing the hybrid progeny again with the parent to obtain another hybrid progeny, iii) optionally repeating step ii) and
- Backcrossing methods can be used with the present invention to improve or introduce a characteristic into the plant line comprising the T-DNA of the present invention.
- Such hybrid progeny is selected in step iv) which suffices predetermined parameters.
- the backcrossing method of the present invention thereby beneficially facilitates a modification of the genetic material of the recurrent parent with the desired gene, or preferably the T-DNA of the present invention, from the non-recurrent parent, while retaining essentially all of the rest of the desired genetic material of the recurrent parent, and therefore the desired physiological and morphological, constitution of the parent line.
- the selected hybrid progeny is then preferably multiplied and constitutes a line as described herein.
- step ii) Selection of useful progeny for repetition of step ii) can be further facilitated by the use of genomic markers.
- progeny is selected for the repetition of step ii) which comprises, compared to other progeny obtained in the previous crossing step, most markers also found in the parent and/or least markers also found in the non-recurring parent except the desired T-DNA of the present invention or part thereof.
- a hybrid progeny which comprises the T-DNA of the present invention, and even more preferably also comprises at least one further expression cassette from the nonrecurring parent of the present invention, e.g. by incorporation of an additional part of the T-DNA of the present invention into the hybrid plant genetic material.
- a hybrid progeny is obtained wherein essentially all of the desired morphological and physiological characteristics of the parent are recovered in the converted plant, in addition to genetic material from the non-recurrent parent as determined at the 5% significance level when grown under the same environmental conditions.
- a hybrid progeny is selected which produces seed comprising an oil as described elsewhere herein (i.e. an oil of the present invention).
- a hybrid progeny is selected which produces seed comprising VLC-PUFA such that the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 8% (w/w) and/or the content of DHA is at least 1 % (w/w) of the total seed fatty acid content at an oil content of 30% (w/w), preferably at an oil content of 35% (w/w), and more preferably at an oil content of 40% (w/w).
- seed VLC-PUFA content is to be measured not from a single seed or from the seeds of an individual plant, but refer to the numeric average of seed VLC-PUFA content of at least 100 plants, even more preferably of at least 200 plants, even more preferably of at least 200 plants half of which have been grown in field trials in different years, in particular ofbulked seed VLC-PUFA content of at least 100 plants, even more preferably of at least 200 plants, even more preferably of at least 200 plants half of which have been grown in field trials in different years.
- the choice of the particular non-recurrent parent will depend on the purpose of the backcross. One of the major purposes is to add some commercially desirable, agronomically important trait to the line.
- a “line” refers to a group of plants that displays very little overall variation among individuals sharing that designation.
- a “line” generally refers to a group of plants that display little or no genetic variation between individuals for at least one trait.
- a “DH (doubled haploid) line,” as used in this application refers to a group of plants generated by culturing a haploid tissue and then doubling the chromosome content without accompanying cell division, to yield a plant with the diploid number of chromosomes where each chromosome pair is comprised of two duplicated chromosomes. Therefore, a DH line normally displays little or no genetic variation between individuals for traits. Lines comprising one or more genes originally comprised in a T-DNA of the present invention in the non-recurring parent also constitute plants of the present invention.
- the invention is also concerned with a method of plant oil production, comprising the steps of i) growing a plant of the present invention such as to obtain oil-containing seeds thereof, ii) harvesting said seeds, and
- the oil is an oil as described herein below in more detail (i.e. an oil of the present invention). More preferably, the oil has a DHA content of at least 1 % by weight based on the total lipid content and/or a EPA content of at least 8% by weight based on the total lipid content. Also preferably, the oil has a DHA content of at least 1 % by weight based on the total fatty acid content and/or a EPA content of at least 8% by weight based on the total fatty acid content.
- the plant of the present invention comprises, for the purposes of such method of plant oil production, preferably comprises a T-DNA (or construct) of the present invention and optionally also one or more additional parts thereof, wherein the part or parts, respectively, comprise at least one expression cassette of the T-DNA of the present invention.
- the invention is also concerned with parts of plants of the present invention.
- the term "parts of plants” includes anything derived from a plant of the invention, including plant parts such as cells, tissues, roots, stems, leaves, non-living harvest material, silage, seeds, seed meals and pollen.
- plant part comprises a T-DNA of the present invention and/or comprises a content of EPA of at least 8% by weight, more preferably at least 10%, even more preferably at least 13% (w/w), of the total lipid content.
- the content of DHA is at least 1 .0% by weight, more preferably at least 1.5%, even more preferably at least 2% (w/w), of the total lipid content of the plant part.
- Parts of plants of the present invention comprising, compared to wild-type plants, elevated content of EPA and/or DHA, or the oil or lipid of the present invention are particularly useful also for feed purposes, e.g. for aquaculture feed, e.g. as described in AU201 1289381A and members of the patent family thereof.
- the plants of the present invention do not necessarily have to comprise a complete T-DNA of the present invention.
- crossing or back-crossing
- crossing or back-crossing it is possible to transfer one or more, even all, expression cassettes comprised in a plant of the present invention (such plant comprising a T-DNA of the present invention) to another plant line, thereby losing e.g. a left or right border element (or both) and/or a spacer.
- the invention also provides plants comprising genetic material hybridizing to a primer as given in Example 24.
- each flanking region may differ from the below indicated flanking regions by at most 10% calculated over a consecutive stretch of at least 100nt, preferably by at most 5% calculated over a consecutive stretch of at least - with increasing percentage identity more preferred - 90. 91. 92, 93, 94, 95, 96, 97, 98 or 99, preferred 100% identity for 100 nt. Even more preferably, the flanking region(s) comprise at least - with increasing percentage identity more preferred - 90. 91.
- Example 24 provides an overview of all the flanking sequences of all loci obtained for each event listed in that table.
- event specific primers and probes are disclosed in Table 176 for event specific detection. The method for using those primers and probes is described in example 24.
- insertions in these flanking regions have now been proven to lead to a surprisingly high production of VLC-PUFAs in seed, wherein such production is stable over many generations and under different growth conditions.
- insertion of other genetic material at these insertion locations also leads to a stable, high expression of inserted genes compared to insertions at other positions of the plant genome.
- the invention is also concerned with establishing and optimizing efficient metabolic VLC-PUFA synthesis pathways.
- the invention provides a method for analysing desaturase reaction specificity, comprising the steps of
- the labelled molecule preferably is a fatty acid-coenzyme A or a fatty acid-phospholipid, the latter preferably being a lysophosphatidylcholine bound fatty acid.
- the method advantageously allows to determining desaturase headgroup preference or even headgroup specificity by detecting whether coenzyme A bound fatty acids are desaturated and/or whether phospholipid-bound fatty acids are desaturated.
- the desaturase is provided as a microsomal fraction of an organism, preferably of yeast. Transgenic yeasts expressing the desaturase in question are easy to prepare and handle, and microsomal fractions comprising functional desaturases can be reliably and reproducibly prepared thereof without major burden.
- Microsomal fractions particularly of yeast, most preferably of Saccharomyces cerevisiae, also allow to convert fatty acid-coenzyme A molecules to fatty acids bound to other headgroups by using the yeast's native LPCAT.
- microsomal fractions can be prepared from other cells and organisms.
- the molecule is detectably labelled by including a radioactive isotope instead of a nonradioactive isotope.
- the isotope preferably is [14C].
- Such label is easy to detect, does not interefere in biochemical reactions and can be incorporated in virtually any carbon-containing molecule, thereby allowing sensitively detecting and characterizing any desaturation product.
- the fatty acid moiety preferably is a PUFA moiety, more preferably a VLC-PUFA moiety and most preferably a VLC-PUFA moiety.
- the desaturase is allowed to react on the labelled molecule. If the desaturase can accept the labelled molecule as a substrate, then the desaturation reaction is performed. Preferably, the method is repeated by including, as a positive control, a labelled molecule which had been confirmed to be a substrate for the desaturase.
- Detection preferably is accomplished using chromatography, most preferably thin layer chromatography. This technique is well known to the skilled person, readily available, very sensitive and allows differentiating even between very similar molecules. Thus, even if the positive control molecule is similar to the molecule of interest, a clear detection of desaturation products (if desaturation of the molecule occurred) is still possible.
- the above method allows preparing a collection of specificity data for each desaturase, type of microsomal fraction (e.g. from yeast, plant cells etc.), fatty acid moiety and headgroup.
- the method can be used to select a desaturase for a given need, e.g. to accept CoA-bound fatty acids in plant cells for further presentation to an elongase.
- the method also allows establishing substrate specificty of the desaturase in an organism or organ of interest, e.g. a yeast, a plant leaf cell or a plant seed cell.
- the invention also provides a method for analysing elongase reaction specificity, comprising the steps of
- the method for analysing elongase reaction specificity is performed corresponding to the method for analysing desaturase reaction specificity for corresponding reasons.
- the elongation substrate preferably is malonyl-CoA.
- the elongation substrate is preferably labelled radioactively, most preferably [14C] malonyl-CoA. Radioactive labelling allows for an easy and sensitive detection of elongation products. Also, labelling of the elongation substrate instead of the molecule to be elongated allows presenting a mixture of molecules to be elongated to the elongase, and only the elongation products will have incorporated significant amounts of label to render them easily detectable.
- the invention thus also provides a method for pathway optimization, comprising the steps of
- the method particularly allows providing desaturases and elongases to form a pathway. This is useful to determine the yield of product(s) of the pathway and of any unwanted side products. Also, by providing two or more different enzymes which perform the same metabolic function, e.g. a particular desaturation step, e.g. a delta-5 desaturation, it is possible to analyse if the presence of more than one type of enzymes has an effect on product formation, particularly on product formation rate. For such analysis, one would compare the results with a method performed with only one of the at least two enzymes. Thus, if addition of enzymes performing the same metabolic function leads to an increased yield or product formation rate, then this metabolic step is subject to a gene dosage effect.
- a particular desaturation step e.g. a delta-5 desaturation
- the method advantageously allows determining the mode of action of an enzyme in question.
- a helper enzyme is provided to produce a substrate for a target enzyme.
- the helper enzyme's mode of action is known.
- the helper enzyme is then provided with a substrate to turn into a product which could be used as a substrate of the target enzyme.
- Generation of product by the target enzyme is determined, preferably by measuring the amount of product per time or the final amount of product divided by the amount of substrate converted by the helper enzyme.
- the method is repeated using a helper enzyme of a different mode of action, and generation of product by the target enzyme is determined, too.
- the mode of action of the target enzyme is defined as being the mode of action of the helper enzyme giving rise to the most intense generation of product by the target enzyme.
- a helper elongase is provided for which it has been text book knowledge that it is utilizing acyl CoA substrate and produces acyl-CoA products. Then, product generation by the target desaturase is measured. In another step, a helper desaturase is provided for which it has been established that it produces phosphatidylcholine-bound fatty acids. Again, product generation by the target desaturase is measured.
- the target desaturase can be defined as being a CoA-dependent desaturase if the product generation of the target desaturase under conditions where CoA-bound fatty acids are provided by the helper enzyme is more intense (e.g. higher conversion efficiency) than under conditions where phosphatidylcholine-bound fatty acids are provided by the helper enzyme.
- the invention also provides a method for determining CoA-dependence of a target desaturase, comprising the steps of
- step ii) providing a non-CoA dependent desaturase to produce the substrate for the target desaturase, and determining conversion efficiency of the target desaturase, and iii) comparing the target desaturase conversion efficiencies of step i) and ii).
- step i) If the conversion efficiency of the target desaturase is larger in step i) than in step ii), then the target desaturase is CoA-dependent. Of course, both steps must be performed under comparable conditions; particularly a substrate limitation of the target desaturase must be avoided.
- the method can also be performed by providing an elongase which uses the substrate of the target desaturase.
- the invention provides a method for determining CoA-dependence of a target desaturase, comprising the steps of
- the target desaturase is CoA-dependence.
- the desaturation product does not have to be converted into an elongatable CoA-bound fatty acid, thus desaturated product can be immediately utilized by the elongase without accumulation.
- both steps must be performed under comparable conditions; particularly a substrate limitation of the elongase must be avoided.
- the present invention also relates to oil comprising a polyunsaturated fatty acid obtainable by the aforementioned methods.
- the present invention also relates to a lipid or fatty acid composition comprising a polyunsaturated fatty acid obtainable by the aforementioned methods.
- oil refers to a fatty acid mixture comprising unsaturated and/or saturated fatty acids which are esterified to triglycerides.
- the triglycerides in the oil of the invention comprise PUFA or VLC-PUFA moieties as referred to above.
- the amount of esterified PUFA and/or VLC- PUFA is, preferably, approximately 30%, a content of 50% is more preferred, a content of 60%, 70%, 80% or more is even more preferred.
- the oil may further comprise free fatty acids, preferably, the PUFA and VLC-PUFA referred to above.
- the fatty acid content can be, e.g., determined by GC analysis after converting the fatty acids into the methyl esters by transesterification.
- the content of the various fatty acids in the oil or fat can vary, in particular depending on the source.
- the oil shall have a non-naturally occurring composition with respect to the PUFA and/or VLC-PUFA composition and content. It is known that most of the fatty acids in plant oil are esterified in triacylglycerides. Accordingly, in the oil of the invention, the PUFAs and VLC-PUFAs are, preferably, also occur in esterified form in the triacylglcerides.
- the oil of the invention may comprise other molecular species as well. Specifically, it may comprise minor impurities (and thus minor amounts) of the polynucleotide or vector of the invention, which however, can be detected only by highly sensitive techniques such as PCR.
- these oils, lipids or fatty acids compositions preferably, comprise 4 to 15% of palmitic acid (in an embodiment 6 to 15% of palmitic acid), 1 to 6% of stearic acid, 7-85% of oleic acid, 0.5 to 8% of vaccenic acid, 0.1 to 1 % of arachidic acid, 7 to 25% of saturated fatty acids, 8 to 85% of monounsaturated fatty acids and 60 to 85% of polyunsaturated fatty acids, in each case based on 100% and on the total fatty acid content of the organisms (preferably by weight).
- Preferred VLC-PUFAs present in the fatty acid esters or fatty acid mixtures is, preferably, at least 5,5% to 20% of DHA and/or 9,5% to 30% EPA based on the total fatty acid content (preferably by weight).
- the oils, lipids or fatty acids according to the invention preferably, comprise at least 1 %, 1.5%, 2%, 3%, 4%, 5.5%, 6%, 7% or 7,5%, more preferably, at least 8%, 9%, 10%, 1 1 % or 12%, and most preferably at least 13%, 14%, 15%, 16%. 17%, 18%, 19% or 20% of DHA (preferably by weight), or at least 5%, 8%, 9.5%, 10%, 1 1 % or 12%, more preferably, at least 13%, 14%, 14,5%, 15% or 16%, and most preferably at least 17 % , 18 % , 19 % , 20 % .
- EPA preferably by weight
- a plant especially of an oil crop such as soybean, oilseed rape, coconut, oil palm, safflower, flax, hemp, castor-oil plant, Calendula, peanut, cacao bean, sunflower or the abovementioned other monocotyledonous or dicotyledonous oil crops.
- an oil crop such as soybean, oilseed rape, coconut, oil palm, safflower, flax, hemp, castor-oil plant, Calendula, peanut, cacao bean, sunflower or the abovementioned other monocotyledonous or dicotyledonous oil crops.
- the oils, lipids or fatty acids according to the invention preferably, comprise at least 1 % of DHA, and/or at least 8% of EPA based on the total fatty acid content of the production host cell, organism, advantageously of a plant, especially of an oil crop such as soybean, oilseed rape, coconut, oil palm, safflower, flax, hemp, castor-oil plant, Calendula, peanut, cacao bean, sunflower or the abovementioned other monocotyledonous or dicotyledonous oil crops.
- an oil crop such as soybean, oilseed rape, coconut, oil palm, safflower, flax, hemp, castor-oil plant, Calendula, peanut, cacao bean, sunflower or the abovementioned other monocotyledonous or dicotyledonous oil crops.
- the oil, lipid or fatty acid composition of the present invention is a plant oil, plant lipid, or plant fatty acid composition.
- said oil or lipid is extracted, obtained, obtainable or produced from a plant, more preferably from seeds of a plant or plants (in particular a plant or plants of the present invention).
- the oil or lipid thus can be obtained by the methods of the present invention.
- the plant oil or plant lipid is an extracted plant oil or lipid.
- said oil or lipid is extracted, obtained, obtainable or produced from a plant, more preferably from batches of seeds or bulked seeds of a plant or plants (in particular a plant or plants of the present invention).
- the term “extracted” in connection with an oil or lipid refers to an oil or lipid that has been extracted from a plant, in particular from seeds of a plant or plants. More preferably, the term “extracted” in connection with an oil or lipid refers to an oil or lipid that has been extracted from a plant, in particular from batch of seeds or bulked seeds of a plant or plants.
- Such oil or lipid can be a crude composition. However, it may be also a purified oil or lipid in which e.g. the water has been removed. In an embodiment, the oil or lipid is not blended with fatty acids from other sources.
- the oil or lipid of the present invention may be also an oil or lipid in a seed of plant.
- said plant is a transgenic plant. More preferably, said plant is a plant of the present invention. In a particular preferred embodiment, the plant is a Brassica plant.
- the oil or lipid of the present invention shall comprise fatty acids.
- the oil or lipid shall comprise fatty acids in esterified form.
- the fatty acids shall be esterified.
- the oil or lipid of the present comprises one or more of following fatty acids (in esterified form): Oleic acid (OA), Linoleic acid (LA), gamma-Linolenic acid (GLA), alpha-Linolenic acid (ALA), Stearidonic acid (SDA), 20:2n-9 ((Z,Z)-8,1 1 -Eicosadienoic acid), Mead acid (20:3n-9), Dihomo-gamma- linolenic acid (DHGLA), Eicosapentaenoic acid (Timnodonic acid, EPA, 20:5n-3), Clupanodonic acid (DPA n-3), and DHA ((Z,Z,Z,Z,Z,Z)-4,7,10,13,16,19-Do
- the oil or lipid comprises EPA, DHA and Mead acid. Even more preferably, the oil or lipid comprises EPA, DHA, Mead acid, DPA n-3, and DHGLA. Most preferably, the oil or lipid comprises fatty acids mentioned in this paragraph.
- the oil or lipid of the present invention comprises both EPA and DHA. Preferred contents of EPA and DHA are given elsewhere herein. Further, it is envisaged that the oil or lipid comprises EPA, DHA, and DPA n-3. In an embodiment, the oil or lipid further comprises Mead Acid.
- the oil or lipid comprises EPA, DHA, and DHGLA.
- the oil or lipid further comprises Mead Acid.
- oil or lipid may comprise EPA, DHA, DPA n-3, and DHGLA.
- oil or lipid further comprises Mead Acid.
- the expression cassettes, the construct or the T-DNA of the present invention can be used for modulating, in particular increasing, the content of one or more of the aforementioned fatty acids in plants, in seeds and/or in seed oil of a plant as compared to a control plant.
- the preferred content of aforementioned fatty acids in the total fatty acid content of the lipid or oil of the present invention is further described in the following.
- ranges are given for the contents.
- the contents (levels) of fatty acids are expressed as percentage (weight of a particular fatty acid) of the (total weight of all fatty acids), in particular of the (total weight of all fatty acids present in the oil or lipid).
- the contents are thus, preferably given as weight percentage (% (w/w)) of total fatty acids present in the oil or lipid. Accordingly, "%” preferably means “% (w/w) for a fatty acid (or combination of fatty acids) compared to the total weight of fatty acids”.
- the fatty acids are present in esterified form.
- the fatty acids shall be esterified fatty acids.
- the oil or lipid comprises Oleic acid (OA).
- the content of Oleic acid (OA) is between 10% and 45%, more preferably between 20% and 38%, most preferably between 26% and 32% of the total fatty acid content.
- the oil or lipid comprises Linoleic acid (LA).
- LA Linoleic acid
- the content of Linoleic acid (LA) is between 5% and 40%, more preferably between 10% and 40%, most preferably between 20% and 35% of the total fatty acid content.
- the oil or lipid comprises gamma-Linolenic acid (GLA).
- GLA gamma-Linolenic acid
- the content of gamma-Linolenic acid (GLA) is between 0.1 % and 6%, more preferably between 0.1 % and 3%, most preferably between 0.5% and 2% of the total fatty acid content.
- the oil or lipid comprises alpha-linolenic acid (ALA).
- the content of alpha- Linolenic acid (ALA) is between 2% and 20%, more preferably between 4% and 10%, most preferably between 4% and 7% of the total fatty acid content.
- the oil or lipid comprises Stearidonic acid (SDA).
- the content of Stearidonic acid (SDA) is between 0.1 % and 10%, more preferably between 0.1 % and 5%, most preferably between 0.1 % and 1 % of the total fatty acid content.
- the content of SDA was surprisingly low.
- the content of SDA is lower than 2%, in particular lower than 1 %.
- the oil or lipid comprises 20:2n-9.
- the content of 20:2n-9 ((Z,Z)-8,1 1 - Eicosadienoic acid) is between 0.1 % and 3%, more preferably between 0.1 % and 2%, most preferably between 0.1 % and 1 % of the total fatty acid content.
- the oil or lipid comprises Mead acid (20:3n-9).
- the content of Mead acid (20:3n-9) is between 0.1 % and 2%, more preferably between 0.1 % and 1 %, most preferably between 0.1 % and 0.5% of the total fatty acid content.
- the content of Mead acid (20:3n-9) is between 0.1 % and 0.3% of the total fatty acid content
- the oil or lipid comprises Dihomo-gamma-linolenic acid (DHGLA).
- DHGLA Dihomo-gamma-linolenic acid
- the content of Dihomo-gamma-linolenic acid (DHGLA) is between 0.1 % and 10%, more preferably between 1 % and 6%, most preferably between 1 % and 5%, in particular between 2 and 4% of the total fatty acid content. The accumulation of this internmediate was not necessarily expected.
- the oil or lipid comprises EPA (20:5n-3).
- the content of Eicosapentaenoic acid is between 0.1 % and 20%, more preferably between 2% and 15%, most preferably between 5% and 10% of the total fatty acid content.
- the content of EPA is between 5% and 15% of the total fatty acid content
- the oil or lipid comprises Clupanodonic acid (DPA n-3).
- the content of Clupanodonic acid (DPA n-3) is between 0.1 % and 10%, more preferably between 1 % and 6%, most preferably between 2% and 4% of the total fatty acid content.
- the content of DPA n-3 may be at least 2% of the total fatty acids.
- the oil or lipid comprises DHA.
- the content of DHA is between 1 % and 10%, more preferably between 1 % and 4%, most preferably between 1 % and 2% of the total fatty acid content. Further, it is envisaged that the content of DHA is between 1 % and 3% of the total fatty acid content
- the oil or lipid of the invention has a content of DHA between 1 % and 4% and a content of EPA between 2% and 15% of the total fatty acid content. In another preferred embodiment, the oil or lipid of the invention has a content of DHA between 1 % and 3% and a content of EPA between 5% and 15% of the total fatty acid content.
- the oil or lipid of the invention has a content of DHA between 1 % and 2% and a content of EPA between 5% and 10% of the total fatty acid content.
- the oil or lipid of the present invention may also comprise saturated fatty acids such as 16:0 (Palmitic acid) and/or 18:0 (Stearic acid).
- the contents of 16:0 and 18:0 are advantageoulsly low as compared to wild-type plants. Low saturated fat is a desireable feature from the health perspective.
- the oil or lipid may comprise 16:0.
- the content of 16:0 is less than 6% of the total fatty acid content. More preferably, the content of 16:0 is between 3% and 6% of the total fatty acid content
- the oil or lipid may comprise 18:0.
- the content of 18:0 is less than 4%, in particular less than 3% of the total fatty acid content. More preferably, the content of 18:0 is between 1 .5% and 4%, in particular between 2% and 3% of the total fatty acid content.
- the total content of EPA, DHA and DPA n-3 is preferably more than 6% and the content of SDA is lower than 2% of all fatty acids present in the oil or lipids. More preferably the content of EPA, DHA, and DPA n-3 is between 7% and 14% and the content of SDA is lower than 1 % of all fatty acids present in the oil or lipids.
- the content of DPA n-3 is preferably at least 2% of the total fatty acid content, and the total content of EPA and DHA is at least 3% of the total fatty acid content. More preferably the content of DPA n-3 is between 2% and 5%, and the total content of EPA and DHA is between 6% and 12% of all fatty acids present in the oil or lipids.
- the content of 16:0 is preferably lower than 6% of the total fatty acid content, and the total content of EPA and DHA is at least 3% of the total fatty acid content. More preferably the content of 16:0 is between 2% and 6%, and the total content of EPA and DHA is between 6% and 12% of all fatty acids present in the oil or lipids.
- the content of 16:0 is preferably lower than 5% of the total fatty acid content, and the total content of EPA, DHA, DPA n-3 is at least 6% of the total fatty acid content. More preferably content of 16:0 is between 2% and 5% and the total content of EPA, DHA, and DPA is between 8% and 14% of all fatty acids present in the oil or lipids.
- the content of EPA of the total fatty acids in the seeds, in particular in the seed oil was larger than the content of DHA. This is not always the case; see for examples US2015/0299676A1 and WO 2015/089587.
- the oil and lipid of the present invention comprises more EPA than DHA.
- the content of EPA shall be larger than the content of DHA.
- the content of EPA of the total fatty acid acid content is 3 to 7-fold the content of DHA of the total fatty acid content. More preferably, the content of EPA of the total fatty acid acid content is 4 to 5-fold the content of DHA of the total fatty acid content.
- the total content of all omega-3 polyunsaturated [n-3 (C18-C22)] fatty acids is between 1 % and 40%, more preferably between 10% and 30%, most preferably between 15% and 22% of the total fatty acid content.
- the total content of all omega-6 polyunsaturated [n-6 (C18-C22)] fatty acids is between 0.1 % and 50%, more preferably between 20% and 50%, most preferably between 37% and 42% of the total fatty acid content.
- the oil or lipid of the present invention may comprise fatty acids that are non-naturally occurring in wild type control Brassica napus lipid or oil, preferably greater than 10%, more preferably between 12% and 25.2%, and most preferably between 16% and 25.0% of the total fatty acid content.
- non naturally occurding fatty acids are 18:2n-9, GLA, SDA, 20:2n-9, 20:3n- 9, 20:3 n-6, 20:4n-6, 22:2n-6, 22:5n-6, 22:4n-3, 22:5n-3, and 22:6n-3.
- the total content of these fatty acids in the oil or lipid of the present invention is preferably greater than 10%, more preferably between 12% and 25.2%, and most preferably between 16% and 25.0% of the total fatty acid content
- Example 32 it is shown that certain TAG (triacylglyceride) species were decreased and certain TAG species were increased in the seeds of the plants of the present invention (in particular in seed oil extracted from plants of the present invention).
- the five most abundant TAG (triacylglyceride) species in wild-type Kumilly plants were TAG (18:1 18:1 18:3), TAG (18:1 18:2 18:3), TAG (18:1 18:1 18:2), TAG (18:1 18:1 18:1 ), and (TAG 18:1 18:2 18:2). Together, these account for 64.5% of all TAG species (in oil of wild-type plants). These species are specifically reduced in plants of the present invention (see Example 32, Table 192).
- the two most abundant DHA containing TAG species in the transgenic canola samples were TAG (18:1 18:2 22:6) and TAG (18:2 18:2 22:6).
- TAG 18:1 18:2 22:6
- the EPA and DHA are found most frequently esterified to TAG together with 18:1 and 18:2.
- This makeup is likely to be more oxidatively stable that TAG species containing multiple PUFAs (see Wijesundra 2008, Lipid Technology 20(9): 199-202).
- the oil or lipid of the present invention thus may comprise certain TAG species.
- the oil or lipid comprises one or more of the following TAG species: TAG (18:1 18:2 20:5), TAG (18:1 18:1 20:5), TAG (18:2 18:2 20:5), TAG (18:1 18:2 22:6) and TAG (18:2 18:2 22:6). More preferably, the oil of lipid of the present invention comprises all of the aforementioned TAG species. Alternatively or additionally, the oil or lipid of the present invention may comprise TAG (18:1 18:1 22:6).
- the triacylglyceride nomenclature used herein is well known in the art and well understood by the skilled person.
- the triacylglyceride TAG (x 1 :y 1 x 2 :y 2 x 3 :y 3 ) is preferably denoted to mean that the triacylglyceride comprises three fatty acid ester residues, wherein one fatty acid ester residue is x 1 :y 1 which means that this residue comprises x 1 carbon atoms and y 1 double bonds, wherein one fatty acid ester residue is x 2 :y 2 which means that this residue comprises x 2 carbon atoms and y 2 double bonds, and wherein one fatty acid ester residue is x 3 :y 3 which means that this residue comprises x 3 carbon atoms and y 3 double bonds.
- any of these fatty acid ester residues may be attached to any former hydroxyl groups of the glycerol.
- the preferred content of aforementioned TAG species of the total TAG content of the lipid or oil of the present invention is further described in the following.
- the contents (levels) of TAGs are expressed as percentage (weight of a particular TAG, or a combinations of TAGs) of the total weight of total TAGs (i.e. all TAGs) present in the oil or lipid).
- the contents are thus, preferably, given as weight percentage (% (w/w)).
- "%” preferably means "% (w/w) for a TAG (or combination of TAGs) compared to the total weight of TAGs".
- the oil or lipid comprises TAG (18:1 18:2 20:5).
- the content of TAG (18:1 18:2 20:5) is between 0.1 % and 20%, more preferably between 5% and 15%, most preferably between 7% and 12% of the total TAG content.
- the oil or lipid preferably comprises TAG (18:1 18:1 20:5).
- the content of TAG (18:1 18:1 20:5) is between 1.5% and 15%, more preferably between 2% and 10%, most preferably between 4% and 7.6% of the total TAG content.
- the oil or lipid preferably comprises TAG (18:2 18:2 20:5).
- the content of TAG (18:2 18:2 20:5) is between 3% and 20%, more preferably between 3% and 15%, most preferably between 3.5% and 9% of the total TAG content.
- the sum of the contents of TAG (18:1 18:2 20:5), TAG (18:1 18:1 20:5), and TAG (18:2 18:2 20:5), i.e. the combined contents of these three TAG species, is between 5% and 55%, more preferably between 10% and 45%, most preferably between 20% and 26% of the total TAG content.
- TAG species those that contain esterified EPA.
- EPA is better than DHA for some health reasons.
- the oil or lipid preferably comprises TAG (18:1 18:2 22:6).
- the content of TAG (18:1 18:2 22:6) is between 0.1 % and 15%, more preferably between 0.1 % and 10%, most preferably between 0.5% and 3% of the total TAG content.
- the oil or lipid preferably comprises TAG (18:2 18:2 22:6).
- the content of TAG (18:2 18:2 22:6) is between 0.1 % and 15%, more preferably between 0.1 % and 10%, most preferably between 0.5% and 2% of the total TAG content.
- the oil or lipid preferably comprises TAG (18:1 18:1 22:6).
- the content of TAG (18:1 18:1 22:6) is between 0.1 % and 15%, more preferably between 0.1 % and 10%, most preferably between 0.3% and 1 % of the total TAG content.
- the sum of the contents of TAG (18:1 18:2 22:6), TAG (18:2 18:2 22:6) and TAG (18:1 18:1 22:6), i.e. the combined content of these three TAG species, is between 0.3% and 45%, more preferably between 1 % and 30%, most preferably between 1 % and 5% of the total TAG content.
- the oil or lipid of the present invention may also comprise TAG (18:3 18:3 20:5) and/or TAG (18:3 18:3 22:6). As can be seen from the examples, a low abundance of these TAG species was observed (see table 192). The low abundance can have an oxidative stability benefit.
- the content of TAG (18:3 18:3 20:5) is between 0.1 % and 2%, more preferably between 0.1 % and 1 %, most preferably between 0.1 % and 0.5% of the total TAG content.
- the content of TAG (18:3 18:3 22:6) is between 0.03% and 2%, more preferably between 0.03% and 1 %, most preferably between 0.03% and 0.5% of the total TAG content. Further, it is contemplated that the content of TAG (18:3 18:3 22:6) is between 0.03% and 0.2% of the total TAG content.
- TAG (18:1 18:1 18:3) the most abundant TAG species in wild-type Kumily plants were TAG (18:1 18:1 18:3), TAG (18:1 18:2 18:3), TAG (18:1 18:1 18:2), TAG (18:1 18:1 18:1 ), and (TAG 18:1 18:2 18:2).
- TAG (18:1 18:1 18:3) the most abundant TAG species in wild-type Kumily plants were TAG (18:1 18:1 18:3), TAG (18:1 18:2 18:3), TAG (18:1 18:1 18:2), TAG (18:1 18:1 18:1 ), and (TAG 18:1 18:2 18:2).
- TAG (18:1 18:1 18:3 the most abundant TAG species in wild-type Kumily plants were TAG (18:1 18:1 18:3), TAG (18:1 18:2 18:3), TAG (18:1 18:1 18:2), TAG (18:1 18:1 18:1
- the oil or lipid of the present invention may further one or more of the following features:
- the oil or lipid preferably comprises TAG (18:1 18:1 18:3).
- the content of TAG (18:1 18:1 18:3) is between 0% and 10%, more preferably between 0% and 5%, most preferably between 0% and 3% of the total TAG content.
- the content of TAG (18:1 18:1 18:3) of the total TAG content may be lower than 3%, in particular lower than 1 %.
- the oil or lipid preferably comprises TAG (18:1 18:2 18:3).
- the content of TAG (18:1 18:2 18:3) is between 3% and 19%, more preferably between 4% and 18%, most preferably between 4% and 7% of the total TAG content.
- the content of TAG (18:1 18:2 18:3) of the total TAG content may be lower than 7%.
- the oil or lipid preferably comprises TAG (18:1 18:1 18:2).
- the content of TAG (18:1 18:1 18:2) is between 1 % and 10%, more preferably between 2% and 10%, most preferably between 2% and 5% of the total TAG content.
- the content of TAG (18:1 18:1 18:2) of the total TAG content may be lower than 5%.
- the oil or lipid preferably comprises TAG (18:1 18:1 18:1 ).
- the content of TAG (18:1 18:1 18:1 ) is between 0.1 % and 8%, more preferably between 0.5% and 5%, most preferably between 1 % and 3% of the total TAG content.
- the content of TAG (18:1 18:1 18: 1 ) of the total TAG content may be lower than 3%.
- the oil or lipid preferably comprises TAG (18:1 18:2 18:2).
- the content of TAG (18:1 18:2 18:2) is between 0.1 % and 13%, more preferably between 3% and 1 1 %, most preferably between 4% and 10% of the total TAG content.
- the content of TAG (18:1 18:2 18:2) of the total TAG content may be lower than 10%.
- the total content and thus sum of the contents of TAG (18:1 18:1 18:3), TAG (18:1 18:2 18:3), TAG (18:1 18:1 18:2), and TAG (18:1 18:1 18:1 ), TAG (18:1 18:2 18:2) is between 5% and 50%, more preferably between 10% and 30%, most preferably between 14% and 22% of the total TAG content.
- the total content of the aforementioned TAG species of the total TAG content is lower that 21 .2% of the total TAG content.
- EPA and DHA are found most frequently esterified to TAG together with 18:1 and/or 18:2. These combinations of fatty acids are advantageous because they are more oxidatively stable than TAG species with more than one PUFA.
- less that 21 % of the total TAG species comprised by the oil or lipid contain more than one EPA, DPA, and DHA n-3 residue.
- the oil or lipid of the present invention comprises TAGs (triacylglycerides), DAGs (diacylglycerides), and DAGs (diacylglycerides).
- TAG triacylglyceride
- MAG and DAG species were decreased and certain MAG and DAG species were increased in the seeds of the plants of the present invention (in particular in seed oil of plants of the present invention).
- the examples show that there is more esterified EPA and DHA in DAG than in MAG.
- the content of esterified EPA and DHA in DAG is larger than the content of esterified EPA and DHA in MAG (with respect to the total esterfied fatty acid content in MAG).
- the ratio of the content of esterified EPA and DHA in DAG (with respect to the total esterfied fatty acid content in DAG) to the content of esterified EPA and DHA in MAG (with respect to the total esterfied fatty acid content in MAG) is about 1.5.
- Examples show that DHA is accumulated in the phosphatidylcholine (PC) fraction. This is thought to be achieved by expression of both a phospholipid and CoA dependent d4Des. It could be advantageous because DHA in phospholipids is thought to be more readily digestible.
- PC phosphatidylcholine
- the content of DHA in in the phosphatidylcholine (PC) fraction in the oil or lipid of the present invention is between 2 and 12%, more preferably, between 2 and 10, most preferably between 5 and 9% of to the total fatty acid content of the PC fraction (preferably % w/w). Morever, it is envisaged that the ratio of the content DHA in the PC fraction to the content in the TAG fraction of the oil or lipid of the present invention is larger than 1 .
- the studies underlying the present invention showed that the ratio of DHA to DPA n-3 is higher in the PC and PE (phosphatidylethanolamine) fraction than in the neutral lipid fraction (MAG, DAG, and TAG), see Example 30.
- PC and PE phosphatidylethanolamine
- the ratio of the content of DHA of all fatty acids in the PC and PE fraction to the content of DPA n-3 of all fatty acids in the PC and PE fraction is larger than the ratio of the content of DHA of all fatty acids in the MAG, DAG, and/or TAG fraction to the content of DPA n-3 of all fatty acids in the MAG, DAG, and/or TAG fraction.
- the amount of DHA in the phospholipid fraction in the oil or lipid of the present is larger that the amount of EPA in the phospholipid fraction.
- the amount of EPA in the TAG fraction in the oil or lipid of the present shall be larger that the amount of DHA in the TAG fraction.
- “Amount” is this paragraph preferably means absolute amount.
- Example 31 shows that the abundant PC (phosphatidylcholine) species containing EPA or DHA are PC (18:2, 22:6) and PC (18:2 20:5). This majority of PUFA are combined with 18:2 which is more stable than if they are combined with 18:3 or another PUFA.
- PC phosphatidylcholine
- the oil or lipid of the present invention preferably comprises PC (18:2, 22:6), PC (18:2 20:5), or both.
- Preferred contents of the species in the oil or lipid of the present invention are given below.
- the contents (levels) of the species are expressed as percentage (weight of a particular PC species) of the total weight of total PCs (i.e. all PCs) present in the oil or lipid).
- the contents are thus, preferably, given as weight percentage (% (w/w)).
- "%” preferably means "% (w/w) for a PC (or combination of PCs) compared to the total weight of PCs".
- the content of PC (18:2 20:5) is between 2.5% and 15%, more preferably between 2.5% and 12%, most preferably between 3% and 10% of the total phosphatidylcholine content. Also preferably the content of this species is at least 3%.
- the content of PC (18:2, 22:6) is between 0.5% and 10%, more preferably between 1 % and 7 %, most preferably between 1 % and 6% of the total phosphatidylcholine content. Also preferably, the content of this species is at least 1 .4%.
- the present invention also relates to a plant comprising seeds comprising an oil of the present invention. Furthermore, the present invention relates to a seed comprising the oil of the present invention. Preferred plant species are described herein above.
- the plant and the seed(s) comprises one ore more polynucleotides, expression cassettes, T-DNAs and/or construct as set forth in the context of the present invention.
- the present invention also relates to a seed, in particular to bulked seeds, of the plant of the present invention.
- the seed/seeds shall contain the oil or lipid of the present invention.
- bulked seeds from event LBFGKN were determined to have 25.7 mg EPA+DHA/g seed and bulked seeds from event LBFDAU was determined to have 47.4 mg EPA+DHA/g seed.
- the present invention relates to seeds, in particular Brassica seeds, wherein 1 g of the seeds comprises a combined content of EPA and DHA of at least 10 mg, in particular of at least 20 mg.
- 1 g of the seeds of the present invention comprise a combined content of EPA and DHA of preferably 15 to 75 mg, more preferably of 20 to 60 mg, and most preferably of 25 to 50 mg.
- the seeds of the present invention comprise at least one T-DNA of the present invention.
- said seeds are transgenic.
- the present invention also concerns seed meal and seed cake produced from the seeds of the present invention, in particular from bulked seeds of the present invention.
- the seeds that were produced in the context of the studies underlying the present invention had higher yield and larger contents of seed oil than expected (see e.g. Example 18, EPA/DHA in tables 152 and 153, and oil in table 154).
- the degree of unsaturation and elongation was increased in transgenic seed oil relative to controls.
- the introduced desaturases and elongases consume additional ATP and NADH compared to controls. Therefore, the desaturases and elongases that we introduced are in direct competition with de novo fatty acid and oil synthesis, which also require ATP and NADH (every elongation requires two NADH and one ATP, and every desaturation requires one NADH).
- the seeds of the present invention and the seeds of the plant or plants of the present invention preferably have a seed oil content at least 38%, More preferably, the seeds have a seed oil content of 38 to 42%, in particular of 38% to 40%.
- seed oil content is expressed as percentage of oil weight of the total weight of seeds.
- the seed oil is produced in plants that have a seed yield that is no different from control plants when cultivated in the field.
- the plant of the present invention is preferably a transgenic B. napus plant. As described elsewhere herein, the plant shall produce both EPA and DHA. It is envisaged that the oil from the bulked seed contains more than 12% non-naturally occurring PUFA. Thus, the content of the non- naturally occurring fatty acids shall be more than 12% of the total fatty acid content. In another embodiment, the oil from the bulked seed contains more than 16% non-naturally occurring PUFA. In another embodiment, the oil from the bulked seed contains more than 18% non-naturally occurring PUFA.
- the expression "non-naturally occurring” preferably refers to PUFAs which do not occur naturally in wild-type Brassica plant.
- said non-naturally occurring PUFASs are 18:2n-9, GLA, SDA, 20:2n-9, 20:3n-9, 20:3 n-6, 20:4n-6, 22:2n-6, 22:5n-6, 22:4n-3, 22:5n-3, and 22:6n-3.
- these PUFAs do not naturally occur in Brassica plants, they may nevertheless occurring in other non-transgenic organisms.
- each T-DNA copy of the transgenic plant is stable over multiple generations as determined by copy number analysis at three or more locations on the T-DNA.
- the transgenic construct inserted into the B. napus plant has a copy number of 1 or 2.
- one or two copies of the T-DNA of the invention shall be present in the plant.
- the transgenic construct inserted into the B. napus plant has a copy number of 1.
- all inserted transgenes are fully functional (thus, the enzymes encoded by the genes shall retain their function).
- the genetic insertion is located >5000 base pairs away from any endogenous gene. In an embodiment, the distance is measured from the end of the left and right border.
- the plant of the present invention in particular the plant described is used in a method using produce an oil containing EPA and DHA.
- the oil has been described in detail elsewhere herein.
- the oil comprises non-naturally occurring PUFA as described above.
- the method of producing the oil may comprise the steps of growing a plant of the present invention such as to obtain oil-containing seeds thereof, harvesting said seed, and extracting oil form said seeds.
- the present invention further envisages an oil containing EPA and DHA produced by plants the plant described above.
- a further embodiment according to the invention is the use of the oil, lipid, fatty acids and/or the fatty acid composition in feedstuffs, foodstuffs, dietary supplies, cosmetics or pharmaceutical compositions as set forth in detail below.
- the oils, lipids, fatty acids or fatty acid mixtures according to the invention can be used for mixing with other oils, lipids, fatty acids or fatty acid mixtures of animal origin such as, for example, fish oils.
- the present invention thus envisages feedstuffs, foodstuffs and dietary supplies.
- the feedstuffs, foodstuffs and dietary supplies comprise the plant of the present invention, a part of a plant of the present invention, in particular a seed or seed, and/or the oil or lipid of the present invention.
- the feedstuffs, foodstuffs and dietary supplies comprise seedcake or seedmeal produced from the plant of the present invention, in particular from seeds of the plant of the present invention.
- the present invention also concerns seedcake or seedmeal produced from the plant of the present invention, in particular from seeds of the plant of the present invention.
- the seedmeal or seedcake comprises at least one T-DNA of the present invention.
- the feedstuffs, foodstuffs and dietary supplies may comprise a fatty acid ester, or a fatty acid produced from a plant of the present invention (orfrom a part thereof, in particular from the seeds).
- the feedstuff of the present invention can be used in aquaculture. Using the feedstuff will allow to increase the contents of VLC-PUFAs in fish. In an embodiment, the fish is salmon.
- composition refers to any composition formulated in solid, liquid or gaseous form.
- Said composition comprises the compound of the invention optionally together with suitable auxiliary compounds such as diluents or carriers or further ingredients.
- suitable auxiliary compounds i.e. compounds which do not contribute to the effects elicited by the compounds of the present invention upon application of the composition for its desired purpose
- further ingredients i.e. compounds which contribute a further effect or modulate the effect of the compounds of the present invention.
- Suitable diluents and/or carriers depend on the purpose for which the composition is to be used and the other ingredients. The person skilled in the art can determine such suitable diluents and/or carriers without further ado.
- suitable carriers and/or diluents are well known in the art and include saline solutions such as buffers, water, emulsions, such as oil/water emulsions, various types of wetting agents, etc.
- the said composition is further formulated as a pharmaceutical composition, a cosmetic composition, a foodstuff, a feedstuff, preferably, fish feed or a dietary supply.
- pharmaceutical composition as used herein comprises the compounds of the present invention and optionally one or more pharmaceutically acceptable carrier.
- the compounds of the present invention can be formulated as pharmaceutically acceptable salts. Acceptable salts comprise acetate, methylester, Hel, sulfate, chloride and the like.
- the pharmaceutical compositions are, preferably, administered topically or systemically. Suitable routes of administration conventionally used for drug administration are oral, intravenous, or parenteral administration as well as inhalation. However, depending on the nature and mode of action of a compound, the pharmaceutical compositions may be administered by other routes as well.
- polynucleotide compounds may be administered in a gene therapy approach by using viral vectors or viruses or liposomes.
- the compounds can be administered in combination with other drugs either in a common pharmaceutical composition or as separated pharmaceutical compositions wherein said separated pharmaceutical compositions may be provided in form of a kit of parts.
- the compounds are, preferably, administered in conventional dosage forms prepared by combining the drugs with standard pharmaceutical carriers according to conventional procedures. These procedures may involve mixing, granulating and compressing or dissolving the ingredients as appropriate to the desired preparation.
- standard pharmaceutical carriers according to conventional procedures. These procedures may involve mixing, granulating and compressing or dissolving the ingredients as appropriate to the desired preparation.
- the form and character of the pharmaceutically acceptable carrier or diluent is dictated by the amount of active ingredient with which it is to be combined, the route of administration and other well-known variables.
- the carrier(s) must be acceptable in the sense of being compatible with the other ingredients of the formulation and being not deleterious to the recipient thereof.
- the pharmaceutical carrier employed may be, for example, a solid, a gel or a liquid.
- solid carriers are lactose, terra alba, sucrose, talc, gelatin, agar, pectin, acacia, magnesium stearate, stearic acid and the like.
- liquid carriers are phosphate buffered saline solution, syrup, oil such as peanut oil and olive oil, water, emulsions, various types of wetting agents, sterile solutions and the like.
- the carrier or diluent may include time delay material well known to the art, such as glyceryl mono- stearate or glyceryl distearate alone or with a wax.
- suitable carriers comprise those mentioned above and others well known in the art, see, e.g., Remington's Pharmaceutical Sciences, Mack Publishing Company, Easton, Pennsylvania.
- the diluent(s) is/are selected so as not to affect the biological activity of the combination. Examples of such diluents are distilled water, physiological saline, Ringer's solutions, dextrose solution, and Hank's solution.
- the pharmaceutical composition or formulation may also include other carriers, adjuvants, or nontoxic, nontherapeutic, nonimmunogenic stabilizers and the like.
- a therapeutically effective dose refers to an amount of the compounds to be used in a pharmaceutical composition of the present invention which prevents, ameliorates or treats the symptoms accompanying a disease or condition referred to in this specification.
- Therapeutic efficacy and toxicity of such compounds can be determined by standard pharmaceutical procedures in cell cultures or experimental animals, e.g., ED50 (the dose therapeutically effective in 50% of the population) and LD50 (the dose lethal to 50% of the population).
- the dose ratio between therapeutic and toxic effects is the therapeutic index, and it can be expressed as the ratio, LD50/ED50.
- the dosage regimen will be determined by the attending physician and other clinical factors; preferably in accordance with anyone of the above described methods. As is well known in the medical arts, dosages for anyone patient depends upon many factors, including the patient's size, body surface area, age, the particular compound to be administered, sex, time and route of administration, general health, and other drugs being administered concurrently. Progress can be monitored by periodic assessment.
- a typical dose can be, for example, in the range of 1 to 1000 ⁇ g; however, doses below or above this exemplary range are envisioned, especially considering the aforementioned factors. However, depending on the subject and the mode of administration, the quantity of substance administration may vary over a wide range.
- the pharmaceutical compositions and formulations referred to herein are administered at least once in order to treat or ameliorate or prevent a disease or condition recited in this specification. However, the said pharmaceutical compositions may be administered more than one time, for example from one to four times daily up to a non-limited number of days.
- Specific pharmaceutical compositions are prepared in a manner well known in the pharmaceutical art and comprise at least one active compound referred to herein above in admixture or otherwise associated with a pharmaceutically acceptable carrier or diluent.
- the active compound(s) will usually be mixed with a carrier or the diluent, or enclosed or encapsulated in a capsule, sachet, cachet, paper or other suitable containers or vehicles.
- the resulting formulations are to be adopted to the mode of administration, i.e. in the forms of tablets, capsules, suppositories, solutions, suspensions or the like.
- Dosage recommendations shall be indicated in the prescribers or users instructions in order to anticipate dose adjustments depending on the considered recipient.
- cosmetic composition relates to a composition which can be formulated as described for a pharmaceutical composition above.
- the compounds of the present invention are also, preferably, used in substantially pure form. Impurities, however, may be less critical than for a pharmaceutical composition.
- Cosmetic compositions are, preferably, to be applied topically.
- Preferred cosmetic compositions comprising the compounds of the present invention can be formulated as a hair tonic, a hair restorer composition, a shampoo, a powder, a jelly, a hair rinse, an ointment, a hair lotion, a paste, a hair cream, a hair spray and/or a hair aerosol.
- the deposition of seeds was made only for convenience of the person skilled in the art and does not constitute or imply any confession, admission, declaration or assertion that deposited seed are required to fully describe the invention, to fully enable the invention or for carrying out the invention or any part or aspect thereof. Also, the deposition of seeds does not constitute or imply any recommendation to limit the application of any method of the present invention to the application of such seed or any material comprised in such seed, e.g. nucleic acids, proteins or any fragment of such nucleic acid or protein.
- the deposited seeds are derived from plants that were transformed with the T-DNA vector having a sequence as shown in SEQ ID NO: 3.
- the plant of the present invention comprises the T-DNAs comprised by LBFLFK and LBFDAU, preferably at the the position in the genome (as in the plants designated LBFLFK and LBFDAU.
- the events are decribed in section B in more detail.
- the present invention thus provides Brassica plants comprising transgenic Brassica event LBFLFK deposited as ATCC Designation "PTA-121703".
- Brassica event LBFLFK contains two insertions of T-DNA of the binary T-plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFLFK Locus 1 and LBFLFK Locus 2.
- the Brassica plants of this embodiment include progeny that are indistinguishable from Brassica event LBFLFK (to the extent that such progeny also contain at least one allele corresponding to LBKLFK Locus 1 and/or LBFLFK Locus 2).
- the Brassica plants of this embodiment comprise unique genomic DNA/transgene junction points, and consequently unique junction regions, for each LBFLFK insertion: the junction region for LBFLFK Locus 1 having at least the polynucleotide sequence of SEQ ID NO:282 or at least the polynucleotide sequence of SEQ ID NO:283, and the junction region for LBFLFK Locus 2 having at least the polynucleotide sequence of SEQ ID NO:291 or at least the polynucleotide sequence of SEQ ID NO:292. Also included in this embodiment are seeds, plant parts, plant cells, and plant products derived from Brassica event LBFLFK and progeny thereof.
- the invention provides commodity products, including canola oil and meal, produced from Brassica event LBFLFK and/or its progeny.
- the invention provides Brassica plants comprising transgenic Brassica event LBFDAU deposited as ATCC Designation "PTA-122340".
- Brassica event LBFDAU contains two insertions of the T-DNA of the binary T-plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFDAU Locus 1 and/or LBFDAU Locus 2.
- the Brassica plants of this embodiment include and progeny thereof that are indistinguishable from Brassica event LBFDAU (to the extent that such progeny also contain at least one allele that corresponds to the inserted transgenic DNA).
- the Brassica plants of this embodiment comprise unique genomic DNA/transgene junction points, and consequently two unique junction regions, for each LBFDAU insertion: the junction region for LBFDAU Locus 1 having at least the polynucleotide sequence of SEQ ID NO:300 or at least the polynucleotide sequence of SEQ ID NO:301 and the junction region for LBFDAU Locus 2 having at least the polynucleotide sequence of SEQ ID NO:309 or at least the polynucleotide sequence of SEQ ID NO:310. Also included in this embodiment are seeds, plant parts, plant cells, and plant products derived from Brassica event LBFDAU and progeny thereof. In another embodiment, the invention provides commodity products, including canola oil and meal, produced from Brassica event LBFDAU and/or its progeny.
- the aforementioned plant of the present invention can be used in method the context of the present invention.
- the oil, fatty acid, or lipid of the present invention is obtainable from the plant (and can be extracted).
- the plants of the invention have been modified by the transformation binary T-plasmid VC- LTM593-1 qcz rc (SEQ ID NO:3) described in the Examples section.
- the T-DNA of this vector (which is a T-DNA of the present invention) comprises (preferably in the following order), polynucleotides encoding the following enzymes of the VLC-PUFA biosynthetic pathway: Delta- 6 ELONGASE from Physcomitrella patens; Delta-5 DESATURASE from Thraustochytrium sp.
- the aforementioned T- DNA of the present invention comprises two copies of a polynucleotide encoding a Delta-5 desaturase from Thraustochytrium sp. ATCC21685, and two copies of a polynucleotide encoding Omega-3 desaturase from Pythium irregulare.
- the T-DNA of VC-LTM593-1 qcz (SEQ ID NO:3) further comprises a polynucleotide encoding the selectable marker acetohydroxy acid synthase, which confers tolerance to imidazolinone herbicides.
- the invention further relates to the T-DNA insertions in each of Brassica events LBFLFK and LBFDAU, and to the genomic DNA/transgene insertions, i.e., the Locus 1 and Locus 2 junction regions found in Brassica plants or seeds comprising Brassica event LBFLFK, to the genomic DNA/transgene insertions, i.e., Locus 1 and Locus 2 junction regions found in Brassica plants or seeds comprising Brassica event LBFDAU, and the detection of the respective genomic DNA/transgene insertions, i.e., the respective Locus 1 and Locus 2 junction regions in Brassica plants or seed comprising event LBFLFK or event LBFDAU and progeny thereof.
- the genomic DNA/transgene insertions i.e., the Locus 1 and Locus 2 junction regions found in Brassica plants or seeds comprising Brassica event LBFLFK
- the genomic DNA/transgene insertions i.e., Locus 1 and Locu
- Progeny, variants and mutants of the regenerated plants are also included within the scope of the invention, provided that the progeny, variants and mutants comprise a LBFLFK or LBFDAU event.
- the progeny, variants, and mutants contain two insertions of T-DNA of the binary T- plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFLFK Locus 1 and LBFLFK Locus 2, provided that the progeny, variants and mutants comprise two insertions of the T-DNA of the binary T-plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFDAU Locus 1 and LBFDAU Locus 2.
- a transgenic "event” is preferably produced by transformation of plant cells with a heterologous DNA construct(s) including a nucleic acid expression cassette that comprises one or more transgene(s) of interest, the regeneration of a population of plants from cells which each comprise the inserted transgene(s) and selection of a particular plant characterized by insertion into a particular genome location.
- An event is characterized phenotypically by the expression of the transgene(s).
- an event is part of the genetic makeup of a plant.
- the term "event” refers to the original transformant and progeny of the transformant that include the heterologous DNA.
- vent also refers to progeny, produced by a sexual outcross between the transformant and another variety, that include the heterologous DNA. Even after repeated back-crossing to a recurrent parent, the inserted DNA and flanking DNA from the transformed parent are present in the progeny of the cross at the same chromosomal location.
- the term “event” also refers to DNA from the original transformant comprising the inserted DNA and flanking sequence immediately adjacent to the inserted DNA that would be expected to be transferred to a progeny as the result of a sexual cross of one parental line that includes the inserted DNA (e.g., the original transformant and progeny resulting from selfing) and a parental line that does not contain the inserted DNA.
- progeny of the Brassica LBFLFK event preferably comprises either LBFLFK Locus 1 or LBFLFK Locus 2, or both LBFLFK Locus 1 and LBFLFK Locus 2.
- progeny of the Brassica LBFDAU event preferably comprises either LBFDAU Locus 1 or LBFDAU Locus 2, or both LBFDAU Locus 1 and LBFDAU Locus 2.
- a “flanking region” or “flanking sequence” as used herein preferably refers to a sequence of at least 20, 50, 100, 200, 300, 400, 1000, 1500, 2000, 2500 or 5000 base pairs or greater which is located either immediately upstream of and contiguous with, or immediately downstream of and contiguous with, the original foreign insert DNA molecule.
- flanking regions of the LBFLFK event comprise, for Locus 1 , nucleotides 1 to 570 of SEQ ID NO: 284, nucleotides 229 to 81 1 of SEQ ID NO:285 and for Locus 2, nucleotides 1 to 2468 of SEQ ID NO:293, and/or nucleotides 242 to 1800 of SEQ ID NO:294 and variants and fragments thereof.
- flanking regions of the LBFDAU event comprise, for Locus 1 , nucleotides 1 to 1017 of SEQ ID NO: 302, nucleotides 637 to 1677 of SEQ ID NO:303, and for Locus 2, nucleotides 1 to 1099 of SEQ ID NO:31 1 and/or nucleotides 288 to 1321 of SEQ ID NO: 312 and variants and fragments thereof.
- junction DNA from the LBFLFK event comprise, for Locus 1 , SEQ ID NO:282, SEQ ID NO:283, and for Locus 2, SEQ ID NO:291 , and/or SEQ ID NO:292, complements thereof, or variants and fragments thereof.
- junction DNA from the LBFDAU event comprise, for Locus 1 , SEQ ID NO:300, SEQ ID NO:301 , and for Locus 2, SEQ ID NO:309 and/or SEQ ID NO:310, complements thereof, or variants and fragments thereof.
- the oil of the aforementioned plants of the present invention preferably is an oil as specified elsewhere herein.
- the transgenic Brassica plants of the invention comprise event LBFLFK (ATCC designation PTA-121703). Seed and progeny of event LBFLFK are also encompassed in this embodiment.
- the transgenic Brassica plants of the invention comprise event LBFDAU (ATCC designation PTA-122340). Seed and progeny of event LBFDAU are also encompassed in this embodiment.
- the Brassica plants LBFLFK and LBFDAU can be used to manufacture commodities typically acquired from Brassica. Seeds of LBFLFK and LBFDAU can be processed into meal or oil as well as be used as an oil source in animal feeds for both terrestrial and aquatic animals.
- the LBFLFK Locus 1 genomic DNA/transgene junction region and/or the LBFLFK Locus 2 genomic DNA/transgene junction region is present in Brassica plant LBFLFK (ATCC Accession No. PTA-121703) and progeny thereof.
- the LBFLFK Locus 1 DNA/transgene right border junction region comprises SEQ ID NO:282 and the LBFLFK Locus 1 left border junction region comprises SEQ ID NO:283, and the LBFLFK Locus 2 right border junction region comprises SEQ ID NO:291 and the LBFLFK left border junction region comprises SEQ ID NO:292.
- DNA sequences are provided that comprise at least one junction region sequence of event LBFLFK selected from the group consisting of SEQ ID NO:282 corresponding to positions 561 through 580 of SEQ ID NO:280); SEQ ID NO:283 corresponding to positions 44318 through 44337 of SEQ ID NO:280); SEQ ID NO:291 corresponding to positions 2459 through 2478 of SEQ ID NO:289); and SEQ ID NO:292 corresponding to positions 46232 through 46251 of SEQ ID NO:289), and complements thereof; wherein detection of these sequences in a biological sample containing Brassica DNA is diagnostic for the presence of Brassica event LBFLFK DNA in said sample.
- a Brassica event LBFLFK and Brassica seed comprising these DNA molecules is an aspect of this invention.
- DNA extracted from a Brassica plant tissue sample may be subjected to nucleic acid amplification method using (i) a first primer pair that includes: (a) a first primer derived from an LBFLFK Locus 1 flanking sequence and (b) a second primer derived from the LBFLFK Locus 1 inserted heterologous DNA, wherein amplification of the first and second primers produces an amplicon that is diagnostic for the presence of event LBFLFK Locus 1 DNA; and (ii) a second primer pair that includes (a) a third primer derived from an LBFLFK Locus 2 flanking sequence and (b) a fourth primer derived from the LBFLFK Locus 2 inserted heterologous DNA, wherein amplification of the third and fourth primers produces an amplicon that is diagnostic for the presence of event LBFLFK Locus 2 DNA.
- a first primer pair that includes: (a) a first primer derived from an LBFLFK Locus 1 flanking sequence and (b) a
- the primer DNA molecules specific for target sequences in Brassica event LBFLFK comprise at least 1 1 contiguous nucleotides of any portion of the insert DNAs, flanking regions, and/or junction regions of LBFLFK Locus 1 and Locus 2.
- LBFLFK Locus 1 primer DNA molecules may be derived from any of SEQ ID NO:280, SEQ ID NO:281 , SEQ ID NO:282, or SEQ ID NO:283; SEQ ID NO:284, or SEQ ID NO:285, or complements thereof, to detect LBFLFK Locus 1.
- LBFLFK Locus 2 primer DNA molecules may be derived from any of SEQ ID NO:293, SEQ ID NO:294, SEQ ID NO:291 , or SEQ ID NO:292; SEQ ID NO:290, or SEQ ID NO:289, or complements thereof, to detect LBFLFK Locus 2.
- the LBFLFK Locus 1 and Locus 2 amplicons produced using these DNA primers in the DNA amplification method are diagnostic for Brassica event LBFLFK when the amplification product contains an amplicon comprising an LBFLFK Locus 1 junction region SEQ ID NO:282 or SEQ ID NO:283, or complements thereof, and an amplicon comprising an LBFLFK Locus 2 junction region SEQ ID NO:291 , or SEQ ID NO:292, or complements thereof.
- the LBFDAU Locus 1 genomic DNA/transgene junction region and/or the LBFDAU Locus 2 genomic DNA/transgene junction region is present in Brassica event LBFDAU (ATCC Accession No. PTA-122340) and progeny thereof.
- the LBFDAU Locus 1 DNA/transgene right border junction region comprises SEQ ID NO:300 and the LBFDAU Locus 1 left border junction region comprises SEQ ID NO:301
- the LBFDAU Locus 2 right border junction region comprises SEQ ID NO:309 and the LBFDAU left border junction region comprises SEQ ID NO:310.
- DNA sequences are provided that comprise at least one junction region sequence of event LBFDAU selected from the group consisting of SEQ ID NO:300 (corresponding to positions 1008 through 1027 of SEQ ID NO:298, as shown in FIG. 4); SEQ ID NO:301 (corresponding to positions 44728 through 44747 of SEQ ID NO:298, as shown in FIG. 4); SEQ ID NO:309 (corresponding to positions 1090 through 1 109 of SEQ ID NO:307, as shown in FIG. 5); and SEQ ID NO:310 (corresponding to positions 38577 through 38596 of SEQ ID NO:307, as shown in FIG.
- a Brassica event LBFDAU and Brassica seed comprising these DNA molecules is an aspect of this invention.
- DNA extracted from a Brassica plant tissue sample may be subjected to nucleic acid amplification method using (i) a first primer pair that includes: (a) a first primer derived from an LBFDAU Locus 1 flanking sequence and (b) a second primer derived from the LBFDAU Locus 1 inserted heterologous DNA, wherein amplification of the first and second primers produces an amplicon that is diagnostic for the presence of event LBFDAU Locus 1 DNA; and/or (ii) a second primer pair that includes (a) a third primer derived from an LBFDAU Locus 2 flanking sequence and (b) a fourth primer derived from the LBFDAU Locus 2 inserted heterologous DNA, wherein amplification of the third and fourth primers produces an amplicon that is diagnostic for the presence of event LBFDAU Locus 2 DNA.
- a first primer pair that includes: (a) a first primer derived from an LBFDAU Locus 1 flanking sequence and (b)
- Seed derived from Brassica event LBFLFK or Brassica event LBFDAU for sale for planting or for making commodity products is an aspect of the invention.
- Such commodity products include canola oil or meal containing VLC-PUFAs including but not limited to EPA and DHA.
- Commodity products derived from Brassica event LBFLFK comprise a detectable amount a DNA molecule comprising SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and/or SEQ ID NO:292.
- Commodity products derived from Brassica event LBFDAU comprise a detectable amount a DNA molecule comprising SEQ ID NO:300, SEQ ID NO:301 , SEQ ID NO:309, and/or SEQ ID NO:310.
- Exemplary commodity products derived from events LBFLFK and LBFDAU include, but are not limited to, cooking oil, salad oil, shortening, nutritionally enhanced foods, animal feed, pharmaceutical compositions, cosmetic compositions, hair care products, and the like.
- the invention also provides a commercially relevant source of plant material, preferably of seed.
- the invention provides a heap of at least 5kg, preferably of at least 10 kg, more preferably of at least 50kg, even more preferably of at least 100 kg, even more preferably of at least 500 kg, even more preferably of at least 1 t, even more preferably of at least 2t, even more preferably of at least 5t of plant material, wherein the plant material comprises VLC-PUFAs as described according to the invention.
- the plant material is preferably plant seed, even more preferably seed of VLC-PUFA producing seed, such that the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 10% (w/w) and/or the content of DHA is at least 1 % (w/w) of the total seed fatty acid content at an oil content of 30% (w/w), or meal of such plant seed.
- the invention provides a container comprising such plant seed in an amount of at least 5kg, preferably of at least 10 kg, more preferably of at least 50kg, even more preferably of at least 100 kg, even more preferably of at least 500 kg, even more preferably of at least 1t, even more preferably of at least 2t, even more preferably of at least 5t.
- the invention thus demonstrates that the invention has well eclipsed anecdotal findings of lab scale VLC-PUFA containing plants, and instead has overcome the additional requirements for providing, on a large scale, a reliable source for VLC-PUFA and particularly for EPA and/or DHA in plant oil and plant material.
- the present invention allows for the generation of plants comprising a modified fatty acid composition (as compared to control plants).
- the T-DNAs, the expression cassettes, vectors, polynucleotides (in particular the combination of polynucleotides), and polypeptides ((in particular the combination of polynucleotides) as disclosed herein can be used for modifying the fatty acid composition of a plant.
- the content of at least one fatty acid disclosed in Table 18 or 181 is modified in seed oil (increased or decreased as compared to the content in seed oil of a control plant).
- the content of at least one fatty acid disclosed in Table 18 or 181 is modified in in the monoacylgylcerol (MAG) fraction, the diacylgylcerol (DAG) fraction, the triacylgylcerol (TAG) fraction, phosphatidylcholine (PC) fraction and/or phosphatidylethanolamine (PE) fraction of seed oil (increased or decreased as compared to the content of seed oil of a control plant).
- the content of at least one Lysophosphatidylcholine species shown in Table 189 is modified in seed oil (increased or decreased as compared to the content in seed oil of a control plant).
- the content of at least one Phosphatidylethanolamine species shown in Table 190 is modified in seed oil (increased or decreased as compared to the content in seed oil of a control plant).
- the content of at least one Lysophosphatidylethanolamine species shown in Table 191 is modified in seed oil (increased or decreased as compared to the content in seed oil of a control plant).
- the content of at least one Triacylglycerol species shown in Table 192 is modified in seed oil (increased or decreased as compared to the content in seed oil of a control plant).
- mead acid may be made from the side activities of d6Des, d6Elo, and d5Des, using 18:1 n-9 to make 18:2n-9 (by d6Des), then 20:2n-9 (by d6Elo), then 20:3n-9 (by d5Des).
- mead acid in fungi is only made if the d12Des is mutated to be inactive (Takeno etal. 2005 App. Environ. Microbiol. 71 (9): 5124- 5128).
- the studies underlying the present invention surprisingly show that mead acid is produced in plants even when a d12Des is overexpressed.
- the present invention relates to a method for increasing the content of Mead acid (20:3n-9) in a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6- elongase, and at least one polynucleotide encoding a delta-5-desaturase.
- the present invention relates to a method for producing Mead acid (20:3n-9) in a plant relative to a control plant, comprising expressing in a plant, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase.
- the aforementioned methods may further comprise the expression of further desatuarase or eleogase, in particular of one or more of a delta-12-desaturase, omega-3-desaturase, a delta-5- elongase, and delta-4-desaturase.
- at least one, two, three, or in particular four further enzymatic actitivities can be expressed in the plant.
- the methods further comprise expressing in the plant at least one polynucleotide encoding a delta-12-desaturase.
- the methods further comprise expressing in the plant at least one polynucleotide encoding an omega-3-desaturase.
- the methods further comprise expressing in the plant at least one polynucleotide encoding a delta-5-elongase. In an embodiment, the methods further comprise expressing in the plant at least one polynucleotide encoding a delta-4-desaturase. In an embodiment, at least one CoA dependent delta-4-desaturase and at least one phospholipid dependent delta-4 desaturase is expressed.
- the methods further comprise expressing in the plant at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding an omega-3-desaturase, at least one polynucleotide encoding a delta-5-elongase, and at least one polynucleotide encoding delta-4-desaturase.
- Preferred polynucleotides encoding desaturases and elongases are described above.
- the gene dosage effect described above may be also used for the the producing of mead acid or for increasing the content of mead acid in plants.
- At least one polynucleotide encoding a delta-6-desaturase at least two polynucleotides encoding a delta-6-elongase, and at least two polynucleotides encoding a delta-5-desaturase.
- At least one polynucleotide encoding a delta-12-desaturase at least three polynucleotides encoding an omega-3-desaturase, at least one polynucleotide encoding a delta-5-elongase, and/or at least two polynucleotides encoding a delta-4-desaturase can be further expressed (preferably at least one CoA dependent delta-4-desaturase and at least one phospholipid dependent delta-4 desaturase).
- At least one polynucleotide encoding a delta-6 elongase from Physcomitrella patens at least one polynucleotide encoding a delta-6 elongase from Thalassiosira pseudonana, and at least two polynucleotides encoding a delta-5 desaturase from Thraustochytrium sp are expressed.
- the polynucleotides to be expressed are recombinant polynucleotides. More preferably, the polynucleotides are present on one T-DNA which is comprised by the genome of the plant. Thus, the T-DNA is stably integrated into the genome.
- the polynucleotides encoding for the desaturaes and elongases as set forth herein are comprised by the same T- DNA.
- the polynucleotides encoding the desaturases or elongases i.e. each of the polynucleotides
- are operably linked to an expression control sequence see elsewhere herein for a definition.
- the polynucleotides may be linked to a terminator, thereby forming an expression cassette comprising an expression control sequence, the target gene, and the terminator.
- the polynucleotides are expressed in the seeds of the plant.
- the expression control sequences may be seed-specific promoters. Preferred seed- specific promoters are e.g. disclosed in Table 1 1 in the Examples section.
- the polynucleotides are expressed by introducing and expressing the polynucleotides in the plants. How to introduce polynucleotides into a plant is well known in the art. Preferred methods are described elsewhere herein.
- the polynucleotides are introduced into a plant by Agrobacterium-mediated transformation.
- the mead acid content is increased in the seeds as compared to the mead acid in seeds of a control plant.
- the mead acid content in seed oil is increased in the seeds is increased as compared to the mead acid in seed oil of a control plant.
- the plant is an oilseed plant.
- the plant is selected from the group consisting of flax (Linum sp.), rapeseed (Brassica sp.), soybean (Glycine and Soja sp.), sunflower (Helianthus sp.), cotton (Gossypium sp.), corn (Zea mays), olive (Olea sp.), safflower (Carthamus sp.), cocoa (Theobroma cacoa), peanut (Arachis sp.), hemp, camelina, crambe, oil palm, coconuts, groundnuts, sesame seed, castor bean, lesquerella, tallow tree, sheanuts, tungnuts, kapok fruit, poppy seed, jojoba seeds and perilla.
- the plant is a plant of the family Brassicaceae, preferably of genus Brassica and most preferably of a species comprising a genome of one or two members of the species Brassica oleracea, Brassica nigra and Brassica rapa, thus in particular of the species Brassica napus, Brassica carinata, Brassica juncea, Brassica oleracea, Brassica nigra or Brassica rapa.
- the method further comprises the step of a selecting for a plant having an increased mead acid content, in particular in seed oil.
- the selection is done based on the mead acid content.
- the step may thus comprise the step of determining the mead acid content in the seeds, or seed oil of the plant. How to determine the mead acid content is e.g. described in Example 29.
- the Mead acid is preferably esterified mead acid.
- the plants expressing said polynucleotides, in particular the seeds of the plants shall comprise/produce mead acid.
- the content of Mead acid (20:3n-9) in the seed oil of the plant is between about 0.1 % and 2%, more preferably between about 0.1 % and 1 %, most preferably between about 0.1 % and 0.5% of the total fatty acid content of seed oil (in particular the total content of esterified fatty acids).
- VLC-PUFAs may be present in the seed oil (as described elsewhere herein in connection with the oil of the present invention).
- the present invention also relates to a construct or T-DNA comprising expression cassettes for the desaturases and elongases as referred to in the context of the method of increasing the content of mead acid.
- the present invention also relates to a construct comprising at least one expression cassette for for a delta-6-desaturase, at least one expression cassette for a delta- 6-elongase, and at least one expression cassette for a delta-5-desaturase.
- the construct or T- DNA may further comprise at least one expression cassette for a delta-12-desaturase, at least one expression cassette for an omega-3-desaturase, at least one expression cassette for a delta- 5-elongase, and/or at least one expression cassette for a delta-4-desaturase.
- the construct or T-DNA comprises at least one expression cassette for a delta- 6 elongase from Physcomitrella patens, at least one expression cassette for a delta-6 elongase from Thalassiosira pseudonana, and at least two expression cassettes for a delta-5 desaturase from Thraustochytnum sp. (in particular Thraustochytnum sp.
- ATCC21685 and optionally at least two expression cassettes for an omega-3 desaturase from Pythium irregulare, at least one expression cassette for a omega-3-desaturase from Phythophthora infestans, at least one expression cassette for a delta-5 elongase from Ostreococcus tauri, and at least one expression cassette for a delta-4 desaturase from Thraustochytnum sp., and/or at least one expression cassette for a delta-4 desaturase from Pavlova lutheri.
- the present invention further relates to the use of i) a construct or T-DNA of the present invention or of ii) at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, at least one polynucleotide encoding a delta-5-desaturase, for a) increasing the mead acid content of a plant (in particular in the seeds) relative to a control plants (in particular in the seeds of a control plant) or for producing mead acid in a plant, in particular in the seeds of a plant.
- polynucleotides encoding desaturases and/or elongases as referred to in the context of the method for increasing mead acid can be used (such as a polynucleotide encoding a delta-12-desaturase).
- the present invention also relates to plant, or plant cells transformed with or comprising i) a construct or T-DNA of the present invention or ii) at least one polynucleotide encoding a delta-6- desaturase, at least one polynucleotide encoding a delta-6-elongase, at least one polynucleotide encoding a delta-5-desaturase.
- the plant or plant cell further is transformed with or comprises the further polynucleotides encoding desaturases and/or elongases as referred to in the context of the method for increasing mead acid can be used (such as a polynucleotide encoding a delta-12-desaturase).
- Preferred polynucleotide sequences for the desaturases and elongases are disclosed above.
- the present invention relates to a method of mead acid production, comprising the steps of
- the oil is an oil as described herein above.
- the oil shall have a mead acid content as described above.
- the present invention pertains to plants that produce VLC-PUFAs (and to plants that produce Mead acid).
- Said plants shall comprise one or more T-DNAs comprising expression cassettes for certain desaturases and elongases as explained herein in detail.
- said expression cassettes are comprised by the same T-DNA (or construct).
- the T-DNA or construct of the present invention further comprises at least one expression cassette comprising a polynucleotide encoding for an acetohydroxy acid synthase (abbreviated AH AS enzyme, also known a acetolactate synthase), wherein said acetohydroxy acid synthase confers tolerance to an herbicide of the imidazolinone class.
- AHAS enzyme is preferably a mutated AHAS enzyme. Mutated AHAS enzymes that confer tolerance to an herbicide of the imidazolinone class are known in the art and e.g. disclosed in WO 2008/124495 which herewith is incorporated by reference in its entirety.
- the matutated AHAS enzyme is a mutated Arabidopsis thaliana AHAS enzyme.
- the envisaged enzyme is mutated at two positions.
- the envisaged enzyme has at position 653 a serine replaced by an asparagine and at position 122 an alanine replaced by a threonine.
- polynucleotide encoding for an AHAS enzyme which confers tolerance to an herbicide of the imidazolinone class is selected from:
- nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NO: 277 b) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NO:278.
- nucleic acid sequence being at least 70%, 80%, or 90% identical to the nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NO: 277, d) a nucleic acid sequence encoding a polypeptide which is at least 60%, 70%, 80, or 90% identical to a polypeptide having an amino acid sequence as shown in SEQ ID NO: 278 , and
- nucleic acid sequence which is capable of hybridizing under stringent conditions to i) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NO: 277, or to ii) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NO:278.
- the polypetide encoded by the said polynucleotide shall confer tolerance to an herbicide of the imidazolinone class.
- the polypeptide thus shall have a serine-to-asparagine substitution at the position corresponding to position 653 of SEQ ID NO:278, and/or an alanine-to-threonin substitution at the position corresponding to position 122 of SEQ ID NO:278.
- the herbicide of the imidazolinone class is preferably selected from imazethapyr, imazapic, imazamox, imazaquin, imazethabenz, and imazapyr, in particular imazamox (lUPAC: (R/S)-2-(4- isopropyl-4-methyl-5-oxo-2-imidazolin-2-yl)-5-methoxymethylnicotinic acid).
- the herbicide of the imidazolinone class can be selected from, but is not limited to, 2- (4-isopropyl- 4-methyl-5-oxo- 2-imidiazolin-2-yl) -nicotinic acid, [2- (4-isopropyl)-4-] [methyl-5-oxo-2-imidazolin- 2-yl)-3-quinolinecarboxylic] acid, [5-ethyl-2- (4-isopropyl-] 4-methyl-5-oxo-2- imidazolin-2-yl) - nicotinic acid, 2- (4-isopropyl-4-methyl-5-oxo-2- imidazolin-2-yl)- 5- (methoxymethyl)-nicotinic acid, [2- (4-isopropyl -4-methyl-5-oxo-2-] imidazolin-2- yl)-5-methylnicotinic acid.
- the present invention relates to a method of controlling weeds in the vicinity of a plant of the present invention, said method comprising applying at least one herbicide of the imidazolinone class to the weeds and to the plant of the present invention, thereby suppressing growth of the weeds in the vicinity of a plant of the present invention.
- the plant of the present invention in the context with the aforementioned method shall comprise the expression cassettes for the desaturases and elongases as explained elsewhere herein (preferably, at least one T-DNA comprising the expression cassettes) and an expression cassette comprising a polynucleotide encoding for an acetohydroxy acid synthase, wherein said acetohydroxy acid synthase confers tolerance to an herbicide of the imidazolinone class.
- the expression cassettes for the desaturases and elongases and the comprising a polynucleotide encoding for an acetohydroxy acid synthase are comprised by the same T-DNA.
- the present invention also relates to the aforementioned plant.
- the polynucleotide encoding for an acetohydroxy acid synthase as set forth above is overexpressed.
- said polynucleotide is operably linked to a constitutive promoter.
- said constitutive promoter is a CaMV 35S promoter.
- said constitutive promoter is a parsley ubiquitin promoter (such as the promoter used for the expression of the mutated AHAS genes in the examples, for the position in SEQ ID NO; 3, see table 1 1 ).
- preferred plants of the current invention contain a gene for resistance to imidazolinone class of herbicides, which inhibit the aceto-hydroxy acid synthase (AHAS) gene of plants.
- the gene that confers resistance is a modified variant of AHAS.
- the expression cassettes for the polynucleotide encoding for an acetohydroxy acid synthase may be comprised by the same T- DNA as the expression cassettes for the elongases and desaturases as referred to herein, or by a different T-DNA.
- the expression cassettes are comprised by the same T-DNA.
- the T-DNA or construct of the present invention comprises polynucleotides encoding the following enzymes (in particular in this order): Delta-6 ELONGASE from Physcomitrella patens; Delta-5 DESATURASE from Thraustochytrium sp. ATCC21685; Delta-6 DESATURASE from Ostreococcus tauri; Delta-6 ELONGASE from Thalassiosira pseudonana; Delta-12 DESATURASE from Phythophthora sojae; Omega-3 DESATURASE from Pythium irregulare; Omega-3-DESATURASE from Phythophthora infestans; Delta-5 DESATURASE from Thraustochytrium sp (in particular sp.
- AHAS overexpression of AHAS could be increased consumption of pyruvate, leading to a reduction in oil content and potentially an increase in amino acid or protein content
- overexpression of AHAS results in increased lysine production in bacteria; see also Muhitch 1988 Plant Physiol 83:23-27, where the role of AHAS in amino acid supply is described. Therefore, it is surprising that overexpression of an AHAS variant, especially in combination with the AHAS inhibiting herbicide, did not result in changes to protein, oil, or VLC-PUFA content in seeds (see example 18).
- the present invention provides for a method of production of VLC-PUFA in which field grown plants are sprayed with an AHAS-inhibiting herbicide.
- said herbicide is of the imidazolinone class
- Embodiments T-DNA for expression of a target gene in a plant wherein the T-DNA comprises a left and a right border element and at least one expression cassette comprising a promoter, operatively linked thereto a target gene, and downstream thereof a terminator, wherein the length of the T-DNA, measured from left to right border element and comprising the target gene, has a length of at least 30000 bp.
- T-DNA comprising the coding sequences of any single gene of the tables given in the examples, preferably comprising the coding sequences and and promoters of any single of the tables given in the examples, more preferably the coding sequences and promoters and terminators of any single of the tables given in the examples, and most preferably the expression cassettes of any single of the tables of the examples, in particular wherein the T-DNA comprises the coding sequences of the desaturases and elongases of Table 1 1 in the Examples.
- Plant comprising one or more T-DNA comprising one or more expression cassettes encoding for one or more d5Des, one or more d6Elo, one or more d6Des, one or more o3Des, one or more d5Elo and one or more D4Des.
- Embodiment 3 or 4 comprising one or more T-DNAs encoding for at least two d6Des, at least two d6Elo and/or, at least two o3Des.
- the plant any one of Embodiments 3 to 5 on or a part thereof comprising a T-DNA encoding for at least one CoA-depenent d4Des and at least one phopho-lipid dependent d4Des.
- the plant, seed or part thereof any one of Embodiments 3 to 6 the plant, seed or part thereof further encoding for one or more d12Des.
- a plant of family Brassicaceae preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant comprising a T-DNA of any of Embodiments 1 or 2 and/or part of such T-DNA, with a plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant not comprising said T-DNA and/or part thereof, to yield a F1 hybrid,
- step (ii) comprising the T-DNA of the present invention capable of producing seed comprising VLC-PUFA such that the content of all VLC- PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 6%, preferably at least 7,5% (w/w) and/or the content of DHA is at least 0,8% (w/w), preferably 1 ,2% of the total seed fatty acid content at an oil content of 40% (w/w).
- a transgenic plant according to any of Embodiments 3 or 4 with a plant not comprising a T-DNA according to any of Embodiments 1 or 2 or part thereof, said latter plant being of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, to yield a F1 hybrid,
- step (ii) identifying the progeny of step (ii) comprising the T-DNA of the present invention capable of producing seed comprising VLC-PUFA such that the content of all VLC- PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 6%, preferably at least 7,5% (w/w) and/or the content of DHA is at least 0,8% (w/w), prerferably 1.2% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w).
- Method of plant oil production comprising the steps of
- step iii) extracting oil from said seeds harvested in step ii), wherein the oil has a DHA content of at least 1 % by weight based on the total lipid content and/or a EPA content of at least 8% by weight based on the total lipid content.
- Plant oil comprising a polyunsaturated fatty acid obtainable or obtained by the method of Embodiment 1 1.
- Method for determining CoA-dependence of a target desaturase comprising the steps of i) providing an elongase to produce a substrate for the target desaturase, and determining conversion efficiency of the target desaturase, and
- step ii) providing a non-CoA dependent desaturase to produce the substrate for the target desaturase, and determining conversion efficiency of the target desaturase, and iii) comparing the target desaturase conversion efficiencies of step i) and ii).
- Method for determining CoA-dependence of a target desaturase comprising the steps of i) providing an elongase to elongate the products of the target desaturase, and determining conversion efficiency of the elongase,
- a method for increasing the content of Mead acid (20:3n-9) in a plant relative to a control plant comprising expressing in a plant at least one polynucleotide encoding a delta-6- desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase.
- SECTION B BRASSICA EVENTS LBFLFK AND LBFDAU AND METHODS FOR DETECTION THEREOF
- the present invention relates to the field of biotechnology and agriculture, and more specifically, to transgenic Brassica plants comprising event LBFLFK or event LBFDAU, progeny plants, seed thereof, and oil and meal derived therefrom.
- the invention also relates to methods for detecting the presence of event LBFLFK or event LBFDAU in biological samples which employ nucleotide sequences that are unique to each event. BACKGROUND OF THE INVENTION (for the invention described in Section B)
- VLC-PUFA Very Long Chain Polyunsaturated Fatty Acids
- PUFA Very Long Chain Polyunsaturated Fatty Acids
- EPA eicosapentaenoic acid
- DHA docosahexaenoic acid
- dietary supplements containing EPA and DHA are used to alleviate cardiovascular and neurological pathology, and may be useful in treating some cancers.
- Polynucleotides encoding polypeptides which exhibit delta-6-elongase activity have been described in WO2005/012316, WO2005/007845 and WO2006/069710, said documents, describing this enzyme from Thalassiosira pseudonana.
- Polynucleotides encoding polypeptides which exhibit delta-12-desaturase activity have been described for example in WO2006100241 , said documents, describing this enzyme from Phytophthora sojae.
- Polynucleotides encoding polypeptides which exhibit delta-5-elongase activity have been described for example in WO2005/012316 and WO2007/096387, said documents, describing this enzyme from Ostreococcus tauri.
- Polynucleotides encoding polypeptides which exhibit omega 3-desaturase activity have been described for example in WO2008/022963, said documents, describing this enzyme from Phytium irregulare. Polynucleotides encoding polypeptides which exhibit omega 3-desaturase activity have been described for example in WO2005012316 and WO2005083053, said documents, describing this enzyme from Phytophthora infestans.
- polypeptides which exhibit delta-4-desaturase activity have been described for example in WO2002026946, said documents, describing this enzyme from Thraustochytrium s p .
- Polynucleotides coding for a delta-4 desaturase from Pavlova lutheri are described in WO2003078639 and WO2005007845.
- the expression of foreign gene constructs in plants is known to be influenced by the chromosomal location at which the genes are inserted, and the presence of the transgenic construct at different locations in the plant's genome can influence expression of endogenous genes and the phenotype of the plant. For these reasons, it is necessary to screen large numbers of transgenic events made from a particular construct, in order to identify one or more "elite" events for commercialization that exhibit optimal expression of the transgene without undesirable characteristics.
- An elite event has the desired levels and patterns of transgenic expression and may be used to introgress the transgenic construct into commercially relevant genetic backgrounds, by sexual outcrossing using conventional breeding methods. Progeny of such crosses maintain the transgenic construct expression characteristics of the original elite event.
- This strategy is used to ensure reliable gene expression in a number of varieties that are adapted to local growing conditions. For introgression, deregulation, and quality control purposes, it is necessary to be able to detect the presence of the transgenic construct in an elite event, both in the progeny of sexual crosses and in other plants. In addition, grain, meal, and foodstuffs may also be monitored for adventitious presence of transgenic constructs to ensure compliance with regulatory requirements.
- transgenic construct may be detected using known nucleic acid detection methods such as the polymerase chain reaction (PCR) or DNA hybridization using nucleic acid probes. These detection methods may be directed to frequently used genetic elements, such as promoters, terminators, marker genes, etc. Such methods may not be useful for discriminating between different events that contain the same genetic elements, unless the sequence of the chromosomal DNA adjacent to the inserted construct ("flanking DNA") is also known.
- Event- specific assays are known for numerous genetically modified products which have been commercialized. Event-specific detection assays are also required by regulatory agencies responsible for approving use of transgenic plants comprising a particular elite event. Transgenic plant event-specific assays have been described, for example, in U.S. Pat. Nos. 6,893,826; 6,825,400; 6,740,488; 6,733,974; 6,689,880; 6,900,014; 6,818,807; and 8,999,41 1.
- the present invention provides Brassica plants comprising transgenic Brassica event LBFLFK deposited as ATCC Designation "PTA-121703".
- Brassica event LBFLFK contains two insertions of the binary T-plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFLFK Locus 1 and LBFLFK Locus 2.
- the Brassica plants of this embodiment include progeny that are indistinguishable from Brassica event LBFLFK (to the extent that such progeny also contain at least one allele corresponding to LBKLFK Locus 1 or LBFLFK Locus 2).
- the Brassica plants of this embodiment comprise unique genomic DNA/transgene junction points, and consequently unique junction regions, for each LBFLFK insertion: the junction region for LBFLFK Locus 1 having at least the polynucleotide sequence of SEQ ID NO:282 or at least the polynucleotide sequence of SEQ ID NO:283, and the junction region for LBFLFK Locus 2 having at least the polynucleotide sequence of SEQ ID NO:291 or at least the polynucleotide sequence of SEQ ID NO:292. Also included in this embodiment are seeds, plant parts, plant cells, and plant products derived from Brassica event LBFLFK and progeny thereof.
- compositions and methods are provided for detecting the presence of the Brassica event LBFLFK genomic DNA/transgene junction regions for each LBFLFK insertion: the junction region for LBFLFK Locus 1 having at least the polynucleotide sequence of SEQ ID NO:282 or at least the polynucleotide sequence of SEQ ID NO:283, and the junction region for LBFLFK Locus 2 having at least the polynucleotide sequence of SEQ ID NO:291 or at least the polynucleotide sequence of SEQ ID NO:292.
- the invention provides commodity products, including canola oil and meal, produced from Brassica event LBFLFK and/or its progeny.
- the invention provides Brassica plants comprising transgenic Brassica event LBFDAU deposited as ATCC Designation "PTA-122340".
- Brassicaevent LBFDAU contains two insertions of the binary T-plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFDAU Locus 1 and LBFDAU Locus 2.
- the Brassica plants of this embodiment include and progeny thereof that are indistinguishable from Brassica event LBFDAU (to the extent that such progeny also contain at least one allele that corresponds to the inserted transgenic DNA).
- the Brassica plants of this embodiment comprise unique genomic DNA/transgene junction points, and consequently two unique junction regions, for each LBFDAU insertion: the junction region for LBFDAU Locus 1 having at least the polynucleotide sequence of SEQ ID NO:300or at least the polynucleotide sequence of SEQ ID NO:301 and the junction region for LBFDAU Locus 2 having at least the polynucleotide sequence of SEQ ID NO:309 or at least the polynucleotide sequence of SEQ ID NO:310. Also included in this embodiment are seeds, plant parts, plant cells, and plant products derived from Brassica event LBFDAU and progeny thereof.
- compositions and methods are provided for detecting the presence of the Brassica event LBFDAU genomic DNA/transgene junction regions; the junction region for LBFDAU Locus 1 having at least the polynucleotide sequence of SEQ ID NO:300 or at least the polynucleotide sequence of SEQ ID NO:301 and the junction region for LBFDAU Locus 2 having at least the polynucleotide sequence of SEQ ID NO:309 or at least the polynucleotide sequence of SEQ ID NO:310.
- the invention provides commodity products, including canola oil and meal, produced from Brassica event LBFDAU and/or its progeny.
- SEQ ID NO:279 is the sequence of vector VC-LTM593-1 qcz rc used for transformation (see Figure 92)
- SEQ ID NO:280 is a 44910 bp sequence assembled from the insert sequence of LBFLFK T-DNA Locus 1 (SEQ ID NO: 281 ) and flanking sequences represented by SEQ ID NO:284 and SEQ ID NO:285 (See Figure 93).
- SEQ ID NO:281 is the sequence of the T-DNA insertion in Locus 1 of event LBFLFK, including left and right border sequences (See Figure 93).
- SEQ ID NO:282 is the LBFLFK Locus 1 RB junction region sequence including 10 bp of flanking genomic DNA and bp 1-10 of SEQ ID NO:281 (See Figure 93).
- SEQ ID NO:283 is the LBFLFK Locus 1 LB junction region sequence including bp 43748-43757 of SEQ ID NO:281 and 10 bp of flanking genomic DNA (See Figure 93).
- SEQ ID NO:284 is the flanking sequence up to and including the right border of the T-DNA in LBFLFK Locus 1 .
- Nucleotides 1 -570 are genomic DNA (See Figure 93).
- SEQ ID NO:285 is the flanking sequence up to and including the left border of the T-DNA in LBFLFK Locus 1 .
- Nucleotides 229-81 1 are genomic DNA (See Figure 93).
- SEQ ID NO:286 is an LBFLFK Locus 1_Forward primer suitable for identifying Locus 1 of LBFLFK events.
- a PCR amplicon using the combination of SEQ ID NO:286 and SEQ ID NO:287 is positive for the presence of LBFLFK Locus 1 .
- SEQ ID NO:287 is an LBFLFK Locus 1_Reverse primer suitable for identifying Locus 1 of LBFLFK events.
- a PCR amplicon using the combination of SEQ ID NO:286 and SEQ ID NO:287 is positive for the presence of LBFLFK Locus 1 .
- SEQ ID NO:288 is an LBFLFK locus 1_Probe is a FAMTM -labeled synthetic oligonucleotide that when used in an amplification reaction with SEQ ID NO:286 and SEQ ID NO:287 will release a fluorescent signal when positive for the presence of LBFLFK Locus 1 .
- SEQ ID NO:289 is a 47800 bp sequence assembled from the insert sequence of LBFLFK T-DNA Locus 2 (SEQ ID NO: 290) and flanking sequences represented by SEQ ID NO:293 and SEQ ID NO:294 (See Figure 94).
- SEQ ID NO:290 is the sequence of the T-DNA insertion in Locus 2 of event LBFLFK, including left and right border sequences (See Figure 94).
- SEQ ID NO:291 is the LBFLFK Locus 2 RB junction sequence including 10 bp of flanking genomic DNA and bp 1 -10 of SEQ ID NO:290 (See Figure 94).
- SEQ ID NO:292 is the LBFLFK Locus 2 LB junction sequence including bp 43764-43773 of SEQ ID NO:290 and 10 bp of flanking genomic DNA (See Figure 94).
- SEQ ID NO:293 is the flanking sequence up to and including the right border of the T-DNA in LBFLFK Locus 2.
- Nucleotides 1 -2468 are genomic DNA (See Figure 94).
- SEQ ID NO:294 is the flanking sequence up to and including the left border of the T-DNA in LBFLFK Locus 2.
- Nucleotides 242-1800 are genomic DNA (See Figure 94).
- SEQ ID NO:295 is the LBFLFK locus 2_Forward primer suitable for identifying Locus 2 of LBFLFK events.
- a PCR amplicon using the combination of SEQ ID NO:295 and SEQ ID NO:296 is positive for the presence of LBFLFK Locus 2.
- SEQ ID NO:296 is the LBFLFK locus 2_Reverse primer suitable for identifying Locus 2 of LBFLFK events.
- a PCR amplicon using the combination of SEQ ID NO:295 and SEQ ID NO:296 is positive for the presence of LBFLFK Locus 2.
- SEQ ID NO:297 is the LBFLFK locus 2_Probe is a FAMTM -labeled synthetic oligonucleotide that when used in an amplification reaction with SEQ ID NO:295 and SEQ ID NO:296 will release a fluorescent signal when positive for the presence of LBFLFK Locus 2.
- SEQ ID NO:298 is a 45777 bp sequence assembled from the insert sequence of LBFDAU T-DNA Locus 1 (SEQ ID NO:299) and flanking sequences represented by SEQ ID NO:302 and SEQ ID NO:303 (See Figure 95).
- SEQ ID NO:299 is the sequence of the T-DNA insertion in Locus 1 of event LBFDAU, including left and right border sequences (See Figure 95).
- SEQ ID NO:300 is the LBFDAU Locus 1 RB junction sequence including 10 bp of flanking genomic DNA and bp 1-10 of SEQ ID NO:299 (See Figure 95).
- SEQ ID NO:301 is the LBFDAU Locus 1 LB junction sequence including bp 4371 1-43720 of SEQ ID NO:299 and 10 bp of flanking genomic DNA (See Figure 95).
- SEQ ID NO:302 is the flanking sequence up to and including the right border of the T-DNA in LBFDAU Locus 1 .
- Nucleotides 1 -1017 are genomic DNA (See Figure 95).
- SEQ ID NO:303 is the flanking sequence up to and including the left border of the T-DNA in LBFDAU Locus 1 .
- Nucleotides 637-1677 are genomic DNA (See Figure 95).
- SEQ ID NO:304 is an LBFDAU Locus 1_Forward primer suitable for identifying Locus 1 of LBFDAU events.
- a PCR amplicon using the combination of SEQ ID NO:304 and SEQ ID NO:305 is positive for the presence of LBFDAU Locus 1.
- SEQ ID NO:305 is an LBFDAU Locus 1_Reverse primer suitable for identifying Locus locus 1 of LBFDAU events.
- a PCR amplicon using the combination of SEQ ID NO:304 and SEQ ID NO:305 is positive for the presence of LBFDAU Locus 1.
- SEQ ID NO:306 is an LBFDAU locus 1_Probe is a FAMTM -labeled synthetic oligonucleotide that when used in an amplification reaction with SEQ ID NO:304 and SEQ ID NO:305 will release a fluorescent signal when positive for the presence of LBFDAU Locus 1.
- SEQ ID NO:307 is a 39620 bp sequence assembled from the insert sequence of LBFDAU T-DNA Locus 2 (SEQ ID NO:308) and flanking sequences represented by SEQ ID NO:31 1 and SEQ ID NO:312 (See Figure 96).
- SEQ ID NO:308 is the sequence of the T-DNA insertion in Locus 2 of event LBFDAU, including left and right border sequences (See Figure 96).
- SEQ ID NO:309 is the LBFDAU Locus 2 RB junction sequence including 10 bp of flanking genomic DNA and bp 1-10 of SEQ ID NO: 308 (See Figure 96).
- SEQ ID NO:310 is the LBFDAU Locus 2 LB junction sequence including bp 37478-37487 of SEQ ID NO:308 and 10 bp of flanking genomic DNA (See Figure 96).
- SEQ ID NO:31 1 is the flanking sequence up to and including the right border of the T-DNA in LBFDAU Locus 2.
- Nucleotides 1 -1099 are genomic DNA (See Figure 96).
- SEQ ID NO:312 is the flanking sequence up to and including the left border of the T-DNA in LBFLFK Locus 2. Nucleotides 288-1321 are genomic DNA (See Figure 96). SEQ ID NO:313 is an LBFDAU locus 2_Forward primer suitable for identifying Locus 2 of LBFDAU events. A PCR amplicon using the combination of SEQ ID NO:313 and SEQ ID NO:314 is positive for the presence of LBFDAU locus 2.
- SEQ ID NO:314 is an LBFDAU locus 2_Reverse primer suitable for identifying Locus 2 of LBFDAU events.
- a PCR amplicon using the combination of SEQ ID NO:313 and SEQ ID NO:314 is positive for the presence of LBFDAU locus 2.
- SEQ ID NO:315 is an LBFDAU locus 2_Probe is a FAMTM -labeled synthetic oligonucleotide that when used in an amplification reaction with SEQ ID NO:313 and SEQ ID NO:314 will release a fluorescent signal when positive for the presence of LBFDAU Locus 2.
- SEQ ID NO:316 is a primer suitable for determining zygosity of LBFLFK Locus 1 . When used in combination with SEQ ID NO:317, production of a PCR amplicon of about 542bp is positive for presence of WT at LBFLFK Locus 1.
- SEQ ID NO:317 is a primer suitable for determining zygosity of LBFLFK Locus 1 .
- production of a PCR amplicon of about 542bp is positive for presence of WT at LBFLFK Locus 1.
- SEQ ID NO:318 is a primer suitable for determining zygosity of LBFLFK Locus 2.
- production of a PCR amplicon of about 712bp is positive for presence of WT at LBFLFK Locus 2.
- SEQ ID NO:319 is a primer suitable for determining zygosity of LBFLFK Locus 2.
- production of a PCR amplicon of about 712bp is positive for presence of WT at LBFLFK Locus 2.
- SEQ ID NO:320 is a primer suitable for determining zygosity of LBFDAU Locus 1 .
- production of a PCR amplicon of about 592bp is positive for presence of WT at LBFDAU Locus 1 .
- SEQ ID NO:321 is a primer suitable for determining zygosity of LBFDAU Locus 1 .
- production of a PCR amplicon of about 592bp is positive for presence of WT at LBFDAU Locus 1 .
- SEQ ID NO:322 is a primer suitable for determining zygosity of LBFDAU Locus 2.
- production of a PCR amplicon of about 247bp is positive for presence of WT at LBFDAU Locus 2.
- SEQ ID NO:323 is a primer suitable for determining zygosity of LBFDAU Locus 2. When used in combination with SEQ ID NO:322, production of a PCR amplicon of about 247bp is positive for presence of WT at LBFDAU Locus 2. DETAILED DESCRIPTION OF THE INVENTION (for the invention described in Section B only)
- the present invention is directed to transgenic Brassica events LBFLFK and LBFDAU, which are capable of producing oil comprising VLC-PUFAs, including EPA and DHA, for use as commodity products.
- Brassica plants of the invention have been modified by the insertion of the binary T-plasmid VC-LTM593-1 qcz rc (SEQ ID NO:279) described in Example B1 comprising, in order, polynucleotides encoding the following enzymes of the VLC-PUFA biosynthetic pathway: Delta-6 ELONGASE from Physcomitrella patens; Delta-5 DESA TURASE from Thraustochytrium sp.
- the VC-LTM593-1 qcz rc binary T-plasmid (SEQ ID NO:279) further comprises a polynucleotide encoding the selectable marker acetohydroxy acid synthase, which confers tolerance to imidazolinone herbicides.
- the invention further relates to the T-DNA insertions in each of Brassica events LBFLFK and LBFDAU, and to the genomic DNA/transgene insertions, i.e., the Locus 1 and Locus 2 junction regions found in Brassica plants or seeds comprising Brassica event LBFLFK, to the genomic DNA/transgene insertions, i.e., Locus 1 and Locus 2 junction regions found in Brassica plants or seeds comprising Brassica event LBFDAU, and the detection of the respective genomic DNA/transgene insertions, i.e., the respective Locus 1 and Locus 2 junction regions in Brassica plants or seed comprising event LBFLFK or event LBFDAU and progeny thereof.
- the genomic DNA/transgene insertions i.e., the Locus 1 and Locus 2 junction regions found in Brassica plants or seeds comprising Brassica event LBFLFK
- the genomic DNA/transgene insertions i.e., Locus 1 and Locu
- Brassica means any Brassica plant and includes all plant varieties that can be bred with Brassica.
- Brassica species include B. napus, B. rapa, B. juncea, B. oleracea, B. nigra, and B. carinata.
- the species of the LBFLFK and LBFDAU events and their progeny is B. napus.
- the term plant includes plant cells, plant organs, plant protoplasts, plant cell tissue cultures from which plants can be regenerated, plant calli, plant clumps and plant cells that are intact in plants or parts of plants such as embryos, pollen, ovules, seeds, leaves, flowers, branches, fruit, stalks, roots, root tips, anthers, and the like. Mature seed produced may be used for food, feed, fuel or other commercial or industrial purposes or for purposes of growing or reproducing the species. Progeny, variants and mutants of the regenerated plants are also included within the scope of the invention, provided that these parts comprise a LBFLFK or LBFDAU event.
- a transgenic "event” is produced by transformation of plant cells with a heterologous DNA construct(s) including a nucleic acid expression cassette that comprises one or more transgene(s) of interest, the regeneration of a population of plants from cells which each comprise the inserted transgene(s) and selection of a particular plant characterized by insertion into a particular genome location.
- An event is characterized phenotypically by the expression of the transgene(s).
- an event is part of the genetic makeup of a plant.
- the term "event” refers to the original transformant and progeny of the transformant that include the heterologous DNA.
- vent also refers to progeny, produced by a sexual outcross between the transformant and another variety, that include the heterologous DNA. Even after repeated back-crossing to a recurrent parent, the inserted DNA and flanking DNA from the transformed parent are present in the progeny of the cross at the same chromosomal location.
- the term “event” also refers to DNA from the original transformant comprising the inserted DNA and flanking sequence immediately adjacent to the inserted DNA that would be expected to be transferred to a progeny as the result of a sexual cross of one parental line that includes the inserted DNA (e.g., the original transformant and progeny resulting from selfing) and a parental line that does not contain the inserted DNA.
- progeny of the Brassica LBFLFK event may comprise either LBFLFK Locus 1 or LBFLFK Locus 2, or both LBFLFK Locus 1 and LBFLFK Locus 2.
- progeny of the Brassica LBFDAU event may comprise either LBFDAU Locus 1 or LBFDAU Locus 2, or both LBFDAU Locus 1 and LBFDAU Locus 2.
- insert DNA refers to the heterologous DNA within the expression cassettes used to transform the plant material while “flanking DNA” can comprise either genomic DNA naturally present in an organism such as a plant, or foreign (heterologous) DNA introduced via the transformation process which is extraneous to the original insert DNA molecule, e.g. fragments associated with the transformation event.
- a "flanking region” or “flanking sequence” as used herein refers to a sequence of at least 20, 50, 100, 200, 300, 400, 1000, 1500, 2000, 2500 or 5000 base pairs or greater which is located either immediately upstream of and contiguous with, or immediately downstream of and contiguous with, the original foreign insert DNA molecule.
- flanking regions of the LBFLFK event comprise, for Locus 1 , nucleotides 1 to 570 of SEQ ID NO: 284, nucleotides 229 to 81 1 of SEQ ID NO:285 and for Locus 2, nucleotides 1 to 2468 of SEQ ID NO:293, and/or nucleotides 242 to 1800 of SEQ ID NO:294 and variants and fragments thereof.
- flanking regions of the LBFDAU event comprise, for Locus 1 , nucleotides 1 to 1017 of SEQ ID NO: 302, nucleotides 637 to 1677 of SEQ ID NO:303, and for Locus 2, nucleotides 1 to 1099 of SEQ ID NO:31 1 and/or nucleotides 288 to 1321 of SEQ ID NO: 312 and variants and fragments thereof.
- Transformants will also contain unique junctions between a piece of heterologous insert DNA and genomic DNA or two pieces of genomic DNA or two pieces of heterologous DNA.
- a "junction point” is a point where two specific DNA fragments join. For example, a junction point exists where insert DNA joins flanking DNA.
- a junction point also exists in a transformed organism where two DNA fragments join together in a manner that is modified from that found in the native organism.
- junction DNA or "junction region” refers to DNA that comprises a junction point.
- junction DNA from the LBFLFK event comprise, for Locus 1 , SEQ ID NO:282, SEQ ID NO:283, and for Locus 2, SEQ ID NO:291 , and/or SEQ ID NO:292, complements thereof, or variants and fragments thereof.
- junction DNA from the LBFDAU event comprise, for Locus 1 , SEQ ID NO:300, SEQ ID NO:301 , and for Locus 2, SEQ ID NO:309 and/or SEQ ID NO:310, complements thereof, or variants and fragments thereof.
- breeding refers to an individual, a group of individuals or a clone representing a genotype, variety, species or culture or the genetic material thereof.
- a "line” or “strain” is a group of individuals of identical parentage that are generally inbred to some degree and that are generally isogenic or near isogenic. Inbred lines tend to be highly homogeneous, homozygous and reproducible. Many analytical methods are available to determine the homozygosity and phenotypic stability of inbred lines.
- hybrid plants refers to plants which result from a cross between genetically different individuals.
- crossed or “cross” in the context of this invention means the fusion of gametes, e.g., via pollination to produce progeny (i.e., cells, seeds, or plants) in the case of plants.
- the term encompasses both sexual crosses (the pollination of one plant by another) and, in the case of plants, selfing (self-pollination, i.e., when the pollen and ovule are from the same plant).
- introduction refers to the transmission of a desired allele of a genetic locus from one genetic background to another. In one method, the desired alleles can be introgressed through a sexual cross between two parents, wherein at least one of the parents has the desired allele in its genome.
- polynucleotide refers to a deoxyribonucleic acid or ribonucleic acid. Unless stated otherwise, "polynucleotide” herein refers to a single strand of a DNA polynucleotide or to a double stranded DNA polynucleotide.
- the length of a polynucleotide is designated according to the invention by the specification of a number of base pairs ("bp") or nucleotides ("nt"). According to the invention, both designations are used interchangeably for single or double stranded nucleic acids.
- nucleotide/polynucleotide and nucleotide sequence/polynucleotide sequence are used interchangeably, so that a reference to a nucleic acid sequence also is meant to define a nucleic acid comprising or consisting of a nucleic acid stretch the sequence of which is identical to the nucleic acid sequence.
- an "isolated DNA molecule” is an artificial polynucleotide corresponding to all or part of a flanking region, junction region, transgenic insert, amplicon, primer or probe that is unique to Brassica event LBFLFK or Brassica event LBFDAU, and which is not contained within the genome of Brassica event LBFLFK or the genome of Brassica event LBFDAU.
- Such isolated DNA molecules may be derived from the VC-LTM593-1 qcz rc plasmid used to produce the LBFLFK and LBFDAU events, or from the genome of Brassica event LBFLFK or Brassica event LBFDAU, or from tissues, seeds, progeny, cells, plant organs, biological samples or commodity products derived from Brassica event LBFLFK or Brassica event LBFDAU.
- Such isolated DNA molecules can be extracted from cells, or tissues, or homogenates from a plant or seed or plant organ; or can be produced as an amplicon from extracted DNA or RNA from cells, or tissues, or homogenate from a plant or seed or plant organ, any of which is derived from Brassica event LBFLFK or Brassica event LBFDAU, or progeny, biological samples or commodity products derived therefrom.
- a “probe” is an isolated nucleic acid to which is attached a conventional detectable label or reporter molecule, e.g., a radioactive isotope, ligand, chemiluminescent agent, or enzyme.
- a probe is complementary to a strand of a target nucleic acid, in the case of the present invention, to a strand of genomic DNA from Brassica event LBFLFK or Brassica event LBFDAU, whether from a Brassica plant or from a sample that includes DNA from the event.
- Probes according to the present invention include not only deoxyribonucleic or ribonucleic acids but also polyamides and other probe materials that bind specifically to a target DNA sequence and such binding can be used to detect the presence of that target DNA sequence.
- Primers are isolated nucleic acids that can specifically anneal to a complementary target DNA strand by nucleic acid hybridization to form a hybrid between the primer and the target DNA strand, and then can be extended along the target DNA strand by a polymerase, e.g., a DNA polymerase.
- a primer pair or primer set of the present invention refers to two different primers that together are useful for amplification of a target nucleic acid sequence, e.g., by the polymerase chain reaction (PCR) or other conventional nucleic-acid amplification methods.
- PCR polymerase chain reaction
- Probes and primers are generally 1 1 nucleotides or more in length, preferably 18 nucleotides or more, more preferably 24 nucleotides or more, and most preferably 30 nucleotides or more. Such probes and primers hybridize specifically to a target sequence under high stringency hybridization conditions. Preferably, probes and primers according to the present invention have complete sequence similarity with the target sequence, although probes differing from the target sequence and that retain the ability to hybridize to target sequences may be designed by conventional methods. Primers, primer pairs, or probes, may be produced by nucleotide synthesis, cloning, amplification, or other standard methods for producing a polynucleotide molecule.
- one or more primer or probe sequences specific for target sequences in event LBFLFK Locus 1 , LBFLFK Locus 2, LBFDAU Locus 1 , and LBFDAU Locus 2, or complementary sequences thereto may be selected using this disclosure and methods known in the art, for instance, via in silico analysis as described in Wojciech and Rhoads, NAR 17:8543-8551 , 1989.
- the term "specific for (a target sequence)" indicates that a probe or primer hybridizes under stringent hybridization conditions only to the target sequence in a sample comprising the target sequence.
- amplified DNA refers to the product of nucleic-acid amplification of a target nucleic acid sequence that is part of a nucleic acid template.
- the amplicon is of a length and has a sequence that is also diagnostic for the event.
- An amplicon may be of any length, and may range in length, for example, from the combined length of the primer pairs plus one nucleotide base pair, or the length of the primer pairs plus about fifty nucleotide base pairs, or the length of the primer pairs plus about two hundred nucleotide base pairs, the length of the primer pairs plus about five hundred nucleotide base pairs, or the length of the primer pairs plus about seven hundred fifty nucleotide base pairs, and the like.
- a primer pair can be derived from flanking sequence on both sides of the inserted DNA so as to produce an amplicon that includes the entire insert nucleotide sequence.
- a primer pair can be derived from flanking sequence on one side of an insert and sequence within the insert.
- a member of a primer pair derived from the plant genomic sequence may be located a distance from the inserted DNA molecule, and this distance can range from one nucleotide base pair up to about twenty thousand nucleotide base pairs.
- the use of the term "amplicon" specifically excludes primer-dimers that may be formed in the DNA thermal amplification reaction.
- a “commodity product” refers to any product which is comprised of material derived from Brassica or Brassica oil and is sold to consumers.
- polyunsaturated fatty acids refers to fatty acids comprising at least two, preferably, three, four, five or six, double bonds. Moreover, it is to be understood that such fatty acids comprise, preferably from 18 to 24 carbon atoms in the fatty acid chain. In accordance with the invention, the term relates to long chain PUFA (VLC-PUFA) having from 20 to 24 carbon atoms in the fatty acid chain.
- VLC-PUFA long chain PUFA
- the VLC-PUFA produced by the LBFLFK and LBFDAU events and their progeny include DHGLA, ARA, ETA, EPA, DPA, DHA. More preferably, the VLC-PUFA produced by the LBFLFK and LBFDAU events and their progeny include ARA, EPA, and DHA. Most preferably, the VLC-PUFA produced by the LBFLFK and LBFDAU events and their progeny include EPA and/or DHA. Moreover, the LBFLFK and LBFDAU events and their progeny also produce intermediates of VLC-PUFA which occur during synthesis.
- Such intermediates may be formed from substrates by the desaturase, keto-acyl-CoA-synthase, keto-acyl-CoA-reductase, dehydratase and enoyl-CoA-reductase activity of the polypeptides of the present invention.
- substrates may include LA, GLA, DHGLA, ARA, eicosadienoic acid, ETA, and EPA.
- the transgenic Brassica plants of the invention comprise event LBFLFK (ATCC designation PTA-121703). Seed and progeny of event LBFLFK are also encompassed in this embodiment.
- the transgenic Brassica plants of the invention comprise event LBFDAU (ATCC designation PTA-122340). Seed and progeny of event LBFDAU are also encompassed in this embodiment.
- Brassica event LBFLFK (ATCC designation PTA-121703) and Brassica event LBFDAU (ATCC designation PTA-122340) have been deposited by applicant(s) at the American Type Culture Collection, Manassas, VA, USA, under the provisions of the Budapest Treaty on the International Recognition of the Deposit of Microorganisms for the Purposes of Patent Procedure.
- Applicants have no authority to waive any restrictions imposed by law on the transfer of biological material or its transportation in commerce. Applicants do not waive any infringement of their rights granted under this patent or rights applicable to the deposited events under the Plant Variety Protection Act (7 USC sec. 2321 , et seq.), Unauthorized seed multiplication prohibited. This seed may be regulated according to national law.
- the deposition of seeds was made only for convenience of the person skilled in the art and does not constitute or imply any confession, admission, declaration or assertion that deposited seed are required to fully describe the invention, to fully enable the invention or for carrying out the invention or any part or aspect thereof.
- the Brassica plants LBFLFK and LBFDAU can be used to manufacture commodities typically acquired from Brassica. Seeds of LBFLFK and LBFDAU can be processed into meal or oil as well as be used as an oil source in animal feeds for both terrestrial and aquatic animals.
- the VLC- PUFA-containing oil from events LBFLFK and LBFDAU may be used, for example, as a food additive to increase ⁇ -3 fatty acid intake in humans and animals, or in pharmaceutical compositions to enhance therapeutic effects thereof, or as a component of cosmetic compositions, and the like.
- An LBFLFK or LBFDAU plant can be bred by first sexually crossing a first parental Brassica plant grown from the transgenic LBFLFK or LBFDAU Brassica plant (or progeny thereof) and a second parental Brassica plant that lacks the EPA/DHA profile and imidazolinone tolerance of the LBFLFK or LBFDau event, respectively, thereby producing a plurality of first progeny plants and then selecting a first progeny plant that displays the desired imidazolinone tolerance and selfing the first progeny plant, thereby producing a plurality of second progeny plants and then selecting from the second progeny plants which display the desired imidazolinone tolerance and EPA/DHA profile.
- steps can further include the back-crossing of the first EPA/DHA producing progeny plant or the second EPA/DHA producing progeny plant to the second parental Brassica plant or a third parental Brassica plant, thereby producing a Brassica plant that displays the desired imidazolinone tolerance and EPA/DHA profile. It is further recognized that assaying progeny for phenotype is not required.
- Various methods and compositions, as disclosed elsewhere herein, can be used to detect and/or identify the LBFLFK or LBFDAU event.
- Two different transgenic plants can also be sexually crossed to produce offspring that contain two independently-segregating exogenous genes. Selfing of appropriate progeny can produce plants that are homozygous for both exogenous transgenic inserts.
- the LBFLFK Locus 1 genomic DNA/transgene junction region and/or the LBFLFK Locus 2 genomic DNA/transgene junction region is present in Brassica plant LBFLFK (ATCC Accession No. PTA-121703) and progeny thereof.
- the LBFLFK Locus 1 DNA/transgene right border junction region comprises SEQ ID NO:282 and the LBFLFK Locus 1 left border junction region comprises SEQ ID NO:283, and the LBFLFK Locus 2 right border junction region comprises SEQ ID NO:291 and the LBFLFK left border junction region comprises SEQ ID NO:292.
- DNA sequences are provided that comprise at least one junction region sequence of event LBFLFK selected from the group consisting of SEQ ID NO:282 corresponding to positions 561 through 580 of SEQ ID NO:280 as shown in FIG. 93); SEQ ID NO:283 corresponding to positions 44318 through 44337 of SEQ ID NO:280 , as shown in FIG. 93); SEQ ID NO:291 corresponding to positions 2459 through 2478 of SEQ ID NO:289 as shown in FIG. 94); and SEQ ID NO:292 corresponding to positions 46232 through 46251 of SEQ ID NO:289, as shown in FIG.
- a Brassica event LBFLFK and Brassica seed comprising these DNA molecules is an aspect of this invention.
- DNA extracted from a Brassica plant tissue sample may be subjected to nucleic acid amplification method using (i) a first primer pair that includes: (a) a first primer derived from an LBFLFK Locus 1 flanking sequence and (b) a second primer derived from the LBFLFK Locus 1 inserted heterologous DNA, wherein amplification of the first and second primers produces an amplicon that is diagnostic for the presence of event LBFLFK Locus 1 DNA; and (ii) a second primer pair that includes (a) a third primer derived from an LBFLFK Locus 2 flanking sequence and (b) a fourth primer derived from the LBFLFK Locus 2 inserted heterologous DNA, wherein amplification of the third and fourth primers produces an amplicon that is diagnostic for the presence of event LBFLFK Locus 2 DNA.
- a first primer pair that includes: (a) a first primer derived from an LBFLFK Locus 1 flanking sequence and (b) a
- the primer DNA molecules specific for target sequences in Brassica event LBFLFK comprise at least 1 1 contiguous nucleotides of any portion of the insert DNAs, flanking regions, and/or junction regions of LBFLFK Locus 1 and Locus 2.
- LBFLFK Locus 1 primer DNA molecules may be derived from any of SEQ ID NO:280, SEQ ID NO:281 , SEQ ID NO:282, or SEQ ID NO:283; SEQ ID NO:284, or SEQ ID NO:285, or complements thereof, to detect LBFLFK Locus 1 .
- LBFLFK Locus 2 primer DNA molecules may be derived from any of SEQ ID NO:293, SEQ ID NO:294, SEQ ID NO:291 , or SEQ ID NO:292; SEQ ID NO:290, or SEQ ID NO:289, or complements thereof, to detect LBFLFK Locus 2.
- the LBFLFK Locus 1 and Locus 2 amplicons produced using these DNA primers in the DNA amplification method are diagnostic for Brassica event LBFLFK when the amplification product contains an amplicon comprising an LBFLFK Locus 1 junction region SEQ ID NO:282 or SEQ ID NO:283, or complements thereof, and an amplicon comprising an LBFLFK Locus 2 junction region SEQ ID NO:291 , or SEQ ID NO:292, or complements thereof.
- Any LBFLFK amplicon produced by DNA primers homologous or complementary to any portion of SEQ ID NO:280 or SEQ ID NO:289, or complements thereof, is an aspect of the invention.
- Any amplicon that comprises SEQ ID NO:282 or SEQ ID NO:283 SEQ ID NO:291 , or SEQ ID NO:292, or complements thereof, is an aspect of the invention.
- methods of detecting the presence of DNA corresponding to the Brassica event LBFLFK in a sample comprise the steps of: (a) contacting the sample comprising DNA with an LBFLFK Locus 1 primer pair and an LBFLFK Locus 2 primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFLFK, produces a Locus 1 amplicon and a Locus 2 amplicon that are diagnostic for Brassica event LBFLFK; (b) performing a nucleic acid amplification reaction, thereby producing the Locus 1 and Locus 2 amplicons; and (c) detecting the amplicons, wherein one amplicon comprises the LBFLFK Locus 1 junction region SEQ ID NO:282 or SEQ ID NO:283, or the complements thereof, and one amplicon comprises the LBFLFK Locus 2 junction region SEQ ID NO:291 or SEQ ID NO:292, or the complements thereof.
- the method of detecting the presence of DNA corresponding to the Brassica event LBFLFK in a sample may alternatively comprise the steps of: (a) contacting the sample comprising DNA with a primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFLFK, produces a Locus 1 amplicon that is diagnostic for Brassica event LBFLFK; (b) performing a nucleic acid amplification reaction, thereby producing the amplicon; and (c) detecting the amplicon, wherein the amplicon comprises the LBFLFK Locus 1 junction region SEQ ID NO:282 or SEQ ID NO:283, or the complement thereof.
- the probe of SEQ ID NO:288 may be used to detect an LBFLFK Locus 1 amplicon.
- the method of detecting the presence of DNA corresponding to the Brassica event LBFLFK in a sample may alternatively comprise the steps of: (a) contacting the sample comprising DNA with a primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFLFK, produces a Locus 2 amplicon that is diagnostic for Brassica event LBFLFK; (b) performing a nucleic acid amplification reaction, thereby producing the amplicon; and (c) detecting the amplicon, wherein the amplicon comprises the LBFLFK Locus 2 junction region SEQ ID NO:291 or SEQ ID NO:292, or the complement thereof.
- the probe of SEQ ID NO:297 may be used to detect an LBFLFK Locus 2 amplicon. According to another aspect of the invention, methods are provided for detecting the presence of a DNA corresponding to LBFLFK event Locus 1 in a sample.
- the method comprises the steps of: (a) contacting the sample comprising DNA with a probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 1 of Brassica event LBFLFK and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probe to the Brassica event LBFLFK DNA, wherein said probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:2 or the complement thereof.
- An exemplary probe for detecting LBFLFK Locus 1 is represented as SEQ ID NO:288.
- the invention is also embodied in methods of detecting the presence of a DNA corresponding to LBFLFK event Locus 2 in a sample.
- the method comprises the steps of: (a) contacting the sample comprising DNA with a probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 2 of Brassica event LBFLFK and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probe to the Brassica event LBFLFK DNA, wherein said probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:289 or the complement thereof.
- An exemplary probe for detecting LBFLFK Locus 2 is represented as SEQ ID NO:297.
- the methods for detecting Brassica event LBFLFK also encompass detecting Brassica event LBFLFK Locus 1 and Locus 2 in a single assay.
- the method comprises the steps of: (a) contacting the sample comprising DNA with a first probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 1 of Brassica event LBFLFK and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant and a second probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 2 of Brassica event LBFLFK and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probes to the Brassica event LBFLFK Locus 1 DNA and Locus 2 DNA, wherein said first probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:280 or the complement thereof and said second probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:289 or the complement thereof.
- Another aspect of the invention is a method of determining zygosity of the progeny of Brassica event LBFLFK, the method comprising performing the steps above for detecting LBFLFK Locus 1 and LBFLFK Locus 2, and performing the additional steps of: (d) contacting the sample comprising Brassica DNA with an LBFLFK wild type primer pair comprising at least 1 1 nucleotides of the Brassica genomic region of the LBFLFK Locus 1 transgene insertion and and LBFLFK Locus 2 wild type primer pair comprising at least 1 1 consecutive nucleotides of the Brassica genomic region of the LBFLFK Locus 2 transgene insertion, that when used in a nucleic acid amplification reaction with genomic DNA from wild type Brassica plants corresponding to the LBFLFK Locus 1 and/or LBFLFK Locus 2 transgene insertion region(s), produces amplicons that are diagnostic of the wild type Brassica genomic DNA homologous to the Brassica genomic region of the LBFLFK Lo
- the zygosity detection method of the invention may employ any of the primers and probes described above which are specific for event LBFLFK Locus 1 and/or Locus 2.
- Exemplary primers for detection of wild type Brassica genomic DNA at the LBFLFK Locus 1 insertion site may be derived from SEQ ID NO:316 and SEQ ID NO:317, and suitable wild type Locus 1 probes may be designed from the wild type Brassica genomic sequence produced through amplification of SEQ ID NO:316 and SEQ ID NO:317.
- Exemplary primers for detection of wild type Brassica genomic DNA at the LBFLFK Locus 2 insertion site may be derived from SEQ ID NO:318 and SEQ ID NO:319, and suitable wild type Locus 2 probes may be designed from the wild type Brassica genomic sequence produced through amplification of SEQ ID NO:318 and SEQ ID NO:319.
- Kits for the detection of Brassica event LBFLFK are provided which use primers designed from SEQ ID NO:280 and SEQ ID NO:289, or the complements thereof.
- An amplicon produced using said kit is diagnostic for LBFLFK when the amplicon (1 ) contains either nucleotide sequences set forth as SEQ ID NO:282, or SEQ ID NO:283, or complements thereof, and/or an amplicon comprising the Locus 2 junction region SEQ ID NO:291 , or SEQ ID NO:292, or complements thereof.
- the LBFDAU Locus 1 genomic DNA/transgene junction region and/or the LBFDAU Locus 2 genomic DNA/transgene junction region is present in Brassica event LBFDAU (ATCC Accession No. PTA-122340) and progeny thereof.
- the LBFDAU Locus 1 DNA/transgene right border junction region comprises SEQ ID NO:300 and the LBFDAU Locus 1 left border junction region comprises SEQ ID NO:301
- the LBFDAU Locus 2 right border junction region comprises SEQ ID NO:309 and the LBFDAU left border junction region comprises SEQ ID NO:310.
- DNA sequences are provided that comprise at least one junction region sequence of event LBFDAU selected from the group consisting of SEQ ID NO:300 (corresponding to positions 1008 through 1027 of SEQ ID NO:298, as shown in FIG. 95); SEQ ID NO:301 (corresponding to positions 44728 through 44747 of SEQ ID NO:298, as shown in FIG. 95); SEQ ID NO:309 (corresponding to positions 1090 through 1 109 of SEQ ID NO:307, as shown in FIG. 96); and SEQ ID NO:310 (corresponding to positions 38577 through 38596 of SEQ ID NO:307, as shown in FIG.
- a Brassica event LBFDAU and Brassica seed comprising these DNA molecules is an aspect of this invention.
- DNA extracted from a Brassica plant tissue sample may be subjected to nucleic acid amplification method using (i) a first primer pair that includes: (a) a first primer derived from an LBFDAU Locus 1 flanking sequence and (b) a second primer derived from the LBFDAU Locus 1 inserted heterologous DNA, wherein amplification of the first and second primers produces an amplicon that is diagnostic for the presence of event LBFDAU Locus 1 DNA; and/or (ii) a second primer pair that includes (a) a third primer derived from an LBFDAU Locus 2 flanking sequence and (b) a fourth primer derived from the LBFDAU Locus 2 inserted heterologous DNA, wherein amplification of the third and fourth primers produces an amplicon that is diagnostic for the presence of event LBFDAU Locus 2 DNA.
- a first primer pair that includes: (a) a first primer derived from an LBFDAU Locus 1 flanking sequence and (b)
- primer DNA molecules specific for target sequences in Brassica event LBFDAU comprise 1 1 or more contiguous nucleotides of any portion of the insert DNAs, flanking regions, and/or junction regions of LBFDAU Locus 1 and Locus 2.
- primer DNA molecules may be derived from any of SEQ ID NO:298, SEQ ID NO:299, SEQ ID NO:300, or SEQ ID NO:301 ;SEQ ID NO:302, or SEQ ID NO:303, or complements thereof, to detect LBFDAU Locus 1 .
- primer DNA molecules may be derived from any of SEQ ID NO:307, SEQ ID NO:308, SEQ ID NO:309, or SEQ ID NO:310; SEQ ID NO:31 1 , or SEQ ID NO:312, or complements thereof, to detect LBFDAU Locus 2.
- LBFDAU Locus 1 and Locus 2 amplicons produced using these DNA primers in the DNA amplification method is diagnostic for Brassica event LBFDAU when the amplification product contains an amplicon comprising the LBFDAU Locus 1 junction region SEQ ID NO:300 or SEQ ID NO:301 and/or an amplicon comprising the LBFDAU Locus 2 junction region SEQ ID NO:309, or SEQ ID NO:310.
- Any LBFDAU amplicon produced by DNA primers homologous or complementary to any portion of SEQ ID NO:298 or SEQ ID NO:307, or complements thereof, is an aspect of the invention.
- Any amplicon that comprises the LBFDAU Locus 1 junction region SEQ ID NO:300, or SEQ ID NO:301 , or complements thereof, and any amplicon comprising the LBFDAU Locus 2 junction region SEQ ID NO:309, or SEQ ID NO:310, or complements thereof, is an aspect of the invention.
- methods of detecting the presence of DNA corresponding to the Brassica event LBFDAU in a sample comprise: (a) contacting the sample comprising DNA with an LBFDAU Locus 1 primer pair and an LBFDAU Locus 2 primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFDAU, produces a Locus 1 amplicon and a Locus 2 amplicon that are diagnostic for Brassica event LBFDAU; (b) performing a nucleic acid amplification reaction, thereby producing the amplicons; and (c) detecting the amplicons, wherein one amplicon comprises the LBFDAU Locus 1 junction region SEQ ID NO:300 or SEQ ID NO:301 , or complements thereof, and one amplicon comprises the Locus 2 junction region SEQ ID NO:309 or SEQ ID NO:310, or complements thereof.
- the method of detecting the presence of DNA corresponding to the Brassica event LBFDAU in a sample may alternatively comprise the steps of: (a) contacting the sample comprising DNA with a primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFDAU, produces a Locus 1 amplicon that is diagnostic for Brassica event LBFDAU; (b) performing a nucleic acid amplification reaction, thereby producing the amplicon; and (c) detecting the amplicon, wherein the amplicon comprises the LBFDAU Locus 1 junction region SEQ ID NO:300 or SEQ ID NO:301 , or a complement thereof.
- the probe of SEQ ID NO:306 may be used to detect an LBFDAU Locus 1 amplicon.
- the method of detecting the presence of DNA corresponding to the Brassica event LBFDAU in a sample may alternatively comprise the steps of: (a) contacting the sample comprising DNA with a primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFDAU, produces a Locus 2 amplicon that is diagnostic for Brassica event LBFDAU; (b) performing a nucleic acid amplification reaction, thereby producing the amplicon; and (c) detecting the amplicon, wherein the amplicon comprises the LBFDAU Locus 2 junction region SEQ ID NO:309 or SEQ ID NO:310, or a complement thereof.
- the probe of SEQ ID NO:315 may be used to detect an LBFDAU Locus 2 amplicon.
- the method comprises the steps of: (a) contacting the sample comprising DNA with a probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 1 of Brassica event LBFDAU and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probe to the Brassica event LBFDAU DNA, wherein said probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:298, or the complement thereof.
- An exemplary probe for detecting LBFDAU Locus 1 is represented as SEQ ID NO:306.
- the invention is also embodied in methods of detecting the presence of a DNA corresponding to LBFDAU event Locus 2 in a sample.
- the method comprises the steps of: (a) contacting the sample comprising DNA with a probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 2 of Brassica event LBFDAU and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probe to the Brassica event LBFDAU DNA, wherein said probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:307, or the complement thereof.
- An exemplary probe for detecting LBFLFK Locus 2 is represented as SEQ ID NO:315.
- the methods for detecting Brassica event LBFDAU also encompass detecting Brassica event LBFDAU Locus 1 and Locus 2 in a single assay.
- the method comprises the steps of: (a) contacting the sample comprising DNA with a first probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 1 of Brassica event LBFDAU and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant and a second probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 2 of Brassica event LBFDAU and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probes to the Brassica event LBFDAU Locus 1 DNA and Locus 2 DNA, wherein said first probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:298 or the complement thereof and said second
- Another aspect of the invention is a method of determining zygosity of the progeny of Brassica event LBFDAU, the method comprising performing the steps above for detecting LBFDAU Locus 1 and LBFDAU Locus 2, and performing the additional steps of: (d) contacting the sample comprising Brassica DNA with an LBFDAU Locus 1 wild type primer pair comprising at least 1 1 consecutive nucleotides of the Brassica genomic region of the LBFDAU Locus 1 transgene insertion and an LBFDAU Locus 2 wild type primer pair comprising at least 1 1 consecutive nucleotides of the Brassica genomic region of the LBFDAU Locus 2 transgene insertion that when used in a nucleic acid amplification reaction with genomic DNA from wild type Brassica plants produces a second amplicon corresponding to the LBFDAU Locus 1 and/or LBFDAU Locus 2 transgene insertion region(s); (e) performing a nucleic acid amplification reaction, thereby producing the second
- the zygosity detection method of the invention may employ any of the primers and probes described above which are specific for event LBFDAU Locus 1 and/or Locus 2.
- Exemplary primers for detection of wild type Brassica genomic DNA at the LBFDAU Locus 1 insertion site may be derived from SEQ ID NO:320 and SEQ ID NO:321 , or the complements thereof and suitable wild type Locus 1 probes may be designed from the wild type Brassica genomic sequence produced through amplification of SEQ ID NO:320 and SEQ ID NO:321 .
- Exemplary primers for detection of wild type Brassica genomic DNA at the LBFDAU Locus 2 insertion site may be derived from SEQ ID NO:322 and SEQ ID NO:323, and suitable wild type Locus 2 probes may be designed from the wild type Brassica genomic sequence produced through amplification of SEQ ID NO:322 and SEQ ID NO:323.
- Kits for the detection of Brassica event LBFDAU are provided which use primers designed from SEQ ID NO:298 and SEQ ID NO:307, or the complements thereof.
- An amplicon produced using said kit is diagnostic for LBFDAU when the amplicon (1 ) contains either nucleotide sequences set forth as SEQ ID NO:300 or SEQ ID NO:301 , or the complements thereof, and an amplicon comprising the Locus 2 junction region SEQ ID NO:309 or SEQ ID NO:310, or the complements thereof.
- PCR-primer pairs can be derived from a known sequence, for example, by using computer programs intended for that purpose such as Primer (Version 0.5, .COPYRGT. 1991 , Whitehead Institute for Biomedical Research, Cambridge, Mass.). Primers and probes based on the flanking DNA and insert sequences disclosed herein can be used to confirm (and, if necessary, to correct) the disclosed sequences by conventional methods, e.g., by re-cloning and sequencing such sequences.
- nucleic acid probes and primers of the present invention hybridize under stringent conditions to a target DNA sequence. Any conventional nucleic acid hybridization or amplification method can be used to identify the presence of DNA from a transgenic event in a sample.
- Nucleic acid molecules or fragments thereof are capable of specifically hybridizing to other nucleic acid molecules under certain circumstances. As used herein, two nucleic acid molecules are said to be capable of specifically hybridizing to one another if the two molecules are capable of forming an anti-parallel, double-stranded nucleic acid structure.
- a nucleic acid molecule is said to be the "complement" of another nucleic acid molecule if they exhibit complete complementarity.
- molecules are said to exhibit "complete complementarity" when every nucleotide of one of the molecules is complementary to a nucleotide of the other.
- Two molecules are said to be “minimally complementary” if they can hybridize to one another with sufficient stability to permit them to remain annealed to one another under at least conventional "low-stringency” conditions.
- the molecules are said to be “complementary” if they can hybridize to one another with sufficient stability to permit them to remain annealed to one another under conventional "high- stringency” conditions.
- Conventional stringency conditions are described by Sambrook et al., 1989, and by Haymes et al., In: Nucleic Acid Hybridization, A Practical Approach, IRL Press, Washington, D.C.
- nucleic acid molecule In order for a nucleic acid molecule to serve as a primer or probe it need only be sufficiently complementary in sequence to be able to form a stable double-stranded structure under the particular solvent and salt concentrations employed.
- nucleic-acid amplification can be accomplished by any of the various nucleic-acid amplification methods known in the art, including the polymerase chain reaction (PCR). A variety of amplification methods are known in the art and are described, inter alia, in U.S. Pat. Nos.
- PCR amplification methods have been developed to amplify up to 22 kb of genomic DNA and up to 42 kb of bacteriophage DNA (Cheng et al., Proc. Natl. Acad. Sci. USA 91 :5695-5699, 1994). These methods as well as other methods known in the art of DNA amplification may be used in the practice of the present invention.
- the sequence of the heterologous DNA insert or flanking sequence from a plant or seed tissue comprising Brassica event LBFLFK or Brassica event LBFDAU can be verified (and corrected if necessary) by amplifying such sequences from the event using primers derived from the sequences provided herein followed by standard DNA sequencing of the PCR amplicon or of the cloned DNA.
- the amplicon produced by these methods may be detected by a plurality of techniques.
- One such method is Genetic Bit Analysis (e.g. Nikiforov, et al. Nucleic Acid Res. 22:4167-4175, 1994) where an DNA oligonucleotide is designed which overlaps both the adjacent flanking genomic DNA sequence and the inserted DNA sequence.
- the oligonucleotide is immobilized in wells of a microwell plate. Following PCR of the region of interest (using one primer in the inserted sequence and one in the adjacent flanking genomic sequence), a single-stranded PCR product can be hybridized to the immobilized oligonucleotide and serve as a template for a single base extension reaction using a DNA polymerase and labelled ddNTPs specific for the expected next base. Readout may be fluorescent or ELISA-based. A signal indicates presence of the insert/flanking sequence due to successful amplification, hybridization, and single base extension.
- oligonucleotide is designed that overlaps the adjacent genomic DNA and insert DNA junction.
- the oligonucleotide is hybridized to single-stranded PCR product from the region of interest (one primer in the inserted sequence and one in the flanking genomic sequence) and incubated in the presence of a DNA polymerase, ATP, sulfurylase, luciferase, apyrase, adenosine 5' phosphosulfate and luciferin.
- dNTPs are added individually and the incorporation results in a light signal which is measured.
- a light signal indicates the presence of the transgene insert/flanking sequence due to successful amplification, hybridization, and single or multi-base extension.
- Fluorescence Polarization as described by Chen, et al., (Genome Res. 9:492-498, 1999) is a method that can be used to detect the amplicon of the present invention. Using this method an oligonucleotide is designed which overlaps the genomic flanking and inserted DNA junction. The oligonucleotide is hybridized to single-stranded PCR product from the region of interest (one primer in the inserted DNA and one in the flanking genomic DNA sequence) and incubated in the presence of a DNA polymerase and a fluorescent-labeled ddNTP.
- Single base extension results in incorporation of the ddNTP. Incorporation can be measured as a change in polarization using a fluorometer. A change in polarization indicates the presence of the transgene insert/flanking sequence due to successful amplification, hybridization, and single base extension.
- TaqMan.RTM (PE Applied Biosystems, Foster City, Calif.) is described as a method of detecting and quantifying the presence of a DNA sequence and is fully understood in the instructions provided by the manufacturer. Briefly, a FRET oligonucleotide probe is designed which overlaps the genomic flanking and insert DNA junction.
- the FRET probe and PCR primers (one primer in the insert DNA sequence and one in the flanking genomic sequence) are cycled in the presence of a thermostable polymerase and dNTPs. Hybridization of the FRET probe results in cleavage and release of the fluorescent moiety away from the quenching moiety on the FRET probe.
- a fluorescent signal indicates the presence of the flanking/transgene insert sequence due to successful amplification and hybridization.
- Molecular Beacons have been described for use in sequence detection as described in Tyangi, et al. (Nature Biotech. 14:303-308, 1996) Briefly, a FRET oligonucleotide probe is designed that overlaps the flanking genomic and insert DNA junction. The unique structure of the FRET probe results in it containing secondary structure that keeps the fluorescent and quenching moieties in close proximity.
- the FRET probe and PCR primers are cycled in the presence of a thermostable polymerase and dNTPs.
- hybridization of the FRET probe to the target sequence results in the removal of the probe secondary structure and spatial separation of the fluorescent and quenching moieties that results in the production of a fluorescent signal.
- the fluorescent signal indicates the presence of the flanking/transgene insert sequence due to successful amplification and hybridization.
- microfluidics US Patent Pub. 2006068398, U.S. Pat. No. 6,544,734.
- Optical dyes are used to detect and quantitate specific DNA molecules (WO/05017181 ).
- Nanotube devices (WO/06024023) that comprise an electronic sensor for the detection of DNA molecules or nanobeads that bind specific DNA molecules and can then be detected.
- Seed derived from Brassica event LBFLFK or Brassica event LBFDAU for sale for planting or for making commodity products is an aspect of the invention.
- Such commodity products include canola oil or meal containing VLC-PUFAs including but not limited to EPA and DHA.
- Commodity products derived from Brassica event LBFLFK comprise a detectable amount a DNA molecule comprising SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and/or SEQ ID NO:292.
- Commodity products derived from Brassica event LBFDAU comprise a detectable amount a DNA molecule comprising SEQ ID NO:300, SEQ ID NO:301 , SEQ ID NO:309, and/or SEQ ID NO:310.
- Exemplary commodity products derived from events LBFLFK and LBFDAU include, but are not limited to, cooking oil, salad oil, shortening, nutritionally enhanced foods, animal feed, pharmaceutical compositions, cosmetic compositions, hair care products, and the like.
- a Brassica plant comprising SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and/or SEQ ID NO:292.
- a Brassica seed comprising SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and/or SEQ ID NO:292.
- a Brassica plant or seed comprising event LBFLFK, a sample of seed comprising transformation event LBFLFK having been deposited under ATCC Accession No. PTA-121703. 4.
- Progeny of the Brassica plant of Embodiment 3 wherein the progeny comprise SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , or SEQ ID NO:292.
- an artificial dna molecule comprising a sequence selected from the group consisting of SEQ ID NO:282,SEQ ID NO:283, SEQ ID NO:291 , and SEQ ID NO:292.
- a method of detecting the presence of DNA corresponding to the Brassica event LBFLFK in a sample comprising DNA comprising the steps of:
- one amplicon comprises the LBFLFK Locus 1 junction region SEQ ID NO:282 or SEQ ID NO:283, or the complement thereof, and one amplicon comprises the
- LBFLFK Locus 2 junction region SEQ ID NO:291 or SEQ ID NO:292, or the complement thereof.
- the LBFLFK Locus 1 primer pair comprises:
- a first primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:284, at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:284, at least 1 1 consecutive nucleotides of SEQ ID NO:285, and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:285; and
- a second primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:281 and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:281 , and
- the LBFLFK Locus 2 primer pair comprises:
- a third primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:293 at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:293, at least 1 1 consecutive nucleotides of SEQ ID NO:294, and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:294; and
- a fourth primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:290 and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:290.
- the first primer comprises SEQ ID NO:286, the second primer comprises SEQ ID NO:287, the third primer comprises SEQ ID NO:295, and the fourth primer comprises SEQ ID NO:296.
- step g) comparing the amplicons produced in step c) with the amplicons produced in step f), wherein the presence of both amplicons indicates that the sample is heterozygous for the LBFLFK Locus 1 and Locus 2 transgene insertions.
- kits for use in detecting Brassica event LBFLFK in a biological sample employs a method comprising the steps of:
- the oil or meal of Embodiment 1 1 wherein the oil or meal comprises a detectable amount of a nucleotide sequence diagnostic for Brassica event LBFLFK wherein the sequence is selected from the group consisting of SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and SEQ ID NO:292.
- a commodity product comprising a detectable amount of a Brassica event LBFLFK DNA sequence, wherein the sequence is selected from the group consisting of SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and SEQ ID NO:292.
- a method for producing a Brassica plant comprising altered VLC-PUFA content comprising the step of crossing a plant comprising Brassica event LBFLFK with a Brassica plant lacking event LBFLFK to obtain a plant comprising the Brassica event LBFLFK and altered VLC- PUFA content, wherein a sample of event LBFLFK has been deposited under ATCC Accession No. PTA-121703.
- a method for producing a Brassica variety comprising Brassica event LBFLFK comprising the step of crossing a plant comprising Brassica event LBFLFK with a second Brassica plant, wherein a sample of event LBFLFK has been deposited under ATCC Accession No. PTA-121703.
- a Brassica plant comprising SEQ ID NO:300, SEQ ID NO:301 , SEQ ID NO:309, and/or SEQ ID NO:310.
- a Brassica seed comprising SEQ ID NO:300, SEQ ID NO:301 , SEQ ID NO:309, and/or SEQ ID NO:310.
- an artificial dna molecule comprising a sequence selected from the group consisting of SEQ ID NO:300, SEQ ID NO:301, SEQ ID NO:309, and SEQ ID NO:310.
- a method of detecting the presence of DNA corresponding to the Brassica event LBFDAU in a sample comprising DNA comprising the steps of:
- one amplicon comprises the LBFDAU Locus 1 junction region SEQ ID NO:300 or SEQ ID NO:301 and one amplicon comprises the LBFLFK Locus 2 junction region SEQ ID NO:309 or SEQ ID NO:310.
- the LBFLFK Locus 1 primer pair comprises:
- a first primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:302, at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:302, at least 1 1 consecutive nucleotides of SEQ ID NO:303, and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:303;
- a second primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:299 and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:299, and
- the LBFLFK Locus 2 primer pair comprises:
- a third primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:31 1 at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:31 1 , at least 1 1 consecutive nucleotides of SEQ ID NO:312, and comprising at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:312; and
- a fourth primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:308 and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:308.
- the first primer comprises SEQ ID NO:304
- the second primer comprises SEQ ID NO:305
- the third primer comprises SEQ ID NO:313
- the fourth primer comprises SEQ ID NO:314.
- the method of Embodiment 21 further comprising the steps of:
- kits for use in detecting Brassica event LBFDAU in a biological sample employs a method comprising the steps of:
- the LBFDAU Locus 1 amplicon comprises SEQ ID NO:300 or SEQ ID NO:301 and the LBFDAU Locus 2 amplicon comprises SEQ ID NO:309 or SEQ ID NO:310.
- a commodity product comprising a detectable amount of a Brassica event LBFDAU nucleotide sequence, wherein the sequence is selected from the group consisting of SEQ ID NO:300, SEQ
- a method for producing a Brassica plant comprising altered VLC-PUFA content comprising the step of crossing a plant comprising Brassica event LBFDAU with a Brassica plant lacking event LBFDAU to obtain a plant comprising the Brassica event LBFDAU and altered VLC- PUFA content, wherein a sample of event LBFDAU has been deposited under ATCC Accession No. PTA-122340.
- a method for producing a Brassica variety comprising Brassica event LBFDAU comprising the step of crossing a plant comprising Brassica event LBFDAU with a second Brassica plant, wherein a sample of event LBFDAU has been deposited under ATCC Accession No. PTA- 122340.
- the Examples for the invention described in Section B are the Examples B1 to B4 in the Examples section.
- the present invention relates generally to the field of molecular biology and concerns increasing the tocopherol content of a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase.
- the present invention also relates to methods for the manufacture of oil, fatty acid- or lipids-containing compositions, and to such oils and lipids as such.
- Fatty acids are carboxylic acids with long-chain hydrocarbon side groups that play a fundamental role in many biological processes. Fatty acids are rarely found free in nature but, rather, occur in esterified form as the major component of lipids. As such, lipids/fatty acids are sources of energy (e.g., beta-oxidation). In addition, lipids/fatty acids are an integral part of cell membranes and, therefore, are indispensable for processing biological or biochemical information.
- VLC-PUFAs Very long chain polyunsaturated fatty acids
- DHA docosahexaenoic acid
- mammals e.g. nerve, retina, brain and immune cells.
- DHA docosahexaenoic acid
- DHA is essential for the growth and development of the brain in infants, and for maintenance of normal brain function in adults (Martinetz, M. (1992) J. Pediatr. 120:S129 S138).
- DHA also has significant effects on photoreceptor function involved in the signal transduction process, rhodopsin activation, and rod and cone development (Giusto, N.M., et al. (2000) Prog.
- DHA eicosapentaenoic acid
- EPA eicosapentaenoic acid
- EPA is normally found in marine food and is abundant in oily fish from the North Atlantic.
- EPA can also be converted into eicosanoids in the human body.
- the eicosanoids produced from EPA have anti-inflammatory and anti-platelet aggregating properties.
- a large number of beneficial health effects have been shown for DHA or mixtures of EPA and DHA.
- Vitamin E (tocopherol) is a lipid soluble antioxidant that is important for preventing oxidative damage in both plants and animals and is known to have a beneficial effect in the prevention of cardiovascular disease. Vitamin E naturally occurs in vegetable oils, where it functions to prevent oxidative damage. Vegetable oils therefore represent a useful source of vitamin E in the human diet. Additionally, vitamin E extracted from vegetable oils is used as an additive in other food, health supplement, and cosmetic products.
- Vitamin E occurs in plants as various forms of tocopherol, including alpha-, beta-, gamma-, and delta.
- a study containing 52 landraces and 15 breeding lines of Brassica napus revealed a significant positive correlation between alpha-tocopherol and 18:1 +18:2, but no correlation between gamma-tocopherol and any fatty acid component (Li et al. (2013) J Agric Food Chem 61 :34-40).
- Tocopherol concentrations have not been correlated with the degree of unsaturation in various Brassica napus seeds with genetically altered fatty acid composition (Abidi et al (1999) J Am Oil Chem Soc 76, 463-467, and Dolde et al (1999) J Am Oil Chem Soc 76, 349-355).
- the invention is thus concerned with a method for increasing the tocopherol content of a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5- desaturase.
- the method further comprises expressing in the plant at least one polynucleotide encoding an omega-3-desaturase.
- the method further comprises expressing in the plant at least one polynucleotide encoding a delta-5-elongase.
- the method further comprises expressing in the plant at least one polynucleotide encoding a delta-4-desaturase.
- a delta-4-desaturase Preferably, two or more polynucleotides encoding a delta-4-desaturase are expressed. More preferably, at least one polynucleotide encoding a Coenzyme A dependent delta-4-desaturase and at least one polynucleotide encoding a phospholipid dependent delta-4-desaturase.
- the method may further comprise expressing at least one polynucleotide encoding a delta-5-elongase, at least one polynucleotide encoding a delta-4-desaturase (preferably at least one polynucleotide for a Coenzyme A dependent delta-4 desaturase and at least one for a phospholipid dependent delta- 4 desaturase), and at least one polynucleotide encoding an omega-3 desaturase.
- the method of the present invention may further comprise expressing in the plant at least one polynucleotide encoding a delta-15-desaturase.
- At least one polynucleotide encoding a delta-6 elongase from Physcomitrella patens at least one polynucleotide encoding a delta-12 desaturase from Phythophthora sojae, at least one polynucleotide encoding a delta-6 desaturase from Ostreococcus tauri, at least one polynucleotide encoding a delta-6 elongase from Thalassiosira pseudonana, at least one polynucleotide (preferably at least two polynucleotides) encoding a delta-5 desaturase from Thraustochytrium sp.
- At least one polynucleotide (preferably, at least two polynucleotides) encoding a omega-3 desaturase from Pythium irregulare, at least one polynucleotide encoding a omega-3-desaturase from Phythophthora infestans, at least one polynucleotide encoding a delta-5 elongase from Ostreococcus tauri, and at least one polynucleotide encoding a delta-4 desaturase from Thraustochytrium sp., and at least one polynucleotide encoding a delta-4 desaturase from Pavlova lutheri are expressed.
- At least two polynucleotides encoding a delta-5 desaturase from Thraustochytrium sp. are expressed.
- also variants of the aforementioned polynucleotides can be expressed.
- At least one polynucleotide encoding a Coenzyme A dependent delta-4-desaturase and at least one polynucleotide encoding a phospholipid dependent delta-4-desaturase are expressed.
- the polynucleotides are expressed in the seeds of the plant.
- the tocopherol content shall be preferably increased in the seeds of the plant as compared to the tocopherol content in seeds of a control plant, in particular the tocopherol content is increased in the seed oil of the plant as compared to the seed oil of a control plant.
- the polynucleotides encoding the elongases and desaturases referred to above are recombinant polynucleotides. They may be expressed in a plant by introducing them into the plant by recombinant means such as Agrobacterium-mediated transformation. Thus, the method may comprise the steps of introducing and expressing the above-referenced polynucleotides.
- the method may further comprise the step of selecting for plants having an increased tocopherol content (as compared to a control plant).
- polynucleotides are referred to herein above present on one T-DNA or construct (and thus on the same T-DNA or construct).
- Said construct or T-DNA shall be is stably integrated in the genome of the plant.
- the plant is homozygous for the T-DNA.
- the plant is hemizygous for the T-DNA. If the plant is homozygous for one T-DNA at one locus, this is nevertheless considered as a single copy herein, i.e. as one copy.
- Double copy refers to a plant in which two T-DNAs have been inserted, at one or two loci, and in the hemizygous or homozygous state.
- the present invention also relates to a construct or T-DNA comprising expression cassettes for the polynucleotides as set forth in the context of method of the present invention for increasing the tocopherol content.
- the construct or T-DNA shall comprise expression cassettes for at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6- desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase, and optionally for at least one of the further polynucleotides encoding the desaturases or elongases referred to above.
- the present invention further concerns the use of the polynucleotides as set forth in the context of the present invention, or of a construct or T-DNA comprising expression cassettes for said polynucleotides for increasing the tocopherol content of a plant relative to control plants.
- the present invention also relates to a plant comprising expression cassettes for the polynucleotides as referred to in the context of the method of the present invention for increasing the tocopherol content, or comprising the T-DNA or construct of the present invention.
- the present invention also relates to a seed of the plant of the present invention.
- Said seed shall comprise expression cassettes for the polynucleotides as referred to in the context of the method of the present invention for increasing the tocopherol content, or comprising the T-DNA or construct of the present invention.
- the seed shall comprise an oil of the present invention. The oil is described herein below.
- the method for increasing the tocopherol content comprises the further step of obtaining an oil from the plant, in particular from the seeds of the plant.
- Said oil shall have an increased tocopherol content as specified elsewhere herein.
- the oil shall have an increased content of VLC-PUFAs.
- the oil shall be obtained from the plant under conditions which maintain the tocopherol content. Such methods are well known in the art.
- the invention also provides methods of producing an oil, wherein the oil has a high content of tocopherol.
- the oil may have a high VLC-PUFA content, in particular a high content of EPA and/or DHA. In particularly preferred aspects these methods are for producing a corresponding plant oil.
- the invention also provides methods of producing an oil.
- the invention also provides methods for creating a plant, such that the plant or progeny thereof can be used as a source of an oil having a high content of tocopherol.
- the oil further has a high VLC-PUFA content, in particular a high content of EPA and/or DHA.
- the invention beneficially also provides methods for the production of plants having a heritable phenotype of high tocopherol content in seed oil.
- the plants may have a hight VLC-PUFA content in one or more of their tissues or components, preferably a high content of EPA and/or DHA in seed oil.
- Tocopherols are well known in the art.
- the term "content of tocopherol” preferably refers to the total tocopherol content, i.e. to the sum of the amounts of the tocopherols present in the plant, plant part (preferably in the seed) or oil (in particular in seed oil) thereof.
- the term refers to the sum of the amounts of alpha-tocopherol, beta-tocopherol, gamma-tocopherol, and delta-tocopherol.
- term refers to the amount of alpha-tocopherol, the amount of beta-tocopherol, andr to the amount of gamma-ocopherol, or the amount of delta- tocopherol.
- the term refers to the amount of gamma-tocopherol. In another preferred embodiment, the term term to the amount of delta-tocopherol. Also preferably, the term refers to the amount of total tocopherol, gamma-tocopherol and/or delta-tocopherol.
- tocopherol in the context of the present invention, preferably, refers to total tocopherol, alpha-tocopherol, beta-tocopherol, gamma-tocopherol, and/or delta-tocopherol. In particular, the term refers to total tocopherol, gamma-tocopherol, or delta-tocopherol
- amount preferably refers to the absolute amount or the concentration (preferably, in the plant, more preferably in the seed and most preferably in the seed oil).
- amount of tocopherol is increased in the seed oil of a plant as compared to the seed oil of a control plant.
- Increasing the content of tocopherols refers to the increase of the content of tocopherols in a plant, or a part, tissue or organ thereof, preferably in the seed, in particular in the oil compared to a control plant by at least 1 %, at least 5%, at least 10%, at least 12% or at least 15%.
- An "increased content” or “high content” of tocopherol as referred to herein preferably refers to a total content of tocopherol in seed oil of more than 97 mg/100 g seed oil, in particular of more than 100 mg/100 g seed oil, a content of alpha tocopherol in seed oil of more than 31 mg/100 g seed oil, in particular of more than 33 mg/100 g seed oil, a content of beta tocopherol in seed oil of more than 0.6 mg/100 g seed oil, a content of gamma tocopherol in seed oil of more than 65 mg/100 g seed oil, in particular of more than 70 mg/100 g seed oil, or a content of delta tocopherol in seed oil of more than 1.4 mg/100 g seed oil, in particular of more than 1.5 mg/100 g seed oil.
- an "increased content” or “high content” of tocopherol as referred to herein preferably refers to a total seed content of tocopherol of more than 35 mg/100 g seed, in particular of more than 39 mg/100 g seed, a seed content of alpha tocopherol in seed of more than 12 mg/100 g seed, in particular of more than 13 mg/100 g seed, a seed content of beta tocopherol in seed of more than 0.22 mg/100 g seed, a seed content of gamma tocopherol in seed of more than 25 mg/100 g seed, in particular of more than 26 mg/100 g seed, or a seed content of delta tocopherol in seed of more than 0.45 mg/100 g seed, in particular of more than 0.48 mg/100 g seed.
- the seeds in particular the oil, may further comprise a high VLC-PUFA (very long chain polyunsaturated fatty acid) content.
- VLC-PUFA very long chain polyunsaturated fatty acid
- control plants are routine part of an experimental setup and may include corresponding wild type plants or corresponding plants without the polynucleotides as encoding desaturases and elongase as referred to herein.
- the control plant is typically of the same plant species or even of the same variety as the plant to be assessed.
- the control plant may also be a nullizygote of the plant to be assessed. Nullizygotes (or null control plants) are individuals missing the transgene by segregation.
- control plants are grown under the same or essentially the same growing conditions to the growing conditions of the plants of the invention, i.e. in the vicinity of, and simultaneously with, the plants of the invention.
- a "control plant” as used herein preferably refers not only to whole plants, but also to plant parts, including seeds and seed parts. The control could also be the oil from a control plant.
- control plant is an isogenic control plant (thus, the control oil e.g. shall be from an isogenic control plant).
- polyunsaturated fatty acids refers to fatty acids comprising at least two, preferably, three, four, five or six, double bonds. Moreover, it is to be understood that such fatty acids comprise, preferably from 18 to 24 carbon atoms in the fatty acid chain. More preferably, the term relates to long chain PUFA (VLC-PUFA) having from 20 to 24 carbon atoms in the fatty acid chain.
- polyunsaturated fatty acids in the sense of the present invention are DHGLA 20:3 (8,1 1 ,14), ARA 20:4 (5,8,1 1 ,14), ETA 20:4 (8,1 1 ,14,17), EPA 20:5 (5,8,1 1 ,14,17), DPA 22:5 (4,7,10,13,16), DPA n-3 (7,10,13,16,19) DHA 22:6 (4,7,10,13,16,19), more preferably, eicosapentaenoic acid (EPA) 20:5 (5,8,1 1 ,14,17), and docosahexaenoic acid (DHA) 22:6 (4,7,10,13,16,19).
- DHGLA 20:3 8,1 1 ,14
- ARA 20:4 (5,8,1 1 ,14), ETA 20:4 (8,1 1 ,14,17)
- EPA 20:5 (5,8,1 1 ,14,17)
- the methods provided by the present invention pertain to the manufacture of EPA and/or DHA and/or tocopherol.
- the intermediates of VLC-PUFA which occur during synthesis. Such intermediates are, preferably, formed from substrates by the desaturase, keto- acyl-CoA-synthase, keto-acyl-CoA-reductase, dehydratase and enoyl-CoA-reductase activity of the polypeptide of the present invention.
- substrates encompass LA 18:2 (9,12), GLA 18:3 (6,9,12), DHGLA 20:3 (8,1 1 ,14), ARA 20:4 (5,8,1 1 ,14), eicosadienoic acid 20:2 (1 1 ,14), eicosatetraenoic acid 20:4 (8,1 1 ,14,17), eicosapentaenoic acid 20:5 (5,8,1 1 ,14,17).
- Systematic names of fatty acids including polyunsaturated fatty acids, their corresponding trivial names and shorthand notations used according to the present invention are given in the following table:
- cultivating refers to maintaining and growing the transgenic plant under culture conditions which allow the cells to produce tocopherol in a plant, a seed comprising an increased tocopherol content or an oil comprising and increased tocopherol content (as compared to a control). This implies that the polynucleotides as referred to herein in connection with the method of the present invention are present in the plant. Suitable culture conditions for cultivating the host cell are described in more detail below.
- the polynucleotides encoding the enzymes as referred to herein are stably integrated into the genome of the plant. More preferably, the polynucleotides are present on one T-DNA or construct which is stably integrated into the genome of the plant. Thus, they are preferably present on a single, i.e. the same T-DNA (or construct). The same applies to the expression cassettes as referred to herein.
- the polynucleotides or expression cassttes are preferably comprised by the same T-DNA.
- T-DNA may be present in the plant (e.g. in plants which are homozygous for the T-DNA (or construct), or in plants in which Agrobacterium mediated transformation resulted in more than one integration event.
- the term "obtaining" as used herein encompasses the provision of the cell culture including the host cells and the culture medium or the plant or plant part, particularly the seed, of the current invention, as well as the provision of purified or partially purified preparations thereof comprising the tococpherol
- the plant, plant part or purified or partially purified preparations may further comprise the polyunsaturated fatty acid, preferably, ARA, EPA, DHA, in free or in CoA bound form, as membrane phospholipids or as triacylglyceride esters. More preferably, the PUFA and VLC-PUFA are to be obtained as triglyceride esters, e.g., in the form of an oil. More details on purification techniques can be found elsewhere herein below.
- polynucleotide refers to a desoxyribonucleic acid or ribonucleic acid. Unless stated otherwise, "polynucleotide” herein refers to a single strand of a DNA polynucleotide or to a double stranded DNA polynucleotide.
- the length of a polynucleotide is designated according to the invention by the specification of a number of basebairs ("bp") or nucleotides ("nt"). According to the invention, both specifications are used interchangeably, regardless whether or not the respective nucleic acid is a single or double stranded nucleic acid.
- nucleotide/polynucleotide and nucleotide sequence/polynucleotide sequence are used interchangeably, thus that a reference to a nucleic acid sequence also is meant to define a nucleic acid comprising or consisting of a nucleic acid stretch, the sequence of which is identical to the nucleic acid sequence.
- polynucleotide as used in accordance with the present invention as far as it relates to a desaturase or elongase gene relates to a polynucleotide comprising a nucleic acid sequence which encodes a polypeptide having desaturase or elongase activity.
- the polypeptides encoded by the polynucleotides of the present invention having desaturase or elongase activity upon combined expression in a plant shall be capable of increasing the content, and thus the amount of tocopherol in a plant in particular, in seeds, seed oils or an entire plant or parts thereof. Whether an increase is statistically significant can be determined by statistical tests well known in the art including, e.g., Student's t-test with a confidentiality level of at least 90%, preferably of at least 95% and even more preferably of at least 98%.
- the increase is an increase of the amount of tocopherol of at least 1 %, at least 5%, at least 10%, at least 12% or at least 15% (preferably, by weight) compared to a control, in particular to the content in seeds, seed oil, crude oil, or refined oil from a control.
- polypeptides having desaturase or elongase activity upon combined expression in a plant shall be capable of increasing the amount of PUFA and, in particular, VLC-PUFA in, e.g., seed oils or an entire plant or parts thereof. More preferably, the increase is an increase of the amount of triglycerides containing VLC-PUFA of at least 5%, at least 10%, at least 15%, at least 20% or at least 30% (preferably by weight) compared to wild-type control, in seeds, seed oil, crude oil, or refined oil from a wildtype control.
- the present invention allows for producing an oil having not only an increased tocopherol content as compared to tocopherol content of oil of control plants but also an increased content of PUFA, in particular, of VLC-PUFA.
- the VLC-PUFA referred to before is a polyunsaturated fatty acid having a C20, C22 or C24 fatty acid body, more preferably EPA and/or DHA. Lipid analysis of oil samples are shown in the accompanying Examples.
- the fatty acid esters with polyunsaturated C20- and/or C22-fatty acid molecules can be isolated in the form of an oil or lipid, for example, in the form of compounds such as sphingolipids, phosphoglycerides, lipids, glycolipids such as glycosphingolipids, phos-pholipids such as phosphatidylethanolamine, phosphatidylcholine, phosphatidylserine, phosphatidylglycerol, phosphatidylinositol or diphosphatidylglycerol, monoacylglycerides, diacylglycerides, triacylglycerides or other fatty acid esters such as the acetylcoenzyme A esters which comprise the polyunsaturated fatty acids with at least two, three, four, five or six, preferably five or six, double bonds, from the organisms which were used for the preparation of the fatty acid esters.
- compounds such as sphingolipid
- the polyunsaturated fatty acids are also present in the non-human transgenic organisms or host cells, preferably in the plants, as free fatty acids or bound in other compounds.
- the fatty acids are, preferably, produced in bound form.
- these unsaturated fatty acids prefferably be positioned at the sn1 , sn2 and/or sn3 position of the triglycerides which are, preferably, to be produced.
- the desaturares and elongases referred to herein are well known in the art.
- the term "desaturase” encompasses all enzymatic activities and enzymes catalyzing the desaturation of fatty acids with different lengths and numbers of unsaturated carbon atom double bonds.
- delta 4 desaturase, preferably catalyzing the dehydrogenation of the 4th and 5th carbon atom; Delta 5 (d5)-desaturase catalyzing the dehydrogenation of the 5th and 6th carbon atom; Delta 6 (d6)-desaturase catalyzing the dehydrogenation of the 6th and 7th carbon atom; Delta 15 (d15)-desaturase catalyzing the dehydrogenation of the 15th and 16th carbon atom.
- An omega 3 (o3) desaturase preferably catalyzes the dehydrogenation of the n-3 and n-2 carbon atom.
- elongase encompasses all enzymatic activities and enzymes catalyzing the elongation of fatty acids with different lengths and numbers of unsaturated carbon atom double bonds.
- elongase refers to the activity of an elongase, introducing two carbon molecules into the carbon chain of a fatty acid, preferably in the positions 1 , 5, 6, 9, 12 and/or 15 of fatty acids.
- the term "elongase” shall refer to the activity of an elongase, introducing two carbon molecules to the carboxyl ends ⁇ i.e. position 1 ) of both saturated and unsaturated fatty acids.
- the delta-6-desaturase is a CoA (Coenzyme A)-dependent delta-6- desaturase.
- Polynucleotides encoding polypeptides which exhibit delta-6-elongase activity have been described in WO2005/012316, WO2005/007845 and WO2006/069710, said documents, describing this enzyme from Thalassiosira pseudonana, are incorporated herein in their entirety.
- Polynucleotides encoding polypeptides which exhibit delta-12-desaturase activity have been described for example in WO2006100241 , said documents, describing this enzyme from Phytophthora sojae, are incorporated herein in their entirety.
- Polynucleotides encoding polypeptides which exhibit omega 3-desaturase activity have been described for example in WO2005012316 and WO2005083053, said documents, describing this enzyme from Phytophthora infestans, are incorporated herein in their entirety.
- Polynucleotides encoding polypeptides which exhibit delta-4-desaturase activity have been described for example in WO2002026946, said documents, describing this enzyme from Thraustochytrium sp., are incorporated herein in their entirety.
- polynucleotides encoding the aforementioned polypeptides are herein also referred to as "target genes" or "nucleic acid of interest".
- the polynucleotides are well known in the art.
- the sequences of said polynucleotides can be found in the sequence of the T-DNA disclosed in the Examples section (see e.g. the sequence of VC-LTM593-1 qcz which has a sequence as shown in SEQ ID NO: 3, see also Table C1 ).
- the polynucleotide and polypeptide sequences are also given in Table C2 in the Examples section. Sequences of preferred polynucleotides for the desaturases and elongases referred to herein in connection with the present invention are indicated below.
- polynucleotides can be used.
- the polynucleotides encoding for desaturases and elogases to be used in accordance with the present invention can be derived from certain organisms.
- a polynucleotide derived from an organism e.g from Physcomitrella patens
- the polynucleotide shall be codon-optimized for expression in a plant.
- a codon optimized polynucleotide is a polynucleotide which is modified by comparison with the nucleic acid sequence in the organism from which the sequence originates in that it is adapted to the codon usage in one or more plant species.
- the polynucleotide, in particular the coding region is adapted for expression in a given organism (in particular in a plant) by replacing at least one, or more than one of codons with one or more codons that are more frequently used in the genes of that organism (in particular of the plant).
- a codon optimized variant of a particular polynucleotide "from an organism" preferably shall be considered to be a polynucleotide derived from said organism.
- a codon-optimized polynucleotide shall encode for the same polypeptide having the same sequence as the polypeptide encoded by the non codon-optimized polynucleotide (i.e. the wild-type sequence).
- codon optimized polynucleotides were used (for the desaturases).
- the codon optimized polynucleotides are comprised by the T-DNA of the vector having a sequence as shown in SEQ ID NO: 3 (see Table C1 ).
- sequences of preferred polynucleotides for the desaturases and elongases and the sequences corresponding polypeptides referred to herein in connection with the present invention are described herein below.
- variants of polynucleotides and polynucleotides can be used in connection with the present invention (in particular in connection with the methods, T- DNAs, constructs, plants, seeds, etc.).
- a delta-6-elongase to be used in accordance with the present invention is derived from Physcomitrella patens.
- a preferred sequence of said delta-6-elongase is shown in SEQ ID NO:258.
- said delta-6-elongase is encoded by a polynucleotide derived from Physcomitrella patens, in particular, said delta-6-elongase is encoded by a codon-optimized variant thereof.
- the polynucleotide encoding the delta-6-elongase derived from Physcomitrella patens is a polynucleotide having a sequence as shown in nucleotides 1267 to 2139 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 257.
- a delta-5-desaturase to be used in accordance with the present invention is derived from Thraustochytrium sp.. Thraustochytrium sp. in the context of the present invention preferably means Thraustochytrium sp. ATCC21685.
- a preferred sequence of said delta-5-desaturase is shown in SEQ ID NO:260.
- said delta-5-desaturase is encoded by a polynucleotide derived from Thraustochytrium sp.; in particular, said delta-5-desaturase is encoded by a codon- optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-5- desaturase derived from Thraustochytrium sp. is a polynucleotide having a sequence as shown in nucleotides 3892 to 521 1 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 259.
- the T-DNA, construct, plant, seed etc. of the present invention shall comprise two (or more) copies of a polynucleotide encoding a delta-5-desaturase derived from Thraustochytrium sp..
- a delta-6-desaturase to be used in accordance with the present invention is derived from Ostreococcus tauri.
- a preferred sequence of said delta-6-desaturase is shown in SEQ ID NO:262.
- said delta-6-desaturase is encoded by a polynucleotide derived from Ostreococcus tauri; in particular, said delta-6-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-6-desaturase derived from Ostreococcus tauri is a polynucleotide having a sequence as shown in nucleotides 7802 to 9172 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 261.
- a delta-6-elongase to be used in accordance with the present invention is derived from Thalassiosira pseudonana.
- a preferred sequence of said delta-6-elongase is shown in SEQ ID NO:264.
- said delta-6-elongase is encoded by a polynucleotide derived from Thalassiosira pseudonana; in particular, said delta-6-elongase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-6-elongase derived from Thalassiosira pseudonana is a polynucleotide having a sequence as shown in nucleotides 12099 to 12917 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 263. (Thus, the polynucleotide encoding the delta-6-elongase derived from Thalassiosira pseudonana preferably has a sequence as shown in SEQ ID NO: 263)
- a delta-12-elongase to be used in accordance with the present invention is derived from Phytophthora sojae.
- a preferred sequence of said delta-12-elongase is shown in SEQ ID NO:266.
- said delta-12-elongase is encoded by a polynucleotide derived from Phytophthora sojae; in particular, said delta-12-elongase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-12-elongase derived from Phytophthora sojae is a polynucleotide having a sequence as shown in nucleotides 14589 to 15785 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 265.
- a delta-5-elongase to be used in accordance with the present invention is derived from Ostreococcus tauri.
- a preferred sequence of said delta-5-elongase is shown in SEQ ID NO:276.
- said delta-5-elongase is encoded by a polynucleotide derived from Ostreococcus tauri; in particular, said delta-5-elongase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-5-elongase derived from Ostreococcus tauri is a polynucleotide having a sequence as shown in nucleotides 38388 to 39290 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 275.
- an omega 3-desaturase to be used in accordance with the present invention is derived from Pythium irregulare. A preferred sequence of said omega 3-desaturase is shown in SEQ ID NO:268.
- said omega 3-desaturase is encoded by a polynucleotide derived from Pythium irregulare; in particular, said omega 3-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the omega 3-desaturase derived from Pythium irregulare is a polynucleotide having a sequence as shown in nucleotides 17690 to 18781 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 267.
- the T-DNA, construct, plant, seed etc. of the present invention shall comprise two (or more) copies of a polynucleotide encoding a omega 3-desaturase derived from Pythium irregulare
- an omega 3-desaturase to be used in accordance with the present invention is derived from Phytophthora infestans.
- a preferred sequence of said omega 3-desaturase is shown in SEQ ID NO:270.
- said omega 3-desaturase is encoded by a polynucleotide derived from Phytophthora infestans; in particular, said omega 3-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the omega 3-desaturase derived from Phytophthora infestans is a polynucleotide having a sequence as shown in nucleotides 20441 to 21526 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 269.
- the method of the present invention it is in particular envisaged to express two or more polynucleotides encoding, preferably omega 3-desaturases in the plant.
- at least one polynucleotide encoding an omega 3-desaturase from Phytophthora infestans and at least one polynucleotide (in particular two polynucleotides, i.e. two copies of a polynucleotide) encoding an omega 3-desaturase from Pythium irregulare are expressed.
- a delta-4-desaturase to be used in accordance with the present invention is derived from Thraustochytrium sp..
- a preferred sequence of said delta-4-desaturase is shown in SEQ ID NO:272.
- said delta-4-desaturase is encoded by a polynucleotide derived from Thraustochytrium sp.; in particular, said delta-4-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-4-desaturase derived from Thraustochytrium sp. is a polynucleotide having a sequence as shown in nucleotides 26384 to 27943 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 271 .
- a delta-4-desaturase to be used in accordance with the present invention is derived from Pavlova lutheri.
- a preferred sequence of said delta-4-desaturase is shown in SEQ ID NO:274.
- said delta-4-desaturase is encoded by a polynucleotide derived from Pavlova lutheri; in particular, said delta-4-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-4-desaturase derived from Pavlova lutheri is a polynucleotide having a sequence as shown in nucleotides 34360 to 35697 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 273.
- a delta-15-desaturase to be used in accordance with the present invention is derived from Cochliobolus heterostrophus.
- said delta-15-desaturase is encoded by a polynucleotide derived from Cochliobolus heterostrophus; in particular, said delta-15-desaturase is encoded by a codon-optimized variant of said polynucleotide.
- the polynucleotide encoding the delta-15-desaturase derived from Cochliobolus heterostrophus is a polynucleotide having a sequence as shown in nucleotides 2151 to 3654 of SEQ ID NO: 9.
- the polynucleotide encoding a delta-6-elongase can be derived from Physcomitrella patens. Moreover, the polynucleotide encoding a delta-6-elongase can be derived from Thalassiosira pseudonana. In particular, it is envisaged in the context of the method of the present invention to express at least one polynucleotide encoding a delta-6-elongase from Physcomitrella patens and at least one polynucleotide encoding a delta-6-elongase from Thalassiosira pseudonana in the plant.
- a polynucleotide encoding a polypeptide having a desaturase or elongase activity as specified above is obtainable or obtained in accordance with the present invention for example from an organism of genus Ostreococcus, Thraustochytrium, Euglena, Thalassiosira, Phytophthora, Pythium, Cochliobolus, Physcomitrella.
- orthologs, paralogs or other homologs may be identified from other species.
- plants such as algae, for example Isochrysis, Mantoniella, Crypthecodinium, algae/diatoms such as Phaeodactylum, mosses such as Ceratodon, or higher plants such as the Primulaceae such as Aleuritia, Calendula stellata, Osteospermum spinescens or Osteospermum hyoseroides, microorganisms such as fungi, such as Aspergillus, Entomophthora, Mucor or Mortierella, bacteria such as Shewanella, yeasts or animals.
- Preferred animals are nematodes such as Caenorhabditis, insects or vertebrates.
- the nucleic acid molecules may, preferably, be derived from Euteleostomi, Actinopterygii; Neopterygii; Teleostei; Euteleostei, Protacanthopterygii, Salmoniformes; Salmonidae or Oncorhynchus, more preferably, from the order of the Salmoniformes, most preferably, the family of the Salmonidae, such as the genus Salmo, for example from the genera and species Oncorhynchus mykiss, Trutta trutta or Salmo trutta fario.
- the nucleic acid molecules may be obtained from the diatoms such as the genera Thalassiosira or Phaeodactylum.
- polynucleotide as used in accordance with the present invention further encompasses variants or derivatives of the aforementioned specific polynucleotides representing orthologs, paralogs or other homologs of the polynucleotide of the present invention.
- variants or derivatives of the polynucleotide of the present invention also include artificially generated muteins.
- Said muteins include, e.g., enzymes which are generated by mutagenesis techniques and which exhibit improved or altered substrate specificity, or codon optimized polynucleotides.
- Nucleic acid variants or derivatives according to the invention are polynucleotides which differ from a given reference polynucleotide by at least one nucleotide substitution, addition and/or deletion. If the reference polynucleotide codes for a protein, the function of this protein is conserved in the variant or derivative polynucleotide, such that a variant nucleic acid sequence shall still encode a polypeptide having a desaturase or elongase activity as specified above. Variants or derivatives also encompass polynucleotides comprising a nucleic acid sequence which is capable of hybridizing to the aforementioned specific nucleic acid sequences, preferably, under stringent hybridization conditions.
- stringent hybridization conditions are known to the skilled in the art and can be found in Current Protocols in Molecular Biology, John Wiley & Sons, N. Y. (1989), 6.3.1-6.3.6.
- SSC sodium chloride/sodium citrate
- 0.1 % SDS at 50 to 65°C (in particular at 65°C).
- the skilled worker knows that these hybridization conditions differ depending on the type of nucleic acid and, for example when organic solvents are present, with regard to the temperature and concentration of the buffer.
- the temperature under standard hybridization conditions the temperature ranges depending on the type of nucleic acid, between 42°C and 58°C in aqueous buffer, with a concentration of 0.1 to 5X SSC (pH 7.2). If organic solvent is present in the abovementioned buffer, for example 50% formamide, the temperature under standard conditions is approximately 42°C.
- the hybridization conditions for DNA: DNA hybrids are, preferably, 0.1 X SSC and 20°C to 45°C, preferably between 30°C and 45°C.
- the hybridization conditions for DNA:RNA hybrids are, preferably, 0.1X SSC and 30°C to 55°C, preferably between 45°C and 55°C.
- the skilled worker knows how to determine the hybridization conditions required by referring to textbooks such as the textbook mentioned above, or the following textbooks: Sambrook et al., “Molecular Cloning", Cold Spring Harbor Laboratory, 1989; Hames and Higgins (Ed.) 1985, “Nucleic Acids Hybridization: A Practical Approach”, IRL Press at Oxford University Press, Oxford; Brown (Ed.) 1991 , “Essential Molecular Biology: A Practical Approach”, IRL Press at Oxford University Press, Oxford.
- stringent hybridization conditions encompass hybridization at 65°C in 1x SSC, or at 42°C in 1 x SSC and 50% formamide, followed by washing at 65°C in 0.3x SSC.
- stringent hybridization conditions encompass hybridization at 65°C in 1 x SSC, or at 42°C in 1 x SSC and 50% formamide, followed by washing at 65°C in 0.1 x SSC.
- polynucleotide variants are obtainable by PCR-based techniques such as mixed oligonucleotide primer based amplification of DNA, i.e. using degenerated primers against conserved domains of the polypeptides of the present invention.
- conserveed domains of the polypeptide of the present invention may be identified by a sequence comparison of the nucleic acid sequences of the polynucleotides or the amino acid sequences of the polypeptides of the present invention.
- DNA or cDNA from bacteria, fungi, plants, or animals may be used as a template.
- variants include polynucleotides comprising nucleic acid sequences which are at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 98% or at least 99% identical to the nucleic acid coding sequences shown in any one of the T-DNA sequences given in Table C1 of the Examples, and in particular to polynucleotides encoding the desaturases or elongases referred to above, in particular the elongases and desaturases given in Table C2.
- polynucleotides are envisaged which are at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 98% or at least 99% identical to the polynucleotide encoding the delta-4-desaturase from Thraustochytrium sp (and thus to a polynucleotide having sequence as shown in nucleotides 26384 to 27943 of SEQ ID NO: 3).
- a variant as referred to herein must retain the function of the respective enzyme, e.g. a variant of a delta-4-desaturase must retain delta-4-desaturase activity, or a variant of a delta-12- desaturase must retain delta-12-desaturase activity.
- the percent identity values are, preferably, calculated over the entire amino acid or nucleic acid sequence region.
- a series of programs based on a variety of algorithms is available to the skilled worker for comparing different sequences.
- the percent identity between two amino acid sequences is determined using the Needleman and Wunsch algorithm (Needleman 1970, J. Mol. Biol. (48):444-453) which has been incorporated into the needle program in the EMBOSS software package (EMBOSS: The European Molecular Biology Open Software Suite, Rice.P., LongdenJ., and BleasbyA Trends in Genetics 16(6), 276-277, 2000), a BLOSUM62 scoring matrix, and a gap opening penalty of 10 and a gap extension pentalty of 0.5.
- parameters to be used for aligning two amino acid sequences using the needle program are the default parameters, including the EBLOSUM62 scoring matrix, a gap opening penalty of 10 and a gap extension penalty of 0.5.
- the percent identity between two nucleotide sequences is determined using the needle program in the EMBOSS software package (EMBOSS: The European Molecular Biology Open Software Suite, Rice, P., LongdenJ., and BleasbyA Trends in Genetics 16(6), 276-277, 2000), using the EDNAFULL scoring matrix and a gap opening penalty of 10 and a gap extension penalty of 0.5.
- EMBOSS European Molecular Biology Open Software Suite, Rice, P., LongdenJ., and BleasbyA Trends in Genetics 16(6), 276-277, 2000
- a preferred, non-limiting example of parameters to be used in conjunction for aligning two nucleic acid sequences using the needle program are the default parameters, including the EDNAFULL scoring matrix, a gap opening penalty of 10 and a gap extension penalty of 0.5.
- nucleic acid and protein sequences of the present invention can further be used as a "query sequence" to perform a search against public databases to, for example, identify other family members or related sequences.
- search can be performed using the BLAST series of programs (version 2.2) of Altschul et al. (Altschul 1990, J. Mol. Biol. 215:403-10).
- BLAST using desaturase and elongase nucleic acid sequences of the invention as query sequence can be performed with the BLASTn, BLASTx or the tBLASTx program using default parameters to obtain either nucleotide sequences (BLASTn, tBLASTx) or amino acid sequences (BLASTx) homologous to desaturase and elongase sequences of the invention.
- BLAST using desaturase and elongase protein sequences of the invention as query sequence can be performed with the BLASTp or the tBLASTn program using default parameters to obtain either amino acid sequences (BLASTp) or nucleic acid sequences (tBLASTn) homologous to desaturase and elongase sequences of the invention.
- Gapped BLAST using default parameters can be utilized as described in Altschul et al. (Altschul 1997, Nucleic Acids Res. 25(17):3389-3402).
- polynucleotides having a sequence shown in SEQ ID NO: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275 are described herein below.
- a variant of a polynucleotide encoding a desaturase or elongase as referred to herein is, preferably, a polynucleotide comprising a nucleic acid sequence selected from the group consisting of:
- nucleic acid sequence being at least 70%, 80%, or 90% identical to the nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
- nucleic acid sequence encoding a polypeptide which is at least 70%, 80, or 90% identical to a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276, and
- nucleic acid sequence which is capable of hybridizing under stringent conditions to i) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275, or to ii) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276.
- the polypeptide encoded by said nucleic acid must retain the function and thus the activity of the respective enzyme.
- the polypeptide having a sequence as shown in SEQ ID NO: 270 has omega-3-desaturase activity. Accordingly, the variant this polypeptide also shall have omega-3-desaturase activity.
- a polynucleotide encoding a desaturase or elongase as referred to herein is, preferably, a polynucleotide comprising a nucleic acid sequence selected from the group consisting of:
- nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NO: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
- nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NO: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276
- nucleic acid sequence being at least 70%, 80%, or 90% identical to the nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
- nucleic acid sequence encoding a polypeptide which is at least 70%, 80, or 90% identical to a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276, and e) a nucleic acid sequence which is capable of hybridizing under stringent conditions to i) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275, or to ii) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276.
- LBFLFK comprises two T-DNA insertions, the insertions being designated LBFLFK Locus 1 and LBFLFK Locus 2.
- Plants comprising this insertion were generated by transformation with the T-DNA vector having a sequence as shown in SEQ ID NO: 3. Sequencing of the insertions present in the plant revealed that each locus contained a point mutation in a coding sequence resulting in a single amino acid exchange. The mutations did not affect the function of the genes.
- Locus 1 has a point mutation in the coding sequence for the delta-12 desaturase from Phythophthora sojae (d12Des(Ps)).
- the resulting polynucleotide has a sequence as shown in SEQ ID NO: 324.
- Said polynucleotide encodes a polypeptide having a sequence as shown in SEQ ID NO: 325.
- Locus 2 has a point mutation in the coding sequence for the delta-4 desaturase from Pavlova lutheri (d4Des(PI)).
- the resulting polynucleotide has a sequence as shown in SEQ ID NO: 326.
- Said polynucleotide encodes a polypeptide having a sequence as shown in SEQ ID NO: 327.
- polynucleotides are considered as variants of the polynucleotide encoding the delta-12 desaturase from Phythophthora sojae and the polynucleotide encoding the delta-4 desaturase from Pavlova lutheri.
- the polynucleotides are considered as variants and can be used in the context of the present invention.
- a polynucleotide comprising a fragment of any nucleic acid, particularly of any of the aforementioned nucleic acid sequences, is also encompassed as a polynucleotide of the present invention.
- the fragments shall encode polypeptides which still have desaturase or elongase activity as specified above. Accordingly, the polypeptide may comprise or consist of the domains of the polypeptide of the present invention conferring the said biological activity.
- a fragment as meant herein preferably, comprises at least 50, at least 100, at least 250 or at least 500 consecutive nucleotides of any one of the aforementioned nucleic acid sequences or encodes an amino acid sequence comprising at least 20, at least 30, at least 50, at least 80, at least 100 or at least 150 consecutive amino acids of any one of the aforementioned amino acid sequences.
- variant polynucleotides or fragments referred to above preferably, encode polypeptides retaining desaturase or elongase activity to a significant extent, preferably, at least 10%, at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 80% or at least 90% of the desaturase or elongase activity exhibited by any of the polypeptides encoded by T- DNA given in the accompanying Examples (in particular of the desaturases or elongases listed in Table C1 and C2).
- the polynucleotides shall be operably linked to expression control sequences.
- the expression control sequences are heterologous with respect to the polynucleotides operably linked thereto. It is to be understood that each polynucleotide is operably linked to an expression control sequence.
- expression control sequence refers to a nucleic acid sequence which is capable of governing, i.e. initiating and controlling, transcription of a nucleic acid sequence of interest, in the present case the nucleic sequences recited above.
- a sequence usually comprises or consists of a promoter or a combination of a promoter and enhancer sequences.
- Expression of a polynucleotide comprises transcription of the nucleic acid molecule, preferably, into a translatable mRNA. Additional regulatory elements may include transcriptional as well as translational enhancers.
- the following promoters and expression control sequences may be, preferably, used in an expression vector according to the present invention.
- the cos, tac, trp, tet, trp-tet, Ipp, lac, Ipp-lac, laclq, T7, T5, T3, gal, trc, ara, SP6, ⁇ -PR or ⁇ -PL promoters are, preferably, used in Gram-negative bacteria.
- promoters amy and SP02 may be used.
- yeast or fungal promoters ADC1 , AOX1 r, GAL1 , MFa, AC, P-60, CYC1 , GAPDH, TEF, rp28, ADH are, preferably, used.
- the promoters CMV-, SV40-, RSV-promoter Rosarcoma virus
- CMV-enhancer SV40-enhancer
- SV40-enhancer are preferably used.
- CaMV/35S Franck 1980, Cell 21 : 285-294]
- PRP1 Ward 1993, Plant. Mol. Biol. 22
- SSU SSU
- OCS OCS
- Iib4 usp
- STLS1 , B33 nos or the ubiquitin or phaseolin promoter.
- inducible promoters such as the promoters described in EP 0388186 A1 (i.e. a benzylsulfonamide-inducible promoter), Gatz 1992, Plant J.
- EP 0335528 A1 i.e. a abscisic-acid- inducible promoter
- WO 93/21334 i.e. a ethanol- or cyclohexenol-inducible promoter
- Further suitable plant promoters are the promoter of cytosolic FBPase or the ST-LSI promoter from potato (Stockhaus 1989, EMBO J. 8, 2445), the phosphoribosyl-pyrophosphate amidotransferase promoter from Glycine max (Genbank accession No. U87999) or the node-specific promoter described in EP 0249676 A1.
- promoters which enable the expression in tissues which are involved in the biosynthesis of fatty acids.
- seed-specific promoters such as the USP promoter in accordance with the practice, but also other promoters such as the LeB4, DC3, phaseolin or napin promoters.
- promoters are seed-specific promoters which can be used for monocotyledonous or dicotyledonous plants and which are described in US 5,608,152 (napin promoter from oilseed rape), WO 98/45461 (oleosin promoter from Arobidopsis, US 5,504,200 (phaseolin promoter from Phaseolus vulgaris), WO 91/13980 (Bce4 promoter from Brassica), by Baeumlein et al., Plant J., 2, 2, 1992:233-239 (LeB4 promoter from a legume), these promoters being suitable for dicots.
- promoters are suitable for monocots: lpt-2 or lpt-1 promoter from barley (WO 95/15389 and WO 95/23230), hordein promoter from barley and other promoters which are suitable and which are described in WO 99/16890.
- all natural promoters together with their regulatory sequences, such as those mentioned above, for the novel process.
- synthetic promoters either additionally or alone, especially when they mediate a seed-specific expression, such as, for example, as described in WO 99/16890.
- the polynucleotides encoding the desaturases and elongases as referred to herein are expressed in the seeds of the plants.
- seed-specific promoters are utilized in accordance with the present invention.
- the polynucleotides encoding the desaturares or elongases are operably linked to expression control sequences used for the the expression of the desaturases and elongases in the Examples section (see e.g. the promoters used for expressing the elongases and desaturases in VC-LTM593-1 qcz rc.
- the sequence of this vector is shown in SEQ ID NO: 3, see also Table C1 in the Examples section).
- operatively linked means that the expression control sequence and the nucleic acid of interest are linked so that the expression of the said nucleic acid of interest can be governed by the said expression control sequence, i.e. the expression control sequence shall be functionally linked to the said nucleic acid sequence to be expressed.
- the expression control sequence and, the nucleic acid sequence to be expressed may be physically linked to each other, e.g., by inserting the expression control sequence at the 5 ' end of the nucleic acid sequence to be expressed.
- the expression control sequence and the nucleic acid to be expressed may be merely in physical proximity so that the expression control sequence is capable of governing the expression of at least one nucleic acid sequence of interest.
- the expression control sequence and the nucleic acid to be expressed are, preferably, separated by not more than 500 bp, 300 bp, 100 bp, 80 bp, 60 bp, 40 bp, 20 bp, 10 bp or 5 bp.
- Preferred polynucleotides of the present invention comprise, in addition to a promoter, a terminator sequence operatively linked to the nucleic acid sequence of interest. Thereby, an expression cassette is formed.
- terminal refers to a nucleic acid sequence which is capable of terminating transcription. These sequences will cause dissociation of the transcription machinery from the nucleic acid sequence to be transcribed.
- the terminator shall be active in plants and, in particular, in plant seeds.
- Suitable terminators are known in the art and, preferably, include polyadenylation signals such as the SV40-poly-A site or the tk-poly-A site or one of the plant specific signals indicated in Loke et al. (Loke 2005, Plant Physiol 138, pp. 1457-1468), downstream of the nucleic acid sequence to be expressed.
- polynucleotides encoding the desaturases or elongase referred to herein are recombinant.
Abstract
The present invention relates to a T-DNA for expression of a target gene in a plant. The present invention further concerns increasing the tocopherol content of a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase. Further, the present invention relates to an assay method, comprising providing a plant capable of expressing a delta-12 desaturase. The present invention provides also transgenic Brassica events LBFLFK and LBFDAU and progeny thereof, and cells, seeds, plants comprising DNA diagnostic for these events.
Description
PRODUCTION OF PUFAS IN PLANTS
This application claims priority to U.S. Provisional Patent Application Serial Number 62/079622 application number filed November 14, 2014 and to U.S. Provisional Patent Application Serial Number 62/234373 filed September 29, 2015, which are incorporated herein by reference in their entirety.
The Sequence Listing, which is a part of the present disclosure, is submitted concurrently with the specification as a text file. The subject matter of the Sequence Listing is incorporated herein in its entirety by reference.
The present specification contains four sections, namly section A, section B, section C and section D. Section A has the title "MATERIALS AND METHODS FOR PUFA PRODUCTION, AND PUFA- CONTAINING COMPOSITIONS"
Section B has the title "BRASSICA EVENTS LBFLFK AND LBFDAU AND METHODS FOR DETECTION THEREOF"
Section C has the title "MATERIALS AND METHODS FOR INCREASING THE TOCOPHEROL CONTENT IN SEED OIL",
Section D has the title "STABILISING FATTY ACIDS COMPOSITIONS"
In accordance with the present application, the definitions and explanations given in a certain section and in the corresponding Examples shall preferably only apply to this section (except if stated otherwise). Thus, the definitions and explanations in Section A and in the Examples for Section A shall preferably only apply to the embodiments of Section A.
If in a specific section, reference is made to the examples, this shall mean that it is referred to the Examples of said corresponding specification. For example, Examples 1 to 32 belong to the invention described in section A. Further, a reference in section A to a table, e.g. table 1 1 , shall be a reference to the corresponding table in the examples of said section A, whereas in section B the reference to table B1 refers to the table B1 listed in Section B.
Accordingly, each section (with the corresponding Examples) is a complete section with definitions, tables, examples and embodiments. However, any reference to a figure is a reference to a figure as listed below
BRIEF DESCRIPTION OF THE FIGURES for all sections
Figure 1 : Schematical figure of the different enzymatic activities leading to the production of ARA, EPA and DHA
Figure 2: Formulas to calculate pathway step conversion efficiencies. S: substrate of pathway step. P: product of pathway step. Product was always the sum of the immediate product of the conversion at this pathway step, and all downstream products that passed this pathway step in order to be formed. E.g. DHA (22:6n-3 does possess a double bond that was a result of the delta- 12-desaturation of oleic acid (18:1 n-9) to linoleic acid (18:2n-6).
Figure 3: Strategy employed for stepwise buildup of plant expression plasmids of the invention. Figure 4: Stabiliy of binary plant expression plasmids containing the ColE1/pVS1 origin of replication for plasmid recplication in E.coli/Agrobacteria. Left Panel: Stability in Agrobacterium cells by isolating plasmid DNA from Agrobacterium cutures prior to usage of this culture for plant transformation, and subjecting the plasmid DNA to a restriction digest. An unexpected restriction pattern indicates disintegration/instability of the plasmid either in E.coli or in Agrobacterium. Right panel: Under the assumption at least one intact T-DNA from LB to RB was integrated into the plant genome during the transformation process most plants obtained via transformation of a given plasmid are expected to reach the desired trait encoded by the plasmid (here: production of novel fatty acids (FA) in the seeds). The decrease in the percentage of such 'functional' plants indicates instability either in Agrobacteria or during the transfer process into the plant or during the integration process into the genome. As can be seen, the proportion of non functional plants goes sharply up for plasmids above 25,000bp size when ColE1/pVS1 containing plasmids are used.
Figure 5: Plasmid map of VC-LJB2197-1 qcz indicating the position of genetic elements listed in table 1 (and in table D1 ).
Figure 6: Plasmid map of VC-LJB2755-2qcz rc indicating the position of genetic elements listed in table 2 (and in table D2). Figure 7: Plasmid map of VC-LLM306-1 qcz rc indicating the position of genetic elements listed in table 3.
Figure 8: Plasmid map of VC-LLM337-1 qcz rc indicating the position of genetic elements listed in table 4(and in table D4) .
Figure 9: Plasmid map of VC-LLM338-3qcz rc indicating the position of genetic elements listed in table 5.
Figure 10: Plasmid map of VC-LLM391 -2qcz rc indicating the position of genetic elements listed in table 6 (and in table D6).
Figure 1 1 : Plasmid map of VC-LTM217-1 qcz rc indicating the position of genetic elements listed in table 7.
Figure 12: Plasmid map of RTP10690-1 qcz_F indicating the position of genetic elements listed in table 8. Figure 13: Plasmid map of RTP10691 -2qcz indicating the position of genetic elements listed in table 9.
Figure 14: Plasmid map of LTM595-1 qcz rc indicating the position of genetic elements listed in table 10.
Figure 15: Plasmid map of LTM593-1 qcz rc indicating the position of genetic elements listed in table 1 1 .
Figure 16: Comparative transcript analysis o3Des(Pi_GA2) driven by the VfUSP promoter during seed development of single copy event of four different construct combinations.
Figure 17: Comparative transcript analysis of o3Des(Pir_GA) during seed development of single copy event of four different construct combinations. In VC-LJB2755-2qcz and VC-RTP10690- 1 qcz_F the gene was driven by the LuCnl promoter while in VC-LLM337-1 qcz rc the gene was driven by the VfUSP promoter and was expressed at a lower level than the LuCnl o3Des(Pir_GA) combination.
Figure 18: Comparative transcript analysis of o3Des(Pir_GA) driven by the BnSETL promoter during seed development of single copy event of VC-RTP10690-1 qcz_F.
Figure 19: Comparative transcript analysis of d4Des(PI_GA)2 driven by the LuCnl promoter during seed development of single copy event from VC-RTP10690-1 qcz_F and VC-LTM217-1 qcz rc, which was present with VC-LJB2755-1 qcz. The other constructs lacked this particular d4Des. Figure 20: Comparative transcript analysis of d4Des(Tc_GA) driven by the ARC5 promoter during seed development of single copy event of four different construct combinations.
Figure 21 : Comparative transcript analysis of d4Des(Eg_GA) driven by the LuCnl promoter during seed development of single copy event of two different construct combinations; VC-LJB2755- 2qcz, VC-LLM391-2qcz rc and VC-LJB2197-1 qcz, VC-LLM337-1 qcz rc. Figure 22: Half Kernel Analysis of segregating T1 seeds of Event LANPMZ. A total of 288 seedlings where analysed. 71 of those seedlings were found to produce no significant amount of VLC-PUFA (dark grey diamonds) while containing >49% Oleic acid and <28% Linoleic acid. 71 seed of 288 seed correspond to 24.65% of the total analysed seed. All remaining seed were
capable of producing DHA, indicating the presence of both T-DNA from construct VC-LJB2197- 1 qcz and VC-LLM337-1 qcz rc. Among those seeds producing DHA, one can discriminate a group of 146 seeds showing medium VLC-PUFA levels (open diamonds), and a group of 71 seed showing high VLC-PUFA levels (light grey diamonds). The ratios of these three groups is 71 :146:71 , which corresponds to the Medelain 1 :2:1 ratio (NULL:HETEROZYGOUS:HOMOZYGOUS) expected for a phenotype when all genes conveying this phenotype (in this case the two T-DNAs of plasmid VC-LJB2197-1 qcz and VC-LLM337-1 qcz rc) integrated into one locus in the genome. Figure 23: Half Kernel Analysis of segregating T1 seeds of Event LBDIHN. A total of 288 seedlings where analysed. The levels of first substrate fatty acid of the pathway was plotted on the x-axis, the levels of the sum of two products of the pathways (EPA+DHA) was plotted on the y-axis. One can clearly see three clusters, where the ratio of the number of seeds in the these three clusters was 1 :2:1 (Homozygous:Heterozygous:Null segregant). This segregation of the phenotype according to the first Mendelian law demonstrates a single locus insertion of the T-DNA of construct RTP10690-1 qcz_F into the genome of B.napus cv Kumily.
Figure 24: Examples of Desaturase Enzyme Activity Heterologously Expressed in Yeast.
[14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using Instant Imager. In panel A Delta-12 Desaturase (Ps), c-d12Des(Ps_GA), activity was demonstrated by comparison of enzyme activity present in yeast microsomes isolated from a strain expressing the c-d12Des(Ps_GA) protein relative to microsomes isolated from a control strain containing an empty vector (VC). In panel B Omega-3 Desaturase activities, c-o3Des(Pir_GA) and c- o3Des(Pi_GA2), activities were demonstrated by comparison of enzyme activity from yeast microsomes isolated from strains expressing c-o3Des(Pir_GA) protein, c-o3Des(Pi_GA2) protein or an empty vector (VC) control. In panel C Delta-4 Desaturase (Tc), c-d4Des(Tc_GA), activity was demonstrated by comparison of enzyme activity from yeast microsomes isolated from a strain expressing the c-d4Des(Tc_GA) protein relative to microsomes isolated from a control strain containing an empty vector (VC). In panel D Delta-4 Desaturase (PI), c-d4Des(PI_GA)2, activity was demonstrated by comparison of enzyme activity from yeast microsomes isolated from a strain expressing the c-d4Des(PI_GA)2 protein relative to microsomes isolated from a control strain containing an empty vector (VC). Figure 25: Examples of Desaturase Enzyme Activity in transgenic Brassica napus. [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using Instant Imager. In panel A Delta-12 Desaturase (Ps), c-d12Des(Ps_GA), activity was demonstrated by comparison of enzyme activity from yeast microsomes isolated from a strain expressing the c- d12Des(Ps_GA) protein relative to microsomes isolated from transgenic B. napus containing the d12Des(Ps_GA2) gene. In panel B Delta-4 Desaturase (Tc), c-d4Des(Tc_GA), and Delta-4 Desaturase (PI) activities were demonstrated by comparison of enzyme activity from yeast
microsomes isolated from a strain expressing the c-d4Des(Tc_GA) protein relative to microsomes isolated from transgenic B. napus containing the d4Des(Tc_GA3) and d4Des(PI_GA)2 genes.
Figure 26: Examples of Desaturase Enzyme Reactions Showing Specificity for Acyl-lipid substrates. [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions containing microsomes obtained from a yeast strain expressing the protein of interest, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using Instant Imager. In panel A Delta-12 Desaturase (Ps), c-d12Des(Ps_GA), desaturated enzyme products were only detected in the phosphatidylcholine fraction indicating the enzyme was specific for an acyl-lipid substrate. In panel B and panel C Delta-4 Desaturase (Tc), c- d4Des(Tc_GA), desaturated enzyme products were detected in the phosphatidylcholine fraction indicating the enzyme was specific for an acyl-lipid substrate. In panel D a time-course demonstrates the activity of the Delta-4 Desaturase (Tc), c-d4Des(Tc_GA). Figure 27: Examples of Desaturase Enzyme Reactions Showing Specificity for Acyl-CoA substrates. [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions containing microsomes obtained from a yeast strain expressing the protein of interest, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using Instant Imager. In panel A PC was in situ labeled with substrate according to the method for determining lipid linked desaturation. Delta-9 Desaturase (Sc), d9D(Sc), desaturated enzyme products were very low in the phosphatidylcholine fraction, except for in the control reaction (none in situ labeled PC), indicating the enzyme cannot desaturate an acyl-lipid substrate. In panel B and C the incubation was done according to the method for determining acyl-CoA linked desaturation. In panel B the amount of radioactivity in the acyl-CoA fraction (MeOH/H20-phase, called nmol 16:1 in H20) was increasing when 20:1-CoA was added to the assay. This indicates that the added 20:1-CoA was competing with the radioactive substrate in formation of PC and free fatty acids. In panel C the amount of desaturated enzyme products was increased in the acyl- CoA fraction when 20:1-CoA was added to the assay, indicating that the desaturation was acyl- CoA linked.
Figure 28: Examples of Elongase Enzyme Activity Heterologously Expressed in Yeast. [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using Instant Imager. All FAME'S shown had similar Rf's as authentic standards. In the absence of [14C]malonyl-CoA no radioactive fatty acids were observed in any of these elongase reactions. In panel A delta-6 elongase (Tp), c-d6Elo(Tp_GA2), activity was demonstrated by comparison of enzyme activity present in yeast microsomes isolated from a strain expressing the c- d6Elo(Tp_GA2) protein relative to microsomes isolated from a control strain containing an empty vector (VC). In panel B, delta-6 elongase (Pp), c-d6Elo(Pp_GA2), was demonstrated by comparison of enzyme acitivity from yeast microsomes isolated from a strains expressing c- d6Elo(Pp_GA2) protein to microsomes isolated from a control strain containing an empty vector (VC), as shown in panel A. In panel C, delta-5 elongase (Ot), c-d5Elo(Ot_GA3), activity was demonstrated by comparison of enzyme activity present in yeast microsomes isolated from a
strain expressing the d5E(0t) protein relative to microsomes isolated from a control strain containing an empty vector (VC).
Figure 29: Examples of Elongase Activity in transgenic Brassica napus. [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using Instant Imager. In panel A Delta-6 Elongase activity was demonstrated by comparison of enzyme activity from yeast microsomes isolated from a strain expressing the d6E(Pp_GA2) protein relative to microsomes isolated from transgenic B. Napus containing the c-d6Elo(Pp_GA2) gene and the c- d6Elo(Tp_GA2) gene. In panel B the Delta-5 Elongase (Ot), d5Elo(Ot_GA3), activity was demonstrated by comparison of enzyme activity from yeast microsomes isolated from a strain expressing the c-d5Elo(Ot_GA3) protein relative to microsomes isolated from transgenic B. Napus containing the d5Elo(Ot_GA3) and a wild-type B. napus (control). Figure 30: Time course optimization.Yeast cells expressing the c-d5Des(Tc_GA2) were fed with 0.25 mM DHGLA and the production of ARA was determined by GC. Samples were collected starting immediately after feeding. In Panels A-D, Desaturation was represented as %Conversion vs Growth Time (hours) and Product and Substrate levels are represented as %Total Fatty acid vs Growth time (hours). Panel A pertains to samples supplied with DHGLA immediately after induction. Panel B is overnight induction (22hrs) before feeding. Panel C is for cultures supplied with 3X normal DHGLA level. Panel D is for cultures supplied with normal rate of DHGLA (0.25 mM) daily.
Figure 31 : Representative time course graphs for all desaturases and elongases. Yeast cells expressing each enzyme were supplied with 0.25 mM of preferred fatty acid substrate, and fatty acid profiles were obtained by GC at the indicated time points. In Panels A-J, Desaturation and Elongation were represented as %Conversion vs Growth Time (hours), and Product and Substrate levels were represented as %Total Fatty acid vs Growth time (hours).A. c- d5Des(Tc_GA2) + DHGLA B. c-d6Des(Ot_febit) + ALA C. c-d4Des(PI_GA)2 + DTA D. c- d4Des(Tc_GA) + DTA E. c-o3Des(Pir_GA) + ARA F. c-o3Des(Pi_GA2) + ARA G. c- d12Des(Ps_GA) + OA H. c-d5Elo(Ot_GA3) + EPA I. c-d6Elo(Tp_GA2) + GLA J. c-d6Elo(Pp_GA2) + SDA.
Figure 32: Conversion efficiencies of delta-12-desaturation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. Shown are average conversion efficiencies of various plant populations, as well as the conversion efficiencies observed in a seedbacth of event LBFDAU having highest EPA+DHA levels, and those efficiencies observed in a single seed of that seedbatch, where this single seed had highest EPA+DHA levels among all 95 measured single seeds. Data were taken from Example 10 to Example 18. TO and T1 designates the plant generation producing the seeds (all grown in the greenhouse except for the two LBFDAU data points)
Figure 33: Conversion efficiencies of delta-6-desaturation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
Figure 34: Conversion efficiencies of delta-6-elongation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
Figure 35: Conversion efficiencies of delta-5-desaturation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details. Figure 36: Conversion efficiencies of omega-3 desaturation (excluding C18 fatty acids) in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
Figure 37: Conversion efficiencies of omega-3 desaturation (including C18 fatty acids) in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
Figure 38: Conversion efficiencies of delta-5-elongation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
Figure 39: Conversion efficiencies of delta-4-desturation in seed of transgenic Brassica napus and in Brassica napus wildtype seeds. See caption in Figure 32 for further details.
Figure 40: The sum of all pathway fatty acids was negatively correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 41 : The sum of all pathway fatty acids was negatively correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 42: The sum of all pathway fatty acids was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
Figure 43: The sum of all pathway fatty acids was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2
seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot. Figure 44: The conversion efficiency of the delta-12-desaturase was negatively correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seed batch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot. Figure 45: The conversion efficiency of the delta-12-desaturase was negatively correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seed batch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot. Figure 46: The conversion efficiency of the delta-12-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
Figure 47: The conversion efficiency of the delta-12-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
Figure 48: The conversion efficiency of the delta-6-desaturase was negatively correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 49: The conversion efficiency of the delta-6-desaturase was negatively correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 50: The conversion efficiency of the delta-6-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis
of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
Figure 51 : The conversion efficiency of the delta-6-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
Figure 52: The conversion efficiency of the delta-6 elongase was not negatively correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 53: The conversion efficiency of the delta-6 elongase was not negatively correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 54: The conversion efficiency of the delta-6 elongase was not negatively correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
Figure 55: The conversion efficiency of the delta-6 elongase was not negatively correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot. Figure 56: The conversion efficiency of the delta-5-desaturase was not correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot. Figure 57: The conversion efficiency of the delta-5-desaturase was not correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 58: The conversion efficiency of the delta-5-desaturase was not correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
Figure 59: The conversion efficiency of the delta-5-desaturase was not correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
Figure 60: The conversion efficiency of the omega-3-desaturase was not correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 61 : The conversion efficiency of the omega-3-desaturase was not correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 62: The conversion efficiency of the omega-3-desaturase was not correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
Figure 63: The conversion efficiency of the omega-3-desaturase was not correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot. Figure 64: The conversion efficiency of the delta-5-elongase was not correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 65: The conversion efficiency of the delta-5-elongase was not correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 66: The conversion efficiency of the delta-5-elongase was not correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
Figure 67: The conversion efficiency of the delta-5-elongase was not correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing one plot.
Figure 68: The conversion efficiency of the delta-4-desaturase was negatively correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 69: The conversion efficiency of the delta-4-desaturase was negatively correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 70: The conversion efficiency of the delta-4-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
Figure 71 : The conversion efficiency of the delta-4-desaturase was negatively correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
Figure 72: The sum of all pathway fatty acids was not correlated with seed oil content in wildtype canola, but differs between greenhouse and field. Shown are data of three seasons. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 73: The total fatty acid percentage of 20:5n-3 (EPA) correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 74: The total fatty acid percentage of 20:5n-3 (EPA) correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 75: The total fatty acid percentage of 20:5n-3 (EPA) correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2 seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants).
Figure 76: The total fatty acid percentage of 20:5n-3 (EPA) correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
Figure 77: The total fatty acid percentage of 22:6n-3 (DHA) correlated with seed oil content. Shown are data of 3 generations of event LANPMZ. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 78: The total fatty acid percentage of 22:6n-3 (DHA) correlated with seed oil content. Shown are data of 4 generations of event LAODDN. For the greenhouse data, one marker corresponds to one seedbatch of one plant, for the field data, one marker corresponds to an analysis on a random selection of seeds representing one plot.
Figure 79: The total fatty acid percentage of 22:6n-3 (DHA) correlated with seed oil content. Shown are data of 2 generations of event LBFGKN. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 50 T2
seedbatches, or 182 T3 seedbatches, for the field data, one marker corresponds to an analysis of one T2 seedbtach of one T1 plant, or the analysis of a random selection of T3 seeds representing plots (36 plots) or single plants (60 plants). Figure 80: The total fatty acid percentage of 22:6n-3 (DHA) correlated with seed oil content. Shown are data of 2 generations of event LBFLFK. For the greenhouse data, one marker corresponds to the analysis of a random selection of seeds representing a bulk of 10 T2 seedbatches, or 195 T3 seedbatches, for the field data, one marker corresponds to an analysis of 1 T2 seedbtach of one T1 plant, or a the analysis of a random selection of T3 seeds representing one plot.
Figure 81 : The levels of EPA+DHA (20:5n-3 and 22:6n-3) correlated with seed oil content. Shown are data of homozygous plants (single plant: capital G or F, plots: lower case f, grown in greenhouses: G, grown in field trials: f and F). The data are described in more detail in Example 12 (event LANBCH), and Example 14 (all other events).
Figure 82: The levels of ARA (20:4n-6) correlated with seed oil content. Shown are data of homozygous plants (single plant: capital G or F, plots: lower case f, grown in greenhouses: G, grown in field trials: f and F). The data are described in more detail in Example 12 (event LANBCH), and Example 14 (all other events).
Figure 83: The levels of EPA (20:5n-3) correlated with seed oil content. Shown are data of homozygous plants (single plant: capital G or F, plots: lower case f, grown in greenhouses: G, grown in field trials: f and F). The data are described in more detail in Example 12 (event LANBCH), and Example 14 (all other events).
Figure 84: The levels of DHA (22:6n-3) correlated with seed oil content. Shown are data of homozygous plants (single plant: capital G or F, plots: lower case f, grown in greenhouses: G, grown in field trials: f and F). The data are described in more detail in Example 12 (event LANBCH), and example 14 (all other events).
Figure 85. Examples of Desaturase Enzyme Activity in Transgenic Brassica napus. [14C]Fatty acid methyl esters (ME's) were isolated from the enzymatic reactions, resolved by TLC as described for each specific enzyme and detected by electronic autoradiography using an Instant Imager. Duplicate reactions are shown for each enzyme activity in Panels A-C. In Panel A delta- 6 desaturase (Ostreococcus tauri) activity was demonstrated by the presence of [14C]18:3n-6 ME using membranes isolated from transgenic Brassica napus. This desaturase activity was not present in membranes derived from a wild-type (Kumily) B. napus. In Panel B delta-5 desaturase (Thraustochytrium ssp.) activity was demonstrated by the presence of [14C]20:4n-6 ME using membranes isolated from transgenic Brassica napus. This desaturase activity was not present in membranes derived from a wild-type (Kumily) B. napus. In Panel C omega-3 desaturase activity was demonstrated by the presence of [14C]20:5n-3 ME using membranes isolated from
transgenic Brassica napus. This desaturase activity was not present in membranes derived from a wild-type (Kumily) B. napus.
Figure 86. Delta-12 desaturase (Phytophthora sojae), c-d12Des(Ps_GA), substrate preference. During the course of the enzymatic reaction the following lipid pools were isolated: phosphatidylcholine (PC, ■), free fatty acid (FFA, · ), and H20 (CoA, o). |n Panel A c- d12Des(Ps_GA) enzyme activity is shown using assay conditions to present the fatty acid substrate (18:1 (n-9)) in the acyl-phosphatidylcholine form. Desaturated enzymatic product (18:2(n-6)) is found predominantly in the phosphatidylcholine (PC) pool, relative to the free fatty acid (FFA) or H20 (CoA) pools, indicating c-d12Des(Ps_GA) utilizes 18:1 (n-9) attached to phosphatidylcholine as a substrate. In Panel B c-d12Des(Ps_GA) enzyme activity is shown using assay conditions to present the fatty acid substrate (18:1 (n-9)) in the acyl-CoA form. Relative to Panel A, desaturated enzymatic product (18:2(n-6)) is not produced in the phosphatidylcholine (PC), free fatty acid (FFA) or H20 (CoA) pools indicating c-d12Des(Ps_GA) does not utilize 18:1 (n-9) bound as an acyl-CoA ester.
Figure 87. Delta-9 desaturase (Saccharomyces cerevisiae), d9Des(Sc) substrate preference. During the course of the enzymatic reaction the following lipid pools were isolated: phosphatidylcholine (PC,■), free fatty acid (FFA, · ), and H20 (CoA, o). |n Panel A d9Des(Sc) enzyme activity is shown using assay conditions to present the fatty acid substrate (16:0) in the acyl-phosphatidylcholine form. Relative to Panel B, desaturated enzymatic product (16:1 (n-7)) is not produced in the phosphatidylcholine (PC), free fatty acid (FFA), or H20 (CoA) pools indicating d9Des(Sc) does not utilize 18:0 attached to phosphatidylcholine as a substrate. In Panel B d9Des(Sc) enzyme activity is shown using assay conditions to present the fatty acid substrate (16:0) in the acyl-CoA form. Desaturated enzymatic product (16:1 (n-7)) is isolated in both the free fatty acid (FFA) and H20 (CoA) pools, but not the phosphatidylcholine (PC) pool. Furthermore, production of the desaturated enzymatic product (16:1 (n-7)) in the H20 (CoA) pool is linear for the first 60 minutes of the assay as shown by the hashed line (r2 = 0.99). The high levels of [14C]16:1 (n-7) detected in the FFA pool likely result from hydrolysis of the desaturated enzymatic product, 16:1 (n-7)-CoA, by endogenous thioesterases present in the membrane preparations.
Figure 88. Yield (kg seeds/ha) of canola plants grown in the field in 2014. Plants were either not treated (Yield) or were treated with 2x rate of imidazolinone herbicide (Yield w/herbicide). Figure 89. EPA plus DHA content in seeds of plants grown in the field with (Imazamox) or without (control) herbicide treatment. *** denotes a significant difference between herbicide treatment and control as calculated by ANOVA, p<0.05.
Figure 90. Oil content in seeds of plants grown in the field with (Imazamox) or without (control) herbicide treatment. *** denotes a significant difference between herbicide treatment and control as calculated by ANOVA, p<0.05.
Figure 91. Protein content in seeds of plants grown in the field with (Imazamox) or without (control) herbicide treatment. *** denotes a significant difference between herbicide treatment and control as calculated by ANOVA, p<0.05. Figure 92: is a map of binary transformation vector VC-LTM593-1 qcz rc, used to generate Brassica plants comprising event LBFLFK and Brassica plants comprising event LBFDAU.
Figure 93 shows the organization T-DNA locus 1 in the genome of a plant comprising Brassica event LBFLFK. SEQ ID NO:282 corresponds to the junction region of the Locus 1 T-DNA insert SEQ ID NO:281 and the right border flanking sequence SEQ ID NO:284. SEQ ID NO:283 corresponds to the junction region between the Locus 1 T-DNA insert SEQ ID NO:281 and left border flanking sequence SEQ ID NO:285.
Figure 94 shows the organization of T-DNA Locus 2 in the genome of a plant comprising Brassica event LBFLFK. SEQ ID NO:291 corresponds to the junction region of the Locus 2 T-DNA insert SEQ ID NO:290 and the right border flanking sequence SEQ ID NO:293. SEQ ID NO:292 corresponds to the junction region of the Locus 2 T-DNA insert SEQ ID NO:290 and left border flanking sequence SEQ ID NO:294. Figure 95 shows the organization of T-DNA Locus 1 in the genome of a plant comprising Brassica event LBFDAU. SEQ ID NO:300 corresponds to the junction region of the Locus 1 T-DNA insert SEQ ID NO:299 and the right border flanking sequence SEQ ID NO:302. SEQ ID NO:301 corresponds to the junction region of the Locus 1 T-DNA insert SEQ ID NO:299 and left border flanking sequence SEQ ID NO:303.
Figure 96 shows the organization of T-DNA Locus 2 in the genome of a plant comprising Brassica event LBFDAU. SEQ ID NO:309 corresponds to the junction region of the Locus 2 T-DNA insert SEQ ID NO:308 and the right border flanking sequence SEQ ID NO:31 1 . SEQ ID NO:310 corresponds to the junction region of the Locus 2 T-DNA insert SEQ ID NO:308 and left border flanking sequence SEQ ID NO:312.
Figure 97 shows the EPA and DHA content of bulked seed batches produced in the field and in the greenhouse from event LBFLFK. Figure 98 shows the EPA and DHA content of bulked seed batches produced in the field and in the greenhouse from event LBFDAU.
Figure 99 shows the distribution of combined EPA plus DHA content in 95 T2 single seeds of event LBFDAU.
SECTION A: MATERIALS AND METHODS FOR PUFA PRODUCTION, AND PUFA- CONTAINING COMPOSITIONS
FIELD OF THE INVENTION (for the invention described in Section A)
The invention generally pertains to the field of manufacture of fatty acids, particularly for large- scale production of very long chain polyunsaturated fatty acids (VLC-PUFAs, also called polyunsaturated fatty acids or PUFAs), e.g. eicosapentaenoic acid (EPA), omega-3 docosapentaenoic acid (DPA) and docosahexaenoic acid (DHA). The invention particularly is concerned with the production of VLC-PUFAs in plants and thus inter alia provides nucleic acids for transformation of plants to enable such transformed plants to produce VLC-PUFAs. To this end, the invention also provides transgenic constructs and expression vectors containing desaturase and elongase genes and host cells into which the constructs and expression vectors have been introduced. The present invention also relates to methods for the manufacture of oil, fatty acid- or lipids-containing compositions, and to such oils and lipids as such. In addition, the invention is concerned with methods for further improving the production of VLC-PUFAs in plants.
BACKGROUND OF THE INVENTION (for the invention described in Section A)
Fatty acids are carboxylic acids with long-chain hydrocarbon side groups that play a fundamental role in many biological processes. Fatty acids are rarely found free in nature but, rather, occur in esterified form as the major component of lipids. As such, lipids/fatty acids are sources of energy (e.g., beta-oxidation). In addition, lipids/fatty acids are an integral part of cell membranes and, therefore, are indispensable for processing biological or biochemical information.
Long chain polyunsaturated fatty acids (VLC-PUFAs) such as docosahexaenoic acid (DHA, 22:6(4,7,10,13,16,19)) are essential components of cell membranes of various tissues and organelles in mammals (nerve, retina, brain and immune cells). Clinical studies have shown that DHA is essential for the growth and development of the brain in infants, and for maintenance of normal brain function in adults (Martinetz, M. (1992) J. Pediatr. 120:S129 S138). DHA also has significant effects on photoreceptor function involved in the signal transduction process, rhodopsin activation, and rod and cone development (Giusto, N.M., et al. (2000) Prog. Lipid Res. 39:315-391 ). In addition, some positive effects of DHA were also found on diseases such as hypertension, arthritis, atherosclerosis, depression, thrombosis and cancers (Horrocks, L.A. and Yeo, Y.K. (1999) Pharmacol. Res. 40:21 1-215). Therefore, appropriate dietary supply of the fatty acid is important for human health. Because such fatty acids cannot be efficiently synthesized by infants, young children and senior citizerns, it is particularly important for these individuals to adequately intake these fatty acids from the diet (Spector, A.A. (1999) Lipids 34:S1 S3).
EPA (20:5n-3 5,8,1 1 ,14,17) and also ARA (arachidonic acid, 20:4n-6 (5,8,1 1 ,14)) are both delta 5 (d5) essential fatty acids. They form a unique class of food and feed constituents for humans and animals. EPA belongs to the n-3 series with five double bonds in the acyl chain. EPA is found in marine food and is abundant in oily fish from North Atlantic. ARA belongs to the n-6 series with four double bonds. The lack of a double bond in the omega-3 position confers on ARA different properties than those found in EPA. The eicosanoids produced from ARA (sometimes abbreviated "AA") have strong inflammatory and platelet aggregating properties, whereas those
derived from EPA have anti-inflammatory and anti-platelet aggregating properties. ARA can be obtained from some foods such as meat, fish and eggs, but the concentration is low.
Gamma-linolenic acid (GLA, C18:3n-6 (6,9,12)) is another essential fatty acid found in mammals. GLA is the metabolic intermediate for very long chain n-6 fatty acids and for various active molecules. In mammals, formation of long chain polyunsaturated fatty acids is rate-limited by delta-6 desaturation. Many physiological and pathological conditions such as aging, stress, diabetes, eczema, and some infections have been shown to depress the delta-6 desaturation step. In addition, GLA is readily catabolized from the oxidation and rapid cell division associated with certain disorders, e.g., cancer or inflammation. Therefore, dietary supplementation with GLA can reduce the risks of these disorders. Clinical studies have shown that dietary supplementation with GLA is effective in treating some pathological conditions such as atopic eczema, premenstrual syndrome, diabetes, hypercholesterolemia, and inflammatory and cardiovascular disorders.
A large number of benefitial health effects have been shown for DHA or mixtures of EPA and DHA.
Although biotechnology offers an attractive route for the production of specialty fatty acids, current techniques fail to provide an efficient means for the large scale production of unsaturated fatty acids. Accordingly, there exists a need for an improved and efficient method of producing very long chain poly unsaturated fatty acids (VLC-PUFAs), such as EPA and DHA.
The current commercial source of EPA and DHA is fish oil. However, marine stocks are diminishing as a result of over-fishing, and alternative sustainable sources of EPA and DHA are needed to meet increasing demand. Numerous efforts have been made to develop transgenic oilseed plants that produce VLC-PUFAs, including EPA and DHA. See, e.g., WO 2004/071467, WO 2013/185184, WO 2015/089587, Ruiz-Lopez, et al. (2014) Plant J. 77, 198-208. However, no transgenic oilseed plant has been commercialized which produces EPA and DHA at commercially relevant levels.
To make possible the fortification of food and/or of feed with polyunsaturated omega-3-fatty acids, there is still a great need for a simple, inexpensive process for the production of each of the aforementioned long chain polyunsaturated fatty acids, especially in eukaryotic systems.
SUMMARY OF THE INVENTION (for the invention described in Section A)
The invention is thus concerned with providing a reliable source for easy manufacture of VLC- PUFAs. To this end the invention is also concerned with providing plants reliably producing VLC- PUFAS, preferably EPA and/or DHA. The invention is also concerned with providing means and methods for obtaining, improving and farming such plants, and also with VLC-PUFA containing oil obtainable from such plants, particularly from the seeds thereof. Also, the invention provides uses for such plants and parts thereof.
According to the invention there is thus provided a T-DNA for expression of a target gene in a plant. The invention beneficially provides a system for transformation of plant tissue and for generation of recombinant plants, wherein the recombinant plant differs from the respective parental plant (for the purposes of the present invention the parental plant is termed a wild-type plant regardless of whether or not such parental plant is as such found in nature) by the introduction of T-DNA. The T-DNA introduced into the parental plant beneficially has a length of at least 30000 nucleotides.
The invention also provides plants with a genotype that confers a heritable phenotype of high seed oil VLC-PUFA content in one or more of their tissues or components, preferably a high content of EPA and/or DHA in seed oil. The invention further provides material comprising a high VLC-PUFA content relative to their total oil content, preferably a high content of EPA and/or DHA. Also, the invention provides exemplary events of Brassica plants. Most beneficially the invention provides oil comprising a high VLC-PUFA content, preferably a high content of EPA and/or DHA.
The invention also provides methods of producing an oil, wherein the oil has a high VLC-PUFA content, a high content of EPA and/or DHA. In particularly preferred aspects these methods are for producing a corresponding plant oil. Thus, invention also provides methods of producing an oil.
The invention also provides methods for creating a plant, such that the plant or progeny thereof can be used as a source of an oil, wherein the oil has a high VLC-PUFA content, a high content of EPA and/or DHA. Thus, the invention beneficially also provides methods for the production of plants having a heritable phenotype of high seed oil VLC-PUFA content in one or more of their tissues or components, preferably a high content of EPA and/or DHA in seed oil.
The present invention also provides a method for increasing the content of Mead acid (20:3n-9) in a plant relative to a control plant, comprising expressing in a plant, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase.
The invention also provides means for optimizing a method for creating plants according to the invention. In this respect, the invention provides a system of methods for analyzing enzyme specificities, particularly for analyzing desaturase reaction specificity and for analyzing elongase specificities, for optimization of a metabolic pathway and for determining CoA-dependence of a target desaturase.
BRIEF DESCRIPTION OF THE SEQUENCES
For a further description of some sequences mentioned in this Section A, please be referred to the corresponding description in Section B ".BRIEF DESCRIPTION OF THE SEQUENCES". Thus, the description provided in Section B "BRIEF DESCRIPTION OF THE SEQUENCES" below for these sequences shall also apply to the sequences of this Section A.
DETAILED DESCRIPTION OF THE INVENTION (for the invention described in Section A)
Various aspects of the invention are hereinafter described in more detail. It is to be understood that the detailed description is not intended to limit the scope of the claims. The term "polyunsaturated fatty acids (PUFA)" as used herein refers to fatty acids comprising at least two, preferably, three, four, five or six, double bonds. Moreover, it is to be understood that such fatty acids comprise, preferably from 18 to 24 carbon atoms in the fatty acid chain. More preferably, the term relates to long chain PUFA (VLC-PUFA) having from 20 to 24 carbon atoms in the fatty acid chain. Particularly, polyunsaturated fatty acids in the sense of the present invention are DHGLA 20:3 (8,1 1 ,14), ARA 20:4 (5,8,1 1 ,14), ETA 20:4 (8,1 1 ,14,17), EPA 20:5 (5,8,1 1 ,14,17), DPA 22:5 (4,7,10,13,16), DPA n-3 (7,10,13,16,19), DHA 22:6 (4,7,10,13,16,19), more preferably, eicosapentaenoic acid (EPA) 20:5 (5,8,1 1 ,14,17), and docosahexaenoic acid (DHA) 22:6 (4,7,10,13,16,19). Thus, it will be understood that most preferably, the methods provided by the present invention pertaining to the manufacture of EPA and/or DHA. Moreover, also encompassed are the intermediates of VLC-PUFA which occur during synthesis. Such intermediates are, preferably, formed from substrates by the desaturase, keto-acyl-CoA- synthase, keto-acyl-CoA-reductase, dehydratase and enoyl-CoA-reductase activity of the polypeptide of the present invention. Preferably, substrates encompass LA 18:2 (9,12), GLA 18:3 (6,9,12), DHGLA 20:3 (8,1 1 ,14), ARA 20:4 (5,8,1 1 ,14), eicosadienoic acid 20:2 (1 1 ,14), eicosatetraenoic acid 20:4 (8,1 1 ,14,17), eicosapentaenoic acid 20:5 (5,8,1 1 ,14,17). Systematic names of fatty acids including polyunsaturated fatty acids, their corresponding trivial names and shorthand notations used according to the present invention are given in table Table 18 (and in table 181 ). The transgenic plants of this invention produce a number of VLC-PUFA and intermediates that are non-naturally occurring in wild type Brassica plants. While these VLC- PUFA and intermediates may occur in various organisms, they do not occur in wild type Brassica plants. These fatty acids include 18:2n-9, GLA, SDA, 20:2n-9, 20:3n-9, 20:3 n-6, 20:4n-6, 22:2n- 6, 22:5n-6, 22:4n-3, 22:5n-3, and 22:6n-3.
The term "cultivating" as used herein refers to maintaining and growing the transgenic plant under culture conditions which allow the cells to produce the said polyunsaturated fatty acids, i.e. the PUFAs and/or VLC-PUFAs referred to above. This implies that the polynucleotide of the present invention is expressed in the transgenic plant so that the desaturase, elongase as also the keto- acyl-CoA-synthase, keto-acyl-CoA-reductase, dehydratase and enoyl-CoA-reductase activity is present. Suitable culture conditions for cultivating the host cell are described in more detail below. The term "obtaining" as used herein encompasses the provision of the cell culture including the host cells and the culture medium or the plant or plant part, particularly the seed, of the current invention, as well as the provision of purified or partially purified preparations thereof comprising the polyunsaturated fatty acids, preferably, ARA, EPA, DHA, in free or in CoA bound form, as membrane phospholipids or as triacylglyceride esters. More preferably, the PUFA and VLC-PUFA are to be obtained as triglyceride esters, e.g., in form of an oil. More details on purification techniques can be found elsewhere herein below.
The term "polynucleotide" according to the present invention refers to a desoxyribonucleic acid or ribonucleic acid. Unless stated otherwise, "polynucleotide" herein refers to a single strand of a DNA polynucleotide or to a double stranded DNA polynucleotide. The length of a polynucleotide is designated according to the invention by the specification of a number of basebairs ("bp") or nucleotides ("nt"). According to the invention, both specifications are used interchangeably, regardless whether or not the respective nucleic acid is a single or double stranded nucleic acid. Also, as polynucleotides are defined by their respective nucleotide sequence, the terms nucleotide/polynucleotide and nucleotide sequence/polynucleotide sequence are used interchangeably, thus that a reference to a nucleic acid sequence also is meant to define a nucleic acid comprising or consisting of a nucleic acid stretch the sequence of which is identical to the nucleic acid sequence.
In particular, the term "polynucleotide" as used in accordance with the present invention as far as it relates to a desaturase or elongase gene relates to a polynucleotide comprising a nucleic acid sequence which encodes a polypeptide having desaturase or elongase activity. Preferably, the polypeptide encoded by the polynucleotide of the present invention having desaturase, or elongase activity upon expression in a plant shall be capable of increasing the amount of PUFA and, in particular, VLC-PUFA in, e.g., seed oils or an entire plant or parts thereof. Whether an increase is statistically significant can be determined by statistical tests well known in the art including, e.g., Student's t-test with a confidentiality level of at least 90%, preferably of at least 95% and even more preferably of at least 98%. More preferably, the increase is an increase of the amount of triglycerides containing VLC-PUFA of at least 5%, at least 10%, at least 15%, at least 20% or at least 30% compared to wildtype control (preferably by weight), in particular compared to seeds, seed oil, extracted seed oil, crude oil, or refined oil from a wild-type control. Preferably, the VLC-PUFA referred to before is a polyunsaturated fatty acid having a C20, C22 or C24 fatty acid body, more preferably EPA or DHA. Lipid analysis of oil samples are shown in the accompanying Examples.
Preferred polynucleotides encoding polypeptides having desaturase or elongase activity as shown in Table 130 in the Examples section of Section A (the SEQ ID Nos of the nucleic acid sequences and the polypeptide sequences are given in the last two columns).
In the plants of the present invention, in particular in the oil obtained or obtainable from the plant of the present invention, the content of certain fatty as shall be decreased or, in particular, increased as compared to the oil obtained or obtainable from a control plant. In particular decreased or increased as compared to seeds, seed oil, crude oil, or refined oil from a control plant. The choice of suitable control plants is a routine part of an experimental setup and may include corresponding wild type plants or corresponding plants without the polynucleotides as encoding desaturases and elongase as referred to herein. The control plant is typically of the same plant species or even of the same variety as the plant to be assessed. The control plant may also be a nullizygote of the plant to be assessed. Nullizygotes (or null control plants) are individuals missing the transgene by segregation. Further, control plants are grown under the same or essentially the same growing conditions to the growing conditions of the plants of the
invention, i.e. in the vicinity of, and simultaneously with, the plants of the invention. A "control plant" as used herein preferably refers not only to whole plants, but also to plant parts, including seeds and seed parts. The control could also be the oil from a control plant. Preferably, the control plant is an isogenic control plant. Thus, e.g. the control oil or seed shall be from an isogenic control plant.
The fatty acid esters with polyunsaturated C20- and/or C22-fatty acid molecules can be isolated in the form of an oil or lipid, for example, in the form of compounds such as sphingolipids, phosphoglycerides, lipids, glycolipids such as glycosphingolipids, phos-pholipids such as phosphatidylethanolamine, phosphatidylcholine, phosphatidylserine, phosphatidylglycerol, phosphatidylinositol or diphosphatidylglycerol, monoacylglycerides, diacylglycerides, triacylglycerides or other fatty acid esters such as the acetylcoenzyme A esters which comprise the polyunsaturated fatty acids with at least two, three, four, five or six, preferably five or six, double bonds, from the organisms which were used for the preparation of the fatty acid esters. Preferably, they are isolated in the form of their diacylglycerides, triacylglycerides and/or in the form of phosphatidylcholine, especially preferably in the form of the triacylglycerides. In addition to these esters, the polyunsaturated fatty acids are also present in the non-human transgenic organisms or host cells, preferably in the plants, as free fatty acids or bound in other compounds. As a rule, the various abovementioned compounds (fatty acid esters and free fatty acids) are present in the organisms with an approximate distribution of 80 to 90% by weight of triglycerides, 2 to 5% by weight of diglycerides, 5 to 10% by weight of monoglycerides, 1 to 5% by weight of free fatty acids, 2 to 8% by weight of phospholipids, the total of the various compounds amounting to 100% by weight. In the process of the invention, the VLC-PUFAs which have been produced are produced in a content as for DHA of at least 5,5% by weight, at least 6% by weight, at least 7% by weight, advantageously at least 8% by weight, preferably at least 9% by weight, especially preferably at least 10,5% by weight, very especially preferably at least 20% by weight, as for EPA of at least 9,5% by weight, at least 10% by weight, at least 1 1 % by weight, advantageously at least 12% by weight, preferably at least 13% by weight, especially preferably at least 14,5% by weight, very especially preferably at least 30% by weight based on the total fatty acids in the non- human transgenic organisms or the host cell referred to above. The fatty acids are, preferably, produced in bound form. It is possible, with the aid of the polynucleotides and polypeptides of the present invention, for these unsaturated fatty acids to be positioned at the sn1 , sn2 and/or sn3 position of the triglycerides which are, preferably, to be produced.
In a method or manufacturing process of the present invention the polynucleotides and polypeptides of the present invention may be used with at least one further polynucleotide encoding an enzyme of the fatty acid or lipid biosynthesis. Preferred enzymes are in this context the desaturases and elongases as mentioned above, but also a polynucleotide encoding an enzyme having delta-8-desaturase and/or delta-9-elongase activity. All these enzymes reflect the individual steps according to which the end products of the method of the present invention, for example EPA or DHA are produced from the starting compounds oleic acid (C18:1 ), linoleic acid (C18:2) or linolenic acid (C18:3). As a rule, these compounds are not generated as essentially
pure products. Rather, small traces of the precursors may be also present in the end product. If, for example, both linoleic acid and linolenic acid are present in the starting host cell, organism, or the starting plant, the end products, such as EPA or DHA, are present as mixtures. The precursors should advantageously not amount to more than 20% by weight, preferably not to more than 15% by weight, more preferably, not to more than 10% by weight, most preferably not to more than 5% by weight, based on the amount of the end product in question. Alternatively if, for example, appropriately all three oleic acid, linoleic acid and linolenic acid are present in the starting host cell, organism, or the starting plant, the end products, such as EPA or DHA, are present as mixtures. The precursors should advantageously not amount to more than 60% by weight, preferably not to more than 40% by weight, more preferably, not to more than 20% by weight, most preferably not to more than 10% by weight, based on the amount of the end product in question. Advantageously, only EPA or more preferably only DHA, bound or as free acids, is/are produced as end product(s) in the process of the invention in a host cell. If the compounds EPA and DHA are produced simultaneously, they are, preferably, produced in a ratio of at least 1 :2 (DHA:EPA), more preferably, the ratios are at least 1 :5 and, most preferably, 1 :8. Fatty acid esters or fatty acid mixtures produced by the invention, preferably, comprise 6 to 15% of palmitic acid, 1 to 6% of stearic acid, 7-85% of oleic acid, 0.5 to 8% of vaccenic acid, 0.1 to 1 % of arachidic acid, 7 to 25% of saturated fatty acids, 8 to 85% of monounsaturated fatty acids and 60 to 85% of polyunsaturated fatty acids, in each case based on 100% and on the total fatty acid content of the organisms. DHA as a preferred long chain polyunsaturated fatty acid is present in the fatty acid esters or fatty acid mixtures in a concentration of, preferably, at least 0.1 ; 0.2; 0.3; 0.4; 0.5; 0.6; 0.7; 0.8; 0.9 or 1 %, based on the total fatty acid content.
Chemically pure VLC-PUFAs or fatty acid compositions can also be synthesized by the methods described herein. To this end, the fatty acids or the fatty acid compositions are isolated from a corresponding sample via extraction, distillation, crystallization, chromatography or a combination of these methods. These chemically pure fatty acids or fatty acid compositions are advantageous for applications in the food industry sector, the cosmetic sector and especially the pharmacological industry sector.
The term "desaturase" encompasses all enzymatic activities and enzymes catalyzing the desaturation of fatty acids with different lengths and numbers of unsaturated carbon atom double bonds. Specifically this includes delta 4 (d4)-desaturase, catalyzing the dehydrogenation of the 4th and 5th carbon atom; Delta 5 (d5)-desaturase catalyzing the dehydrogenation of the 5th and 6th carbon atom; Delta 6 (d6)-desaturase catalyzing the dehydrogenation of the 6th and 7th carbon atom; Delta 8 (d8)-desaturase catalyzing the dehydrogenation of the 8th and 9th carbon atom; Deta 9 (d9)-desaturase catalyzing the dehydrogenation of the 9th and 10th carbon atom; Delta 12 (d12)-desaturase catalyzing the dehydrogenation of the 12th and 13th carbon atom; Delta 15 (d15)-desaturase catalyzing the dehydrogenation of the 15th and 16th carbon atom. An omega 3 (o3)-desaturase preferably catalyzes the dehydrogenation of the n-3 and n-2 carbon atom.
The terms "elongase" encompasses all enzymatic activities and enzymes catalyzing the elongation of fatty acids with different lengths and numbers of unsaturated carbon atom double bonds. Especially, the term "elongase" as used herein refers to the activity of an elongase, introducing two carbon molecules into the carbon chain of a fatty acid, preferably in the positions 1 , 5, 6, 9, 12 and/or 15 of fatty acids, in particular in the positions 5, 6, 9, 12 and/or 15 of fatty acids.
Moreover, the term "elongase" as used herein preferably refers to the activity of an elongase, introducing two carbon molecules to the carboxyl ends {i.e. position 1 ) of both saturated and unsaturated fatty acids.
In the studies underlying this invention, enzymes with superior desaturase and elongase catalytic activities for the production of VLC-PUFA has been provided. Tables 1 1 and 130 in the Examples section list preferred polynucleotides encoding for preferred desaturases or elongases to be used in the present invention. Thus, polynucleotides for desaturases or elongases that can be used in the context of the present invention are shown in Table 1 1 and 130, respectively. The SEQ ID NOs of these desaturases and elongases are shown in the last two columns of Table 130 (nucleic acid sequence and amino acid sequence). As set forth elsewhere herein, also variants of the said polynucleotides can be used.
Polynucleotides encoding polypeptides which exhibit delta-6-elongase activity have been described in WO2001/059128, WO2004/087902 and WO2005/012316, said documents, describing this enzyme from Physcomitrella patens, are incorporated herein in their entirety. Polynucleotides encoding polypeptides which exhibit delta-5-desaturase activity have been described in WO2002026946 and WO2003/093482, said documents, describing this enzyme from Thraustochytrium sp., are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit delta-6-desaturase activity have been described in WO2005/012316, WO2005/083093, WO2006/008099 and WO2006/069710, said documents, describing this enzyme from Ostreococcus tauri, are incorporated herein in their entirety.
In a preferred embodiment of the present invention, the delta-6-desaturase is a CoA (Coenzyme A)-dependent delta-6-desaturase. Such enzymes are well known in the art. For example, the delta-6-desaturase from Ostreococcus tauri used in the the example section is a Coenzyme A- dependent delta-6-desaturase. The use of CoA (Coenzyme A)-dependent delta-6-desaturase in combination with a delta-12-desaturase may allow for reducing the content of 18:1 n-9 in seeds, in particular in seed oil, as compared to a control. The use of CoA-dependent delta-6-desaturase in combination with a delta-6-elongase may allow for reducing the content of 18:3n-6 in seeds, in particular in seed oil, as compared to using a phospholipid-dependent delta-6-desaturase in combination with a delta-6-elongase.
Polynucleotides encoding polypeptides which exhibit delta-6-elongase activity have been described in WO2005/012316, WO2005/007845 and WO2006/069710, said documents, describing this enzyme from Thalassiosira pseudonana, are incorporated herein in their entirety. Polynucleotides encoding polypeptides which exhibit delta-12-desaturase activity have been described for example in WO2006100241 , said documents, describing this enzyme from Phytophthora sojae, are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit delta-4-desaturase activity have been described for example in WO2004/090123, said documents, describing this enzyme from Euglena gracilis, are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit delta-5-elongase activity have been described for example in WO2005/012316 and WO2007/096387, said documents, describing this enzyme from Ostreococcus tauri, are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit omega 3-desaturase activity have been described for example in WO2008/022963, said documents, describing this enzyme from Pythium irregulare, are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit omega 3-desaturase activity have been described for example in WO2005012316 and WO2005083053, said documents, describing this enzyme from Phytophthora infestans, are incorporated herein in their entirety. Polynucleotides encoding polypeptides which exhibit delta-4-desaturase activity have been described for example in WO2002026946, said documents, describing this enzyme from Thraustochytrium sp., are incorporated herein in their entirety.
Polynucleotides coding for a delta-4 desaturase from Pavlova lutheri are described in WO2003078639 and WO2005007845. These documents are incorporated herein in their entirety, particularly in sofar as the documents relate to the delta-4 desaturase "PIDES 1 "and figures 3a- 3d of WO2003078639 and figures 3a, 3b of WO2005007845, respectively.
The polynucleotides encoding the aforementioned polypeptides are herein also referred to as "target genes" or "nucleic acid of interest". The polynucleotides are well known in the art. The sequences of said polynucleotides can be found in the sequence of the T-DNAs disclosed in the Examples section (see e.g. the sequence of VC-LTM593-1 qcz which has a sequence as shown in SEQ ID NO: 3). The SEQ ID Nos for the preferred polynucleotide and and polypeptide sequences are also given in Table 130 in the Examples section.
Sequences of preferred polynucleotides for the desaturases and elongases referred to herein in connection with the present invention are indicated below. As set forth elsewhere herein, also variants of the polynucleotides can be used. The polynucleotides encoding for desaturases and
elogases to be used in accordance with the present invention can be derived from certain organisms. Preferably, a polynucleotide derived from an organism (e.g from Physcomitrella patens) is codon-optimized. In particular, the polynucleotide shall be codon-optimized for expression in a plant.
The term "codon-optimized" is well understood by the skilled person. Preferably, a codon optimized polynucleotide is a polynucleotide which is modified by comparison with the nucleic acid sequence in the organism from which the sequence originates in that it is adapted to the codon usage in one or more plant species. Typically, the polynucleotide, in particular the coding region, is adapted for expression in a given organism (in particular in a plant) by replacing at least one, or more than one of codons with one or more codons that are more frequently used in the genes of that organism (in particular of the plant). In accordance with the present invention, a codon optimized variant of a particular polynucleotide "from an organism" (or "derived from an organism") preferably shall be considered to be a polynucleotide derived from said organism.
Preferably, a codon-optimized polynucleotide shall encode for the same polypeptide having the same sequence as the polypeptide encoded by the non codon-optimized polynucleotide (i.e. the wild-type sequence). In the studies underlying the present invention, codon optimized polynucleotides were used (for the desaturases). The codon optimized polynucleotides are comprised by the T-DNA of the vector having a sequence as shown in SEQ ID NO: 3 (see table 130).
Preferably, a delta-6-elongase to be used in accordance with the present invention is derived from Physcomitrella patens. A preferred sequence of said delta-6-elongase is shown in SEQ ID NO:258. Preferably, said delta-6-elongase is encoded by a polynucleotide derived from Physcomitrella patens, in particular, said delta-6-elongase is encoded by a codon-optimized variant thereof (i.e. of said polynucleotide). Preferably, the polynucleotide encoding the delta-6- elongase derived from Physcomitrella patens is a polynucleotide having a sequence as shown in nucleotides 1267 to 2139 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 257 (Thus, the polynucleotide encoding the delta-6-elongase derived from Physcomitrella patens preferably has a sequence as shown in SEQ ID NO: 257).
Preferably, a delta-5-desaturase to be used in accordance with the present invention is derived from Thraustochytrium sp.. Thraustochytrium sp. in the context of the present invention preferably means Thraustochytrium sp. ATCC21685. A preferred sequence of said delta-5-desaturase is shown in SEQ ID NO:260. Preferably, said delta-5-desaturase is encoded by a polynucleotide derived from Thraustochytrium sp.; in particular, said delta-5-desaturase is encoded by a codon- optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-5- desaturase derived from Thraustochytrium sp. is a polynucleotide having a sequence as shown in nucleotides 3892 to 521 1 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 259. In accordance with the present invention, it is envisaged to express two or more polynucleotides (i.e. two or more copies of a polynucleotide) encoding a delta-5-desaturase
derived from Thraustochytrium sp. (preferably two polynucleotides). Thus, the T-DNA, construct, plant, seed etc. of the present invention shall comprise two (or more) copies of a polynucleotide encoding a delta-5-desaturase derived from Thraustochytrium sp.. Preferably, a delta-6-desaturase to be used in accordance with the present invention is derived from Ostreococcus tauri. A preferred sequence of said delta-6-desaturase is shown in SEQ ID NO:262. Preferably, said delta-6-desaturase is encoded by a polynucleotide derived from Ostreococcus tauri; in particular, said delta-6-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-6-desaturase derived from Ostreococcus tauri is a polynucleotide having a sequence as shown in nucleotides 7802 to 9172 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 261.
Preferably, a delta-6-elongase to be used in accordance with the present invention is derived from Thalassiosira pseudonana. A preferred sequence of said delta-6-elongase is shown in SEQ ID NO:264. Preferably, said delta-6-elongase is encoded by a polynucleotide derived from Thalassiosira pseudonana; in particular, said delta-6-elongase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-6-elongase derived from Thalassiosira pseudonana is a polynucleotide having a sequence as shown in nucleotides 12099 to 12917 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 263.
Preferably, a delta-12-elongase to be used in accordance with the present invention is derived from Phytophthora sojae. A preferred sequence of said delta-12-elongase is shown in SEQ ID NO:266. Preferably, said delta-12-elongase is encoded by a polynucleotide derived from Phytophthora sojae; in particular, said delta-12-elongase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-12-elongase derived from Phytophthora sojae is a polynucleotide having a sequence as shown in nucleotides 14589 to 15785 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 265.
Preferably, a delta-5-elongase to be used in accordance with the present invention is derived from Ostreococcus tauri. A preferred sequence of said delta-5-elongase is shown in SEQ ID NO:276. Preferably, said delta-5-elongase is encoded by a polynucleotide derived from Ostreococcus tauri; in particular, said delta-5-elongase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-5-elongase derived from Ostreococcus tauri is a polynucleotide having a sequence as shown in nucleotides 38388 to 39290 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 275.
Preferably, an omega 3-desaturase to be used in accordance with the present invention is derived from Pythium irregulare. A preferred sequence of said omega 3-desaturase is shown in SEQ ID NO:268. Preferably, said omega 3-desaturase is encoded by a polynucleotide derived from Pythium irregulare; in particular, said omega 3-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the omega 3-desaturase derived from Pythium irregulare is a polynucleotide having a sequence as shown in nucleotides
17690 to 18781 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 267. In accordance with the present invention, it is envisaged to express two or more polynucleotides (i.e. two or more copies of a polynucleotide) encoding a omega 3-desaturase derived from Pythium irregulare (preferably two polynucleotides). Thus, the T-DNA, construct, plant, seed etc. of the present invention shall comprise two (or more) copies of a polynucleotide encoding a omega 3-desaturase derived from Pythium irregulare
Preferably, an omega 3-desaturase to be used in accordance with the present invention is derived from Phytophthora infestans. A preferred sequence of said omega 3-desaturase is shown in SEQ ID NO:270. Preferably, said omega 3-desaturase is encoded by a polynucleotide derived from Phytophthora infestans; in particular, said omega 3-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the omega 3-desaturase derived from Phytophthora infestans is a polynucleotide having a sequence as shown in nucleotides 20441 to 21526 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 269.
In accordance with the present invention, it is in particular envisaged to express two or more polynucleotides encoding for omega 3-desaturases in the plant. Preferably, at least one polynucleotide encoding an omega 3-desaturase from Phytophthora infestans and at least one polynucleotide (in particular two polynucleotides, i.e. two copies of a polynucleotide) encoding an omega 3-desaturase from Pythium irregulare are expressed.
Preferably, a delta-4-desaturase to be used in accordance with the present invention is derived from Thraustochytrium sp.. A preferred sequence of said delta-4-desaturase is shown in SEQ ID NO:272. Preferably, said delta-4-desaturase is encoded by a polynucleotide derived from Thraustochytrium sp.; in particular, said delta-4-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-4-desaturase derived from Thraustochytrium sp. is a polynucleotide having a sequence as shown in nucleotides 26384 to 27943 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 271 .
Preferably, a delta-4-desaturase to be used in accordance with the present invention is derived from Pavlova lutheri. A preferred sequence of said delta-4-desaturase is shown in SEQ ID NO:274. Preferably, said delta-4-desaturase is encoded by a polynucleotide derived from Pavlova lutheri; in particular, said delta-4-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-4-desaturase derived from Pavlova lutheri is a polynucleotide having a sequence as shown in nucleotides 34360 to 35697 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 273. In accordance with the present invention, it is further envisaged to express two non-identical polynucleotides encoding, preferably non-identical delta-4-desaturases in the plant. Preferably, at least one polynucleotide encoding a delta-4-desaturase from Thraustochytrium sp. and at least one polynucleotide encoding a delta-4-desaturase from Pavlova lutheri are expressed.
Preferably, a delta-15-desaturase to be used in accordance with the present invention is derived from Cochliobolus heterostrophus. Preferably, said delta-15-desaturase is encoded by a polynucleotide derived from Cochliobolus heterostrophus; in particular, said delta-15-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-15-desaturase derived from Cochliobolus heterostrophus is a polynucleotide having a sequence as shown in nucleotides 2151 to 3654 of SEQ ID NO: 9.
As set forth above, the polynucleotide encoding a delta-6-elongase can be derived from Physcomitrella patens. Moreover, the polynucleotide encoding a delta-6-elongase can be derived from Thalassiosira pseudonana. In particular, it is envisaged in the context of the present invention to express at least one polynucleotide encoding a delta-6-elongase from Physcomitrella patens and at least one polynucleotide encoding a delta-6-elongase from Thalassiosira pseudonana in the plant. Thus, the T-DNA, plant, seed etc. shall comprise the said polynucleotides.
A polynucleotide encoding a polypeptide having a desaturase or elongase activity as specified above is obtainable or obtained in accordance with the present invention for example from an organism of genus Ostreococcus, Thraustochytrium, Euglena, Thalassiosira, Phytophthora, Pythium, Cochliobolus, Physcomitrella. However, orthologs, paralogs or other homologs may be identified from other species. Preferably, they are obtained from plants such as algae, for example Isochrysis, Mantoniella, Crypthecodinium, algae/diatoms such as Phaeodactylum, mosses such as Ceratodon, or higher plants such as the Primulaceae such as Aleuritia, Calendula stellata, Osteospermum spinescens or Osteospermum hyoseroides, microorganisms such as fungi, such as Aspergillus, Entomophthora, Mucor or Mortierella, bacteria such as Shewanella, yeasts or animals. Preferred animals are nematodes such as Caenorhabditis, insects or vertebrates. Among the vertebrates, the nucleic acid molecules may, preferably, be derived from Euteleostomi, Actinopterygii; Neopterygii; Teleostei; Euteleostei, Protacanthopterygii, Salmoniformes; Salmonidae or Oncorhynchus, more preferably, from the order of the Salmoniformes, most preferably, the family of the Salmonidae, such as the genus Salmo, for example from the genera and species Oncorhynchus mykiss, Trutta trutta or Salmo trutta fario. Moreover, the nucleic acid molecules may be obtained from the diatoms such as the genera Thalassiosira or Phaeodactylum. Thus, the term "polynucleotide" as used in accordance with the present invention further encompasses variants or derivatives of the aforementioned specific polynucleotides representing orthologs, paralogs or other homologs of the polynucleotide of the present invention. Moreover, variants or derivatives of the polynucleotide of the present invention also include artificially generated muteins. Said muteins include, e.g., enzymes which are generated by mutagenesis techniques and which exhibit improved or altered substrate specificity, or codon optimized polynucleotides.
Nucleic acid variants or derivatives according to the invention are polynucleotides which differ from a given reference polynucleotide by at least one nucleotide substitution, addition and/or deletion. If the reference polynucleotide codes for a protein, the function of this protein is conserved in the variant or derivative polynucleotide, such that a variant nucleic acid sequence shall still encode a polypeptide having a desaturase or elongase activity as specified above. Variants or derivatives also encompass polynucleotides comprising a nucleic acid sequence which is capable of hybridizing to the aforementioned specific nucleic acid sequences, preferably, under stringent hybridization conditions. These stringent conditions are known to the skilled in the art and can be found in Current Protocols in Molecular Biology, John Wiley & Sons, N. Y. (1989), 6.3.1-6.3.6. A preferred example for stringent hybridization conditions are hybridization conditions in 6X sodium chloride/sodium citrate (= SSC) at approximately 45°C, followed by one or more wash steps in 0.2X SSC, 0.1 % SDS at 50 to 65°C. The skilled worker knows that these hybridization conditions differ depending on the type of nucleic acid and, for example when organic solvents are present, with regard to the temperature and concentration of the buffer. For example, under "standard hybridization conditions" the temperature ranges depending on the type of nucleic acid between 42°C and 58°C in aqueous buffer with a concentration of 0.1 to 5X SSC (pH 7.2). If organic solvent is present in the abovementioned buffer, for example 50% formamide, the temperature under standard conditions is approximately 42°C. The hybridization conditions for DNA: DNA hybrids are, preferably, 0.1X SSC and 20°C to 45°C, preferably between 30°C and 45°C. The hybridization conditions for DNA:RNA hybrids are, preferably, 0.1X SSC and 30°C to 55°C, preferably between 45°C and 55°C. The abovementioned hybridization temperatures are determined for example for a nucleic acid with approximately 100 bp (= base pairs) in length and a G + C content of 50% in the absence of formamide. The skilled worker knows how to determine the hybridization conditions required by referring to textbooks such as the textbook mentioned above, or the following textbooks: Sambrook et al., "Molecular Cloning", Cold Spring Harbor Laboratory, 1989; Hames and Higgins (Ed.) 1985, "Nucleic Acids Hybridization: A Practical Approach", IRL Press at Oxford University Press, Oxford; Brown (Ed.) 1991 , "Essential Molecular Biology: A Practical Approach", IRL Press at Oxford University Press, Oxford. In an embodiment, stringent hybridization conditions encompass hybridization at 65°C in 1x SSC, or at 42°C in 1x SSC and 50% formamide, followed by washing at 65°C in 0.2x SSC. In another embodiment, stringent hybridization conditions encompass hybridization at 65°C in 1x SSC, or at 42°C in 1x SSC and 50% formamide, followed by washing at 65°C in 0.1 x SSC.
Alternatively, polynucleotide variants are obtainable by PCR-based techniques such as mixed oligonucleotide primer based amplification of DNA, i.e. using degenerate primers against conserved domains of the polypeptides of the present invention. Conserved domains of the polypeptide of the present invention may be identified by a sequence comparison of the nucleic acid sequences of the polynucleotides or the amino acid sequences of the polypeptides of the present invention. Oligonucleotides suitable as PCR primers as well as suitable PCR conditions are described in the accompanying Examples. As a template, DNA or cDNA from bacteria, fungi, plants or animals may be used. Further, variants include polynucleotides comprising nucleic acid sequences which are at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 98% or at least 99% identical
to the nucleic acid coding sequences shown in any one of the T-DNA sequences given in the corresponding tables of the examples. Of course, the variants must retain the function of the respective enzyme, e.g. a variant of a delta-4-desaturase shall have delta-4-desaturase activity. The percent identity values are, preferably, calculated over the entire amino acid or nucleic acid sequence region. A series of programs based on a variety of algorithms is available to the skilled worker for comparing different sequences. In a preferred embodiment, the percent identity between two amino acid sequences is determined using the Needleman and Wunsch algorithm (Needleman 1970, J. Mol. Biol. (48):444-453) which has been incorporated into the needle program in the EMBOSS software package (EMBOSS: The European Molecular Biology Open Software Suite, Rice, P., Longden, I., and Bleasby, A., Trends in Genetics 16(6), 276-277, 2000), a BLOSUM62 scoring matrix, and a gap opening penalty of 10 and a gap entension pentalty of 0.5. Guides for local installation of the EMBOSS package as well as links to WEB-Services can be found at http://emboss.sourceforge.net. A preferred, non-limiting example of parameters to be used for aligning two amino acid sequences using the needle program are the default parameters, including the EBLOSUM62 scoring matrix, a gap opening penalty of 10 and a gap extension penalty of 0.5. In yet another preferred embodiment, the percent identity between two nucleotide sequences is determined using the needle program in the EMBOSS software package (EMBOSS: The European Molecular Biology Open Software Suite, Rice, P., Longden, I., and Bleasby, A., Trends in Genetics 16(6), 276-277, 2000), using the EDNAFULL scoring matrix and a gap opening penalty of 10 and a gap extension penalty of 0.5. A preferred, non-limiting example of parameters to be used in conjunction for aligning two nucleic acid sequences using the needle program are the default parameters, including the EDNAFULL scoring matrix, a gap opening penalty of 10 and a gap extension penalty of 0.5. The nucleic acid and protein sequences of the present invention can further be used as a "query sequence" to perform a search against public databases to, for example, identify other family members or related sequences. Such searches can be performed using the BLAST series of programs (version 2.2) of Altschul et al. (Altschul 1990, J. Mol. Biol. 215:403-10). BLAST using desaturase and elongase nucleic acid sequences of the invention as query sequence can be performed with the BLASTn, BLASTx or the tBLASTx program using default parameters to obtain either nucleotide sequences (BLASTn, tBLASTx) or amino acid sequences (BLASTx) homologous to desaturase and elongase sequences of the invention. BLAST using desaturase and elongase protein sequences of the invention as query sequence can be performed with the BLASTp or the tBLASTn program using default parameters to obtain either amino acid sequences (BLASTp) or nucleic acid sequences (tBLASTn) homologous to desaturase and elongase sequences of the invention. To obtain gapped alignments for comparison purposes, Gapped BLAST using default parameters can be utilized as described in Altschul et al. (Altschul 1997, Nucleic Acids Res. 25(17):3389-3402).
In an embodiment, a variant of a polynucleotide encoding a desaturase or elongase as referred to herein is, preferably, a polynucleotide comprising a nucleic acid sequence selected from the group consisting of:
a) a nucleic acid sequence being at least 70%, 80%, or 90% identical to the nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
b) a nucleic acid sequence encoding a polypeptide which is at least 70%, 80, or 90% identical to a polypeptide having an amino acid sequence as shown in SEQ ID NOs:
258, 260, 262, 264, 266, 268, 270, 272, 274, or 276, and
c) a nucleic acid sequence which is capable of hybridizing under stringent conditions to i) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257,
259, 261 , 263, 265, 267, 269, 271 , 273, or 275, or to ii) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258,
260, 262, 264, 266, 268, 270, 272, 274, or 276.
As set forth above, the polypeptide encoded by said nucleic acid must retain the function of the respective enzyme. For example, the polypeptide having a sequence as shown in SEQ ID NO: 270 has omega-3-desaturase activity. Accordingly, the variant of this polypeptide also shall have omega-3-desaturase activity. The function of desaturases and elongases of the present invention is analyzed in Example 22.
Thus, a polynucleotide encoding a desaturase or elongase as referred to herein is, preferably, a polynucleotide comprising a nucleic acid sequence selected from the group consisting of:
a) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NO: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
b) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NO: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276 c) a nucleic acid sequence being at least 70%, 80%, or 90% identical to the nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
d) a nucleic acid sequence encoding a polypeptide which is at least 70%, 80, or 90% identical to a polypeptide having an amino acid sequence as shown in SEQ ID NOs
258, 260, 262, 264, 266, 268, 270, 272, 274, or 276, and
e) a nucleic acid sequence which is capable of hybridizing under stringent conditions to i) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257,
259, 261 , 263, 265, 267, 269, 271 , 273, or 275, or to ii) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258,
260, 262, 264, 266, 268, 270, 272, 274, or 276.
The event LBFLFK comprises two T-DNA insertions, the insertions being designated LBFLFK Locus 1 and LBFLFK Locus 2. Plants comprising this insertion were generated by transformation with the T-DNA vector having a sequence as shown in SEQ ID NO: 3. Sequencing of the insertions present in the plant revealed that each locus contained a point mutation in a coding sequence resulting in a single amino acid exchange. The mutations did not affect the function of the genes. Locus 1 has a point mutation in the coding sequence for the delta-12 desaturase from Phythophthora sojae (d12Des(Ps)). The resulting polynucleotide has a sequence as shown in
SEQ ID NO: 324. Said polynucleotide encodes a polypeptide having a sequence as shown in SEQ ID NO: 325. Locus 2 has a point mutation in the coding sequence for the delta-4 desaturase from Pavlova lutheri (d4Des(PI)). The resulting polynucleotide has a sequence as shown in SEQ ID NO: 326. Said polynucleotide encodes a polypeptide having a sequence as shown in SEQ ID NO: 327. The aforementioned polynucleotides are considered as variants of the polynucleotide encoding the delta-12 desaturase from Phythophthora sojae and the polynucleotide encoding the delta-4 desaturase from Pavlova lutheri. The polynucleotides are considered as variants and can be used in the context of the present invention. A polynucleotide comprising a fragment of any nucleic acid, particularly of any of the aforementioned nucleic acid sequences, is also encompassed as a polynucleotide of the present invention. The fragments shall encode polypeptides which still have desaturase or elongase activity as specified above. Accordingly, the polypeptide may comprise or consist of the domains of the polypeptide of the present invention conferring the said biological activity. A fragment as meant herein, preferably, comprises at least 50, at least 100, at least 250 or at least 500 consecutive nucleotides of any one of the aforementioned nucleic acid sequences or encodes an amino acid sequence comprising at least 20, at least 30, at least 50, at least 80, at least 100 or at least 150 consecutive amino acids of any one of the aforementioned amino acid sequences. The variant polynucleotides or fragments referred to above, preferably, encode polypeptides retaining desaturase or elongase activity to a significant extent, preferably, at least 10%, at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 80% or at least 90% of the desaturase or elongase activity exhibited by any of the polypeptide comprised in any of the T-DNAs given in the accompanying Examples (in particular of the desaturase or elongases listed in Table 1 1 and 130)
Further enzymes beneficial for the present invention as described in detail in the examples are aclytransf erases and transacylases (cf. WO 201 1 161093 A1 ). One group of acyltransferases having three distinct enzymatic activities are enzymes of the "Kennedy pathway", which are located on the cytoplasmic side of the membrane system of the endoplasmic reticulum (ER). The ER-bound acyltransferases in the microsomal fraction use acyl-CoA as the activated form of fatty acids. Glycerol-3-phosphate acyltransferase (GPAT) catalyzes the incorporation of acyl groups at the sn-1 position of glycerol-3-phosphate. 1-Acylglycerol-3-phosphate acyltransferase, also known as lysophosphatidic acid acyltransferase (LPAAT), catalyze the incorporation of acyl groups at the sn-2 position of lysophosphatidic acid (LPA). After dephosphorylation of phosphatidic acid by phosphatidic acid phosphatase (PAP), diacylglycerol acyltransferase (DGAT) catalyzes the incorporation of acyl groups at the sn-3 position of diacylglycerols. Further enzymes directly involved in TAG biosynthesis - apart from the said Kennedy pathway enzymes - are the phospholipid diacylglycerol acyltransferase (PDAT), an enzyme that transfers acyl groups from the sn-2 position of membrane lipids to the sn-3 position of diacylglycerols, and diacylglyceroldiacylglycerol transacylase (DDAT), an enzyme that transfers acylgroups from the sn-2 position of one diacylglycerol-molecule to the sn-3 position of another diacylglycerol- molecule. Lysophospholipid acyltransferase (LPLAT) represents a class of acyltransferases that
are capable of incorporating activated acyl groups from acyl-CoA to membrane lipids, and possibly also catalyze the reverse reaction. More specifically, LPLATs can have activity as lysophosphophatidylethanolamine acyltransf erase (LPEAT) and lysophosphatidylcholine acyltransferase (LPCAT). Further enzymes, such as lecithin cholesterol acyltransferase (LCAT) can be involved in the transfer of acyl groups from membrane lipids into triacylglycerides, as well. The documents WO 98/54302 and WO 98/54303 disclose a human LPAAT and its potential use for the therapy of diseases, as a diagnostic, and a method for identifying modulators of the human LPAAT. Moreover, a variety of acyltransf erases with a wide range of enzymatic functions have been described in the documents WO 98/55632, WO 98/55631 , WO 94/13814, WO 96/24674, WO 95/27791 , WO 00/18889, WO 00/18889, WO 93/10241 , Akermoun 2000, Biochemical Society Transactions 28: 713-715, Tumaney 1999, Biochimica et Biophysica Acta 1439: 47-56, Fraser 2000, Biochemical Society Transactions 28: 715- 7718, Stymne 1984, Biochem. J. 223: 305-314, Yamashita 2001 , Journal of Biological Chemistry 276: 26745-26752, and WO 00/18889. In order to express the polynucleotides encoding the desaturases or elongases as set forth in connection with the present invention, the polynucleotides shall be operably linked to expression control sequences. Preferably, the expression control sequences are heterologous with respect to the polynucleotides operably linked thereto. It is to be understood that each polynucleotide is operably linked to an expression control sequence.
The term "expression control sequence" as used herein refers to a nucleic acid sequence which is capable of governing, i.e. initiating and controlling, transcription of a nucleic acid sequence of interest, in the present case the nucleic sequences recited above. Such a sequence usually comprises or consists of a promoter or a combination of a promoter and enhancer sequences. Expression of a polynucleotide comprises transcription of the nucleic acid molecule, preferably, into a translatable mRNA. Additional regulatory elements may include transcriptional as well as translational enhancers. The following promoters and expression control sequences may be, preferably, used in an expression vector according to the present invention. The cos, tac, trp, tet, trp-tet, Ipp, lac, Ipp-lac, laclq, T7, T5, T3, gal, trc, ara, SP6, λ-PR or λ-PL promoters are, preferably, used in Gram-negative bacteria. For Gram-positive bacteria, promoters amy and SP02 may be used. From yeast or fungal promoters ADC1 , AOX1 r, GAL1 , MFa, AC, P-60, CYC1 , GAPDH, TEF, rp28, ADH are, preferably, used. For animal cell or organism expression, the promoters CMV-, SV40-, RSV-promoter (Rous sarcoma virus), CMV-enhancer, SV40-enhancer are preferably used. From plants the promoters CaMV/35S (Franck 1980, Cell 21 : 285-294], PRP1 (Ward 1993, Plant. Mol. Biol. 22), SSU, OCS, Iib4, usp, STLS1 , B33, nos or the ubiquitin or phaseolin promoter. Also preferred in this context are inducible promoters, such as the promoters described in EP 0388186 A1 (i.e. a benzylsulfonamide-inducible promoter), Gatz 1992, Plant J. 2:397-404 (i.e. a tetracyclin-inducible promoter), EP 0335528 A1 ( i.e. a abscisic-acid- inducible promoter) or WO 93/21334 (i.e. a ethanol- or cyclohexenol-inducible promoter). Further suitable plant promoters are the promoter of cytosolic FBPase or the ST-LSI promoter from potato (Stockhaus 1989, EMBO J. 8, 2445), the phosphoribosyl-pyrophosphate amidotransferase promoter from Glycine max (Genbank accession No. U87999) or the node-specific promoter described in EP 0249676 A1. Particularly preferred are promoters which enable the expression
in tissues which are involved in the biosynthesis of fatty acids. Also particularly preferred are seed-specific promoters such as the USP promoter in accordance with the practice, but also other promoters such as the LeB4, DC3, phaseolin or napin promoters. Further especially preferred promoters are seed-specific promoters which can be used for monocotyledonous or dicotyledonous plants and which are described in US 5,608,152 (napin promoter from oilseed rape), WO 98/45461 (oleosin promoter from Arobidopsis, US 5,504,200 (phaseolin promoter from Phaseolus vulgaris), WO 91/13980 (Bce4 promoter from Brassica), by Baeumlein et al., Plant J., 2, 2, 1992:233-239 (LeB4 promoter from a legume), these promoters being suitable for dicots. The following promoters are suitable for monocots: lpt-2 or lpt-1 promoter from barley (WO 95/15389 and WO 95/23230), hordein promoter from barley and other promoters which are suitable and which are described in WO 99/16890. In principle, it is possible to use all natural promoters together with their regulatory sequences, such as those mentioned above, for the novel process. Likewise, it is possible and advantageous to use synthetic promoters, either additionally or alone, especially when they mediate a seed-specific expression, such as, for example, as described in WO 99/16890. Preferably, the polynucleotides encoding the desaturases and elongases as referred to herein are expressed in the seeds of the plants. In a particular embodiment, seed-specific promoters are utilized to enhance the production of the desired PUFA orVLC-PUFA. In a particular preferred embodiment the polynucleotides encoding the desaturares or elongases are operably linked to expression control sequences used for the the expression of the respective desaturases and elongases in the Examples section (see e.g. the promoters used for expressing the elongases and desaturases in VC-LTM593-1 qcz rc, Table 1 1 ). The sequence of this vector is shown in SEQ ID NO: 3.
The term "operatively linked" as used herein means that the expression control sequence and the nucleic acid of interest are linked so that the expression of the said nucleic acid of interest can be governed by the said expression control sequence, i.e. the expression control sequence shall be functionally linked to the said nucleic acid sequence to be expressed. Accordingly, the expression control sequence and, the nucleic acid sequence to be expressed may be physically linked to each other, e.g., by inserting the expression control sequence at the 5'end of the nucleic acid sequence to be expressed. Alternatively, the expression control sequence and the nucleic acid to be expressed may be merely in physical proximity so that the expression control sequence is capable of governing the expression of at least one nucleic acid sequence of interest. The expression control sequence and the nucleic acid to be expressed are, preferably, separated by not more than 500 bp, 300 bp, 100 bp, 80 bp, 60 bp, 40 bp, 20 bp, 10 bp or 5 bp.
Preferred polynucleotides of the present invention comprise, in addition to a promoter, a terminator sequence operatively linked to the nucleic acid sequence of interest.
The term "terminator" as used herein refers to a nucleic acid sequence which is capable of terminating transcription. These sequences will cause dissociation of the transcription machinery from the nucleic acid sequence to be transcribed. Preferably, the terminator shall be active in plants and, in particular, in plant seeds. Suitable terminators are known in the art and, preferably, include polyadenylation signals such as the SV40-poly-A site or the tk-poly-A site or one of the plant specific signals indicated in Loke et al. (Loke 2005, Plant Physiol 138, pp. 1457-1468), downstream of the nucleic acid sequence to be expressed.
The invention furthermore relates to recombinant nucleic acid molecules comprising at least one nucleic acid sequence which codes for a polypeptide having desaturase and/or elongase activity which is modified by comparison with the nucleic acid sequence in the organism from which the sequence originates in that it is adapted to the codon usage in one or more plant species.
For the purposes of the invention "recombinant" means with regard to, for example, a nucleic acid sequence, an expression cassette (=gene construct) or a vector comprising the nucleic acid sequences used in the process according to the invention or a host cell transformed with the nucleic acid sequences, expression cassette or vector used in the process according to the invention, all those constructions brought about by recombinant methods in which either the nucleic acid sequence, or a genetic control sequence which is operably linked with the nucleic acid sequence, for example a promoter, or are not located in their natural genetic environment or have been modified by recombinant methods.
Preferably, the plant cell (or plant) of the present invention is an oilseed crop plant cell (or oilseed crop plant). More preferably, said oilseed crop is selected from the group consisting of flax (Linum sp.), rapeseed (Brassica sp.), soybean (Glycine and Soja sp.), sunflower (Helianthus sp.), cotton (Gossypium sp.), corn (Zea mays), olive (Olea sp.), safflower (Carthamus sp.), cocoa (Theobroma cacoa), peanut (Arachis sp.), hemp, camelina, crambe, oil palm, coconuts, groundnuts, sesame seed, castor bean, lesquerella, tallow tree, sheanuts, tungnuts, kapok fruit, poppy seed, jojoba seeds and perilla. Preferred plants to be used for introducing the polynucleotide or T-DNA of the invention are plants which are capable of synthesizing fatty acids, such as all dicotyledonous or monocotyledonous plants, algae or mosses. It is to be understood that host cells derived from a plant may also be used for producing a plant according to the present invention. Preferred plants are selected from the group of the plant families Adelotheciaceae, Anacardiaceae, Arecaceae, Asteraceae, Apiaceae, Betulaceae, Boraginaceae, Brassicaceae, Bromeliaceae, Caricaceae, Cannabaceae, Convolvulaceae, Chenopodiaceae, Compositae, Crypthecodiniaceae, Cruciferae, Cucurbitaceae, Ditrichaceae, Elaeagnaceae, Ericaceae, Euphorbiaceae, Fabaceae, Geraniaceae, Gramineae, Juglandaceae, Lauraceae, Leguminosae, Linaceae, Malvaceae, Moringaceae, Marchantiaceae, Onagraceae, Olacaceae, Oleaceae, Papaveraceae, Piperaceae, Pedaliaceae, Poaceae, Solanaceae, Prasinophyceae or vegetable plants or ornamentals such as Tagetes. Examples which may be mentioned are the following plants selected from the group consisting of: Adelotheciaceae such as the genera Physcomitrella, such as the genus and species Physcomitrella patens, Anacardiaceae such as the genera Pistacia, Mangifera, Anacardium, for example the genus and species Pistacia vera [pistachio], Mangifer indica [mango] or Anacardium occidentale [cashew], Asteraceae, such as the genera Calendula, Carthamus, Centaurea, Cichorium, Cynara, Helianthus, Lactuca, Locusta, Tagetes, Valeriana, for example the genus and species Calendula officinalis [common marigold], Carthamus tinctorius [safflower], Centaurea cyanus [cornflower], Cichorium intybus [chicory], Cynara scolymus [artichoke], Helianthus annus [sunflower], Lactuca sativa, Lactuca crispa, Lactuca esculenta, Lactuca scariola L. ssp. sativa, Lactuca scariola L. var. integrata, Lactuca scariola L. var. integrifolia, Lactuca sativa subsp. romana, Locusta communis, Valeriana locusta [salad vegetables], Tagetes lucida, Tagetes erecta
or Tagetes tenuifolia [african or french marigold], Apiaceae, such as the genus Daucus, for example the genus and species Daucus carota [carrot], Betulaceae, such as the genus Corylus, for example the genera and species Corylus avellana or Corylus colurna [hazelnut], Boraginaceae, such as the genus Borago, for example the genus and species Borago officinalis [borage], Brassicaceae, such as the genera Brassica, Melanosinapis, Sinapis, Arabadopsis, for example the genera and species Brassica napus, Brassica rapa ssp. [oilseed rape], Sinapis arvensis Brassica juncea, Brassica juncea var. juncea, Brassica juncea var. crispifolia, Brassica juncea var. foliosa, Brassica nigra, Brassica sinapioides, Melanosinapis communis [mustard], Brassica oleracea [fodder beet] or Arabidopsis thaliana, Bromeliaceae, such as the genera Anana, Bromelia (pineapple), for example the genera and species Anana comosus, Ananas ananas or Bromelia comosa [pineapple], Caricaceae, such as the genus Carica, such as the genus and species Carica papaya [pawpaw], Cannabaceae, such as the genus Cannabis, such as the genus and species Cannabis sativa [hemp], Convolvulaceae, such as the genera Ipomea, Convolvulus, for example the genera and species Ipomoea batatus, Ipomoea pandurata, Convolvulus batatas, Convolvulus tiliaceus, Ipomoea fastigiata, Ipomoea tiliacea, Ipomoea triloba or Convolvulus panduratus [sweet potato, batate], Chenopodiaceae, such as the genus Beta, such as the genera and species Beta vulgaris, Beta vulgaris var. altissima, Beta vulgaris var.Vulgaris, Beta maritima, Beta vulgaris var. perennis, Beta vulgaris var. conditiva or Beta vulgaris var. esculenta [sugarbeet], Crypthecodiniaceae, such as the genus Crypthecodinium, for example the genus and species Cryptecodinium cohnii, Cucurbitaceae, such as the genus Cucurbita, for example the genera and species Cucurbita maxima, Cucurbita mixta, Cucurbita pepo or Cucurbita moschata [pumpkin/squash], Cymbellaceae such as the genera Amphora, Cymbella, Okedenia, Phaeodactylum, Reimeria, for example the genus and species Phaeodactylum tricornutum, Ditrichaceae such as the genera Ditrichaceae, Astomiopsis, Ceratodon, Chrysoblastella, Ditrichum, Distichium, Eccremidium, Lophidion, Philibertiella, Pleuridium, Saelania, Trichodon, Skottsbergia, for example the genera and species Ceratodon antarcticus, Ceratodon columbiae, Ceratodon heterophyllus, Ceratodon purpureus, Ceratodon purpureus, Ceratodon purpureus ssp. convolutus, Ceratodon, purpureus spp. stenocarpus, Ceratodon purpureus var. rotundifolius, Ceratodon ratodon, Ceratodon stenocarpus, Chrysoblastella chilensis, Ditrichum ambiguum, Ditrichum brevisetum, Ditrichum crispatissimum, Ditrichum difficile, Ditrichum falcifolium, Ditrichum flexicaule, Ditrichum giganteum, Ditrichum heteromallum, Ditrichum lineare, Ditrichum lineare, Ditrichum montanum, Ditrichum montanum, Ditrichum pallidum, Ditrichum punctulatum, Ditrichum pusillum, Ditrichum pusillum var. tortile, Ditrichum rhynchostegium, Ditrichum schimperi, Ditrichum tortile, Distichium capillaceum, Distichium hagenii, Distichium inclinatum, Distichium macounii, Eccremidium floridanum, Eccremidium whiteleggei, Lophidion strictus, Pleuridium acuminatum, Pleuridium alternifolium, Pleuridium holdridgei, Pleuridium mexicanum, Pleuridium ravenelii, Pleuridium subulatum, Saelania glaucescens, Trichodon borealis, Trichodon cylindricus or Trichodon cylindricus var. oblongus, Elaeagnaceae such as the genus Elaeagnus, for example the genus and species Olea europaea [olive], Ericaceae such as the genus Kalmia, for example the genera and species Kalmia latifolia, Kalmia angustifolia, Kalmia microphylla, Kalmia polifolia, Kalmia occidentalis, Cistus chamaerhodendros or Kalmia lucida [mountain laurel], Euphorbiaceae such as the genera Manihot, Janipha, Jatropha, Ricinus, for example the genera and species Manihot utilissima,
Janipha manihot, Jatropha manihot, Manihot aipil, Manihot dulcis, Manihot manihot, Manihot melanobasis, Manihot esculenta [manihot] or Ricinus communis [castor-oil plant], Fabaceae such as the genera Pisum, Albizia, Cathormion, Feuillea, Inga, Pithecolobium, Acacia, Mimosa, Medicajo, Glycine, Dolichos, Phaseolus, Soja, for example the genera and species Pisum sativum, Pisum arvense, Pisum humile [pea], Albizia berteriana, Albizia julibrissin, Albizia lebbeck, Acacia berteriana, Acacia littoralis, Albizia berteriana, Albizzia berteriana, Cathormion berteriana, Feuillea berteriana, Inga fragrans, Pithecellobium berterianum, Pithecellobium fragrans, Pithecolobium berterianum, Pseudalbizzia berteriana, Acacia julibrissin, Acacia nemu, Albizia nemu, Feuilleea julibrissin, Mimosa julibrissin, Mimosa speciosa, Sericanrda julibrissin, Acacia lebbeck, Acacia macrophylla, Albizia lebbek, Feuilleea lebbeck, Mimosa lebbeck, Mimosa speciosa [silk tree], Medicago sativa, Medicago falcata, Medicago varia [alfalfa], Glycine max Dolichos soja, Glycine gracilis, Glycine hispida, Phaseolus max, Soja hispida or Soja max [soybean], Funariaceae such as the genera Aphanorrhegma, Entosthodon, Funaria, Physcomitrella, Physcomitrium, for example the genera and species Aphanorrhegma serratum, Entosthodon attenuatus, Entosthodon bolanderi, Entosthodon bonplandii, Entosthodon californicus, Entosthodon drummondii, Entosthodon jamesonii, Entosthodon leibergii, Entosthodon neoscoticus, Entosthodon rubrisetus, Entosthodon spathulifolius, Entosthodon tucsoni, Funaria americana, Funaria bolanderi, Funaria calcarea, Funaria californica, Funaria calvescens, Funaria convoluta, Funaria flavicans, Funaria groutiana, Funaria hygrometrica, Funaria hygrometrica var. arctica, Funaria hygrometrica var. calvescens, Funaria hygrometrica var. convoluta, Funaria hygrometrica var. muralis, Funaria hygrometrica var. utahensis, Funaria microstoma, Funaria microstoma var. obtusifolia, Funaria muhlenbergii, Funaria orcuttii, Funaria plano-convexa, Funaria polaris, Funaria ravenelii, Funaria rubriseta, Funaria serrata, Funaria sonorae, Funaria sublimbatus, Funaria tucsoni, Physcomitrella californica, Physcomitrella patens, Physcomitrella readeri, Physco-rnitrium australe, Physcomitrium californicum, Physcomitrium collenchymatum, Physcomitrium coloradense, Physcomitrium cupuliferum, Physcomitrium drummondii, Physcomitrium eurystomum, Physcomitrium flexifolium, Physcomitrium hookeri, Physcomitrium hookeri var. serratum, Physcomitrium immersum, Physcomitrium kellermanii, Physcomitrium megalocarpum, Physcomitrium pyriforme, Physcomitrium pyriforme var. serratum, Physcomitrium rufipes, Physcomitrium sandbergii, Physcomitrium subsphaericum, Physcomitrium washingtoniense, Geraniaceae, such as the genera Pelargonium, Cocos, Oleum, for example the genera and species Cocos nucifera, Pelargonium grossularioides or Oleum cocois [coconut], Gramineae, such as the genus Saccharum, for example the genus and species Saccharum officinarum, Juglandaceae, such as the genera Juglans, Wallia, for example the genera and species Juglans regia, Juglans ailanthifolia, Juglans sieboldiana, Juglans cinerea, Wallia cinerea, Juglans bixbyi, Juglans californica, Juglans hindsii, Juglans intermedia, Juglans jamaicensis, Juglans major, Juglans microcarpa, Juglans nigra or Wallia nigra [walnut], Lauraceae, such as the genera Persea, Laurus, for example the genera and species Laurus nobilis [bay], Persea americana, Persea gratissima or Persea persea [avocado], Leguminosae, such as the genus Arachis, for example the genus and species Arachis hypogaea [peanut], Linaceae, such as the genera Linum, Adenolinum, for example the genera and species Linum usitatissimum, Linum humile, Linum austriacum, Linum bienne, Linum angustifolium, Linum catharticum, Linum flavum, Linum grandiflorum, Adenolinum grandiflorum, Linum lewisii, Linum
narbonense, Linum perenne, Linum perenne var. lewisii, Linum pratense or Linum trigynum [linseed], Lythrarieae, such as the genus Punica, for example the genus and species Punica granatum [pomegranate], Malvaceae, such as the genus Gossypium, for example the genera and species Gossypium hirsutum, Gossypium arboreum, Gossypium barbadense, Gossypium herbaceum or Gossypium thurberi [cotton], Marchantiaceae, such as the genus Marchantia, for example the genera and species Marchantia berteroana, Marchantia foliacea, Marchantia macropora, Musaceae, such as the genus Musa, for example the genera and species Musa nana, Musa acuminata, Musa paradisiaca, Musa spp. [banana], Onagraceae, such as the genera Camissonia, Oenothera, for example the genera and species Oenothera biennis or Camissonia brevipes [evening primrose], Palmae, such as the genus Elacis, for example the genus and species Elaeis guineensis [oil palm], Papaveraceae, such as the genus Papaver, for example the genera and species Papaver orientale, Papaver rhoeas, Papaver dubium [poppy], Pedaliaceae, such as the genus Sesamum, for example the genus and species Sesamum indicum [sesame], Piperaceae, such as the genera Piper, Artanthe, Peperomia, Steffensia, for example the genera and species Piper aduncum, Piper amalago, Piper angustifolium, Piper auritum, Piper betel, Piper cubeba, Piper longum, Piper nigrum, Piper retrofractum, Artanthe adunca, Artanthe elongata, Peperomia elongata, Piper elongatum, Steffensia elongata [cayenne pepper], Poaceae, such as the genera Hordeum, Secale, Avena, Sorghum, Andropogon, Holcus, Panicum, Oryza, Zea (maize), Triticum, for example the genera and species Hordeum vulgare, Hordeum jubatum, Hordeum murinum, Hordeum secalinum, Hordeum distichon, Hordeum aegiceras, Hordeum hexastichon, Hordeum hexastichum, Hordeum irregulare, Hordeum sativum, Hordeum secalinum [barley], Secale cereale [rye], Avena sativa, Avena fatua, Avena byzantina, Avena fatua var. sativa, Avena hybrida [oats], Sorghum bicolor, Sorghum halepense, Sorghum saccharatum, Sorghum vulgare, Andropogon drummondii, Holcus bicolor, Holcus sorghum, Sorghum aethiopicum, Sorghum arundinaceum, Sorghum caffrorum, Sorghum cernuum, Sorghum dochna, Sorghum drummondii, Sorghum durra, Sorghum guineense, Sorghum lanceolatum, Sorghum nervosum, Sorghum saccharatum, Sorghum subglabrescens, Sorghum verticilliflorum, Sorghum vulgare, Holcus halepensis, Sorghum miliaceum, Panicum militaceum [millet], Oryza sativa, Oryza latifolia [rice], Zea mays [maize], Triticum aestivum, Triticum durum, Triticum turgidum, Triticum hybernum, Triticum macha, Triticum sativum or Triticum vulgare [wheat], Porphyridiaceae, such as the genera Chroothece, Flintiella, Petrovanella, Porphyridium, Rhodella, Rhodosorus, Vanhoeffenia, for example the genus and species Porphyridium cruentum, Proteaceae, such as the genus Macadamia, for example the genus and species Macadamia intergrifolia [macadamia], Prasinophyceae such as the genera Nephroselmis, Prasinococcus, Scherffelia, Tetraselmis, Mantoniella, Ostreococcus, for example the genera and species Nephroselmis olivacea, Prasinococcus capsulatus, Scherffelia dubia, Tetraselmis chui, Tetraselmis suecica, Mantoniella squamata, Ostreococcus tauri, Rubiaceae such as the genus Cofea, for example the genera and species Cofea spp., Coffea arabica, Coffea canephora or Coffea liberica [coffee], Scrophulariaceae such as the genus Verbascum, for example the genera and species Verbascum blattaria, Verbascum chaixii, Verbascum densiflorum, Verbascum lagurus, Verbascum longifolium, Verbascum lychnitis, Verbascum nigrum, Verbascum olympicum, Verbascum phlomoides, Verbascum phoenicum, Verbascum pulverulentum or Verbascum thapsus [mullein], Solanaceae such as the genera Capsicum, Nicotiana, Solanum,
Lycopersicon, for example the genera and species Capsicum annuum, Capsicum annuum var. glabriusculum, Capsicum frutescens [pepper], Capsicum annuum [paprika], Nicotiana tabacum, Nicotiana alata, Nicotiana attenuata, Nicotiana glauca, Nicotiana langsdorffii, Nicotiana obtusifolia, Nicotiana quadrivalvis, Nicotiana repanda, Nicotiana rustica, Nicotiana sylvestris [tobacco], Solanum tuberosum [potato], Solanum melongena [eggplant], Lycopersicon esculentum, Lycopersicon lycopersicum, Lycopersicon pyriforme, Solanum integrifolium or Solanum lycopersicum [tomato], Sterculiaceae, such as the genus Theobroma, for example the genus and species Theobroma cacao [cacao] or Theaceae, such as the genus Camellia, for example the genus and species Camellia sinensis [tea]. In particular preferred plants to be used as transgenic plants in accordance with the present invention are oil fruit crops which comprise large amounts of lipid compounds, such as peanut, oilseed rape, canola, sunflower, safflower, poppy, mustard, hemp, castor-oil plant, olive, sesame, Calendula, Punica, evening primrose, mullein, thistle, wild roses, hazelnut, almond, macadamia, avocado, bay, pumpkin/squash, linseed, soybean, pistachios, borage, trees (oil palm, coconut, walnut) or crops such as maize, wheat, rye, oats, triticale, rice, barley, cotton, cassava, pepper, Tagetes, Solanaceae plants such as potato, tobacco, eggplant and tomato, Vicia species, pea, alfalfa or bushy plants (coffee, cacao, tea), Salix species, and perennial grasses and fodder crops. Preferred plants according to the invention are oil crop plants such as peanut, oilseed rape, canola, sunflower, safflower, poppy, mustard, hemp, castor-oil plant, olive, Calendula, Punica, evening primrose, pumpkin/squash, linseed, soybean, borage, trees (oil palm, coconut). Especially preferred are sunflower, safflower, tobacco, mullein, sesame, cotton, pumpkin/squash, poppy, evening primrose, walnut, linseed, hemp, thistle or safflower. Very especially preferred plants are plants such as safflower, sunflower, poppy, evening primrose, walnut, linseed, or hemp, or most preferred, plants of family Brassicaceae.
The invention is also concerned with providing constructs for establishing high content of VLC- PUFAs in plants or parts thereof, particularly in plant oils.
As such, the invention provides a T-DNA for expression of a target gene in a plant, wherein the T-DNA comprises a left and a right border element and at least one expression cassette comprising a promoter, operatively linked thereto a target gene, and downstream thereof a terminator, wherein the length of the T-DNA, preferably measured from left to right border element and comprising the target gene, has a length of at least 30000 bp. In an embodiment, the expression cassette is separated from the closest border of the T-DNA by a separator of at least 500 bp length. In another embodiment, the expression cassette is separated from the closest border of the T-DNA by a separator of at least 100 bp in length. In another embodiment, the expression cassette is separated from the closest border of the T-DNA by a separator of at least 200 bp in length. Also, the invention relates to a construct comprising expression cassettes for various desaturase and elongase genes as described elsewhere herein in more detail.
As described elsewhere herein, the the T-DNA or construct of the present invention may comprise multiple expression cassettes encoding various, i.e. multiple proteins. In an embodiment, the T- DNA or construct of the present invention may comprise a separator between the expression cassettes encoding for the desaturases or elongases referred to above. In an embodiment, the expression cassettes are separated from each other by a separator of at least 100 base pairs, preferably they are separated by a separator of 100-200 base pairs. Thus, there is a separator between each expression cassette.
The invention thus provides nucleic acids, i.e. polynucleotides. A polynucleotide according to the present invention is or comprises a T-DNA according to the present invention. Thus, a T-DNA according to the present invention is a polynucleotide, preferably a DNA, and most preferably a double stranded DNA. A "T-DNA" according to the invention is a nucleic acid capable of eventual integration into the genetic material (genome) of a plant. The skilled person understands that for such integration a transformation of respective plant material is required, prefered transformation methods and plant generation methods are described herein.
According to the invention are also provided nucleic acids comprising a T-DNA or construct as defined according to the present invention. For example, a T-DNA or construct of the present invention may be comprised in a circular nucleic acid, e.g. a plasmid, such that an additional nucleic acid section is present between the left and right border elements, i.e. "opposite" of the expression cassette(s) according to the present invention. Such circular nucleic acid may be mapped into a linear form using an arbitrary starting point, e.g. such that the definition "left border element - expression cassette - right border element - additional nucleic acid section opposite of the expression cassette" defines the same circular nucleic acid as the definition "expression cassette - right border element - additional nucleic acid section opposite of the expression cassette - left border element". The additional nucleic acid section preferably comprises one or more genetic elements for replication of the total nucleic acid, i.e. the nucleic acid molecule comprising the T-DNA and the additional nucleic acid section, in one or more host microorganisms, preferably in a microorganism of genus Escherichia, preferably E. coli, and/or Agrobacterium. Preferable host microorganisms are described below in more detail. Such circular nucleic acids comprising a T-DNA of the present invention are particularly useful as transformation vectors; such vectors and are described below in more detail.
The polynucleotides as referred to herein preferably are expressed in a plant after introducing them into a plant. Thus, the method of the present invention may also comprise the step of introducing the polynucleotides into the plant. Preferably, the polynucleotides are introduced into the plant by transformation, in particular by Agrobacterium-mediated transformation. In an embodiment, the plants are transformed with a construct or T-DNA comprising the polynucleotides and/or expression cassette as set forth in connection with the present invention such as the expression cassettes encoding for desaturase and elongase as shown in Table 1 1. Thus, it is envisaged that the plant is (has been) transformed with a T-DNA or construct of the present invention. The construct or T-DNA used for the introduction, preferably comprises all polynucleotides to be expressed. Thus, a single construct or T-DNA shall be used for
transformation, in other words, the polynucleotides encoding for desaturases and elongases shall be comprised by the same T-DNA. It is to be understood, however, that more than one copy of the T-DNA may be comrprised by the plant. The T-DNA length is preferably large, i.e. it has a minimum length of at least 30000 bp, preferably more than 30000 bp, more preferably at least 40000 bp, even more preferably at least 50000 bp and most preferably at least 60000 bp. Preferably, the length of the T-DNA is in a range of any of the aforementioned minimum lengths to 120000bp, more preferably in a range of any of the aforementioned minimum lengths to 100000bp, even more preferably in a range of any of the aforementioned minimum lengths to 90000 bp, even more preferably in a range of any of the aforementioned minimum lengths to 80000 bp. With such minimum lengths it is possible to introduce a number of genes in the form of expression cassettes such that each individual gene is operably liked to at least one promoter and at least one terminator. As is shown hereinafter in the examples section, the invention makes use of such minimum length T-DNA for introducing the genes required for the metabolic pathway of VLC-PUFA production in plants, e.g. oil seed plants, preferably plants of genus Brassica. Also, the length of the T-DNA is preferably limited as described before to allow for easy handling.
Moreover, the construct of the present invention may have a minimum length of at least 30000 bp, preferably more than 30000 bp, more preferably at least 40000 bp, even more preferably at least 50000 bp and most preferably at least 60000 bp.
In an embodiment, in 3' direction of the T-DNA left border element or in 5' direction of the T-DNA right border element, a separator is present setting the respective border element apart from the expression cassette comprising the target gene. The separator in 3' direction of the T-DNA left border element does not necessarily have the same length and/or sequence as the separator in 5' direction of the T-DNA right border element, as long as both separators suffice to the further requirements given below. In another embodiment, the expression cassettes are separated from each other by a separator of at least 100 base pairs, preferably by a separator of 100 to 200 base pairs. Thus, there is a separator between the expression cassettes.
The separator or spacer is a section of DNA predominantly defined by its length. Its function is to separate a target gene from the T-DNA's left or right border, respectively. As will be shown in the examples, introducing a separator effectively separates the gene of interest from major influences exerted by the neighbouring genomic locations after insertion of the T-DNA into a genomic DNA. For example it is commonly believed that not all genomic loci are equally suitable for expression of a target gene, and that the same gene under the control of the same promoter and terminator may be expressed in different inensity in plants depending on the region of integration of the target gene (and its corresponding promoter and terminator) in the plant genome. It is generally believed that different regions of a plant genome are accessible with differing ease for transcription factors and/or polymerase enzymes, for example due to these regions being tightly
wound around histones and/or attached to the chromosomal backbone (cf. for example Deal et al., Curr Opin Plant Biol. Apr 201 1 ; 14(2): 1 16-122) or other scaffold material (cf. e.g. Fukuda Y., Plant Mol Biol. 1999 Mar; 39(5): 1051-62). The mechanism of achieving the above mentioned benefits by the T-DNA of the present invention is not easily understood, so it is convenient to think of the spacer as a means for physically providing a buffer to compensate for strain exerted by DNA winding by neighbouring histones or chromosomal backbone or other scaffold attached regions. As a model it can be thought that to transcribe a target gene, the DNA has to be partially unwound. If neighbouring regions of the target gene resist such unwinding, for example because they are tightly wound around histones or otherwise attached to a scaffold or backbone such that rotation of nucleic acid strands is limited, the spacer allows to distribute the strain created by the unwinding attempt over a longer stretch of nucleic acid, thereby reducing the force required for unwinding at the target gene.
In an embodiment, the separator has a length of at least 500 bp. The separator, thus, can be longer than 500 bp, and preferably is at least 800 bp in length, more preferably at least 1000 bp. Longer spacers allow for even more physical separation between the target gene and the nearest genomic flanking region.
In another embodiment, the spacer has a length of at least 100 bp. Preferably, the spacer has a length of 100 to 200 base pairs.
The separator preferably has a sequence devoid of matrix or scaffold attachment signals. Preferably, the separator or spacer is does not comprise more than once for a length of 500 bp, preferably not more than once for a length of 1000 bp, a 5-tuple which occurs in the spacers described below in the examples for 20 or more times, summarized over all spacers given in the examples. Those tuples are, in increasing frequency in the spacers given in the examples: AGCCT, CGTAA, CTAAC, CTAGG, GTGAC, TAGGC, TAGGT, AAAAA, AACGC, TTAGC, ACGCT, GCTGA, ACGTT, AGGCT, CGTAG, CTACG, GACGT, GCTTA, AGCTT, CGCTA, TGACG, ACGTG, AGCTG, CACGT, CGTGA, CGTTA, AGCGT, TCACG, CAGCT, CGTCA, CTAGC, GCGTC, TTACG, GTAGC, TAGCG, TCAGC, TAGCT, AGCTA, GCTAG, ACGTA, TACGT. By reducing the frequency of occurrence of one or more of the aforelisted tuples compared to the separators or spacers as given in the examples, a further increase in expression of a target gene in the T-DNA can be achieved.
The separator may contain a selectable marker. A selectable marker is a nucleic acid section whose presence preferably can be verified in seed without having to wait for the sprouting or full growth of the plant. Preferably the selectable marker conveys a phenotypical property to seed or to a growing plant, for example herbicide tolerance, coloration, seed surface properties (e.g. wrinkling), luminescence or fluorescence proteins, for example green fluorecent protein or luciferase. If for exhibiting the phenotypical feature an expression of a marker gene is required, then the separator correspondingly comprises the marker gene as selectable marker, preferably in the form of an expression cassette. Inclusion of a selectable marker in the separator is particularly advantageous since the marker allows to easily discard non-transformant plant material. Also, in such unexpected case where the T-DNA integrates in a location of the plant
genome where the length and/or nucleobase composition of the spacer is insufficient to overcome gene silencing effects caused by the neighbouring genomic DNA, the selectable marker allows to easily discard such unfortunately badly performing exceptional transformants. Thus, preferably the separator comprises an expression cassette for expression of an herbicide tolerance gene. Such separator greatly reduces the chance of having to cultivate a transformant where silencing effects are so strong that even the expression of the selectable marker gene is greatly reduced or fully inhibited. According to the invention, the separator preferably does not comprise a desaturase or elongase gene, and also preferably does not comprise a promoter or operatively linked to a desaturase or elongase gene. Thus, the T-DNA of the present invention in preferred embodiments is useful for effective separation of the desaturase and elongase genes essential for the production of VLC-PUFAs from any influence of effects caused by neighbouring genomic plant DNA.
Another method of isolating T-DNAs from major influences exerted by the neighbouring genomic locations in is maximize the distance of the T-DNA insert from neighboring genes. In addition, disruption of neighboring genes could result in unexpected effects on the host plant. It is possible to determine the genomic insertion site of a T-DNA with various methods known to those skilled in the art, such as adapter ligation-mediated PCR as described in O'Malley et al. 2007 Nature Protocols 2(1 1 ):2910-2917. Such methods allow for the selection of transgenic plants where the T-DNA has been inserted at a desired distance away from endogenous genes. It is preferable to identify transgenic events where the T-DNA is more than 1000 bp away from a neighboring coding sequence. More prefereable, the T-DNA is 2500 bp away, and most preferably the T-DNA is 5000 or more bp away from the nearest coding sequence. In an embodiment, the T-DNA or T-DNAs comprised by the plant of the present invention, thus, does not (do not) disrupt an endogenous coding sequence. Preferably, the T-DNA is (the T-DNAs are) more than 1000 bp away from a neighboring coding sequence. More prefereable, the T-DNA is (the T-DNAs are) 2500 bp away, and most preferably the T-DNA is (the T-DNAs are) 5000 or more bp away from the nearest coding sequence.
For the production of VLC-PUFAs in plants, the invention also provides a T-DNA or construct comprising the coding sequences of any single gene (in particular of the coding sequences for the desaturases and elongases) of the tables given in the examples, preferably comprising the coding sequences and and promoters of any single of the tables given in the examples, more preferably the coding sequences and promoters and terminators of any single of the tables given in the examples, and most preferably the expression cassettes of any single of the tables of the examples.
In an embodiment, the invention also provides a construct or a T-DNA comprising the coding sequences (in particular of the desaturases and elogases) as given in Table 1 1 and 130 in the examples, preferably comprising the coding sequences (in particular of the desaturases and elogases) and and promoters as given in Table 1 1 in the examples, more preferably the coding sequences (in particular of the desaturases and elogases) and promoters and terminators as given in Table 1 1 in the examples, and most preferably the expression cassettes for the
desaturases and elongases as referred to in the context of the method of present invention as present in VC-LTM593-1 qcz rc (see Examples section, SEQ ID NO: 3).
Also, the invention provides a T-DNA for production of VLC-PUFAs in a plant, wherein the T-DNA comprises a left and a right border element and in between one or more expression cassette(s), wherein the length of the T-DNA, measured from left to right border element and comprising the one or more expression cassettes, has a length of at least 30000 bp. In an embodiment, the expression cassette(s) closest to a left or right border element, respectively, is (are) separated from said closest border element of the T-DNA by a separator of at least 500 bp length. It is to be understood that the one or more expression cassette(s) each comprise a promoter, operatively linked to a target gene, and downstream thereof a terminator, wherein the target gene of a respective expression cassette is a desaturase or elongase gene as required for production of a VLC-PUFA. Preferably at least one and most preferably all of the target genes codes/code for a desaturase or elongase as given in any of the tables in the examples section, and further preferably at least one and most preferably all expression cassettes consist of a combination of promoter, desaturase/elongase gene and terminator as given in any of the examples below. In one embodiment a plant of the invention comprises one or more T-DNA of the present invention comprising one or more expression cassettes encoding for one or more d6Des (delta 6 desaturase), one or more d6Elo (delta 6 elongase), one or more d5Des (delta 5 desaturase), one or more o3Des (omega 3 desaturase), one or more d5Elo (delta 5 elongase) and one or more D4Des (delta 4 desaturase), preferably for at least one CoA-dependent D4Des and one Phospholipid-dependent d4Des. In one embodiment, the T-DNA encodes also for one or more d12Des (delta 12 desaturase). In an embodiment, the desaturases and elongases are derived from the organisms disclosed above. In one embodiment, a plant of the invention thus comprises one or more T-DNA of the present invention comprising at least one polynucleotide encoding a delta-6-desaturase (preferably a CoA-dependent delta-6-desaturase), at least two polynucleotides encoding a delta-6-elongase, at least two polynucleotides encoding a delta-5- desaturase, at least one polynucleotide encoding a delta-12-desaturase, at least three polynucleotides encoding an omega-3-desaturase, and at least one polynucleotide encoding a delta-5-elongase, and at least two polynucleotides encoding a delta-4-desaturase (preferably at least one for a CoA-dependent D4Des and at least one for Phospholipid-dependent d4Des).
Preferred polynucleotide sequences encoding for the desaturases and elongases referred to above are disclosed elsewherein herein (see also SEQ ID Nos in Table 130). In a particular preferred embodiment, the desaturases and elongases are from the organisms disclosed above. In one embodiment, a plant of the invention thus comprises one or more T-DNA of the present invention comprising at least one polynucleotide encoding a delta-6-desaturase, at least two polynucleotides encoding a delta-6-elongase, at least two polynucleotides encoding a delta-5-desaturase, at least one polynucleotide encoding a delta-12-desaturase, at least three polynucleotides encoding an omega-3-desaturase, and at least one polynucleotide encoding a delta-5-elongase, and at least two polynucleotides encoding a delta-4-desaturase (preferably for at least one CoA-dependent D4Des and one Phospholipid-dependent d4Des).
In a further preferred embodiment of the present invention, a plant of the invention comprises one or more T-DNA of the present invention comprising one expression cassette for a delta-6 elongase from Physcomitrella patens, one expression cassette for a delta-6 elongase from Thalassiosira pseudonana, two expression cassettes for a delta-5 desaturase from Thraustochytrium sp. (in particular from Thraustochytrium sp. ATCC21685), two expression cassettes for an omega-3 desaturase from Pythium irregulare, one expression cassette for a omega-3-desaturase from Phythophthora infestans, one expression cassette for a delta-5 elongase from Ostreococcus tauri, one expression cassette for a delta-4 desaturase from Thraustochytrium sp., and one expression cassette for a delta-4 desaturase from Pavlova lutheri. The sequences of polynucleotides encoding the desaturases or elongases can be found in in the T-DNA vector VC-LTM593-1 qcz (SEQ ID NO: 3). For more information, see also Table 1 1. In an even further preferred embodiment, a plant of the invention comprises one or more T-DNA, wherein the T-DNA comprises the expression cassettes for the desaturases and elongases of VC-LTM593-1 qcz (see e.g. Table 1 1 ). Moreover, it is envisaged that the plant of the present invention comprises one or more T-DNA of the present invention, wherein the T-DNA has the sequence of the T-DNA of the vector VC-LTM593-1 qcz. The position of the T-DNA in the vector is indicated in Table 1 1 . The vector has a sequence shown in SEQ ID NO: 3.
In a preferred embodiment, the T-DNA, construct, or plant of the present invention comprises polynucleotides encoding for the following desaturases and elongases, in particular in the following order: Delta-6 ELONGASE from Physcomitrella patens; Delta-5 DESATURASE from Thraustochytrium (in particular from Thraustochytrium sp. ATCC21685); Delta-6 DESATURASE from Ostreococcus tauri; Delta-6 ELONGASE from Thalassiosira pseudonana; Delta-12 DESATURASE from Phythophthora sojae; Omega-3 DESATURASE from Pythium irregulare; Omega-3-DESATURASE from Phythophthora infestans; Delta-5 DESATURASE from Thraustochytrium (in particular from Thraustochytrium sp. ATCC21685); Delta-4 DESATURASE from Thraustochytrium sp.; Omega-3 DESATURASE from Pythium irregular; Delta-4 DESATURASE from Pavlova lutheri; Delta-5 ELONGASE from Ostreococcus tauri. Thus, T- DNA, construct, or plant of the present invention comprises two copies of a Delta-5 desaturase from Thraustochytrium and two copies of Delta-5 desaturase from Thraustochytrium. Also encompassed are variants thereof.
As set forth elsewhere herein, the T-DNA preferably shall have a length of at least 30000 bp. In one embodiment, the plant of the invention or a part thereof as described herein comprises one or more T-DNAs of the invention which encode for at least two d6Des, at least two d6Elo and/or, at least two o3Des. In one embodiment, the present plant of the invention or a part thereof comprise a T-DNA comprising one or more expression cassettes encoding for at least one CoA- dependent d4Des and at least one phopho-lipid dependent d4Des. In one embodiment the activities of the enzymes expressed by the one or more T-DNAs in the plant of the invention or a part thereof are encoded and expressed polpeptides having the activities shown in column 1 of Table 19. In one embodiment the plant of the invention comprises at least one T-DNA as shown
in columns 1 to 9 in Table 13. In one embodiment, one T-DNA of the present invention comprises one or more gene expression cassettes encoding for the activities or enzymes listed in Table 13.
In one embodiment, the at least one T-DNA further comprises an expression cassette which encodes for at least one d12Des. In one embodiemt, the T-DNA or T-DNAs comprise one or more expression cassettes encoding one or more d5Des(Tc_GA), o3Des(Pir_GA), d6Elo(Tp_GA) and/or d6Elo(Pp_GA). Such plants of the present invention have shown particularly high amounts and concentrations of VLC-PUFAs over three or more generations and under different growth conditions.
In one embodiment the T-DNA of the invention encodes for the activites of column 1 as disclosed in Table 19, preferably of gene combinations disclosed in Table 13, even more preferred for promoter-gene combinations as described in Table 13. The contribution from each desaturase and elongase gene present in the T-DNA to the amount of VLC-PUFA is difficult to assess, but it is possible to calculate conversion efficiencies for each pathway step, for example by using the equations shown in Figure 2. The calculations are based on fatty acid composition of the tissue or oil in question and indicate the amount of product fatty acid (and downstream products) formed from the subatrate of a particular enzyme. The conversion efficiencies are sometimes referred to as "apparent" conversion efficiencies because for some of the calculations it is recognized that the calculations do not take into account all factors that could be influencing the reaction. Nevertheless, conversion efficiency values can be used to assess contribution of each desaturase or elongase reaction to the overall production of VLC-PUFA. By comparing conversion efficiencies, one can compare the relative effectiveness of a given enzymatic step between different individual seeds, plants, bulk seed batches, events, Brassica germplasm, or transgenic constructs.
In an embodiment of the present invention, the plant is a Brassica napus plant. Preferably, the plant comprises at least one T-DNA of the invention (and thus one or more T-DNAs). The T-DNA shall have a length of at least at least 10.000 base pairs, in particular of at least 30.000 bp.
As set forth elsewhere herein, the T-DNA comprised by the invention shall comprise expression cassettes for desaturases and elongases. In an embodiment, the T-DNA comprises one or more expression cassettes for a delta-5 desaturase (preferably one), one or more expression cassettes for a omega-3 desaturase (preferably three), one or more expression cassettes for a delta 12 desaturase (preferably one), one or more expression cassettes for a delta 4 desaturase (preferably one CoA-dependent d4des and one phospholipid dependent d4des), one or more expression cassettes for a delta-5 elongase (preferably one), one or more expression cassettes for a delta-6 desaturase (preferably one), and one or more expression cassettes for a delta-6 elongase (preferably two). Preferably, the T-DNA comprises two expression cassettes for a delta- 5 desaturase from Thraustochytrium sp., two expression cassettes for an omega-3-desaturase from Phythophthora infestans, one expression cassette for an omega-3-desaturase from Pythium irregulare, one expression cassette for a delta-12 desaturase from Phythophthora sojae, one
expression cassette for a Delta-4 desaturase from Pavlova lutheri, one expression cassette for a Delta-4 desaturase from Thraustochytrium sp., one expression cassette for a Delta-6 desaturase from Ostreococcus tauri, one expression cassette for a Delta-6 elongase from Physcomitrella patens, and one expression cassette for a Delta-6 elongase from Thalassiosira pseudonana. The SEQ ID Nos are given in Table 130. Further, it is envisaged that expression cassettes for variants of the aforementioned enzymes may be used.
The plant shall produce an oil as described elsewhere herein in more detail:
In connection with the present invention is envisaged, that the plant has one or more of the following features:
A delta 6 desaturase conversion efficiency in bulk seed of greater than about 28%, or greater than about 34%, or greater than about 40%,
A delta 6 desaturase conversion efficiency in a single seed of greater than about 40%, A delta 6 elongase conversion efficiency in bulk seed of greater than about 75%, or greater than about 82%, or greater than about 89%,
A delta 6 elongase conversion efficiency in single seed of greater than about 86%, The T-DNA insert or inserts do not disrupt an endogenous coding sequence (as described elsewhere herein),
The distance between any inserted T-DNA sequence and the nearest endogenous gene is about 1000, or about 2000, or about 5000 base pairs,
The T-DNA insert or inserts do not cause rearrangements or any DNA surrounding the insertion location,
No partial T-DNA inserts (Thus, the full length T-DNA shall be integrated in the genome),
The T-DNA insert or inserts occur exclusively in the C genome of Brassica,
All inserted transgenes are fully functional (thus, the enzymes encoded by the genes shall retain their function).
How to calculate conversion efficiencies for a delta-6-desaturase of a delta 6-elongase is well known in the art. In an embodiment, the conversion efficiencies are calculated by using the equations shown in Figure 2. Moreover, it is envisaged that conversion efficiencies are calculated as described in Examples 19 to 22.
As described in detail in the examples, with regards to the production of VLC-PUFAs three desaturase genes are particularly prone to gene dosage effects (also called "copy number effects"), such that increasing the number of expression cassettes comprising these respective genes leads to a stronger increase in VLC-PUFA levels in plant oils than increasing the number of expression cassettes of other genes. These genes are the genes coding for delta-12- desaturase activity, for delta-6-desaturase activity and omega-3-desaturase activity. Thus, according to the invention each expression cassette comprising a gene coding for a delta-12- desaturase, delta-6-desaturase or omega-3-desaturase is separated from the respective closest left or right border element by a separator and optionally one or more expression cassettes. It is to be understood that where the T-DNA of the present invention comprises more than one
expression cassette comprising a gene of the same function, these genes do not need to be identical concerning their nucleic acid sequence or the polypeptide sequence encoded thereby, but should be functional homologs. Thus, for example, to make use of the gene dosage effect described herein a T-DNA according to the present invention may comprise, in addition to optionally a multiplicity of genes coding for delta-6-desaturases and/or omega-3-desaturases, two, three, four or more expression cassettes each comprising a gene coding for a delta-12- desaturase, wherein the delta-12-desaturase polypeptides coded by the respective genes differ in their amino acid sequence. Likewise, a T-DNA of the present invention may comprise, in addition to optionally a multiplicity of genes coding for delta-12-desaturases and/or omega-3- desaturases, two, three, four or more expression cassettes each comprising a gene coding for a delta-6-desaturase, wherein the delta-6-desaturase polypeptides coded by the respective genes differ in their amino acid sequence, or a T-DNA of the present invention may comprise, in addition to optionally a multiplicity of genes coding for delta-12-desaturases and/or delta-6-desaturases, two, three, four or more expression cassettes each comprising a gene coding for a omega-3- desaturase, wherein the omega-3-desaturase polypeptides coded by the respective genes differ in their amino acid sequence.
According to the invention, the T-DNA, construct or plant may also comprise, instead of one or more of the aforementioned coding sequences, a functional homolog thereof. A functional homolog of a coding sequence is a sequence coding for a polypeptide having the same metabolic function as the replaced coding sequence. For example, a functional homolog of a delta-5- desaturase would be another delta-5-desaturase, and a functional homolog of a delta-5-elongase would be another delta-5-elongase. The functional homolog of a coding sequence preferably codes for a polypeptide having at least 40% sequence identity to the polypeptide coded for by the corresponding coding sequence given in the corresponding table of the examples, more preferably at least 41 %, more preferably at least 46%, more preferably at least 48%, more preferably at least 56%, more preferably at least 58%, more preferably at least 59%, more preferably at least 62%, more preferably at least 66%, more preferably at least 69%, more preferably at least 73%, more preferably at least 75%, more preferably at least 77%, more preferably at least 81 %, more preferably at least 84%, more preferably at least 87%, more preferably at least 90%, more preferably at least 92%, more preferably at least 95%, more preferably at least 96%, more preferably at least 97%, more preferably at least 98% and even more preferably at least 99%. Likewise, a functional homolog of a promoter is a sequence for starting transcription of a coding sequence located within 500 bp for a proximal promoter or, for a distal promoter, within 3000 bp distant from the promoter TATA box closest to the coding sequence. Again, a functional homolog of a plant seed specific promoter is another plant seed specific promoter. The functional homolog of a terminator, correspondingly, is a sequence for ending transcription of a nucleic acid sequence.
The examples describe particularly preferred T-DNA sequences. As described above, the skilled person understands that the coding sequences, promoters and terminators described therein can be replaced by their functional homologs. However, the examples also describe that according to the invention, certain combinations of promoters and coding sequences, or certain combinations of promoters driving the expression of their corresponding coding sequences, or certain coding
sequences or combinations thereof are particularly advantageous; such combinations or individual coding sequences should according to the invention not be replaced by functional homologs of the respective element (here: coding sequence or promoter). A T-DNA or construct of the present invention preferably comprises two or more genes, preferably all genes, susceptible to a gene dosage effect. As described herein, it is advantageous for achieving high conversion efficiencies of certain enzymatic acitvities, e.g. delta-12-desaturase, delta-6-desaturase and/or omega-3-desaturase activity, to introduce more than one gene coding for an enzyme having the desired activity into a plant cell. When introducing T-DNA into plant cells, generally transformation methods involving exposition of plant cells to microorganisms are employed, e.g. as described herein. As each microorganism may comprise more than one nucleic acid comprising a T-DNA of the present invention, recombinant plant cells are frequently obtained comprising two or more T-DNAs of the present invention independently integrated into the cell's genetic material. Thus, by combining genes susceptible to a gene dosage effect on one construct for transformation allows to easily exploit the independence of transformations to achieve a higher frequency of multiple insertions of such T-DNAs. This could be e.g. useful for transformation methods relying on co-transformation to keep the size of each construct to be transformed low.
The invention accordingly also provides a construct comprising a T-DNA according to the present invention, wherein the construct preferably is a vector for transformation of a plant cell by microorganism-mediated transformation, preferably by Agrobacterium-mediated transformation. Correspondingly, the invention also provides a transforming microorganism comprising one T- DNA according to the present invention, preferably as a construct comprising said T-DNA. Preferably the microorganism is of genus Agrobacterium, preferably a disarmed strain thereof, and preferably of species Agrobacterium tumefaciens or, even more preferably, of species Agrobacterium rhizogenes. Corresponding strains are for example described in WO06024509A2, and methods for plant transformation using such microorganisms are for example described in WO13014585A1. These WO publications are incorporated herein in their entirety, because they contain valuable information about the creation, selection and use of such microorganisms.
The term "vector", preferably, encompasses phage, plasmid, viral vectors as well as artificial chromosomes, such as bacterial or yeast artificial chromosomes. Moreover, the term also relates to targeting constructs which allow for random or site-directed integration of the targeting construct into genomic DNA. Such target constructs, preferably, comprise DNA of sufficient length for either homologous or heterologous recombination as described in detail below. The vector encompassing the polynucleotide of the present invention, preferably, further comprises selectable markers for propagation and/or selection in a host. The vector may be incorporated into a host cell by various techniques well known in the art. If introduced into a host cell, the vector may reside in the cytoplasm or may be incorporated into the genome. In the latter case, it is to be understood that the vector may further comprise nucleic acid sequences which allow for homologous recombination or heterologous insertion. Vectors can be introduced into prokaryotic or eukaryotic cells via conventional transformation or transfection techniques. The terms "transformation" and "transfection", conjugation and transduction, as used in the present context,
are intended to comprise a multiplicity of prior-art processes for introducing foreign nucleic acid (for example DNA) into a host cell, including calcium phosphate, rubidium chloride or calcium chloride co-precipitation, DEAE-dextran-mediated transfection, lipofection, natural competence, carbon-based clusters, chemically mediated transfer, electroporation or particle bombardment. Suitable methods for the transformation or transfection of host cells, including plant cells, can be found in Sambrook et al. (Molecular Cloning: A Laboratory Manual, 2nd ed., Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, 1989) and other laboratory manuals, such as Methods in Molecular Biology, 1995, Vol. 44, Agrobacterium protocols, Ed.: Gartland and Davey, Humana Press, Totowa, New Jersey. Alternatively, a plasmid vector may be introduced by heat shock or electroporation techniques. Should the vector be a virus, it may be packaged in vitro using an appropriate packaging cell line prior to application to host cells.
Preferably, the vector referred to herein is suitable as a cloning vector, i.e. replicable in microbial systems. Such vectors ensure efficient cloning in bacteria and, preferably, yeasts or fungi and make possible the stable transformation of plants. Those which must be mentioned are, in particular, various binary and co-integrated vector systems which are suitable for the T DNA- mediated transformation. Such vector systems are, as a rule, characterized in that they contain at least the vir genes, which are required for the Agrobacterium-mediated transformation, and the sequences which delimit the T-DNA (T-DNA border). These vector systems, preferably, also comprise further cis-regulatory regions such as promoters and terminators and/or selection markers with which suitable transformed host cells or organisms can be identified. While co- integrated vector systems have vir genes and T-DNA sequences arranged on the same vector, binary systems are based on at least two vectors, one of which bears vir genes, but no T-DNA, while a second one bears T-DNA, but no vir gene. As a consequence, the last-mentioned vectors are relatively small, easy to manipulate and can be replicated both in E. coli and in Agrobacterium. These binary vectors include vectors from the pBIB-HYG, pPZP, pBecks, pGreen series. Preferably used in accordance with the invention are Bin19, pB1101 , pBinAR, pGPTV and pCAMBIA. An overview of binary vectors and their use can be found in Hellens et al, Trends in Plant Science (2000) 5, 446-451 . Furthermore, by using appropriate cloning vectors, the polynucleotides can be introduced into host cells or organisms such as plants or animals and, thus, be used in the transformation of plants, such as those which are published, and cited, in: Plant Molecular Biology and Biotechnology (CRC Press, Boca Raton, Florida), chapter 6/7, pp. 71-1 19 (1993); F.F. White, Vectors for Gene Transfer in Higher Plants; in: Transgenic Plants, vol. 1 , Engineering and Utilization, Ed.: Kung and R. Wu, Academic Press, 1993, 15-38; B. Jenes et al., Techniques for Gene Transfer, in: Transgenic Plants, vol. 1 , Engineering and Utilization, Ed.: Kung and R. Wu, Academic Press (1993), 128-143; Potrykus 1991 , Annu. Rev. Plant Physiol. Plant Molec. Biol. 42, 205-225. More preferably, the vector of the present invention is an expression vector. In such an expression vector, i.e. a vector which comprises the polynucleotide of the invention having the nucleic acid sequence operatively linked to an expression control sequence (also called "expression cassette") allowing expression in prokaryotic plant cells or isolated fractions thereof.
Most important, the invention also provides a plant or seed thereof, comprising, integrated in its genome, a T-DNA or a construct of the present invention. Thus, the construct or T-DNA shall be stably integrated into the genome of the plant or plant cell. In an embodiment, the plant is homozygous for the T-DNA. In another embodiment, the plant is hemizygous for the T-DNA. If the plant is homozygous for one T-DNA at one locus, this is nevertheless considered as a single copy herein, i.e. as one copy. Double copy, as used herein, refers to a plant in which two T-DNAs have been inserted, at one or two loci, and in the hemizygous or homozygous state.
Stability of the T-DNA can be assessed by determining the presence of the T-DNA in two or more subsequent generations of a transgenic event. Determining the presence of a T-DNA can be achieved by Southern blot analysis, PCR, DNA sequencing, or other methods that are suitable for the detection of specific DNA sequences. Stability of the T-DNA should also include copy number measurements for transgenic events that contain more than one copy of the T-DNA. In this case, instability of a single copy of the T-DNA may not be detectable by selecting for the trait, i.e. VLC-PUFA conent, because the presence of one stable T-DNA copy may mask the instability of the other. When working with large T-DNAs of at least 30000 bp in length, and with multiple copies of certain sequences (for example two copies of the same promoter) it is especially important to confirm presence and copy number at multiple locations within the T-DNA. The borders of a long T-DNA have an increased likelihood of being in linkage equilibrium, and duplicated sequences increase the possibility of homologous recombination. The effects of being in linkage equilibrium, and the potential for homologous recombination, mean that transgenes of a T-DNA could be disrupted or lost over generations. Therefore, it is preferred to test for the presence and copy number of a large T-DNA (at least 30000 bp) at more than three locations on the T-DNA, including a region at the right and left borders as well as a region internal to the T- DNA. It is more preferred to test for the presence and copy number of more than 5 regions, and most preferred to test presence and copy number of at least 7 regions on the T-DNA.
Such T-DNA or construct preferably allows for the expression of all genes required for production of VLC-PUFAs in plants and particularly in the seeds thereof, particularly in oilseed plants, and most beneficially in plants or seeds of family Brassicaceae, preferably of genus Brassica and most preferably of a species comprising a genome of one or two members of the species Brassica oleracea, Brassica nigra and Brassica rapa, thus preferably of the species Brassica napus, Brassica carinata, Brassica juncea, Brassica oleracea, Brassica nigra or Brassica rapa. Particularly preferred according to the invention are plants and seeds of the species Brassica napus and Brassica carinata.
The plants of the present invention are necessarily transgenic, i.e. they comprise genetic material not present in corresponding wild type plant or arranged differently in corresponding wild type plant, for example differing in the number of genetic elements. For example, the plants of the present invention comprise promoters also found in wild type plants, but the plants of the present invention comprise such promoter operatively linked to a coding sequence such that this
combination of promoter and coding sequence is not found in the corresponding wild type plant. Accordingly, the polynucleotide encoding for the desaturases or elongases shall be recombinant polynucleotides. The plants and seeds of the present invention differ from hitherto produced plants for production of VLC-PUFAs in a number of advantageous features, some of which are described in detail in the examples. In particular, T-DNAs of the present invention allow for the generation of transformant plants (also called "recombinant plants") and seeds thereof with a high transformation frequency, with a high stability of T-DNA insertions over multiple generations of self-fertilized plants, unchanged or unimpaired phenotypical and agronomic characteristics other than VLC-PUFA production, and with high amounts and concentration of VLC-PUFAs, particularly EPA and/or DHA, in the oil of populations of such transformed plants and their corresponding progeny. Seed-to-seed variability and plant-to-plant variability in VLC-PUFA amounts per seed are high even for identical clones cultivated side by side under identical greenhouse conditions. Also, it has now been found and is reported below in the examples that the contentration of VLC-PUFAs is negatively correlated with seed oil content in Brassica napus. The mere statement of VLC- PUFA concentration in %(w/w) of all fatty acids of a plant oil is not indicative of the VLC-PUFA amount achievable by agricultural (i.e. large scale) growing of corresponding clones.VLC-PUFA amounts or concentrations depends on which genes, promoters, gene-promoter combinations, gene-gene combinations etc. are beneficial for VLC-PUFA synthesis in oilseed plants. Different classes of seed groupings based on the seeds used to generate that group are: (i) "individual seed" or "single seed" refers to one seed from one plant, (ii) seed derived from a "individual plant" refers to all seeds grown on a single plant without effort to select based on seed-to-seed variability, (iii) "batches of seed" or "seedbatches" refers to all of the seeds collected from a specific number of plants without selection based on plant-to-plant or seed-to-seed variability. The specific number of plants referred to in a batch can be any number, one or greater, where it is understood that a batch of one plant is equivalent to individual plant, (iv) "bulked seed" refers to all of the seed gathered from a large number of plants (equal to or greater than 100) without effort to select seeds based on plant-to-plant or seed-to-seed variability.
Also, it is important to note that VLC-PUFA amounts or concentrations can indeed be increased by increasing the number of expression cassettes of functionally identical genes. And it is also important to note that even though many prior art documents purport to comprise applicable technical teachings, e.g. to combine desaturases having a particular property, e.g. CoA- dependence, it is not known how to reduce such alleged technical teachings to practice, particularly as such documents only teach requirements (i.e. functional claim features) but not solutions for these requirements (i.e. structural features). For example, such prior art documents frequently comprise only one example of a single gene and leave the reader with the instruction to start a research program to find other enzymes satisfying the functional definition given therein, provided that any other enzyme exists that satisfies those functional requirements.
Unless stated otherwise, a plant of the present invention comprising a T-DNA or construct of the present invention can also be a plant comprising a part of a T-DNA or construct of the present invention, where such part is sufficient for the production of a desaturase and/or elongase coded for in the corresponding full T-DNA or construct of the present invention. Such plants most preferably comprise at least one full T-DNA or construct of the present invention in addition to the part of a T-DNA of the present invention as defined in the previous sentence. Such plants are hereinafter also termed "partial double copy" plants. Event LBFDAU is an example of a plant comprising a part of a T-DNA of the present invention, and still being a plant of the present invention. In one embodiment the T_DNA is a full T-DNA.
Preferred plants of the present invention comprise one or more T-DNA(s) or construct of the present invention comprising expression cassettes comprising, one or more genes encoding for one or more d5Des, one or more d6Elo, one or more d6Des, one or more o3Des, one or more d5Elo and one or more D4Des, preferably for at least one CoA-dependent D4Des and one Phospholipid-dependent d4Des. In one embodiment, at least one T-DNA further comprises an expression cassette which encodes for at least one d12Des. In one embodiemt, the T-DNA or T- DNAs further comprise one or more expression cassettes encoding one or more d5Des(Tc_GA), o3Des(Pir_GA), d6Elo(Tp_GA) and/or d6Elo(Pp_GA), an explanation for the abbreviation in the brackets is given e.g. in Table 130, e.g. d6Elo(Tp_GA) is a Delta-6 elongase from Thaiassiosira pseudonana, d6Elo(Pp_GA) i a Delta-6 elongase from Physcomitrella patens. Such plants of the present invention have shown particularly high amounts and concentrations of VLC-PUFAs over three or more generations and under different growth conditions.
Preferred plants according to the invention are oilseed crop plants.
Most preferably, the plant of the present invention is a plant found in the "Triangle of U", i.e. a plant of genus Brassica: Brassica napus (AA CC genome; n=19) is an amphidiploid plant of the Brassica genus but is thought to have resulted from hybridization of Brassica rapa (AA genome; n=10) and Brassica oleracea (CC genome; n=9). Brassica juncea (AA BB genome; n=18) is an amphidiploid plant of the Brassica genus that is generally thought to have resulted from the hybridization of Brassica rapa and Brassica nigra (BB genome; n=8). Under some growing conditions, B. juncea may have certain superior traits to B. napus. These superior traits may include higher yield, better drought and heat tolerance and better disease resistance. Brassica carinata (BB CC genome; n=17) is an amphidiploid plant of the Brassica genus but is thought to have resulted from hybridization of Brassica nigra and Brassica oleracea. Under some growing conditions, B. carinata may have superior traits to B. napus. Particularly, B. carinata allows for an increase in VLC-PUFA concentrations by at least 20% compared to B. napus when transformed with the same T-DNA. The plant of the present invention preferably is a "Canola" plant. Canola is a genetic variation of rapeseed developed by Canadian plant breeders specifically for its oil and meal attributes, particularly its low level of saturated fat. Canola herein generally refers to plants of Brassica species that have less than 2% erucic acid (Delta 13-22:1 ) by weight in seed oil and less than 30
micromoles of glucosinolates per gram of oil free meal. Typically, canola oil may include saturated fatty acids known as palmitic acid and stearic acid, a monounsaturated fatty acid known as oleic acid, and polyunsaturated fatty acids known as linoleic acid and linolenic acid. Canola oil may contain less than about 7%(w/w) total saturated fatty acids (mostly palmitic acid and stearic acid) and greater than 40%(w/w) oleic acid (as percentages of total fatty acids). Traditionally, canola crops include varieties of Brassica napus and Brassica rapa. Preferred plants of the present invention are spring canola (Brassica napus subsp. oleifera var. annua) and winter canola (Brassica napus subsp. oleifera var. biennis). Furthermore a canola quality Brassica juncea variety, which has oil and meal qualities similar to other canola types, has been added to the canola crop family (U.S. Pat. No. 6,303,849, to Potts et al., issued on Oct. 16, 2001 ; U.S. Pat. No. 7,423,198, to Yao et al.; Potts and Males, 1999; all of which are incorporated herein by reference). Likewise it is possible to establish canola quality B. carinata varieties by crossing canola quality variants of Brassica napus with Brassica nigra and appropriately selecting progeny thereof, optionally after further back-crossing with B. carinata, B. napus and/or B. nigra.
The invention also provides a plant or seed thereof of family Brassicaceae, preferably of genus Brassica, with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from progeny lines prepared by a method comprising the steps of i) crossing a plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant comprising a T-DNA or construct of the present invention and/or part of such T-DNA, with a parent plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant not comprising said T- DNA and/or part thereof, to yield a F1 hybrid,
ii) selfing the F1 hybrid for at least one generation, and
iii) identifying the progeny of step (ii) comprising the T-DNA of the present invention capable of producing seed comprising VLC-PUFA.
Preferably, the progeny are capable of producing seed comprising an oil as described elsewhere herein (in particular, see the definition for the oil of the present invention). More preferably, the progeny shall be capable of producing seed comprising VLC-PUFA such that the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 12% (w/w) and/or the content of DHA is at least 2% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w). Also preferably, the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 5%, in particular at least 8% (w/w) and/or the content of DHA is at least 1 % (w/w), in particular 1 .5% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w). This method allows to effectively incorporate genetic material of other members of family Brassicaceae, preferably of genus Brassica, into the genome of a plant comprising a T-DNA or construct of the present invention. The method is particularly useful for combining a T-DNA or construct of the present invention with genetic material responsible for beneficial traits exhibited
in other members of family Brassicaceae. Beneficial traits of other members of family Brassicaceae are exemplarily described herein, other beneficial traits or genes and/or regulatory elements involved in the manifestation of a beneficial trait may be described elsewhere. The parent plant not comprising the T-DNA or contruct of the present invention or part thereof preferably is an agronomically elite parent. In particular, the present invention teaches to transfer heterologous material from a plant or seed of the present invention to a different genomic background, for example a different variety or species. In particular, the invention teaches to transfer the T-DNA or part thereof (the latter is particularly relevant for those plants of the present invention which comprise, in addition to a full T-DNA of the present invention, also a part of a T-DNA of the present invention, said part preferably comprising at least one expression cassette, the expression cassette preferably comprising a gene coding for a desaturase or elongase, preferably a delta-12-desaturase, delta-6-desaturase and/or omega-3-desaturase), or construct into a species of genus Brassica carinata, or to introduce genetic material from Brassica carinata or Brassica nigra into the plants of the present invention comprising the T-DNA of the present invention and/or a part or two or more parts thereof. According to the invention, genes of Brassica nigra replacing their homolog found in Brassica napus or added in addition to the homolog found in Brassica napus are particularly helpful in further increasing the amount of VLC-PUFAs in plant seeds and oils thereof.
Also, the invention teaches novel plant varieties comprising the T-DNA and/or part thereof of the present invention. Such varieties can, by selecting appropriate mating partners, be particularly adapted e.g. to selected climatic growth conditions, herbicide tolerance, stress resistance, fungal resistance, herbivore resistance, increased or reduced oil content or other beneficial features. As shown hereinafter in the examples it is particularly beneficial to provide plants of the present invention wherein the oil content thereof at harvest is lower than that of corresponding wild type plants of the same variety, such as to improve VLC-PUFA amounts in the oil of said plants of the present invention and/or VLC-PUFA concentrations in said oil.
Also, the invention provides a method for creating a plant with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from progeny lines prepared by a method comprising the steps of
i) crossing a transgenic plant of the invention with a parent plant not comprising a T-DNA of the present invention or part thereof, said parent plant being of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, to yield a F1 hybrid,
ii) selfing the F1 hybrid for at least one generation, and
iii) identifying the progeny of step (ii) comprising the T-DNA of the present invention capable of producing seed comprising VLC-PUFA.
Preferably, the progeny are capable of producing seed comprising an oil as described elsewhere herein (in particular the oil of the present invention). More preferably, the progeny shall be capable
of producing seed comprising VLC-PUFA such that the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 8% (w/w) and/or the content of DHA is at least 1 % (w/w) of the total seed fatty acid content at an oil content of 30% (w/w), preferably at an oil content of 35% (w/w), and more preferably at an oil content of 40% (w/w).
The method allows the creation of novel variants and transgenic species of plants of the present invention, and the seeds thereof. Such plants and seeds exhibit the aforementioned benefits of the present invention. Preferably, the content of EPA is at least 5%, more preferably at least 8%, even more preferably at least 10% by weight, most preferably at least 13% (w/w), of the total lipid content of the oil. Also preferably, the content of DHA is at least 1.0% by weight, more preferably at least 1.5%, even more preferably at least 2% (w/w), of the total lipid content of the oil. The present invention for the first time allows to achieve such high levels of VLC-PUFA in seed reliably under agronomic conditions, i.e. representative for the real yield obtained from seeds of a commercial field of at least 1 ha planted with plants of the present invention, wherein the plants have a defined copy number of genes for implementing the pathway for production of EPA and/or DHA in said plants, and the copy number being low, i.e. single-copy or partial double copy.
A plant of the present invention also includes plants obtainable or obtained by backcrossing (cross into the non-transgenic, isogenic parent line), and by crossing with other germplasms of the Triangle of U. Accordingly, the invention provides a method for creating a plant with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from a progeny line prepared by a method comprising the steps of
i) crossing a transgenic plant of the invention (also called "non-recurring parent") with a parent plant not expressing a gene comprised in the T-DNA of the present invention, said parent plant being of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, to yield a hybrid progeny,
ii) crossing the hybrid progeny again with the parent to obtain another hybrid progeny, iii) optionally repeating step ii) and
iv) selecting a hybrid progeny comprising the T-DNA of the present invention.
Backcrossing methods, e.g. as described above, can be used with the present invention to improve or introduce a characteristic into the plant line comprising the T-DNA of the present invention. Such hybrid progeny is selected in step iv) which suffices predetermined parameters. The backcrossing method of the present invention thereby beneficially facilitates a modification of the genetic material of the recurrent parent with the desired gene, or preferably the T-DNA of the present invention, from the non-recurrent parent, while retaining essentially all of the rest of the desired genetic material of the recurrent parent, and therefore the desired physiological and morphological, constitution of the parent line. The selected hybrid progeny is then preferably multiplied and constitutes a line as described herein. Selection of useful progeny for repetition of step ii) can be further facilitated by the use of genomic markers. For example, such progeny is selected for the repetition of step ii) which comprises, compared to other progeny obtained in the
previous crossing step, most markers also found in the parent and/or least markers also found in the non-recurring parent except the desired T-DNA of the present invention or part thereof.
Preferably, a hybrid progeny is selected which comprises the T-DNA of the present invention, and even more preferably also comprises at least one further expression cassette from the nonrecurring parent of the present invention, e.g. by incorporation of an additional part of the T-DNA of the present invention into the hybrid plant genetic material.
Further preferably a hybrid progeny is obtained wherein essentially all of the desired morphological and physiological characteristics of the parent are recovered in the converted plant, in addition to genetic material from the non-recurrent parent as determined at the 5% significance level when grown under the same environmental conditions.
Further preferably, a hybrid progeny is selected which produces seed comprising an oil as described elsewhere herein (i.e. an oil of the present invention). In particular, a hybrid progeny is selected which produces seed comprising VLC-PUFA such that the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 8% (w/w) and/or the content of DHA is at least 1 % (w/w) of the total seed fatty acid content at an oil content of 30% (w/w), preferably at an oil content of 35% (w/w), and more preferably at an oil content of 40% (w/w).
It is to be understood that such seed VLC-PUFA content is to be measured not from a single seed or from the seeds of an individual plant, but refer to the numeric average of seed VLC-PUFA content of at least 100 plants, even more preferably of at least 200 plants, even more preferably of at least 200 plants half of which have been grown in field trials in different years, in particular ofbulked seed VLC-PUFA content of at least 100 plants, even more preferably of at least 200 plants, even more preferably of at least 200 plants half of which have been grown in field trials in different years. The choice of the particular non-recurrent parent will depend on the purpose of the backcross. One of the major purposes is to add some commercially desirable, agronomically important trait to the line.
The term "line" refers to a group of plants that displays very little overall variation among individuals sharing that designation. A "line" generally refers to a group of plants that display little or no genetic variation between individuals for at least one trait. A "DH (doubled haploid) line," as used in this application refers to a group of plants generated by culturing a haploid tissue and then doubling the chromosome content without accompanying cell division, to yield a plant with the diploid number of chromosomes where each chromosome pair is comprised of two duplicated chromosomes. Therefore, a DH line normally displays little or no genetic variation between individuals for traits. Lines comprising one or more genes originally comprised in a T-DNA of the present invention in the non-recurring parent also constitute plants of the present invention.
The invention is also concerned with a method of plant oil production, comprising the steps of
i) growing a plant of the present invention such as to obtain oil-containing seeds thereof, ii) harvesting said seeds, and
iii) extracting oil from said seeds harvested in step ii). Preferably, the oil is an oil as described herein below in more detail (i.e. an oil of the present invention). More preferably, the oil has a DHA content of at least 1 % by weight based on the total lipid content and/or a EPA content of at least 8% by weight based on the total lipid content. Also preferably, the oil has a DHA content of at least 1 % by weight based on the total fatty acid content and/or a EPA content of at least 8% by weight based on the total fatty acid content.
Again preferably, the content of EPA is at least 10% by weight, even more preferably at least 13% (w/w), of the total lipid content of the oil. Also preferably, the content of DHA is at least 1 .5% by weight, even more preferably at least 2% (w/w), of the total lipid content of the oil. As described herein, the plant of the present invention comprises, for the purposes of such method of plant oil production, preferably comprises a T-DNA (or construct) of the present invention and optionally also one or more additional parts thereof, wherein the part or parts, respectively, comprise at least one expression cassette of the T-DNA of the present invention.
The invention is also concerned with parts of plants of the present invention. The term "parts of plants" includes anything derived from a plant of the invention, including plant parts such as cells, tissues, roots, stems, leaves, non-living harvest material, silage, seeds, seed meals and pollen. Preferably such plant part comprises a T-DNA of the present invention and/or comprises a content of EPA of at least 8% by weight, more preferably at least 10%, even more preferably at least 13% (w/w), of the total lipid content. Also preferably, the content of DHA is at least 1 .0% by weight, more preferably at least 1.5%, even more preferably at least 2% (w/w), of the total lipid content of the plant part. Parts of plants of the present invention comprising, compared to wild-type plants, elevated content of EPA and/or DHA, or the oil or lipid of the present invention are particularly useful also for feed purposes, e.g. for aquaculture feed, e.g. as described in AU201 1289381A and members of the patent family thereof.
The plants of the present invention do not necessarily have to comprise a complete T-DNA of the present invention. As described above, by crossing (or back-crossing) methods it is possible to transfer arbitrary genetic material of one line to another line. Thus, by applying such crossing or back-crossing it is possible to transfer one or more, even all, expression cassettes comprised in a plant of the present invention (such plant comprising a T-DNA of the present invention) to another plant line, thereby losing e.g. a left or right border element (or both) and/or a spacer.
Thus, the invention also provides plants comprising genetic material hybridizing to a primer as given in Example 24.
Also, the invention provides plants comprising a heterologous nucleic acid segment inserted in its genetic material. The insertion is according to the invention in one of the below listed flanking regions or between a pair of flanking regions. Due to plant-to-plant variability, each flanking region
may differ from the below indicated flanking regions by at most 10% calculated over a consecutive stretch of at least 100nt, preferably by at most 5% calculated over a consecutive stretch of at least - with increasing percentage identity more preferred - 90. 91. 92, 93, 94, 95, 96, 97, 98 or 99, preferred 100% identity for 100 nt. Even more preferably, the flanking region(s) comprise at least - with increasing percentage identity more preferred - 90. 91. 92, 93, 94, 95, 96, 97, 98 or 99, preferred 100% identity for 50 consecutive nucleotides identical to a fragment of a flanking region as given below, even more preferable the length of consecutive identical nucleotides is at least 100. Example 24 provides an overview of all the flanking sequences of all loci obtained for each event listed in that table. In addition, event specific primers and probes are disclosed in Table 176 for event specific detection. The method for using those primers and probes is described in example 24. As shown in the examples, insertions in these flanking regions have now been proven to lead to a surprisingly high production of VLC-PUFAs in seed, wherein such production is stable over many generations and under different growth conditions. Thus, insertion of other genetic material at these insertion locations also leads to a stable, high expression of inserted genes compared to insertions at other positions of the plant genome.
The invention is also concerned with establishing and optimizing efficient metabolic VLC-PUFA synthesis pathways. To this end, the invention provides a method for analysing desaturase reaction specificity, comprising the steps of
i) providing, to a desaturase, a detectably labelled molecule comprising a fatty acid moiety and a headgroup,
ii) allowing the desaturase to react on the labelled molecule, and
iii) detecting desaturation products.
The labelled molecule preferably is a fatty acid-coenzyme A or a fatty acid-phospholipid, the latter preferably being a lysophosphatidylcholine bound fatty acid. The method advantageously allows to determining desaturase headgroup preference or even headgroup specificity by detecting whether coenzyme A bound fatty acids are desaturated and/or whether phospholipid-bound fatty acids are desaturated. Preferably the desaturase is provided as a microsomal fraction of an organism, preferably of yeast. Transgenic yeasts expressing the desaturase in question are easy to prepare and handle, and microsomal fractions comprising functional desaturases can be reliably and reproducibly prepared thereof without major burden. Microsomal fractions, particularly of yeast, most preferably of Saccharomyces cerevisiae, also allow to convert fatty acid-coenzyme A molecules to fatty acids bound to other headgroups by using the yeast's native LPCAT. Likewise, microsomal fractions can be prepared from other cells and organisms.
Preferably the molecule is detectably labelled by including a radioactive isotope instead of a nonradioactive isotope. The isotope preferably is [14C]. Such label is easy to detect, does not interefere in biochemical reactions and can be incorporated in virtually any carbon-containing molecule, thereby allowing sensitively detecting and characterizing any desaturation product.
The fatty acid moiety preferably is a PUFA moiety, more preferably a VLC-PUFA moiety and most preferably a VLC-PUFA moiety. This way, the headgroup preference or specificity for economically important desaturases can be determined without having to resort to error prone and laborious feeding of live organisms or living cells.
The desaturase is allowed to react on the labelled molecule. If the desaturase can accept the labelled molecule as a substrate, then the desaturation reaction is performed. Preferably, the method is repeated by including, as a positive control, a labelled molecule which had been confirmed to be a substrate for the desaturase.
Detection preferably is accomplished using chromatography, most preferably thin layer chromatography. This technique is well known to the skilled person, readily available, very sensitive and allows differentiating even between very similar molecules. Thus, even if the positive control molecule is similar to the molecule of interest, a clear detection of desaturation products (if desaturation of the molecule occurred) is still possible.
The above method allows preparing a collection of specificity data for each desaturase, type of microsomal fraction (e.g. from yeast, plant cells etc.), fatty acid moiety and headgroup. Thus, the method can be used to select a desaturase for a given need, e.g. to accept CoA-bound fatty acids in plant cells for further presentation to an elongase. The method also allows establishing substrate specificty of the desaturase in an organism or organ of interest, e.g. a yeast, a plant leaf cell or a plant seed cell.
The invention also provides a method for analysing elongase reaction specificity, comprising the steps of
i) providing, to an elongase, a detectably labelled elongation substrate and a molecule to be elongated,
ii) allowing the elongase to elongate the molecule to be elongated using the labelled elongation substrate, and
iii) detecting elongation products.
Unless stated otherwise, the method for analysing elongase reaction specificity is performed corresponding to the method for analysing desaturase reaction specificity for corresponding reasons. The elongation substrate preferably is malonyl-CoA. The elongation substrate is preferably labelled radioactively, most preferably [14C] malonyl-CoA. Radioactive labelling allows for an easy and sensitive detection of elongation products. Also, labelling of the elongation substrate instead of the molecule to be elongated allows presenting a mixture of molecules to be elongated to the elongase, and only the elongation products will have incorporated significant
amounts of label to render them easily detectable. Thus, in a single reaction vessel a multitude of potential molecules to be elongated can be assayed to determine which of these molecules are indeed elongated, and the relative affinity of the elongase to the respective molecule. By combining both methods, it is possible to analyse even complex sequences of desaturation and elongation reactions. The invention thus also provides a method for pathway optimization, comprising the steps of
i) providing enzymes of a metabolic pathway and one or more substrates to be used by the first enzyme or enzymes of the pathway,
ii) reacting the enzymes and the substrates to produce products, which in turn are also exposed as potential substrates to the enzymes of the pathway, and
iii) determining the accumulation of products.
The method particularly allows providing desaturases and elongases to form a pathway. This is useful to determine the yield of product(s) of the pathway and of any unwanted side products. Also, by providing two or more different enzymes which perform the same metabolic function, e.g. a particular desaturation step, e.g. a delta-5 desaturation, it is possible to analyse if the presence of more than one type of enzymes has an effect on product formation, particularly on product formation rate. For such analysis, one would compare the results with a method performed with only one of the at least two enzymes. Thus, if addition of enzymes performing the same metabolic function leads to an increased yield or product formation rate, then this metabolic step is subject to a gene dosage effect. To optimize the pathway in an organism one would correspondingly strive to implement the pathway step using the two or more enzymes as required. Also, the method advantageously allows determining the mode of action of an enzyme in question. To this end, a helper enzyme is provided to produce a substrate for a target enzyme. The helper enzyme's mode of action is known. The helper enzyme is then provided with a substrate to turn into a product which could be used as a substrate of the target enzyme. Generation of product by the target enzyme is determined, preferably by measuring the amount of product per time or the final amount of product divided by the amount of substrate converted by the helper enzyme. Then the method is repeated using a helper enzyme of a different mode of action, and generation of product by the target enzyme is determined, too. By comparing the product generation by the target enzyme for each mode of action, the mode of action of the target enzyme is defined as being the mode of action of the helper enzyme giving rise to the most intense generation of product by the target enzyme.
For example, to determine the mode of action of a target desaturase, a helper elongase is provided for which it has been text book knowledge that it is utilizing acyl CoA substrate and produces acyl-CoA products. Then, product generation by the target desaturase is measured. In another step, a helper desaturase is provided for which it has been established that it produces phosphatidylcholine-bound fatty acids. Again, product generation by the target desaturase is measured. When comparing the product generation of the target desaturase, the target desaturase can be defined as being a CoA-dependent desaturase if the product generation of the
target desaturase under conditions where CoA-bound fatty acids are provided by the helper enzyme is more intense (e.g. higher conversion efficiency) than under conditions where phosphatidylcholine-bound fatty acids are provided by the helper enzyme. Thus, the invention also provides a method for determining CoA-dependence of a target desaturase, comprising the steps of
i) providing an elongase to produce a substrate for the target desaturase, and determining conversion efficiency of the target desaturase, and
ii) providing a non-CoA dependent desaturase to produce the substrate for the target desaturase, and determining conversion efficiency of the target desaturase, and iii) comparing the target desaturase conversion efficiencies of step i) and ii).
If the conversion efficiency of the target desaturase is larger in step i) than in step ii), then the target desaturase is CoA-dependent. Of course, both steps must be performed under comparable conditions; particularly a substrate limitation of the target desaturase must be avoided.
The method can also be performed by providing an elongase which uses the substrate of the target desaturase. Thus, the invention provides a method for determining CoA-dependence of a target desaturase, comprising the steps of
i) providing an elongase to elongate the products of the target desaturase, and determining conversion efficiency of the elongase,
ii) providing the elongase to elongate the products of a comparison desaturase known to be non-CoA dependent, and determining conversion efficiency of the elongase,
iii) comparing the elongase conversion efficiencies of step i) and ii).
If the elongase conversion efficiency is higher in step i) than in step ii), the target desaturase is CoA-dependence. Without being bound by any particular theory it is presently expected that in such case the desaturation product does not have to be converted into an elongatable CoA-bound fatty acid, thus desaturated product can be immediately utilized by the elongase without accumulation. Of course, both steps must be performed under comparable conditions; particularly a substrate limitation of the elongase must be avoided.
The present invention also relates to oil comprising a polyunsaturated fatty acid obtainable by the aforementioned methods. In addition, the present invention also relates to a lipid or fatty acid composition comprising a polyunsaturated fatty acid obtainable by the aforementioned methods.
The term "oil" refers to a fatty acid mixture comprising unsaturated and/or saturated fatty acids which are esterified to triglycerides. Preferably, the triglycerides in the oil of the invention comprise PUFA or VLC-PUFA moieties as referred to above. The amount of esterified PUFA and/or VLC- PUFA is, preferably, approximately 30%, a content of 50% is more preferred, a content of 60%, 70%, 80% or more is even more preferred. The oil may further comprise free fatty acids, preferably, the PUFA and VLC-PUFA referred to above. For the analysis, the fatty acid content can be, e.g., determined by GC analysis after converting the fatty acids into the methyl esters by
transesterification. The content of the various fatty acids in the oil or fat can vary, in particular depending on the source. The oil, however, shall have a non-naturally occurring composition with respect to the PUFA and/or VLC-PUFA composition and content. It is known that most of the fatty acids in plant oil are esterified in triacylglycerides. Accordingly, in the oil of the invention, the PUFAs and VLC-PUFAs are, preferably, also occur in esterified form in the triacylglcerides. It will be understood that such a unique oil composition and the unique esterification pattern of PUFA and VLC-PUFA in the triglycerides of the oil shall only be obtainable by applying the methods of the present invention specified above. Moreover, the oil of the invention may comprise other molecular species as well. Specifically, it may comprise minor impurities (and thus minor amounts) of the polynucleotide or vector of the invention, which however, can be detected only by highly sensitive techniques such as PCR.
As described above, these oils, lipids or fatty acids compositions, preferably, comprise 4 to 15% of palmitic acid (in an embodiment 6 to 15% of palmitic acid), 1 to 6% of stearic acid, 7-85% of oleic acid, 0.5 to 8% of vaccenic acid, 0.1 to 1 % of arachidic acid, 7 to 25% of saturated fatty acids, 8 to 85% of monounsaturated fatty acids and 60 to 85% of polyunsaturated fatty acids, in each case based on 100% and on the total fatty acid content of the organisms (preferably by weight). Preferred VLC-PUFAs present in the fatty acid esters or fatty acid mixtures is, preferably, at least 5,5% to 20% of DHA and/or 9,5% to 30% EPA based on the total fatty acid content (preferably by weight).
The oils, lipids or fatty acids according to the invention, preferably, comprise at least 1 %, 1.5%, 2%, 3%, 4%, 5.5%, 6%, 7% or 7,5%, more preferably, at least 8%, 9%, 10%, 1 1 % or 12%, and most preferably at least 13%, 14%, 15%, 16%. 17%, 18%, 19% or 20% of DHA (preferably by weight), or at least 5%, 8%, 9.5%, 10%, 1 1 % or 12%, more preferably, at least 13%, 14%, 14,5%, 15% or 16%, and most preferably at least 17 % , 18 % , 19 % , 20 % . 21 %, 22%, 23%, 24%, 25%, 26%, 27%, 28%, 29% or 30% of EPA (preferably by weight) based on the total fatty acid content of the production host cell, organism, advantageously of a plant, especially of an oil crop such as soybean, oilseed rape, coconut, oil palm, safflower, flax, hemp, castor-oil plant, Calendula, peanut, cacao bean, sunflower or the abovementioned other monocotyledonous or dicotyledonous oil crops. In an embodiment, the oils, lipids or fatty acids according to the invention, preferably, comprise at least 1 % of DHA, and/or at least 8% of EPA based on the total fatty acid content of the production host cell, organism, advantageously of a plant, especially of an oil crop such as soybean, oilseed rape, coconut, oil palm, safflower, flax, hemp, castor-oil plant, Calendula, peanut, cacao bean, sunflower or the abovementioned other monocotyledonous or dicotyledonous oil crops.
Preferably, the oil, lipid or fatty acid composition of the present invention is a plant oil, plant lipid, or plant fatty acid composition. Preferably, said oil or lipid is extracted, obtained, obtainable or produced from a plant, more preferably from seeds of a plant or plants (in particular a plant or plants of the present invention). The oil or lipid thus can be obtained by the methods of the present invention. In particular, the plant oil or plant lipid is an extracted plant oil or lipid. Also preferably, said oil or lipid is extracted, obtained, obtainable or produced from a plant, more preferably from
batches of seeds or bulked seeds of a plant or plants (in particular a plant or plants of the present invention).
Preferably, the term "extracted" in connection with an oil or lipid refers to an oil or lipid that has been extracted from a plant, in particular from seeds of a plant or plants. More preferably, the term "extracted" in connection with an oil or lipid refers to an oil or lipid that has been extracted from a plant, in particular from batch of seeds or bulked seeds of a plant or plants. Such oil or lipid can be a crude composition. However, it may be also a purified oil or lipid in which e.g. the water has been removed. In an embodiment, the oil or lipid is not blended with fatty acids from other sources.
The oil or lipid of the present invention may be also an oil or lipid in a seed of plant. Preferably, said plant is a transgenic plant. More preferably, said plant is a plant of the present invention. In a particular preferred embodiment, the plant is a Brassica plant.
The oil or lipid of the present invention shall comprise fatty acids. In particular, the oil or lipid shall comprise fatty acids in esterified form. Thus, the fatty acids shall be esterified. Preferably, the oil or lipid of the present comprises one or more of following fatty acids (in esterified form): Oleic acid (OA), Linoleic acid (LA), gamma-Linolenic acid (GLA), alpha-Linolenic acid (ALA), Stearidonic acid (SDA), 20:2n-9 ((Z,Z)-8,1 1 -Eicosadienoic acid), Mead acid (20:3n-9), Dihomo-gamma- linolenic acid (DHGLA), Eicosapentaenoic acid (Timnodonic acid, EPA, 20:5n-3), Clupanodonic acid (DPA n-3), and DHA ((Z,Z,Z,Z,Z,Z)-4,7,10,13,16,19-Docosahexaenoic acid). More preferably, the oil or lipid comprises EPA, DHA and Mead acid. Even more preferably, the oil or lipid comprises EPA, DHA, Mead acid, DPA n-3, and DHGLA. Most preferably, the oil or lipid comprises fatty acids mentioned in this paragraph.
It is in particular envisaged that the oil or lipid of the present invention comprises both EPA and DHA. Preferred contents of EPA and DHA are given elsewhere herein. Further, it is envisaged that the oil or lipid comprises EPA, DHA, and DPA n-3. In an embodiment, the oil or lipid further comprises Mead Acid.
Also, it is envisaged that the oil or lipid comprises EPA, DHA, and DHGLA. In an embodiment, the oil or lipid further comprises Mead Acid.
In addition, the oil or lipid may comprise EPA, DHA, DPA n-3, and DHGLA. In an embodiment, the oil or lipid further comprises Mead Acid.
Thus, the expression cassettes, the construct or the T-DNA of the present invention can be used for modulating, in particular increasing, the content of one or more of the aforementioned fatty acids in plants, in seeds and/or in seed oil of a plant as compared to a control plant.
The preferred content of aforementioned fatty acids in the total fatty acid content of the lipid or oil of the present invention is further described in the following. In the following, ranges are given for
the contents. The contents (levels) of fatty acids are expressed as percentage (weight of a particular fatty acid) of the (total weight of all fatty acids), in particular of the (total weight of all fatty acids present in the oil or lipid). The contents are thus, preferably given as weight percentage (% (w/w)) of total fatty acids present in the oil or lipid. Accordingly, "%" preferably means "% (w/w) for a fatty acid (or combination of fatty acids) compared to the total weight of fatty acids".
Preferably, the fatty acids are present in esterified form. Thus, the fatty acids shall be esterified fatty acids. Preferably, the oil or lipid comprises Oleic acid (OA). Preferably, the content of Oleic acid (OA) is between 10% and 45%, more preferably between 20% and 38%, most preferably between 26% and 32% of the total fatty acid content.
Preferably, the oil or lipid comprises Linoleic acid (LA). Preferably, the content of Linoleic acid (LA) is between 5% and 40%, more preferably between 10% and 40%, most preferably between 20% and 35% of the total fatty acid content.
Preferably, the oil or lipid comprises gamma-Linolenic acid (GLA). Preferably, the content of gamma-Linolenic acid (GLA) is between 0.1 % and 6%, more preferably between 0.1 % and 3%, most preferably between 0.5% and 2% of the total fatty acid content.
Preferably, the oil or lipid comprises alpha-linolenic acid (ALA). Preferably, the content of alpha- Linolenic acid (ALA) is between 2% and 20%, more preferably between 4% and 10%, most preferably between 4% and 7% of the total fatty acid content. Preferably, the oil or lipid comprises Stearidonic acid (SDA). Preferably, the content of Stearidonic acid (SDA) is between 0.1 % and 10%, more preferably between 0.1 % and 5%, most preferably between 0.1 % and 1 % of the total fatty acid content.
The content of SDA was surprisingly low. In an embodiment, the content of SDA is lower than 2%, in particular lower than 1 %.
Preferably, the oil or lipid comprises 20:2n-9. Preferably, the content of 20:2n-9 ((Z,Z)-8,1 1 - Eicosadienoic acid) is between 0.1 % and 3%, more preferably between 0.1 % and 2%, most preferably between 0.1 % and 1 % of the total fatty acid content.
Preferably, the oil or lipid comprises Mead acid (20:3n-9). Preferably, the content of Mead acid (20:3n-9) is between 0.1 % and 2%, more preferably between 0.1 % and 1 %, most preferably between 0.1 % and 0.5% of the total fatty acid content. In another embodiment, the content of Mead acid (20:3n-9) is between 0.1 % and 0.3% of the total fatty acid content
Preferably, the oil or lipid comprises Dihomo-gamma-linolenic acid (DHGLA). Preferably, the content of Dihomo-gamma-linolenic acid (DHGLA) is between 0.1 % and 10%, more preferably
between 1 % and 6%, most preferably between 1 % and 5%, in particular between 2 and 4% of the total fatty acid content. The accumulation of this internmediate was not necessarily expected.
Preferably, the oil or lipid comprises EPA (20:5n-3). Preferably, the content of Eicosapentaenoic acid (Timnodonic acid, EPA, 20:5n-3) is between 0.1 % and 20%, more preferably between 2% and 15%, most preferably between 5% and 10% of the total fatty acid content.
Further, it is envisaged that the content of EPA is between 5% and 15% of the total fatty acid content
Preferably, the oil or lipid comprises Clupanodonic acid (DPA n-3). Preferably, the content of Clupanodonic acid (DPA n-3) is between 0.1 % and 10%, more preferably between 1 % and 6%, most preferably between 2% and 4% of the total fatty acid content. In addition, the content of DPA n-3 may be at least 2% of the total fatty acids.
Preferably, the oil or lipid comprises DHA. Preferably, the content of DHA is between 1 % and 10%, more preferably between 1 % and 4%, most preferably between 1 % and 2% of the total fatty acid content. Further, it is envisaged that the content of DHA is between 1 % and 3% of the total fatty acid content
In a preferred embodiment, the oil or lipid of the invention has a content of DHA between 1 % and 4% and a content of EPA between 2% and 15% of the total fatty acid content. In another preferred embodiment, the oil or lipid of the invention has a content of DHA between 1 % and 3% and a content of EPA between 5% and 15% of the total fatty acid content.
In another preferred embodiment, the oil or lipid of the invention has a content of DHA between 1 % and 2% and a content of EPA between 5% and 10% of the total fatty acid content. The oil or lipid of the present invention may also comprise saturated fatty acids such as 16:0 (Palmitic acid) and/or 18:0 (Stearic acid). The contents of 16:0 and 18:0 are advantageoulsly low as compared to wild-type plants. Low saturated fat is a desireable feature from the health perspective. Thus, the oil or lipid may comprise 16:0. Preferably, the content of 16:0 is less than 6% of the total fatty acid content. More preferably, the content of 16:0 is between 3% and 6% of the total fatty acid content
Thus, the oil or lipid may comprise 18:0. Preferably, the content of 18:0 is less than 4%, in particular less than 3% of the total fatty acid content. More preferably, the content of 18:0 is between 1 .5% and 4%, in particular between 2% and 3% of the total fatty acid content.
In an embodiment of the oil or lipid of the present invention, the total content of EPA, DHA and DPA n-3 is preferably more than 6% and the content of SDA is lower than 2% of all fatty acids present in the oil or lipids. More preferably the content of EPA, DHA, and DPA n-3 is between 7% and 14% and the content of SDA is lower than 1 % of all fatty acids present in the oil or lipids.
In another preferred embodiment of the oil or the lipid of the present invention, the content of DPA n-3 is preferably at least 2% of the total fatty acid content, and the total content of EPA and DHA is at least 3% of the total fatty acid content. More preferably the content of DPA n-3 is between 2% and 5%, and the total content of EPA and DHA is between 6% and 12% of all fatty acids present in the oil or lipids.
In an embodiment of the oil or the lipid of the present invention, the content of 16:0 is preferably lower than 6% of the total fatty acid content, and the total content of EPA and DHA is at least 3% of the total fatty acid content. More preferably the content of 16:0 is between 2% and 6%, and the total content of EPA and DHA is between 6% and 12% of all fatty acids present in the oil or lipids.
In an embodiment of the oil or the lipid of the present invention, the content of 16:0 is preferably lower than 5% of the total fatty acid content, and the total content of EPA, DHA, DPA n-3 is at least 6% of the total fatty acid content. More preferably content of 16:0 is between 2% and 5% and the total content of EPA, DHA, and DPA is between 8% and 14% of all fatty acids present in the oil or lipids.
Interestingly, the content of EPA of the total fatty acids in the seeds, in particular in the seed oil, was larger than the content of DHA. This is not always the case; see for examples US2015/0299676A1 and WO 2015/089587. Thus, it is in particular envisaged, that the oil and lipid of the present invention comprises more EPA than DHA. Thus, the content of EPA shall be larger than the content of DHA. Preferably, the content of EPA of the total fatty acid acid content is 3 to 7-fold the content of DHA of the total fatty acid content. More preferably, the content of EPA of the total fatty acid acid content is 4 to 5-fold the content of DHA of the total fatty acid content.
Preferably, the total content of all omega-3 polyunsaturated [n-3 (C18-C22)] fatty acids is between 1 % and 40%, more preferably between 10% and 30%, most preferably between 15% and 22% of the total fatty acid content.
Also preferably, the total content of all omega-6 polyunsaturated [n-6 (C18-C22)] fatty acids is between 0.1 % and 50%, more preferably between 20% and 50%, most preferably between 37% and 42% of the total fatty acid content. The oil or lipid of the present invention may comprise fatty acids that are non-naturally occurring in wild type control Brassica napus lipid or oil, preferably greater than 10%, more preferably between 12% and 25.2%, and most preferably between 16% and 25.0% of the total fatty acid content. Preferably, non naturally occurding fatty acids are 18:2n-9, GLA, SDA, 20:2n-9, 20:3n-
9, 20:3 n-6, 20:4n-6, 22:2n-6, 22:5n-6, 22:4n-3, 22:5n-3, and 22:6n-3. Thus, the total content of these fatty acids in the oil or lipid of the present invention is preferably greater than 10%, more preferably between 12% and 25.2%, and most preferably between 16% and 25.0% of the total fatty acid content
In Example 32 it is shown that certain TAG (triacylglyceride) species were decreased and certain TAG species were increased in the seeds of the plants of the present invention (in particular in seed oil extracted from plants of the present invention). The five most abundant TAG (triacylglyceride) species in wild-type Kumilly plants were TAG (18:1 18:1 18:3), TAG (18:1 18:2 18:3), TAG (18:1 18:1 18:2), TAG (18:1 18:1 18:1 ), and (TAG 18:1 18:2 18:2). Together, these account for 64.5% of all TAG species (in oil of wild-type plants). These species are specifically reduced in plants of the present invention (see Example 32, Table 192). The two most abundant DHA containing TAG species in the transgenic canola samples were TAG (18:1 18:2 22:6) and TAG (18:2 18:2 22:6). Interestingly, the EPA and DHA are found most frequently esterified to TAG together with 18:1 and 18:2. This makeup is likely to be more oxidatively stable that TAG species containing multiple PUFAs (see Wijesundra 2008, Lipid Technology 20(9): 199-202). For more details, see Example 32 and table 192. The oil or lipid of the present invention thus may comprise certain TAG species. Preferably, the oil or lipid comprises one or more of the following TAG species: TAG (18:1 18:2 20:5), TAG (18:1 18:1 20:5), TAG (18:2 18:2 20:5), TAG (18:1 18:2 22:6) and TAG (18:2 18:2 22:6). More preferably, the oil of lipid of the present invention comprises all of the aforementioned TAG species. Alternatively or additionally, the oil or lipid of the present invention may comprise TAG (18:1 18:1 22:6).
The triacylglyceride nomenclature used herein is well known in the art and well understood by the skilled person. The triacylglyceride TAG (x1:y1 x2:y2 x3:y3) is preferably denoted to mean that the triacylglyceride comprises three fatty acid ester residues, wherein one fatty acid ester residue is x1:y1 which means that this residue comprises x1 carbon atoms and y1 double bonds, wherein one fatty acid ester residue is x2:y2 which means that this residue comprises x2 carbon atoms and y2 double bonds, and wherein one fatty acid ester residue is x3:y3 which means that this residue comprises x3 carbon atoms and y3 double bonds. Preferably, any of these fatty acid ester residues may be attached to any former hydroxyl groups of the glycerol.
The preferred content of aforementioned TAG species of the total TAG content of the lipid or oil of the present invention is further described in the following. In the following ranges are given for the contents. The contents (levels) of TAGs are expressed as percentage (weight of a particular TAG, or a combinations of TAGs) of the total weight of total TAGs (i.e. all TAGs) present in the oil or lipid). The contents are thus, preferably, given as weight percentage (% (w/w)). Accordingly, "%" preferably means "% (w/w) for a TAG (or combination of TAGs) compared to the total weight of TAGs".
Preferably, the oil or lipid comprises TAG (18:1 18:2 20:5). Preferably, the content of TAG (18:1 18:2 20:5) is between 0.1 % and 20%, more preferably between 5% and 15%, most preferably between 7% and 12% of the total TAG content. As set forth above, the oil or lipid preferably comprises TAG (18:1 18:1 20:5). Preferably, the content of TAG (18:1 18:1 20:5) is between 1.5% and 15%, more preferably between 2% and 10%, most preferably between 4% and 7.6% of the total TAG content.
As set forth above, the oil or lipid preferably comprises TAG (18:2 18:2 20:5). Preferably, the content of TAG (18:2 18:2 20:5) is between 3% and 20%, more preferably between 3% and 15%, most preferably between 3.5% and 9% of the total TAG content.
Also preferably, the sum of the contents of TAG (18:1 18:2 20:5), TAG (18:1 18:1 20:5), and TAG (18:2 18:2 20:5), i.e. the combined contents of these three TAG species, is between 5% and 55%, more preferably between 10% and 45%, most preferably between 20% and 26% of the total TAG content.
Thus, the most abundant TAG species are those that contain esterified EPA. EPA is better than DHA for some health reasons.
As set forth above, the oil or lipid preferably comprises TAG (18:1 18:2 22:6). Preferably, the content of TAG (18:1 18:2 22:6) is between 0.1 % and 15%, more preferably between 0.1 % and 10%, most preferably between 0.5% and 3% of the total TAG content. As set forth above, the oil or lipid preferably comprises TAG (18:2 18:2 22:6). Preferably, the content of TAG (18:2 18:2 22:6) is between 0.1 % and 15%, more preferably between 0.1 % and 10%, most preferably between 0.5% and 2% of the total TAG content.
As set forth above, the oil or lipid preferably comprises TAG (18:1 18:1 22:6). Preferably, the content of TAG (18:1 18:1 22:6) is between 0.1 % and 15%, more preferably between 0.1 % and 10%, most preferably between 0.3% and 1 % of the total TAG content.
Also preferably, the sum of the contents of TAG (18:1 18:2 22:6), TAG (18:2 18:2 22:6) and TAG (18:1 18:1 22:6), i.e. the combined content of these three TAG species, is between 0.3% and 45%, more preferably between 1 % and 30%, most preferably between 1 % and 5% of the total TAG content.
The oil or lipid of the present invention may also comprise TAG (18:3 18:3 20:5) and/or TAG (18:3 18:3 22:6). As can be seen from the examples, a low abundance of these TAG species was observed (see table 192). The low abundance can have an oxidative stability benefit.
Preferably, the content of TAG (18:3 18:3 20:5) is between 0.1 % and 2%, more preferably between 0.1 % and 1 %, most preferably between 0.1 % and 0.5% of the total TAG content.
Preferably, the content of TAG (18:3 18:3 22:6) is between 0.03% and 2%, more preferably between 0.03% and 1 %, most preferably between 0.03% and 0.5% of the total TAG content. Further, it is contemplated that the content of TAG (18:3 18:3 22:6) is between 0.03% and 0.2% of the total TAG content.
As set forth above, the most abundant TAG species in wild-type Kumily plants were TAG (18:1 18:1 18:3), TAG (18:1 18:2 18:3), TAG (18:1 18:1 18:2), TAG (18:1 18:1 18:1 ), and (TAG 18:1 18:2 18:2). As compared to wild-type oil, the content of these species in seed oil from transgenic Brassice plants was advantageously reduced. One of these species, TAG (18:1 18:1 18:3), was not detectable in the oil.
Thus, the oil or lipid of the present invention may further one or more of the following features: As set forth above, the oil or lipid preferably comprises TAG (18:1 18:1 18:3). Preferably, the content of TAG (18:1 18:1 18:3) is between 0% and 10%, more preferably between 0% and 5%, most preferably between 0% and 3% of the total TAG content.
Also preferably, the content of TAG (18:1 18:1 18:3) of the total TAG content may be lower than 3%, in particular lower than 1 %.
As set forth above, the oil or lipid preferably comprises TAG (18:1 18:2 18:3). Preferably, the content of TAG (18:1 18:2 18:3) is between 3% and 19%, more preferably between 4% and 18%, most preferably between 4% and 7% of the total TAG content.
Also preferably, the content of TAG (18:1 18:2 18:3) of the total TAG content may be lower than 7%.
As set forth above, the oil or lipid preferably comprises TAG (18:1 18:1 18:2). Preferably, the content of TAG (18:1 18:1 18:2) is between 1 % and 10%, more preferably between 2% and 10%, most preferably between 2% and 5% of the total TAG content.
Also preferably, the content of TAG (18:1 18:1 18:2) of the total TAG content may be lower than 5%.
As set forth above, the oil or lipid preferably comprises TAG (18:1 18:1 18:1 ). Preferably, the content of TAG (18:1 18:1 18:1 ) is between 0.1 % and 8%, more preferably between 0.5% and 5%, most preferably between 1 % and 3% of the total TAG content. Also preferably, the content of TAG (18:1 18:1 18: 1 ) of the total TAG content may be lower than 3%.
As set forth above, the oil or lipid preferably comprises TAG (18:1 18:2 18:2). Preferably, the content of TAG (18:1 18:2 18:2) is between 0.1 % and 13%, more preferably between 3% and 1 1 %, most preferably between 4% and 10% of the total TAG content. Also preferably, the content of TAG (18:1 18:2 18:2) of the total TAG content may be lower than 10%.
Also preferably, the total content and thus sum of the contents of TAG (18:1 18:1 18:3), TAG (18:1 18:2 18:3), TAG (18:1 18:1 18:2), and TAG (18:1 18:1 18:1 ), TAG (18:1 18:2 18:2) is between 5% and 50%, more preferably between 10% and 30%, most preferably between 14% and 22% of the total TAG content. In an embodiment, the total content of the aforementioned TAG species of the total TAG content is lower that 21 .2% of the total TAG content.
As can be derived from Example 32, EPA and DHA are found most frequently esterified to TAG together with 18:1 and/or 18:2. These combinations of fatty acids are advantageous because they are more oxidatively stable than TAG species with more than one PUFA. In a preferred embodiment of the oil or lipid of the present invention, less that 21 % of the total TAG species comprised by the oil or lipid contain more than one EPA, DPA, and DHA n-3 residue. The oil or lipid of the present invention comprises TAGs (triacylglycerides), DAGs (diacylglycerides), and DAGs (diacylglycerides). As set forth certain TAG (triacylglyceride) species were decreased and certain TAG species were increased in the seeds of the plants of the present invention (in particular in seed oil of plants of the present invention). In addition, certain MAG and DAG species were decreased and certain MAG and DAG species were increased in the seeds of the plants of the present invention (in particular in seed oil of plants of the present invention).
E.g., the examples show that there is more esterified EPA and DHA in DAG than in MAG. Thus, is is envisaged that the content of esterified EPA and DHA in DAG (with respect to the total esterfied fatty acid content in DAG) is larger than the content of esterified EPA and DHA in MAG (with respect to the total esterfied fatty acid content in MAG). Preferably, the ratio of the content of esterified EPA and DHA in DAG (with respect to the total esterfied fatty acid content in DAG) to the the content of esterified EPA and DHA in MAG (with respect to the total esterfied fatty acid content in MAG) is about 1.5.
Further, the Examples show that DHA is accumulated in the phosphatidylcholine (PC) fraction. This is thought to be achieved by expression of both a phospholipid and CoA dependent d4Des. It could be advantageous because DHA in phospholipids is thought to be more readily digestible.
Preferably, the content of DHA in in the phosphatidylcholine (PC) fraction in the oil or lipid of the present invention is between 2 and 12%, more preferably, between 2 and 10, most preferably between 5 and 9% of to the total fatty acid content of the PC fraction (preferably % w/w).
Morever, it is envisaged that the ratio of the content DHA in the PC fraction to the content in the TAG fraction of the oil or lipid of the present invention is larger than 1 .
In addition, the studies underlying the present invention showed that the ratio of DHA to DPA n-3 is higher in the PC and PE (phosphatidylethanolamine) fraction than in the neutral lipid fraction (MAG, DAG, and TAG), see Example 30. This makes the PC and PE fractions potentially more valuable. In an embodiment of the oil or lipid of the present invention, the ratio of the content of DHA of all fatty acids in the PC and PE fraction to the content of DPA n-3 of all fatty acids in the PC and PE fraction is larger than the ratio of the content of DHA of all fatty acids in the MAG, DAG, and/or TAG fraction to the content of DPA n-3 of all fatty acids in the MAG, DAG, and/or TAG fraction.
Further, it is envisaged that the amount of DHA in the phospholipid fraction in the oil or lipid of the present is larger that the amount of EPA in the phospholipid fraction. In contrast, the amount of EPA in the TAG fraction in the oil or lipid of the present shall be larger that the amount of DHA in the TAG fraction. "Amount" is this paragraph preferably means absolute amount.
Example 31 shows that the abundant PC (phosphatidylcholine) species containing EPA or DHA are PC (18:2, 22:6) and PC (18:2 20:5). This majority of PUFA are combined with 18:2 which is more stable than if they are combined with 18:3 or another PUFA.
Thus, the oil or lipid of the present invention preferably comprises PC (18:2, 22:6), PC (18:2 20:5), or both. Preferred contents of the species in the oil or lipid of the present invention are given below. The contents (levels) of the species are expressed as percentage (weight of a particular PC species) of the total weight of total PCs (i.e. all PCs) present in the oil or lipid). The contents are thus, preferably, given as weight percentage (% (w/w)). Accordingly, "%" preferably means "% (w/w) for a PC (or combination of PCs) compared to the total weight of PCs".
Preferably, the content of PC (18:2 20:5) is between 2.5% and 15%, more preferably between 2.5% and 12%, most preferably between 3% and 10% of the total phosphatidylcholine content. Also preferably the content of this species is at least 3%.
Preferably, the content of PC (18:2, 22:6) is between 0.5% and 10%, more preferably between 1 % and 7 %, most preferably between 1 % and 6% of the total phosphatidylcholine content. Also preferably, the content of this species is at least 1 .4%.
The present invention also relates to a plant comprising seeds comprising an oil of the present invention. Furthermore, the present invention relates to a seed comprising the oil of the present invention. Preferred plant species are described herein above. Preferably, the plant and the seed(s) comprises one ore more polynucleotides, expression cassettes, T-DNAs and/or construct as set forth in the context of the present invention.
The present invention also relates to a seed, in particular to bulked seeds, of the plant of the present invention. The seed/seeds shall contain the oil or lipid of the present invention.
In addition, as shown in the Examples, bulked seeds from event LBFGKN were determined to have 25.7 mg EPA+DHA/g seed and bulked seeds from event LBFDAU was determined to have 47.4 mg EPA+DHA/g seed. Thus, the present invention relates to seeds, in particular Brassica seeds, wherein 1 g of the seeds comprises a combined content of EPA and DHA of at least 10 mg, in particular of at least 20 mg. Further, it is envisaged that 1 g of the seeds of the present invention comprise a combined content of EPA and DHA of preferably 15 to 75 mg, more preferably of 20 to 60 mg, and most preferably of 25 to 50 mg. Preferably, the seeds of the present invention comprise at least one T-DNA of the present invention. Thus, it is envisaged that said seeds are transgenic.
The present invention also concerns seed meal and seed cake produced from the seeds of the present invention, in particular from bulked seeds of the present invention.
Interestingly, the seeds that were produced in the context of the studies underlying the present invention had higher yield and larger contents of seed oil than expected (see e.g. Example 18, EPA/DHA in tables 152 and 153, and oil in table 154). The degree of unsaturation and elongation was increased in transgenic seed oil relative to controls. To achieve these increases the introduced desaturases and elongases consume additional ATP and NADH compared to controls. Therefore, the desaturases and elongases that we introduced are in direct competition with de novo fatty acid and oil synthesis, which also require ATP and NADH (every elongation requires two NADH and one ATP, and every desaturation requires one NADH). Moreover, the provision of malonyl-CoA for elongating fatty acids results in the loss of carbon in form of CO2 (see Schwender et al 2004 Nature 432: 779-782). Therefore, we expected lower yield or oil content due to increased consumption of NADH, ATP, and increased loss of CO2. However, we produced seeds containing high amounts of EPA and DHA that did not have differences in yield or in oil content relative to controls (see Example 18 and Table 154). For example, seed were produced containing EPA/DHA and more than 38.2% oil. This was not expected because a negative correlation between oil and PUFA content was observed (see Examples). Thus, the seeds of the present invention and the seeds of the plant or plants of the present invention, preferably, have a seed oil content at least 38%, More preferably, the seeds have a seed oil content of 38 to 42%, in particular of 38% to 40%. Preferably, seed oil content is expressed as percentage of oil weight of the total weight of seeds. Also preferably, the seed oil is produced in plants that have a seed yield that is no different from control plants when cultivated in the field.
The plant of the present invention, is preferably a transgenic B. napus plant. As described elsewhere herein, the plant shall produce both EPA and DHA. It is envisaged that the oil from the bulked seed contains more than 12% non-naturally occurring PUFA. Thus, the content of the non- naturally occurring fatty acids shall be more than 12% of the total fatty acid content. In another embodiment, the oil from the bulked seed contains more than 16% non-naturally occurring PUFA. In another embodiment, the oil from the bulked seed contains more than 18% non-naturally occurring PUFA. The expression "non-naturally occurring" preferably refers to PUFAs which do
not occur naturally in wild-type Brassica plant. Preferably, said non-naturally occurring PUFASs are 18:2n-9, GLA, SDA, 20:2n-9, 20:3n-9, 20:3 n-6, 20:4n-6, 22:2n-6, 22:5n-6, 22:4n-3, 22:5n-3, and 22:6n-3. Although these PUFAs do not naturally occur in Brassica plants, they may nevertheless occurring in other non-transgenic organisms.
In an embodiment of the plant of the present invention, each T-DNA copy of the transgenic plant is stable over multiple generations as determined by copy number analysis at three or more locations on the T-DNA. In an embodiment of the plant of the present invention, the transgenic construct inserted into the B. napus plant has a copy number of 1 or 2. Thus, one or two copies of the T-DNA of the invention shall be present in the plant. In a preferred embodiment of the plant of the present invention, the transgenic construct inserted into the B. napus plant has a copy number of 1. Preferably, all inserted transgenes are fully functional (thus, the enzymes encoded by the genes shall retain their function). Preferably, the genetic insertion is located >5000 base pairs away from any endogenous gene. In an embodiment, the distance is measured from the end of the left and right border.
Preferably, the plant of the present invention, in particular the plant described is used in a method using produce an oil containing EPA and DHA. The oil has been described in detail elsewhere herein. In an embodiment, the oil comprises non-naturally occurring PUFA as described above.
The method of producing the oil may comprise the steps of growing a plant of the present invention such as to obtain oil-containing seeds thereof, harvesting said seed, and extracting oil form said seeds. The present invention further envisages an oil containing EPA and DHA produced by plants the plant described above.
A further embodiment according to the invention is the use of the oil, lipid, fatty acids and/or the fatty acid composition in feedstuffs, foodstuffs, dietary supplies, cosmetics or pharmaceutical compositions as set forth in detail below. The oils, lipids, fatty acids or fatty acid mixtures according to the invention can be used for mixing with other oils, lipids, fatty acids or fatty acid mixtures of animal origin such as, for example, fish oils.
The present invention thus envisages feedstuffs, foodstuffs and dietary supplies. In an embodiment, the feedstuffs, foodstuffs and dietary supplies comprise the plant of the present invention, a part of a plant of the present invention, in particular a seed or seed, and/or the oil or lipid of the present invention.
In an embodiment, the feedstuffs, foodstuffs and dietary supplies comprise seedcake or seedmeal produced from the plant of the present invention, in particular from seeds of the plant of the present invention. Thus, the present invention also concerns seedcake or seedmeal produced from the plant of the present invention, in particular from seeds of the plant of the present invention. In an embodiment, the seedmeal or seedcake comprises at least one T-DNA of the present invention.
The feedstuffs, foodstuffs and dietary supplies may comprise a fatty acid ester, or a fatty acid produced from a plant of the present invention (orfrom a part thereof, in particular from the seeds). The feedstuff of the present invention can be used in aquaculture. Using the feedstuff will allow to increase the contents of VLC-PUFAs in fish. In an embodiment, the fish is salmon.
The term "composition" refers to any composition formulated in solid, liquid or gaseous form. Said composition comprises the compound of the invention optionally together with suitable auxiliary compounds such as diluents or carriers or further ingredients. In this context, it is distinguished for the present invention between auxiliary compounds, i.e. compounds which do not contribute to the effects elicited by the compounds of the present invention upon application of the composition for its desired purpose, and further ingredients, i.e. compounds which contribute a further effect or modulate the effect of the compounds of the present invention. Suitable diluents and/or carriers depend on the purpose for which the composition is to be used and the other ingredients. The person skilled in the art can determine such suitable diluents and/or carriers without further ado. Examples of suitable carriers and/or diluents are well known in the art and include saline solutions such as buffers, water, emulsions, such as oil/water emulsions, various types of wetting agents, etc.
In a more preferred embodiment of the oil-, fatty acid or lipid-containing composition, the said composition is further formulated as a pharmaceutical composition, a cosmetic composition, a foodstuff, a feedstuff, preferably, fish feed or a dietary supply. The term "pharmaceutical composition" as used herein comprises the compounds of the present invention and optionally one or more pharmaceutically acceptable carrier. The compounds of the present invention can be formulated as pharmaceutically acceptable salts. Acceptable salts comprise acetate, methylester, Hel, sulfate, chloride and the like. The pharmaceutical compositions are, preferably, administered topically or systemically. Suitable routes of administration conventionally used for drug administration are oral, intravenous, or parenteral administration as well as inhalation. However, depending on the nature and mode of action of a compound, the pharmaceutical compositions may be administered by other routes as well. For example, polynucleotide compounds may be administered in a gene therapy approach by using viral vectors or viruses or liposomes.
Moreover, the compounds can be administered in combination with other drugs either in a common pharmaceutical composition or as separated pharmaceutical compositions wherein said separated pharmaceutical compositions may be provided in form of a kit of parts. The compounds are, preferably, administered in conventional dosage forms prepared by combining the drugs with standard pharmaceutical carriers according to conventional procedures. These procedures may involve mixing, granulating and compressing or dissolving the ingredients as appropriate to the desired preparation. It will be appreciated that the form and character of the pharmaceutically acceptable carrier or diluent is dictated by the amount of active ingredient with which it is to be
combined, the route of administration and other well-known variables. The carrier(s) must be acceptable in the sense of being compatible with the other ingredients of the formulation and being not deleterious to the recipient thereof. The pharmaceutical carrier employed may be, for example, a solid, a gel or a liquid. Exemplary of solid carriers are lactose, terra alba, sucrose, talc, gelatin, agar, pectin, acacia, magnesium stearate, stearic acid and the like. Exemplary of liquid carriers are phosphate buffered saline solution, syrup, oil such as peanut oil and olive oil, water, emulsions, various types of wetting agents, sterile solutions and the like. Similarly, the carrier or diluent may include time delay material well known to the art, such as glyceryl mono- stearate or glyceryl distearate alone or with a wax. Said suitable carriers comprise those mentioned above and others well known in the art, see, e.g., Remington's Pharmaceutical Sciences, Mack Publishing Company, Easton, Pennsylvania. The diluent(s) is/are selected so as not to affect the biological activity of the combination. Examples of such diluents are distilled water, physiological saline, Ringer's solutions, dextrose solution, and Hank's solution. In addition, the pharmaceutical composition or formulation may also include other carriers, adjuvants, or nontoxic, nontherapeutic, nonimmunogenic stabilizers and the like. A therapeutically effective dose refers to an amount of the compounds to be used in a pharmaceutical composition of the present invention which prevents, ameliorates or treats the symptoms accompanying a disease or condition referred to in this specification. Therapeutic efficacy and toxicity of such compounds can be determined by standard pharmaceutical procedures in cell cultures or experimental animals, e.g., ED50 (the dose therapeutically effective in 50% of the population) and LD50 (the dose lethal to 50% of the population). The dose ratio between therapeutic and toxic effects is the therapeutic index, and it can be expressed as the ratio, LD50/ED50. The dosage regimen will be determined by the attending physician and other clinical factors; preferably in accordance with anyone of the above described methods. As is well known in the medical arts, dosages for anyone patient depends upon many factors, including the patient's size, body surface area, age, the particular compound to be administered, sex, time and route of administration, general health, and other drugs being administered concurrently. Progress can be monitored by periodic assessment. A typical dose can be, for example, in the range of 1 to 1000 μg; however, doses below or above this exemplary range are envisioned, especially considering the aforementioned factors. However, depending on the subject and the mode of administration, the quantity of substance administration may vary over a wide range. The pharmaceutical compositions and formulations referred to herein are administered at least once in order to treat or ameliorate or prevent a disease or condition recited in this specification. However, the said pharmaceutical compositions may be administered more than one time, for example from one to four times daily up to a non-limited number of days. Specific pharmaceutical compositions are prepared in a manner well known in the pharmaceutical art and comprise at least one active compound referred to herein above in admixture or otherwise associated with a pharmaceutically acceptable carrier or diluent. For making those specific pharmaceutical compositions, the active compound(s) will usually be mixed with a carrier or the diluent, or enclosed or encapsulated in a capsule, sachet, cachet, paper or other suitable containers or vehicles. The resulting formulations are to be adopted to the mode of administration, i.e. in the forms of tablets, capsules, suppositories, solutions, suspensions or the like. Dosage recommendations shall be indicated in the prescribers
or users instructions in order to anticipate dose adjustments depending on the considered recipient.
The term "cosmetic composition" relates to a composition which can be formulated as described for a pharmaceutical composition above. For a cosmetic composition, likewise, it is envisaged that the compounds of the present invention are also, preferably, used in substantially pure form. Impurities, however, may be less critical than for a pharmaceutical composition. Cosmetic compositions are, preferably, to be applied topically. Preferred cosmetic compositions comprising the compounds of the present invention can be formulated as a hair tonic, a hair restorer composition, a shampoo, a powder, a jelly, a hair rinse, an ointment, a hair lotion, a paste, a hair cream, a hair spray and/or a hair aerosol.
Seeds of three events described in detail in the examples section below have been deposited at ATCC under the provisions of the Budapest treaty on the International Recognition of the Deposit of Microorganisms for the Purposes of Patent Procedure, i.e. seeds of event "LBFLFK" = ATCC Designation "PTA-121703", seeds of event "LBFDHG" = ATCC designation "PTA-121704", and seeds of event "LBFDAU" = ATCC Designation "PTA-122340". Applicants have no authority to waive any restrictions imposed by law on the transfer of biological material or its transportation in commerce. Applicants do not waive any infringement of their rights granted under this patent or rights applicable to the deposited events under the Plant Variety Protection Act (7 USC sec. 2321 , et seq.), Unauthorized seed multiplication prohibited. This seed may be regulated according to national law. The deposition of seeds was made only for convenience of the person skilled in the art and does not constitute or imply any confession, admission, declaration or assertion that deposited seed are required to fully describe the invention, to fully enable the invention or for carrying out the invention or any part or aspect thereof. Also, the deposition of seeds does not constitute or imply any recommendation to limit the application of any method of the present invention to the application of such seed or any material comprised in such seed, e.g. nucleic acids, proteins or any fragment of such nucleic acid or protein. The deposited seeds are derived from plants that were transformed with the T-DNA vector having a sequence as shown in SEQ ID NO: 3.
The events LBFLFK and LBFDAU are described herein in more detail. In an embodiment, the plant of the present invention comprises the T-DNAs comprised by LBFLFK and LBFDAU, preferably at the the position in the genome (as in the plants designated LBFLFK and LBFDAU. In addition, the events are decribed in section B in more detail.
In one embodiment, the present invention thus provides Brassica plants comprising transgenic Brassica event LBFLFK deposited as ATCC Designation "PTA-121703". Brassica event LBFLFK contains two insertions of T-DNA of the binary T-plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFLFK Locus 1 and LBFLFK Locus 2. The Brassica plants of this embodiment include progeny that are indistinguishable from Brassica event LBFLFK (to the extent that such progeny also contain at least one allele corresponding to LBKLFK Locus 1 and/or
LBFLFK Locus 2). The Brassica plants of this embodiment comprise unique genomic DNA/transgene junction points, and consequently unique junction regions, for each LBFLFK insertion: the junction region for LBFLFK Locus 1 having at least the polynucleotide sequence of SEQ ID NO:282 or at least the polynucleotide sequence of SEQ ID NO:283, and the junction region for LBFLFK Locus 2 having at least the polynucleotide sequence of SEQ ID NO:291 or at least the polynucleotide sequence of SEQ ID NO:292. Also included in this embodiment are seeds, plant parts, plant cells, and plant products derived from Brassica event LBFLFK and progeny thereof. In another embodiment, the invention provides commodity products, including canola oil and meal, produced from Brassica event LBFLFK and/or its progeny.
In another embodiment, the invention provides Brassica plants comprising transgenic Brassica event LBFDAU deposited as ATCC Designation "PTA-122340". Brassica event LBFDAU contains two insertions of the T-DNA of the binary T-plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFDAU Locus 1 and/or LBFDAU Locus 2. The Brassica plants of this embodiment include and progeny thereof that are indistinguishable from Brassica event LBFDAU (to the extent that such progeny also contain at least one allele that corresponds to the inserted transgenic DNA). The Brassica plants of this embodiment comprise unique genomic DNA/transgene junction points, and consequently two unique junction regions, for each LBFDAU insertion: the junction region for LBFDAU Locus 1 having at least the polynucleotide sequence of SEQ ID NO:300 or at least the polynucleotide sequence of SEQ ID NO:301 and the junction region for LBFDAU Locus 2 having at least the polynucleotide sequence of SEQ ID NO:309 or at least the polynucleotide sequence of SEQ ID NO:310. Also included in this embodiment are seeds, plant parts, plant cells, and plant products derived from Brassica event LBFDAU and progeny thereof. In another embodiment, the invention provides commodity products, including canola oil and meal, produced from Brassica event LBFDAU and/or its progeny.
The aforementioned plant of the present invention can be used in method the context of the present invention. E.g, the oil, fatty acid, or lipid of the present invention is obtainable from the plant (and can be extracted).
The plants of the invention have been modified by the transformation binary T-plasmid VC- LTM593-1 qcz rc (SEQ ID NO:3) described in the Examples section. The T-DNA of this vector (which is a T-DNA of the present invention) comprises (preferably in the following order), polynucleotides encoding the following enzymes of the VLC-PUFA biosynthetic pathway: Delta- 6 ELONGASE from Physcomitrella patens; Delta-5 DESATURASE from Thraustochytrium sp. ATCC21685; Delta-6 DESATURASE from Ostreococcus tauri; Delta-6 ELONGASE from Thalassiosira pseudonana; Delta-12 DESATURASE from Phythophthora sojae; Omega-3 DESATURASE from Pythium irregulare; Omega-3-DESATURASE from Phythophthora infestans; Delta-5 DESATURASE from Thraustochytrium sp. ATCC21685; Delta-4 DESATURASE from Thraustochytrium sp.; Omega-3 DESATURASE from Pythium irregulare; Delta-4 DESATURASE from Pavlova lutheri; Delta-5 ELONGASE from Ostreococcus tauri. Thus, the aforementioned T- DNA of the present invention comprises two copies of a polynucleotide encoding a Delta-5
desaturase from Thraustochytrium sp. ATCC21685, and two copies of a polynucleotide encoding Omega-3 desaturase from Pythium irregulare.
The T-DNA of VC-LTM593-1 qcz (SEQ ID NO:3) further comprises a polynucleotide encoding the selectable marker acetohydroxy acid synthase, which confers tolerance to imidazolinone herbicides.
The invention further relates to the T-DNA insertions in each of Brassica events LBFLFK and LBFDAU, and to the genomic DNA/transgene insertions, i.e., the Locus 1 and Locus 2 junction regions found in Brassica plants or seeds comprising Brassica event LBFLFK, to the genomic DNA/transgene insertions, i.e., Locus 1 and Locus 2 junction regions found in Brassica plants or seeds comprising Brassica event LBFDAU, and the detection of the respective genomic DNA/transgene insertions, i.e., the respective Locus 1 and Locus 2 junction regions in Brassica plants or seed comprising event LBFLFK or event LBFDAU and progeny thereof.
Progeny, variants and mutants of the regenerated plants are also included within the scope of the invention, provided that the progeny, variants and mutants comprise a LBFLFK or LBFDAU event. Preferably, the progeny, variants, and mutants contain two insertions of T-DNA of the binary T- plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFLFK Locus 1 and LBFLFK Locus 2, provided that the progeny, variants and mutants comprise two insertions of the T-DNA of the binary T-plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFDAU Locus 1 and LBFDAU Locus 2.
A transgenic "event" is preferably produced by transformation of plant cells with a heterologous DNA construct(s) including a nucleic acid expression cassette that comprises one or more transgene(s) of interest, the regeneration of a population of plants from cells which each comprise the inserted transgene(s) and selection of a particular plant characterized by insertion into a particular genome location. An event is characterized phenotypically by the expression of the transgene(s). At the genetic level, an event is part of the genetic makeup of a plant. The term "event" refers to the original transformant and progeny of the transformant that include the heterologous DNA. The term "event" also refers to progeny, produced by a sexual outcross between the transformant and another variety, that include the heterologous DNA. Even after repeated back-crossing to a recurrent parent, the inserted DNA and flanking DNA from the transformed parent are present in the progeny of the cross at the same chromosomal location. The term "event" also refers to DNA from the original transformant comprising the inserted DNA and flanking sequence immediately adjacent to the inserted DNA that would be expected to be transferred to a progeny as the result of a sexual cross of one parental line that includes the inserted DNA (e.g., the original transformant and progeny resulting from selfing) and a parental line that does not contain the inserted DNA. In accordance with the invention, progeny of the Brassica LBFLFK event preferably comprises either LBFLFK Locus 1 or LBFLFK Locus 2, or both LBFLFK Locus 1 and LBFLFK Locus 2. Similarly, progeny of the Brassica LBFDAU event preferably comprises either LBFDAU Locus 1 or LBFDAU Locus 2, or both LBFDAU Locus 1 and LBFDAU Locus 2.
A "flanking region" or "flanking sequence" as used herein preferably refers to a sequence of at least 20, 50, 100, 200, 300, 400, 1000, 1500, 2000, 2500 or 5000 base pairs or greater which is located either immediately upstream of and contiguous with, or immediately downstream of and contiguous with, the original foreign insert DNA molecule. Non-limiting examples of the flanking regions of the LBFLFK event comprise, for Locus 1 , nucleotides 1 to 570 of SEQ ID NO: 284, nucleotides 229 to 81 1 of SEQ ID NO:285 and for Locus 2, nucleotides 1 to 2468 of SEQ ID NO:293, and/or nucleotides 242 to 1800 of SEQ ID NO:294 and variants and fragments thereof. Non-limiting examples of the flanking regions of the LBFDAU event comprise, for Locus 1 , nucleotides 1 to 1017 of SEQ ID NO: 302, nucleotides 637 to 1677 of SEQ ID NO:303, and for Locus 2, nucleotides 1 to 1099 of SEQ ID NO:31 1 and/or nucleotides 288 to 1321 of SEQ ID NO: 312 and variants and fragments thereof.
Non-limiting examples of junction DNA from the LBFLFK event comprise, for Locus 1 , SEQ ID NO:282, SEQ ID NO:283, and for Locus 2, SEQ ID NO:291 , and/or SEQ ID NO:292, complements thereof, or variants and fragments thereof. Non-limiting examples of junction DNA from the LBFDAU event comprise, for Locus 1 , SEQ ID NO:300, SEQ ID NO:301 , and for Locus 2, SEQ ID NO:309 and/or SEQ ID NO:310, complements thereof, or variants and fragments thereof.
The oil of the aforementioned plants of the present invention preferably is an oil as specified elsewhere herein.
In one embodiment, the transgenic Brassica plants of the invention comprise event LBFLFK (ATCC designation PTA-121703). Seed and progeny of event LBFLFK are also encompassed in this embodiment. In another embodiment, the transgenic Brassica plants of the invention comprise event LBFDAU (ATCC designation PTA-122340). Seed and progeny of event LBFDAU are also encompassed in this embodiment.
The Brassica plants LBFLFK and LBFDAU can be used to manufacture commodities typically acquired from Brassica. Seeds of LBFLFK and LBFDAU can be processed into meal or oil as well as be used as an oil source in animal feeds for both terrestrial and aquatic animals.
In accordance with the invention embodied in Brassica event LBFLFK, the LBFLFK Locus 1 genomic DNA/transgene junction region and/or the LBFLFK Locus 2 genomic DNA/transgene junction region is present in Brassica plant LBFLFK (ATCC Accession No. PTA-121703) and progeny thereof. The LBFLFK Locus 1 DNA/transgene right border junction region comprises SEQ ID NO:282 and the LBFLFK Locus 1 left border junction region comprises SEQ ID NO:283, and the LBFLFK Locus 2 right border junction region comprises SEQ ID NO:291 and the LBFLFK left border junction region comprises SEQ ID NO:292. DNA sequences are provided that comprise at least one junction region sequence of event LBFLFK selected from the group consisting of SEQ ID NO:282 corresponding to positions 561 through 580 of SEQ ID NO:280); SEQ ID NO:283 corresponding to positions 44318 through 44337 of SEQ ID NO:280); SEQ ID NO:291 corresponding to positions 2459 through 2478 of SEQ ID NO:289); and SEQ ID NO:292 corresponding to positions 46232 through 46251 of SEQ ID NO:289), and complements thereof; wherein detection of these sequences in a biological sample containing Brassica DNA is
diagnostic for the presence of Brassica event LBFLFK DNA in said sample. A Brassica event LBFLFK and Brassica seed comprising these DNA molecules is an aspect of this invention.
For example, to determine whether the Brassica plant resulting from a sexual cross contains transgenic DNA from event LBFLFK, DNA extracted from a Brassica plant tissue sample may be subjected to nucleic acid amplification method using (i) a first primer pair that includes: (a) a first primer derived from an LBFLFK Locus 1 flanking sequence and (b) a second primer derived from the LBFLFK Locus 1 inserted heterologous DNA, wherein amplification of the first and second primers produces an amplicon that is diagnostic for the presence of event LBFLFK Locus 1 DNA; and (ii) a second primer pair that includes (a) a third primer derived from an LBFLFK Locus 2 flanking sequence and (b) a fourth primer derived from the LBFLFK Locus 2 inserted heterologous DNA, wherein amplification of the third and fourth primers produces an amplicon that is diagnostic for the presence of event LBFLFK Locus 2 DNA. The primer DNA molecules specific for target sequences in Brassica event LBFLFK comprise at least 1 1 contiguous nucleotides of any portion of the insert DNAs, flanking regions, and/or junction regions of LBFLFK Locus 1 and Locus 2. For example, LBFLFK Locus 1 primer DNA molecules may be derived from any of SEQ ID NO:280, SEQ ID NO:281 , SEQ ID NO:282, or SEQ ID NO:283; SEQ ID NO:284, or SEQ ID NO:285, or complements thereof, to detect LBFLFK Locus 1. Similarly, LBFLFK Locus 2 primer DNA molecules may be derived from any of SEQ ID NO:293, SEQ ID NO:294, SEQ ID NO:291 , or SEQ ID NO:292; SEQ ID NO:290, or SEQ ID NO:289, or complements thereof, to detect LBFLFK Locus 2. Those of skill in the art may use these primers to design primer pairs to produce LBFLFK Locus 1 and Locus 2 amplicons using known DNA amplification methods. The LBFLFK Locus 1 and Locus 2 amplicons produced using these DNA primers in the DNA amplification method are diagnostic for Brassica event LBFLFK when the amplification product contains an amplicon comprising an LBFLFK Locus 1 junction region SEQ ID NO:282 or SEQ ID NO:283, or complements thereof, and an amplicon comprising an LBFLFK Locus 2 junction region SEQ ID NO:291 , or SEQ ID NO:292, or complements thereof. In accordance with the invention embodied in Brassica event LBFDAU, the LBFDAU Locus 1 genomic DNA/transgene junction region and/or the LBFDAU Locus 2 genomic DNA/transgene junction region is present in Brassica event LBFDAU (ATCC Accession No. PTA-122340) and progeny thereof. The LBFDAU Locus 1 DNA/transgene right border junction region comprises SEQ ID NO:300 and the LBFDAU Locus 1 left border junction region comprises SEQ ID NO:301 , and the LBFDAU Locus 2 right border junction region comprises SEQ ID NO:309 and the LBFDAU left border junction region comprises SEQ ID NO:310. DNA sequences are provided that comprise at least one junction region sequence of event LBFDAU selected from the group consisting of SEQ ID NO:300 (corresponding to positions 1008 through 1027 of SEQ ID NO:298, as shown in FIG. 4); SEQ ID NO:301 (corresponding to positions 44728 through 44747 of SEQ ID NO:298, as shown in FIG. 4); SEQ ID NO:309 (corresponding to positions 1090 through 1 109 of SEQ ID NO:307, as shown in FIG. 5); and SEQ ID NO:310 (corresponding to positions 38577 through 38596 of SEQ ID NO:307, as shown in FIG. 5) and complements thereof; wherein detection of these sequences in a biological sample containing Brassica DNA is diagnostic for the
presence of Brassica event LBFDAU DNA in said sample. A Brassica event LBFDAU and Brassica seed comprising these DNA molecules is an aspect of this invention.
For example, to determine whether the Brassica plant resulting from a sexual cross contains transgenic DNA from event LBFDAU, DNA extracted from a Brassica plant tissue sample may be subjected to nucleic acid amplification method using (i) a first primer pair that includes: (a) a first primer derived from an LBFDAU Locus 1 flanking sequence and (b) a second primer derived from the LBFDAU Locus 1 inserted heterologous DNA, wherein amplification of the first and second primers produces an amplicon that is diagnostic for the presence of event LBFDAU Locus 1 DNA; and/or (ii) a second primer pair that includes (a) a third primer derived from an LBFDAU Locus 2 flanking sequence and (b) a fourth primer derived from the LBFDAU Locus 2 inserted heterologous DNA, wherein amplification of the third and fourth primers produces an amplicon that is diagnostic for the presence of event LBFDAU Locus 2 DNA. Seed derived from Brassica event LBFLFK or Brassica event LBFDAU for sale for planting or for making commodity products is an aspect of the invention. Such commodity products include canola oil or meal containing VLC-PUFAs including but not limited to EPA and DHA. Commodity products derived from Brassica event LBFLFK comprise a detectable amount a DNA molecule comprising SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and/or SEQ ID NO:292. Commodity products derived from Brassica event LBFDAU comprise a detectable amount a DNA molecule comprising SEQ ID NO:300, SEQ ID NO:301 , SEQ ID NO:309, and/or SEQ ID NO:310. Exemplary commodity products derived from events LBFLFK and LBFDAU include, but are not limited to, cooking oil, salad oil, shortening, nutritionally enhanced foods, animal feed, pharmaceutical compositions, cosmetic compositions, hair care products, and the like.
The invention also provides a commercially relevant source of plant material, preferably of seed. As such, the invention provides a heap of at least 5kg, preferably of at least 10 kg, more preferably of at least 50kg, even more preferably of at least 100 kg, even more preferably of at least 500 kg, even more preferably of at least 1 t, even more preferably of at least 2t, even more preferably of at least 5t of plant material, wherein the plant material comprises VLC-PUFAs as described according to the invention. As described herein, it is a merit of the present invention to provide, for the first time, an agronomically reliable source of VLC-PUFA plant oil, and to this end such heap of plant material is provided. The plant material is preferably plant seed, even more preferably seed of VLC-PUFA producing seed, such that the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 10% (w/w) and/or the content of DHA is at least 1 % (w/w) of the total seed fatty acid content at an oil content of 30% (w/w), or meal of such plant seed. Also, the invention provides a container comprising such plant seed in an amount of at least 5kg, preferably of at least 10 kg, more preferably of at least 50kg, even more preferably of at least 100 kg, even more preferably of at least 500 kg, even more preferably of at least 1t, even more preferably of at least 2t, even more preferably of at least 5t. The invention thus demonstrates that the invention has well eclipsed anecdotal findings of lab scale VLC-PUFA containing plants, and instead has overcome the additional requirements for providing, on a large
scale, a reliable source for VLC-PUFA and particularly for EPA and/or DHA in plant oil and plant material.
The present invention allows for the generation of plants comprising a modified fatty acid composition (as compared to control plants). Thus, the T-DNAs, the expression cassettes, vectors, polynucleotides (in particular the combination of polynucleotides), and polypeptides ((in particular the combination of polynucleotides) as disclosed herein can be used for modifying the fatty acid composition of a plant. In an embodiment, the content of at least one fatty acid disclosed in Table 18 or 181 is modified in seed oil (increased or decreased as compared to the content in seed oil of a control plant). In another embodiment, the content of at least one fatty acid disclosed in Table 18 or 181 is modified in in the monoacylgylcerol (MAG) fraction, the diacylgylcerol (DAG) fraction, the triacylgylcerol (TAG) fraction, phosphatidylcholine (PC) fraction and/or phosphatidylethanolamine (PE) fraction of seed oil (increased or decreased as compared to the content of seed oil of a control plant). In another embodiment, the content of at least one Lysophosphatidylcholine species shown in Table 189 is modified in seed oil (increased or decreased as compared to the content in seed oil of a control plant). In another embodiment, the content of at least one Phosphatidylethanolamine species shown in Table 190 is modified in seed oil (increased or decreased as compared to the content in seed oil of a control plant). In another embodiment, the content of at least one Lysophosphatidylethanolamine species shown in Table 191 is modified in seed oil (increased or decreased as compared to the content in seed oil of a control plant). In another embodiment, the content of at least one Triacylglycerol species shown in Table 192 is modified in seed oil (increased or decreased as compared to the content in seed oil of a control plant). The definitions and explanations given herein above, preferably, apply mutatis mutandis to the following (e.g. with respect to the "plant", "the control plant" etc.).
It has been shown in the context of the studies underlying that the present invention that that the generated plants produce mead acid (20:3n-9, see Example 29). The mead acid may be made from the side activities of d6Des, d6Elo, and d5Des, using 18:1 n-9 to make 18:2n-9 (by d6Des), then 20:2n-9 (by d6Elo), then 20:3n-9 (by d5Des). Interestingly, in mead acid in fungi is only made if the d12Des is mutated to be inactive (Takeno etal. 2005 App. Environ. Microbiol. 71 (9): 5124- 5128). However, the studies underlying the present invention surprisingly show that mead acid is produced in plants even when a d12Des is overexpressed.
Accordingly, the present invention relates to a method for increasing the content of Mead acid (20:3n-9) in a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6- elongase, and at least one polynucleotide encoding a delta-5-desaturase.
In addition, the present invention relates to a method for producing Mead acid (20:3n-9) in a plant relative to a control plant, comprising expressing in a plant, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase.
The aforementioned methods may further comprise the expression of further desatuarase or eleogase, in particular of one or more of a delta-12-desaturase, omega-3-desaturase, a delta-5- elongase, and delta-4-desaturase. Thus, at least one, two, three, or in particular four further enzymatic actitivities can be expressed in the plant.
In an embodiment, the methods further comprise expressing in the plant at least one polynucleotide encoding a delta-12-desaturase.
In an embodiment, the methods further comprise expressing in the plant at least one polynucleotide encoding an omega-3-desaturase.
In an embodiment, the methods further comprise expressing in the plant at least one polynucleotide encoding a delta-5-elongase. In an embodiment, the methods further comprise expressing in the plant at least one polynucleotide encoding a delta-4-desaturase. In an embodiment, at least one CoA dependent delta-4-desaturase and at least one phospholipid dependent delta-4 desaturase is expressed.
In a particular preferred embodiment, the methods further comprise expressing in the plant at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding an omega-3-desaturase, at least one polynucleotide encoding a delta-5-elongase, and at least one polynucleotide encoding delta-4-desaturase.
Preferred polynucleotides encoding desaturases and elongases are described above.
The gene dosage effect described above may be also used for the the producing of mead acid or for increasing the content of mead acid in plants.
Thus, it is contemplated to express at least one polynucleotide encoding a delta-6-desaturase, at least two polynucleotides encoding a delta-6-elongase, and at least two polynucleotides encoding a delta-5-desaturase. Moreover, at least one polynucleotide encoding a delta-12-desaturase, at least three polynucleotides encoding an omega-3-desaturase, at least one polynucleotide encoding a delta-5-elongase, and/or at least two polynucleotides encoding a delta-4-desaturase can be further expressed (preferably at least one CoA dependent delta-4-desaturase and at least one phospholipid dependent delta-4 desaturase).
In an embodiment, at least one polynucleotide encoding a delta-6 elongase from Physcomitrella patens, at least one polynucleotide encoding a delta-6 elongase from Thalassiosira pseudonana, and at least two polynucleotides encoding a delta-5 desaturase from Thraustochytrium sp are expressed. Moreover, at least one polynucleotide encoding a omega-3-desaturase from Phythophthora infestans, at least two polynucleotides encoding a omega-3 desaturase from Pythium irregulare, at least one polynucleotide encoding a delta-5 elongase from Ostreococcus tauri, and at least one polynucleotide encoding a delta-4 desaturase from Thraustochytrium sp.,
and/or at least one polynucleotide encoding a delta-4 desaturase from Pavlova lutheri can be expressed.
Preferably, the polynucleotides to be expressed are recombinant polynucleotides. More preferably, the polynucleotides are present on one T-DNA which is comprised by the genome of the plant. Thus, the T-DNA is stably integrated into the genome. Preferably, the polynucleotides encoding for the desaturaes and elongases as set forth herein are comprised by the same T- DNA. Preferably, the polynucleotides encoding the desaturases or elongases (i.e. each of the polynucleotides) are operably linked to an expression control sequence (see elsewhere herein for a definition). Moreover, the polynucleotides may be linked to a terminator, thereby forming an expression cassette comprising an expression control sequence, the target gene, and the terminator.
In a particular preferred embodiment, the polynucleotides are expressed in the seeds of the plant. Accordingly, the expression control sequences may be seed-specific promoters. Preferred seed- specific promoters are e.g. disclosed in Table 1 1 in the Examples section. In an embodiment, the polynucleotides are expressed by introducing and expressing the polynucleotides in the plants. How to introduce polynucleotides into a plant is well known in the art. Preferred methods are described elsewhere herein. In an embodiment, the polynucleotides are introduced into a plant by Agrobacterium-mediated transformation. In an embodiment, the mead acid content is increased in the seeds as compared to the mead acid in seeds of a control plant. Preferably, the mead acid content in seed oil is increased in the seeds is increased as compared to the mead acid in seed oil of a control plant.
Preferred plants are described above. In an embodiment, the plant is an oilseed plant. Preferably, the plant is selected from the group consisting of flax (Linum sp.), rapeseed (Brassica sp.), soybean (Glycine and Soja sp.), sunflower (Helianthus sp.), cotton (Gossypium sp.), corn (Zea mays), olive (Olea sp.), safflower (Carthamus sp.), cocoa (Theobroma cacoa), peanut (Arachis sp.), hemp, camelina, crambe, oil palm, coconuts, groundnuts, sesame seed, castor bean, lesquerella, tallow tree, sheanuts, tungnuts, kapok fruit, poppy seed, jojoba seeds and perilla. More preferably, the plant is a plant of the family Brassicaceae, preferably of genus Brassica and most preferably of a species comprising a genome of one or two members of the species Brassica oleracea, Brassica nigra and Brassica rapa, thus in particular of the species Brassica napus, Brassica carinata, Brassica juncea, Brassica oleracea, Brassica nigra or Brassica rapa. In an embodiment, the method further comprises the step of a selecting for a plant having an increased mead acid content, in particular in seed oil. In embodiment, the selection is done based on the mead acid content. The step may thus comprise the step of determining the mead acid
content in the seeds, or seed oil of the plant. How to determine the mead acid content is e.g. described in Example 29.
The Mead acid is preferably esterified mead acid.
Upon expression of the polynucleotides referred to above in the seeds of the plant, mead acid is produced. Thus, the plants expressing said polynucleotides, in particular the seeds of the plants shall comprise/produce mead acid. Preferably, the content of Mead acid (20:3n-9) in the seed oil of the plant is between about 0.1 % and 2%, more preferably between about 0.1 % and 1 %, most preferably between about 0.1 % and 0.5% of the total fatty acid content of seed oil (in particular the total content of esterified fatty acids). Further VLC-PUFAs may be present in the seed oil (as described elsewhere herein in connection with the oil of the present invention).
The present invention also relates to a construct or T-DNA comprising expression cassettes for the desaturases and elongases as referred to in the context of the method of increasing the content of mead acid. Thus, the present invention also relates to a construct comprising at least one expression cassette for for a delta-6-desaturase, at least one expression cassette for a delta- 6-elongase, and at least one expression cassette for a delta-5-desaturase. The construct or T- DNA may further comprise at least one expression cassette for a delta-12-desaturase, at least one expression cassette for an omega-3-desaturase, at least one expression cassette for a delta- 5-elongase, and/or at least one expression cassette for a delta-4-desaturase.
In an embodiment, the construct or T-DNA comprises at least one expression cassette for a delta- 6 elongase from Physcomitrella patens, at least one expression cassette for a delta-6 elongase from Thalassiosira pseudonana, and at least two expression cassettes for a delta-5 desaturase from Thraustochytnum sp. (in particular Thraustochytnum sp. ATCC21685), and optionally at least two expression cassettes for an omega-3 desaturase from Pythium irregulare, at least one expression cassette for a omega-3-desaturase from Phythophthora infestans, at least one expression cassette for a delta-5 elongase from Ostreococcus tauri, and at least one expression cassette for a delta-4 desaturase from Thraustochytnum sp., and/or at least one expression cassette for a delta-4 desaturase from Pavlova lutheri.
The present invention further relates to the use of i) a construct or T-DNA of the present invention or of ii) at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, at least one polynucleotide encoding a delta-5-desaturase, for a) increasing the mead acid content of a plant (in particular in the seeds) relative to a control plants (in particular in the seeds of a control plant) or for producing mead acid in a plant, in particular in the seeds of a plant. Preferably, also further polynucleotides encoding desaturases and/or elongases as referred to in the context of the method for increasing mead acid can be used (such as a polynucleotide encoding a delta-12-desaturase).
The present invention also relates to plant, or plant cells transformed with or comprising i) a construct or T-DNA of the present invention or ii) at least one polynucleotide encoding a delta-6- desaturase, at least one polynucleotide encoding a delta-6-elongase, at least one polynucleotide encoding a delta-5-desaturase. In an embodiment, the plant or plant cell further is transformed with or comprises the further polynucleotides encoding desaturases and/or elongases as referred to in the context of the method for increasing mead acid can be used (such as a polynucleotide encoding a delta-12-desaturase). Preferred polynucleotide sequences for the desaturases and elongases are disclosed above. Further, the present invention relates to a method of mead acid production, comprising the steps of
i) growing a plant of the present invention such as to obtain oil-containing seeds thereof, ii) harvesting said seeds, and
iii) extracting oil comprising mead acid from said seeds harvested in step ii.
Preferably, the oil is an oil as described herein above. In particular, the oil shall have a mead acid content as described above.
As set forth above, the present invention pertains to plants that produce VLC-PUFAs (and to plants that produce Mead acid). Said plants shall comprise one or more T-DNAs comprising expression cassettes for certain desaturases and elongases as explained herein in detail. Preferably, said expression cassettes are comprised by the same T-DNA (or construct).
In an embodiment of the present invention, the T-DNA or construct of the present invention further comprises at least one expression cassette comprising a polynucleotide encoding for an acetohydroxy acid synthase (abbreviated AH AS enzyme, also known a acetolactate synthase), wherein said acetohydroxy acid synthase confers tolerance to an herbicide of the imidazolinone class. Thus, the AHAS enzyme is preferably a mutated AHAS enzyme. Mutated AHAS enzymes that confer tolerance to an herbicide of the imidazolinone class are known in the art and e.g. disclosed in WO 2008/124495 which herewith is incorporated by reference in its entirety. In an embodiment, the matutated AHAS enzyme is a mutated Arabidopsis thaliana AHAS enzyme. As compared to the wild-type enzyme, the envisaged enzyme is mutated at two positions. The envisaged enzyme has at position 653 a serine replaced by an asparagine and at position 122 an alanine replaced by a threonine.
Also preferably, the polynucleotide encoding for an AHAS enzyme which confers tolerance to an herbicide of the imidazolinone class is selected from:
a) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NO: 277, b) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NO:278.
c) a nucleic acid sequence being at least 70%, 80%, or 90% identical to the nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NO: 277,
d) a nucleic acid sequence encoding a polypeptide which is at least 60%, 70%, 80, or 90% identical to a polypeptide having an amino acid sequence as shown in SEQ ID NO: 278 , and
e) a nucleic acid sequence which is capable of hybridizing under stringent conditions to i) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NO: 277, or to ii) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NO:278.
Is is to be understood that the polypetide encoded by the said polynucleotide shall confer tolerance to an herbicide of the imidazolinone class. In an embodiment, the polypeptide thus shall have a serine-to-asparagine substitution at the position corresponding to position 653 of SEQ ID NO:278, and/or an alanine-to-threonin substitution at the position corresponding to position 122 of SEQ ID NO:278. The herbicide of the imidazolinone class is preferably selected from imazethapyr, imazapic, imazamox, imazaquin, imazethabenz, and imazapyr, in particular imazamox (lUPAC: (R/S)-2-(4- isopropyl-4-methyl-5-oxo-2-imidazolin-2-yl)-5-methoxymethylnicotinic acid). More specifically, the herbicide of the imidazolinone class can be selected from, but is not limited to, 2- (4-isopropyl- 4-methyl-5-oxo- 2-imidiazolin-2-yl) -nicotinic acid, [2- (4-isopropyl)-4-] [methyl-5-oxo-2-imidazolin- 2-yl)-3-quinolinecarboxylic] acid, [5-ethyl-2- (4-isopropyl-] 4-methyl-5-oxo-2- imidazolin-2-yl) - nicotinic acid, 2- (4-isopropyl-4-methyl-5-oxo-2- imidazolin-2-yl)- 5- (methoxymethyl)-nicotinic acid, [2- (4-isopropyl -4-methyl-5-oxo-2-] imidazolin-2- yl)-5-methylnicotinic acid. The use of 5- ethyl-2- (4-isopropyl-4-methyl-5-oxo- 2- imidazolin-2-yl) -nicotinic acid and [2- (4-isopropyl-4- methyl-5-oxo-2-imidazolin-2-] yl)-5- (methoxymethyl)-nicotinic acid is preferred. The use of [2- (4- isopropyl-4-] methyl-5-oxo-2-imidazolin-2-yl)-5- (methoxymethyl)-nicotinic acid is particularly preferred.
In addition, the present invention relates to a method of controlling weeds in the vicinity of a plant of the present invention, said method comprising applying at least one herbicide of the imidazolinone class to the weeds and to the plant of the present invention, thereby suppressing growth of the weeds in the vicinity of a plant of the present invention.
The plant of the present invention in the context with the aforementioned method shall comprise the expression cassettes for the desaturases and elongases as explained elsewhere herein (preferably, at least one T-DNA comprising the expression cassettes) and an expression cassette comprising a polynucleotide encoding for an acetohydroxy acid synthase, wherein said acetohydroxy acid synthase confers tolerance to an herbicide of the imidazolinone class. In an embodiment, the expression cassettes for the desaturases and elongases and the comprising a polynucleotide encoding for an acetohydroxy acid synthase are comprised by the same T-DNA. The present invention also relates to the aforementioned plant.
Preferably, the polynucleotide encoding for an acetohydroxy acid synthase as set forth above is overexpressed. In an embodiment, said polynucleotide is operably linked to a constitutive
promoter. In an embodiment said constitutive promoter is a CaMV 35S promoter. In another embodiment, said constitutive promoter is a parsley ubiquitin promoter (such as the promoter used for the expression of the mutated AHAS genes in the examples, for the position in SEQ ID NO; 3, see table 1 1 ).
Thus, preferred plants of the current invention contain a gene for resistance to imidazolinone class of herbicides, which inhibit the aceto-hydroxy acid synthase (AHAS) gene of plants. The gene that confers resistance is a modified variant of AHAS. The expression cassettes for the polynucleotide encoding for an acetohydroxy acid synthase may be comprised by the same T- DNA as the expression cassettes for the elongases and desaturases as referred to herein, or by a different T-DNA. Preferably, the expression cassettes are comprised by the same T-DNA.
In an embodiment, the T-DNA or construct of the present invention comprises polynucleotides encoding the following enzymes (in particular in this order): Delta-6 ELONGASE from Physcomitrella patens; Delta-5 DESATURASE from Thraustochytrium sp. ATCC21685; Delta-6 DESATURASE from Ostreococcus tauri; Delta-6 ELONGASE from Thalassiosira pseudonana; Delta-12 DESATURASE from Phythophthora sojae; Omega-3 DESATURASE from Pythium irregulare; Omega-3-DESATURASE from Phythophthora infestans; Delta-5 DESATURASE from Thraustochytrium sp (in particular sp. ATCC21685); Delta-4 DESATURASE from Thraustochytrium sp.; Omega-3 DESATURASE from Pythium irregulare; Delta-4 DESATURASE from Pavlova lutheri; Delta-5 ELONGASE from Ostreococcus tauri, and an acetohydroxy acid synthase, which confers tolerance to imidazolinone herbicides (see definitions above). The sequences of the polynucleotides and polypeptides are given e.g. in Table 130. Insterestingly, the enzyme AHAS shares a common metabolic precursor with fatty acid biosynthesis (pyruvate). One result of the overexpression of AHAS could be increased consumption of pyruvate, leading to a reduction in oil content and potentially an increase in amino acid or protein content (see for example Blombach et al 2009, Applied and Environment Microbiology 75(2) :419-427, where overexpression of AHAS results in increased lysine production in bacteria; see also Muhitch 1988 Plant Physiol 83:23-27, where the role of AHAS in amino acid supply is described). Therefore, it is surprising that overexpression of an AHAS variant, especially in combination with the AHAS inhibiting herbicide, did not result in changes to protein, oil, or VLC-PUFA content in seeds (see example 18). As such, the present invention provides for a method of production of VLC-PUFA in which field grown plants are sprayed with an AHAS-inhibiting herbicide. Preferably, said herbicide is of the imidazolinone class
Preferred embodiments of the invention described in Section A are given herein below. The explanations and embodiments described in this section preferably apply mutatis mutandis to the following:
Embodiments
T-DNA for expression of a target gene in a plant, wherein the T-DNA comprises a left and a right border element and at least one expression cassette comprising a promoter, operatively linked thereto a target gene, and downstream thereof a terminator, wherein the length of the T-DNA, measured from left to right border element and comprising the target gene, has a length of at least 30000 bp.
T-DNA comprising the coding sequences of any single gene of the tables given in the examples, preferably comprising the coding sequences and and promoters of any single of the tables given in the examples, more preferably the coding sequences and promoters and terminators of any single of the tables given in the examples, and most preferably the expression cassettes of any single of the tables of the examples, in particular wherein the T-DNA comprises the coding sequences of the desaturases and elongases of Table 1 1 in the Examples.
Plant or a seed or part thereof, comprising, integrated in its genome, a heterologous T- DNA of the present invention.
Plant comprising one or more T-DNA comprising one or more expression cassettes encoding for one or more d5Des, one or more d6Elo, one or more d6Des, one or more o3Des, one or more d5Elo and one or more D4Des.
The plant of Embodiment 3 or 4 comprising one or more T-DNAs encoding for at least two d6Des, at least two d6Elo and/or, at least two o3Des.
The plant any one of Embodiments 3 to 5 on or a part thereof comprising a T-DNA encoding for at least one CoA-depenent d4Des and at least one phopho-lipid dependent d4Des.
The plant, seed or part thereof any one of Embodiments 3 to 6 the plant, seed or part thereof further encoding for one or more d12Des.
Plant or seed thereof of family Brassicaceae, preferably of genus Brassica, with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from progeny lines prepared by a method comprising the steps of
i) crossing a plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant comprising a T-DNA of any of Embodiments 1 or 2 and/or part of such T-DNA, with a plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant not comprising said T-DNA and/or part thereof, to yield a F1 hybrid,
ii) selfing the F1 hybrid for at least one generation, and
iii) identifying the progeny of step (ii) comprising the T-DNA of the present invention capable of producing seed comprising VLC-PUFA such that the content of all VLC- PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 6%, preferably at least 7,5% (w/w) and/or the content of DHA is at least 0,8% (w/w), preferably 1 ,2% of the total seed fatty acid content at an oil content of 40% (w/w).
Method for creating a plant with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from progeny lines prepared by a method comprising the steps of
i) crossing a transgenic plant according to any of Embodiments 3 or 4 with a plant not comprising a T-DNA according to any of Embodiments 1 or 2 or part thereof, said latter plant being of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, to yield a F1 hybrid,
ii) selfing the F1 hybrid for at least one generation, and
iii) identifying the progeny of step (ii) comprising the T-DNA of the present invention capable of producing seed comprising VLC-PUFA such that the content of all VLC- PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 6%, preferably at least 7,5% (w/w) and/or the content of DHA is at least 0,8% (w/w), prerferably 1.2% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w).
The method of Embodiment 9 or the plant of Embodiment 8, wherein the T-DNA is homozygous
Method of plant oil production, comprising the steps of
i) growing a plant according to any of Embodiments 3 to 8 such as to obtain oil- containing seeds thereof,
ii) harvesting said seeds, and
iii) extracting oil from said seeds harvested in step ii), wherein the oil has a DHA content of at least 1 % by weight based on the total lipid content and/or a EPA content of at least 8% by weight based on the total lipid content.
Plant oil comprising a polyunsaturated fatty acid obtainable or obtained by the method of Embodiment 1 1.
Method for analysing desaturase reaction specificity, comprising the steps of
i) providing, to a desaturase, a detectably labelled molecule comprising a fatty acid moiety and a headgroup,
ii) allowing the desaturase to react on the labelled molecule, and
iii) detecting desaturation products.
Method for analysing elongase reaction specificity, comprising the steps of
i) providing, to an elongase, a detectably labelled elongation substrate and a molecule to be elongated,
ii) allowing the elongase to elongate the molecule to be elongated using the labelled elongation substrate, and
iii) detecting elongation products.
Method for optimization of a metabolic pathway, comprising the steps of
i) providing enzymes of a metabolic pathway and one or more substrates to be used by the first enzyme or enzymes of the pathway,
ii) reacting the enzymes and the substrates to produce products, which in turn are also exposed as potential substrates to the enzymes of the pathway, and iii) determining the accumulation of products.
Method for determining CoA-dependence of a target desaturase, comprising the steps of i) providing an elongase to produce a substrate for the target desaturase, and determining conversion efficiency of the target desaturase, and
ii) providing a non-CoA dependent desaturase to produce the substrate for the target desaturase, and determining conversion efficiency of the target desaturase, and iii) comparing the target desaturase conversion efficiencies of step i) and ii).
Method for determining CoA-dependence of a target desaturase, comprising the steps of i) providing an elongase to elongate the products of the target desaturase, and determining conversion efficiency of the elongase,
ii) providing the elongase to elongate the products of a comparison desaturase known to be non-CoA dependent, and determining conversion efficiency of the elongase,
iii) comparing the elongase conversion efficiencies of step i) and ii).
A method for increasing the content of Mead acid (20:3n-9) in a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-6- desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase.
The method according to claim 18, further comprising expression a delta-12-desaturase, omega-3-desaturase, a delta-5-elongase, and/or a delta-4-desaturase.
The Examples for the invention described in Section A are Examples 1 to 32 in the Exampl section.
SECTION B: BRASSICA EVENTS LBFLFK AND LBFDAU AND METHODS FOR DETECTION THEREOF
FIELD OF THE INVENTION (for the invention described in Section B) The present invention relates to the field of biotechnology and agriculture, and more specifically, to transgenic Brassica plants comprising event LBFLFK or event LBFDAU, progeny plants, seed thereof, and oil and meal derived therefrom. The invention also relates to methods for detecting the presence of event LBFLFK or event LBFDAU in biological samples which employ nucleotide sequences that are unique to each event. BACKGROUND OF THE INVENTION (for the invention described in Section B)
The health benefits of the Very Long Chain Polyunsaturated Fatty Acids ("VLC-PUFA" or "PUFA") to human and animal nutrition have become increasingly established in recent years. In particular, the ω3 PUFA eicosapentaenoic acid (EPA) and docosahexaenoic acid (DHA) play roles in neural development, immune responses, and inflammatory responses. In addition, dietary supplements containing EPA and DHA are used to alleviate cardiovascular and neurological pathology, and may be useful in treating some cancers.
The current commercial source of EPA and DHA is fish oil. However, marine stocks are diminishing, and alternative sources of EPA and DHA are needed to meet increasing demand. Numerous efforts have been made to develop transgenic oilseed plants that produce VLC- PUFAs, including EPA and DHA. See, e.g., WO 2004/071467, WO 2013/185184, WO 2015/089587, Ruiz-Lopez, et al. (2014) Plant J. 77, 198-208. However, no transgenic oilseed plant has been commercialized which produces EPA and DHA at commercially relevant levels.
Polynucleotides encoding polypeptides which exhibit delta-6-elongase activity have been described in WO2001/059128, WO2004/087902 and WO2005/012316, said documents, describing this enzyme from Physcomitrella patens.
Polynucleotides encoding polypeptides which exhibit delta-5-desaturase activity have been described in WO2002026946 and WO2003/093482, said documents, describing this enzyme from Thraustochytrium sp.
Polynucleotides encoding polypeptides which exhibit delta-6-desaturase activity have been described in WO2005/012316, WO2005/083093, WO2006/008099 and WO2006/069710, said documents, describing this enzyme from Ostreococcus tauri.
Polynucleotides encoding polypeptides which exhibit delta-6-elongase activity have been described in WO2005/012316, WO2005/007845 and WO2006/069710, said documents, describing this enzyme from Thalassiosira pseudonana.
Polynucleotides encoding polypeptides which exhibit delta-12-desaturase activity have been described for example in WO2006100241 , said documents, describing this enzyme from Phytophthora sojae.
Polynucleotides encoding polypeptides which exhibit delta-5-elongase activity have been described for example in WO2005/012316 and WO2007/096387, said documents, describing this enzyme from Ostreococcus tauri.
Polynucleotides encoding polypeptides which exhibit omega 3-desaturase activity have been described for example in WO2008/022963, said documents, describing this enzyme from Phytium irregulare. Polynucleotides encoding polypeptides which exhibit omega 3-desaturase activity have been described for example in WO2005012316 and WO2005083053, said documents, describing this enzyme from Phytophthora infestans.
Polynucleotides encoding polypeptides which exhibit delta-4-desaturase activity have been described for example in WO2002026946, said documents, describing this enzyme from Thraustochytrium s p .
Polynucleotides coding for a delta-4 desaturase from Pavlova lutheri are described in WO2003078639 and WO2005007845.
The expression of foreign gene constructs in plants is known to be influenced by the chromosomal location at which the genes are inserted, and the presence of the transgenic construct at different locations in the plant's genome can influence expression of endogenous genes and the phenotype of the plant. For these reasons, it is necessary to screen large numbers of transgenic events made from a particular construct, in order to identify one or more "elite" events for commercialization that exhibit optimal expression of the transgene without undesirable characteristics. An elite event has the desired levels and patterns of transgenic expression and may be used to introgress the transgenic construct into commercially relevant genetic backgrounds, by sexual outcrossing using conventional breeding methods. Progeny of such crosses maintain the transgenic construct expression characteristics of the original elite event. This strategy is used to ensure reliable gene expression in a number of varieties that are adapted to local growing conditions. For introgression, deregulation, and quality control purposes, it is necessary to be able to detect the presence of the transgenic construct in an elite event, both in the progeny of sexual crosses and in other plants. In addition, grain, meal, and foodstuffs may also be monitored for adventitious presence of transgenic constructs to ensure compliance with regulatory requirements.
The presence of a transgenic construct may be detected using known nucleic acid detection methods such as the polymerase chain reaction (PCR) or DNA hybridization using nucleic acid probes. These detection methods may be directed to frequently used genetic elements, such as promoters, terminators, marker genes, etc. Such methods may not be useful for discriminating
between different events that contain the same genetic elements, unless the sequence of the chromosomal DNA adjacent to the inserted construct ("flanking DNA") is also known. Event- specific assays are known for numerous genetically modified products which have been commercialized. Event-specific detection assays are also required by regulatory agencies responsible for approving use of transgenic plants comprising a particular elite event. Transgenic plant event-specific assays have been described, for example, in U.S. Pat. Nos. 6,893,826; 6,825,400; 6,740,488; 6,733,974; 6,689,880; 6,900,014; 6,818,807; and 8,999,41 1.
SUMMARY OF THE INVENTION (for the invention described in Section B)
In one embodiment, the present invention provides Brassica plants comprising transgenic Brassica event LBFLFK deposited as ATCC Designation "PTA-121703". Brassica event LBFLFK contains two insertions of the binary T-plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFLFK Locus 1 and LBFLFK Locus 2. The Brassica plants of this embodiment include progeny that are indistinguishable from Brassica event LBFLFK (to the extent that such progeny also contain at least one allele corresponding to LBKLFK Locus 1 or LBFLFK Locus 2). The Brassica plants of this embodiment comprise unique genomic DNA/transgene junction points, and consequently unique junction regions, for each LBFLFK insertion: the junction region for LBFLFK Locus 1 having at least the polynucleotide sequence of SEQ ID NO:282 or at least the polynucleotide sequence of SEQ ID NO:283, and the junction region for LBFLFK Locus 2 having at least the polynucleotide sequence of SEQ ID NO:291 or at least the polynucleotide sequence of SEQ ID NO:292. Also included in this embodiment are seeds, plant parts, plant cells, and plant products derived from Brassica event LBFLFK and progeny thereof.
In another embodiment, compositions and methods are provided for detecting the presence of the Brassica event LBFLFK genomic DNA/transgene junction regions for each LBFLFK insertion: the junction region for LBFLFK Locus 1 having at least the polynucleotide sequence of SEQ ID NO:282 or at least the polynucleotide sequence of SEQ ID NO:283, and the junction region for LBFLFK Locus 2 having at least the polynucleotide sequence of SEQ ID NO:291 or at least the polynucleotide sequence of SEQ ID NO:292.
In another embodiment, the invention provides commodity products, including canola oil and meal, produced from Brassica event LBFLFK and/or its progeny. In another embodiment, the invention provides Brassica plants comprising transgenic Brassica event LBFDAU deposited as ATCC Designation "PTA-122340". Brassicaevent LBFDAU contains two insertions of the binary T-plasmid VC-LTM593-1 qcz rc, the insertions being designated LBFDAU Locus 1 and LBFDAU Locus 2. The Brassica plants of this embodiment include and progeny thereof that are indistinguishable from Brassica event LBFDAU (to the extent that such progeny also contain at least one allele that corresponds to the inserted transgenic DNA). The Brassica plants of this embodiment comprise unique genomic DNA/transgene junction points, and consequently two unique junction regions, for each LBFDAU insertion: the junction region for LBFDAU Locus 1 having at least the polynucleotide sequence of SEQ ID NO:300or at least the polynucleotide sequence of SEQ ID NO:301 and the junction region for LBFDAU Locus 2 having
at least the polynucleotide sequence of SEQ ID NO:309 or at least the polynucleotide sequence of SEQ ID NO:310. Also included in this embodiment are seeds, plant parts, plant cells, and plant products derived from Brassica event LBFDAU and progeny thereof.
In another embodiment, compositions and methods are provided for detecting the presence of the Brassica event LBFDAU genomic DNA/transgene junction regions; the junction region for LBFDAU Locus 1 having at least the polynucleotide sequence of SEQ ID NO:300 or at least the polynucleotide sequence of SEQ ID NO:301 and the junction region for LBFDAU Locus 2 having at least the polynucleotide sequence of SEQ ID NO:309 or at least the polynucleotide sequence of SEQ ID NO:310. In another embodiment, the invention provides commodity products, including canola oil and meal, produced from Brassica event LBFDAU and/or its progeny.
BRIEF DESCRIPTION OF THE SEQUENCES
The following sequences are mentioned in Section B. Some of the following sequences are also mentioned in Section A. Thus, the description provided herein below for these sequences also apply to Section A.
SEQ ID NO:279 is the sequence of vector VC-LTM593-1 qcz rc used for transformation (see Figure 92)
SEQ ID NO:280 is a 44910 bp sequence assembled from the insert sequence of LBFLFK T-DNA Locus 1 (SEQ ID NO: 281 ) and flanking sequences represented by SEQ ID NO:284 and SEQ ID NO:285 (See Figure 93).
SEQ ID NO:281 is the sequence of the T-DNA insertion in Locus 1 of event LBFLFK, including left and right border sequences (See Figure 93).
SEQ ID NO:282 is the LBFLFK Locus 1 RB junction region sequence including 10 bp of flanking genomic DNA and bp 1-10 of SEQ ID NO:281 (See Figure 93).
SEQ ID NO:283 is the LBFLFK Locus 1 LB junction region sequence including bp 43748-43757 of SEQ ID NO:281 and 10 bp of flanking genomic DNA (See Figure 93).
SEQ ID NO:284 is the flanking sequence up to and including the right border of the T-DNA in LBFLFK Locus 1 . Nucleotides 1 -570 are genomic DNA (See Figure 93). SEQ ID NO:285 is the flanking sequence up to and including the left border of the T-DNA in LBFLFK Locus 1 . Nucleotides 229-81 1 are genomic DNA (See Figure 93).
SEQ ID NO:286 is an LBFLFK Locus 1_Forward primer suitable for identifying Locus 1 of LBFLFK events. A PCR amplicon using the combination of SEQ ID NO:286 and SEQ ID NO:287 is positive for the presence of LBFLFK Locus 1 .
SEQ ID NO:287 is an LBFLFK Locus 1_Reverse primer suitable for identifying Locus 1 of LBFLFK events. A PCR amplicon using the combination of SEQ ID NO:286 and SEQ ID NO:287 is positive for the presence of LBFLFK Locus 1 .
SEQ ID NO:288 is an LBFLFK locus 1_Probe is a FAM™ -labeled synthetic oligonucleotide that when used in an amplification reaction with SEQ ID NO:286 and SEQ ID NO:287 will release a fluorescent signal when positive for the presence of LBFLFK Locus 1 . SEQ ID NO:289 is a 47800 bp sequence assembled from the insert sequence of LBFLFK T-DNA Locus 2 (SEQ ID NO: 290) and flanking sequences represented by SEQ ID NO:293 and SEQ ID NO:294 (See Figure 94).
SEQ ID NO:290 is the sequence of the T-DNA insertion in Locus 2 of event LBFLFK, including left and right border sequences (See Figure 94). SEQ ID NO:291 is the LBFLFK Locus 2 RB junction sequence including 10 bp of flanking genomic DNA and bp 1 -10 of SEQ ID NO:290 (See Figure 94).
SEQ ID NO:292 is the LBFLFK Locus 2 LB junction sequence including bp 43764-43773 of SEQ ID NO:290 and 10 bp of flanking genomic DNA (See Figure 94).
SEQ ID NO:293 is the flanking sequence up to and including the right border of the T-DNA in LBFLFK Locus 2. Nucleotides 1 -2468 are genomic DNA (See Figure 94).
SEQ ID NO:294 is the flanking sequence up to and including the left border of the T-DNA in LBFLFK Locus 2. Nucleotides 242-1800 are genomic DNA (See Figure 94).
SEQ ID NO:295 is the LBFLFK locus 2_Forward primer suitable for identifying Locus 2 of LBFLFK events. A PCR amplicon using the combination of SEQ ID NO:295 and SEQ ID NO:296 is positive for the presence of LBFLFK Locus 2.
SEQ ID NO:296 is the LBFLFK locus 2_Reverse primer suitable for identifying Locus 2 of LBFLFK events. A PCR amplicon using the combination of SEQ ID NO:295 and SEQ ID NO:296 is positive for the presence of LBFLFK Locus 2.
SEQ ID NO:297 is the LBFLFK locus 2_Probe is a FAM™ -labeled synthetic oligonucleotide that when used in an amplification reaction with SEQ ID NO:295 and SEQ ID NO:296 will release a fluorescent signal when positive for the presence of LBFLFK Locus 2.
SEQ ID NO:298 is a 45777 bp sequence assembled from the insert sequence of LBFDAU T-DNA Locus 1 (SEQ ID NO:299) and flanking sequences represented by SEQ ID NO:302 and SEQ ID NO:303 (See Figure 95).
SEQ ID NO:299 is the sequence of the T-DNA insertion in Locus 1 of event LBFDAU, including left and right border sequences (See Figure 95).
SEQ ID NO:300 is the LBFDAU Locus 1 RB junction sequence including 10 bp of flanking genomic DNA and bp 1-10 of SEQ ID NO:299 (See Figure 95). SEQ ID NO:301 is the LBFDAU Locus 1 LB junction sequence including bp 4371 1-43720 of SEQ ID NO:299 and 10 bp of flanking genomic DNA (See Figure 95).
SEQ ID NO:302 is the flanking sequence up to and including the right border of the T-DNA in LBFDAU Locus 1 . Nucleotides 1 -1017 are genomic DNA (See Figure 95).
SEQ ID NO:303 is the flanking sequence up to and including the left border of the T-DNA in LBFDAU Locus 1 . Nucleotides 637-1677 are genomic DNA (See Figure 95).
SEQ ID NO:304 is an LBFDAU Locus 1_Forward primer suitable for identifying Locus 1 of LBFDAU events. A PCR amplicon using the combination of SEQ ID NO:304 and SEQ ID NO:305 is positive for the presence of LBFDAU Locus 1.
SEQ ID NO:305 is an LBFDAU Locus 1_Reverse primer suitable for identifying Locus locus 1 of LBFDAU events. A PCR amplicon using the combination of SEQ ID NO:304 and SEQ ID NO:305 is positive for the presence of LBFDAU Locus 1.
SEQ ID NO:306 is an LBFDAU locus 1_Probe is a FAM™ -labeled synthetic oligonucleotide that when used in an amplification reaction with SEQ ID NO:304 and SEQ ID NO:305 will release a fluorescent signal when positive for the presence of LBFDAU Locus 1. SEQ ID NO:307 is a 39620 bp sequence assembled from the insert sequence of LBFDAU T-DNA Locus 2 (SEQ ID NO:308) and flanking sequences represented by SEQ ID NO:31 1 and SEQ ID NO:312 (See Figure 96).
SEQ ID NO:308 is the sequence of the T-DNA insertion in Locus 2 of event LBFDAU, including left and right border sequences (See Figure 96). SEQ ID NO:309 is the LBFDAU Locus 2 RB junction sequence including 10 bp of flanking genomic DNA and bp 1-10 of SEQ ID NO: 308 (See Figure 96).
SEQ ID NO:310 is the LBFDAU Locus 2 LB junction sequence including bp 37478-37487 of SEQ ID NO:308 and 10 bp of flanking genomic DNA (See Figure 96).
SEQ ID NO:31 1 is the flanking sequence up to and including the right border of the T-DNA in LBFDAU Locus 2. Nucleotides 1 -1099 are genomic DNA (See Figure 96).
SEQ ID NO:312 is the flanking sequence up to and including the left border of the T-DNA in LBFLFK Locus 2. Nucleotides 288-1321 are genomic DNA (See Figure 96).
SEQ ID NO:313 is an LBFDAU locus 2_Forward primer suitable for identifying Locus 2 of LBFDAU events. A PCR amplicon using the combination of SEQ ID NO:313 and SEQ ID NO:314 is positive for the presence of LBFDAU locus 2.
SEQ ID NO:314 is an LBFDAU locus 2_Reverse primer suitable for identifying Locus 2 of LBFDAU events. A PCR amplicon using the combination of SEQ ID NO:313 and SEQ ID NO:314 is positive for the presence of LBFDAU locus 2.
SEQ ID NO:315 is an LBFDAU locus 2_Probe is a FAM™ -labeled synthetic oligonucleotide that when used in an amplification reaction with SEQ ID NO:313 and SEQ ID NO:314 will release a fluorescent signal when positive for the presence of LBFDAU Locus 2. SEQ ID NO:316 is a primer suitable for determining zygosity of LBFLFK Locus 1 . When used in combination with SEQ ID NO:317, production of a PCR amplicon of about 542bp is positive for presence of WT at LBFLFK Locus 1.
SEQ ID NO:317 is a primer suitable for determining zygosity of LBFLFK Locus 1 . When used in combination with SEQ ID NO:316, production of a PCR amplicon of about 542bp is positive for presence of WT at LBFLFK Locus 1.
SEQ ID NO:318 is a primer suitable for determining zygosity of LBFLFK Locus 2. When used in combination with SEQ ID NO:319, production of a PCR amplicon of about 712bp is positive for presence of WT at LBFLFK Locus 2.
SEQ ID NO:319 is a primer suitable for determining zygosity of LBFLFK Locus 2. When used in combination with SEQ ID NO:318, production of a PCR amplicon of about 712bp is positive for presence of WT at LBFLFK Locus 2.
SEQ ID NO:320 is a primer suitable for determining zygosity of LBFDAU Locus 1 . When used in combination with SEQ ID NO:321 , production of a PCR amplicon of about 592bp is positive for presence of WT at LBFDAU Locus 1 . SEQ ID NO:321 is a primer suitable for determining zygosity of LBFDAU Locus 1 . When used in combination with SEQ ID NO:320, production of a PCR amplicon of about 592bp is positive for presence of WT at LBFDAU Locus 1 .
SEQ ID NO:322 is a primer suitable for determining zygosity of LBFDAU Locus 2. When used in combination with SEQ ID NO:323, production of a PCR amplicon of about 247bp is positive for presence of WT at LBFDAU Locus 2.
SEQ ID NO:323 is a primer suitable for determining zygosity of LBFDAU Locus 2. When used in combination with SEQ ID NO:322, production of a PCR amplicon of about 247bp is positive for presence of WT at LBFDAU Locus 2.
DETAILED DESCRIPTION OF THE INVENTION (for the invention described in Section B only)
The present invention is directed to transgenic Brassica events LBFLFK and LBFDAU, which are capable of producing oil comprising VLC-PUFAs, including EPA and DHA, for use as commodity products. Brassica plants of the invention have been modified by the insertion of the binary T-plasmid VC-LTM593-1 qcz rc (SEQ ID NO:279) described in Example B1 comprising, in order, polynucleotides encoding the following enzymes of the VLC-PUFA biosynthetic pathway: Delta-6 ELONGASE from Physcomitrella patens; Delta-5 DESA TURASE from Thraustochytrium sp. ATCC21685; Delta-6 DESA TURASE from Ostreococcus tauri; Delta-6 ELONGASE from Thalassiosira pseudonana; Delta-12 DESA TURASE from Phythophthora sojae; Omega-3 DESA TURASEftom Pythium irregulare; Omega-3-DESA TURASEftom Phythophthora infestans; Delta-5 DESA TURASE from Thraustochytrium sp. ATCC21685; Delta-4 DESA TURASE from Thraustochytrium sp.; Omega-3 DESA TURASE from Pythium irregular; Delta-4 DESA TURASE from Pavlova lutheri; Delta-5 ELONGASE from Ostreococcus tauri. The VC-LTM593-1 qcz rc binary T-plasmid (SEQ ID NO:279) further comprises a polynucleotide encoding the selectable marker acetohydroxy acid synthase, which confers tolerance to imidazolinone herbicides.
The invention further relates to the T-DNA insertions in each of Brassica events LBFLFK and LBFDAU, and to the genomic DNA/transgene insertions, i.e., the Locus 1 and Locus 2 junction regions found in Brassica plants or seeds comprising Brassica event LBFLFK, to the genomic DNA/transgene insertions, i.e., Locus 1 and Locus 2 junction regions found in Brassica plants or seeds comprising Brassica event LBFDAU, and the detection of the respective genomic DNA/transgene insertions, i.e., the respective Locus 1 and Locus 2 junction regions in Brassica plants or seed comprising event LBFLFK or event LBFDAU and progeny thereof.
As used herein, the term "Brassica" means any Brassica plant and includes all plant varieties that can be bred with Brassica. As defined herein, Brassica species include B. napus, B. rapa, B. juncea, B. oleracea, B. nigra, and B. carinata. Preferably, the species of the LBFLFK and LBFDAU events and their progeny is B. napus. As used herein, the term plant includes plant cells, plant organs, plant protoplasts, plant cell tissue cultures from which plants can be regenerated, plant calli, plant clumps and plant cells that are intact in plants or parts of plants such as embryos, pollen, ovules, seeds, leaves, flowers, branches, fruit, stalks, roots, root tips, anthers, and the like. Mature seed produced may be used for food, feed, fuel or other commercial or industrial purposes or for purposes of growing or reproducing the species. Progeny, variants and mutants of the regenerated plants are also included within the scope of the invention, provided that these parts comprise a LBFLFK or LBFDAU event.
A transgenic "event" is produced by transformation of plant cells with a heterologous DNA construct(s) including a nucleic acid expression cassette that comprises one or more transgene(s) of interest, the regeneration of a population of plants from cells which each comprise the inserted transgene(s) and selection of a particular plant characterized by insertion into a particular genome location. An event is characterized phenotypically by the expression of the transgene(s). At the genetic level, an event is part of the genetic makeup of a plant. The term "event" refers to the original transformant and progeny of the transformant that include the heterologous DNA. The
term "event" also refers to progeny, produced by a sexual outcross between the transformant and another variety, that include the heterologous DNA. Even after repeated back-crossing to a recurrent parent, the inserted DNA and flanking DNA from the transformed parent are present in the progeny of the cross at the same chromosomal location. The term "event" also refers to DNA from the original transformant comprising the inserted DNA and flanking sequence immediately adjacent to the inserted DNA that would be expected to be transferred to a progeny as the result of a sexual cross of one parental line that includes the inserted DNA (e.g., the original transformant and progeny resulting from selfing) and a parental line that does not contain the inserted DNA. In accordance with the invention, progeny of the Brassica LBFLFK event may comprise either LBFLFK Locus 1 or LBFLFK Locus 2, or both LBFLFK Locus 1 and LBFLFK Locus 2. Similarly, progeny of the Brassica LBFDAU event may comprise either LBFDAU Locus 1 or LBFDAU Locus 2, or both LBFDAU Locus 1 and LBFDAU Locus 2.
As used herein, "insert DNA" refers to the heterologous DNA within the expression cassettes used to transform the plant material while "flanking DNA" can comprise either genomic DNA naturally present in an organism such as a plant, or foreign (heterologous) DNA introduced via the transformation process which is extraneous to the original insert DNA molecule, e.g. fragments associated with the transformation event. A "flanking region" or "flanking sequence" as used herein refers to a sequence of at least 20, 50, 100, 200, 300, 400, 1000, 1500, 2000, 2500 or 5000 base pairs or greater which is located either immediately upstream of and contiguous with, or immediately downstream of and contiguous with, the original foreign insert DNA molecule. Non-limiting examples of the flanking regions of the LBFLFK event comprise, for Locus 1 , nucleotides 1 to 570 of SEQ ID NO: 284, nucleotides 229 to 81 1 of SEQ ID NO:285 and for Locus 2, nucleotides 1 to 2468 of SEQ ID NO:293, and/or nucleotides 242 to 1800 of SEQ ID NO:294 and variants and fragments thereof. Non-limiting examples of the flanking regions of the LBFDAU event comprise, for Locus 1 , nucleotides 1 to 1017 of SEQ ID NO: 302, nucleotides 637 to 1677 of SEQ ID NO:303, and for Locus 2, nucleotides 1 to 1099 of SEQ ID NO:31 1 and/or nucleotides 288 to 1321 of SEQ ID NO: 312 and variants and fragments thereof.
Transformation procedures leading to random integration of the foreign DNA will result in transformants containing different flanking regions characteristic of and unique for each transformant. When recombinant DNA is introduced into a plant through traditional crossing, its flanking regions will generally not be changed. Transformants will also contain unique junctions between a piece of heterologous insert DNA and genomic DNA or two pieces of genomic DNA or two pieces of heterologous DNA. A "junction point" is a point where two specific DNA fragments join. For example, a junction point exists where insert DNA joins flanking DNA. A junction point also exists in a transformed organism where two DNA fragments join together in a manner that is modified from that found in the native organism. As used herein, "junction DNA" or "junction region" refers to DNA that comprises a junction point. Non-limiting examples of junction DNA from the LBFLFK event comprise, for Locus 1 , SEQ ID NO:282, SEQ ID NO:283, and for Locus 2, SEQ ID NO:291 , and/or SEQ ID NO:292, complements thereof, or variants and fragments thereof. Non-limiting examples of junction DNA from the LBFDAU event comprise, for Locus 1 ,
SEQ ID NO:300, SEQ ID NO:301 , and for Locus 2, SEQ ID NO:309 and/or SEQ ID NO:310, complements thereof, or variants and fragments thereof.
The term "germplasm" refers to an individual, a group of individuals or a clone representing a genotype, variety, species or culture or the genetic material thereof. A "line" or "strain" is a group of individuals of identical parentage that are generally inbred to some degree and that are generally isogenic or near isogenic. Inbred lines tend to be highly homogeneous, homozygous and reproducible. Many analytical methods are available to determine the homozygosity and phenotypic stability of inbred lines.
The phrase "hybrid plants" refers to plants which result from a cross between genetically different individuals.
The term "crossed" or "cross" in the context of this invention means the fusion of gametes, e.g., via pollination to produce progeny (i.e., cells, seeds, or plants) in the case of plants. The term encompasses both sexual crosses (the pollination of one plant by another) and, in the case of plants, selfing (self-pollination, i.e., when the pollen and ovule are from the same plant). The term "introgression" refers to the transmission of a desired allele of a genetic locus from one genetic background to another. In one method, the desired alleles can be introgressed through a sexual cross between two parents, wherein at least one of the parents has the desired allele in its genome.
The term "polynucleotide" according to the present invention refers to a deoxyribonucleic acid or ribonucleic acid. Unless stated otherwise, "polynucleotide" herein refers to a single strand of a DNA polynucleotide or to a double stranded DNA polynucleotide. The length of a polynucleotide is designated according to the invention by the specification of a number of base pairs ("bp") or nucleotides ("nt"). According to the invention, both designations are used interchangeably for single or double stranded nucleic acids. Also, as polynucleotides are defined by their respective nucleotide sequence, the terms nucleotide/polynucleotide and nucleotide sequence/polynucleotide sequence are used interchangeably, so that a reference to a nucleic acid sequence also is meant to define a nucleic acid comprising or consisting of a nucleic acid stretch the sequence of which is identical to the nucleic acid sequence.
As used herein, an "isolated DNA molecule", is an artificial polynucleotide corresponding to all or part of a flanking region, junction region, transgenic insert, amplicon, primer or probe that is unique to Brassica event LBFLFK or Brassica event LBFDAU, and which is not contained within the genome of Brassica event LBFLFK or the genome of Brassica event LBFDAU. Such isolated DNA molecules may be derived from the VC-LTM593-1 qcz rc plasmid used to produce the LBFLFK and LBFDAU events, or from the genome of Brassica event LBFLFK or Brassica event LBFDAU, or from tissues, seeds, progeny, cells, plant organs, biological samples or commodity products derived from Brassica event LBFLFK or Brassica event LBFDAU. Such isolated DNA molecules can be extracted from cells, or tissues, or homogenates from a plant or seed or plant organ; or can be produced as an amplicon from extracted DNA or RNA from cells, or tissues, or
homogenate from a plant or seed or plant organ, any of which is derived from Brassica event LBFLFK or Brassica event LBFDAU, or progeny, biological samples or commodity products derived therefrom.
A "probe" is an isolated nucleic acid to which is attached a conventional detectable label or reporter molecule, e.g., a radioactive isotope, ligand, chemiluminescent agent, or enzyme. Such a probe is complementary to a strand of a target nucleic acid, in the case of the present invention, to a strand of genomic DNA from Brassica event LBFLFK or Brassica event LBFDAU, whether from a Brassica plant or from a sample that includes DNA from the event. Probes according to the present invention include not only deoxyribonucleic or ribonucleic acids but also polyamides and other probe materials that bind specifically to a target DNA sequence and such binding can be used to detect the presence of that target DNA sequence.
"Primers" are isolated nucleic acids that can specifically anneal to a complementary target DNA strand by nucleic acid hybridization to form a hybrid between the primer and the target DNA strand, and then can be extended along the target DNA strand by a polymerase, e.g., a DNA polymerase. A primer pair or primer set of the present invention refers to two different primers that together are useful for amplification of a target nucleic acid sequence, e.g., by the polymerase chain reaction (PCR) or other conventional nucleic-acid amplification methods.
Probes and primers are generally 1 1 nucleotides or more in length, preferably 18 nucleotides or more, more preferably 24 nucleotides or more, and most preferably 30 nucleotides or more. Such probes and primers hybridize specifically to a target sequence under high stringency hybridization conditions. Preferably, probes and primers according to the present invention have complete sequence similarity with the target sequence, although probes differing from the target sequence and that retain the ability to hybridize to target sequences may be designed by conventional methods. Primers, primer pairs, or probes, may be produced by nucleotide synthesis, cloning, amplification, or other standard methods for producing a polynucleotide molecule. In accordance with the invention, one or more primer or probe sequences specific for target sequences in event LBFLFK Locus 1 , LBFLFK Locus 2, LBFDAU Locus 1 , and LBFDAU Locus 2, or complementary sequences thereto, may be selected using this disclosure and methods known in the art, for instance, via in silico analysis as described in Wojciech and Rhoads, NAR 17:8543-8551 , 1989. The term "specific for (a target sequence)" indicates that a probe or primer hybridizes under stringent hybridization conditions only to the target sequence in a sample comprising the target sequence.
As used herein, "amplified DNA" or "amplicon" refers to the product of nucleic-acid amplification of a target nucleic acid sequence that is part of a nucleic acid template. The amplicon is of a length and has a sequence that is also diagnostic for the event. An amplicon may be of any length, and may range in length, for example, from the combined length of the primer pairs plus one nucleotide base pair, or the length of the primer pairs plus about fifty nucleotide base pairs, or the length of the primer pairs plus about two hundred nucleotide base pairs, the length of the primer pairs plus about five hundred nucleotide base pairs, or the length of the primer pairs plus about
seven hundred fifty nucleotide base pairs, and the like. A primer pair can be derived from flanking sequence on both sides of the inserted DNA so as to produce an amplicon that includes the entire insert nucleotide sequence. Alternatively, a primer pair can be derived from flanking sequence on one side of an insert and sequence within the insert. A member of a primer pair derived from the plant genomic sequence may be located a distance from the inserted DNA molecule, and this distance can range from one nucleotide base pair up to about twenty thousand nucleotide base pairs. The use of the term "amplicon" specifically excludes primer-dimers that may be formed in the DNA thermal amplification reaction.
A "commodity product" refers to any product which is comprised of material derived from Brassica or Brassica oil and is sold to consumers.
The term "polyunsaturated fatty acids (PUFA)" as used herein refers to fatty acids comprising at least two, preferably, three, four, five or six, double bonds. Moreover, it is to be understood that such fatty acids comprise, preferably from 18 to 24 carbon atoms in the fatty acid chain. In accordance with the invention, the term relates to long chain PUFA (VLC-PUFA) having from 20 to 24 carbon atoms in the fatty acid chain. Systematic names of fatty acids including polyunsaturated fatty acids, their corresponding trivial names and shorthand notations used according to the present invention are given in Table B1 .


Preferably, the VLC-PUFA produced by the LBFLFK and LBFDAU events and their progeny include DHGLA, ARA, ETA, EPA, DPA, DHA. More preferably, the VLC-PUFA produced by the LBFLFK and LBFDAU events and their progeny include ARA, EPA, and DHA. Most preferably, the VLC-PUFA produced by the LBFLFK and LBFDAU events and their progeny include EPA and/or DHA. Moreover, the LBFLFK and LBFDAU events and their progeny also produce intermediates of VLC-PUFA which occur during synthesis. Such intermediates may be formed from substrates by the desaturase, keto-acyl-CoA-synthase, keto-acyl-CoA-reductase, dehydratase and enoyl-CoA-reductase activity of the polypeptides of the present invention.
Preferably, such substrates may include LA, GLA, DHGLA, ARA, eicosadienoic acid, ETA, and EPA.
In one embodiment, the transgenic Brassica plants of the invention comprise event LBFLFK (ATCC designation PTA-121703). Seed and progeny of event LBFLFK are also encompassed in this embodiment. In another embodiment, the transgenic Brassica plants of the invention comprise event LBFDAU (ATCC designation PTA-122340). Seed and progeny of event LBFDAU are also encompassed in this embodiment. Seeds of Brassica event LBFLFK (ATCC designation PTA-121703) and Brassica event LBFDAU (ATCC designation PTA-122340) have been deposited by applicant(s) at the American Type Culture Collection, Manassas, VA, USA, under the provisions of the Budapest Treaty on the International Recognition of the Deposit of Microorganisms for the Purposes of Patent Procedure. Applicants have no authority to waive any restrictions imposed by law on the transfer of biological material or its transportation in commerce. Applicants do not waive any infringement of their rights granted under this patent or rights applicable to the deposited events under the Plant Variety Protection Act (7 USC sec. 2321 , et seq.), Unauthorized seed multiplication prohibited. This seed may be regulated according to national law. The deposition of seeds was made only for convenience of the person skilled in the art and does not constitute or imply any confession, admission, declaration or assertion that deposited seed are required to fully describe the invention, to fully enable the invention or for carrying out the invention or any part or aspect thereof. The Brassica plants LBFLFK and LBFDAU can be used to manufacture commodities typically acquired from Brassica. Seeds of LBFLFK and LBFDAU can be processed into meal or oil as well as be used as an oil source in animal feeds for both terrestrial and aquatic animals. The VLC- PUFA-containing oil from events LBFLFK and LBFDAU may be used, for example, as a food additive to increase ω-3 fatty acid intake in humans and animals, or in pharmaceutical compositions to enhance therapeutic effects thereof, or as a component of cosmetic compositions, and the like.
An LBFLFK or LBFDAU plant can be bred by first sexually crossing a first parental Brassica plant grown from the transgenic LBFLFK or LBFDAU Brassica plant (or progeny thereof) and a second parental Brassica plant that lacks the EPA/DHA profile and imidazolinone tolerance of the LBFLFK or LBFDau event, respectively, thereby producing a plurality of first progeny plants and then selecting a first progeny plant that displays the desired imidazolinone tolerance and selfing the first progeny plant, thereby producing a plurality of second progeny plants and then selecting from the second progeny plants which display the desired imidazolinone tolerance and EPA/DHA profile. These steps can further include the back-crossing of the first EPA/DHA producing progeny plant or the second EPA/DHA producing progeny plant to the second parental Brassica plant or a third parental Brassica plant, thereby producing a Brassica plant that displays the desired imidazolinone tolerance and EPA/DHA profile. It is further recognized that assaying progeny for phenotype is not required. Various methods and compositions, as disclosed elsewhere herein, can be used to detect and/or identify the LBFLFK or LBFDAU event.
Two different transgenic plants can also be sexually crossed to produce offspring that contain two independently-segregating exogenous genes. Selfing of appropriate progeny can produce plants that are homozygous for both exogenous transgenic inserts. Back-crossing to a parental plant and out-crossing with a non-transgenic plant are also contemplated, as is vegetative propagation. Descriptions of other breeding methods that are commonly used for different traits and crops can be found in one of several references, e.g., Fehr, in Breeding Methods for Cultivar Development, Wilcos, ed., American Society of Agronomy, Madison Wis. (1987), and Buzza, Plant Breeding, in Brassica Oilseeds: Production and Utilization. D.S. Kimber and D.I. McGregor eds. Cab International, Wallingford, UK (1995). In accordance with the invention embodied in Brassica event LBFLFK, the LBFLFK Locus 1 genomic DNA/transgene junction region and/or the LBFLFK Locus 2 genomic DNA/transgene junction region is present in Brassica plant LBFLFK (ATCC Accession No. PTA-121703) and progeny thereof. The LBFLFK Locus 1 DNA/transgene right border junction region comprises SEQ ID NO:282 and the LBFLFK Locus 1 left border junction region comprises SEQ ID NO:283, and the LBFLFK Locus 2 right border junction region comprises SEQ ID NO:291 and the LBFLFK left border junction region comprises SEQ ID NO:292. DNA sequences are provided that comprise at least one junction region sequence of event LBFLFK selected from the group consisting of SEQ ID NO:282 corresponding to positions 561 through 580 of SEQ ID NO:280 as shown in FIG. 93); SEQ ID NO:283 corresponding to positions 44318 through 44337 of SEQ ID NO:280 , as shown in FIG. 93); SEQ ID NO:291 corresponding to positions 2459 through 2478 of SEQ ID NO:289 as shown in FIG. 94); and SEQ ID NO:292 corresponding to positions 46232 through 46251 of SEQ ID NO:289, as shown in FIG. 94), and complements thereof; wherein detection of these sequences in a biological sample containing Brassica DNA is diagnostic for the presence of Brassica event LBFLFK DNA in said sample. A Brassica event LBFLFK and Brassica seed comprising these DNA molecules is an aspect of this invention.
For example, to determine whether the Brassica plant resulting from a sexual cross contains transgenic DNA from event LBFLFK, DNA extracted from a Brassica plant tissue sample may be subjected to nucleic acid amplification method using (i) a first primer pair that includes: (a) a first primer derived from an LBFLFK Locus 1 flanking sequence and (b) a second primer derived from the LBFLFK Locus 1 inserted heterologous DNA, wherein amplification of the first and second primers produces an amplicon that is diagnostic for the presence of event LBFLFK Locus 1 DNA; and (ii) a second primer pair that includes (a) a third primer derived from an LBFLFK Locus 2 flanking sequence and (b) a fourth primer derived from the LBFLFK Locus 2 inserted heterologous DNA, wherein amplification of the third and fourth primers produces an amplicon that is diagnostic for the presence of event LBFLFK Locus 2 DNA.
The primer DNA molecules specific for target sequences in Brassica event LBFLFK comprise at least 1 1 contiguous nucleotides of any portion of the insert DNAs, flanking regions, and/or junction regions of LBFLFK Locus 1 and Locus 2. For example, LBFLFK Locus 1 primer DNA molecules may be derived from any of SEQ ID NO:280, SEQ ID NO:281 , SEQ ID NO:282, or SEQ ID NO:283; SEQ ID NO:284, or SEQ ID NO:285, or complements thereof, to detect LBFLFK Locus 1 . Similarly, LBFLFK Locus 2 primer DNA molecules may be derived from any of SEQ ID NO:293,
SEQ ID NO:294, SEQ ID NO:291 , or SEQ ID NO:292; SEQ ID NO:290, or SEQ ID NO:289, or complements thereof, to detect LBFLFK Locus 2. Those of skill in the art may use these primers to design primer pairs to produce LBFLFK Locus 1 and Locus 2 amplicons using known DNA amplification methods. The LBFLFK Locus 1 and Locus 2 amplicons produced using these DNA primers in the DNA amplification method are diagnostic for Brassica event LBFLFK when the amplification product contains an amplicon comprising an LBFLFK Locus 1 junction region SEQ ID NO:282 or SEQ ID NO:283, or complements thereof, and an amplicon comprising an LBFLFK Locus 2 junction region SEQ ID NO:291 , or SEQ ID NO:292, or complements thereof.
Any LBFLFK amplicon produced by DNA primers homologous or complementary to any portion of SEQ ID NO:280 or SEQ ID NO:289, or complements thereof, is an aspect of the invention. Any amplicon that comprises SEQ ID NO:282 or SEQ ID NO:283 SEQ ID NO:291 , or SEQ ID NO:292, or complements thereof, is an aspect of the invention.
According to another aspect of the invention, methods of detecting the presence of DNA corresponding to the Brassica event LBFLFK in a sample are provided. Such methods comprise the steps of: (a) contacting the sample comprising DNA with an LBFLFK Locus 1 primer pair and an LBFLFK Locus 2 primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFLFK, produces a Locus 1 amplicon and a Locus 2 amplicon that are diagnostic for Brassica event LBFLFK; (b) performing a nucleic acid amplification reaction, thereby producing the Locus 1 and Locus 2 amplicons; and (c) detecting the amplicons, wherein one amplicon comprises the LBFLFK Locus 1 junction region SEQ ID NO:282 or SEQ ID NO:283, or the complements thereof, and one amplicon comprises the LBFLFK Locus 2 junction region SEQ ID NO:291 or SEQ ID NO:292, or the complements thereof.
The method of detecting the presence of DNA corresponding to the Brassica event LBFLFK in a sample may alternatively comprise the steps of: (a) contacting the sample comprising DNA with a primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFLFK, produces a Locus 1 amplicon that is diagnostic for Brassica event LBFLFK; (b) performing a nucleic acid amplification reaction, thereby producing the amplicon; and (c) detecting the amplicon, wherein the amplicon comprises the LBFLFK Locus 1 junction region SEQ ID NO:282 or SEQ ID NO:283, or the complement thereof. The probe of SEQ ID NO:288 may be used to detect an LBFLFK Locus 1 amplicon.
The method of detecting the presence of DNA corresponding to the Brassica event LBFLFK in a sample may alternatively comprise the steps of: (a) contacting the sample comprising DNA with a primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFLFK, produces a Locus 2 amplicon that is diagnostic for Brassica event LBFLFK; (b) performing a nucleic acid amplification reaction, thereby producing the amplicon; and (c) detecting the amplicon, wherein the amplicon comprises the LBFLFK Locus 2 junction region SEQ ID NO:291 or SEQ ID NO:292, or the complement thereof. The probe of SEQ ID NO:297 may be used to detect an LBFLFK Locus 2 amplicon.
According to another aspect of the invention, methods are provided for detecting the presence of a DNA corresponding to LBFLFK event Locus 1 in a sample. In one embodiment, the method comprises the steps of: (a) contacting the sample comprising DNA with a probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 1 of Brassica event LBFLFK and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probe to the Brassica event LBFLFK DNA, wherein said probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:2 or the complement thereof. An exemplary probe for detecting LBFLFK Locus 1 is represented as SEQ ID NO:288.
The invention is also embodied in methods of detecting the presence of a DNA corresponding to LBFLFK event Locus 2 in a sample. In this embodiment, the method comprises the steps of: (a) contacting the sample comprising DNA with a probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 2 of Brassica event LBFLFK and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probe to the Brassica event LBFLFK DNA, wherein said probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:289 or the complement thereof. An exemplary probe for detecting LBFLFK Locus 2 is represented as SEQ ID NO:297. The methods for detecting Brassica event LBFLFK also encompass detecting Brassica event LBFLFK Locus 1 and Locus 2 in a single assay. In this embodiment, the method comprises the steps of: (a) contacting the sample comprising DNA with a first probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 1 of Brassica event LBFLFK and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant and a second probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 2 of Brassica event LBFLFK and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probes to the Brassica event LBFLFK Locus 1 DNA and Locus 2 DNA, wherein said first probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:280 or the complement thereof and said second probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:289 or the complement thereof.
Another aspect of the invention is a method of determining zygosity of the progeny of Brassica event LBFLFK, the method comprising performing the steps above for detecting LBFLFK Locus 1 and LBFLFK Locus 2, and performing the additional steps of: (d) contacting the sample comprising Brassica DNA with an LBFLFK wild type primer pair comprising at least 1 1 nucleotides of the Brassica genomic region of the LBFLFK Locus 1 transgene insertion and and LBFLFK Locus 2 wild type primer pair comprising at least 1 1 consecutive nucleotides of the Brassica genomic region of the LBFLFK Locus 2 transgene insertion, that when used in a nucleic acid amplification reaction with genomic DNA from wild type Brassica plants corresponding to the LBFLFK Locus 1 and/or LBFLFK Locus 2 transgene insertion region(s), produces amplicons that
are diagnostic of the wild type Brassica genomic DNA homologous to the Brassica genomic region of the LBFLFK Locus 1 and Locus 2 transgene insertions; (e) performing a nucleic acid amplification reaction, thereby producing the second amplicon; (f) detecting the wild type Brassica amplicons; and (g) comparing the LBFLFK and wild type amplicons produced, wherein the presence of all amplicons indicates the sample is heterozygous for the transgene insertions. The zygosity detection method of the invention may employ any of the primers and probes described above which are specific for event LBFLFK Locus 1 and/or Locus 2. Exemplary primers for detection of wild type Brassica genomic DNA at the LBFLFK Locus 1 insertion site may be derived from SEQ ID NO:316 and SEQ ID NO:317, and suitable wild type Locus 1 probes may be designed from the wild type Brassica genomic sequence produced through amplification of SEQ ID NO:316 and SEQ ID NO:317. Exemplary primers for detection of wild type Brassica genomic DNA at the LBFLFK Locus 2 insertion site may be derived from SEQ ID NO:318 and SEQ ID NO:319, and suitable wild type Locus 2 probes may be designed from the wild type Brassica genomic sequence produced through amplification of SEQ ID NO:318 and SEQ ID NO:319.
Kits for the detection of Brassica event LBFLFK are provided which use primers designed from SEQ ID NO:280 and SEQ ID NO:289, or the complements thereof. An amplicon produced using said kit is diagnostic for LBFLFK when the amplicon (1 ) contains either nucleotide sequences set forth as SEQ ID NO:282, or SEQ ID NO:283, or complements thereof, and/or an amplicon comprising the Locus 2 junction region SEQ ID NO:291 , or SEQ ID NO:292, or complements thereof.
In accordance with the invention embodied in Brassica event LBFDAU, the LBFDAU Locus 1 genomic DNA/transgene junction region and/or the LBFDAU Locus 2 genomic DNA/transgene junction region is present in Brassica event LBFDAU (ATCC Accession No. PTA-122340) and progeny thereof. The LBFDAU Locus 1 DNA/transgene right border junction region comprises SEQ ID NO:300 and the LBFDAU Locus 1 left border junction region comprises SEQ ID NO:301 , and the LBFDAU Locus 2 right border junction region comprises SEQ ID NO:309 and the LBFDAU left border junction region comprises SEQ ID NO:310. DNA sequences are provided that comprise at least one junction region sequence of event LBFDAU selected from the group consisting of SEQ ID NO:300 (corresponding to positions 1008 through 1027 of SEQ ID NO:298, as shown in FIG. 95); SEQ ID NO:301 (corresponding to positions 44728 through 44747 of SEQ ID NO:298, as shown in FIG. 95); SEQ ID NO:309 (corresponding to positions 1090 through 1 109 of SEQ ID NO:307, as shown in FIG. 96); and SEQ ID NO:310 (corresponding to positions 38577 through 38596 of SEQ ID NO:307, as shown in FIG. 96) and complements thereof; wherein detection of these sequences in a biological sample containing Brassica DNA is diagnostic for the presence of Brassica event LBFDAU DNA in said sample. A Brassica event LBFDAU and Brassica seed comprising these DNA molecules is an aspect of this invention.
For example, to determine whether the Brassica plant resulting from a sexual cross contains transgenic DNA from event LBFDAU, DNA extracted from a Brassica plant tissue sample may be subjected to nucleic acid amplification method using (i) a first primer pair that includes: (a) a first primer derived from an LBFDAU Locus 1 flanking sequence and (b) a second primer derived from the LBFDAU Locus 1 inserted heterologous DNA, wherein amplification of the first and second
primers produces an amplicon that is diagnostic for the presence of event LBFDAU Locus 1 DNA; and/or (ii) a second primer pair that includes (a) a third primer derived from an LBFDAU Locus 2 flanking sequence and (b) a fourth primer derived from the LBFDAU Locus 2 inserted heterologous DNA, wherein amplification of the third and fourth primers produces an amplicon that is diagnostic for the presence of event LBFDAU Locus 2 DNA.
The primer DNA molecules specific for target sequences in Brassica event LBFDAU comprise 1 1 or more contiguous nucleotides of any portion of the insert DNAs, flanking regions, and/or junction regions of LBFDAU Locus 1 and Locus 2. For example, primer DNA molecules may be derived from any of SEQ ID NO:298, SEQ ID NO:299, SEQ ID NO:300, or SEQ ID NO:301 ;SEQ ID NO:302, or SEQ ID NO:303, or complements thereof, to detect LBFDAU Locus 1 . Similarly, primer DNA molecules may be derived from any of SEQ ID NO:307, SEQ ID NO:308, SEQ ID NO:309, or SEQ ID NO:310; SEQ ID NO:31 1 , or SEQ ID NO:312, or complements thereof, to detect LBFDAU Locus 2. Those of skill in the art may use these primers to design primer pairs to produce LBFDAU Locus 1 and Locus 2 amplicons using known DNA amplification methods The LBFDAU Locus 1 and Locus 2 amplicons produced using these DNA primers in the DNA amplification method is diagnostic for Brassica event LBFDAU when the amplification product contains an amplicon comprising the LBFDAU Locus 1 junction region SEQ ID NO:300 or SEQ ID NO:301 and/or an amplicon comprising the LBFDAU Locus 2 junction region SEQ ID NO:309, or SEQ ID NO:310. Any LBFDAU amplicon produced by DNA primers homologous or complementary to any portion of SEQ ID NO:298 or SEQ ID NO:307, or complements thereof, is an aspect of the invention. Any amplicon that comprises the LBFDAU Locus 1 junction region SEQ ID NO:300, or SEQ ID NO:301 , or complements thereof, and any amplicon comprising the LBFDAU Locus 2 junction region SEQ ID NO:309, or SEQ ID NO:310, or complements thereof, is an aspect of the invention.
According to another aspect of the invention, methods of detecting the presence of DNA corresponding to the Brassica event LBFDAU in a sample are provided. Such methods comprise: (a) contacting the sample comprising DNA with an LBFDAU Locus 1 primer pair and an LBFDAU Locus 2 primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFDAU, produces a Locus 1 amplicon and a Locus 2 amplicon that are diagnostic for Brassica event LBFDAU; (b) performing a nucleic acid amplification reaction, thereby producing the amplicons; and (c) detecting the amplicons, wherein one amplicon comprises the LBFDAU Locus 1 junction region SEQ ID NO:300 or SEQ ID NO:301 , or complements thereof, and one amplicon comprises the Locus 2 junction region SEQ ID NO:309 or SEQ ID NO:310, or complements thereof.
The method of detecting the presence of DNA corresponding to the Brassica event LBFDAU in a sample may alternatively comprise the steps of: (a) contacting the sample comprising DNA with a primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFDAU, produces a Locus 1 amplicon that is diagnostic for Brassica event LBFDAU; (b) performing a nucleic acid amplification reaction, thereby producing the amplicon;
and (c) detecting the amplicon, wherein the amplicon comprises the LBFDAU Locus 1 junction region SEQ ID NO:300 or SEQ ID NO:301 , or a complement thereof. The probe of SEQ ID NO:306 may be used to detect an LBFDAU Locus 1 amplicon.
The method of detecting the presence of DNA corresponding to the Brassica event LBFDAU in a sample may alternatively comprise the steps of: (a) contacting the sample comprising DNA with a primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFDAU, produces a Locus 2 amplicon that is diagnostic for Brassica event LBFDAU; (b) performing a nucleic acid amplification reaction, thereby producing the amplicon; and (c) detecting the amplicon, wherein the amplicon comprises the LBFDAU Locus 2 junction region SEQ ID NO:309 or SEQ ID NO:310, or a complement thereof. The probe of SEQ ID NO:315 may be used to detect an LBFDAU Locus 2 amplicon.
According to another aspect of the invention, methods are provided for detecting the presence of a DNA corresponding to LBFDAU event Locus 1 in a sample. In one embodiment, the method comprises the steps of: (a) contacting the sample comprising DNA with a probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 1 of Brassica event LBFDAU and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probe to the Brassica event LBFDAU DNA, wherein said probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:298, or the complement thereof. An exemplary probe for detecting LBFDAU Locus 1 is represented as SEQ ID NO:306.
The invention is also embodied in methods of detecting the presence of a DNA corresponding to LBFDAU event Locus 2 in a sample. In this embodiment, the method comprises the steps of: (a) contacting the sample comprising DNA with a probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 2 of Brassica event LBFDAU and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probe to the Brassica event LBFDAU DNA, wherein said probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:307, or the complement thereof. An exemplary probe for detecting LBFLFK Locus 2 is represented as SEQ ID NO:315.
The methods for detecting Brassica event LBFDAU also encompass detecting Brassica event LBFDAU Locus 1 and Locus 2 in a single assay. In this embodiment, the method comprises the steps of: (a) contacting the sample comprising DNA with a first probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 1 of Brassica event LBFDAU and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant and a second probe that hybridizes under stringent hybridization conditions with genomic DNA from Locus 2 of Brassica event LBFDAU and does not hybridize under the stringent hybridization conditions with genomic DNA from a control Brassica plant; (b) subjecting the sample and probe to stringent hybridization conditions; and (c) detecting hybridization of the probes to the Brassica event LBFDAU Locus 1 DNA and Locus 2 DNA, wherein said first probe
is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:298 or the complement thereof and said second probe is specific for a target sequence comprising 1 1 contiguous nucleotides of SEQ ID NO:307 or the complement thereof.
Another aspect of the invention is a method of determining zygosity of the progeny of Brassica event LBFDAU, the method comprising performing the steps above for detecting LBFDAU Locus 1 and LBFDAU Locus 2, and performing the additional steps of: (d) contacting the sample comprising Brassica DNA with an LBFDAU Locus 1 wild type primer pair comprising at least 1 1 consecutive nucleotides of the Brassica genomic region of the LBFDAU Locus 1 transgene insertion and an LBFDAU Locus 2 wild type primer pair comprising at least 1 1 consecutive nucleotides of the Brassica genomic region of the LBFDAU Locus 2 transgene insertion that when used in a nucleic acid amplification reaction with genomic DNA from wild type Brassica plants produces a second amplicon corresponding to the LBFDAU Locus 1 and/or LBFDAU Locus 2 transgene insertion region(s); (e) performing a nucleic acid amplification reaction, thereby producing the second amplicon and (f) detecting the Brassica wild type amplicons; and (g) comparing LBFDAU and wild type amplicons produced, wherein the presence of all amplicons indicates the sample is heterozygous for the transgene insertion. The zygosity detection method of the invention may employ any of the primers and probes described above which are specific for event LBFDAU Locus 1 and/or Locus 2. Exemplary primers for detection of wild type Brassica genomic DNA at the LBFDAU Locus 1 insertion site may be derived from SEQ ID NO:320 and SEQ ID NO:321 , or the complements thereof and suitable wild type Locus 1 probes may be designed from the wild type Brassica genomic sequence produced through amplification of SEQ ID NO:320 and SEQ ID NO:321 . Exemplary primers for detection of wild type Brassica genomic DNA at the LBFDAU Locus 2 insertion site may be derived from SEQ ID NO:322 and SEQ ID NO:323, and suitable wild type Locus 2 probes may be designed from the wild type Brassica genomic sequence produced through amplification of SEQ ID NO:322 and SEQ ID NO:323.
Kits for the detection of Brassica event LBFDAU are provided which use primers designed from SEQ ID NO:298 and SEQ ID NO:307, or the complements thereof. An amplicon produced using said kit is diagnostic for LBFDAU when the amplicon (1 ) contains either nucleotide sequences set forth as SEQ ID NO:300 or SEQ ID NO:301 , or the complements thereof, and an amplicon comprising the Locus 2 junction region SEQ ID NO:309 or SEQ ID NO:310, or the complements thereof.
Methods for preparing and using probes and primers are described, for example, in Molecular Cloning: A Laboratory Manual, 2nd ed., vol. 1 -3, ed. Sambrook et al., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., 1989 (hereinafter, "Sambrook et al., 1989"); Current Protocols in Molecular Biology, ed. Ausubel et al., Greene Publishing and Wiley-lnterscience, New York, 1992 (with periodic updates) (hereinafter, "Ausubel et al., 1992"); and Innis et al., PCR Protocols: A Guide to Methods and Applications, Academic Press: San Diego, 1990. PCR-primer pairs can be derived from a known sequence, for example, by using computer programs intended for that purpose such as Primer (Version 0.5, .COPYRGT. 1991 , Whitehead Institute for Biomedical Research, Cambridge, Mass.).
Primers and probes based on the flanking DNA and insert sequences disclosed herein can be used to confirm (and, if necessary, to correct) the disclosed sequences by conventional methods, e.g., by re-cloning and sequencing such sequences.
The nucleic acid probes and primers of the present invention hybridize under stringent conditions to a target DNA sequence. Any conventional nucleic acid hybridization or amplification method can be used to identify the presence of DNA from a transgenic event in a sample. Nucleic acid molecules or fragments thereof are capable of specifically hybridizing to other nucleic acid molecules under certain circumstances. As used herein, two nucleic acid molecules are said to be capable of specifically hybridizing to one another if the two molecules are capable of forming an anti-parallel, double-stranded nucleic acid structure. A nucleic acid molecule is said to be the "complement" of another nucleic acid molecule if they exhibit complete complementarity. As used herein, molecules are said to exhibit "complete complementarity" when every nucleotide of one of the molecules is complementary to a nucleotide of the other. Two molecules are said to be "minimally complementary" if they can hybridize to one another with sufficient stability to permit them to remain annealed to one another under at least conventional "low-stringency" conditions. Similarly, the molecules are said to be "complementary" if they can hybridize to one another with sufficient stability to permit them to remain annealed to one another under conventional "high- stringency" conditions. Conventional stringency conditions are described by Sambrook et al., 1989, and by Haymes et al., In: Nucleic Acid Hybridization, A Practical Approach, IRL Press, Washington, D.C. (1985). Departures from complete complementarity are therefore permissible, as long as such departures do not completely preclude the capacity of the molecules to form a double-stranded structure. In order for a nucleic acid molecule to serve as a primer or probe it need only be sufficiently complementary in sequence to be able to form a stable double-stranded structure under the particular solvent and salt concentrations employed. Regarding the amplification of a target nucleic acid sequence (e.g., by PCR) using a particular amplification primer pair, "stringent conditions" are conditions that permit the primer pair to hybridize only to the target nucleic-acid sequence to which a primer having the corresponding wild-type sequence (or its complement) would bind and preferably to produce a unique amplification product, the amplicon, in a DNA thermal amplification reaction. Nucleic-acid amplification can be accomplished by any of the various nucleic-acid amplification methods known in the art, including the polymerase chain reaction (PCR). A variety of amplification methods are known in the art and are described, inter alia, in U.S. Pat. Nos. 4,683,195 and 4,683,202 and in PCR Protocols: A Guide to Methods and Applications, ed. Innis et al., Academic Press, San Diego, 1990. PCR amplification methods have been developed to amplify up to 22 kb of genomic DNA and up to 42 kb of bacteriophage DNA (Cheng et al., Proc. Natl. Acad. Sci. USA 91 :5695-5699, 1994). These methods as well as other methods known in the art of DNA amplification may be used in the practice of the present invention. The sequence of the heterologous DNA insert or flanking sequence from a plant or seed tissue comprising Brassica event LBFLFK or Brassica event LBFDAU can be verified (and corrected if necessary) by amplifying such sequences from the event using primers derived from the sequences provided herein followed by standard DNA sequencing of the PCR amplicon or of the cloned DNA.
The amplicon produced by these methods may be detected by a plurality of techniques. One such method is Genetic Bit Analysis (e.g. Nikiforov, et al. Nucleic Acid Res. 22:4167-4175, 1994) where an DNA oligonucleotide is designed which overlaps both the adjacent flanking genomic DNA sequence and the inserted DNA sequence. The oligonucleotide is immobilized in wells of a microwell plate. Following PCR of the region of interest (using one primer in the inserted sequence and one in the adjacent flanking genomic sequence), a single-stranded PCR product can be hybridized to the immobilized oligonucleotide and serve as a template for a single base extension reaction using a DNA polymerase and labelled ddNTPs specific for the expected next base. Readout may be fluorescent or ELISA-based. A signal indicates presence of the insert/flanking sequence due to successful amplification, hybridization, and single base extension.
Another method is the Pyrosequencing technique as described by Winge (Innov. Pharma. Tech. 00:18-24, 2000). In this method an oligonucleotide is designed that overlaps the adjacent genomic DNA and insert DNA junction. The oligonucleotide is hybridized to single-stranded PCR product from the region of interest (one primer in the inserted sequence and one in the flanking genomic sequence) and incubated in the presence of a DNA polymerase, ATP, sulfurylase, luciferase, apyrase, adenosine 5' phosphosulfate and luciferin. dNTPs are added individually and the incorporation results in a light signal which is measured. A light signal indicates the presence of the transgene insert/flanking sequence due to successful amplification, hybridization, and single or multi-base extension. Fluorescence Polarization as described by Chen, et al., (Genome Res. 9:492-498, 1999) is a method that can be used to detect the amplicon of the present invention. Using this method an oligonucleotide is designed which overlaps the genomic flanking and inserted DNA junction. The oligonucleotide is hybridized to single-stranded PCR product from the region of interest (one primer in the inserted DNA and one in the flanking genomic DNA sequence) and incubated in the presence of a DNA polymerase and a fluorescent-labeled ddNTP. Single base extension results in incorporation of the ddNTP. Incorporation can be measured as a change in polarization using a fluorometer. A change in polarization indicates the presence of the transgene insert/flanking sequence due to successful amplification, hybridization, and single base extension.
TaqMan.RTM. (PE Applied Biosystems, Foster City, Calif.) is described as a method of detecting and quantifying the presence of a DNA sequence and is fully understood in the instructions provided by the manufacturer. Briefly, a FRET oligonucleotide probe is designed which overlaps the genomic flanking and insert DNA junction. The FRET probe and PCR primers (one primer in the insert DNA sequence and one in the flanking genomic sequence) are cycled in the presence of a thermostable polymerase and dNTPs. Hybridization of the FRET probe results in cleavage and release of the fluorescent moiety away from the quenching moiety on the FRET probe. A fluorescent signal indicates the presence of the flanking/transgene insert sequence due to successful amplification and hybridization.
Molecular Beacons have been described for use in sequence detection as described in Tyangi, et al. (Nature Biotech. 14:303-308, 1996) Briefly, a FRET oligonucleotide probe is designed that overlaps the flanking genomic and insert DNA junction. The unique structure of the FRET probe
results in it containing secondary structure that keeps the fluorescent and quenching moieties in close proximity. The FRET probe and PCR primers (one primer in the insert DNA sequence and one in the flanking genomic sequence) are cycled in the presence of a thermostable polymerase and dNTPs. Following successful PCR amplification, hybridization of the FRET probe to the target sequence results in the removal of the probe secondary structure and spatial separation of the fluorescent and quenching moieties that results in the production of a fluorescent signal. The fluorescent signal indicates the presence of the flanking/transgene insert sequence due to successful amplification and hybridization.
Other described methods, such as microfluidics (US Patent Pub. 2006068398, U.S. Pat. No. 6,544,734) provide methods and devices to separate and amplify DNA samples. Optical dyes are used to detect and quantitate specific DNA molecules (WO/05017181 ). Nanotube devices (WO/06024023) that comprise an electronic sensor for the detection of DNA molecules or nanobeads that bind specific DNA molecules and can then be detected.
Seed derived from Brassica event LBFLFK or Brassica event LBFDAU for sale for planting or for making commodity products is an aspect of the invention. Such commodity products include canola oil or meal containing VLC-PUFAs including but not limited to EPA and DHA. Commodity products derived from Brassica event LBFLFK comprise a detectable amount a DNA molecule comprising SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and/or SEQ ID NO:292. Commodity products derived from Brassica event LBFDAU comprise a detectable amount a DNA molecule comprising SEQ ID NO:300, SEQ ID NO:301 , SEQ ID NO:309, and/or SEQ ID NO:310. Exemplary commodity products derived from events LBFLFK and LBFDAU include, but are not limited to, cooking oil, salad oil, shortening, nutritionally enhanced foods, animal feed, pharmaceutical compositions, cosmetic compositions, hair care products, and the like.
The Examples for Section B herein below, Examples B1 to B4, are included to demonstrate examples of certain preferred embodiments of the invention. It should be appreciated by those of skill in the art that the techniques disclosed in the examples that follow represent approaches the inventors have found function well in the practice of the invention, and thus can be considered to constitute examples of preferred modes for its practice. However, those of skill in the art should, in light of the present disclosure, appreciate that many changes can be made in the specific embodiments that are disclosed and still obtain a like or similar result without departing from the spirit and scope of the invention.
Preferred embodiments of the invention described in Section B are given herein below. The explanations and embodiments described in this section preferably apply mutatis mutandis to the following:
1. A Brassica plant comprising SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and/or SEQ ID NO:292. 2. A Brassica seed comprising SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and/or SEQ ID NO:292.
3. A Brassica plant or seed comprising event LBFLFK, a sample of seed comprising transformation event LBFLFK having been deposited under ATCC Accession No. PTA-121703. 4. Progeny of the Brassica plant of Embodiment 3, wherein the progeny comprise SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , or SEQ ID NO:292.
5. an artificial dna molecule comprising a sequence selected from the group consisting of SEQ ID NO:282,SEQ ID NO:283, SEQ ID NO:291 , and SEQ ID NO:292.
6. A method of detecting the presence of DNA corresponding to the Brassica event LBFLFK in a sample comprising DNA, the method comprising the steps of:
(a) contacting the sample with an LBFLFK Locus 1 primer pair and an LBFLFK Locus 2 primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFLFK, produces a Locus 1 amplicon and a Locus 2 amplicon that are diagnostic for Brassica event LBFLFK;
(b) performing a nucleic acid amplification reaction, thereby producing the Locus 1 and Locus 2 amplicons; and
(c) detecting the amplicons, wherein one amplicon comprises the LBFLFK Locus 1 junction region SEQ ID NO:282 or SEQ ID NO:283, or the complement thereof, and one amplicon comprises the
LBFLFK Locus 2 junction region SEQ ID NO:291 or SEQ ID NO:292, or the complement thereof.
7. The method of Embodiment 6, wherein
(a) the LBFLFK Locus 1 primer pair comprises:
(i) a first primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:284, at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:284, at least 1 1 consecutive nucleotides of SEQ ID NO:285, and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:285; and
(ii); a second primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:281 and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:281 , and
(b) the LBFLFK Locus 2 primer pair comprises:
(i) a third primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:293 at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:293, at least 1 1 consecutive nucleotides of SEQ ID NO:294, and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:294; and
(ii) a fourth primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:290 and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:290. 8. The method of Embodiment 7, wherein the first primer comprises SEQ ID NO:286, the second primer comprises SEQ ID NO:287, the third primer comprises SEQ ID NO:295, and the fourth primer comprises SEQ ID NO:296.
9. The method of Embodiment 6, further comprising the steps of:
d) contacting the sample with an LBFLFK Locus 1 wild type primer pair comprising at least 1 1 consecutive nucleotides of the Brassica genomic region of the LBFLFK Locus 1 transgene insertion and an LBFLFK Locus 2 wild type primer pair comprising at least 1 1 consecutive nucleotides of the Brassica genomic region of the LBFLFK Locus 2 transgene insertion;
e) performing a nucleic acid amplification reaction, thereby producing amplicons of the homologous wild type Brassica genomic regions corresponding to LBFLFK Locus 1 and LBFLFK Locus 2 insertions;
f) detecting the wild type Brassica amplicons;
g) comparing the amplicons produced in step c) with the amplicons produced in step f), wherein the presence of both amplicons indicates that the sample is heterozygous for the LBFLFK Locus 1 and Locus 2 transgene insertions.
10. A kit for use in detecting Brassica event LBFLFK in a biological sample, wherein the kit employs a method comprising the steps of:
(a) contacting the sample with a DNA primer pair specific for LBFLFK Locus 1 and a DNA primer pair specific for LBFLFK Locus 2;
(b) performing a nucleic acid amplification reaction, thereby producing two amplicons; and
(c) detecting the amplicons, wherein the LBFLFK Locus 1 amplicon comprises SEQ ID NO:282 or SEQ ID NO:283, and the LBFLFK Locus 2 amplicon comprises SEQ ID NO:291 or SEQ ID
NO:292.
1 1. Oil or meal derived from Brassica seed of event LBFLFK or progeny thereof. 12. The oil or meal of Embodiment 1 1 , wherein the oil or meal comprises a detectable amount of a nucleotide sequence diagnostic for Brassica event LBFLFK wherein the sequence is selected from the group consisting of SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and SEQ ID NO:292. 13. A commodity product comprising a detectable amount of a Brassica event LBFLFK DNA sequence, wherein the sequence is selected from the group consisting of SEQ ID NO:282, SEQ ID NO:283, SEQ ID NO:291 , and SEQ ID NO:292.
14. A method for producing a Brassica plant comprising altered VLC-PUFA content, the method comprising the step of crossing a plant comprising Brassica event LBFLFK with a Brassica plant lacking event LBFLFK to obtain a plant comprising the Brassica event LBFLFK and altered VLC- PUFA content, wherein a sample of event LBFLFK has been deposited under ATCC Accession No. PTA-121703. 15. A method for producing a Brassica variety comprising Brassica event LBFLFK, comprising the step of crossing a plant comprising Brassica event LBFLFK with a second Brassica plant, wherein a sample of event LBFLFK has been deposited under ATCC Accession No. PTA-121703.
16. A Brassica plant comprising SEQ ID NO:300, SEQ ID NO:301 , SEQ ID NO:309, and/or SEQ ID NO:310.
17. A Brassica seed comprising SEQ ID NO:300, SEQ ID NO:301 , SEQ ID NO:309, and/or SEQ ID NO:310.
18. A Brassica plant or seed comprising event LBFDAU, a sample of seed comprising transformation event LBFDAU having been deposited under ATCC Accession No. PTA-122340. 19. Progeny of the Brassica plant of Embodiment 18, wherein the progeny comprise SEQ ID NO:300, SEQ ID NO:301 , SEQ ID NO:309, or SEQ ID NO: 310.
20. an artificial dna molecule comprising a sequence selected from the group consisting of SEQ ID NO:300, SEQ ID NO:301, SEQ ID NO:309, and SEQ ID NO:310.
21. A method of detecting the presence of DNA corresponding to the Brassica event LBFDAU in a sample comprising DNA, the method comprising the steps of:
(a) contacting the sample with an LBFDAU Locus 1 primer pair and an LBFDAU Locus 2 primer pair that, when used in a nucleic acid amplification reaction with genomic DNA from Brassica event LBFDAU, produces a Locus 1 amplicon and a Locus 2 amplicon that are diagnostic for Brassica event LBFLFK;
(b) performing a nucleic acid amplification reaction, thereby producing the Locus 1 and Locus 2 amplicons; and
(c) detecting the amplicons, wherein one amplicon comprises the LBFDAU Locus 1 junction region SEQ ID NO:300 or SEQ ID NO:301 and one amplicon comprises the LBFLFK Locus 2 junction region SEQ ID NO:309 or SEQ ID NO:310.
22. The method of Embodiment 21 , wherein
(a) the LBFLFK Locus 1 primer pair comprises:
(i) a first primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:302, at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:302, at least 1 1 consecutive nucleotides of SEQ ID NO:303, and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:303; and
(ii) ; a second primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:299 and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:299, and
(b) the LBFLFK Locus 2 primer pair comprises:
(i) a third primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:31 1 at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:31 1 , at least 1 1 consecutive nucleotides of SEQ ID NO:312, and comprising at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:312; and
(ii) a fourth primer selected from the group consisting of at least 1 1 consecutive nucleotides of SEQ ID NO:308 and at least 1 1 consecutive nucleotides of the complement of SEQ ID NO:308.
23. The method of Embodiment 22, wherein the first primer comprises SEQ ID NO:304, the second primer comprises SEQ ID NO:305, the third primer comprises SEQ ID NO:313, and the fourth primer comprises SEQ ID NO:314. 24. The method of Embodiment 21 , further comprising the steps of:
d) contacting the sample with an LBFDAU Locus 1 wild type primer pair comprising at least 1 1 consecutive nucleotides of the Brassica genomic region of the LBFDAU Locus 1 transgene insertion and an LBFDAU Locus 2 wild type primer pair comprising at least 1 1 consecutive nucleotides of the Brassica genomic region of the LBFDAU Locus 2 transgene insertion;
e) performing a nucleic acid amplification reaction, thereby producing amplicons of the homologous wild type Brassica genomic regions corresponding to LBFDAU Locus 1 and LBFDAU Locus 2 insertions;
f) detecting the wild type Brassica amplicons;
g) comparing the amplicons produced in step c) with the amplicons produced in step f), wherein the presence of both amplicons indicates that the sample is heterozygous for the LBFDAU Locus
1 and Locus 2 transgene insertions.
25. A kit for use in detecting Brassica event LBFDAU in a biological sample, wherein the kit employs a method comprising the steps of:
contacting the sample with a DNA primer pair specific for LBFDAU Locus 1 and a DNA primer pair specific for LBFDAU Locus 2;
performing a nucleic acid amplification reaction, thereby producing two amplicons; and detecting the amplicons, wherein the LBFDAU Locus 1 amplicon comprises SEQ ID NO:300 or SEQ ID NO:301 and the LBFDAU Locus 2 amplicon comprises SEQ ID NO:309 or SEQ ID NO:310.
26. Oil or meal derived from Brassica seed of event LBFDAU or progeny thereof.
27. The oil or meal of Embodiment 26, wherein the oil or meal comprises a detectable amount of a nucleotide sequence diagnostic for Brassica event LBFDAU wherein the sequence is selected from the group consisting of SEQ ID NO:300, SEQ ID NO:301 , SEQ ID NO:309, and SEQ ID NO:310.
28. A commodity product comprising a detectable amount of a Brassica event LBFDAU nucleotide sequence, wherein the sequence is selected from the group consisting of SEQ ID NO:300, SEQ
ID NO:301, SEQ ID NO:309, and SEQ ID NO:310.
29. A method for producing a Brassica plant comprising altered VLC-PUFA content, the method comprising the step of crossing a plant comprising Brassica event LBFDAU with a Brassica plant lacking event LBFDAU to obtain a plant comprising the Brassica event LBFDAU and altered VLC- PUFA content, wherein a sample of event LBFDAU has been deposited under ATCC Accession No. PTA-122340.
30. A method for producing a Brassica variety comprising Brassica event LBFDAU, comprising the step of crossing a plant comprising Brassica event LBFDAU with a second Brassica plant, wherein a sample of event LBFDAU has been deposited under ATCC Accession No. PTA- 122340.
The Examples for the invention described in Section B are the Examples B1 to B4 in the Examples section.
SECTION C: MATERIALS AND METHODS FOR INCREASING THE TOCOPHEROL CONTENT IN SEED OIL"
FIELD OF THE INVENTION (for the invention described in Section C)
The present invention relates generally to the field of molecular biology and concerns increasing the tocopherol content of a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase. The present invention also relates to methods for the manufacture of oil, fatty acid- or lipids-containing compositions, and to such oils and lipids as such.
BACKGROUND OF THE INVENTION (for the invention described in Section C)
Fatty acids are carboxylic acids with long-chain hydrocarbon side groups that play a fundamental role in many biological processes. Fatty acids are rarely found free in nature but, rather, occur in esterified form as the major component of lipids. As such, lipids/fatty acids are sources of energy (e.g., beta-oxidation). In addition, lipids/fatty acids are an integral part of cell membranes and, therefore, are indispensable for processing biological or biochemical information.
Very long chain polyunsaturated fatty acids (VLC-PUFAs) such as docosahexaenoic acid (DHA, 22:6(4,7,10,13,16,19)) are essential components of cell membranes of various tissues and organelles in mammals (e.g. nerve, retina, brain and immune cells). Clinical studies have shown that DHA is essential for the growth and development of the brain in infants, and for maintenance of normal brain function in adults (Martinetz, M. (1992) J. Pediatr. 120:S129 S138). DHA also has significant effects on photoreceptor function involved in the signal transduction process, rhodopsin activation, and rod and cone development (Giusto, N.M., et al. (2000) Prog. Lipid Res. 39:315-391 ). In addition, some positive effects of DHA were also found on diseases such as hypertension, arthritis, atherosclerosis, depression, thrombosis and cancers (Horrocks, L.A. and Yeo, Y.K. (1999) Pharmacol. Res. 40:21 1-215). Therefore, an appropriate dietary supply of DHA is important for human health. The human body is able to convert eicosapentaenoic acid (EPA, 20:5(5,8,1 1 ,14,17)) into DHA. EPA is normally found in marine food and is abundant in oily fish from the North Atlantic. In addition to serving as a precursor to DHA, EPA can also be converted into eicosanoids in the human body. The eicosanoids produced from EPA have anti-inflammatory and anti-platelet aggregating properties. A large number of beneficial health effects have been shown for DHA or mixtures of EPA and DHA.
Vitamin E (tocopherol) is a lipid soluble antioxidant that is important for preventing oxidative damage in both plants and animals and is known to have a beneficial effect in the prevention of cardiovascular disease. Vitamin E naturally occurs in vegetable oils, where it functions to prevent oxidative damage. Vegetable oils therefore represent a useful source of vitamin E in the human
diet. Additionally, vitamin E extracted from vegetable oils is used as an additive in other food, health supplement, and cosmetic products.
Up to now it has not been possible to correlate vitamin E concentration with any n-3 VLC-PUFA (i.e., EPA or DHA) component of oil. Vitamin E occurs in plants as various forms of tocopherol, including alpha-, beta-, gamma-, and delta. A study containing 52 landraces and 15 breeding lines of Brassica napus revealed a significant positive correlation between alpha-tocopherol and 18:1 +18:2, but no correlation between gamma-tocopherol and any fatty acid component (Li et al. (2013) J Agric Food Chem 61 :34-40). Tocopherol concentrations have not been correlated with the degree of unsaturation in various Brassica napus seeds with genetically altered fatty acid composition (Abidi et al (1999) J Am Oil Chem Soc 76, 463-467, and Dolde et al (1999) J Am Oil Chem Soc 76, 349-355).
There is thus the need to provide a reliable source for plants, in particular seeds, comprising tocopherol in preferably high concentrations.
SUMMARY OF THE INVENTION (for the invention described in Section C)
The invention is thus concerned with a method for increasing the tocopherol content of a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5- desaturase. In an embodiment, the method further comprises expressing in the plant at least one polynucleotide encoding an omega-3-desaturase.
In an embodiment, the method further comprises expressing in the plant at least one polynucleotide encoding a delta-5-elongase.
In an embodiment, the method further comprises expressing in the plant at least one polynucleotide encoding a delta-4-desaturase. Preferably, two or more polynucleotides encoding a delta-4-desaturase are expressed. More preferably, at least one polynucleotide encoding a Coenzyme A dependent delta-4-desaturase and at least one polynucleotide encoding a phospholipid dependent delta-4-desaturase.
Preferably, at least two of the further polynucleotides are expressed. Further, the present invention contemplates the expression of all three further polynucleotides. Thus, the method may further comprise expressing at least one polynucleotide encoding a delta-5-elongase, at least one polynucleotide encoding a delta-4-desaturase (preferably at least one polynucleotide for a Coenzyme A dependent delta-4 desaturase and at least one for a phospholipid dependent delta- 4 desaturase), and at least one polynucleotide encoding an omega-3 desaturase.
Moreover, the method of the present invention may further comprise expressing in the plant at least one polynucleotide encoding a delta-15-desaturase.
In an embodiment, at least one polynucleotide encoding a delta-6 elongase from Physcomitrella patens, at least one polynucleotide encoding a delta-12 desaturase from Phythophthora sojae, at least one polynucleotide encoding a delta-6 desaturase from Ostreococcus tauri, at least one polynucleotide encoding a delta-6 elongase from Thalassiosira pseudonana, at least one polynucleotide (preferably at least two polynucleotides) encoding a delta-5 desaturase from Thraustochytrium sp. (preferably from Thraustochytrium sp. ATCC21685), and optionally at least one polynucleotide (preferably, at least two polynucleotides) encoding a omega-3 desaturase from Pythium irregulare, at least one polynucleotide encoding a omega-3-desaturase from Phythophthora infestans, at least one polynucleotide encoding a delta-5 elongase from Ostreococcus tauri, and at least one polynucleotide encoding a delta-4 desaturase from Thraustochytrium sp., and at least one polynucleotide encoding a delta-4 desaturase from Pavlova lutheri are expressed. Preferably, at least two polynucleotides encoding a delta-5 desaturase from Thraustochytrium sp. (preferably from Thraustochytrium sp. ATCC21685) are expressed. Moreover, it is envisaged to express at least two polynucleotides encoding an omega- 3 desaturase from Pythium irregulare. As set forth elsewhere herein, also variants of the aforementioned polynucleotides can be expressed.
In accorandance with the method of the present invention, it is envisaged that at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6- desaturase, at least two polynucleotides encoding a delta-6-elongase, at least two polynucleotides encoding a delta-5-desaturase, and optionally at least three polynucleotides encoding an omega-3-desaturase, and at least one polynucleotide encoding a delta-5-elongase, and at least two polynucleotides encoding a delta-4-desaturase are expressed. Preferably, at least one polynucleotide encoding a Coenzyme A dependent delta-4-desaturase and at least one polynucleotide encoding a phospholipid dependent delta-4-desaturase are expressed. In an embodiment, the polynucleotides are expressed in the seeds of the plant.
In accordance with the present invention, the tocopherol content shall be preferably increased in the seeds of the plant as compared to the tocopherol content in seeds of a control plant, in particular the tocopherol content is increased in the seed oil of the plant as compared to the seed oil of a control plant.
Preferably, the polynucleotides encoding the elongases and desaturases referred to above are recombinant polynucleotides. They may be expressed in a plant by introducing them into the plant by recombinant means such as Agrobacterium-mediated transformation. Thus, the method may comprise the steps of introducing and expressing the above-referenced polynucleotides.
In one embodiment, the method may further comprise the step of selecting for plants having an increased tocopherol content (as compared to a control plant).
In accordance with the present invention, polynucleotides are referred to herein above present on one T-DNA or construct (and thus on the same T-DNA or construct). Said construct or T-DNA shall be is stably integrated in the genome of the plant. In an embodiment, the plant is homozygous for the T-DNA. In another embodiment, the plant is hemizygous for the T-DNA. If the plant is homozygous for one T-DNA at one locus, this is nevertheless considered as a single copy herein, i.e. as one copy. Double copy, as used herein, refers to a plant in which two T-DNAs have been inserted, at one or two loci, and in the hemizygous or homozygous state. The present invention also relates to a construct or T-DNA comprising expression cassettes for the polynucleotides as set forth in the context of method of the present invention for increasing the tocopherol content.
Preferably, the construct or T-DNA shall comprise expression cassettes for at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6- desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase, and optionally for at least one of the further polynucleotides encoding the desaturases or elongases referred to above. The present invention further concerns the use of the polynucleotides as set forth in the context of the present invention, or of a construct or T-DNA comprising expression cassettes for said polynucleotides for increasing the tocopherol content of a plant relative to control plants.
The present invention also relates to a plant comprising expression cassettes for the polynucleotides as referred to in the context of the method of the present invention for increasing the tocopherol content, or comprising the T-DNA or construct of the present invention.
The present invention also relates to a seed of the plant of the present invention. Said seed shall comprise expression cassettes for the polynucleotides as referred to in the context of the method of the present invention for increasing the tocopherol content, or comprising the T-DNA or construct of the present invention. In an embodiment, the seed shall comprise an oil of the present invention. The oil is described herein below.
Preferably, the method for increasing the tocopherol content comprises the further step of obtaining an oil from the plant, in particular from the seeds of the plant. Said oil shall have an increased tocopherol content as specified elsewhere herein. In addition, the oil shall have an increased content of VLC-PUFAs. In accordance with the present invention, the oil shall be obtained from the plant under conditions which maintain the tocopherol content. Such methods are well known in the art.
The invention also provides methods of producing an oil, wherein the oil has a high content of tocopherol. In addition, the oil may have a high VLC-PUFA content, in particular a high content of
EPA and/or DHA. In particularly preferred aspects these methods are for producing a corresponding plant oil. Thus, the invention also provides methods of producing an oil.
The invention also provides methods for creating a plant, such that the plant or progeny thereof can be used as a source of an oil having a high content of tocopherol. Preferably, the oil further has a high VLC-PUFA content, in particular a high content of EPA and/or DHA. Thus, the invention beneficially also provides methods for the production of plants having a heritable phenotype of high tocopherol content in seed oil. Further, the plants may have a hight VLC-PUFA content in one or more of their tissues or components, preferably a high content of EPA and/or DHA in seed oil.
DETAILED DESCRIPTION OF THE INVENTION (for the invention described in Section C)
Various aspects of the invention are hereinafter described in more detail. The definitions and explantions given in the previous section apply accordingly. It is to be understood that the detailed description is not intended to limit the scope of the claims.
Tocopherols are well known in the art. The term "content of tocopherol" preferably refers to the total tocopherol content, i.e. to the sum of the amounts of the tocopherols present in the plant, plant part (preferably in the seed) or oil (in particular in seed oil) thereof. In particular, the term refers to the sum of the amounts of alpha-tocopherol, beta-tocopherol, gamma-tocopherol, and delta-tocopherol. However, it is also envisaged that term refers to the amount of alpha-tocopherol, the amount of beta-tocopherol, andr to the amount of gamma-ocopherol, or the amount of delta- tocopherol. In a preferred embodiment, the term refers to the amount of gamma-tocopherol. In another preferred embodiment, the term term to the amount of delta-tocopherol. Also preferably, the term refers to the amount of total tocopherol, gamma-tocopherol and/or delta-tocopherol.
Thus, "tocopherol" in the context of the present invention, preferably, refers to total tocopherol, alpha-tocopherol, beta-tocopherol, gamma-tocopherol, and/or delta-tocopherol. In particular, the term refers to total tocopherol, gamma-tocopherol, or delta-tocopherol
The term "amount" or "content" preferably refers to the absolute amount or the concentration (preferably, in the plant, more preferably in the seed and most preferably in the seed oil). In an embomdiment, the content of tocopherol is increased in the seed oil of a plant as compared to the seed oil of a control plant.
Increasing the content of tocopherols refers to the increase of the content of tocopherols in a plant, or a part, tissue or organ thereof, preferably in the seed, in particular in the oil compared to a control plant by at least 1 %, at least 5%, at least 10%, at least 12% or at least 15%.
An "increased content" or "high content" of tocopherol as referred to herein preferably refers to a total content of tocopherol in seed oil of more than 97 mg/100 g seed oil, in particular of more than 100 mg/100 g seed oil, a content of alpha tocopherol in seed oil of more than 31 mg/100 g
seed oil, in particular of more than 33 mg/100 g seed oil, a content of beta tocopherol in seed oil of more than 0.6 mg/100 g seed oil, a content of gamma tocopherol in seed oil of more than 65 mg/100 g seed oil, in particular of more than 70 mg/100 g seed oil, or a content of delta tocopherol in seed oil of more than 1.4 mg/100 g seed oil, in particular of more than 1.5 mg/100 g seed oil.
Also, an "increased content" or "high content" of tocopherol as referred to herein preferably refers to a total seed content of tocopherol of more than 35 mg/100 g seed, in particular of more than 39 mg/100 g seed, a seed content of alpha tocopherol in seed of more than 12 mg/100 g seed, in particular of more than 13 mg/100 g seed, a seed content of beta tocopherol in seed of more than 0.22 mg/100 g seed, a seed content of gamma tocopherol in seed of more than 25 mg/100 g seed, in particular of more than 26 mg/100 g seed, or a seed content of delta tocopherol in seed of more than 0.45 mg/100 g seed, in particular of more than 0.48 mg/100 g seed.
The seeds, in particular the oil, may further comprise a high VLC-PUFA (very long chain polyunsaturated fatty acid) content.
The choice of suitable control plants is a routine part of an experimental setup and may include corresponding wild type plants or corresponding plants without the polynucleotides as encoding desaturases and elongase as referred to herein. The control plant is typically of the same plant species or even of the same variety as the plant to be assessed. The control plant may also be a nullizygote of the plant to be assessed. Nullizygotes (or null control plants) are individuals missing the transgene by segregation. Further, control plants are grown under the same or essentially the same growing conditions to the growing conditions of the plants of the invention, i.e. in the vicinity of, and simultaneously with, the plants of the invention. A "control plant" as used herein preferably refers not only to whole plants, but also to plant parts, including seeds and seed parts. The control could also be the oil from a control plant.
Preferably, the control plant is an isogenic control plant (thus, the control oil e.g. shall be from an isogenic control plant).
The term "polyunsaturated fatty acids (PUFA)" as used herein refers to fatty acids comprising at least two, preferably, three, four, five or six, double bonds. Moreover, it is to be understood that such fatty acids comprise, preferably from 18 to 24 carbon atoms in the fatty acid chain. More preferably, the term relates to long chain PUFA (VLC-PUFA) having from 20 to 24 carbon atoms in the fatty acid chain. Particularly, polyunsaturated fatty acids in the sense of the present invention are DHGLA 20:3 (8,1 1 ,14), ARA 20:4 (5,8,1 1 ,14), ETA 20:4 (8,1 1 ,14,17), EPA 20:5 (5,8,1 1 ,14,17), DPA 22:5 (4,7,10,13,16), DPA n-3 (7,10,13,16,19) DHA 22:6 (4,7,10,13,16,19), more preferably, eicosapentaenoic acid (EPA) 20:5 (5,8,1 1 ,14,17), and docosahexaenoic acid (DHA) 22:6 (4,7,10,13,16,19). Thus, it will be understood that most preferably, the methods provided by the present invention pertain to the manufacture of EPA and/or DHA and/or tocopherol. Moreover, also encompassed are the intermediates of VLC-PUFA which occur during synthesis. Such intermediates are, preferably, formed from substrates by the desaturase, keto- acyl-CoA-synthase, keto-acyl-CoA-reductase, dehydratase and enoyl-CoA-reductase activity of
the polypeptide of the present invention. Preferably, substrates encompass LA 18:2 (9,12), GLA 18:3 (6,9,12), DHGLA 20:3 (8,1 1 ,14), ARA 20:4 (5,8,1 1 ,14), eicosadienoic acid 20:2 (1 1 ,14), eicosatetraenoic acid 20:4 (8,1 1 ,14,17), eicosapentaenoic acid 20:5 (5,8,1 1 ,14,17). Systematic names of fatty acids including polyunsaturated fatty acids, their corresponding trivial names and shorthand notations used according to the present invention are given in the following table:

The term "cultivating" as used herein refers to maintaining and growing the transgenic plant under culture conditions which allow the cells to produce tocopherol in a plant, a seed comprising an increased tocopherol content or an oil comprising and increased tocopherol content (as compared to a control). This implies that the polynucleotides as referred to herein in connection with the
method of the present invention are present in the plant. Suitable culture conditions for cultivating the host cell are described in more detail below.
Preferably, the polynucleotides encoding the enzymes as referred to herein are stably integrated into the genome of the plant. More preferably, the polynucleotides are present on one T-DNA or construct which is stably integrated into the genome of the plant. Thus, they are preferably present on a single, i.e. the same T-DNA (or construct). The same applies to the expression cassettes as referred to herein. Accodingly, the polynucleotides or expression cassttes are preferably comprised by the same T-DNA.
It is to be understood that more than one copy of the T-DNA (or construct) may be present in the plant (e.g. in plants which are homozygous for the T-DNA (or construct), or in plants in which Agrobacterium mediated transformation resulted in more than one integration event. The term "obtaining" as used herein encompasses the provision of the cell culture including the host cells and the culture medium or the plant or plant part, particularly the seed, of the current invention, as well as the provision of purified or partially purified preparations thereof comprising the tococpherol The plant, plant part or purified or partially purified preparations may further comprise the polyunsaturated fatty acid, preferably, ARA, EPA, DHA, in free or in CoA bound form, as membrane phospholipids or as triacylglyceride esters. More preferably, the PUFA and VLC-PUFA are to be obtained as triglyceride esters, e.g., in the form of an oil. More details on purification techniques can be found elsewhere herein below.
The term "polynucleotide" according to the present invention refers to a desoxyribonucleic acid or ribonucleic acid. Unless stated otherwise, "polynucleotide" herein refers to a single strand of a DNA polynucleotide or to a double stranded DNA polynucleotide. The length of a polynucleotide is designated according to the invention by the specification of a number of basebairs ("bp") or nucleotides ("nt"). According to the invention, both specifications are used interchangeably, regardless whether or not the respective nucleic acid is a single or double stranded nucleic acid. Also, as polynucleotides are defined by their respective nucleotide sequence, the terms nucleotide/polynucleotide and nucleotide sequence/polynucleotide sequence are used interchangeably, thus that a reference to a nucleic acid sequence also is meant to define a nucleic acid comprising or consisting of a nucleic acid stretch, the sequence of which is identical to the nucleic acid sequence.
In particular, the term "polynucleotide" as used in accordance with the present invention as far as it relates to a desaturase or elongase gene relates to a polynucleotide comprising a nucleic acid sequence which encodes a polypeptide having desaturase or elongase activity. Preferred polynucleotides encoding polypeptides having desaturase or elongase activity as shown in Table C2 in the Examples section (the SEQ ID NOs of the nucleic acid sequences and the polypeptide sequences are given in the last two columns).
Preferably, the polypeptides encoded by the polynucleotides of the present invention having desaturase or elongase activity upon combined expression in a plant shall be capable of increasing the content, and thus the amount of tocopherol in a plant in particular, in seeds, seed oils or an entire plant or parts thereof. Whether an increase is statistically significant can be determined by statistical tests well known in the art including, e.g., Student's t-test with a confidentiality level of at least 90%, preferably of at least 95% and even more preferably of at least 98%. More preferably, the increase is an increase of the amount of tocopherol of at least 1 %, at least 5%, at least 10%, at least 12% or at least 15% (preferably, by weight) compared to a control, in particular to the content in seeds, seed oil, crude oil, or refined oil from a control.
In addition, the polypeptides having desaturase or elongase activity upon combined expression in a plant shall be capable of increasing the amount of PUFA and, in particular, VLC-PUFA in, e.g., seed oils or an entire plant or parts thereof. More preferably, the increase is an increase of the amount of triglycerides containing VLC-PUFA of at least 5%, at least 10%, at least 15%, at least 20% or at least 30% (preferably by weight) compared to wild-type control, in seeds, seed oil, crude oil, or refined oil from a wildtype control.
Thus, the present invention allows for producing an oil having not only an increased tocopherol content as compared to tocopherol content of oil of control plants but also an increased content of PUFA, in particular, of VLC-PUFA.
Preferably, the VLC-PUFA referred to before is a polyunsaturated fatty acid having a C20, C22 or C24 fatty acid body, more preferably EPA and/or DHA. Lipid analysis of oil samples are shown in the accompanying Examples.
The fatty acid esters with polyunsaturated C20- and/or C22-fatty acid molecules can be isolated in the form of an oil or lipid, for example, in the form of compounds such as sphingolipids, phosphoglycerides, lipids, glycolipids such as glycosphingolipids, phos-pholipids such as phosphatidylethanolamine, phosphatidylcholine, phosphatidylserine, phosphatidylglycerol, phosphatidylinositol or diphosphatidylglycerol, monoacylglycerides, diacylglycerides, triacylglycerides or other fatty acid esters such as the acetylcoenzyme A esters which comprise the polyunsaturated fatty acids with at least two, three, four, five or six, preferably five or six, double bonds, from the organisms which were used for the preparation of the fatty acid esters. Preferably, they are isolated in the form of their diacylglycerides, triacylglycerides and/or in the form of phosphatidylcholine, especially preferably in the form of the triacylglycerides. In addition to these esters, the polyunsaturated fatty acids are also present in the non-human transgenic organisms or host cells, preferably in the plants, as free fatty acids or bound in other compounds. The fatty acids are, preferably, produced in bound form. It is possible, with the aid of the polynucleotides and polypeptides of the present invention, for these unsaturated fatty acids to be positioned at the sn1 , sn2 and/or sn3 position of the triglycerides which are, preferably, to be produced.
The desaturares and elongases referred to herein are well known in the art.
The term "desaturase" encompasses all enzymatic activities and enzymes catalyzing the desaturation of fatty acids with different lengths and numbers of unsaturated carbon atom double bonds. Specifically this includes delta 4 (d4)-desaturase, preferably catalyzing the dehydrogenation of the 4th and 5th carbon atom; Delta 5 (d5)-desaturase catalyzing the dehydrogenation of the 5th and 6th carbon atom; Delta 6 (d6)-desaturase catalyzing the dehydrogenation of the 6th and 7th carbon atom; Delta 15 (d15)-desaturase catalyzing the dehydrogenation of the 15th and 16th carbon atom. An omega 3 (o3) desaturase preferably catalyzes the dehydrogenation of the n-3 and n-2 carbon atom.
The terms "elongase" encompasses all enzymatic activities and enzymes catalyzing the elongation of fatty acids with different lengths and numbers of unsaturated carbon atom double bonds. Preferably, the term "elongase" as used herein refers to the activity of an elongase, introducing two carbon molecules into the carbon chain of a fatty acid, preferably in the positions 1 , 5, 6, 9, 12 and/or 15 of fatty acids.
In a preferred embodiment, the term "elongase" shall refer to the activity of an elongase, introducing two carbon molecules to the carboxyl ends {i.e. position 1 ) of both saturated and unsaturated fatty acids.
In the studies underlying this invention, enzymes with superior desaturase and elongase catalytic activities for the increasing the content of tocopherol has been provided. Table C2 in the Examples section lists preferred polynucleotides encoding for preferred desaturases or elongase to be used in the present invention. Thus, polynucleotides desaturases or elongases that can be used in the context of the present invention are shown in Table C2. As set forth elsewhere herein, also variants of the said polynucleotides can be used.
Polynucleotides encoding polypeptides which exhibit delta-6-elongase activity have been described in WO2001/059128, WO2004/087902 and WO2005/012316, said documents, describing this enzyme from Physcomitrella patens, are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit delta-5-desaturase activity have been described in WO2002026946 and WO2003/093482, said documents, describing this enzyme from Thraustochytrium sp., are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit delta-6-desaturase activity have been described in WO2005/012316, WO2005/083093, WO2006/008099 and WO2006/069710, said documents, describing this enzyme from Ostreococcus tauri, are incorporated herein in their entirety.
In an embodiment, the delta-6-desaturase is a CoA (Coenzyme A)-dependent delta-6- desaturase.
Polynucleotides encoding polypeptides which exhibit delta-6-elongase activity have been described in WO2005/012316, WO2005/007845 and WO2006/069710, said documents, describing this enzyme from Thalassiosira pseudonana, are incorporated herein in their entirety. Polynucleotides encoding polypeptides which exhibit delta-12-desaturase activity have been described for example in WO2006100241 , said documents, describing this enzyme from Phytophthora sojae, are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit delta-4-desaturase activity have been described for example in WO2004/090123, said documents, describing this enzyme from Euglena gracilis, are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit delta-5-elongase activity have been described for example in WO2005/012316 and WO2007/096387, said documents, describing this enzyme from Ostreococcus tauri, are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit omega 3-desaturase activity have been described for example in WO2008/022963, said documents, describing this enzyme from Pythium irregulare, are incorporated herein in their entirety.
Polynucleotides encoding polypeptides which exhibit omega 3-desaturase activity have been described for example in WO2005012316 and WO2005083053, said documents, describing this enzyme from Phytophthora infestans, are incorporated herein in their entirety. Polynucleotides encoding polypeptides which exhibit delta-4-desaturase activity have been described for example in WO2002026946, said documents, describing this enzyme from Thraustochytrium sp., are incorporated herein in their entirety.
Polynucleotides coding for a delta-4 desaturase from Pavlova lutheri are described in WO2003078639 and WO2005007845. These documents are incorporated herein in their entirety, particularly insofar as the documents relate to the delta-4 desaturase "PIDES 1 "and figures 3a- 3d of WO2003078639 and figures 3a, 3b of WO2005007845, respectively.
Polynucleotides encoding polypeptides which exhibit delta-15-desaturase activity have been described for example in WO2010/066703, said documents, describing this enzyme from Cochliobolus heterostrophus C5, are incorporated herein in their entirety.
The polynucleotides encoding the aforementioned polypeptides are herein also referred to as "target genes" or "nucleic acid of interest". The polynucleotides are well known in the art. The sequences of said polynucleotides can be found in the sequence of the T-DNA disclosed in the Examples section (see e.g. the sequence of VC-LTM593-1 qcz which has a sequence as shown in SEQ ID NO: 3, see also Table C1 ). The polynucleotide and polypeptide sequences are also given in Table C2 in the Examples section.
Sequences of preferred polynucleotides for the desaturases and elongases referred to herein in connection with the present invention are indicated below. As set forth elsewhere herein, also variants of the polynucleotides can be used. The polynucleotides encoding for desaturases and elogases to be used in accordance with the present invention can be derived from certain organisms. Preferably, a polynucleotide derived from an organism (e.g from Physcomitrella patens) is codon-optimized. In particular, the polynucleotide shall be codon-optimized for expression in a plant.
The term "codon-optimized" is well understood by the skilled person. Preferably, a codon optimized polynucleotide is a polynucleotide which is modified by comparison with the nucleic acid sequence in the organism from which the sequence originates in that it is adapted to the codon usage in one or more plant species. Typically, the polynucleotide, in particular the coding region, is adapted for expression in a given organism (in particular in a plant) by replacing at least one, or more than one of codons with one or more codons that are more frequently used in the genes of that organism (in particular of the plant). In accordance with the present invention, a codon optimized variant of a particular polynucleotide "from an organism" (or "derived from an organism") preferably shall be considered to be a polynucleotide derived from said organism. Preferalby, a codon-optimized polynucleotide shall encode for the same polypeptide having the same sequence as the polypeptide encoded by the non codon-optimized polynucleotide (i.e. the wild-type sequence). In the studies underlying the present invention, codon optimized polynucleotides were used (for the desaturases). The codon optimized polynucleotides are comprised by the T-DNA of the vector having a sequence as shown in SEQ ID NO: 3 (see Table C1 ).
The sequences of preferred polynucleotides for the desaturases and elongases and the sequences corresponding polypeptides referred to herein in connection with the present invention are described herein below. Of course variants of polynucleotides and polynucleotides can be used in connection with the present invention (in particular in connection with the methods, T- DNAs, constructs, plants, seeds, etc.).
Preferably, a delta-6-elongase to be used in accordance with the present invention is derived from Physcomitrella patens. A preferred sequence of said delta-6-elongase is shown in SEQ ID NO:258. Preferably, said delta-6-elongase is encoded by a polynucleotide derived from Physcomitrella patens, in particular, said delta-6-elongase is encoded by a codon-optimized variant thereof. Preferably, the polynucleotide encoding the delta-6-elongase derived from Physcomitrella patens is a polynucleotide having a sequence as shown in nucleotides 1267 to 2139 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 257. Preferably, a delta-5-desaturase to be used in accordance with the present invention is derived from Thraustochytrium sp.. Thraustochytrium sp. in the context of the present invention preferably means Thraustochytrium sp. ATCC21685. A preferred sequence of said delta-5-desaturase is shown in SEQ ID NO:260. Preferably, said delta-5-desaturase is encoded by a polynucleotide
derived from Thraustochytrium sp.; in particular, said delta-5-desaturase is encoded by a codon- optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-5- desaturase derived from Thraustochytrium sp. is a polynucleotide having a sequence as shown in nucleotides 3892 to 521 1 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 259. In accordance with the present invention, it is envisaged to express two or more polynucleotides (i.e. two or more copies of a polynucleotide) encoding a delta-5-desaturase derived from Thraustochytrium sp. (preferably two polynucleotides). Thus, the T-DNA, construct, plant, seed etc. of the present invention shall comprise two (or more) copies of a polynucleotide encoding a delta-5-desaturase derived from Thraustochytrium sp..
Preferably, a delta-6-desaturase to be used in accordance with the present invention is derived from Ostreococcus tauri. A preferred sequence of said delta-6-desaturase is shown in SEQ ID NO:262. Preferably, said delta-6-desaturase is encoded by a polynucleotide derived from Ostreococcus tauri; in particular, said delta-6-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-6-desaturase derived from Ostreococcus tauri is a polynucleotide having a sequence as shown in nucleotides 7802 to 9172 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 261.
Preferably, a delta-6-elongase to be used in accordance with the present invention is derived from Thalassiosira pseudonana. A preferred sequence of said delta-6-elongase is shown in SEQ ID NO:264. Preferably, said delta-6-elongase is encoded by a polynucleotide derived from Thalassiosira pseudonana; in particular, said delta-6-elongase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-6-elongase derived from Thalassiosira pseudonana is a polynucleotide having a sequence as shown in nucleotides 12099 to 12917 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 263. (Thus, the polynucleotide encoding the delta-6-elongase derived from Thalassiosira pseudonana preferably has a sequence as shown in SEQ ID NO: 263)
Preferably, a delta-12-elongase to be used in accordance with the present invention is derived from Phytophthora sojae. A preferred sequence of said delta-12-elongase is shown in SEQ ID NO:266. Preferably, said delta-12-elongase is encoded by a polynucleotide derived from Phytophthora sojae; in particular, said delta-12-elongase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-12-elongase derived from Phytophthora sojae is a polynucleotide having a sequence as shown in nucleotides 14589 to 15785 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 265.
Preferably, a delta-5-elongase to be used in accordance with the present invention is derived from Ostreococcus tauri. A preferred sequence of said delta-5-elongase is shown in SEQ ID NO:276. Preferably, said delta-5-elongase is encoded by a polynucleotide derived from Ostreococcus tauri; in particular, said delta-5-elongase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-5-elongase derived from Ostreococcus tauri is a polynucleotide having a sequence as shown in nucleotides 38388 to 39290 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 275.
Preferably, an omega 3-desaturase to be used in accordance with the present invention is derived from Pythium irregulare. A preferred sequence of said omega 3-desaturase is shown in SEQ ID NO:268. Preferably, said omega 3-desaturase is encoded by a polynucleotide derived from Pythium irregulare; in particular, said omega 3-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the omega 3-desaturase derived from Pythium irregulare is a polynucleotide having a sequence as shown in nucleotides 17690 to 18781 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 267. In accordance with the present invention, it is envisaged to express two or more polynucleotides (i.e. two or more copies of a polynucleotide) encoding a omega 3-desaturase derived from Pythium irregulare (preferably two polynucleotides). Thus, the T-DNA, construct, plant, seed etc. of the present invention shall comprise two (or more) copies of a polynucleotide encoding a omega 3-desaturase derived from Pythium irregulare
Preferably, an omega 3-desaturase to be used in accordance with the present invention is derived from Phytophthora infestans. A preferred sequence of said omega 3-desaturase is shown in SEQ ID NO:270. Preferably, said omega 3-desaturase is encoded by a polynucleotide derived from Phytophthora infestans; in particular, said omega 3-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the omega 3-desaturase derived from Phytophthora infestans is a polynucleotide having a sequence as shown in nucleotides 20441 to 21526 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 269.
In accordance with the method of the present invention, it is in particular envisaged to express two or more polynucleotides encoding, preferably omega 3-desaturases in the plant. Preferably, at least one polynucleotide encoding an omega 3-desaturase from Phytophthora infestans and at least one polynucleotide (in particular two polynucleotides, i.e. two copies of a polynucleotide) encoding an omega 3-desaturase from Pythium irregulare are expressed.
Preferably, a delta-4-desaturase to be used in accordance with the present invention is derived from Thraustochytrium sp.. A preferred sequence of said delta-4-desaturase is shown in SEQ ID NO:272. Preferably, said delta-4-desaturase is encoded by a polynucleotide derived from Thraustochytrium sp.; in particular, said delta-4-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-4-desaturase derived from Thraustochytrium sp. is a polynucleotide having a sequence as shown in nucleotides 26384 to 27943 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 271 .
Preferably, a delta-4-desaturase to be used in accordance with the present invention is derived from Pavlova lutheri. A preferred sequence of said delta-4-desaturase is shown in SEQ ID NO:274. Preferably, said delta-4-desaturase is encoded by a polynucleotide derived from Pavlova lutheri; in particular, said delta-4-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-4-desaturase derived from
Pavlova lutheri is a polynucleotide having a sequence as shown in nucleotides 34360 to 35697 of SEQ ID NO: 3. The sequence of this polynucleotide is also shown in SEQ ID No: 273.
In accordance with the method of the present invention, it is further envisaged to express two non-identical polynucleotides encoding, preferably non-identical delta-4-desaturases in the plant. Preferably, at least one polynucleotide encoding a delta-4-desaturase from Thraustochytrium sp. and at least one polynucleotide (in particular two polynucleotides) encoding a delta-4-desaturase from Pavlova lutheri are expressed. Preferably, a delta-15-desaturase to be used in accordance with the present invention is derived from Cochliobolus heterostrophus. Preferably, said delta-15-desaturase is encoded by a polynucleotide derived from Cochliobolus heterostrophus; in particular, said delta-15-desaturase is encoded by a codon-optimized variant of said polynucleotide. Preferably, the polynucleotide encoding the delta-15-desaturase derived from Cochliobolus heterostrophus is a polynucleotide having a sequence as shown in nucleotides 2151 to 3654 of SEQ ID NO: 9.
As set forth above, the polynucleotide encoding a delta-6-elongase can be derived from Physcomitrella patens. Moreover, the polynucleotide encoding a delta-6-elongase can be derived from Thalassiosira pseudonana. In particular, it is envisaged in the context of the method of the present invention to express at least one polynucleotide encoding a delta-6-elongase from Physcomitrella patens and at least one polynucleotide encoding a delta-6-elongase from Thalassiosira pseudonana in the plant.
A polynucleotide encoding a polypeptide having a desaturase or elongase activity as specified above is obtainable or obtained in accordance with the present invention for example from an organism of genus Ostreococcus, Thraustochytrium, Euglena, Thalassiosira, Phytophthora, Pythium, Cochliobolus, Physcomitrella. However, orthologs, paralogs or other homologs may be identified from other species. Preferably, they are obtained from plants such as algae, for example Isochrysis, Mantoniella, Crypthecodinium, algae/diatoms such as Phaeodactylum, mosses such as Ceratodon, or higher plants such as the Primulaceae such as Aleuritia, Calendula stellata, Osteospermum spinescens or Osteospermum hyoseroides, microorganisms such as fungi, such as Aspergillus, Entomophthora, Mucor or Mortierella, bacteria such as Shewanella, yeasts or animals. Preferred animals are nematodes such as Caenorhabditis, insects or vertebrates. Among the vertebrates, the nucleic acid molecules may, preferably, be derived from Euteleostomi, Actinopterygii; Neopterygii; Teleostei; Euteleostei, Protacanthopterygii, Salmoniformes; Salmonidae or Oncorhynchus, more preferably, from the order of the Salmoniformes, most preferably, the family of the Salmonidae, such as the genus Salmo, for example from the genera and species Oncorhynchus mykiss, Trutta trutta or Salmo trutta fario. Moreover, the nucleic acid molecules may be obtained from the diatoms such as the genera Thalassiosira or Phaeodactylum.
Thus, the term "polynucleotide" as used in accordance with the present invention further encompasses variants or derivatives of the aforementioned specific polynucleotides representing
orthologs, paralogs or other homologs of the polynucleotide of the present invention. Moreover, variants or derivatives of the polynucleotide of the present invention also include artificially generated muteins. Said muteins include, e.g., enzymes which are generated by mutagenesis techniques and which exhibit improved or altered substrate specificity, or codon optimized polynucleotides.
Nucleic acid variants or derivatives according to the invention are polynucleotides which differ from a given reference polynucleotide by at least one nucleotide substitution, addition and/or deletion. If the reference polynucleotide codes for a protein, the function of this protein is conserved in the variant or derivative polynucleotide, such that a variant nucleic acid sequence shall still encode a polypeptide having a desaturase or elongase activity as specified above. Variants or derivatives also encompass polynucleotides comprising a nucleic acid sequence which is capable of hybridizing to the aforementioned specific nucleic acid sequences, preferably, under stringent hybridization conditions. These stringent conditions are known to the skilled in the art and can be found in Current Protocols in Molecular Biology, John Wiley & Sons, N. Y. (1989), 6.3.1-6.3.6. A preferred example for stringent hybridization conditions are hybridization conditions in 6x sodium chloride/sodium citrate (= SSC) at approximately 45°C, followed by one or more wash steps in 0.2 xSSC, 0.1 % SDS at 50 to 65°C (in particular at 65°C). The skilled worker knows that these hybridization conditions differ depending on the type of nucleic acid and, for example when organic solvents are present, with regard to the temperature and concentration of the buffer. For example, under "standard hybridization conditions" the temperature ranges depending on the type of nucleic acid, between 42°C and 58°C in aqueous buffer, with a concentration of 0.1 to 5X SSC (pH 7.2). If organic solvent is present in the abovementioned buffer, for example 50% formamide, the temperature under standard conditions is approximately 42°C. The hybridization conditions for DNA: DNA hybrids are, preferably, 0.1 X SSC and 20°C to 45°C, preferably between 30°C and 45°C. The hybridization conditions for DNA:RNA hybrids are, preferably, 0.1X SSC and 30°C to 55°C, preferably between 45°C and 55°C. The abovementioned hybridization temperatures are determined for example for a nucleic acid with approximately 100 bp (= base pairs) in length and a G + C content of 50% in the absence of formamide. The skilled worker knows how to determine the hybridization conditions required by referring to textbooks such as the textbook mentioned above, or the following textbooks: Sambrook et al., "Molecular Cloning", Cold Spring Harbor Laboratory, 1989; Hames and Higgins (Ed.) 1985, "Nucleic Acids Hybridization: A Practical Approach", IRL Press at Oxford University Press, Oxford; Brown (Ed.) 1991 , "Essential Molecular Biology: A Practical Approach", IRL Press at Oxford University Press, Oxford. In an embodiment, stringent hybridization conditions encompass hybridization at 65°C in 1x SSC, or at 42°C in 1 x SSC and 50% formamide, followed by washing at 65°C in 0.3x SSC. In another embodiment, stringent hybridization conditions encompass hybridization at 65°C in 1 x SSC, or at 42°C in 1 x SSC and 50% formamide, followed by washing at 65°C in 0.1 x SSC. Alternatively, polynucleotide variants are obtainable by PCR-based techniques such as mixed oligonucleotide primer based amplification of DNA, i.e. using degenerated primers against conserved domains of the polypeptides of the present invention. Conserved domains of the polypeptide of the present invention may be identified by a sequence comparison of the nucleic
acid sequences of the polynucleotides or the amino acid sequences of the polypeptides of the present invention. As a template, DNA or cDNA from bacteria, fungi, plants, or animals may be used. Further, variants include polynucleotides comprising nucleic acid sequences which are at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 98% or at least 99% identical to the nucleic acid coding sequences shown in any one of the T-DNA sequences given in Table C1 of the Examples, and in particular to polynucleotides encoding the desaturases or elongases referred to above, in particular the elongases and desaturases given in Table C2. E.g., polynucleotides are envisaged which are at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 98% or at least 99% identical to the polynucleotide encoding the delta-4-desaturase from Thraustochytrium sp (and thus to a polynucleotide having sequence as shown in nucleotides 26384 to 27943 of SEQ ID NO: 3). Of course, a variant as referred to herein must retain the function of the respective enzyme, e.g. a variant of a delta-4-desaturase must retain delta-4-desaturase activity, or a variant of a delta-12- desaturase must retain delta-12-desaturase activity.
The percent identity values are, preferably, calculated over the entire amino acid or nucleic acid sequence region. A series of programs based on a variety of algorithms is available to the skilled worker for comparing different sequences. In a preferred embodiment, the percent identity between two amino acid sequences is determined using the Needleman and Wunsch algorithm (Needleman 1970, J. Mol. Biol. (48):444-453) which has been incorporated into the needle program in the EMBOSS software package (EMBOSS: The European Molecular Biology Open Software Suite, Rice.P., LongdenJ., and BleasbyA Trends in Genetics 16(6), 276-277, 2000), a BLOSUM62 scoring matrix, and a gap opening penalty of 10 and a gap extension pentalty of 0.5. Guides for local installation of the EMBOSS package as well as links to WEB-Services can be found at http://emboss.sourceforge.net. A preferred, non-limiting example of parameters to be used for aligning two amino acid sequences using the needle program are the default parameters, including the EBLOSUM62 scoring matrix, a gap opening penalty of 10 and a gap extension penalty of 0.5. In yet another preferred embodiment, the percent identity between two nucleotide sequences is determined using the needle program in the EMBOSS software package (EMBOSS: The European Molecular Biology Open Software Suite, Rice, P., LongdenJ., and BleasbyA Trends in Genetics 16(6), 276-277, 2000), using the EDNAFULL scoring matrix and a gap opening penalty of 10 and a gap extension penalty of 0.5. A preferred, non-limiting example of parameters to be used in conjunction for aligning two nucleic acid sequences using the needle program are the default parameters, including the EDNAFULL scoring matrix, a gap opening penalty of 10 and a gap extension penalty of 0.5. The nucleic acid and protein sequences of the present invention can further be used as a "query sequence" to perform a search against public databases to, for example, identify other family members or related sequences. Such searches can be performed using the BLAST series of programs (version 2.2) of Altschul et al. (Altschul 1990, J. Mol. Biol. 215:403-10). BLAST using desaturase and elongase nucleic acid sequences of the invention as query sequence can be performed with the BLASTn, BLASTx or the tBLASTx program using default parameters to obtain either nucleotide sequences (BLASTn, tBLASTx) or amino acid sequences (BLASTx) homologous to desaturase and elongase sequences of the
invention. BLAST using desaturase and elongase protein sequences of the invention as query sequence can be performed with the BLASTp or the tBLASTn program using default parameters to obtain either amino acid sequences (BLASTp) or nucleic acid sequences (tBLASTn) homologous to desaturase and elongase sequences of the invention. To obtain gapped alignments for comparison purposes, Gapped BLAST using default parameters can be utilized as described in Altschul et al. (Altschul 1997, Nucleic Acids Res. 25(17):3389-3402).
Preferred variants of the polynucleotides having a sequence shown in SEQ ID NO: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275 are described herein below.
Preferably, a variant of a polynucleotide encoding a desaturase or elongase as referred to herein is, preferably, a polynucleotide comprising a nucleic acid sequence selected from the group consisting of:
a) a nucleic acid sequence being at least 70%, 80%, or 90% identical to the nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
b) a nucleic acid sequence encoding a polypeptide which is at least 70%, 80, or 90% identical to a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276, and
c) a nucleic acid sequence which is capable of hybridizing under stringent conditions to i) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275, or to ii) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276.
As set forth above, the polypeptide encoded by said nucleic acid must retain the function and thus the activity of the respective enzyme. For example, the polypeptide having a sequence as shown in SEQ ID NO: 270 has omega-3-desaturase activity. Accordingly, the variant this polypeptide also shall have omega-3-desaturase activity.
Thus, a polynucleotide encoding a desaturase or elongase as referred to herein is, preferably, a polynucleotide comprising a nucleic acid sequence selected from the group consisting of:
a) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NO: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
b) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NO: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276
c) a nucleic acid sequence being at least 70%, 80%, or 90% identical to the nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275,
d) a nucleic acid sequence encoding a polypeptide which is at least 70%, 80, or 90% identical to a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276, and
e) a nucleic acid sequence which is capable of hybridizing under stringent conditions to i) a nucleic acid sequence having a nucleotide sequence as shown in SEQ ID NOs: 257, 259, 261 , 263, 265, 267, 269, 271 , 273, or 275, or to ii) a nucleic acid sequence encoding a polypeptide having an amino acid sequence as shown in SEQ ID NOs: 258, 260, 262, 264, 266, 268, 270, 272, 274, or 276.
The event LBFLFK comprises two T-DNA insertions, the insertions being designated LBFLFK Locus 1 and LBFLFK Locus 2. Plants comprising this insertion were generated by transformation with the T-DNA vector having a sequence as shown in SEQ ID NO: 3. Sequencing of the insertions present in the plant revealed that each locus contained a point mutation in a coding sequence resulting in a single amino acid exchange. The mutations did not affect the function of the genes. Locus 1 has a point mutation in the coding sequence for the delta-12 desaturase from Phythophthora sojae (d12Des(Ps)). The resulting polynucleotide has a sequence as shown in SEQ ID NO: 324. Said polynucleotide encodes a polypeptide having a sequence as shown in SEQ ID NO: 325. Locus 2 has a point mutation in the coding sequence for the delta-4 desaturase from Pavlova lutheri (d4Des(PI)). The resulting polynucleotide has a sequence as shown in SEQ ID NO: 326. Said polynucleotide encodes a polypeptide having a sequence as shown in SEQ ID NO: 327. The aforementioned polynucleotides are considered as variants of the polynucleotide encoding the delta-12 desaturase from Phythophthora sojae and the polynucleotide encoding the delta-4 desaturase from Pavlova lutheri. The polynucleotides are considered as variants and can be used in the context of the present invention.
A polynucleotide comprising a fragment of any nucleic acid, particularly of any of the aforementioned nucleic acid sequences, is also encompassed as a polynucleotide of the present invention. The fragments shall encode polypeptides which still have desaturase or elongase activity as specified above. Accordingly, the polypeptide may comprise or consist of the domains of the polypeptide of the present invention conferring the said biological activity. A fragment as meant herein, preferably, comprises at least 50, at least 100, at least 250 or at least 500 consecutive nucleotides of any one of the aforementioned nucleic acid sequences or encodes an amino acid sequence comprising at least 20, at least 30, at least 50, at least 80, at least 100 or at least 150 consecutive amino acids of any one of the aforementioned amino acid sequences.
The variant polynucleotides or fragments referred to above, preferably, encode polypeptides retaining desaturase or elongase activity to a significant extent, preferably, at least 10%, at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 80% or at least 90% of the desaturase or elongase activity exhibited by any of the polypeptides encoded by T- DNA given in the accompanying Examples (in particular of the desaturases or elongases listed in Table C1 and C2). In order to express the polynucleotides encoding the desaturases or elongases as set forth in connection with the present invention, the polynucleotides shall be operably linked to expression control sequences. Preferably, the expression control sequences are heterologous with respect
to the polynucleotides operably linked thereto. It is to be understood that each polynucleotide is operably linked to an expression control sequence.
The term "expression control sequence" as used herein refers to a nucleic acid sequence which is capable of governing, i.e. initiating and controlling, transcription of a nucleic acid sequence of interest, in the present case the nucleic sequences recited above. Such a sequence usually comprises or consists of a promoter or a combination of a promoter and enhancer sequences. Expression of a polynucleotide comprises transcription of the nucleic acid molecule, preferably, into a translatable mRNA. Additional regulatory elements may include transcriptional as well as translational enhancers. The following promoters and expression control sequences may be, preferably, used in an expression vector according to the present invention. The cos, tac, trp, tet, trp-tet, Ipp, lac, Ipp-lac, laclq, T7, T5, T3, gal, trc, ara, SP6, λ-PR or λ-PL promoters are, preferably, used in Gram-negative bacteria. For Gram-positive bacteria, promoters amy and SP02 may be used. From yeast or fungal promoters ADC1 , AOX1 r, GAL1 , MFa, AC, P-60, CYC1 , GAPDH, TEF, rp28, ADH are, preferably, used. For animal cell or organism expression, the promoters CMV-, SV40-, RSV-promoter (Rous sarcoma virus), CMV-enhancer, SV40-enhancer are preferably used. From plants the promoters CaMV/35S (Franck 1980, Cell 21 : 285-294], PRP1 (Ward 1993, Plant. Mol. Biol. 22), SSU, OCS, Iib4, usp, STLS1 , B33, nos or the ubiquitin or phaseolin promoter. Also preferred in this context are inducible promoters, such as the promoters described in EP 0388186 A1 (i.e. a benzylsulfonamide-inducible promoter), Gatz 1992, Plant J. 2:397-404 (i.e. a tetracyclin-inducible promoter), EP 0335528 A1 (i.e. a abscisic-acid- inducible promoter) or WO 93/21334 (i.e. a ethanol- or cyclohexenol-inducible promoter). Further suitable plant promoters are the promoter of cytosolic FBPase or the ST-LSI promoter from potato (Stockhaus 1989, EMBO J. 8, 2445), the phosphoribosyl-pyrophosphate amidotransferase promoter from Glycine max (Genbank accession No. U87999) or the node-specific promoter described in EP 0249676 A1. Particularly preferred are promoters which enable the expression in tissues which are involved in the biosynthesis of fatty acids. Also particularly preferred are seed-specific promoters such as the USP promoter in accordance with the practice, but also other promoters such as the LeB4, DC3, phaseolin or napin promoters. Further especially preferred promoters are seed-specific promoters which can be used for monocotyledonous or dicotyledonous plants and which are described in US 5,608,152 (napin promoter from oilseed rape), WO 98/45461 (oleosin promoter from Arobidopsis, US 5,504,200 (phaseolin promoter from Phaseolus vulgaris), WO 91/13980 (Bce4 promoter from Brassica), by Baeumlein et al., Plant J., 2, 2, 1992:233-239 (LeB4 promoter from a legume), these promoters being suitable for dicots. The following promoters are suitable for monocots: lpt-2 or lpt-1 promoter from barley (WO 95/15389 and WO 95/23230), hordein promoter from barley and other promoters which are suitable and which are described in WO 99/16890. In principle, it is possible to use all natural promoters together with their regulatory sequences, such as those mentioned above, for the novel process. Likewise, it is possible and advantageous to use synthetic promoters, either additionally or alone, especially when they mediate a seed-specific expression, such as, for example, as described in WO 99/16890. Preferably, the polynucleotides encoding the desaturases and elongases as referred to herein are expressed in the seeds of the plants. In a particular embodiment, seed-specific promoters are utilized in accordance with the present invention. In a
particular preferred embodiment the polynucleotides encoding the desaturares or elongases are operably linked to expression control sequences used for the the expression of the desaturases and elongases in the Examples section (see e.g. the promoters used for expressing the elongases and desaturases in VC-LTM593-1 qcz rc. The sequence of this vector is shown in SEQ ID NO: 3, see also Table C1 in the Examples section).
The term "operatively linked" as used herein means that the expression control sequence and the nucleic acid of interest are linked so that the expression of the said nucleic acid of interest can be governed by the said expression control sequence, i.e. the expression control sequence shall be functionally linked to the said nucleic acid sequence to be expressed. Accordingly, the expression control sequence and, the nucleic acid sequence to be expressed may be physically linked to each other, e.g., by inserting the expression control sequence at the 5'end of the nucleic acid sequence to be expressed. Alternatively, the expression control sequence and the nucleic acid to be expressed may be merely in physical proximity so that the expression control sequence is capable of governing the expression of at least one nucleic acid sequence of interest. The expression control sequence and the nucleic acid to be expressed are, preferably, separated by not more than 500 bp, 300 bp, 100 bp, 80 bp, 60 bp, 40 bp, 20 bp, 10 bp or 5 bp.
Preferred polynucleotides of the present invention comprise, in addition to a promoter, a terminator sequence operatively linked to the nucleic acid sequence of interest. Thereby, an expression cassette is formed.
The term "terminator" as used herein refers to a nucleic acid sequence which is capable of terminating transcription. These sequences will cause dissociation of the transcription machinery from the nucleic acid sequence to be transcribed. Preferably, the terminator shall be active in plants and, in particular, in plant seeds. Suitable terminators are known in the art and, preferably, include polyadenylation signals such as the SV40-poly-A site or the tk-poly-A site or one of the plant specific signals indicated in Loke et al. (Loke 2005, Plant Physiol 138, pp. 1457-1468), downstream of the nucleic acid sequence to be expressed.
In a preferred embodiment, the polynucleotides encoding the desaturases or elongase referred to herein are recombinant.
The invention furthermore relates to recombinant nucleic acid molecules comprising at least one nucleic acid sequence which codes for a polypeptide having desaturase and/or elongase activity which is modified by comparison with the nucleic acid sequence in the organism from which the sequence originates in that it is adapted to the codon usage in one or more plant species.
For the purposes of the invention "recombinant" means with regard to, for example, a nucleic acid sequence, an expression cassette (=gene construct) or a vector comprising the nucleic acid sequences used in the process according to the invention or a host cell transformed with the nucleic acid sequences, expression cassette or vector used in the process according to the invention, all those constructions brought about by recombinant methods in which either the
nucleic acid sequence, or a genetic control sequence which is operably linked with the nucleic acid sequence, for example a promoter, or are not located in their natural genetic environment or have been modified by recombinant methods. The definitions given herein above preferably apply to the following:
As set forth above, the present invention relates to a method for increasing the tocopherol content of a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase. In an embodiment, the method further comprises the expression of at least one polynucleotide encoding an omega-3-desaturase, at least one polynucleotide encoding a delta-5-elongase, and/or at least one polynucleotide encoding a delta-4-desaturase (for more details regarding the method of the present invention, see section "SUMMARY OF THE INVENTION", the definitions and explanations apply accordingly). Preferably, the polynucleotides are expressed from expression cassettes.
The invention is also concerned with providing polynucleotides as set forth in connection with the method of the present invention, constructs or T-DNAs for establishing high tocopherol content in plants or parts thereof, particularly in plant oils.
The construct or T-DNA shall comprise expression cassettes for the polynucleotides as set forth in the context of the method of the present invention for increasing the tocopherol content. The construct or T-DNA can be used in connection with the method the present invention. In an embodiment, said construct or T-DNA is introduced into the plant for expressing the said polynucleotides (for increasing the tocopherol content).
Accordingly, the present invention relates to a construct or T-DNA comprising at least one expression cassette for a delta-12-desaturase, at least one expression cassette for a delta-6- desaturase, at least one expression cassette for a delta-6-elongase, and at least one expression cassette for a delta-5-desaturase.
An expression cassette for expression of a gene (herein also referred to as target gene) shall comprise the polynucleotide encoding the respective enzyme (i.e. a desaturase or an elongase) operatively linked to a promoter (expression control sequence). Preferably, the expression cassette further comprises a terminator. Preferably, the terminator is downstream of the polynucleotide encoding the desaturase or elongase.
In an embodiment, the construct or T-DNA further comprises at least one expression cassette for an omega-3-desaturase.
In an embodiment, the construct or T-DNA further comprises at least one expression cassette for a delta-5-elongase.
In an embodiment, the construct or T-DNA further comprises at least one expression cassette for a delta-4-desaturase. In an embodiment, the construct or T-DNA further comprises at least one expression cassette for a delta-15-desaturase.
In a preferred embodiment, the construct or T-DNA further comprises at least one expression cassette for an omega-3-desaturase, at least one expression cassette for a delta-5-elongase, and at least one expression cassette for a delta-4-desaturase (preferably at least one for a Coenzyme A dependent delta-4 desaturase and at least one for a phospholipid dependent delta-4 desaturase).
In a particularly preferred embodiment, the T-DNA or construct comprises at least one expression cassette for a delta-12-desaturase, at least one expression cassette for a delta-6-desaturase, at least two expression cassettes for a delta-6-elongase, at least two expression cassettes for a delta-5-desaturase, and optionally at least three expression cassettes for an omega-3- desaturase, and at least one expression cassette for a delta-5-elongase, and at least two expression cassettes for a delta-4-desaturase (preferably for one CoA (Coenzyme A)-dependent D4Des and for one Phospholipid-dependent d4Des.)
In another preferred embodiment, the T-DNA or construct comprises at least one expression cassette for a delta-6 elongase from Physcomitrella patens, at least one expression cassette for a delta-12 desaturase from Phythophthora sojae, at least one expression cassette for a delta-6 desaturase from Ostreococcus tauri, at least one expression cassette for a delta-6 elongase from Thalassiosira pseudonana, at least one expression cassette (in particular at least two) expression cassette(s) for a delta-5 desaturase from Thraustochytrium sp., and optionally at least one expression cassette (in particular at least two) expression cassette(s) for an omega-3 desaturase from Pythium irregulare, at least one expression cassette for an omega-3-desaturase from Phythophthora infestans, at least one expression cassette for a delta-5 elongase from Ostreococcus tauri, and at least one expression cassette for a delta-4 desaturase from Thraustochytrium sp., and at least one expression cassette for a delta-4 desaturase from Pavlova lutheri. Also preferably, the T-DNA or construct comprises the sequence of the T-DNA in the T-DNA vector VC-LTM593-1 qcz described in the Examples section. This vector comprises a sequence shown in SEQ ID NO: 3.
Thus, the invention provides a T-DNA for expression of a target gene in a plant, wherein the T- DNA comprises a left and a right border element and at least one expression cassette comprising a promoter, operatively linked thereto a target gene, and downstream thereof a terminator (and thus at least the expression cassette referred to above), wherein the length of the T-DNA, measured from left to right border element and comprising the target gene, has a length of at
least 30000 bp. In an embodiment, the expression cassette is separated from the closest border of the T-DNA by a separator of at least 500 bp length.
In an embodiment, the T-DNA or construct of the present invention may comprise a separator between the expression cassettes encoding for the desaturases or elongases referred to above. Preferably, the expression cassettes are separated from each other by a separator of at least 100 base pairs, preferably of 100 to 200 base pairs. Thus, there is a separator between each expression cassette. The invention thus provides nucleic acids, i.e. polynucleotides. A polynucleotide according to the present invention is or comprises a T-DNA or construct according to the present invention. Thus, a T-DNA according to the present invention is a polynucleotide, preferably a DNA, and most preferably a double stranded DNA. A "T-DNA" according to the invention is a nucleic acid capable of eventual integration into the genetic material (genome) of a plant. The skilled person understands that for such integration a transformation of respective plant material is required, preferred transformation methods and plant generation methods are described herein.
According to the invention also provided are nucleic acids comprising a T-DNA or construct as defined according to the present invention. For example, a T-DNA of the present invention may be comprised in a circular nucleic acid, e.g. a plasmid, such that an additional nucleic acid section is present between the left and right border elements, i.e. "opposite" of the expression cassette(s) according to the present invention. Such circular nucleic acid may be mapped into a linear form using an arbitrary starting point, e.g. such that the definition "left border element - expression cassette - right border element - additional nucleic acid section opposite of the expression cassette" defines the same circular nucleic acid as the definition "expression cassette - right border element - additional nucleic acid section opposite of the expression cassette - left border element". The additional nucleic acid section preferably comprises one or more genetic elements for replication of the total nucleic acid, i.e. the nucleic acid molecule comprising the T-DNA and the additional nucleic acid section, in one or more host microorganisms, preferably in a microorganism of genus Escherichia, preferably E. coli, and/or Agrobacterium. Preferable host microorganisms are described below in more detail. Such circular nucleic acids comprising a T- DNA of the present invention are particularly useful as transformation vectors; such vectors and are described below in more detail. The polynucleotides as referred to herein are preferably expressed in a plant after introducing them into a plant. Thus, the method of the present invention may also comprise the step of introducing the polynucleotides into the plant. Preferably, the polynucleotides are introduced into the plant by transformation, in particular by Agrobacterium-mediated transformation. In an embodiment, the plants are transformed with a construct or T-DNA comprising the polynucleotides and/or expression cassette as set forth in connect with the present invention. Thus, it is envisaged that the plant is (has been) transformed with a T-DNA or construct of the present invention. The construct or T-DNA used for the introduction, preferably comprises all
polynucleotides to be expressed. Thus, a single construct or T-DNA shall be used for transformation.
The T-DNA or construct length is, thus, preferably large, i.e. may have a minimum length of at least 15000 bp, preferably more than 30000 bp, more preferably at least 40000 bp, even more preferably at least 50000 bp and most preferably at least 60000 bp. Preferably, the length of the T-DNA is in a range of any of the aforementioned minimum lengths to 120000 bp, more preferably in a range of any of the aforementioned minimum lengths to 100000 bp, even more preferably in a range of any of the aforementioned minimum lengths to 90000 bp, even more preferably in a range of any of the aforementioned minimum lengths to 80000 bp. With such minimum lengths it is possible to introduce a number of genes in the form of expression cassettes such that each individual gene is operably liked to at least one promoter and at least one terminator.
In an embodiment, in 3' direction of the T-DNA left border element or in 5' direction of the T-DNA right border element, a separator is present setting the respective border element apart from the expression cassette comprising the target gene. The separator in 3' direction of the T-DNA left border element does not necessarily have the same length and/or sequence as the separator in 5' direction of the T-DNA right border element, as long as both separators suffice to the further requirements given below.
In another embodiment, the expression cassettes are separated from each other by a separator of at least 100 base pairs, preferably of 100 to 200 base pairs. Thus, there is a separator between the expression cassettes. The separator or spacer is a section of DNA predominantly defined by its length. Its function is to separate a target gene from the T-DNA's left or right border, respectively., Introducing a separator effectively separates the gene of interest from major influences exerted by the neighbouring genomic locations after insertion of the T-DNA into a genomic DNA. For example it is commonly believed that not all genomic loci are equally suitable for expression of a target gene, and that the same gene under the control of the same promoter and terminator may be expressed in different intensity in plants depending on the region of integration of the target gene (and its corresponding promoter and terminator) in the plant genome. It is generally believed that different regions of a plant genome are accessible with differing ease for transcription factors and/or polymerase enzymes, for example due to these regions being tightly wound around histones and/or attached to the chromosomal backbone (cf. for example Deal et al., Curr Opin Plant Biol. Apr 201 1 ; 14(2): 1 16-122) or other scaffold material (cf. e.g. Fukuda Y., Plant Mol Biol. 1999 Mar; 39(5): 1051 -62). The mechanism of achieving the above-mentioned benefits by the T-DNA of the present invention is not easily understood, so it is convenient to think of the spacer as a means for physically providing a buffer to compensate for strain exerted by DNA winding by neighbouring histones or chromosomal backbone or other scaffold attached regions. As a model it can be thought that to transcribe a target gene, the DNA has to be partially unwound. If neighbouring regions of the target gene resist such unwinding, for example because they are tightly wound around histones or otherwise attached to a scaffold or backbone such that rotation of nucleic acid strands is limited,
the spacer allows to distribute the strain created by the unwinding attempt over a longer stretch of nucleic acid, thereby reducing the force required for unwinding at the target gene.
In an embodiment, the separator has a length of at least 500 bp. The separator, thus, can be longer than 500 bp, and preferably is at least 800 bp in length, more preferably at least 1000 bp. Longer spacers allow for even more physical separation between the target gene and the nearest genomic flanking region.
In another embodiment, the spacer has a length of at least 100 bp. Preferably, the spacer has a length of 100 to 200 base pairs.
The separator preferably has a sequence devoid of matrix or scaffold attachment signals. Preferably, the separator or spacer does not comprise more than once for a length of 500 bp, preferably not more than once for a length of 1000 bp, a 5-tuple which occurs in the spacers for 20 or more times, summarized over all spacers given in the examples. Those 5-tuples are, in increasing frequency in the spacers given in the examples: AGCCT, CGTAA, CTAAC, CTAGG, GTGAC, TAGGC, TAGGT, AAAAA, AACGC, TTAGC, ACGCT, GCTGA, ACGTT, AGGCT, CGTAG, CTACG, GACGT, GCTTA, AGCTT, CGCTA, TGACG, ACGTG, AGCTG, CACGT, CGTGA, CGTTA, AGCGT, TCACG, CAGCT, CGTCA, CTAGC, GCGTC, TTACG, GTAGC, TAGCG, TCAGC, TAGCT, AGCTA, GCTAG, ACGTA, TACGT. By reducing the frequency of occurrence of one or more of the aforelisted 5-tuples compared to the separators or spacers, a further increase in expression of a target gene in the T-DNA can be achieved.
The separator may contain a selectable marker. A selectable marker is a nucleic acid section whose presence preferably can be verified in seed without having to wait for the sprouting or full growth of the plant. Preferably the selectable marker conveys a phenotypical property to seed or to a growing plant, for example herbicide tolerance, coloration, seed surface properties (e.g. wrinkling), luminescence or fluorescence proteins, for example green fluorescent protein or luciferase. If for exhibiting the phenotypical feature an expression of a marker gene is required, then the separator correspondingly comprises the marker gene as a selectable marker, preferably in the form of an expression cassette. Inclusion of a selectable marker in the separator is particularly advantageous since the marker allows easy discard of non-transformant plant material. Also, in such unexpected case where the T-DNA integrates in a location of the plant genome where the length and/or nucleobase composition of the spacer is insufficient to overcome gene silencing effects caused by the neighbouring genomic DNA, the selectable marker allows easy discard of such unfortunately badly performing exceptional transformants. Thus, preferably the separator comprises an expression cassette for expression of an herbicide tolerance gene. Such separator greatly reduces the chance of having to cultivate a transformant where silencing effects are so strong that even the expression of the selectable marker gene is greatly reduced or fully inhibited. According to the invention, the separator preferably does not comprise a desaturase or elongase gene, and also preferably does not comprise a promoter or operatively linked to a desaturase or elongase gene. Thus, the T-DNA of the present invention in preferred embodiments is useful for effective separation of the desaturase and elongase genes essential
for the production of VLC-PUFAs from any influence of effects caused by neighbouring genomic plant DNA.
For increasing the tocopherol content (and for the production of VLC-PUFAs) in plants, the invention also provides a construct or a T-DNA comprising the coding sequences (in particular of the desaturases and elogases) as given in Table C1 and C2 in the examples, preferably comprising the coding sequences (in particular of the desaturases and elogases) and and promoters as given in Table C1 in the examples, more preferably the coding sequences (in particular of the desaturases and elongases) and promoters and terminators as given in Table C1 in the examples, and most preferably the expression cassettes for the desaturases and elongases as referred to in the context of the method of present invention as present in VC- LTM593-1 qcz rc (see Examples section, SEQ ID NO: 3).
The present invention furthermore relates to a plant comprising the polynucleotides as referred to herein in the context of the method of the present invention for increasing the tocopherol content, or the T-DNA or construct of the present invention. Furthermore, the present invention relates to a seed of the plant. Said seed shall comprised the said polynucleotides. In an embodiment, the said polynucleotides are comprised by the same T-DNA. In addition, the present invention relates to Brassica plant, or a seed thereof, having in increased tocopherol content a compared to a control plant, in particular having an increased tocopherol content the seeds as compared to the seeds of control plants. In an embodiment, said plant is a Brassica napus plant. Said plant shall be transgenic. In a preferred embodiment, the seed of the present invention shall comprise an oil as described herein below in more detail.
The plant of the invention shall comprise one or more T-DNA or construct of the present invention. Thus, the plant shall comprise at least T-DNA or construct of the present invention. Moreover, it is envisaged that the plant of the present invention comprises the polynucleotides encoding desaturases as set forth in the context of the method of the present invention of increasing the tocopherol content.
Preferably, the T-DNA or construct comprised by the plant comprises one or more expression cassettes encoding for one or more d6Des (delta 6 desaturase), one or more d6Elo (delta 6 elongase), one or more d5Des (delta 5 desaturase), or one more d12Des (delta 12 desaturase). In an embodiment, the T-DNA or construct comprised by the plant of the present invention, further comprises expression cassettes for one or more o3Des (omega 3 desaturase), one or more d5Elo (delta 5 elongase) and/or one or more d4Des (delta 4 desaturase), preferably for at least one CoA (Coenzyme A)-dependent D4Des and one Phospholipid-dependent d4Des.
Three desaturase genes are particularly prone to gene dosage effects (also called "copy number effects"), such that increasing the number of expression cassettes comprising these respective
genes leads to a stronger increase in VLC-PUFA levels in plant oils than increasing the number of expression cassettes of other genes. These genes are the genes coding for delta-12- desaturase activity, for delta-6-desaturase activity and omega-3-desaturase activity. It is to be understood that where the T-DNA of the present invention comprises more than one expression cassette comprising a gene of the same function, these genes do not need to be identical concerning their nucleic acid sequence or the polypeptide sequence encoded thereby, but should be functional homologs. Thus, for example, to make use of the gene dosage effect described herein a T-DNA according to the present invention may comprise, in addition to optionally a multiplicity of genes coding for delta-6-desaturases and/or omega-3-desaturases, two, three, four or more expression cassettes each comprising a gene coding for a delta-12-desaturase, wherein the delta-12-desaturase polypeptides coded by the respective genes differ in their amino acid sequence. Likewise, a T-DNA of the present invention may comprise, in addition to optionally a multiplicity of genes coding for delta-12-desaturases and/or omega-3-desaturases, two, three, four or more expression cassettes each comprising a gene coding for a delta-6-desaturase, wherein the delta-6-desaturase polypeptides coded by the respective genes differ in their amino acid sequence, or a T-DNA of the present invention may comprise, in addition to optionally a multiplicity of genes coding for delta-12-desaturases and/or delta-6-desaturases, two, three, four or more expression cassettes each comprising a gene coding for a omega-3-desaturase, wherein the omega-3-desaturase polypeptides coded by the respective genes differ in their amino acid sequence.
According to the invention, the T-DNA, construct or plant may also comprise, instead of one or more of the aforementioned coding sequences, a functional homolog thereof. A functional homolog of a coding sequence is a sequence coding for a polypeptide having the same metabolic function as the replaced coding sequence. For example, a functional homolog of a delta-5- desaturase would be another delta-5-desaturase, and a functional homolog of a delta-5-elongase would be another delta-5-elongase. The functional homolog of a coding sequence preferably codes for a polypeptide having at least 40% sequence identity to the polypeptide coded for by the corresponding coding sequence given Table C1 of the examples, more preferably at least 41 %, more preferably at least 46%, more preferably at least 48%, more preferably at least 56%, more preferably at least 58%, more preferably at least 59%, more preferably at least 62%, more preferably at least 66%, more preferably at least 69%, more preferably at least 73%, more preferably at least 75%, more preferably at least 77%, more preferably at least 81 %, more preferably at least 84%, more preferably at least 87%, more preferably at least 90%, more preferably at least 92%, more preferably at least 95%, more preferably at least 96%, more preferably at least 97%, more preferably at least 98% and even more preferably at least 99%. Likewise, a functional homolog of a promoter is a sequence for starting transcription of a coding sequence located within 500 bp for a proximal promoter or, for a distal promoter, within 3000 bp distant from the promoter TATA box closest to the coding sequence. Again, a functional homolog of a plant seed specific promoter is another plant seed specific promoter. The functional homolog of a terminator, correspondingly, is a sequence for ending transcription of a nucleic acid sequence.
The Examples describe a particularly preferred T-DNA sequence. The skilled person understands that the coding sequences, promoters and terminators described therein can be replaced by their functional homologs. However, the Examples also describe that according to the invention, certain combinations of promoters and coding sequences, or certain combinations of promoters driving the expression of their corresponding coding sequences, or certain coding sequences or combinations thereof are particularly advantageous; such combinations or individual coding sequences should according to the invention not be replaced by functional homologs of the respective element (here: coding sequence or promoter). Preferred promoter-coding sequence- terminator combinations are shown in Table C1 .
A T-DNA or construct of the present invention may comprise two or more genes, preferably all genes, susceptible to a gene dosage effect. As described herein, it is advantageous for achieving high conversion efficiencies of certain enzymatic acitvities, e.g. delta-12-desaturase, delta-6- desaturase and/or omega-3-desaturase activity, to introduce more than one gene coding for an enzyme having the desired activity into a plant cell. When introducing T-DNA into plant cells, generally transformation methods involving exposition of plant cells to microorganisms are employed, e.g. as described herein. As each microorganism may comprise more than one nucleic acid comprising a T-DNA of the present invention, recombinant plant cells are frequently obtained comprising two or more T-DNAs of the present invention independently integrated into the cell's genetic material. Thus, by combining genes susceptible to a gene dosage effect on one construct for transformation allows to easily exploit the independence of transformations to achieve a higher frequency of multiple insertions of such T-DNAs. This is particularly useful for transformation methods relying on co-transformation to keep the size of each construct to be transformed low. The invention accordingly also provides a construct comprising a T-DNA according to the present invention, wherein the construct preferably is a vector for transformation of a plant cell by microorganism-mediated transformation, preferably by Agrobacterium-mediated transformation. Correspondingly, the invention also provides a transforming microorganism comprising one T- DNA according to the present invention, preferably as a construct comprising said T-DNA. Preferably the microorganism is of genus Agrobacterium, preferably a disarmed strain thereof, and preferably of species Agrobacterium tumefaciens or, even more preferably, of species Agrobacterium rhizogenes. Corresponding strains are for example described in WO06024509A2, and methods for plant transformation using such microorganisms are for example described in WO13014585A1. These WO publications are incorporated herein in their entirety, because they contain valuable information about the creation, selection and use of such microorganisms.
The term "vector", preferably, encompasses phage, plasmid, viral vectors as well as artificial chromosomes, such as bacterial or yeast artificial chromosomes. Moreover, the term also relates to targeting constructs which allow for random or site-directed integration of the targeting construct into genomic DNA. Such target constructs, preferably, comprise DNA of sufficient length for either homolgous or heterologous recombination as described in detail below. The vector encompassing the polynucleotide of the present invention, preferably, further comprises selectable markers for propagation and/or selection in a host. The vector may be incorporated
into a host cell by various techniques well known in the art. If introduced into a host cell, the vector may reside in the cytoplasm or may be incorporated into the genome. In the latter case, it is to be understood that the vector may further comprise nucleic acid sequences which allow for homologous recombination or heterologous insertion. Vectors can be introduced into prokaryotic or eukaryotic cells via conventional transformation or transfection techniques. The terms "transformation" and "transfection", conjugation and transduction, as used in the present context, are intended to comprise a multiplicity of prior-art processes for introducing foreign nucleic acid (for example DNA) into a host cell, including calcium phosphate, rubidium chloride or calcium chloride co-precipitation, DEAE-dextran-mediated transfection, lipofection, natural competence, carbon-based clusters, chemically mediated transfer, electroporation or particle bombardment. Suitable methods for the transformation or transfection of host cells, including plant cells, can be found in Sambrook et al. (Molecular Cloning: A Laboratory Manual, 2nd ed., Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, 1989) and other laboratory manuals, such as Methods in Molecular Biology, 1995, Vol. 44, Agrobacterium protocols, Ed.: Gartland and Davey, Humana Press, Totowa, New Jersey. Alternatively, a plasmid vector may be introduced by heat shock or electroporation techniques. Should the vector be a virus, it may be packaged in vitro using an appropriate packaging cell line prior to application to host cells. Preferably, the vector referred to herein is suitable as a cloning vector, i.e. replicable in microbial systems. Such vectors ensure efficient cloning in bacteria and, preferably, yeasts or fungi and make possible the stable transformation of plants. Those which must be mentioned are, in particular, various binary and co-integrated vector systems which are suitable for the T DNA- mediated transformation. Such vector systems are, as a rule, characterized in that they contain at least the vir genes, which are required for the Agrobacterium-mediated transformation, and the sequences which delimit the T-DNA (T-DNA border). These vector systems, preferably, also comprise further cis-regulatory regions such as promoters and terminators and/or selection markers with which suitable transformed host cells or organisms can be identified. While co- integrated vector systems have vir genes and T-DNA sequences arranged on the same vector, binary systems are based on at least two vectors, one of which bears vir genes, but no T-DNA, while a second one bears T-DNA, but no vir gene. As a consequence, the last-mentioned vectors are relatively small, easy to manipulate and can be replicated both in E. coli and in Agrobacterium. These binary vectors include vectors from the pBIB-HYG, pPZP, pBecks, pGreen series. Preferably used in accordance with the invention are Bin19, pB1101 , pBinAR, pGPTV and pCAMBIA. An overview of binary vectors and their use can be found in Hellens et al, Trends in Plant Science (2000) 5, 446-451 . Furthermore, by using appropriate cloning vectors, the polynucleotides can be introduced into host cells or organisms such as plants or animals and, thus, be used in the transformation of plants, such as those which are published, and cited, in: Plant Molecular Biology and Biotechnology (CRC Press, Boca Raton, Florida), chapter 6/7, pp. 71-1 19 (1993); F.F. White, Vectors for Gene Transfer in Higher Plants; in: Transgenic Plants, vol. 1 , Engineering and Utilization, Ed.: Kung and R. Wu, Academic Press, 1993, 15-38; B. Jenes et al., Techniques for Gene Transfer, in: Transgenic Plants, vol. 1 , Engineering and Utilization, Ed.:
Kung and R. Wu, Academic Press (1993), 128-143; Potrykus 1991 , Annu. Rev. Plant Physiol. Plant Molec. Biol. 42, 205-225.
More preferably, the vector of the present invention is an expression vector. In such an expression vector, i.e. a vector which comprises the polynucleotide of the invention having the nucleic acid sequence operatively linked to an expression control sequence (also called "expression cassette") allowing expression in plant cells or isolated fractions thereof.
Most important, the invention also provides a plant or seed thereof, comprising, integrated in its genome, a construct or T-DNA of the present invention.
Thus, the construct or T-DNA shall be stably integrated into the genome of the plant or plant cell. The present invention, thus, relates to a plant comprising the T-DNA or construct of the present invention.
Such T-DNA or construct preferably allows for the expression of all genes required for increasing the tocopherol content in plants and particularly in the seeds thereof, particularly in oilseed plants, and most beneficially in plants or seeds of family Brassicaceae, preferably of genus Brassica and most preferably of a species comprising a genome of one or two members of the species Brassica oleracea, Brassica nigra and Brassica rapa, thus preferably of the species Brassica napus, Brassica carinata, Brassica juncea, Brassica oleracea, Brassica nigra or Brassica rapa. Particularly preferred according to the invention are plants and seeds of the species Brassica napus and Brassica carinata. The plants of the present invention are necessarily transgenic, i.e. they comprise genetic material not present in corresponding wild type plant or arranged differently in corresponding wild type plant, for example differing in the number of genetic elements. For example, the plants of the present invention comprise promoters also found in wild type plants, but the plants of the present invention comprise such promoter operatively linked to a coding sequence sucht that this combination of promoter and coding sequence is not found in the corresponding wild type plant. Accordingly, the the polynucleotide encoding for the desaturases or elongases shall be recombinant polynucleotides.
The plants and seeds of the present invention differ from hitherto produced plants in their production of a high content of tocopherol (and preferably of VLC-PUFAs), see Examples. In particular, the combinations of polynucleotides encoding the elongases or desaturases as set forth in connection with the method of the present invention, the constructs and T-DNAs of the present invention allow for the generation of transformant plants (also called "recombinant plants") and seeds thereof with a high transformation frequency, with a high stability of T-DNA insertions over multiple generations of self-fertilized plants, unchanged or unimpaired phenotypical and agronomic characteristics, with high amounts and concentration of tocopherol, and with high amounts and concentration of VLC-PUFAs, particularly EPA and/or DHA, in the oil of populations of such transformed plants and their corresponding progeny.
Unless stated otherwise, a plant of the present invention comprising a T-DNA or construct of the present invention can also be a plant comprising a part of a T-DNA or construct of the present invention, where such part is sufficient for the production of a desaturase and/or elongase coded for in the corresponding full T-DNA or construct of the present invention. Such plants most preferably comprise at least one full T-DNA of the present invention in addition to the part of a T- DNA of the present invention as defined in the previous sentence. Such plants are hereinafter also termed "partial double copy" plants. Event LBFDAU is an example of a plant comprising a part of a T-DNA of the present invention, and still being a plant of the present invention. In one embodiment the T_DNA is a full T-DNA.
Preferred plants of the present invention comprise one or more T-DNA(s) or construct(s) of the present invention comprising expression cassettes comprising, one or more genes encoding for one or more d5Des, one or more d6Elo, one or more d6Des, and one or more d12Des. In one embodiment, at least one T-DNA or vector further comprises (an) expression cassette(s) which comprises one or more genes encoding for one or more d5Elo, one or more o3Des, one or more d15Des, and/or one or more D4Des, preferably for at least one CoA-dependent D4Des and one Phospholipid-dependent d4Des. In one embodiment, the T-DNA or T-DNAs comprise one or more expression cassettes encoding d6Elo(Tp_GA) and/or d6Elo(Pp_GA). d6Elo(Tp_GA) is a Delta-6 elongase from Thalassiosira pseudonana, d6Elo(Pp_GA) is a Delta-6 elongase from Physcomitrella patens.
Preferably, the plant (or plant cell) of the present invention is an oilseed crop plant (or an oilseed crop plant cell). More preferably, said oilseed crop is selected from the group consisting of flax (Linum sp.), rapeseed (Brassica sp.), soybean (Glycine and Soja sp.), sunflower (Helianthus sp.), cotton (Gossypium sp.), corn (Zea mays), olive (Olea sp.), safflower (Carthamus sp.), cocoa (Theobroma cacoa), peanut (Arachis sp.), hemp, camelina, crambe, oil palm, coconuts, groundnuts, sesame seed, castor bean, lesquerella, tallow tree, sheanuts, tungnuts, kapok fruit, poppy seed, jojoba seeds and perilla. Preferred plants to be used for introducing the polynucleotide or T-DNA of the invention are plants which are capable of synthesizing fatty acids, such as all dicotyledonous or monocotyledonous plants, algae or mosses. Preferred plants are selected from the group of the plant families Adelotheciaceae, Anacardiaceae, Arecaceae, Asteraceae, Apiaceae, Betulaceae, Boraginaceae, Brassicaceae, Bromeliaceae, Caricaceae, Cannabaceae, Convolvulaceae, Chenopodiaceae, Compositae, Crypthecodiniaceae, Cruciferae, Cucurbitaceae, Ditrichaceae, Elaeagnaceae, Ericaceae, Euphorbiaceae, Fabaceae, Geraniaceae, Gramineae, Juglandaceae, Lauraceae, Leguminosae, Linaceae, Malvaceae, Moringaceae, Marchantiaceae, Onagraceae, Olacaceae, Oleaceae, Papaveraceae, Piperaceae, Pedaliaceae, Poaceae, Solanaceae, Prasinophyceae or vegetable plants or ornamentals such as Tagetes. Examples which may be mentioned are the following plants selected from the group consisting of: Adelotheciaceae such as the genera Physcomitrella, such as the genus and species Physcomitrella patens, Anacardiaceae such as the genera Pistacia, Mangifera, Anacardium, for example the genus and species Pistacia vera [pistachio], Mangifer indica [mango] or Anacardium occidentale [cashew], Asteraceae, such as the genera Calendula, Carthamus, Centaurea,
Cichorium, Cynara, Helianthus, Lactuca, Locusta, Tagetes, Valeriana, for example the genus and species Calendula officinalis [common marigold], Carthamus tinctorius [safflower], Centaurea cyanus [cornflower], Cichorium intybus [chicory], Cynara scolymus [artichoke], Helianthus annus [sunflower], Lactuca sativa, Lactuca crispa, Lactuca esculenta, Lactuca scariola L. ssp. sativa, Lactuca scariola L. var. integrata, Lactuca scariola L. var. integrifolia, Lactuca sativa subsp. romana, Locusta communis, Valeriana locusta [salad vegetables], Tagetes lucida, Tagetes erecta or Tagetes tenuifolia [african or french marigold], Apiaceae, such as the genus Daucus, for example the genus and species Daucus carota [carrot], Betulaceae, such as the genus Corylus, for example the genera and species Corylus avellana or Corylus colurna [hazelnut], Boraginaceae, such as the genus Borago, for example the genus and species Borago officinalis [borage], Brassicaceae, such as the genera Brassica, Melanosinapis, Sinapis, Arabadopsis, for example the genera and species Brassica napus, Brassica rapa ssp. [oilseed rape], Sinapis arvensis Brassica juncea, Brassica juncea var. juncea, Brassica juncea var. crispifolia, Brassica juncea var. foliosa, Brassica nigra, Brassica sinapioides, Melanosinapis communis [mustard], Brassica oleracea [fodder beet] or Arabidopsis thaliana, Bromeliaceae, such as the genera Anana, Bromelia (pineapple), for example the genera and species Anana comosus, Ananas ananas or Bromelia comosa [pineapple], Caricaceae, such as the genus Carica, such as the genus and species Carica papaya [pawpaw], Cannabaceae, such as the genus Cannabis, such as the genus and species Cannabis sativa [hemp], Convolvulaceae, such as the genera Ipomea, Convolvulus, for example the genera and species Ipomoea batatus, Ipomoea pandurata, Convolvulus batatas, Convolvulus tiliaceus, Ipomoea fastigiata, Ipomoea tiliacea, Ipomoea triloba or Convolvulus panduratus [sweet potato, batate], Chenopodiaceae, such as the genus Beta, such as the genera and species Beta vulgaris, Beta vulgaris var. altissima, Beta vulgaris var.Vulgaris, Beta maritima, Beta vulgaris var. perennis, Beta vulgaris var. conditiva or Beta vulgaris var. esculenta [sugarbeet], Crypthecodiniaceae, such as the genus Crypthecodinium, for example the genus and species Cryptecodinium cohnii, Cucurbitaceae, such as the genus Cucurbita, for example the genera and species Cucurbita maxima, Cucurbita mixta, Cucurbita pepo or Cucurbita moschata [pumpkin/squash], Cymbellaceae such as the genera Amphora, Cymbella, Okedenia, Phaeodactylum, Reimeria, for example the genus and species Phaeodactylum tricornutum, Ditrichaceae such as the genera Ditrichaceae, Astomiopsis, Ceratodon, Chrysoblastella, Ditrichum, Distichium, Eccremidium, Lophidion, Philibertiella, Pleuridium, Saelania, Trichodon, Skottsbergia, for example the genera and species Ceratodon antarcticus, Ceratodon columbiae, Ceratodon heterophyllus, Ceratodon purpureus, Ceratodon purpureus, Ceratodon purpureus ssp. convolutus, Ceratodon, purpureus spp. stenocarpus, Ceratodon purpureus var. rotundifolius, Ceratodon ratodon, Ceratodon stenocarpus, Chrysoblastella chilensis, Ditrichum ambiguum, Ditrichum brevisetum, Ditrichum crispatissimum, Ditrichum difficile, Ditrichum falcifolium, Ditrichum flexicaule, Ditrichum giganteum, Ditrichum heteromallum, Ditrichum lineare, Ditrichum lineare, Ditrichum montanum, Ditrichum montanum, Ditrichum pallidum, Ditrichum punctulatum, Ditrichum pusillum, Ditrichum pusillum var. tortile, Ditrichum rhynchostegium, Ditrichum schimperi, Ditrichum tortile, Distichium capillaceum, Distichium hagenii, Distichium inclinatum, Distichium macounii, Eccremidium floridanum, Eccremidium whiteleggei, Lophidion strictus, Pleuridium acuminatum, Pleuridium alternifolium, Pleuridium holdridgei, Pleuridium mexicanum, Pleuridium ravenelii, Pleuridium subulatum,
Saelania glaucescens, Trichodon borealis, Trichodon cylindricus or Trichodon cylindricus var. oblongus, Elaeagnaceae such as the genus Elaeagnus, for example the genus and species Olea europaea [olive], Ericaceae such as the genus Kalmia, for example the genera and species Kalmia latifolia, Kalmia angustifolia, Kalmia microphylla, Kalmia polifolia, Kalmia occidentalis, Cistus chamaerhodendros or Kalmia lucida [mountain laurel], Euphorbiaceae such as the genera Manihot, Janipha, Jatropha, Ricinus, for example the genera and species Manihot utilissima, Janipha manihot, Jatropha manihot, Manihot aipil, Manihot dulcis, Manihot manihot, Manihot melanobasis, Manihot esculenta [manihot] or Ricinus communis [castor-oil plant], Fabaceae such as the genera Pisum, Albizia, Cathormion, Feuillea, Inga, Pithecolobium, Acacia, Mimosa, Medicajo, Glycine, Dolichos, Phaseolus, Soja, for example the genera and species Pisum sativum, Pisum arvense, Pisum humile [pea], Albizia berteriana, Albizia julibrissin, Albizia lebbeck, Acacia berteriana, Acacia littoralis, Albizia berteriana, Albizzia berteriana, Cathormion berteriana, Feuillea berteriana, Inga fragrans, Pithecellobium berterianum, Pithecellobium fragrans, Pithecolobium berterianum, Pseudalbizzia berteriana, Acacia julibrissin, Acacia nemu, Albizia nemu, Feuilleea julibrissin, Mimosa julibrissin, Mimosa speciosa, Sericanrda julibrissin, Acacia lebbeck, Acacia macrophylla, Albizia lebbek, Feuilleea lebbeck, Mimosa lebbeck, Mimosa speciosa [silk tree], Medicago sativa, Medicago falcata, Medicago varia [alfalfa], Glycine max Dolichos soja, Glycine gracilis, Glycine hispida, Phaseolus max, Soja hispida or Soja max [soybean], Funariaceae such as the genera Aphanorrhegma, Entosthodon, Funaria, Physcomitrella, Physcomitrium, for example the genera and species Aphanorrhegma serratum, Entosthodon attenuatus, Entosthodon bolanderi, Entosthodon bonplandii, Entosthodon californicus, Entosthodon drummondii, Entosthodon jamesonii, Entosthodon leibergii, Entosthodon neoscoticus, Entosthodon rubrisetus, Entosthodon spathulifolius, Entosthodon tucsoni, Funaria americana, Funaria bolanderi, Funaria calcarea, Funaria californica, Funaria calvescens, Funaria convoluta, Funaria flavicans, Funaria groutiana, Funaria hygrometrica, Funaria hygrometrica var. arctica, Funaria hygrometrica var. calvescens, Funaria hygrometrica var. convoluta, Funaria hygrometrica var. muralis, Funaria hygrometrica var. utahensis, Funaria microstoma, Funaria microstoma var. obtusifolia, Funaria muhlenbergii, Funaria orcuttii, Funaria plano-convexa, Funaria polaris, Funaria ravenelii, Funaria rubriseta, Funaria serrata, Funaria sonorae, Funaria sublimbatus, Funaria tucsoni, Physcomitrella californica, Physcomitrella patens, Physcomitrella readeri, Physco-rnitrium australe, Physcomitrium californicum, Physcomitrium collenchymatum, Physcomitrium coloradense, Physcomitrium cupuliferum, Physcomitrium drummondii, Physcomitrium eurystomum, Physcomitrium flexifolium, Physcomitrium hookeri, Physcomitrium hookeri var. serratum, Physcomitrium immersum, Physcomitrium kellermanii, Physcomitrium megalocarpum, Physcomitrium pyriforme, Physcomitrium pyriforme var. serratum, Physcomitrium rufipes, Physcomitrium sandbergii, Physcomitrium subsphaericum, Physcomitrium washingtoniense, Geraniaceae, such as the genera Pelargonium, Cocos, Oleum, for example the genera and species Cocos nucifera, Pelargonium grossularioides or Oleum cocois [coconut], Gramineae, such as the genus Saccharum, for example the genus and species Saccharum officinarum, Juglandaceae, such as the genera Juglans, Wallia, for example the genera and species Juglans regia, Juglans ailanthifolia, Juglans sieboldiana, Juglans cinerea, Wallia cinerea, Juglans bixbyi, Juglans californica, Juglans hindsii, Juglans intermedia, Juglans jamaicensis, Juglans major, Juglans microcarpa, Juglans nigra or Wallia nigra [walnut],
Lauraceae, such as the genera Persea, Laurus, for example the genera and species Laurus nobilis [bay], Persea americana, Persea gratissima or Persea persea [avocado], Leguminosae, such as the genus Arachis, for example the genus and species Arachis hypogaea [peanut], Linaceae, such as the genera Linum, Adenolinum, for example the genera and species Linum usitatissimum, Linum humile, Linum austriacum, Linum bienne, Linum angustifolium, Linum catharticum, Linum flavum, Linum grandiflorum, Adenolinum grandiflorum, Linum lewisii, Linum narbonense, Linum perenne, Linum perenne var. lewisii, Linum pratense or Linum trigynum [linseed], Lythrarieae, such as the genus Punica, for example the genus and species Punica granatum [pomegranate], Malvaceae, such as the genus Gossypium, for example the genera and species Gossypium hirsutum, Gossypium arboreum, Gossypium barbadense, Gossypium herbaceum or Gossypium thurberi [cotton], Marchantiaceae, such as the genus Marchantia, for example the genera and species Marchantia berteroana, Marchantia foliacea, Marchantia macropora, Musaceae, such as the genus Musa, for example the genera and species Musa nana, Musa acuminata, Musa paradisiaca, Musa spp. [banana], Onagraceae, such as the genera Camissonia, Oenothera, for example the genera and species Oenothera biennis or Camissonia brevipes [evening primrose], Palmae, such as the genus Elacis, for example the genus and species Elaeis guineensis [oil palm], Papaveraceae, such as the genus Papaver, for example the genera and species Papaver orientale, Papaver rhoeas, Papaver dubium [poppy], Pedaliaceae, such as the genus Sesamum, for example the genus and species Sesamum indicum [sesame], Piperaceae, such as the genera Piper, Artanthe, Peperomia, Steffensia, for example the genera and species Piper aduncum, Piper amalago, Piper angustifolium, Piper auritum, Piper betel, Piper cubeba, Piper longum, Piper nigrum, Piper retrofractum, Artanthe adunca, Artanthe elongata, Peperomia elongata, Piper elongatum, Steffensia elongata [cayenne pepper], Poaceae, such as the genera Hordeum, Secale, Avena, Sorghum, Andropogon, Holcus, Panicum, Oryza, Zea (maize), Triticum, for example the genera and species Hordeum vulgare, Hordeum jubatum, Hordeum murinum, Hordeum secalinum, Hordeum distichon, Hordeum aegiceras, Hordeum hexastichon, Hordeum hexastichum, Hordeum irregulare, Hordeum sativum, Hordeum secalinum [barley], Secale cereale [rye], Avena sativa, Avena fatua, Avena byzantina, Avena fatua var. sativa, Avena hybrida [oats], Sorghum bicolor, Sorghum halepense, Sorghum saccharatum, Sorghum vulgare, Andropogon drummondii, Holcus bicolor, Holcus sorghum, Sorghum aethiopicum, Sorghum arundinaceum, Sorghum caffrorum, Sorghum cernuum, Sorghum dochna, Sorghum drummondii, Sorghum durra, Sorghum guineense, Sorghum lanceolatum, Sorghum nervosum, Sorghum saccharatum, Sorghum subglabrescens, Sorghum verticilliflorum, Sorghum vulgare, Holcus halepensis, Sorghum miliaceum, Panicum militaceum [millet], Oryza sativa, Oryza latifolia [rice], Zea mays [maize], Triticum aestivum, Triticum durum, Triticum turgidum, Triticum hybernum, Triticum macha, Triticum sativum or Triticum vulgare [wheat], Porphyridiaceae, such as the genera Chroothece, Flintiella, Petrovanella, Porphyridium, Rhodella, Rhodosorus, Vanhoeffenia, for example the genus and species Porphyridium cruentum, Proteaceae, such as the genus Macadamia, for example the genus and species Macadamia intergrifolia [macadamia], Prasinophyceae such as the genera Nephroselmis, Prasinococcus, Scherffelia, Tetraselmis, Mantoniella, Ostreococcus, for example the genera and species Nephroselmis olivacea, Prasinococcus capsulatus, Scherffelia dubia, Tetraselmis chui, Tetraselmis suecica, Mantoniella squamata, Ostreococcus tauri, Rubiaceae such as the genus
Cofea, for example the genera and species Cofea spp., Coffea arabica, Coffea canephora or Coffea liberica [coffee], Scrophulariaceae such as the genus Verbascum, for example the genera and species Verbascum blattaria, Verbascum chaixii, Verbascum densiflorum, Verbascum lagurus, Verbascum longifolium, Verbascum lychnitis, Verbascum nigrum, Verbascum olympicum, Verbascum phlomoides, Verbascum phoenicum, Verbascum pulverulentum or Verbascum thapsus [mullein], Solanaceae such as the genera Capsicum, Nicotiana, Solanum, Lycopersicon, for example the genera and species Capsicum annuum, Capsicum annuum var. glabriusculum, Capsicum frutescens [pepper], Capsicum annuum [paprika], Nicotiana tabacum, Nicotiana alata, Nicotiana attenuata, Nicotiana glauca, Nicotiana langsdorffii, Nicotiana obtusifolia, Nicotiana quadrivalvis, Nicotiana repanda, Nicotiana rustica, Nicotiana sylvestris [tobacco], Solanum tuberosum [potato], Solanum melongena [eggplant], Lycopersicon esculentum, Lycopersicon lycopersicum, Lycopersicon pyriforme, Solanum integrifolium or Solanum lycopersicum [tomato], Sterculiaceae, such as the genus Theobroma, for example the genus and species Theobroma cacao [cacao] or Theaceae, such as the genus Camellia, for example the genus and species Camellia sinensis [tea]. In particular preferred plants to be used as transgenic plants in accordance with the present invention are oil fruit crops which comprise large amounts of lipid compounds, such as peanut, oilseed rape, canola, sunflower, safflower, poppy, mustard, hemp, castor-oil plant, olive, sesame, Calendula, Punica, evening primrose, mullein, thistle, wild roses, hazelnut, almond, macadamia, avocado, bay, pumpkin/squash, linseed, soybean, pistachios, borage, trees (oil palm, coconut, walnut) or crops such as maize, wheat, rye, oats, triticale, rice, barley, cotton, cassava, pepper, Tagetes, Solanaceae plants such as potato, tobacco, eggplant and tomato, Vicia species, pea, alfalfa or bushy plants (coffee, cacao, tea), Salix species, and perennial grasses and fodder crops. Preferred plants according to the invention are oil crop plants such as peanut, oilseed rape, canola, sunflower, safflower, poppy, mustard, hemp, castor-oil plant, olive, Calendula, Punica, evening primrose, pumpkin/squash, linseed, soybean, borage, trees (oil palm, coconut). Especially preferred are sunflower, safflower, tobacco, mullein, sesame, cotton, pumpkin/squash, poppy, evening primrose, walnut, linseed, hemp, thistle or safflower. Very especially preferred plants are plants such as safflower, sunflower, poppy, evening primrose, walnut, linseed, or hemp, or most preferred, plants of family Brassicaceae.
Most preferably, the plant of the present invention is a plant found in the "Triangle of U", i.e. a plant of genus Brassica: Brassica napus (AA CC genome; n=19) is an amphidiploid plant of the Brassica genus but is thought to have resulted from hybridization of Brassica rapa (AA genome; n=10) and Brassica oleracea (CC genome; n=9). Brassica juncea (AA BB genome; n=18) is an amphidiploid plant of the Brassica genus that is generally thought to have resulted from the hybridization of Brassica rapa and Brassica nigra (BB genome; n=8). Under some growing conditions, B. juncea may have certain superior traits to B. napus. These superior traits may include higher yield, better drought and heat tolerance and better disease resistance. Brassica carinata (BB CC genome; n=17) is an amphidiploid plant of the Brassica genus but is thought to have resulted from hybridization of Brassica nigra and Brassica oleracea. Under some growing conditions, B. carinata may have superior traits to B. napus. Particularly, B. carinata allows for an
increase in VLC-PUFA concentrations by at least 20% compared to B. napus when transformed with the same T-DNA.
The plant of the present invention preferably is a "Canola" plant. Canola is a genetic variation of rapeseed developed by Canadian plant breeders specifically for its oil and meal attributes, particularly its low level of saturated fat. Canola herein generally refers to plants of Brassica species that have less than 2% erucic acid (Delta 13-22:1 ) by weight in seed oil and less than 30 micromoles of glucosinolates per gram of oil-free meal. Typically, canola oil may include saturated fatty acids known as palmitic acid and stearic acid, a monounsaturated fatty acid known as oleic acid, and polyunsaturated fatty acids known as linoleic acid and linolenic acid. Canola oil may contain less than about 7%(w/w) total saturated fatty acids (mostly palmitic acid and stearic acid) and greater than 40%(w/w) oleic acid (as percentages of total fatty acids). Traditionally, canola crops include varieties of Brassica napus and Brassica rapa. Preferred plants of the present invention are spring canola (Brassica napus subsp. oleifera var. annua) and winter canola (Brassica napus subsp. oleifera var. biennis). Furthermore a canola quality Brassica juncea variety, which has oil and meal qualities similar to other canola types, has been added to the canola crop family (U.S. Pat. No. 6,303,849, to Potts et al., issued on Oct. 16, 2001 ; U.S. Pat. No. 7,423,198, to Yao et al.; Potts and Males, 1999; all of which are incorporated herein by reference). Likewise it is possible to establish canola quality B. carinata varieties by crossing canola quality variants of Brassica napus with Brassica nigra and appropriately selecting progeny thereof, optionally after further back-crossing with B. carinata, B. napus and/or B. nigra.
The invention also provides a plant or seed thereof of family Brassicaceae, preferably of genus Brassica, with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from progeny lines prepared by a method comprising the steps of i) crossing a plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant comprising a a combination of polynucleotides encording for desaturases or elongases as set forth in the context of the method of the present invention, a construct or T-DNA of the present invention and/or part of such construct or T-DNA, with a parent plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant not comprising said T-DNA and/or part thereof, to yield a F1 hybrid,
ii) selfing the F1 hybrid for at least one generation, and
iii) identifying the progeny of step (ii) comprising the combination of polynucleotides, theconstruct, T-DNA of the present invention capable of producing seed comprising an increased tocopherol content as compared to a control plant. In an embodiment, an increased tocopherol content is a tocopherol content as disclosed elsewhere herein. In an embodiment, the produced seed comprise VLC-PUFA such that the content of all VLC- PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 8%, or at least 12% (w/w) and/or
the content of DHA is at least 1 % (w/w) of the total seed fatty acid content at an oil content of 40% (w/w).
In an embodiment, the produced seed comprise VLC-PUFA such that the the content of EPA is at least 8%, or at least 12%. (w/w).
In an embodiment, the content of DHA is at least 1 % (w/w) of the total seed fatty acid content.
This method allows for effectively incorporation of genetic material of other members of family Brassicaceae, preferably of genus Brassica, into the genome of a plant comprising the polynucleotides as set forth in the context of the method of the present invention, a T-DNA, or construct of the present invention. The method is particularly useful for combining the polynucleotides, the T-DNA and/or the construct with genetic material responsible for beneficial traits exhibited in other members of family Brassicaceae. Beneficial traits of other members of family Brassicaceae are exemplarily described herein, other beneficial traits or genes and/or regulatory elements involved in the manifestation of a beneficial trait may be described elsewhere.
The parent plant not comprising the said polynucleotides, the T-DNA or the construct of the present invention or part thereof preferably is an agronomically elite parent. In particular, the present invention teaches the transfer of heterologous material from a plant or seed of the present invention to a different genomic background, for example a different variety or species.
In particular, the invention teaches the transfer of the T-DNA or part thereof (the latter is particularly relevant for those plants of the present invention which comprise, in addition to a full T-DNA or construct of the present invention, also a part of a T-DNA or construct of the present invention, said part preferably comprising at least one expression cassette, the expression cassette preferably comprising a gene coding for a desaturase or elongase, preferably a delta- 12-desaturase, delta-6-desaturase and/or omega-3-desaturase) into a species of genus Brassica carinata, or to introduce genetic material from Brassica carinata or Brassica nigra into the plants of the present invention comprising the T-DNA of the present invention and/or a part or two or more parts thereof. According to the invention, genes of Brassica nigra replacing their homolog found in Brassica napus or added in addition to the homolog found in Brassica napus are particularly helpful in further increasing the amount of VLC-PUFAs in plant seeds and oils thereof. Also, the invention teaches novel plant varieties comprising the polynucleotides encoding for the desaturases or elongases as set forth in the context of the method of the present invention, the construct or T-DNA and/or part thereof of the present invention. Such varieties can, by selecting appropriate mating partners, be particularly adapted e.g. to selected climatic growth conditions, herbicide tolerance, stress resistance, fungal resistance, herbivore resistance, increased or reduced oil content or other beneficial features. It is particularly beneficial to provide plants of the present invention wherein the oil content thereof at harvest is lower than that of corresponding wild type plants of the same variety, such as to increase the total tocopherol content (and to
improve VLC-PUFA amounts) in the oil of said plants of the present invention and/or tocopherol concentration (and VLC-PUFA concentrations) in said oil.
Also, the invention provides a method for creating a plant with a genotype that confers a heritable phenotype of tocopherol content (in particular an increased content in the seed oil), obtainable or obtained from progeny lines prepared by a method comprising the steps of
i) crossing a transgenic plant of the invention with a parent plant not comprising the polynucleotides encoding for the desaturases or elongases as set forth in the context of the method of the present invention, the construct or T-DNA of the present invention or part thereof, said parent plant being of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, to yield a F1 hybrid,
ii) selfing the F1 hybrid for at least one generation, and
iii) identifying the progeny of step (ii) comprising the polynucleotides, construct or T-DNA capable of producing seed comprising an increased tocopherol content as compared to seed of a control plant.
In an embodiment, said seed may comprise VLC-PUFA such that the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 8% (w/w) and/or the content of DHA is at least 1 % (w/w) of the total seed fatty acid content at an oil content of 30% (w/w), preferably at an oil content of 35% (w/w), and more preferably at an oil content of 40% (w/w).
The method allows the creation of novel variants and transgenic species of plants of the present invention, and the seeds thereof. Such plants and seeds exhibit the aforementioned benefits of the present invention. Preferably, the content of EPA is at least 10% by weight, even more preferably at least 13% (w/w), of the total lipid content of the oil. Also preferably, the content of DHA is at least 1.5% by weight, even more preferably at least 2% (w/w), of the total lipid content of the oil. The present invention for the first time allows for the achievement of such high levels of tocopherol and VLC-PUFA in seed reliably under agronomic conditions, i.e. representative for the real yield obtained from seeds of a commercial field of at least 1 ha planted with plants of the present invention, wherein the plants have a defined copy number of genes for implementing the pathway for production of EPA and/or DHA in said plants, and the copy number being low, i.e. single-copy or partial double copy.
A plant of the present invention also includes plants obtainable or obtained by backcrossing (cross into the non-transgenic, isogenic parent line), and by crossing with other germplasms of the Triangle of U. Accordingly, the invention provides a method for creating a plant with a genotype that confers a heritable phenotype of an increased seed oil tocopherol content, obtainable or obtained from a progeny line prepared by a method comprising the steps of
i) crossing a transgenic plant of the invention (also called "non-recurring parent") with a parent plant not expressing a gene comprised in the polynucleotides, T-DNA or contruct of the present invention, said parent plant being of family Brassicaceae, preferably of genus Brassica,
most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, to yield a hybrid progeny,
ii) crossing the hybrid progeny again with the parent to obtain another hybrid progeny, iii) optionally repeating step ii) and
iv) selecting a hybrid progeny comprising the polynucleotides encoding desaturases or elongases as set forth in the contect of the method of present invention, the T-DNA, or the construct of the present invention.
Backcrossing methods, e.g. as described above, can be used with the present invention to improve or introduce a characteristic into the plant line comprising the polynucleotides, construct or T-DNA of the present invention. Such hybrid progeny is selected in step iv) which suffices predetermined parameters. The backcrossing method of the present invention thereby beneficially facilitates a modification of the genetic material of the recurrent parent with the desired gene, or preferably the polynucleotides, construct, or T-DNA of the present invention, from the non-recurrent parent, while retaining essentially all of the rest of the desired genetic material of the recurrent parent, and therefore the desired physiological and morphological, constitution of the parent line. The selected hybrid progeny is then preferably multiplied and constitutes a line as described herein. Selection of useful progeny for repetition of step ii) can be further facilitated by the use of genomic markers. For example, such progeny is selected for the repetition of step ii) which comprises, compared to other progeny obtained in the previous crossing step, most markers also found in the parent and/or least markers also found in the non-recurring parent except the desired polynucleotides, construct, or T-DNA of the present invention or part of the T- DNA or construct thereof. Preferably, a hybrid progeny is selected which comprises the polynucleotides, construct or T-DNA of the present invention, and even more preferably also comprises at least one further expression cassette from the non-recurring parent of the present invention, e.g. by incorporation of an additional part of the construct or T-DNA of the present invention into the hybrid plant genetic material.
Further preferably a hybrid progeny is obtained wherein essentially all of the desired morphological and physiological characteristics of the parent are recovered in the converted plant, in addition to genetic material from the non-recurrent parent as determined at the 5% significance level when grown under the same environmental conditions.
Further preferably, a hybrid progeny is selected which produces seed comprising an increased tocopherol content as compared to a control, in particular in the oil of seeds. Also preferably, the seed comprise VLC-PUFA such that the content of all VLC-PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 8% (w/w) and/or the content of DHA is at least 1 % (w/w) of the total seed fatty acid content at an oil content of 30% (w/w), preferably at an oil content of 35% (w/w), and more preferably at an oil content of 40% (w/w).
It is to be understood that such seed VLC-PUFA or tocopherol content is to be measured not from a single seed or from the seeds of an individual plant, but refers to the numeric average of seed VLC-PUFA content of at least 100 plants, even more preferably of at least 200 plants, even more preferably of at least 200 plants half of which have been grown in field trials in different years.
The choice of the particular non-recurrent parent will depend on the purpose of the backcross. One of the major purposes is to add some commercially desirable, agronomically important trait to the line. The term "line" refers to a group of plants that displays very little overall variation among individuals sharing that designation. A "line" generally refers to a group of plants that display little or no genetic variation between individuals for at least one trait. A "DH (doubled haploid) line," as used in this application refers to a group of plants generated by culturing a haploid tissue and then doubling the chromosome content without accompanying cell division, to yield a plant with the diploid number of chromosomes where each chromosome pair is comprised of two duplicated chromosomes. Therefore, a DH line normally displays little or no genetic variation between individuals for traits. Lines comprising one or more genes originally comprised in a T-DNA of the present invention in the non-recurring parent also constitute plants of the present invention. The invention is also concerned with a method of plant oil and/or tocopherol production (in particular for tocopherol production), comprising the steps of
i) growing a plant of the present invention such as to obtain oil-containing seeds thereof, ii) harvesting said seeds, and
iii) extracting oil from said seeds harvested in step ii).
Preferably the oil has an increased tocopherol content, in particular as compared to the oil extracted from seeds of a control plant. Preferred increased tocopherol contents are disclosed elsewhere herein. The extraction step under iii) is preferably carried out under conditions which maintain the tocopherol content of the oil. Conditions which maintain the tocopherol content of the oil in the context of the present invention shall be conditions which do not reduce the tocopherol content. Such conditions are well known in the art and are e.g. described in Willner et al. ΕίηίΙυβ der Prozeβparamezer auf die Tocopherolbilanz bei der Gewinnung von pflanzlichen Olen. Lipid / Fett, Volume 99, Issue 4, pages 138-147, 1997 which herewith is incorporated by reference in its entirety.
In addition, the oil may have a DHA content of at least 1 % by weight based on the total lipid content and/or an EPA content of at least 8% by weight based on the total lipid content.
In a further step, the method may comprise the step iv) of isolating tocopherol from the oil extracted in step iii).
In an embodiment, the term "isolating tocopherol" means "enriching tocopherol".
How to isolate tocopherol from oil is well known in the art and e.g. described in "Commercial Extraction of Vitamin E from Food Sources" in The Encyclopedia of Vitamin E, Preedy, V.R. and Watson R.R. (eds.), CABI Publishers, Oxford, U.K., pp. 140-152 and in US 5,627,289. Both documents are incorporated herein in their entirety.
For example, tocopherols can be isolated from by varous methods such as esterification of the free fatty acids in the oil, by saponification which allows for revomal of fatty components from the oil, distillation, by chromatographic methods, by enzymatic methods (by using lipase) etc.. These and further methods are described in the the chapter of "The Encyclopedia of Vitamin E" referred to in the previous paragraph in detail.
In an embodiment, the isolation comprises esterifying free fatty acids in said oil with methanol; transesterifying triglycerides in said oil by alkali-catalyzed transesterification with methanol; acidifying and then washing the oil resulting from said transesterification; and removing by distillation fatty acid methyl esters from the oil resulting from said acidifying and washing. In an embodiment, steam distillates of the oil are used as the oil. In an embodiment, an inorganic acid such as hydrochloric acid is used for the acidifying.
In an embodiment, 1 to 1.5 parts by volume of said mixture is esterified using 1 part by volume of methanol. In an embodiment, the free fatty acids are esterified at a temperature of 60 to 100°C (in particular at temperature of 65 to 70°C). Preferably, the fatty acids are esterified the presence of a strongly acidic ion exchanger.
Preferably, the oil comprises EPA, DHA, and/or DPA n-3 in concentrations described herein below.
Also preferably, the content of EPA is at least 8% by weight, even more preferably at least 10% (w/w), of the total lipid content of the oil. Preferably, the content of DHA is at least 1 % by weight, even more preferably at least 1.5% (w/w), of the total lipid content of the oil. As described herein, the plant of the present invention comprises, for the purposes of such method of plant oil production, preferably comprises the polynucleotides, the construct, or the T-DNA of the present invention and optionally also one or more additional parts of the T-DNA or of the construct, wherein the part or parts, respectively, comprise at least one expression cassette of the T-DNA of the present invention.
The present invention also relates to oil comprising an increased tocopherol content. Preferably, said oil is obtainable by the aforementioned methods, or produced by the plant of the present invention. Preferably, said oil also comprises an increased content of VLC-PUFA (The term "high
content" and "increased content" are used interchangeably herein). For example, the oil can comprise EPA, DHA, and/or DPA n-3 in concentrations described herein below.
The term "oil" refers to a fatty acid mixture comprising unsaturated and/or saturated fatty acids which are esterified to triglycerides. Preferably, the triglycerides in the oil of the invention comprise PUFA or VLC-PUFA moieties as referred to above. The amount of esterified PUFA and/or VLC- PUFA is, preferably, approximately 30%, a content of 50% is more preferred, a content of 60%, 70%, 80% or more is even more preferred. The oil may further comprise free fatty acids, preferably, the PUFA and VLC-PUFA referred to above. For the analysis, the fatty acid content can be, e.g., determined by GC analysis after converting the fatty acids into the methyl esters by transesterification. The content of the various fatty acids in the oil or fat can vary, in particular depending on the source. The oil, however, shall have a non-naturally occurring composition with respect to the PUFA and/or VLC-PUFA composition and content. It is known that most of the fatty acids in plant oil are esterified in triacylglycerides. Accordingly, in the oil of the invention, the PUFAs and VLC-PUFAs, preferably, also occur in esterified form in the triacylglcerides. It will be understood that such a unique oil composition and the unique esterification pattern of PUFA and VLC-PUFA in the triglycerides of the oil shall only be obtainable by applying the methods of the present invention specified above. Moreover, the oil of the invention may comprise other molecular species as well. Specifically, it may comprise minor amounts of the polynucleotide or vector of the invention. Such low amounts, however, can be detected only by highly sensitive techniques such as PCR.
As described above, these oils, lipids or fatty acids compositions, preferably, comprise (by weight) 6 to 15% of palmitic acid, 1 to 6% of stearic acid, 7-85% of oleic acid, 0.5 to 8% of vaccenic acid, 0.1 to 1 % of arachic acid, 7 to 25% of saturated fatty acids, 8 to 85% of monounsaturated fatty acids and 60 to 85% of polyunsaturated fatty acids, in each case based on 100% and on the total fatty acid content of the organisms (preferably by weight). Preferred VLC-PUFAs present in the fatty acid esters or fatty acid mixtures is, preferably, 1 % to 20% DHA, or 5,5% to 20% of DHA and/or 9,5% to 30% EPA based on the total fatty acid content (preferably by weight).
The oils, lipids or fatty acids according to the invention, preferably, comprise at least 1 %, 2%, 3%, 4% 5.5%, 6%, 7% or 7,5%, more preferably, at least 8%, 9%, 10%, 1 1 % or 12%, and most preferably at least 13%, 14%, 15%, 16%. 17%, 18%, 19% or 20% of DHA, and/or at least 9.5%, 10%, 1 1 % or 12%, more preferably, at least 13%, 14%, 14,5%, 15% or 16%, and most preferably at least 17 % , 18 % , 19 % , 20 % . 21 %, 22%, 23%, 24%, 25%, 26%, 27%, 28%, 29% or 30% of EPA (preferably by weight) based on the total fatty acid content of the production host cell, organism, advantageously of a plant, especially of an oil crop such as soybean, oilseed rape, coconut, oil palm, safflower, flax, hemp, castor-oil plant, Calendula, peanut, cacao bean, sunflower or the abovementioned other monocotyledonous or dicotyledonous oil crops.
The seeds of the present invention shall comprise the oil or lipid of the present invention. Preferably, the oil or lipid is extracted, obtained, obtainable or produced from a plant, more preferably from seeds of a plant or plants (in particular a plant or plants of the present invention).
The oil or lipid thus can be obtained by the methods of the present invention. In particular, the plant oil or plant lipid is an extracted plant oil or lipid.. Also preferably, said oil or lipid is extracted, obtained, obtainable or produced from a plant, more preferably from batches of seeds or bulked seeds of a plant or plants (in particular a plant or plants of the present invention).
Preferably, the term "extracted" in connection with an oil or lipid refers to an oil or lipid that has been extracted from a plant, in particular from seeds of a plant or plants. More preferably, the term "extracted" in connection with an oil or lipid refers to an oil or lipid that has been extracted from a plant, in particular from batch of seeds or bulked seeds of a plant or plants. Such oil or lipid can be a crude composition. However, it may be also a purified oil or lipid in which e.g. the water has been removed. In an embodiment, the oil or lipid is not blended with fatty acids from other sources.
The oil or lipid of the present invention may be also an oil or lipid in a seed of plant. Preferably, said plant is a transgenic plant. More preferably, said plant is a plant of the present invention. In a particular preferred embodiment, the plant is a Brassica plant.
The oil or lipid of the present invention shall comprise fatty acids. In particular, the oil or lipid shall comprise fatty acids in esterified form. Thus, the fatty acids shall be esterified. Preferably, the oil or lipid of the present comprises one or more of following fatty acids (in esterified form): Eicosapentaenoic acid (Timnodonic acid, EPA, 20:5n-3), Clupanodonic acid (DPA n-3), and DHA ((Z,Z,Z,Z,Z,Z)-4,7,10,13,16,19-Docosahexaenoic acid). In an embodiment, the oil or lipid comprises EPA and DHA. Further, it is envisaged that the oil or lipid comprises EPA, DHA, and DPA n-3.
Preferred contents of the aforementioned fatty acids in the total fatty acid content of the lipid or oil of the present invention is further described in the following. In the following, ranges are given for the contents. The contents (levels) of fatty acids given herein are expressed as percentage (weight of a particular fatty acid) of the total weight of all fatty acids (present in the oil or lipid). The contents are thus, preferably given as weight percentage (% w/w). The contents given below are considered as high contents.
Preferably, the fatty acids are present in esterified form. Thus, the fatty acids shall be esterified fatty acids.
As set forth above, the oil or lipid may comprise EPA (20:5n-3). Preferably, the content of Eicosapentaenoic acid (Timnodonic acid, EPA, 20:5n-3) is between 0.1 % and 20%, more preferably between 2% and 15%, most preferably between 5% and 10% of the total fatty acid content. Further, it is envisaged that the content of EPA is between 5% and 15% of the total fatty acid content.
As set forth above, the oil or lipid may comprise Clupanodonic acid (DPA n-3). Preferably, the content of Clupanodonic acid (DPA n-3) is between 0.1 % and 10%, more preferably between 1 %
and 6%, most preferably between 2% and 4% of the total fatty acid content. In addition, the content of DPA n-3 may be at least 2% of the total fatty acids.
As set forth above, the oil or lipid may comprise DHA. Preferably, the content of DHA is between 1 % and 10%, more preferably between 1 % and 4%, most preferably between 1 % and 2% of the total fatty acid content. Further, it is envisaged that the content of DHA is between 1 % and 3% of the total fatty acid content.
A further embodiment according to the invention is the use of the oil, lipid, fatty acids and/or the fatty acid composition in feedstuffs, foodstuffs, dietary supplies, cosmetics or pharmaceutical compositions as set forth in detail below. The oils, lipids, fatty acids or fatty acid mixtures according to the invention can be used for mixing with other oils, lipids, fatty acids or fatty acid mixtures of animal origin such as, for example, fish oils. The term "composition" refers to any composition formulated in solid, liquid or gaseous form. Said composition comprises the compound of the invention optionally together with suitable auxiliary compounds such as diluents or carriers or further ingredients. In this context, it is distinguished for the present invention between auxiliary compounds, i.e. compounds which do not contribute to the effects elicited by the compounds of the present invention upon application of the composition for its desired purpose, and further ingredients, i.e. compounds which contribute a further effect or modulate the effect of the compounds of the present invention. Suitable diluents and/or carriers depend on the purpose for which the composition is to be used and the other ingredients. The person skilled in the art can determine such suitable diluents and/or carriers without further ado. Examples of suitable carriers and/or diluents are well known in the art and include saline solutions such as buffers, water, emulsions, such as oil/water emulsions, various types of wetting agents, etc.
In a more preferred embodiment of the oil-, fatty acid or lipid-containing composition, the said composition is further formulated as a pharmaceutical composition, a cosmetic composition, a foodstuff, a feedstuff, preferably, fish feed or a dietary supply.
The term "pharmaceutical composition" as used herein comprises the compounds of the present invention and optionally one or more pharmaceutically acceptable carrier. The compounds of the present invention can be formulated as pharmaceutically acceptable salts. Acceptable salts comprise acetate, methylester, Hel, sulfate, chloride and the like. The pharmaceutical compositions are, preferably, administered topically or systemically. Suitable routes of administration conventionally used for drug administration are oral, intravenous, or parenteral administration as well as inhalation. However, depending on the nature and mode of action of a compound, the pharmaceutical compositions may be administered by other routes as well. For example, polynucleotide compounds may be administered in a gene therapy approach by using viral vectors or viruses or liposomes.
Moreover, the compounds can be administered in combination with other drugs either in a common pharmaceutical composition or as separated pharmaceutical compositions wherein said separated pharmaceutical compositions may be provided in form of a kit of parts. The compounds are, preferably, administered in conventional dosage forms prepared by combining the drugs with standard pharmaceutical carriers according to conventional procedures. These procedures may involve mixing, granulating and compressing or dissolving the ingredients as appropriate to the desired preparation. It will be appreciated that the form and character of the pharmaceutically acceptable carrier or diluent is dictated by the amount of active ingredient with which it is to be combined, the route of administration and other well-known variables. The carrier(s) must be acceptable in the sense of being compatible with the other ingredients of the formulation and being not deleterious to the recipient thereof. The pharmaceutical carrier employed may be, for example, a solid, a gel or a liquid. Exemplary of solid carriers are lactose, terra alba, sucrose, talc, gelatin, agar, pectin, acacia, magnesium stearate, stearic acid and the like. Exemplary of liquid carriers are phosphate buffered saline solution, syrup, oil such as peanut oil and olive oil, water, emulsions, various types of wetting agents, sterile solutions and the like. Similarly, the carrier or diluent may include time delay material well known to the art, such as glyceryl mono- stearate or glyceryl distearate alone or with a wax. Said suitable carriers comprise those mentioned above and others well known in the art, see, e.g., Remington's Pharmaceutical Sciences, Mack Publishing Company, Easton, Pennsylvania. The diluent(s) is/are selected so as not to affect the biological activity of the combination. Examples of such diluents are distilled water, physiological saline, Ringer's solutions, dextrose solution, and Hank's solution. In addition, the pharmaceutical composition or formulation may also include other carriers, adjuvants, or nontoxic, nontherapeutic, nonimmunogenic stabilizers and the like. A therapeutically effective dose refers to an amount of the compounds to be used in a pharmaceutical composition of the present invention which prevents, ameliorates or treats the symptoms accompanying a disease or condition referred to in this specification.
The term "cosmetic composition" relates to a composition which can be formulated as described for a pharmaceutical composition above. For a cosmetic composition, likewise, it is envisaged that the compounds of the present invention are also, preferably, used in substantially pure form. Impurities, however, may be less critical than for a pharmaceutical composition. Cosmetic compositions are, preferably, to be applied topically.
Preferred cosmetic compositions comprising the compounds of the present invention can be formulated as a hair tonic, a hair restorer composition, a shampoo, a powder, a jelly, a hair rinse, an ointment, a hair lotion, a paste, a hair cream, a hair spray and/or a hair aerosol.
Seeds of three events described in detail in the examples section below have been deposited at ATCC under the provisions of the Budapest treaty on the International Recognition of the Deposit of Microorganisms for the Purposes of Patent Procedure, i.e. seeds of event "LBFLFK" = ATCC Designation "PTA-121703", seeds of event "LBFDHG" = ATCC designation "PTA-121704", and seeds of the event "LBFDAU" = ATCC Designation "PTA-122340". Applicants have no authority to waive any restrictions imposed by law on the transfer of biological material or its transportation
in commerce. Applicants do not waive any infringement of their rights granted under this patent or rights applicable to the deposited events under the Plant Variety Protection Act (7 USC sec. 2321 , et seq.), Unauthorized seed multiplication prohibited. This seed may be regulated according to national law. The deposition of seeds was made only for convenience of the person skilled in the art and does not constitute or imply any confession, admission, declaration or assertion that deposited seed are required to fully describe the invention, to fully enable the invention or for carrying out the invention or any part or aspect thereof. Also, the deposition of seeds does not constitute or imply any recommendation to limit the application of any method of the present invention to the application of such seed or any material comprised in such seed, e.g. nucleic acids, proteins or any fragment of such nucleic acid or protein.
The deposited seeds are derived from plants that were transformed with the T-DNA vector having a sequence as shown in SEQ ID NO: 3. In addition, the events are decribed in section B in more detail.
Preferred embodiments of the invention described in Section C are given herein below. The explanations and embodiments described in this section preferably apply mutatis mutandis to the following:
1. A method for increasing the tocopherol content of a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase.
2. The method according to Embodiment 1 , further comprising expressing in the plant at least one polynucleotide encoding an omega-3-desaturase.
3. The method according to Embodiment 1 or 2, further comprising expressing in the plant at least one polynucleotide encoding a delta-5-elongase.
4. The method according to any one of Embodiments 1 to 3, further comprising expressing in the plant at least one polynucleotide encoding a delta-4-desaturase. 5. The method according to any one of Embodiments 1 to 4, wherein at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6- desaturase, at least two polynucleotides encoding a delta-6-elongase, at least two polynucleotides encoding a delta-5-desaturase, and optionally at least three polynucleotides encoding an omega-3-desaturase, and at least one polynucleotide encoding a delta-5-elongase, and at least two polynucleotides encoding a delta-4-desaturase are expressed.
6. The method of any one of Embodiments 1 to 5, wherein at least one polynucleotide encoding a delta-6 elongase from Physcomitrella patens, at least one polynucleotide encoding a delta-6
elongase from Thalassiosira pseudonana, at least one polynucleotide encoding a delta-12 desaturase from Phythophthora sojae, at least one polynucleotide encoding a delta-6 desaturase from Ostreococcus tauri, and at least one polynucleotide encoding a delta-5 desaturase from Thraustochytrium sp. (in particular at least two polynucleotides encoding a delta-5 desaturase from Thraustochytrium sp.), and optionally at least one polynucleotides encoding a omega-3 desaturase from Pythium irregulare (in particular at least two polynucleotides encoding a omega- 3 desaturase from Pythium irregulare), at least one polynucleotide encoding a omega-3- desaturase from Phythophthora infestans, and at least one polynucleotide encoding a delta-5 elongase from Ostreococcus tauri, and at least one polynucleotide encoding a delta-4 desaturase from Thraustochytrium sp., and at least one polynucleotide encoding a delta-4 desaturase from Pavlova lutheri are expressed.
7. The method of any one of Embodiments 1 to 6, wherein the polynucleotides are recombinant polynucleotides.
8. The method of any one of Embodiments 1 to 7, wherein the polynucleotides are present on one T-DNA or construct which is stably integrated in the genome of the plant.
9. The method of any one of Embodiments 1 to 8, wherein the polynucleotides are expressed in the seeds of the plant.
10. The method of any one of Embodiments 1 to 9, wherein the tocopherol content in the seeds is increased as compared to the tocopherol content in seeds of a control plant. 1 1. The method of any one of Embodiments 1 to 10, wherein the tocopherol content is the total tocopherol content, the content of alpha-tocopherol, the content of beta-tocopherol, the content of gamma tocopherol, and/or the content of delta-tocopherol, in particular wherein the tocopherol content is the total tocopherol content, the content of gamma tocopherol, and/or the content of delta-tocopherol
12. The method of any one of Embodiments 1 to 1 1 , wherein the plant is an oilseed plant, in particular wherein the plant is a plant of the family Brassicaceae, preferably of genus Brassica and most preferably of a species comprising a genome of one or two members of the species Brassica oleracea, Brassica nigra and Brassica rapa, thus preferably of the species Brassica napus, Brassica carinata, Brassica juncea, Brassica oleracea, Brassica nigra or Brassica rapa.
13. The method of any one of Embodiments 1 to 12, further comprising the step of a selecting for a plant having an increased tocopherol content. 14. The method of any one Embodiments 1 to 13, further comprising the step of obtaining an oil from the plant, said oil having an increased tocopherol content, wherein preferably said oil is obtained under conditions which maintain the tocopherol content of the oil.
15. A construct or T-DNA comprising at least one expression cassette for a delta-12-desaturase, at least one at least one expression cassette for a delta-6-desaturase, at least one expression cassette for a delta-6-elongase, and at least one expression cassette for a delta-5-desaturase. 16. Construct or T-DNA according to Embodiment 15, further comprising at least one expression cassette for an omega-3-desaturase, at least one expression cassette for a delta-5-elongase, and/or at least one expression cassette for a delta-4-desaturase.
17. Construct or T-DNA according to Embodiment 15 or 16, wherein said construct or T-DNA comprises at least one expression cassette for a delta-6 elongase from Physcomitrella patens, at least one expression cassette for delta-12 desaturase from Phythophthora sojae, at least one expression cassette for a delta-6 desaturase from Ostreococcus tauri, at least one expression cassette for a delta-6 elongase from Thalassiosira pseudonana, , at least one expression cassette (in particular at least two) expression cassette(s) for a delta-5 desaturase from Thraustochytrium sp., and optionally at least one expression cassette (in particular at least two) expression cassette(s) for an omega-3 desaturase from Pythium irregulare, at least one expression cassette for a omega-3-desaturase from Phythophthora infestans, at least one expression cassette for a delta-5 elongase from Ostreococcus tauri, and at least one expression cassette for a delta-4 desaturase from Thraustochytrium sp., and at least one expression cassette for a delta-4 desaturase from Pavlova lutheri.
18. Use of a i) construct or T-DNA according to any one of Embodiments 15 to 17 or of ii) at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase for increasing the tocopherol content of a plant relative to a control plants.
19. A plant, plant part or plant cell transformed with a construct or T-DNA according to any one of Embodiments 15 to 17.
20. A plant or plant cell comprising at least one polynucleotide encoding a delta-12-desaturase, at least one polynucleotide encoding a delta-6-desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase. 21. The plant of Embodiment 20, wherein said plant comprises at least one polynucleotide encoding a delta-6 elongase from Physcomitrella patens, at least one polynucleotide encoding a delta-6 elongase from Thalassiosira pseudonana, at least one polynucleotide encoding a delta- 12 desaturase from Phythophthora sojae, at least one polynucleotide encoding a delta-6 desaturase from Ostreococcus tauri, and at least one polynucleotide encoding a delta-5 desaturase from Thraustochytrium sp. (in particular at least two polynucleotides encoding a delta- 5 desaturase from Thraustochytrium sp.), and optionally at least one polynucleotide encoding a omega-3 desaturase from Pythium irregulare (in particular at least two polynucleotides encoding a omega-3 desaturase from Pythium irregulare), at least one polynucleotide encoding a omega-
3-desaturase from Phythophthora infestans, and at least one polynucleotide encoding a delta-5 elongase from Ostreococcus tauri, and at least one polynucleotide encoding a delta-4 desaturase from Thraustochytrium sp., and at least one polynucleotide encoding a delta-4 desaturase from Pavlova lutheri.
22. The plant of any one of Embodiments 19 to 21 , wherein said polynucleotides are comprised by the same T-DNA.
23. The plant of any one of Embodiments 19 to 22, wherein said plant is a Brassica plant.
24. A Brassica plant having an increased tocopherol content a compared to a control plant, in particular in the seed.
25. A seed of the plant of any one of Embodiments 19 to 24.
26. Oil obtainable from or obtained from the seed of Embodiment 25, wherein said oil has an increased tocopherol content.
27. A method of plant oil or tocopherol production, comprising the steps of
i) growing a plant of any one of Embodiments 18 to 24 to obtain oil-containing seeds thereof, ii) harvesting said seeds, and
iii) extracting oil from said seeds harvested in step ii
28. The method of Embodiment 27, further comprising the step iv) of isolating tocopherol from the oil extracted in step iii).
The Examples for the invention described in Section C are the Examples indicated with a "C" (C1 and C2)
Section D: STABILISING FATTY ACIDS COMPOSITIONS
FIELD OF THE INVENTION (for the invention described in Section D) The present invention is concerned with materials and methods for the production of genetically modified plants, particularly where the plants are for the production of at least one unsaturated or polyunsaturated fatty acid. The invention is also concerned with identification of genes conveying an unsaturated fatty acid metabolic property to a plant or plant cell, and generally relates to the field of Delta-12 desaturases.
BACKGROUND OF THE INVENTION (for the invention described in Section D)
For the production of genetically modified plants it is not sufficient to test the effects of nucleic acid sequences in plants under greenhouse conditions. Unfortunately it has frequently been observed that plant metabolic properties differ in unpredictable ways when plants are grown in our field or under greenhouse conditions. Thus, when developing genetically modified plants having altered metabolic properties compared to the corresponding wild-type plant, it is necessary to test such plants in field trials. However, field trials entail a variety of disadvantages compared to plant growth under greenhouse conditions: for example, field trial plots have frequently been vandalised or devastated by animals, rendering all work of creating the originally planted plants and sending them on the field useless. Further, field trials require completion of Norma Rose procedures of regulatory supervision, making field trials rather cumbersome. Also, the amount of practical work in raising enough plants for a future test, devising a plot layout to plant the plants, and planting and monitoring the plants is more labour intensive than testing plants under greenhouse conditions, particularly as plant maintenance and monitoring work can be highly automated in the greenhouse. Furthermore, growing plants in an automatic greenhouse allows to inspect plant parts that are not readily accessible on a field, for example because on a field the plants are grown too densely or the interesting plant part is growing underground, for example plant roots. Thus it is generally desired to reduce the number of necessary field trials.
This is particularly true in the field of production of polyunsaturated fatty acids. Plants generally cannot produce unsaturated fatty acids of at least 20 carbon atoms in length and comprising at least two double bonds. Thus, to develop plants for the production of such unsaturated fatty acids, it is necessary to install the whole metabolic process starting from linoleic acid or iPhone-linolenic acid. Even though potentially suitable elongates and desaturase genes are known in the art and have been tested at least in model plants, it is uncertain which combinations of genes and promoters will provide economically satisfactory yields of unsaturated fatty acids in a stable way, particularly under the environmental conditions that change from growth period to growth period. Thus, field trials cannot be avoided when developing plants for the production of unsaturated fatty acids. One of the factors that has to be a certain and by field trials is whether or not the composition of the plant oil will be as expected even under field conditions. It has unfortunately
been observed that the composition of plant oils measured in individual plant seeds greatly differs even for seeds obtained from the very same plant, and particularly varies between plants grown under differing conditions. Thus, the composition of a plant oil obtained from harvesting a plurality of plants grown under field conditions cannot always reliably been predicted on the basis of oil composition analyses of individual plant seeds taken from plants grown under greenhouse conditions.
Reproducible production of a specific fatty acid profile is particularly important for commercial canola oil production. There is need to identify ways to reduce the variability in the fatty acid profile of canola oils produced in different environments.
The invention thus and generally aspires to remove or alleviate the above identified shortcomings and to provide materials and methods useful for reducing the number of field trials required for the manufacturing of a marketable plant variety producing unsaturated fatty acids. Further aspects and embodiments of the invention will become apparent below.
SUMMARY OF THE INVENTION (for the invention described in Section D)
The invention thus generally provides an assay method, comprising:
i) providing a plant capable of expressing a delta-12 desaturase, wherein said delta-
12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336,
and wherein the plant is also capable of expressing at least one or more enzymes of unsaturated fatty acid metabolism, of which enzymes at least one is capable of using linoleic acid as a substrate, and of which enzymes at least one is supposedly connected to a plant metabolic property,
ii) growing the plant, and
iii) measuring said plant metabolic property for said plant.
The invention also provides an assay method, comprising:
i) providing a plant group, wherein the plants of said group are capable of expressing a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336, and wherein the plants of said group are capable of expressing at least one or more enzymes of unsaturated fatty acid metabolism, of which enzymes at least one is capable of using linoleic acid as a substrate, and of which enzymes at least one is supposedly connected to a plant metabolic property,
ii) growing the plants of the plant group, and
iii) measuring said plant metabolic property for plants of said plant group.
Further, the invention provides a method of identifying a gene for conveying an unsaturated fatty acid metabolic property to a plant, comprising:
i) producing a plant comprising said gene,
ii) performing an assay method according to the invention, wherein said gene is expressed and said plant metabolic property is measured, and
iii) evaluating said plant for the presence and/or intensity of said unsaturated fatty acid metabolic property.
Also provided is a method of increasing delta-12 desaturase activity in a plant, comprising growing a plant expressing a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336. Likewise the invention provides a method of stabilizing delta-12 desaturase activity in a plant, comprising growing a plant expressing a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336.
Further provided is a method of producing one or more desired unsaturated fatty acids in a plant, comprising growing a plant,
said plant expressing, at least temporarily, a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336, and
said plant expressing one or more futher genes to convert linoleic acid to said one or more desired unsaturated fatty acids. The invention also provides a nucleic acid comprising
a) a gene coding for a Delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336 and wherein the gene does not code for a Delta-12 desaturase of any of the exact sequences SEQ ID NO. 329 to 336, or
b) a gene coding for a Delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336 and wherein the gene is operably linked to an expression control sequence, and wherein the expression control sequence is heterologous to said gene if the gene codes for any of the exact sequences according to SEQ ID NO. 329 to 336.
In the context of the present invention is also provided a plant cell comprising a gene coding for a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336.
And the invention provides a plant set comprising at least two plant groups,
wherein the plant or plants of each group are capable of expressing a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336,
and wherein the plant or plants of said groups comprise one or more genes coding for at least one or more enzymes of unsaturated fatty acid metabolism, of which enzymes at least one is capable of using linoleic acid as a substrate, and of which enzymes at least one is supposedly connected to a plant metabolic property, and wherein the plants of said groups differ in the expression of at least one of the enzymes of unsaturated fatty acid metabolism.
DETAILED DESCRIPTION OF THE INVENTION (for the invention described in Section D) The present invention thus provides an assay method. The assay method of the present invention is particularly suitable for determining the presence and/or intensity of a metabolic property. The metabolic property depends directly or indirectly on the presence or concentration of at least one unsaturated fatty acid in a plant cell, preferably of a fatty acid having at least 18 carbon atoms in length and at least two carbon-carbon double bonds. Thus, the metabolic property preferably is or depends on the production of unsaturated fatty acids and even more polyunsaturated fatty acids in plant cells.
According to the present invention, unsaturated fatty acids preferably are polyunsaturated fatty acids, that is fatty acids comprising at least two, more preferably at least three and even more preferably at least or exactly 4 carbon-carbon double bonds. Unsaturated fatty acids including polyunsaturated fatty acids are generally known to the skilled person, important unsaturated fatty acids are categorised into a omega-3, omega-6 and omega-9 series, without any limitation intended. Unsaturated fatty acids of the omega-6 series include, for example, and without limitation, linoleic acid (18:2 n-6; LA), gamma-linolenic acid (18:3 n-6; GLA), di-homo-gamma- linolenic acid (C20:3 n-6; DGLA), arachidonic acid (C20:4 n-6; ARA), adrenic acid (also called docosatetraenoic acid or DTA; C22:4 n-6) and docosapentaenoic acid (C22:5 n-6). Unsaturated fatty acids of the omega-3 series include, for example and without limitation, alpha-linolenic acid (18:3 n-3, ALA), stearidonic acid (18:4 n-3; STA or SDA), eicosatrienoic acid (C20:3 n-3; ETA), eicosatetraenoic acid (C20:4 n-3; ETA), eicosapentaenoic acid (C20:5 n-3; EPA), docosapentaenoic acid (C22:5 n-3; DPA) and docosahexaenoic acid (C22:6 n-3; DHA). Unsaturated fatty acids also include fatty acids with greater than 22 carbons and 4 or more double bonds, for example and without limitation, C28:8 (n-3). Unsaturated fatty acids of the omega-9 series include, for example, and without limitation, mead acid (20:3 n-9; 5,8,1 1 -eicosatrienoic
acid), erucic acid (22:1 n-9; 13-docosenoic acid) and nervonic acid (24:1 n-9; 15-tetracosenoic acid). Further unsaturated fatty acids are eicosadienoic acid (C20:2d1 1 ,14; EDA) and eicosatrienoic acid (20:3d1 1 ,14,17; ETrA). According to the present invention, the metabolic property preferably is the production and particularly preferably the yield of an omega-6 type and/or an omega-3 type unsaturated fatty acid. Such yield is preferably defined as the percentage of said fatty acid relative to the total fatty acids of an extract, preferably of a plant or seed oil. Thus, preferably the assay method of the present invention entails measuring the amount and/or concentration of an unsaturated fatty acid, preferably of an unsaturated fatty acid having at least 20 carbon atoms length and belonging to the omiga-3 or omega-6 series. The amount and/or concentration is determined on a plant extract, preferably a plant oil or plant lipids The term "lipids" refers to a complex mixture of molecules comprising compounds such as sterols, waxes, fat soluble vitamins such as tocopherols and carotenoid/retinoids, sphingolipids, phosphoglycerides, glycolipids such as glycosphingolipids, phospholipids such as phosphatidylethanolamine, phosphatidylcholine, phosphatidylserine, phosphatidylglycerol, phosphatidylinositol or diphosphatidylglycerol, monoacylglycerides, diacylglycerides, triacylglycerides or other fatty acid esters such as acetylcoenzyme A esters. "Lipids" can be obtained from biological samples, such as fungi, algae, plants, leaves, seeds, or extracts thereof, by solvent extraction using protocols well known to those skilled in the art (for example, as described in Bligh, E. G., and Dyer, J. J. (1959) Can J. Biochem. Physiol. 37: 91 1- 918).
The term "oil" refers to a fatty acid mixture comprising unsaturated and/or saturated fatty acids which are esterified to triglycerides. The oil may further comprise free fatty acids. Fatty acid content can be, e.g., determined by GC analysis after converting the fatty acids into the methyl esters by transesterification. The content of the various fatty acids in the oil or fat can vary, in particular depending on the source. It is known that most of the fatty acids in plant oil are esterified in triacylglycerides. In addition the oil of the invention may comprise other molecular species, such as monoacylglycerides, diacylglycerides, phospholipids, or any the molecules comprising lipids. Moreover, oil may comprise minor amounts of the polynucleotide or vector of the invention. Such low amounts, however, can be detected only by highly sensitive techniques such as PCR. Oil can be obtained by extraction of lipids from any lipid containing biological tissue and the amount of oil recovered is dependent on the amount of triacylglycerides present in the tissue. Extraction of oil from biological material can be achieved in a variety of ways, including solvent and mechanical extraction. Specifically, extraction of canola oil typically involves both solvent and mechanical extraction, the products of which are combined to form crude oil. The crude canola oil is further purified to remove phospholipids, free fatty acids, pigments and metals, and odifierous compounds by sequential degumming, refining, bleaching, and deoderorizing. The final product after these steps is a refined, bleached, and deodorized oil comprising predominantly fatty acids in the form of triglycerides.
The assay method of the present invention comprises the step of providing a plant. According to the present invention, the term "plant" shall mean a plant or part thereof in any developmental stage. Particularly, the term "plant" herein is to be understood to indicate a callus, shoots, root, stem, branch, leaf, flower, pollen and/or seed, and/or any part thereof. The plant can be monocotyledonous or dicotyledonous and preferably is a crop plant. Crop plants include Brassica species, corn, alfalfa, sunflower, soybean, cotton, safflower, peanut, sorghum, wheat, millet and tobacco. The plant preferably is an oil plant. Preferred plants are of order Brassicales, particularly preferred of family Brassicaceae. Even more preferred are plants of tribus Aethionemeae, Alysseae, Alyssopsideae, Anastaticeae, Anchonieae, Aphragmeae, Arabideae, Asteae, Biscutelleae, Bivonaeeae, Boechereae, Brassiceae, Buniadeae, Calepineae, Camelineae, Cardamineae, Chorisporeae, Cochlearieae, Coluteocarpeae, Conringieae, Cremolobeae, Crucihimalayeae, Descurainieae, Dontostemoneae, Erysimeae, Euclidieae, Eudemeae, Eutremeae, Halimolobeae, Heliophileae, Hesperideae, Iberideae, Isatideae, Kernereae, Lepidieae, Malcolmieae, Megacarpaeeae, Microlepidieae, Noccaeeae, Notothlaspideae, Oreophytoneae, Physarieae, Schizopetaleae, Scoliaxoneae, Sisymbrieae, Smelowskieae, Stevenieae, Thelypodieae, Thiaspideae, Turritideae or Yinshanieae. Even more preferred are plants of genus Aethionema, Moriera, Alyssoides, Alyssum, Aurinia, Berteroa, Bornmuellera, Bornmuellera x Leptoplax, Clastopus, Clypeola, Degenia, Fibigia, Galitzkya, Hormathophylla, Lepidotrichum, Leptoplax, Phyllolepidum, Physocardamum, Physoptychis, Straussiella, Alyssopsis, Calymmatium, Dielsiocharis, Olimarabidopsis, Anastatica, Cithareloma, Diceratella, Eigia, Eremobium, Farsetia, Lachnocapsa, Lobularia, Malcolmia, Maresia, Morettia, Notoceras, Parolinia, Anchonium, Eremoblastus, Iskandera, Matthiola, Micrantha, Microstigma, Petiniotia, Sterigmostemum, Synstemon, Zerdana, Aphragmus, Lignariella, Abdra, Arabis (rockcress), Arcyosperma, Athysanus, Aubrieta, Baimashania, Botschantzevia, Dendroarabis, Draba, Drabella, Erophila, Pachyneurum, Pseudodraba, Scapiarabis, Schivereckia, Sinoarabis, Tomostima, Asta, Biscutella, Megadenia, Bivonaea, Anelsonia, Boechera, Borodinia, Cusickiella, Nevada, Phoenicaulis, Polyctenium, Sandbergia, Ammosperma, Brassica, Brassica x Raphanus, Cakile, Carrichtera, Ceratocnemum, Coincya, Cordylocarpus, Crambe, Crambella, Didesmus, Diplotaxis, Douepea, Enarthrocarpus, Eremophyton, Eruca, Erucaria, Erucastrum, Euzomodendron, Fezia, Foleyola, Fortuynia, Guiraoa, Hemicrambe, Henophyton, Hirschfeldia, Kremeriella, Moricandia, Morisia, Muricaria, Nasturtiopsis, Orychophragmus, Otocarpus, Physorhynchus, Pseuderucaria, Psychine, Raffenaldia, Raphanus, Rapistrum, Rytidocarpus, Savignya, Schouwia, Sinapidendron, Sinapis, Succowia, Trachystoma, Vella, Zilla, Bunias, Calepina, Goldbachia, Leiocarpaea, Spirorhynchus, Camelina, Capsella, Catolobus, Cheesemania, Chrysochamela, Neslia, Noccidium, Pseudoarabidopsis, Aplanodes, Armoracia, Barbarea (winter cress), Cardamine (bittercresses), lodanthus, Iti, Leavenworthia, Nasturtium, Neobeckia, Ornithocarpa, Planodes, Rorippa (yellowcress), Selenia, Sisymbrella, Chorispora, Diptychocarpus, Litwinowia, Neuroloma, Parrya, Pseudoclausia, Cochlearia, lonopsidium, Callothlaspi, Coluteocarpus, Eunomia, Kotschyella, Noccaea, Vania, Conringia, Zuvanda, Cremolobus, Menonvillea, Crucihimalaya, Ladakiella, Transberingia, Descurainia, Hornungia, Hymenolobus, lanhedgea, Pritzelago, Robeschia, Tropidocarpum, Clausia, Dimorphostemon, Dontostemon, Erysimum, Syrenia, Atelanthera, Braya, Catenulina, Christolea, Cryptospora, Cymatocarpus, Dichasianthus, Dilophia, Euclidium, Lachnoloma, Leiospora, Lepidostemon,
Leptaleum, Neotorularia, Octoceras, Phaeonychium, Pycnoplinthopsis, Pycnoplinthus, Rhammatophyllum, Shangrilaia, Sisymbriopsis, Solms-laubachia, Spryginia, Streptoloma, Tetracme, Aschersoniodoxa, Brayopsis, Dactylocardamum, Eudema, Onuris, Xerodraba, Chalcanthus, Eutrema, Pegaeophyton, Thellungiella, Exhalimolobos, Halimolobos, Mancoa, Pennellia, Sphaerocardamum, Heliophila (Cape stock), Hesperis, Tchihatchewia, Iberis, Teesdalia, Boreava, Chartoloma, Glastaria, Isatis, Myagrum, Pachypterygium, Sameraria, Schimpera, Tauscheria, Kernera, Rhizobotrya, Acanthocardamum, Coronopus, Cyphocardamum, Delpinophytum, Lepidium, Lithodraba, Stubendorffia, Winklera, Megacarpaea, Pugionium, Arabidella, Ballantinia, Blennodia, Carinavalva, Cuphonotus, Drabastrum, Geococcus, Harmsiodoxa, Irenepharsus, Menkea, Microlepidium, Pachycladon, Pachymitus, Phlegmatospermum, Scambopus, Stenopetalum, Notothlaspi, Murbeckiella, Oreophyton, Dimorphocarpa, Dithyrea, Lyrocarpa, Nerisyrenia, Paysonia, Physaria (bladderpods), Synthlipsis, Caulanthus, Mathewsia, Schizopetalon, Sibaropsis, Streptanthella, Werdermannia, Scoliaxon, Lycocarpus, Schoenocrambe, Sisymbrium, Hedinia, Smelowskia, Berteroella, Macropodium, Pseudoturritis, Ptilotrichum, Stevenia, Catadysia, Chaunanthus, Chilocardamum, Chlorocrambe, Coelophragmus, Dictyophragmus, Dryopetalon, Englerocharis, Guillenia, Hesperidanthus, Ivania, Mostacillastrum, Neuontobotrys, Phlebolobium, Polypsecadium, Pringlea, Pterygiosperma, Romanschulzia, Sarcodraba, Sibara, Stanleya, Streptanthus, Thelypodiopsis, Thelypodium, Thysanocarpus, Warea, Weberbauera, Alliaria, Didymophysa, Elburzia, Gagria, Graellsia, Pachyphragma, Parlatoria, Peltaria, Peltariopsis, Pseudocamelina, Pseudovesicaria, Sobolewskia, Thlaspi, Turritis, Hilliella, Yinshania. Most preferred are plants of species Brassica aucheri, Brassica balearica, Brassica barrelieri, Brassica carinata, Brassica carinata x Brassica napus, Brassica carinata x Brassica rapa, Brassica carinata x Brassica juncea, Brassica cretica, Brassica deflexa, Brassica desnottesii, Brassica drepanensis, Brassica elongata, Brassica fruticulosa, Brassica gravinae, Brassica hilarionis, Brassica incana, Brassica insularis, Brassica juncea, Brassica macrocarpa, Brassica maurorum, Brassica montana, Brassica napus, Brassica napus x Brassica juncea, Brassica napus x Brassica nigra, Brassica nigra, Brassica oleracea, Brassica oxyrrhina, Brassica procumbens, Brassica rapa, Brassica repanda, Brassica rupestris, Brassica ruvo, Brassica souliei, Brassica spinescens, Brassica tournefortii or Brassica villosa.
The plant of the assay method of the present invention is capable of expressing a Delta-12 desaturase as defined herein. The plant can be provided by any appropriate means. For example, the plant can be provided by transforming a plant cell with a nucleic acid comprising a gene coding for the Delta-12 desaturase of the present invention and raising such transformed plant cell to a plant sufficiently developed for measuring the plant metabolic property. According to the invention, a plant can also be provided in the form of an offspring of such transformed plant. Such offspring may be produced vegetatively from material of a parent plant, or may be produced by crossing a plant with another plant, preferably by inbreeding.
The plant is capable of expressing a Delta-12 desaturase. According to the invention, the term "capable of expressing a gene product" means that a cell will produce the gene product provided that the growth conditions of the sale are sufficient for production of said gene product. For example, a plant is capable of expressing a Delta-12 desaturase is a cell of said plant during any developmental stage of said plant will produce the corresponding Delta-12 desaturase. It goes
without saying that where expression depends on human intervention, for example the application of an inductor, a plant is likewise considered capable of expressing the Delta-12 desaturase.
According to the invention, the plant is capable of expressing a Delta-12 desaturase, wherein said Delta-12 desaturase has at least 50% total amino acid sequence identity to any of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to any of the sequences SEQ ID NO. 328 to 336. A Delta-12 desaturase having this desired sequence identity and/or sequence similarity is also called a Delta-12 desaturase of the present invention. A Delta- 12 desaturase according to the invention is an enzyme catalysing (at least) the conversion of oleic acid to linoleic acid. For a metabolic pathway for the production of unsaturated and polyunsaturated fatty acids, see for example figure one of WO2006100241. Examples of Delta- 12 desaturases referred to herein are:
SEQ ID NO. 328 artificial Delta-12 desaturase sequence
SEQ ID NO. 329 Uniprot G5A275_PHYSP of Phytophthora_sojae
SEQ ID NO. 330 Uniprot H3G9L1_PHYRM of Phytophthora_ramorum
SEQ ID NO. 331 Uniprot G4XUM4_PHYIN of Phytophthorajnfestans
SEQ ID NO. 332 Uniprot M4 BXW8_H YAAE of Hyaloperonospora_arabidopsidis
SEQ ID NO. 333 Uniprot W2PDL4_PHYPN of Phytophthora_parasitica
SEQ ID NO. 334 Uniprot W2LW72_PHYPR of Phytophthora_parasitica
SEQ ID NO. 335 Uniprot W2ZYI2_PHYPR of Phytophthora_parasitica
SEQ ID NO. 336 Uniprot Q6UB74_9STRA of Saprolegnia diclina
It has now surprisingly been found that expression of a Delta-12 desaturase of the present invention reduces the difference between fatty acid composition of plants grown under greenhouse and field conditions, respectively. This was unexpected, as plants generally are capable of expressing at least one Delta-12 desaturase even as wild type plants. However, as seen in the accompanying examples, the percentage of linoleic acid (and correspondingly also the concentration of other unsaturated fatty acids metabolically downstream of linoleic acid) differs between wild-type plants grown under greenhouse and field conditions, respectively. However, where plants express a delta-12 desaturases of the present invention, optionally in addition to the one or more type delta-12 desaturase(s), the difference in oil composition between plants raised in the greenhouse and plants raised under field conditions is greatly diminished or even removed. Thus, by making use of the delta-12 desaturases of the present invention it is possible to improve the delta-12 desaturases conversion efficiency in plants grown under greenhouse conditions. The assay method of the present invention hence effectively allows to simulate the influence of field conditions on a plant metabolic property, wherein said metabolic property is directly or indirectly connected to the presence and/or concentration of linoleic acid in a plant cell as described above. Using an assay method of the present invention therefore unexpectedly allows to screen plants for such metabolic properties with higher reliability and prediction accuracy of said plant metabolic property. Effectively the assay method of the present invention enables the skilled person to reduce the number of field trials required for development of a commercially viable plant variety producing unsaturated or even more preferably polyunsaturated fatty acids.
A gene coding for a Delta-12 desaturase of the present invention can be obtained by de novo synthesis. Starting from any of the amino acid sequences SEQ ID NO. 328 to 336, the skilled person can reverse-translate the selected sequence into a nucleic acid sequence and have the sequence synthesised. As described herein, the skilled person can also introduce one or more mutations, including insertions, substitutions and deletions to the amino acid sequence chosen or the corresponding nucleic acid sequence. For reverse translation, the skilled person can and should use nucleic acid codons such as to reflect codon frequency of the plant intended for expression of said Delta-12 desaturase of the present invention. By using any of the amino acid sequences according to SEQ ID NO. 328 to 336 as such or one or more mutations, the person can obtain using routine techniques and standard equipment, a Delta-12 desaturase having the beneficial properties described herein and exhibiting these beneficial properties in numerous plant species.
Instead of starting from any of the amino acid sequences according to SEQ ID NO. 328 to 336, the skilled person may also obtain a Delta-12 desaturase from any organism of class oomycetes, preferably of order Peronosporales, Pythiales or Saprolegniales, particularly preferably of genus Basidiophora, Benua, Bremia, Erapthora, Graminivora, Hyaloperonospora, Novotelnova, Paraperonospora, Perofascia, Peronosclerospora, Peronospora, Phytophthora, Phytopythium, Plasmopara, Plasmoverna, Protobremia, Pseudoperonospora, Salisapiliaceae, Sclerophthora, Sclerospora or Viennotia, or genus Diasporangium, Elongisporangium, Globisporangium, Halophytophthora, Ovatisporangium, Pilasporangium or Pythium, or genus Achlya, Aphanomyces, Aplanes, Aplanopsis, Aquastella, Brevilegnia, Calyptralegnia, Dictyuchus, Geolegnia, Isoachlya, Leptolegnia, Newbya, Plectospira, Protoachlya, Pythiopsis, Saprolegnia, Scoliolegnia or Thraustotheca. Methods for obtaining such Delta-12 desaturase nucleic acid and amino acid sequences are described for example in international publication WO 2006 100 241 . Particularly preferably, the skilled person starts with a Delta-12 desaturase nucleic acid sequence obtainable or obtained from any member of the above genera, preferably the genera Phytophthora, Hyaloperonospora or Saprolegnia. Even more preferably, the skilled person starts by using the nucleic acid sequence coding for a Delta-12 desaturase obtainable or obtained from any member of species Phytophthora sojae, Phytophthora parasitica, Phytophthora ramorum or Phytophthora infestans.
The amino acid sequence of the Delta-12 desaturase of the present invention may be identical to any of the sequences according to SEQ ID NO. 328 to 336. However, in certain embodiments it is preferred that the amino acid sequence of the Delta-12 desaturase of the present invention is not the sequence according to SEQ ID NO. 328 and/or is not the amino acid sequence according to SEQ ID NO. 329 and/or is not the amino acid sequence according to SEQ ID NO. 330 and/or is not the amino acid sequence according to SEQ ID NO. 331 and/or is not the amino acid sequence according to SEQ ID NO. 332 and/or is not the amino acid sequence according to SEQ ID NO. 333and/or is not the amino acid sequence according to SEQ ID NO. 334 and/or is not the amino acid sequence according to SEQ ID NO. 335 and/or is not the amino acid sequence according to SEQ ID NO. 336. Where the skilled person for any reason wants to avoid any one
or more of the amino acid sequences according to SEQ ID NO. 328 to 336, the skilled person can use any of the remaining sequences of this set of sequences. However, the skilled person can also make up a new amino acid and corresponding nucleic acid sequence by selecting a base sequence from the set of amino acid sequences according to SEQ ID NO. 328 to 336 and introducing one or more mutations (insertions, substitutions and/or deletions) at appropriate positions of the base sequence to obtain a derived sequence. Generally, the skilled person will take into account that the higher the sequence identity and/or similarity between base sequence and derived sequence, the more will the corresponding derived Delta-12 desaturase resemble the Delta-12 desaturase activity that corresponds to the desaturase of the base sequence. Thus, if the skilled person uses a mutated Delta-12 desaturase according to the present invention and such mutated Delta-12 desaturase unexpectedly does not convey the benefits of a Delta-12 desaturase of the present invention, the skilled person should reduce the number of differences of the Delta-12 desaturase sequence to increase resemblance of any of the sequences according to SEQ ID NO. 328 to 336.
For substituting amino acids of a base sequence selected from any of the sequences SEQ ID NO. 328 to 336 without regard to the occurrence of amino acid in other of these sequences, the following applies, wherein letters indicate L amino acids using their common abbreviation and bracketed numbers indicate preference of replacement (higher numbers indicate higher preference): A may be replaced by any amino acid selected from S (1 ), C (0), G (0), T (0) or V (0). C may be replaced by A (0). D may be replaced by any amino acid selected from E (2), N (1 ), Q (0) or S (0). E may be replaced by any amino acid selected from D (2), Q (2), K (1 ), H (0), N (0), R (0) or S (0). F may be replaced by any amino acid selected from Y (3), W (1 ), I (0), L (0) or M (0). G may be replaced by any amino acid selected from A (0), N (0) or S (0). H may be replaced by any amino acid selected from Y (2), N (1 ), E (0), Q (0) or R (0). I may be replaced by any amino acid selected from V (3), L (2), M (1 ) or F (0). K may be replaced by any amino acid selected from R (2), E (1 ), Q (1 ), N (0) or S (0). L may be replaced by any amino acid selected from I (2), M (2), V (1 ) or F (0). M may be replaced by any amino acid selected from L (2), I (1 ), V (1 ), F (0) or Q (0). N may be replaced by any amino acid selected from D (1 ), H (1 ), S (1 ), E (0), G (0), K (0), Q (0), R (0) or T (0). Q may be replaced by any amino acid selected from E (2), K (1 ), R (1 ), D (0), H (0), M (0), N (0) or S (0). R may be replaced by any amino acid selected from K (2), Q (1 ), E (0), H (0) or N (0). S may be replaced by any amino acid selected from A (1 ), N (1 ), T (1 ), D (0), E (0), G (0), K (0) or Q (0). T may be replaced by any amino acid selected from S (1 ), A (0), N (0) or V (0). V may be replaced by any amino acid selected from I (3), L (1 ), M (1 ), A (0) or T (0). W may be replaced by any amino acid selected from Y (2) or F (1 ). Y may be replaced by any amino acid selected from F (3), H (2) or W (2).
According to the invention, sequence identity and similarity are calculated by pairwise alignment of two sequences according to the algorithm of Needleman and Wunsch (J. Mol. Biol. 1970, 48(3), 433-453) using, for amino acid sequence comparisons, a gap opening penalty of 12 and a gap extension penalty of 2 and applying the BLOSUM62 matrix, and using for nucleic acid sequence comparisons a gap opening penalty of 16 and a gap extension penalty of 4. Identity is then calculated as the number of identical positions in the alignment divided by the length of the
alignment. Similarity is calculated as the number of positions where amino acids of both sequences have a weight of at least zero or larger in the BLOSUM62 matrix and then dividing this number by the length of the alignment. The Delta-12 desaturase of the present invention preferably has at least 50% amino acid sequence identity to any of the sequences SEQ ID NO. 328 to 336. Most preferably, the Delta-12 desaturase of the present invention has at least 50% amino acid sequence identity to sequence SEQ ID NO. 329. This desaturase can be shown to be functional in numerous plant species, it is easy to obtain and conveys the benefits of the desaturase of the present invention. Preferably, the Delta-12 desaturase of the present invention has at least 55% amino acid sequence identity to any of the sequences SEQ ID NO. 328, 329, 330, 331 , 332, 333, 334, 335, 336, 337, 338 and 339, wherein identity to SEQ ID NO. 329 is particularly preferred, even more preferably at least 65%, even more preferably at least 72%, even more preferably at least 78%, even more preferably at least 80%, even more preferably at least 82%, even more preferably at least 89%, even more preferably at least 91 %, even more preferably at least 96%. The Delta-12 desaturase of the present invention preferably has at least 50% amino acid sequence identity to any of the sequences SEQ ID NO. 328 to 336. Most preferably, the Delta-12 desaturase of the present invention has at least 50% amino acid sequence identity to sequence SEQ ID NO. 329. This desaturase can be shown to be functional in numerous plant species, it is easy to obtain and conveys the benefits of the desaturase of the present invention. Preferably, the Delta-12 desaturase of the present invention has at least 60% amino acid sequence identity to any of the sequences SEQ ID NO. 1 , 2, 3, 4, 5, 6, 7, 8 or 9, where similarity to SEQ ID NO. 329 is particularly preferred, even more preferably at least 73%, even more preferably at least 75%, even more preferably at least 89%, even more preferably at least 95%, even more preferably at least 96%, even more preferably at least 97%, even more preferably at least 98%, even more preferably at least 99%. Preferably, the delta-12 desaturase of the present invention has both the required or preferred minimal identity and the required or preferred minimal similarity. The higher the similarity and identity between the amino acid sequence of the Delta-12 desaturase of the present invention and the amino acid sequence according to SEQ ID NO. 1 , 2, 3, 4, 5, 6, 7, 8 or 9, the more reliable will the Delta-12 desaturase of the present invention exhibit Delta-12 desaturase activity in a plant cell and convey the benefits of the present invention.
Preferably, the amino acid sequence of the Delta-12 desaturase of the present invention differs from the amino acid sequences according to any of SEQ ID NO. 328 to 336 only at such one or more positions where at least one of the amino acid sequences SEQ ID NO. 328 to 336 differs from at least one other of the sequences SEQ ID NO. 328 to 336, preferably not allowing any amino acid insertion or deletion. Preferably, the amino acid sequence of the Delta-12 desaturase of the invention can be thought to be the result of exchanging selected amino acids from one chosen base sequence of the sequences SEQ ID NO. 328 to 336 for the corresponding amino acid at the respective positions of any other of the sequences SEQ ID NO. 328 to 336. Also preferably, any mutation should increase the similarity, or, even more preferably, the identity, of the amino acid sequence of the Delta-12 desaturase of the present invention to that of a sequence
according to SEQ ID NO. 328 to 336 and reduce the similarity or, even more preferably, the identity, to an amino acid sequence according to SEQ ID NO. 10 to 12.
For the reasons indicated above, the Delta-12 desaturase of the present invention preferably consists of the amino acid sequence SEQ ID NO. 329. Less preferably, the amino acid sequence of the Delta-12 desaturase of the present invention differs from the amino acid sequence according to SEQ ID NO. 329 only at such positions where any of the sequences SEQ ID NO. 338 or 330 to 336 differ from the amino acid sequence of SEQ ID NO. 329. More preferably, the Delta-12 desaturase of the present invention does not differ from the amino acid sequence of SEQ ID NO. 329 by an insertion or deletion and thus only comprises one or more substitutions. Even more preferably, the Delta-12 desaturase of the present invention consists of an amino acid sequence that differs from SEQ ID NO. 329 only by amino acids found at the corresponding position of any of the other amino acid sequence SEQ ID NO. 328 and 330-336.
The plant of the present invention is further capable of expressing at least one or more enzymes of unsaturated fatty acid metabolism. Preferably, such enzymes are capable of using an unsaturated fatty acid of the omega-6 and/or, more preferably, of the omega-3 series as a substrate. Preferred activities of the enzymes are: desaturase, elongase, ACS, acylglycerol-3- phosphate acyltransferase (AGPAT), choline phosphotransferase (CPT), diacylglycerol acyltransferase (DGAT), glycerol-3-phosphate acyltransferase (GPAT), lysophosphatidate acyltransferase (LPAT), lysophosphatidylcholine acyltransferase
(LPCAT),lysophosphatidylethanolamine acyltransferase (LPEAT), lysophospholipid acyltransferase (LPLAT), phosphatidate phosphatase (PAP), phospholipid:diacylglycerol acyltransferase (PDAT), phosphatidylcholine:diacylglycerol choline phosphotransferase (PDCT), particularly Delta-8 desaturase, Delta-6 desaturase, Delta-5 desaturase, Delta-4 desaturase, Delta-9 elongase, Delta-6 elongase, Delta-5 elongase, omega-3 desaturase.
At least one of the enzymes is capable of using linoleic acid as substrate. Such enzymes are known to the skilled person as omega-3 desaturases, Delta-15 desaturases, Delta-9 along gazes and Delta-6 desaturases. It is possible that one or more enzymes of unsaturated fatty acid metabolism can have more than one activity. For example, it is common for omega-3 desaturases to be also Delta-15 desaturases and/or Delta-17 desaturases and/or Delta-19 desaturases. Further preferred enzymes of unsaturated fatty acid metabolic is our Delta-6 along gazes, Delta- 8 desaturases, Delta-5 desaturases, Delta-5 elongates this and Delta-4 desaturases. At least one of these enzymes is supposedly connected to a plant metabolic property. Preferably, the metabolic property is the presence and/or concentration of the product of the respective enzyme. Thus, preferably the plant metabolic property is the presence and/or concentration of any of GL a, SDA, EDA, ETrA, the GLA, EDTA, ARA, EPA, DTA, DPA and DHA, wherein particularly preferred are the concentration of ARA, EPA and DHA. In the assay method of the present invention, the plant is capable of expressing the Delta-12 desaturase of the present invention and at least one more enzyme of unsaturated fatty acid metabolic is and are grown. "Growing" for the present invention means to nurture plant material, preferably a plant can use, embryo or seed, such that cells of said plant material can develop and
preferably multiply, such that at least one cell of the developed plant material can be expected to exhibit the plant metabolic property. For example, where the expression of a gene coding for an enzyme of unsaturated fatty acid metabolism, for example a desaturase or elongates, is under the control of a tissue-specific promoter, the plant material is grown such that the corresponding tissue develops.
The plant metabolic property is then measured by any suitable means. For example, the concentration of fatty acids in the form of free fatty acids or in the form of mono-, di- or triglycerides can be measured from extracts of plant material, preferably of plant seeds and most preferably from seed oil.
The assay method of the present invention preferably is not performed only on one plant but on a group of plants. This way, the measured plant metabolic properties will be statistically more significant than measurements taken only on plant material of a single plant, for example a single seed. Even though assay methods of the present invention preferably are performed on plant groups, assay methods of the present invention performed on single plants are also useful and beneficial. Such methods allow for a fast screening plants and thus are particularly suitable for high throughput evaluation of genes and gene combinations coding for enzymes of unsaturated fatty acid metabolism.
As indicated above, a preferred assay method of the present invention comprises
1 ) providing a plant group, wherein the plants of said group are capable of expressing a Delta-12 desaturase of the present invention,
and wherein the plants of said group are capable of expressing at least one or more enzymes of unsaturated fatty acid metabolism, of which enzymes at least one is capable of using linoleic acid as a substrate, and of which enzymes at least one is supposedly connected to a plant metabolic property,
2) growing the plants of the plant group, and
3) measuring said plant metabolic property for at least one, preferably at least 2 and even more preferably at least 3, 4, 5, 6 or more plants of said plant group.
As indicated above, the present invention aspires to and allows to reduce the number of field trials. Thus, the assay method of the present invention (performed on single plants or plant groups) is preferably performed such that the plant or plants are grown under greenhouse conditions. According to the present invention, greenhouse conditions are environmental conditions where intensity can be controlled and adjusted at will, and may also be refered to as controlled environment conditions. Greenhouse conditions are generally maintained using standard equipment, for example a germination chamber, a growth cabinet or a greenhouse. Such equipment particularly allows to control more than one environmental condition, preferably light, temperature (of growth material and of air bracket, humidity and growth medium composition, particularly water content, and the concentration of growth regulators like water, nutrients and protection agents like bactericides, fungicides, helminticides and insecticidal agents. Greenhouses, growth cabinets and germination chambers (that is according to the invention equipment for maintaining greenhouse conditions) also allow controlled changes of one or more
of the aforementioned environmental conditions, for example in a diurnal rhythm to simulate for example short day or long day light conditions and/or drought or nutrient deficiency conditions. For automated greenhouses, such conditions can also be controlled for each individual plant or group of plants. Thus, for example greenhouse conditions allow to subject single or more plants to stress conditions at selected stages of plant development and for a selected duration.
For Brassica species grown in the greenhouse, temperatures can range from 10°C to 30°C, but the preferred conditions include 15-22°C day and 12-20°C night temperatures. Preferably, there is a 3°C difference between night and day. Colder day and night temperatures can be used to slow the growth rate of plants or to assess the effect of temperature on plant growth. A preferred light cycle is 16 hrs light and 8 hrs dark. A shorter day length can be used to delay growth or to delay reproduction. The preferred light intensity is 200-300 micromoles of photons m-2 s-1 , but it can range from 100-1200 micromoles of photons m-2 s-1. Humidity can range from 20-70%, with the preferred range being 30-50%. Lower humidity is useful to limit disease incidence.
The gene coding for the Delta-12 desaturase of the present invention preferably is operably linked to an expression control sequence to allow constitutive or non-constitutive expression of said gene. Expression control sequences according to the present invention are known to the skilled person as promoters, transcription factor binding sites and regulatory nucleic acids like for example RNAi. Preferably, the expression control sequence directs expression of the gene in a tissue-specific manner. Where the plant is an oil seed plant, preferably of a Brassica species, expression of the gene preferably is specific to plant seeds in one or more of their developmental stages. According to the present invention, tissue-specific expression does not require the total absence of gene expression in any other tissue. However, tissue-specific expression for a selected tissue means that the maximum amount of mRNA transcript in this tissue is at least 2- fold, preferably at least 5-fold, even more preferably at least 10-fold, even more preferably at least 20-fold, even more preferably at least 50-fold and most preferably at least 100-fold the maximum amount of said mRNA in the other tissues. Furthermore, expression control sequences are known to the skilled person which allow induction or repression of expression by a signal applied by a user, for example application of an inductor like IPTG.
The Delta-12 desaturase of the present invention can be present in the plant or plants of the SA method of the present invention as a single copy gene or in multiple gene copies. It is an advantage of the present invention that even a single copy of the Delta-12 desaturase gene of the present invention can be shown to be sufficient for reducing or even removing differences in oil composition between plants grown under greenhouse and field conditions, and it can also be shown that a single copy of the Delta-12 desaturase gene of the present invention is sufficient for increasing Delta-12 desaturase conversion efficiencies as defined below. This is a considerable advantage, as the production of polyunsaturated fatty acids like EPA and DHA generally requires the introduction of at least 3 genes to provide the activities of a Delta-6 desaturase/Delta-6 elongase, Delta-9 elongase/Delta-8 desaturase, Delta-5 desaturase, Delta-5 elongase and/or Delta-4 desaturase. Thus, establishing a metabolic pathway for production of polyunsaturated fatty acids requires transformation of plants either by very long nucleic acid constructs (for example using a technique known in the art as BiBAC) or multiple transformations using shorter
nucleic acid constructs. All of these techniques can be laborious, and labour intensity generally increases the more nucleic acids and/or the longer nucleic acids have to be introduced into a plant. Thus, the possibility of achieving the advantages conferred by the present invention by using only a single gene coding for the Delta-12 desaturase of the present invention allows the skilled person to materialise these benefits with minimal additional work. Also, expression of the- 12 desaturase of the present invention does not require functional inactivation of one or more Delta-12 desaturase genes of the plant in question. The skilled person may even decide to prepare one or more plant varieties comprising one or another gene coding for a Delta-12 desaturase of the present invention under the control of a desired expression control sequence, for example a seed-specific promoter. Using such plant varieties, the skilled person can then introduce the genes of unsaturated fatty acid metabolism using normal constructs and without having to increase construct length by an additional Delta-12 desaturase gene and its corresponding expression control sequence. Where the gene coding for the Delta-12 desaturase of the present invention is under the control of a seat-specific expression control sequence mRNA transcripts of the gene are preferably detectable, for example by qPCR, at least 25 days, more preferably at least 20 days and even more preferably at least 15 days after flowering of the plant. Also preferably, the maximum expression of the Delta-12 desaturase gene of the present invention is before 40 days after inflorescence, more preferably before 35 days after inflorescence and even more preferably before 33 days after inflorescence. Preferably, the maximum expression, for example as determined by qPCR, is from day 22 day 35 after inflorescence, even more preferably from day 21 to 31 after inflorescence. To achieve such expression pattern, the SBP promoter or, more preferably, the Napin promoter are particularly preferred. Thus, the present invention allows to materialise the benefits conferred by the use of the Delta-12 desaturase of the present invention without having to express said Delta-12 desaturase constitutively throughout the plant or constitutively throughout seed-development. Constitutive gene expression requires a plant cell to produce a gene product regardless of whether it is beneficial or even necessary or not. Thus, the present invention allows to minimise the stress inflicted upon the plant in question.
The Delta-12 desaturase of the present invention preferably is expressed in the same plant cell also expressing the other at least one or more enzymes of unsaturated fatty acid metabolism. It is possible but not necessary that the Delta-12 desaturase of the present invention is expressed at the same time as one, some or all of said other genes of unsaturated fatty acid metabolism. For example, the Delta-12 desaturase of the present invention may reach a maximum expression as determined by qPCR during the 1 st two thirds of seed development time (preferably, as described above, during days 20 and 31 after inflorescence) with mRNA concentration of said Delta-12 desaturase gene being halved or even less at further stages of seed development, whereas the one or more other genes of unsaturated fatty acid metabolism may start to be or continue to be expressed even after maximal expression of the Delta-12 desaturase gene of the present invention. This is beneficial for reducing unwanted intermediary products in the formation of a polyunsaturated fatty acid. For example, where the skilled person desires to produce EPA and reduce the concentration of intermediates in the final plant oil, expression of the genes coding
for Delta-6 desaturase, Delta-6 elongase and Delta-5 desaturase (or Delta-9 elongase, Delta-8 desaturase and Delta-5 desaturase) may be reduced or switched of in this sequence. Thus, the enzymes involved in late steps of product formation have the chance to consume some or all of the required intermediated products without these intermediate products being replenished by the enzymes involved in early steps of product formation. The resulting oil is then enriched in EPA and reduced in content of for example ALA, SDA and/or ETA.
According to the invention there is also provided a method of identifying a gene for conveying an unsaturated fatty acid metabolic property to a plant, comprising:
i) producing a plant comprising said gene,
ii) performing an assay method of the present invention, wherein said gene is expressed and said plant metabolic property is measured, and
iii) evaluating said plant for the presence and/or intensity of said unsaturated fatty acid metabolic property.
As described herein, by using the Delta-12 desaturase of the present invention it is possible to obtain plant metabolic property measurements, preferably plant oil composition data, of plants grown under greenhouse conditions that approximate closely or are identical to paints grown under field conditions.
The invention also provides a method of increasing Delta-12 desaturase activity and/or of stabilising Delta-12 desaturase activity in a plant or part thereof or during developmental stages of a plant or part thereof, preferably during seed development, which methods comprise growing a plant expressing a Delta-12 desaturase of the present invention. As described herein, expression of the Delta-12 desaturase according to the present invention allows to simulate or approximate a plant metabolic property (preferably seed oil composition) obtainable or to be expected under field conditions by merely growing a corresponding plant or plants under greenhouse conditions. Thus, the use of the Delta-12 desaturase according to the present invention effectively reduces the impact of environmental influences (preferably of temperature and/or daily/seasonal temperature variation) on Delta-12 desaturase activity in the plant or plants, thus effectively stabilising or increasing Delta-12 desaturase activity. This also allows to produce unsaturated fatty acids downstream of linoleic acid, for example EPA, DPA and/or DHA, more reliably than without a Delta-12 desaturase of the present invention. Thus, the invention also provides a method of producing one or more desired unsaturated fatty acids in a plant, comprising growing a plant, said plant expressing, at least temporarily, a Delta- 12 desaturase of the present invention and one or more further genes to convert linoleic acid to said one or more desired unsaturated fatty acids. As indicated above, the one or more further genes coding for enzymes for the production of unsaturated fatty acids preferably comprise desaturases and elongases.
The invention also provides a nucleic acid comprising a gene coding for a Delta-12 desaturase of the present invention, wherein the gene does not code for a Delta-12 desaturase of any of the
exact sequences SEQ ID NO. 329 to 336. Thus, the present invention provides a nucleic acid comprising a gene coding for a Delta-12 desaturase, wherein said Delta-12 desaturase has at least 50% total amino acid sequence identity to any of the sequences SEQ ID NO. 328 to 336 and/or at least 60% total amino acid sequence similarity to any of the sequences SEQ ID NO. 328 to 336, and wherein the sequence is not any of the sequences SEQ ID NO. 329 to 336. The amino acid sequence according to SEQ ID NO. 328 had not been described in the prior art. The aforementioned nucleic acid of the invention thus for the first time provides you nucleic acid sequences coding for Delta-12 desaturases of the present invention. Corresponding to the preferred Delta-12 desaturase amino acid sequences described above, the present invention provides corresponding nucleic acids comprising a gene coding for such preferred Delta-12 desaturase of the present invention.
The invention also provides a nucleic acid comprising a gene coding for a Delta-12 desaturase of the present invention, wherein the gene is operably linked to an expression control sequence, and wherein the expression control sequence is heterologous to said gene if the gene codes for any of the exact sequences according to SEQ ID NO. 329 to 336. Thus, the invention particularly provides combinations of promoters and genes not found in nature, and particularly not found in any organism of genus Phytophthora, Hyaloperonospora and Saprolegnia. The nucleic acids of the present invention preferably are expression vectors or transformation constructs useful for transforming a plant cell and causing the Delta-12 desaturase gene of the present invention to be expressed at least temporarily during plant or plant cell development. Thus, the nucleic acids of the present invention facilitate to materialise the benefits conveyed by the present invention as described herein. Also, the invention provides purified Delta-12 desaturase polypeptides coded by any of the nucleic acids of the present invention.
According to the invention, there is also provided a plant cell comprising a gene coding for a Delta- 12 desaturase of the present invention. Such plant cells can be obtained, as described above, by transformation of wild-type plant cells or offspring thereof, for example by crossing a plant comprising a gene coding for a Delta-12 desaturase of the invention with a plant not comprising such gene and selecting offspring, preferably seeds, which comprise said gene. This way it is easily possible to transfer the gene coding for a Delta-12 desaturase of the present invention from one germplasm to another. The plant cell of the present invention preferably comprises a gene coding for one of the preferred Delta-12 desaturases of the present invention to materialise the benefits conveyed by such preferred desaturase. Also as described above, the gene coding for the Delta-12 desaturase of the present invention preferably is operably linked to an expression control sequence, and it is particularly preferred that said expression control sequence directs expression to certain tissues and certain times of plant development, for example to developing seed tissue and the above indicated preferred times after flowering.
As the present invention provides an assay method which can, as described above, also be used for screening and comparison purposes, the present invention also provides a plant set comprising at least 2 plant groups, each consisting of one or more plants, wherein the plant or
plants of each group are capable of expressing a Delta-12 desaturase of the present invention, and wherein the plant or plants of said groups comprise one or more genes coding for at least one or more enzymes of unsaturated fatty acid metabolism, of which enzymes at least one is capable of using linoleic acid as a substrate, and of which enzymes at least one is supposedly connected to a plant metabolic property, and wherein the plant or plants of said groups differ in the expression of at least one of the enzymes of unsaturated fatty acid metabolism. To differ in expression of at least one of the enzymes of unsaturated fatty acid metabolism, one gene present in the plant or plants of one group may be missing in the plant or plants of another group, or may be expressed at different times or in different tissues or in differing intensities. For example, the plants of 2 groups may both comprise a gene coding for a Delta-4 desaturase under the control of identical expression control sequences, but the Delta-4 desaturase nucleic acid sequences are derived from different organisms such that the amino acid sequences of the respective Delta-4 desaturases are unique for the plants of each of the groups. Instead of or additional to differing in the genes for Delta-4 desaturases, the groups can also differ in any other nucleic acid sequence coding for an enzyme of unsaturated fatty acid metabolism, included but not limited to omega-3 desaturases, Delta-6 desaturases, Delta-9 elongases, Delta-6 elongases, Delta-8 desaturases, Delta-5 desaturases and Delta-5 elongases.
As described above, the present invention allows to reduce the number of field trials for analysing plant metabolic properties, particularly of unsaturated fatty acid metabolism properties. Therefore the plants of the plant set of the present invention preferably are growing under greenhouse conditions. Even more preferably, at least one plant of at least one group of the plant set of the present invention is within at most 100m distance to a plant of another group. Where plants are grown in an automated greenhouse, in a growth chamber or germination chamber, it is allowable according to the invention to temporarlily remove one or more plants from the greenhouse, growth chamber or germination chamber, respectively, for up to 1 hour per day, preferably for not more than 45min, more preferably for not more than 30min and most preferably for not more than 20min per day. Thus, the invention allows to perform analyses done on the plant or plants outside of e.g. a greenhouse or in a separate chamber thereof where environmental conditions can differ from those of the location where the plant or plants are normally grown.
Preferred embodiments of the invention described in Section D are given herein below. The explanations and embodiments described in this section preferably apply mutatis mutandis to the following:
1. Assay method, comprising:
i) providing a plant capable of expressing a delta-12 desaturase, wherein said delta- 12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336,
and wherein the plant is also capable of expressing at least one or more enzymes of unsaturated fatty acid metabolism, of which enzymes at least one is capable of using linoleic acid
as a substrate, and of which enzymes at least one is supposedly connected to a plant metabolic property,
ii) growing the plant, and
iii) measuring said plant metabolic property for said plant.
2. Assay method, comprising:
i) providing a plant group, wherein the plants of said group are capable of expressing a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336, and wherein the plants of said group are capable of expressing at least one or more enzymes of unsaturated fatty acid metabolism, of which enzymes at least one is capable of using linoleic acid as a substrate, and of which enzymes at least one is supposedly connected to a plant metabolic property,
ii) growing the plants of the plant group, and
iii) measuring said plant metabolic property for plants of said plant group.
3. Assay method according to any of Embodiments 1 or 2, wherein the plant or plants, respectively, are grown under greenhouse conditions.
4. Assay method according to any of Embodiments 1 to 3, wherein
a) the plant or plants are of order Brassicales and preferably of family Brassicaceae, and/or
b) the Delta-12 desaturase is derived from or identical to a Delta-12 desaturase of an organism of class oomycetes, preferably or order Peronosporales, even more preferably of any of the genera Basidiophora, Benua, Bremia, Erapthora, Graminivora, Hyaloperonospora, Novotelnova, Paraperonospora, Perofascia, Peronosclerospora, Peronospora, Phytophthora, Phytopythium, Plasmopara, Plasmoverna, Protobremia, Pseudoperonospora, Salisapiliaceae, Sclerophthora, Sclerospora and Viennotia.
5. Method of identifying a gene for conveying an unsaturated fatty acid metabolic property to a plant, comprising:
i) producing a plant comprising said gene,
ii) performing an assay method according to any of Embodiments 1 to 4, wherein said gene is expressed and said plant metabolic property is measured, and
iii) evaluating said plant for the presence and/or intensity of said unsaturated fatty acid metabolic property.
6. Method of increasing delta-12 desaturase activity in a plant, comprising growing a plant expressing a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336.
7. Method of stabilizing delta-12 desaturase activity in a plant, comprising growing a plant expressing a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336.
8. Method according to any of Embodiments 5 to 7, wherein the plant or plants, respectively, are grown under greenhouse conditions and preferably are of order Brassicales, more preferably of family Brassicaceae.
9. Method of producing one or more desired unsaturated fatty acids in a plant, preferably of order Brassicales, more preferably of family Brassicaceae, comprising growing a plant, preferably under greenhouse conditions,
said plant expressing, at least temporarily, a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336, and
said plant expressing one or more futher genes to convert linoleic acid to said one or more desired unsaturated fatty acids.
10. Nucleic acid comprising
a) a gene coding for a Delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336 and wherein the gene does not code for a Delta-12 desaturase of any of the exact sequences SEQ ID NO. 329 to 336, or
b) a gene coding for a Delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336 and wherein the gene is operably linked to an expression control sequence, and wherein the expression control sequence is heterologous to said gene if the gene codes for any of the exact sequences according to SEQ ID NO. 329 to 336.
1 1. Plant or plant cell, preferably of order Brassicales, more preferably of family Brassicaceae, comprising a gene coding for a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336. 12. Plant set comprising at least two plant groups, preferably of order Brassicales, more preferably of family Brassicaceae,
wherein the plant or plants of each group are capable of expressing a delta-12 desaturase, wherein said delta-12 desaturase has at least 50% total amino acid sequence identity to at least
one of the sequences SEQ ID NO. 328 to 336, and/or at least 59% total amino acid sequence similarity to at least one of the sequences SEQ ID NO. 328 to 336,
and wherein the plant or plants of said groups comprise one or more genes coding for at least one or more enzymes of unsaturated fatty acid metabolism, of which enzymes at least one is capable of using linoleic acid as a substrate, and of which enzymes at least one is supposedly connected to a plant metabolic property, and wherein the plants of said groups differ in the expression of at least one of the enzymes of unsaturated fatty acid metabolism.
13. Plant set according to Embodiment 12, wherein the plant or plants of each group are grown under greenhouse conditions, and preferably the distance between a plant of one group and a plant of another group is at most 100m, preferably at most 50m, even more preferably at most 25m.
The Examples for the invention described in Section D are the Examples indicated with a "D" (D1 to D6)
The invention described in the sections above is further described by means of accompanying examples and figures, which, however, are not intended to limit the scope of the invention described herein.
EXAMPLES (for Section A only) The following Examples (Examples 1 to 32) are for the invention described in Section A. Example 1 : General cloning methods
Cloning methods as e.g. use of restriction endonucleases to cut double stranded DNA at specific sites, agarose gel electrophoreses, purification of DNA fragments, transfer of nucleic acids onto nitrocellulose and nylon membranes, joining of DNA-fragments, transformation of E. coliceWs and culture of bacteria were performed as described in Sambrook et al. (1989) (Cold Spring Harbor Laboratory Press: ISBN 0-87965-309-6). Polymerase chain reaction was performed using Phusion™ High-Fidelity DNA Polymerase (NEB, Frankfurt, Germany) according to the manufactures instructions. In general, primers used in PCR were designed such, that at least 20 nucleotides of the 3' end of the primer anneal perfectly with the template to amplify. Restriction sites were added by attaching the corresponding nucleotides of the recognition sites to the 5' end of the primer. Fusion PCR, for example described by K. Heckman and L. R. Pease, Nature Protocols (2207) 2, 924-932 was used as an alternative method to join two fragments of interest, e.g. a promoter to a gene or a gene to a terminator. Gene Synthesis, as for example described by Czar et al. (Trends in Biotechnology, 2009, 27(2): 63-72), was performed by Life Technologies using their Geneart® service. The Geneart® technology, described in WO2013049227 allows production of genetic elements of a few basepair (bp) in length, and was used in this invention to produce entire plasmids of about 60,000bp. Chemical synthesis of nucleotides to polynucleotides
was employed for short DNA fragments, which were then combined in a sequential, modular fashion to fragments of increasing size using a combination of conventional cloning techniques as described in WO2013049227. Example 2: Different types of plant transformation plasmids suitable to transfer of multiple expression cassettes encoding multiple proteins into the plant genome.
For agrobacteria based plant transformation, DNA constructs preferably meet a number of criteria: (1 ) The construct carries a number of genetic elements that are intended to be inserted into the plant genome on a so called Transfer DNA (T-DNA) between a T-DNA Left Border' (LB) and T-DNA Right Border' (2) The construct replicates in E.coli, because most cloning steps require DNA multiplication steps in E.coli. (3) The construct replicates in Agrobacterium (e.g. A. tumefaciens or A. rhizogenes), because the plant transformation methods rely on using Agrobacterium to insert the genetic elements of interest into the plant genome of a cell that was infected by Agrobacterium. (4) The construct contains supporting genetic elements that encode proteins which are required for infection of the plant cell, and for transfer and integration of desired genetic elements into the plant genome of an plant cell infected by the Agrobacterium, or the construct was used in combination with a second construct containing such supporting genetic elements that was present in the same Agrobacterium cell. (5) The constructs can contain selection markers to facilitate selection or identification of bacterial cells that contain the entire construct, and of a plant cell(s) that contains the desired genetic elements. An overview of available plasmids was given in Komori et al (2007).
Agrobacteria mediated transformation results in an almost random integration (with some bias induced by a number of factors) of the desired genetic element into chromosomes of the plant cell. The goal of the transformation was to integrate the entire T-DNA from T-DNA Left border to T-DNA Right border into a random position of a random chromosome. It can also be desirable to integrate the entire T-DNA twice or three times into the genome, for example to increase the plant expression levels of genes encoded by the T-DNA. To avoid complex Mendelian segregation of multiple integrations, it was preferred to have all T-DNA insertions at one genomic location, ('locus'). Inserting more than 25,000 bp T-DNA into plant genomes has been found to be a particular challenge in the current invention. In particular, it has been found in this invention plasmids carrying a ColE1/pVS1 origin of replication for plasmid replication in E.coli and/or Agrobacterium, are not stable above -25,000 bp. Such plasmids of the invention are described in Example 3. Because of this limitation, not more than ~4 to 5 gene expression cassettes can be transferred on one T-DNA containing plasmid into the plant genome. However, for the current invention up to 13 gene expression cassettes having a combined size of about 44,000 bp needed to be transferred into the plant genome. In contrast to plasmids containing the ColE1/pVS1 origin of replication for high copy plasmid replication in E.coli and/or Agrobacterium, BiBAC plasmids (Hammilton 1997) containing the F factor / pRi origin of replication for single copy plasmid replication in Eco/i and/or Agrobacterium where found to be stable in this invention up to a size of -60,000 bp. Such plasmids of the invention are described in Example 4. Both approaches described above were followed in the current invention.
Example 3: Assembly of genes required for EPA and DHA synthesis within T-plasmids containing the ColE1/pVS1 origin of replication
For synthesis of VLC-PUFA in Brassica napus seeds, the set of genes encoding the proteins of the metabolic VLC-PUFA pathway were combined with expression elements (promoters, terminators, Introns) and transferred into binary t-plasmids that were used for agrobacteria mediated transformation of plants. Attributed to the large number of expression cassettes promoting expression of one protein each, two binary t-plasmids where used for cloning of the complete set of proteins required for EPA and DHA synthesis. To this end, the general cloning strategy depicted in Figure 3 was employed. While Figure 3 depicts the general strategy, cloning of the final plant expression vectors described in example 10 to 14 was not restricted to this strategy; specifically a combination of all methods known to one skilled in the art, such as cloning, the use of restriction endonucleases for generation of sticky and blunt ends, synthesis and fusion PCR has been used. Following the modular cloning scheme depicted in Figure 3, genes were either synthesized by GeneArt (Regensburg) or PCR-amplified using Phusion™ High-Fidelity DNA Polymerase (NEB, Frankfurt, Germany) according to the manufacturer's instructions from cDNA. In both cases an Nco I and/or Asc I restriction site at the 5' terminus, and a Pac \ restriction site at the 3' terminus (Figure 3A) were introduced to enable cloning of these genes between functional elements such as promoters and terminators using these restriction sites (see below in this example). Promoter-terminator modules or promoter-intron-terminator modules were created by complete synthesis by GeneArt (Regensburg) or by joining the corresponding expression elements using fusion PCR as described in example 1 and cloning the PCR-product into the TOPO-vector pCR2.1 (Invitrogen) according to the manufacturer's instructions (Figure 3B). While joining terminator sequences to promoter sequences or promoter-intron sequences either via synthesis of whole cassettes or using fusion PCR, recognition sequences for the restriction endonucleases depicted in Figure 3 were added to either side of the modules, and the recognition sites for the restriction endonucleases Nco \, Asc \ and Pac \ were introduced between promoter and terminator or between introns and terminator (see Figure 3B). To obtain the final expression modules, PCR-amplified genes were cloned between promoter and terminator or intron and terminator via Nco I and/or Pac I restriction sites (Figure 3C). Employing the custom multiple cloning site (MCS) up to three of those expression modules were combined as desired to expression cassettes harbored by either one of pENTR/A, pENTR/B or pENTR/C (Figure 3D). Finally, the Multi-site Gateway™ System (Invitrogen) was used to combine three expression cassettes harbored by pENTR/A, pENTR/B and pENTR/C (Figure 3E) to obtain the final binary pSUN T-plasmids for plant transformation: VC-LJB2197-1 qcz, VC-LJB2755-2qcz rc, VC-LLM306- 1 qcz rc, VC-LLM337-1 qcz rc, VC-LLM338-3qcz rc and VC-LLM391 -2qcz rc. An overview of binary vectors and their usage was given by Hellens eta/, Trends in Plant Science (2000) 5: 446-451 .
The structure of the plamsids VC-LJB2197-1 qcz, VC-LJB2755-2qcz rc, VC-LLM306-1 qcz rc, VC- LLM337-1 qcz rc, VC-LLM338-3qcz rc, VC-LLM391 -2qcz rc, and VC-LTM217-1 qcz rc was given in the Table 1 , Table 2, Table 3, Table 4, Table 5, Table 6, and Table 7
Nomeclature of genetic elements:
j- indicates a junction between two genetic elements
c- coding sequence t- terminator
p- promoter
i- intron
T-DNA Transferred DNA
RB Right Border of the T-DNA
LB Left Border of the T-DNA
Table 1 Genetic Elements of plasmid VC-LJB2197-1qcz. Listed are the names of the elements, the position in VC-LJB2197-1 qcz (note: start posi was larger than stop position for elements encoded by the complementary strand of VC-LJB2197-1 qcz), the function and source of the element. T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleotides 148 to 4 of VC-LJB2197-1 and a left border (nucleotides 22232 to 22105 of VC-LJB2197-1 qcz). Elements outside of that region (=vector backbone) are required for clo 5 and stable maintenance in Eco/Zand/or agrobacteria.






LLM306-1qcz rc) and a left border (nucleotides 20180 to 20053 of VC-LLM306-1qcz rc). Elements outside of that region (=vector backbone) required for cloning and stable maintenance in E.coli rand/or agrobacteria.


Table 4: Genetic Elements of plasmid VC-LLM337-1qcz rc. Listed are the names of the elements, the position in VC-LLM337-1qcz rc (nucleo number, note: start position was larger than stop position for elements encoded by the complementary strand of VC-LLM337-1qcz rc), the fun and source of the element. The T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleoti
1


Table 5: Genetic Elements of plasmid VC-LLM338-3qcz rc. Listed are the name of the element, the position in VC-LLM338-3qcz rc (nucle number, note: start position was larger than stop position for elements encoded by the complementary strand VC-LLM338-3qcz rc), the function source of the element. The T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleoti 5 148 to 4 of VC-LLM338-3qcz rc) and a left border (nucleotides 17069 to 16942 of VC-LLM338-3qcz rc). Elements outside of that region (=ve backbone) are required for cloning and stable maintenance in Eco/Zand/or agrobacteria.



Table 6: Genetic Elements of plasmid VC-LLM391-2qcz rc rc. Listed are the names of the elements, the position in VC-LLM391-2qcz rc rc (nucle number, note: start position was larger than stop position for elements encoded by the complementary strand of VC-LLM391-2qcz rc rc), the fun and source of the element. The T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleoti 5 148 to 4 of VC-LLM391-2qcz rc rc) and a left border (nucleotides 10947 to 10820 of VC-LLM391-2qcz rc rc). Elements outside of that region (=ve backbone) are required for cloning and stable maintenance in Eco/Zand/or agrobacteria.




Example 4: Assembly of genes required for EPA and DHA synthesis within BiBAC T-plasmids containing the F factor / pRI origin of replication
For synthesis of VLC-PUFA in Brassica napus seeds, the set of genes encoding the proteins of the metabolic VLC-PUFA pathway were combined with expression elements (promoters, terminators and introns) and transferred into binary t-plasmids that were used for agrobacteria mediated transformation of plants. While the large number of expression cassettes promoting expression of one protein each, were distributed in example 3 onto two binary t-plasmids T-DNA, in this example all expression cassettes have been combined onto a single binary T-plasmid. The advance of DNA synthesis allows numerous companies to offer services to use a combination of chemical synthesis and molecular biological techniques to synthesize de novo, without an initial template, polynucleotides up to the size of microbial genomes. Synthesis used in the construction of the plasmids described in this example was performed by Life Technologies using their Geneart® service. The Geneart® technology, described in WO2013049227 allows production of genetic elements of a few basepair (bp) length, and was used in this invention to produce the binary T-plasmids for plant transformation VC-RTP10690-1 qcz_F, VC-RTP10691 -2qcz, VC- LTM595-1 qcz rc and VC-LTM593-1 qcz rc having a total size of ~61 .000bp for each construct. The structure of the plasmids VC-RTP10690-1 qcz_F, VC-RTP10691 -2qcz, VC-LTM595-1 qcz rc and VC-LTM593-1 qcz rc is given in: Table 8, Table 9, Table 10 and Table 1 1 .
Table 8: Genetic Elements of plasmid RTP10690-1qcz_F. Listed are the names of the elements, the position in RTP10690-1qcz_F (nucleotide number, note: start position was larger than stop position for elements encoded by the complementary strand of SEQ ID NO.6), the function and source of the element. The T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleotides 59918 to 148 of RTP10690-1 qcz_F) and a left border (nucleotides 43853 to 43718 of RTP10690-1qcz_F). Elements outside of that region (=vector backbone) are required for cloning and stable maintenance in _Eco//and/or agrobacteria.






Table 9: Genetic Elements of plasmid RTP10691-2qcz. Listed are the names of the elements, the position in RTP10691-2qcz (nucleotide number, note: start position was larger than stop position for elements encoded by the complementary strand of RTP10691 -2qcz), the function and source of the element. The T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleotides 60923 to 148 of RTP10691-2qcz and a left






Table 10: Genetic Elements of plasmid VC-LTM595-1qcz rc. Listed are the names of the elements, the position in VC-LTM595-1qcz rc (nucleotide number, note: start position was larger than stop position for elements encoded by the complementary strand of VC-LTM595-1qcz rc), the function and source of the element. The T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleotides 60913 to 148 of VC-LTM595- 1qcz rc) and a left border (nucleotides 44848 to 44713 of VC-LTM595-1qcz rc). Elements outside of that region (=vector backbone) are required for cloning and stable maintenance in E. co/Zand/or agrobacteria.






Table 1 1 : Genetic Elements of plasmid VC-LTM593-1qcz rc. Listed are the names of the elements, the position in VC-LTM593-1qcz rc (nucleotide number, note: start position was larger than stop position for elements encoded by the complementary strand of VC-LTM593-1qcz rc), the function and source of the element. The T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleotides 59895 to 148 of VC-LTM593- 1qcz rc) and a left border (nucleotides 43830 to43695 of VC-LTM593-1qcz rc). Elements outside of that region (=vector backbone) are required for cloning and stable maintenance in E. co/Zand/or agrobacteria.






Table 13 compares the order of the gene expression cassettes among all the different constructs and the construct combinations, using short terms for these expression cassettes, see Table 12 for definitions. The data in Examples 10 to 19 demonstrate significant differences among the different construct or construct combinations in terms of the PUFA profile measured in transgenic seed. The differences between constructs and the construct combinations were evident even when eliminating all other sources that affect PUFA levels (e.g. different environments, plant-to- plant variability, seed oil content, T-DNA copy number). For example VC-RTP10690-1 qcz_F and VC-LMT593-1 qcz rc are isogenic, i.e. the two constructs contained exactly the same gene expression cassettes. Because of the similarity between RTP10690-1 qcz_F and VC-LMT593- 1 qcz one would expect exactly the same pathway step conversion efficiencies e.g. when
comparing the average conversion efficiencies of all single copy events. However, Figure 39 shows that VC-RTP10690-1 qcz_F had a Delta-4 DESATURASE conversion efficiency of 32%, (average of T1 seeds of 52 single copy TO events), wheras VC-LMT593-1 qcz rc had a Delta-4 DESATURASE conversion efficiency of 47% (average of T1 seeds of 241 single copy TO events). This was not expected, and can be explained by transcript levels, which in turn determine protein levels. The transcript levels are affected by the genetic elements that flank the Delta-4 DESA TURASE cassettes in VC-LMT593-1 qcz rc. The observations between the two constructs is an unexpected finding and indicates that not only the genome but also the T-DNA itself impacts the Delta-4 DESATURASE conversion efficiency, that was dependent on "gene dosage" as described in Example 19. Furthermore, the data in Example 10 to 19 demonstrate that it was possible to insulate expression cassettes from such effects. As can be seen in those Examples 10-19 all single copy events were capable of producing almost exactly the same VLC-PUFA levels when eliminating all other sources that affect PUFA levels (e.g. different environments, plant-to- plant variability, seed oil content). This was particularly striking when comparing all the single copy events in Example 18. Comparing the total C20+C22 VLC-PUFA content, which was largely controlled by how much was converted by the delta-12 desaturase and by the delta-6 desaturase, it was striking to observe there was virtually no difference between e.g. the single copy event LANPMZ obtained from the contruct combination VC-LJB2197-1 qcz + VC-LLM337-1 qcz rc, and all single copy events listed in Example 18. To this end, it is important to note that one side of the T-DNA that encodes either the entire pathway (Example 15 to 18) or at least the first steps of the pathway up to ARA and EPA production (Example 10 to 14) always contains the AHAS gene which confers herbicide tolerance but was not involved in the VLC-PUFA pathway. The other side of the T-DNA encodes either the entire pathway (Example 15 to 18) or at least the first steps of the pathway up to ARA and EPA production (Example 10 to 14) in most cases the Delta-6 EL ONGASEftom Physcomitralla patens (except in Example 13 and 14). As described in Example 19, the Delta-6 ELONGASE protein encoded by the Physcomitrella patens gene works close to maximum conversion efficiency (>90%), thus any increase in delta-6 elongase enzyme levels due to any effect that increases transcript levels will have virtually no effect on the C20 and C22 VLC- PUFA levels. Effectively, the T-DNA determining the total level of VLC-PUFA accumulation are flanked on both sides by genes where expression level differences will have no impact on the VLC-PUFA accumulation. As these two genes were encoded by expression cassettes that were several thousand bp in size, it appears the genes inside the T-DNA were shielded/insulated from any effects the genomic environment could have on the expression level of those genes (e.g. the delta-12-desaturase, compare with Example 19). This effect was consistent with the observation that double copy events differ considerably more in total C20 and C22 VLC-PUFA levels: As in many cases the additional T-DNA insertions are not complete (see Example 10 to 18), resulting in exporsure of T-DNA internal genes to the genome. When these genes are susceptible to gene- dosage effects (the conversion efficiency of those genes depends on the amount of transcript and the derived amount of enzyme, compare with Example 19), then in some genomic locations the genomic environment boosted the transcript level.
Table 12: Definition of shorthands used for plant expression cassettes of this invention





In general, the transgenic rapeseed plants were generated by a modified protocol according to DeBlock et al. 1989, Plant Physiology, 91 :694-701 ). For the generation of rapeseed plants transgenic for two different T-DNAs, the binary vectors described in example 3 were transformed into Agrobacterium rhizogenes SHA001 (see WO2006024509 A2 for full description of the Agrobacterium used). For the transformation of rapeseed plants (cv. Kumily), a co-transformation strategy was used. Transformation was performed with two different agrobacteria strains harbouring one of the two different plasmids listed in Table 14 and described in detail in Example 3, Example 4, Example 6 and/or Example 7
Table 14: Overview of combinations used in Co-transformation Strategy described in Example 3 for generation of plants harboring two different T-DNAs

Cultures were pelleted at about 4000 g and re-suspended in liquid MS medium (Murashige and Skoog 1962), pH 5.8, 3% sucrose with 100 mg/L Acetosyringone to reach an OD6oonm of 0.1 . The Agrobacterium suspensions corresponding to each of the two constructs to be co- transformed were mixed in equal parts and used for inoculation of hypocotyl segments prepared from 5 days old etiolated seedlings.
Seeds were germinated under low light conditions (< 50 Mol/m2s) using MSB5 medium from Duchefa (Duchefa Biochemie, PO Box 809 2003 RV Haarlem, Netherlands), pH 5.8, 3% sucrose and 0.8% Oxoid agar. Germination under light conditions produces explants, which are more stable and easier to handle compared to etiolated hypocotyls. Hypocotyl segments of 4 to 7 mm length were inoculated in a bath of Agrobacterium cells under gentle shaking up to 4 min, followed by sieving the explants. Infected explants were transferred to petri dishes with co-cultivation medium (MS medium, pH 5.6, 3% sucrose, 0.6 g/L MES (2-(N-Morpholino)ethanesulfonic acid), 18 g/L mannitol, 0.7% phytoagar (Duchefa Biochemie, PO Box 809 2003 RV Haarlem, Netherlands, part number SKU:P1003), 100 mg/L Acetosyringone, 200 mg/L L-Cysteine, 1 mg/L 2,4D (2,4-Dichlorophenoxyacetic acid)) carrying one layer of Whatman filter paper on its surface. Petri dishes were sealed with tape and incubated at 23 C under long day conditions (16 h light/8 h darkness) for three days. After the three days co-cultivation period explants were transferred to MS medium, pH 5.6, 3% sucrose, 0.6 g/L MES, 18 g/L mannitol, 07% Phytoagar, 1 mg/L 2,4D and 500 mg/L Carbenicillin to prevent Agrobacterium growth and incubated for a recovery period under the same physical conditions as for the co-cultivation for 7 days.
For selective regeneration explants were transferred after the recovery period to MS medium, pH 5.8, 3% sucrose, 0.7% Phytoagar, 2.5 mg/L AgN03, 3 mg/L BAP (6-Benzylaminopurine), 0.1 mg/L GA (Gibberellic acid), 0.1 mg/L NAA (1-Naphthaleneacetic acid), 500 mg/L Carbenicillin, 100 nM Imazethapyr (Pursuit) and cultured for two weeks under long day conditions as described above. Sub-cultivation takes place every two weeks. Hormones were stepwise reduced as follows: BAP 3 to 0.5 to 0.05 mg/L; GA (Gibberellic acid) 0.1 to 0.25 to 0.25 mg/L; NAA 0.1 to 0 to 0 mg/L. Developing shootlets could be harvested after the second cycle of selective regeneration. Shootlets were cut and transferred to either Elongation/rooting medium (MS medium, pH 5.8, 2%sucrose, 100 mg/L myo-inositol, 40 mg/L Adenine sulphate, 500 mg/L MES, 0.4% Sigma Agar, 150 mg/L Timentin, 0.1 mg/L IBA (lndole-3-butyric acid)) or to rock wool/stone wool or foam mats (Grodan, GRODAN Group P.O. Box 1 160, 6040 KD Roermond The Netherlands, or Oasis, 919 Marvin Street, Kent, OH 44240 USA) watered with 1/10 Vol. of MS medium, pH 5.8 without sucrose under ex vitro long day conditions in covered boxes. Shoots were elongated and rooted in in vitro medium and were transferred directly to soil.
Either in vitro shoots or GH adapted shoots were sampled for molecular analysis.
Medium were used either autoclaved (except antibiotics, hormones, additives such as L-cysteine, Acetosyringon, imidazolinone components) or filter sterilized prepared (Agar component autoclaved, allowed to cool to 42 C and then used).
Example 6: Procedure for production of transgenic plants using BiBACs For BiBAC transformation the same protocol as described for the co-transformation approach was used except that only one construct was used. According to the prokaryotic kanamycin resistance gene of binary plasmid 50 mg/L kanamycin was used instead of Spectinomycin tor Agrobacterium growth. It was observed during the course of this work that Agrobacterium carrying BiBACs grow
very slowly, often taking 18 hours to reach a liquid culture OD6oonm considered optimal for use in plant transformation.
The table below gives an example for some key data documented during the transformation of the construct LTM593

The amount of single copy events produced by the plant transformation protocol described above was 45% and 38% of vector backbone-free events selected after transformation of the constructs LTM593 and LTM595, respectively, were single copy events (see Table 15).
Table 15: Statistics of single and double copy events with and without vector backbone in transformation experiments performed with the two BiBAC strains VC-LTM593-1qcz rc and VC- LTM595-1qcz rc

Table 16: Impact of Agrobacterium rhizogenes strains on transformation success of BiBACs

Table 17: Transformation Efficiencies of the various plasmids and Agrobacterium strains used. With respect to the integration of the T-DNA, it was possible that multiple copies or single copies of intact or truncated or duplicated T-DNA's could be inserted into the genome. The terms copy or copies refer to the number of copies of a particular T-DNA or fragment of a T-DNA that were inserted into the plant genome. The term locus refers to how many different locations within the plant genome the copy or copies of the T-DNA were inserted into and isdefined as a region of disequilibrium within the genome and which can vary between plant species and even within cultivars of a given species. For the purpose of this definition this is within one genetic map unit or CentiMorgan.


Example 7: Seed Germination and Plant Growth in the Greenhouse and Field
Transformed plants were cultivated for seed production and phenotypic assessment in both the greenhouse and in the field. Greenhouse growth conditions were a sixteen hour light period followed by an eight hour dark period. The temperature was 20 degrees celsius during the light period (also called the day period) with a level of light corresponding to 200-300 micromoles of photons m-2 s-1 (this is the incident of light at the top of the plant and lights were adjusted in terms of distance from the plant to achieve this rate). During the day period the range of light in the greenhouse varied between 130 and 500 micromoles of photons m-2 s-1 . Getting out of the day range just cited triggered either the use of artificial light to bring the level up to 200-300 micromoles of photons m-2 s-1 or shading and/or shut off of lights to bring the level back to 200- 300 micromoles of photons m-2 s-1 . The dark period (also referred to as the night period) temperature was 18 C. Four hours before the light period began the temperature was lowered to 15 C for the remainder of the dark period. Plants were irrigated and treated for insects as necessary. The soil type was 50 % Floradur B Seed + 50 % Floradur B Cutting (including sand and perlite) provided by Floragard (Oldenburg, Germany). Plant growth was enhanced by nutrient supplementation. Nutrients were combined with the daily watering. A 0.1 % (w/v) fertilizer solution (Hakaphos Blue 15(N) -10 (P) - 15(K), Compo GmbH & Co KG, Munster, Germany) was used to water the plants. Water was supplied on demand (e.g. depending on plant growth stage, water consumption etc.). To avoid cross-pollination, plants were bagged at the time when the first flowers opened. Plants were checked daily in order to ensure that all open flowers were covered by the bags. Open flowers that were not covered properly were removed. For field grown plants, the plants were grown in six locations which correspond climatically to USDA growth zones 3a-4b and 5a, and five locations corresponding climatically to USDA growth zones 8a-9b and 1 1. The plants grown in the regions corresponding to USDA growth zones 3a- 4b and 5a were grown in the summer and the plants grown in the regions corresponding to USDA growth zones 8a-9b and 1 1 were grown in the winter. Standard horticultural practices for canola were followed. Netting and other measures to protect from birds and insects were used as deemed necessary by the growers, as were herbicides and fertilizer applications. The planting
density for all locations was eighty seeds per square meter with germination rate of 95 or better percent.
In the case where it was necessary to determine germination rates for the purpose of seed quality assurance or control, or where it was advantageous to germinate seeds to obtain cotyledons or seedling tissues, the following protocol was used:
150 mm by 15 mm petri-plates and Whatman (no. 2) filter paper cut into 120 mm disks were used. The filter paper was pre-moistened with sterile deionized water. One hundred seeds of the appropriate line were obtained and spread evenly across the pre-moistened filter paper.
Clean and sterile tweezers were used to spread the seeds to obtain the uniform pattern as shown above. Additional sterile water was added to ensure the seeds and paper were wetted, but not floating. The total amount of water used per petri-plate was approximately 20 mL. Three plates were done for each genotype tested. The plates were sealed with surgical tape, VWR (1050 Satellite Blvd.Suwanee, GA 30024 USA) catalog number 56222-1 10. After the plates were sealed, they were then incubated in a germination chamber set to 90% humidity, set to a sixteen hour photoperiod with 20 degrees Celsius day temperature and 15 degrees Celsius night temperature. The light intensity was 90-120 micro-moles per square meter per second. Germination was scored twice, once at four days after placing the plates into the growth chamber and again at eight days after incubation.
Example 8: Lipid extraction and lipid analysis of plant oils
The results of genetic modifications in plants or on the production of a desired molecule, e.g. a certain fatty acid, were determined by growing the plant under suitable conditions, e.g. as described above and analyzing the growth media and/or the cellular components for enhanced production of the desired molecule, e.g. lipids or a certain fatty acid. Lipids were extracted as described in the standard literature including Ullman, Encyclopedia of Industrial Chemistry, Bd. A2, S. 89-90 und S. 443-613, VCH: Weinheim (1985); Fallon, A., et al., (1987) "Applications of HPLC in Biochemistry" in: Laboratory Techniques in Biochemistry and Molecular Biology, Bd. 17; Rehm et al. (1993) Biotechnology, Bd. 3, Kapitel III: "Product recovery and purification", S. 469- 714, VCH: Weinheim; Belter, P.A., et al. (1988) Bioseparations: downstream processing for Biotechnology, John Wiley and Sons; Kennedy, J.F., und Cabral, J. M.S. (1992) Recovery processes for biological Materials, John Wiley and Sons; Shaeiwitz, J.A., und Henry, J.D. (1988) Biochemical Separations, in: Ullmann's Encyclopedia of Industrial Chemistry, Bd. B3; Kapitel 1 1 , S. 1 -27, VCH: Weinheim; and Dechow, F.J. (1989) Separation and purification techniques in biotechnology, Noyes Publications.
It is acknowledged that extraction of lipids and fatty acids can be carried out using other protocols than those cited above, such as described in Cahoon et al. (1999) Proc. Natl. Acad. Sci. USA 96 (22): 12935-12940, and Browse et al. (1986) Analytic Biochemistry 152:141 -145. The protocols used for quantitative and qualitative analysis of lipids or fatty acids are described in Christie, William W., Advances in Lipid Methodology, Ayr/Scotland: Oily Press (Oily Press Lipid Library;
2); Christie, William W., Gas Chromatography and Lipids. A Practical Guide - Ayr, Scotland: Oily Press, 1989, Repr. 1992, IX, 307 S. (Oily Press Lipid Library; 1 ); "Progress in Lipid Research, Oxford: Pergamon Press, 1 (1952) - 16 (1977) u.d.T.: Progress in the Chemistry of Fats and Other Lipids CODEN.
To generate transgenic plants containing the genetic elements described in examples 3 and 4 for production of EPA and DHA in seeds, rapeseed (Brassica napus) was transformed as described in examples 5 and 6. Selected plants containing the genetic elements described in examples 3 and 4 were grown until development of mature seeds under the conditions cited in Example 7. Fatty acids from harvested seeds were extracted as described above and analyzed using gas chromatography as described above. The content (levels) of fatty acids is expressed throughout the present invention as percentage (weight of a particular fatty acid) of the (total weight of all fatty acids). Similiarly, the contents of other components of the oil are given in "% (w/w)". E.g., the content (levels) of TAGs or PCs is expressed throughout the present invention as percentage (weight of a particular TAGs or PCs) of the (total weight of all TAGs or PCs), in particular to the total weight of all TAGs or PCs present in the oil or lipid of the present invention. In an embodiment, the contents of the compounds are determined as described in the Examples. For example, the contents can be determined as in Examples 29, 31 or 32. Seed oil content is expressed throughout the present invention as percentage of (oil weight) of the (total weight of seeds).
Table 18: Fatty acids analyzed using gas chromatography

Example 9: Non-destructive analysis of lipids in single cotyledons of seedlings Transformation of plants according to the methods described in Example 5 and Example 6 results in a random integration of the T-DNA into the genome. It was known that such integrations can also occur in a partial manner, furthermore multiple integrations of complete and partial T-DNAs can occur. Self pollination of the TO plant will result in production of T1 seeds which will be segregating for the T-DNA insertion(s) according to the ratios observed by Gregor Mendel (Mendel, 1866) and which are now part of the basic general knowledge in the life sciences. Due to the Mendelian segregation; for each integration of the T-DNA, one quarter (-25%) of the T1
seed have lost the integration, and can be called "null segregants". 50% of the T1 seed will carry the T-DNA integration either on the maternal chromosome (25%), or paternal chromosome (25%); these seeds are 'heterozygous' or 'hemizygous' related to the T-DNA integration. The remaining quarter (-25%) of the T1 seed will carry the T-DNA on the maternal and paternal chromosome; these seeds are 'homozygous' related to the T-DNA integration. For plants that follow such a sexual propagation, it is essential to genetically fix the T-DNA integration(s), by selecting progenies that are homozygous for the T-DNA integration(s).
In order to identify T1 seedlings where each T-DNA integration that was essential for the trait was present, ideally homozygous, one can perform quantitative PCR to measure the copy number of the T-DNA integration(s) directly. Alternatively one can analyse the trait conferred by the presence of the T-DNAs, which at least enables the identification of all seeds that do not contain all T-DNA of interest (null-segregants). For all constructs described in Example 10 to Example 14, and where indicated, a non-destructive analysis of VLC-PUFA production was performed. To this end, T1 seeds were germinated in the dark for three days on wet filter paper. After three days, one of the two cotyledons was cut off to subject it to lipid analysis as described in Example 8. The other cotyledon, including the hypocotyl and root, was planted in soil. As an example, the result from the lipid content analysis of these cotyledons from segregating T1 seedlings of event LANPMZ obtained from the construct combination described in Example 1 1 are shown in Figure 22; the results of event LBDIHN obtained from the construct combination described in Example 15 are shown in Figure 23. In both of these figures, it is observed that one quarter of the seed do not produce a significant amount of VLC-PUFA, while producing wildtype levels of Oleic acid (null segregant seedlings). One can furthermore see in both figures two additional clusters of seedlings that produce different amounts of VLC-PUFA, see Figure 23. Counting the number of seed in these respective clusters, a 1 :2:1 segregation ratio was observed for the clusters that produce (~0 VLC-PUFA): (intermediate level of VLC-PUFAs): (higher level of VLC-PUFAs). The observations demonstrate a relationship between 'gene dosage', that was the number of T-DNA copies present in the genome, and VLC-PUFA levels. For all constructs described in Example 10 to Example 13, and where indicated, this relationship was exploited to identify T1 plants where at least one T-DNA locus has become homozygous, or where multiple T-DNA integration loci are at least present, or some are homozygous while others still segregate. The applicability of this method can be demonstrated for event LANPMZ, see Figure 22, all heterozygous (hemizygous) and homozygous T1 seeds of event LANPMZ that produce VLC_PUFA are capable of producing both EPA and DHA. As DHA production requires the presence of both T-DNAs, it can be concluded that at least one copy of the T-DNA of VC-LJB2197-1 qcz and one copy of the T-DNA of VC-LLM337-1 qcz rc have inserted into the genome, likely at the same locus. 13 T1 seedlings of those 288 seedlings of event LANPMZ having the highest VLC-PUFA levels have been selected and have been grown to mature plants. Copy number analysis on those 13 selected plants shown in Table 40 indicates that both T-DNAs are present in a single copy, and comparison of the TO plant copy number results against the average result of the 13 T1 plants demonstrates that these single T-DNA insertions are homozygous (duplicated copy number). All results combined provide the information that the event LANPMZ contains the T-DNAs of construct VC- LJB2197-1 qcz and the T-DNA of construct VC-LLM337-1 qcz rc in one copy each, whereby both T-DNAs co-segregate in a single locus.
For a single T-DNA integration into the genome, 1 out of 4 T1 seed are expected to be homozygous for that T-DNA integration. For each additional T-DNA integration, just one quarter of all seed homozygous for all other T-DNA integrations are homozygous for the additional T- DNA integration, consequently for two T-DNA integration events into the genome 1 out of 16 T1 seed are expected to be homozygous for both T-DNA integration; for three T-DNA integration into the genome 1 out of 64 T1 seed are expected to be homozygous for all three T-DNA integration; for four T-DNA integration into the genome 1 out of 256 T1 seed are expected to be homozygous for all four T-DNA integration; and so forth. All plants in Example 10 to Example 14 contain a minimum of two T-DNA insertion events (one from each plasmid) in order for the plant to contain all the necessary genes to generate all the required enzymes to reconstitute the PUFA pathway sufficiently to generate the VLC-PUFAs: DHA and EPA as well as ARA.
Example 10: Plants containing the T-DNAs of plasmid VC-LJB2197-1qcz and VC-LLM306-1qcz rc (combination A in example 5) for production of EPA and DHA in seeds
In this example, the genetic elements required for EPA and DHA synthesis were transferred into the plant genome on two different T-DNAs. To this end, the two different plasmids VC-LJB2197- 1 qcz and VC-LLM306-1 qcz rc containing two different T-DNAs where cloned into agrobacteria, and plant tissue was incubated according Example 5 at the same time with these two agrobacterial cultures that are identical apart from containing either VC-LJB2197-1 qcz or VC- LLM306-1 qcz rc. Due to the selectable herbicide resistance marker, regenerated plants contained at least the T-DNA of VC-LJB2197-1 qcz. Only those plants were kept, that also contained the T- DNA of plasmid VC-LLM306-1 qcz rc as confirmed by PCR, conducted as described in Example 24, which contains a description of PCR used for gene expression and gene copy number determination. Only plants containing both the T-DNA of plasmid VC-LJB2197-1 qcz as well as the T-DNA of plasmid VC-LLM306-1 qcz rc contain all the genetic elements required for EPA and DHA synthesis in seeds. The genetic elements of VC-LJB2197-1 qcz, and the function of each of the elements, are listed in Table 1 . The genetic elements of VC-LLM306-1 qcz rc, and the function of each of the elements, are listed in Table 3. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC-LJB2197-1 qcz and VC-LLM306-1 qcz rc that are required for EPA and DHA synthesis are additionally listed in Table 19.
Table 19: Combined list of useful genes of EPA and DHA synthesis carried by the T-DNAs of lasmids VC-LJB2197-1 cz and VC-LLM306-1 cz rc.


Fatty acid profiles, copy number measurements, and phenotypic observations of TO plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM306-1qcz rc cultivated in greenhouses during the summer.
The data in Table 20, Table 21 and Table 22 show that there was an increase in DHA and EPA content when comparing one versus two copies of each of the T-DNAs (VC-LJB2197-1 qcz and VC-LLM306-1 qcz rc) in the plant. The copy number of the construct VC-LJB2197-1 qcz has been determined by measuring the left border of the T-DNA in the TO generation and not other genetic elements along the T-DNA (see Table 20). It was possible that the 88 plants representing the single copy category do in fact contain additional partial T-DNA insertions, and that the 86 plant representing the double copy category might in fact lack parts of one of the T-DNAs. Therefore, due to insufficient data to correctly classify TO plants into "single copy" and "double copy" groups, both populations overlap. Comparisons between two and three copies of the T-DNA's revealed that there was a minimal increase in DHA and EPA, suggesting that two copies of each gene was sufficient to reach maximum performance of the VLC-PUFA biosynthesis pathway (C20 and C22 PUFAs, including, but not limited to, EPA, DHA and ARA) when considering copy numbers up to three. Of note was that the majority of insertions in this example are one or two copy events. Table 23 indicates that with respect to the PUFA pathway or the copy number of the T-DNA encoding genes of the PUFA pathway, there was no significant effect on plant morphology or development when the plant carries one, two or three copies of the T-DNA's of interest.
Table 20: Copy number measurement of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 1qcz and VC-LLM306-1qcz rc. Considering each event in this generation was represented by only 1 plant, all events have been grouped into categories indicated in the first column; sc: all TO plants where the average of all copy number assays listed in this table was 0.51-1.49, dc: al plants where the average of all copy number assays listed in this table was 1.51-2.49, tc: all TO plants where the average of all copy number as 5 listed in this table was 2.51-3.49.

Table 21 : Fatty acid profiles of T1 seeds harvested from TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM306-1qcz rc. Considering each event in this generation was represented by only 1 plant, all events have b
grouped into the categories indicated in the first column as described in Table 20. The number of T1 plants/events fullfilling these criteria displayed in parentheses. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 22: Fatty acid profiles of T1 seeds harvested from TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM306-1qcz rc. Considering each event in this generation was represented by only 1 plant, all events have b grouped into the categories indicated in the first column as described in Table 20. For each category, the fatty acid profile of the plant/event ha the highest EPA+DHA levels was shown. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 23: Phenotypic rating of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz 10 VC-LLM306-1qcz rc. Considering each event in this generation was represented by only 1 plant, all events were grouped into the categories indic
in the first column as described in Table 20. The number of T1 plants/events fulfilling these criteria are displayed in parentheses. DFF: days to flower (days), DF: deformed flower (9=deformed, 1 =normal), DL: deformed leaf (9=deformed, 1 =normal), DP: deformed plant (9=defor 1=normal), DS: deformed silique (9=deformed, 1=normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3 dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes (#), PH: p 5 height (cm), TKW: thousand kernel weight (g), SC: seed quality (1=good, 9=bad)

Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM306-1qcz rc cultivated in greenhouses during winter
The copy number analysis indicates that LALTHK was homozygous for two copies of the VC- LJB2197-1 qcz T-DNA and homozygous for one copy of the VC-LLM306-1 qcz rc while LALJCX was homozygous for two copies of both T-DNAs (VC-LJB2197-1 qcz and VC-LLM306-1 qcz rc). The other events were still partially segregating for the T-DNAs but contained at least one copy of each T-DNA in all plants. Event LALTHK had no accumulation of DHA, which illustrates the effects of truncations which can occur during insertion of the T-DNA. The events, with the exception of LALTHK, are, within error, similar to one another in terms of EPA+DHA accumulation. The similarity in copy numbers of the events, see Table 23, indicates that insertion site effects that could enhance or repress gene expression are impacting all events equally. The lack of significant variation in EPA and DHA accumulation suggests that there may be a buffering effect in the construct design, such that the T-DNA's integrate into the genome in a manner that minimizes positional effects in gene expression in the T-DNA. The event with the highest VLC- PUFA accumulation, in particular EPA and DHA, was LALFWA which had a maximum accumulation of 4.2 percent DHA and 16 percent EPA with respect to total fatty acid content in the mature seed, but on the average was similar to the other events.
Table 24: Copy number measurement of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 1qcz and VC-LLM306-1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where measured per event. T1 plants underwent a selection from 250 segregating T1 seedlings using half-kernel analysis, where the correlation of VLC-PUFA levels with number was employed to select for homozygous plants, or on case of multilocus events to selecect for plants where one or more loci are homozyg A copy number of ~2 therefore was indicative for one homozygous locus, a copy number of ~4 indicative for two homozygous loci or indicativ one homozygous locus containing two copies of the target gene measured by the assay, and so forth. Odd results of 3 and 5 indicate that at l some of the selected T1 plants carry a heterozygous locus.


Table 25: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM306-1qcz rc The events are indicated in the first column, along with the number of T2 seed batches that measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 26: Fatty acid profiles of one T2 seed batch per event harvested from T1 plants cultivated in the greenhouse of canola events containing T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM306-1qcz rc. The events are indicated in the first column. Fatty acid profiles of T2 seed bat having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in two technical repe

Table 27: Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz VC-LLM306-1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where rated per event. DFF: days to flower (days), DF: deformed flower (9=deformed, 1=normal), DL: deformed leaf (9=deformed, 1=normal), DP: deformed plant (9=defor 1=normal), DS: deformed silique (9=deformed, 1=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3
dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobes(#), PH: p height (cm), TKW: thousand kernel weight (g), SC: seed quality (1=good, 9=bad),

Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LJB2197-1 qcz and VC-LLM306-1qcz rc cultivated in greenhouses during summer
Copy number analysis, see Table 28, indicates that the chosen events are largely homozygous for the genes encoded on the T-DNAs of VC-LJB2197-1 qcz and VC-LLM306-1 qcz rc. All events but LALTLE had two copies of the T-DNAs inserted into the genome. LALTLE appeared to have more than two copies with some segregation still ongoing. Based on the copy number analysis, LALJDF had integrated one copy of the d4Des(Eg_GA) gene and LALTLE was segregating for one or two copies of that gene. The EPA and DHA data in Table 29 and Table 30 indicated the events perform equally well with perhaps LALJDF accumulating less DHA, based on Table 30. Plant morphology was the same for all the events examined. As discussed above for T1 plants grown in the greenhouse, the event to event variation was minimal, suggesting that the impacts of insertion site position effects (both negative and positive) were similar for all events. The lack of insertion site effects indicates that the plasmid design/T-DNA topology was exerting a normalizing effect/mitigates insertion site effects.
Table 28: Copy number measurement of T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 1qcz and VC-LLM306-1qcz rc. The events are indicated in the first column, along with the number of T2 plants that where measured per event. T2 plants underwent a selection from 250 segregating T2 seedlings using half-kernel analysis, where the correlation of VCL-PUFA levels with number was employed to select for homozygous plants, or in case of multilocus events to selecect for plants where one or more loci are homozyg A copy number of ~2 therefore was indicative for one homozygous locus, a copy number of ~4 indicative for two homozygous loci or indicativ one homozygous locus containing two copies of the target gene measured by the assay, and so forth. Odd results of 3 and 5 indicate that at l some of the selected T2 plants carry a heterozygous locus.
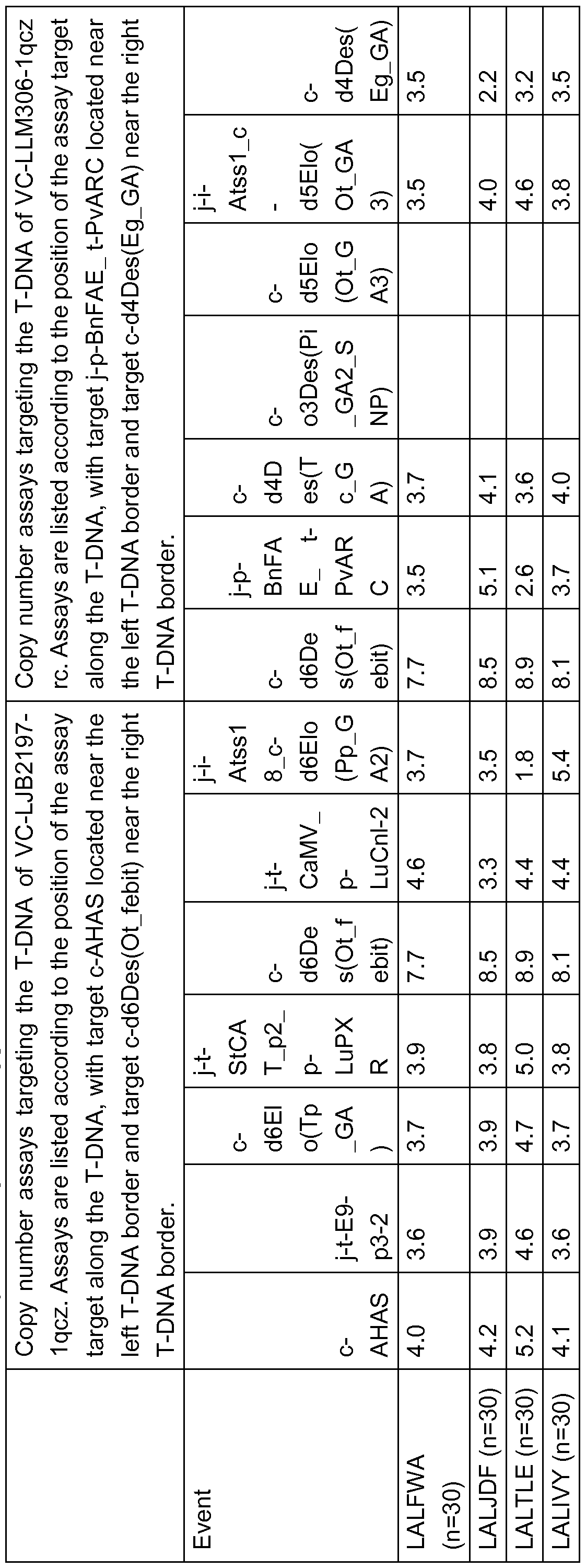
Table 29: Fatty acid profiles of T3 seeds harvested from T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM306-1qcz rc The events are indicated in the first column, along with the number of T3 seed batches that w measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 30: Fatty acid profiles of one T3 seed batch per event harvested from T2 plants cultivated in the greenhouse of canola events containing T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM306-1qcz rc. The events are indicated in the first column. Fatty acid profiles of T3 seed bat having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in two technical repe

Table 31 : Phenotypic rating of T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz VC-LLM306-1qcz rc. The events are indicated in the first column, along with the number of T2 plants that where rated per event. DFF: days to flower (days), DF: deformed flower (9=deformed, 1 =normal), DL: deformed leaf (9=deformed, 1 =normal), DP: deformed plant (9=defor 1=normal), DS: deformed silique (9=deformed, 1=normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3 5 dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobes(#), PH: p height (cm), Oil: oil content (% of seed weight), Protein: Protein content (% of seed cake without oil)

Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM306-1qcz rc cultivated in field trials in USDA growth zones 3a-4b and 5a during summer.
The field data on Table 32 and Table 33 indicate a consistent performance across generations for T2 and T3. The data show that the PUFA (EPA and DHA) accumulation was higher for greenhouse grown plants. Besides levels in VLC-PUFA, there was also a difference in seed oil content observed compared to the greenhouse (e.g. comparing Table 34 and Table 31 ). Results of this analysis are described in Example 20. The field data also demonstrate that the greenhouse data accurately indicated the consistency between events with respect to EPA and DHA accumulation, though not overall levels. As remarked upon above for T1 and T2 plants grown in the greenhouse, the event to event variation was low for this construct, indicating that the T- DNAs/T-DNA design seem to be exerting a buffering/mitigating effect on gene silencing and other positional effects.
Table 32: Fatty acid profiles of T3 seeds harvested from T2 plants cultivated in the field corresponding to USDA growth zones 3a-4b and 5a. trials of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM306-1qcz rc are given below. The events are indicate the first column, along with the number of T3 seed aliquots representing a plot were measured per event. Per seed batch a random selection of seed was measured in two technical repeats.

Table 33: Fatty acid profiles of one T3 seed batch per event harvested from T2 plants cultivated in USDA growth zones 3a-4b and 5a field trial canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM306-1qcz rc. The events are indicated in the first column. F
5

Example 1 1 : Plants containing the T-DNAs of plasmid VC-LJB2197-1 qcz and VC-LLM337-1qcz rc (combination B in example 5) for production of EPA and DHA in seeds
In this example, the genetic elements required for EPA and DHA synthesis were transferred into the plant genome on two different T-DNAs. To this end, the two different plasmids VC-LJB2197- 1 qcz and VC-LLM337-1 qcz rc containing two different T-DNAs were cloned into agrobacteria, and plant tissue was incubated according to Example 5 at the same time with these two agrobacterial cultures that were identical apart from containing either VC-LJB2197-1 qcz or VC- LLM337-1 qcz rc. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of VC-LJB2197-1 qcz. Only those plants were kept, that also contained the T-DNA of plasmid VC-LLM337-1 qcz rc as confirmed by PCR, conducted as described in Example 24, which contains PCR protocols for both gene expression and copy number analysis. Only plants containing the T-DNA of plasmid VC-LJB2197-1 qcz as well as the T-DNA of plasmid VC-LLM337- 1 qcz rc combined all the genetic elements required for EPA and DHA synthesis in seeds. The genetic elements of VC-LJB2197-1 qcz and the function of each element were listed in Table 1. The genetic elements of VC-LLM337-1 qcz rc and the function of each element were listed in Table 4. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC- LJB2197-1 qcz and VC-LLM337-1 qcz rc that were required for EPA and DHA synthesis are additionally listed on Table 35.
Table 35: Combined list of genes essential of EPA and DHA synthesis carried by the T-DNAs of plasmids VC-LJB2197-1 qcz and VC-LLM337-1qcz rc.


Fatty acid profiles, copy number measurements, and phenotypic observations of TO plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc cultivated in greenhouses during summer
Table 34 indicates that the T-DNA integrated as predominantly single and double copies. As observed in Example 10 there was an increase in EPA and DHA between one copy and two copies of the T-DNA from the two constructs, see Table 36, but less of a difference between two and three copies. The T1 data in Table 37 reflects this as well. As noted in Example 10, there was no observed alteration of the phenotype of the plants bearing the T-DNA from both constructs, regardless of copy number (up to three).
Table 36: Copy number measurement of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 1qcz and VC-LLM337-1qcz rc. Considering each event in this generation was represented by only 1 plant, all events have been grouped into categories indicated in the first column; sc: all TO plants where the average of all copy number assays listed in this table was 0.51-1.49, dc: al plants where the average of all copy number assays listed in this table was 1.51-2.49, tc: all TO plants where the average of all copy number as 5 listed in this table was 2.51-3.49.


PAGE INTENTIONALLY LEFT BLANK
5

Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc cultivated in greenhouses during winter
The data on Table 39 indicate that the integration of these two T-DNA's (VC-LJB2197-1 qcz and VC-LLM337-1 qcz rc), has occurred in such a way as to introduce copy number variation of individual genes on a given T-DNA (indicating truncations and deletions along with multiple copies being inserted). For example the event LAMABL on Table 39 was segregating for a single copy of AHAS (homozygous), two copies of j-t-StCAT_p2_p-LuPXR (homozygous), possibly three copies of c-d6Elo(Pp_GA) likely homozygous, though it could be three copies which are not homozygous for all three, and three copies of j-i-Atss18_c-d6Elo(Pp_GA2) (homozygous for all three). Data on Table 42 to Table 45 for fatty acid profile indicates some variation among the events, though not large differences. The highest event average for both DHA and EPA for the events listed on Table 41 was LAMRHL which has DHA of 1.9 and EPA of 10.5 with respect to percent of the total fatty acid content of the seed and contains what was likely a single copy of the T-DNA of of VC-LJB2197-1 qcz still segregating, while VC-LLM337-1 qcz rc seems to be a single copy homozygous insertion. The event, LANMGC, with the lowest levels of EPA and DHA combined, contained EPA of 3.7 and 0.8 for DHA with respect to percent of the total fatty acid content of the seed. LANMGC appeared to be homozygous single copy for VC-LJB2197 and carried at least two separate integrations of VC-LLM337. For the highest single plant level of EPA and DHA, event LAPWLP had 3.2 percent of DHA and 15.9 percent of EPA with respect to percentage of total fatty acids in the seed, Table 43. The data indicate that the location of the insertion site is important for EPA and DHA accumulation in this combination of constructs. As seen in previous examples, comparison of single copy insertions versus double copy insertions revealed that between single copy and double copy containing plants there was an increase in VLC-PUFA levels, but between double and triple copy containing plants there was less distinction. Table 46 displays phenotypic scoring/assessment and shows some small differences in aerial phenotype among events and between the transformed plants and untransformed reference.





5

Table 42: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM337-1qcz rcThe events are indicated in the first column, along with the number of T2 seed batches that measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.













Table 44: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM337-1qcz rc. Plants of all events combined have been grouped into the categories indicated in the first column defined in Table 41. The number of T1 plants fulfilling these criteria are displayed in parentheses. Per seed batch a random selection of -30 s was measured in two technical repeats.

Table 45: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM337-1qcz rc. Plants of all events combined have been grouped into the categories indicated in the first column defined in Table 41. For each category, the fatty acid profile of the plant having the highest EPA+DHA levels was shown. Per seed batch a ran selection of -30 seed was measured in two technical repeats.

PAGE INTENTIONALLY LEFT BLANK
Table 46: Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where rated per event. DFF: days to flower (days), DF: deformed flower (9=deformed, 1=normal), DL: deformed leaf (9=deformed, 1=normal), DP: deformed plant (9=defor 1=normal), DS: deformed silique (9=deformed, 1=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (
dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobes(#), PH: p height (cm), TKW: thousand kernel weight (g), SC: seed quality (1=good, 9=bad)




Table 47: Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz VC-LLM337-1qcz rc. Plants of all events combined have been grouped into the categories indicated in the first column; as defined in Table 41. number of T1 plants fulfilling these criteria are displayed in parentheses. DFF: days to first flower (days), DF: deformed flower (9=defor
1=normal), DL: deformed leaf (9=deformed, 1 =normal), DP: deformed plant (9=deformed, 1 =normal), DS: deformed silique (9=deformed, 1=nor
5 FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3=no dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=opti
7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes (#), PH: plant height (cm), TKW: thousand kernel weight (g), SC: seed qu
(1 =good, 9=bad)

Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc cultivated in greenhouses during summer
Table 48 shows the copy number analysis of select events. The events comprised one to two homozygous insertions and some had additional insertions still segregating. For example LANBCH segregated as homozygous for one T-DNA insertions for each construct, while LANPMZ segregated as homozygous for two T-DNA insertions for each construct. LALXOL seems to segregate for one insertion of VC-LLM337-1 qcz rc, not homozygous, and for one homozygous insertion of LJB2197-1 qcz_F with another copy which was not homozygous with the exception of the region around j-t-StCAT_p2_p-LuPXR, which seems to be a double copy event homozygous for each copy. For the T2 events selected, combined DHA and EPA levels were from nine to thirteen percent of the total fatty acids present in the seed. Whereas the selected T3 events had combined DHA and EPA levels varying from eleven to twenty three percent, with LALWPA having a DHA level of five percent and an EPA level of eighteen percent with respect to total fatty acid content in the seed, see Table 50. The selected events exhibited no morphological or anatomical defects relative to one another or to wild type.


Table 49: Fatty acid profiles of T3 seeds harvested from T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM337-1qcz rc The events are indicated in the first column, along with the number of T3 seed batches that measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.




Table 51 : Phenotypic rating of T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2197-1qc VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of T2 plants that where rated per event. DFF: days t flower (days), DF: deformed flower (9=deformed, 1 =normal), DL: deformed leaf (9=deformed, 1 =normal), DP: deformed plant (9=defor 1=normal), DS: deformed silique (9=deformed, 1=normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf dentation ( dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobes(#), PH:
height (cm), TKW: thousand kernel weight (g), SC: seed quality (1 =good, 9=bad), Oil: oil content (% of seed weight), Protein: Protein content ( seed cake without oil)


Fatty acid profiles of T2 plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC- LLM337-1qcz rc cultivated in field trials in USDA growth zones 3a-4b and 5a during summer.
Field data from the T3 seed indicate that field values are lower for EPA and DHA than what was observed in the greenhouse, with values ranging from six to thirteen percent of the total fatty acid content of the seed for EPA and DHA combined. These data show a difference in seed oil content observed in field studies compared to the greenhouse (e.g. comparing Table 54 with Table 51 ), see also Example 10. Results of this analysis are described in Example 20.
Table 52: Fatty acid profiles of T3 seeds harvested from T2 plants cultivated in the field in field trials, corresponding to USDA zones 3a-4b and z 5a , of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc The events are indicated in the first colu
along with the number of T3 seed aliquots representing a plot were measured per event. Per seed batch a random selection of -30 seed measured in two technical repeats.


Table 53: Fatty acid profiles of one T3 seed batch per event harvested from T2 plants cultivated in field trials, corresponding to USDA zones 3 and zone 5a , of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc. The events are indicated in the
column. Fatty acid profiles of T3 seed batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of seed was measured in two technical repeats.

PAGE INTENTIONALLY LEFT BLANK

PAGE INTENTIONALLY LEFT BLANK
Fatty acid profiles copy number measurements, and phenotypic observations of T3 plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc cultivated in greenhouses during winter
The data indicate that EPA and DHA are still being synthesized by the plant in the seed/generation.
Table 55: Copy number measurement of T3 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of T3 plants that were measured per event the T3 plants underwent two cylces of selecting homozygous plants, all plants of all events are homozygous for all T-DNA insertions. A copy nu of ~2 therefore was indicative for one homozygous locus, a copy number of ~4 indicative for two homozygous loci or indicative for one homozyg 5 locus containing two copies of the target gene measured by the assay, and so forth.

Table 56: Fatty acid profiles of T4 seeds harvested from T3 plants cultivated in greenhouses of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM337-1qcz rc The events are indicated in the first column, along with the number of T4 seed aliquots representi plot were measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 57: Fatty acid profiles of one T4 seed batch per event harvested from T3 plants cultivated in greenhouses of canola events containing th DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column. Fatty acid profiles of T4 seed bat having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in two technical repe

Table 58: Phenotypic rating of T3 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz 10 VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of T3 plants that where rated per event. DFF: days to flower (days), DF: deformed flower (9=deformed, 1=normal), DL: deformed leaf (9=deformed, 1=normal), DP: deformed plant (9=defor 1=normal), DS: deformed silique (9=deformed, 1=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3 dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes(#), PH: p height (cm), TKW: thousand kernel weight (g), SC: seed quality (1=good, 9=bad), Oil: oil content (% of seed weight), Protein: Protein content ( 15 seed cake without oil)

Fatty acid profiles and phenotypes of T3 plants carrying T-DNAs of plasmids VC-LJB2197- 1qcz and VC-LLM337-1qcz rc cultivated in field trials in USDA growth zones 8a-9a during winter
The data indicate that in the field the T4 seed are making EPA and DHA, but at lower levels than seen in the summer field trial (above, T2 plants cultivated in the field in summer)). The greenhouse data show higher oil content compared to the summer field trials (Comparison of Table 61 with Table 54). This data was analyzed in detail in Example 20.
Table 59: Fatty acid profiles of T4 seeds harvested from T3 plants cultivated in the field in USDA growth zones 8a-9a of canola events contai the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc The events are indicated in the first column, along with the number of T4 s aliquots representing a plot were measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 60: Fatty acid profiles of one T4 seed batch per event harvested from T3 plants cultivated in the field in USDA growth zones 8a-9a of ca events containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column. Fatty profiles of T4 seed batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was meas in two technical repeats.

Table 61 : Phenotypic rating of T3 plants cultivated in the field in USDA growth zones 8a-9b of canola events containing the T-DNAs of plasmids LJB2197-1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of field plots that where rated per e Oil: oil content in T4 seeds harvested from T3 plants (% of seed weight), Protein: Protein content in T4 seeds harvested from T3 plants (% of s cake without oil)

Fatty acid profiles and phenotypes of T4 plants carrying T-DNAs of plasmids VC-LJB2197- 1qcz and VC-LLM337-1qcz rc cultivated in field trials in USDA growth zones 3a-4b and 5a during summer.
The data indicate that through the T5 generation the transformants are still producing EPA and DHA at a level consistent with the field trial of T2 plants in summer. An additional observation is that the oil levels are comparable between these two field trials.
Table 62: Fatty acid profiles of T5 seeds harvested from T4 plants cultivated in the fied in USDA growth zones 3a-4b and 5a of canola ev containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc The events are indicated in the first column, along with the nu of T4 seed aliquots representing a plot were measured per event. Per seed batch a random selection of -30 seed was measured in two tech repeats.

Table 63: Fatty acid profiles of one T5 seed batch per event harvested from T4 plants cultivated in the field in USDA growth zones 3a-4b and 5 canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column. F acid profiles of T5 seed batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed measured in two technical repeats.

Table 64: Phenotypic rating of T4 plants cultivated in the field in USDA growth zones 3a-4b and 5a of canola events containing the T-DNA plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of field plots that
rated per event. Oil: oil content in T5 seeds harvested from T4 plants (% of seed weight), Protein: Protein content in T5 seeds harvested fro plants (% of seed cake without
Example 12: Plants containing the T-DNAs of plasmid VC-LJB2197-1qcz and VC-LLM338-3qcz rc (combination C in example 5) for production of EPA and DHA in seeds
In this example, the genetic elements required for EPA and DHA synthesis were transferred into the plant genome on two different T-DNA. To this end, the two different plasmids VC-LJB2197- 1 qcz and VC-LLM338-3qcz rc containing two different T-DNAs where cloned into Agrobacteria, and plant tissue was incubated according to example 5 at the same time with these two agrobacterial cultures that are identical apart from containing either VC-LJB2197-1 qcz or VC- LLM338-3qcz rc. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of VC-LJB2197-1 qcz. Only those plants where kept, that also contained the T-DNA of plasmid VC-LLM338-3qcz rc as confirmed by PCR, conducted as described in example 5. Only plants containing the T-DNA of plasmid VC-LJB2197-1 qcz as well as the T-DNA of plasmid VC- LLM338-3qcz rc combine all the genetic elements required for EPA and DHA synthesis in seeds. The genetic elements of VC-LJB2197-1 qcz and the function of each element are listed in Table 1 . The genetic elements of VC-LLM338-3qcz rc and the function of each element was listed in Table 5. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC- LJB2197-1 qcz and VC-LLM338-3qcz rc that are required for EPA and DHA synthesis are additionally listed in Table 65.


Fatty acid profiles, copy number measurements, and phenotypic observations of TO plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM338-3qcz rc cultivated in greenhouses during summer
The data in Table 67 and Table 68 indicate that for this construct the increase in EPA and DHA, when comparing single copy to double copy events, was more subtle, but double copy events still had an increase in EPA and DHA over single copy events. As observed in the other examples, there was no significant observed alteration of the phenotype of the plants bearing the T-DNA from both constructs.
Table 66: Copy number measurement of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 1qcz and VC-LLM338-3qcz rc. Considering each event in this generation was represented by only 1 plant, all events have been grouped into categories indicated in the first column; sc: all TO plants where the average of all copy number assays listed in this table was 0.51-1.49, dc: al plants where the average of all copy number assays listed in this table was 1.51-2.49.

Table 67: Fatty acid profiles of T1 seeds harvested from TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM338-3qcz rc. Considering each event in this generation was represented by only 1 plant, all events have b grouped into the categories indicated in the first column as described in Table 66. The number of TO plants/events fullfilling these criteria displayed in parentheses. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 68: Fatty acid profiles of T1 seeds harvested from TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plas
VC-LJB2197-1qcz and VC-LLM338-3qcz rc. Considering each event in this generation was represented by only 1 plant, all events have b grouped into the categories indicated in the first column as described in Table 66. For each category, the fatty acid profile of the plant/event ha
5 the highest EPA+DHA levels was shown. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 69: Phenotypic rating of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz VC-LLM338-3qcz rc. Considering each event in this generation was represented by only 1 plant, all events have been grouped into the catego indicated in the first column as described in Table 66. The number of TO plants/events fullfilling these criteria are displayed in parentheses. days to first flower (days), DF: deformed flower (9=deformed, 1 =normal), DL: deformed leaf (9=deformed, 1 =normal), DP: deformed p
(9=deformed, 1 =normal), DS: deformed silique (9=deformed, 1 =normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf denta (3=no dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes PH: plant height (cm), TKW: thousand kernel weight (g), SC: seed quality (1 =good, 9=bad)

Example 13: Plants containing the T-DNAs of plasmid VC-LJB2755-2qcz rc and VC-LLM391- 2qcz rc (combination D in example 5) for production of EPA and DHA in seeds
In this example, the genetic elements required for EPA and DHA synthesis were transferred into the plant genome on two different T-DNAs. To this end, the two different plasmids VC-LJB2755- 2qcz rc and VC-LLM391-2qcz rc containing two different T-DNAs where cloned into agrobacteria, and plant tissue was incubated according to example 5 at the same time with these two agrobacterial cultures that are identical apart from containing either VC-LJB2755-2qcz rc or VC- LLM391-2qcz rc. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of VC-LJB2755-2qcz rc. Only those plants where kept, that also contained the T-DNA of plasmid VC-LLM391 -2qcz rc as confirmed by PCR, conducted as described in example 5. Only plants containing the T-DNA of plasmid VC-LJB2755-2qcz rc as well as the T-DNA of plasmid VC-LLM391 -2qcz rc combine all the genetic elements required for EPA and DHA synthesis in seeds. The genetic elements of VC-LJB2755-2qcz rc and the function of each element are listed in Table 2. The genetic elements of VC-LLM391-2qcz rc and the function of each element was listed in Table 6. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC-LJB2755-2qcz rc and VC-LLM391 -2qcz rc that are required for EPA and DHA synthesis are additionally listed Table 70.

The data in Table 72, Table 73 and Table 74 show that this combination of constructs was able to insert the T-DNA into the genome, but EPA and DHA accumulation was again at a more subtle level than observed in previous examples. None the less the constructs successfully recapitulated the pathway to generate EPA and DHA and ARA with no impact on the aerial portion of the plant.
Table 71 : Copy number measurement of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 2qcz rc and VC-LLM391-2qcz rc. Considering that each event in this generation was represented by only 1 plant, all events have been grouped the categories indicated in the first column; sc: all TO plants where the average of all copy number assays listed in this table was 0.51-1.49, d



Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in greenhouses during winter.
The data on Table 75, Table 76, Table 77, Table 78, Table 79, Table 80, Table 81 and Table 82 demonstrate that this pair of constructs was successful in recapitulating the pathway to generate VLC-PUFA (C20 and C22, including EPA, DHA and ARA). The copy number for each gene varied from homozygous single insertion of the T-DNA to insertions of parts of the T-DNA's and/or deletions of the T-DNA after insertion into the genome. The fatty acid profile indicated that some events (see Table 78, event LAPCSC) were able to accumulate up to 18 percent EPA and DHA combined). Table 75 indicates that LAPCSC was largely homozygous for a single insertion of each T-DNA with the exception of region of j-p-LuPXR_i-Atss15 on construct VC-LJB2755-2qcz, which contained at least four copies of the regions around that marker. The data presented on Table 81 indicate there was no obvious alteration of the phenotype of the plants bearing T-DNA corresponding to the constructs VC-LJB2755-2qcz and VC-LLM391-2qcz rc.
Table 75: Copy number measurement of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first column, along with the number of T1 plants that were measured per ev The T1 plants underwent a selection from 250 segregating T1 seedlings using half-kernel analysis, where the correlation of VCL-PUFA levels copy number was employed to select for homozygous plants, or on case of multilocus events to selecect for plants where one or more loci 5 homozygous. A copy number of ~2 therefore was indicative for one homozygous locus, a copy number of ~4 indicative for two homozygous lo
indicative for one homozygous locus containing two copies of the target gene measured by the assay, and so forth. Odd results of 3 and 5 indi that at least some of the selected T1 plants carry a heterozygous locus.


Table 76: Copy number measurement of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 2qcz rc and VC-LLM391-2qcz rc. Plants of all events combined have been grouped into the categories indicated in the first column; sc: all T1 pl where the average of all copy number assays listed in this table was 1.51-2.49, dc: all T1 plants where the average of all copy number assays li

Table 77: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc The events are indicated in the first column, along with the number of T2 seed batches that measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.


batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in two tech repeats.


Table 79: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. Plants of all events combined have been grouped into the categories indicated in the first column defined in Table 76. The number of T1 plants fullfilling these criteria are displayed in parentheses. Per seed batch a random selection of -30 s 5 was measured in two technical repeats.

Table 80: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. Plants of all events combined have been grouped into the categories indicated in the first column defined in Table 76. For each category, the fatty acid profile of the plant having the highest EPA+DHA levels was shown. Per seed batch a ran selection of -30 seed was measured in two technical repeats.

Table 81 : Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc VC-LLM391-2qcz rc. The events are indicated in the first column, along with the number of T1 plants that where rated per event. DFF: days to flower (days), DF: deformed flower (9=deformed, 1 =normal), DL: deformed leaf (9=deformed, 1 =normal), DP: deformed plant (9=defor 15 1=normal), DS: deformed silique (9=deformed, 1=normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3 dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobes(#), PH: p
height (cm), TKW: thousand kernel weight (g), SC: seed quality (1 =good, 9=bad), Oil: oil content (% of seed weight), Protein: Protein content ( seed cake without oil)


Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in greenhouses during summer.
The data in Table 83 indicate the copy number of the selected events was a single insertion which was homozygous in the T3 seed. Fatty acid profile measurements, see Table 84 and Table 85, indicated the combination of T-DNAs from VC-LJB2755-2qcz and VC-LLM391-2qcz rc are capable of bringing in the VLC-PUFA pathway to successfully accumulate ARA, EPA and DHA. The data on Table 86 show that there was no significant impact on the aerial portion of the plant caused by VC-LJB2755-2qcz and VC-LLM391-2qcz rc.
Table 83: Copy number measurement of T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first column, along with the number of T2 plants that were measured per event the T2 plants underwent two cylces of selecting homozygous plants, all plants of all events are homozygous for all T-DNA insertions. A copy nu of ~2 therefore was indicative for one homozygous locus, a copy number of ~4 indicative for two homozygous loci or indicative for one homozyg

Table 84: Fatty acid profiles of T3 seeds harvested from T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc The events are indicated in the first column, along with the number of T3 seed batches that w measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 85: Fatty acid profiles of one T3 seed batch per event harvested from T2 plants cultivated in the greenhouse of canola events containing T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first column. Fatty acid profiles of T3 s batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in two tech repeats.


Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in field trials in USDA growth zones 3a-4b and 5a during the summer
Field data for the T3 seed from the events carrying the T-DNA from VC-LJB2755-2qcz and VC- LLM391-2qcz rc, shown in Table 87 and Table 88, indicate that the plants are capable of making VLC-PUFAs in the field (ARA, EPA and DHA), though not at the level observed in the greenhouse. However, there was also a difference in seed oil content observed compared to the greenhouse (e.g. comparing Table 89 with Table 86). These observations are in agreement with previous examples where it was observed that increased oil contents in the field grown plants concomitant with a decrease in VLC-PUFAs, in particular EPA, DHA and ARA. A more detailed description of the observations regarding oil content and VLC-PUFAs is given in Example 20.
Table 87: Fatty acid profiles of T3 seeds harvested from T2 plants cultivated in the field, corresponding to USDA growth zones 3a-4b and 5a field trials of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc The events are indicated in the column, along with the number of T3 seed aliquots representing a plot where measured per event. Per seed batch a random selection of -30 s was measured in two technical repeats.

Table 88: Fatty acid profiles of one T3 seed batch per event harvested from T2 plants cultivated in USDA growth zones 3a-4b and 5a for field t of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first colu Fatty acid profiles of T3 seed batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 s w m r in w hni l r .

Table 89: Phenotypic rating of T2 plants cultivated in USDA growth zones 3a-4b and 5a for field trials of canola events containing the T-DNA plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first column, along with the number of field plots that w rated per event. Oil: oil content (% of seed weight), protein: Protein content (% of seed cake without oil)

Fatty acid profiles, copy number measurements, and phenotypic observations of T3 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in greenhouses during winter.
T4 seed from T3 plants from the event LAODDN, which was homozygous for T-DNA from both VC-LJB2755-2qcz and VC-LLM391 -2qcz rc (see Table 90) accumulated VLC-PUFAs (in particular ARA, EPA and DHA, see Table 91 and Table 92). The combination of EPA and DHA was up to approximately ten percent of the total fatty acid content in the seed for this event.
5

Table 92: Fatty acid profiles of one T4 seed batch per event harvested from T3 plants cultivated in the greenhouse of canola events containing T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first column. Fatty acid profiles of T4 s batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in two tech repeats.

Table 93: Phenotypic rating of T3 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc VC-LLM391-2qcz rc. The events are indicated in the first column, along with the number of T3 plants that where rated per event. DFF: days to flower (days), DF: deformed flower (9=deformed, 1=normal), DL: deformed leaf (9=deformed, 1=normal), DP: deformed plant (9=defor 1=normal), DS: deformed silique (9=deformed, 1=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3 dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes (#), PH: p height (cm)

Fatty acid profiles, copy number measurements, and phenotypic observations of T3 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in field trials in USDA growth zones 8a-9a in the winter.
Field data for T4 seed of two events carrying homozygous T-DNA insertions from VC-LJB2755- 2qcz and VC-LLM391 -2qcz rc (see Table 83 and Table 90 and Table 84, Table 87, Table 91 ) indicate these events do accumulate EPA, DHA and ARA when grown in the greenhouse and field, though as consistently observed, the field grown material did not accumulate the VLC- PUFAs (ARA, EPA, DHA) to the extent observed in the greenhouse (see Table 94 and Table 95 in comparison with Table 91 , Table 92, Table 87 and Table 88). As observed in in Example 1 1 part F, higher oil content was observed compared to the summer field trials (Comparison Table 96 with Table 89). This phenomenon is analyzed in detail in Example 20.
Table 94: Fatty acid profiles of T4 seeds harvested from T3 plants cultivated in the field corresponding to USDA growth zones 8a-9a for field t of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc The events are indicated in the first colu along with the number of T4 seed aliquots representing a plot were measured per event. Per seed batch a random selection of -30 seed measured in two technical repeats.

Table 95: Fatty acid profiles of one T4 seed batch per event harvested from T3 plants cultivated in the field corresponding to USDA growth zo 8a-9a for field trials of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. The events are indicate the first column. Fatty acid profiles of T4 seed batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random sele of -30 seed was measured in two technical repeats.


Fatty acid profiles, copy number measurements, and phenotypic observations of T4 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in field trials in USDA zones 3a-4b and 5a during the summer.
The data indicate that through the T5 generation the event LAODDN was still producing EPA and DHA at a level consistent with the field trial (described in part D). Also oil content was comparable between these two field trials.
Table 97: Fatty acid profiles of T5 seeds harvested from T4 plants cultivated in the field corresponding to USDA growth zones 3a-3b and 5a for trials of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc The events are indicated in the first colu along with the number of T5 seed aliquots representing a plot where measured per event. Per seed batch a random selection of -30 seed measured in two technical repeats.

Table 98: Fatty acid profiles of one T5 seed batch per event harvested from T4 plants cultivated in the field corresponding to USDA growth zo 3a-3b and 5a for field trials of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. The events indicated in the first column. Fatty acid profiles of T5 seed batches having the highest EPA+DHA levels per event are shown. Per seed batc random selection of -30 seed was measured in two technical repeats.

Table 99: Phenotypic rating of T4 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz r VC-LLM391-2qcz rc. The events are indicated in the first column, along with the number of field plots that were rated per event. Oil: oil conte of seed weight), protein: Protein content (% of seed cake without oil)

Example 14: Plants containing the T-DNAs of plasmid VC-LJB2755-2qcz rc and VC-LTM217- 1qcz rc (combination E in example 5) for production of EPA and DHA in seeds
In this example, the genetic elements required for EPA and DHA synthesis were transferred into the plant genome on two different T-DNAs. To this end, the two different plasmids VC-LJB2755- 2qcz rc and VC-LTM217-1 qcz rc containing two different T-DNAs were cloned into Agrobacteria, and plant tissue was incubated according to example 5 at the same time with these two agrobacterial cultures that are identical apart from containing either VC-LJB2755-2qcz rc or VC- LTM217-1 qcz rc rc. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of VC-LJB2755-2qcz rc. Only those plants were kept, that also contained the T-DNA of plasmid VC-LTM217-1 qcz rc rc as confirmed by PCR, conducted as described in example 5. Only plants containing the T-DNA of plasmid VC-LJB2755-2qcz rc as well as the T- DNA of plasmid VC-LTM217-1 qcz rc combined all the genetic elements required for EPA and DHA synthesis in seeds. The genetic elements of VC-LJB2755-2qcz rc and the function of each element are listed in Table 2. The genetic elements of VC-LTM217-1 qcz rc and the function of each element were listed in Table 7. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC-LJB2755-2qcz rc and VC- LTM217-1 qcz rc that were required for EPA and DHA synthesis are additionally listed Table 100.

Table 102 and Table 103 indicate the single copy events for insertions of VC-LJB2755-2qcz and VC-LTM217-1 qcz rc did not accumulate as much EPA and DHA as the double copy events. Table 103 indicates that the combined EPA and DHA content, for the highest producers in T1 seed, was in the range of 15 percent of the total fatty acid content of the seed (5% of the total seed fatty acid content being DHA and 10% being EPA).
Table 101 : Copy number measurement of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 2qcz rc and VC-LTM217-1qcz rc. Considering each event in this generation was represented by only 1 plant, all events have been grouped into categories indicated in the first column; sc: all TO plants where the average of all copy number assays listed in this table was 0.51-1.49, dc: al

Table 102: Fatty acid profiles of T1 seeds harvested from TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2755-2qcz rc and VC-LTM217-1qcz rc. Considering each event in this generation was represented by only 1 plant, all events have b grouped into the categories indicated in the first column as described in Table 101. The number of TO plants/events fulfilling these criteria displayed in parentheses. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 103: Fatty acid profiles of T1 seeds harvested from TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2755-2qcz rc and VC-LTM217-1qcz rc. Considering each event in this generation was represented by only 1 plant, all events have b grouped into the categories indicated in the first column as described in Table 101. For each category, the fatty acid profile of the plant/event ha the highest EPA+DHA levels was shown. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 104: Phenotypic rating of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2755-2qc and VC-LTM217-1qcz rc. Plants of all events combined have been grouped into the categories indicated in the first column; as defined inTable

Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LTM217-1qcz rc cultivated in greenhouses during summer.
Measurements carried out on plants from selected T1 events indicated single copy homozygous insertions of the T-DNA corresponding to VC-LJB2755-2qcz and VC-LTM217-1 qcz rc (see table 104, in particular the table legend) and the T2 accumulates EPA and DHA in similar levels as the T1 . Measurements on T2 seed (see Table 106 and Table 107) showed that EPA and DHA accumulated up to 13% of the total fatty acid content of the seed (with ca. 3% of the seed total fatty acid content being DHA).
Table 105: Copy number measurement of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 2qcz rc and VC-LTM217-1qcz rc. Homozygous plants of the T1 generation of these two events have been selected using Half Kernel Anal (Example 9). Based on the proven ability to discriminate homozygous and heterozygous seeds using half kernel analysis, it can be assumed al

Table 106: Fatty acid profiles of T2 seeds harvested from homozygous T1 plants cultivated in the greenhouse of canola events containing th DNAs of plasmids VC-LJB2755-2qcz rc and VC-LTM217-1qcz rc The events are indicated in the first column, along with the number of T2 s batches that where measured er event. Per seed batch a random selection of -30 seed was measured in two technical re eats.

Table 107: Fatty acid profiles of one T2 seed batch per event harvested from homozygous T1 plants cultivated in the greenhouse of canola ev containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LTM217-1qcz rc. The events are indicated in the first column. Fatty acid profile T2 seed batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in technical repeats.

Table 108: Fatty acid profiles of T2 seeds harvested from homozygous T1 plants cultivated in the greenhouse of canola events containing th DNAs of plasmids VC-LJB2755-2qcz rc and VC-LTM217-1qcz rc. Plants of all events combined have been grouped into the category "sc".

Example 15: Plants containing the T-DNA of plasmid RTP10690-1qcz_F for production of EPA and DHA in seeds
All genetic elements required for EPA and DHA synthesis described in this example, were transferred on a single T-DNA using a BiBAC plasmid into the plant genome. To this end, the plasmid RTP10690-1 qcz_F was cloned into agrobacteria, and plant tissue was incubated according to example 6 with this agrobacterial culture. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of RTP10690-1 qcz_F. The genetic elements of RTP10690-1 qcz_F and the function of each element are listed in Table 8. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of RTP10690-1 qcz_F that required for EPA and DHA synthesis are additionally listed Table 109.
Table 109: List of genes essential of EPA and DHA synthesis carried by the T-DNA of plasmid RTP10690-1qcz_F.

As Table 1 10 indicates there were fewer insertion events of this construct observed than for other constructs, with more single copy events than double copy, by approximately four fold. Fatty acid profile data on Table 1 1 1 and Table 1 12 indicated that DHA and EPA can accumulate up to 4% of the total seed fatty acid content in the T1 with similar performance between single and double copy events, within error. Table 1 13 demonstrates that there was no significant aerial phenotype associated with this construct in the TO.

Table 112: Fatty acid profiles of T1 seeds harvested from TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plas RTP10690-1 qcz rc. Considering each event in this generation was represented by only 1 plant, all events have been grouped into the catego indicated in the first column as described in Table 110. For each category, the fatty acid profile of the plant/event having the highest EPA+ levels was shown. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 113: Phenotypic rating of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmid RTP10690-1qc Considering each event was in this generation represented by only 1 plant, all events have been grouped into the categories indicated in the column as described in Table 110. The number of TO plants/events fullfilling these criteria are displayed in parentheses. DFF: days to first flo (days), DF: deformed flower (1=deformed, 9=normal), DL: deformed leaf (1=deformed, 9=normal), DP: deformed plant (1=deformed, 9=normal), deformed silique (1=deformed, 9=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3=no dentation, 7=str dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes (#), PH: plant height (cm), T thousand kernel weight (g), SC: seed quality (1=good, 9=bad), Oil: oil content (% of seed weight), Protein: Protein content (% of seed cake wit oil)

Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNA of plasmids RTP10690-1qcz_F cultivated in greenhouses during summer
Data in Table 1 15 and Table 1 16 indicate a similar performance of the T2 seed as that of the T1 seed with respect to EPA and DHA, see also Table 1 1 1 and Table 1 12 for comparison. The selected events all performed at a similar level and segregated for one to two copies of each gene.

Table 115: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas RTP10690-1 qcz rc. The events are indicated in the first column, along with the number of T1 plants that were measured per event.

5 Table 116: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas RTP10690-1 qcz rc. The events are indicated in the first column. Fatty acid profiles of T2 seed batches having the highest EPA+DHA levels per e are shown. Per seed batch, a random selection of -30 seed was measured in two technical re eats.

Table 117: Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmid RTP10690-1 qcz rc. events are indicated in the first column, along with the number of T1 plants that were measured per event. Oil: oil content (% of seed weight), Pro Protein content (% of seed cake without oil)

Example 16: Plants containing the T-DNA of plasmid RTP10691-2qcz for production of EPA and DHA in seeds
All genetic elements required for EPA and DHA synthesis described in this example, were transferred on a single T-DNA using a BiBAC plasmid into the plant genome. To this end, the plasmid RTP10691-2qcz was cloned into agrobacteria, and plant tissue was incubated according to example 6 with this agrobacterial culture. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of RTP10691-2qcz. The genetic elements of RTP10691 - 2qcz and the function of each element are listed in Table 9. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of RTP10691 -2qcz that required for EPA and DHA synthesis are additionally listed in Table 1 18.
Table 1 18: List of genes essential of EPA and DHA synthesis carried by the T-DNA of plasmid RTP10691-2qcz.

Example 17: Plants containing the T-DNA of plasmid VC-LTM595-1qcz rc for production of EPA and DHA in seeds
All genetic elements required for EPA and DHA synthesis described in this example, were transferred on a single T-DNA using a BiBAC plasmid into the plant genome. To this end, the plasmid VC-LTM595-1 qcz rc was cloned into agrobacteria, and plant tissue was incubated according to example 6 with this agrobacterial culture. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of VC-LTM595-1 qcz rc. The genetic elements of VC-LTM595-1 qcz rc and the function of each element are listed in Table 10. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC-LTM595-1 qcz rc that required for EPA and DHA synthesis are additionally listed Table 1 19. Table 1 19: List of genes essential of EPA and DHA synthesis carried by the T-DNA of plasmid
VC-LTM595-1qcz rc.

Fatty acid profiles, copy number measurements, and phenotypic observations of TO plants carrying T-DNA of plasmids VC-LTM595-1qcz rc cultivated in greenhouses during summer
Similar to VC-RTP10690-1 qcz_F, the number of insertions of the entire T-DNA was not as high as obtained for the multi-construct transformations, see Table 120. Table 121 and Table 122 show
the fatty acid profile measurements for single, double and triple copy T-DNA, and indicate that the double copy constructs perform marginally better than the single copy constructs and perhaps marginally better than the triple copy constructs in terms of EPA and DHA accumulation. The fatty acid profile data further indicate that the accumulation of EPA and DHA in the T1 seed was up to 10% of the total fatty acids with up to 2% of the total fatty acids in the seed being DHA. Phenotypic measurements, shown on Table 123, indicated some variability in flowering time (as represented by DFF).
5

Table 121 : Fatty acid profiles of T1 seeds harvested from TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LTM595-1qcz rc. Considering each event in this generation was represented by only 1 plant, all events have been grouped into the catego indicated in the first column as described in Table 120. The number of TO plants/events fullfilling these criteria are displayed in parentheses. seed batch a random selection of -30 seed was measured in two technical repeats.

5
Table 122: Fatty acid profiles of T1 seeds harvested from TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LTM595-1qcz rc. Considering each event in this generation was represented by only 1 plant, all events have been grouped into the catego
indicated in the first column as described in Table 120. For each category, the fatty acid profile of the plant/event having the highest EPA+ levels was shown. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 123: Phenotypic rating of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmid VC-LTM595-1qc
5 Considering each event in this generation was represented by only 1 plant, all events have been grouped into the categories indicated in the column as described in Table 120. The number of TO plants/events fullfilling these criteria are displayed in parentheses. DFF: days to first flo (days), DF: deformed flower (1 =deformed, 9=normal), DL: deformed leaf (1=deformed, 9=normal), DP: deformed plant (1 =deformed, 9=normal), deformed silique (1 =deformed, 9=normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3=no dentation, 7=str dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes (#), PH: plant height (cm), T 10 thousand kernel weight (g), SC: seed quality (1 =good, 9=bad)

Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNA of plasmids VC-LTM595-1qcz rc cultivated in greenhouses during winter
The data Table 124, Table 125 and Table 126 indicate that a variety of copy numbers for the genes contained on the T-DNA were obtained, with copy number values ranging from 1 to 3. The performance of the events selected for measurements of fatty acid profiles (see Table 127 and Table 128) was similar to that observed in the previous example with the EPA and DHA combined value being approximately ten percent of the total fatty acid content of the seed, for the upper end of values. The data in Table 129 indicate, as observed in prior generations for this construct (see example 17 part A), that there was some variation in flowering time among the various events.
Table 124: Copy number measurement of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LTM 1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where measured per event. The T1 plants under a selection from 250 segregating T1 seedlings, using zygosity analysis as illustrated in Table 125, keeping only plants that are homozygous for desired number of loci (which are indicated in the last column of Table 125). A copy number of ~2 therefore was indicative for one homozyg copy, a copy number of ~4 indicative for two homozygous copies (located either at on or at two different loci) and so forth. Odd results of 3, 5, etc indicate that at least some of the selected T1 plants carry at least one heterozygous locus. Homozygosity was indicated if the average resu the selected T1 plants was about two fold higher than the the result oberved in the TO generation (indicated in parentheses). For some events

Table 125: Observed Medelian segregation of the genotype of T1 seeds of events from construct VC-LTM595-1qcz rc. The segregation has b analysed at three positions of the T-DNA. For each position, the number of seedlings have been counted that have a copy number (arithmeti rounded) of 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 and 12. The of seedlings counted for each copy number category are separated by colon, displa the categories in the following order: 0 : 1 : 2 : 3 : 4 : 5 : 6 : 7 : 8 : 9 : 10 : 11 : 12. Listed are the observed copy number segregation ratios fo seeds segregating for one or more unlinked genomic loci, which contain one or more linked copies of T-DNA insertions. The observed frequen for each assay have been compared against expected frequencies for various locus configurations listed in Table 136 using Chi-Square anal The last column displays the total number of loci that are segregating in the genome of a given event. Many events contain truncated insertions was evident when some assays indicate single copy insertion at e.g. the left border (e.g. event LBEDTZ), while other position on the T-DNA cle indicate a double copy insertion that are either inserted in one locus (e.g. event LBEDTZ), or in two loci (e.g. event LBEDWU)


Table 127: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LTM595-1qcz rc. The events are indicated in the first column, along with the number of T1 plants that were measured per event.

Table 128: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LTM595-1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where measured per event. For e

Example 18: Plants containing the T-DNA of plasmid VC-LTM593-1qcz rc for production of EPA and DHA in seeds
All genetic elements required for EPA and DHA synthesis described in this example, were transferred on a single T-DNA using a BiBAC plasmid into the plant genome. To this end, the plasmid VC-LTM593-1 qcz rc where cloned into agrobacteria, and plant tissue was incubated according to example 6 with this agrobacterial culture. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of VC-LTM593-1 qcz rc . The genetic elements of VC-LTM593-1 qcz rc and the function of each element are listed in Table 1 1. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC-LTM593-1 qcz rc that are required for EPA and DHA synthesis are additionally listed Table 130.
Table 130: List of genes essential of EPA and DHA synthesis carried by the T-DNA of plasmid VC-LTM593-1qcz rc . Preferred polynucleotide and protein sequences are shown in column 4 and 5.

One observation from the data on Table 131 was that there was a higher number of insertion events obtained from VC-LTP593-1 qcz than obtained from the BiBAC constructs in examples 16 or 17. The data on Table 132 and Table 133 indicate that with respect to VLC-PUFA accumulation, in particular EPA and DHA, double copy events accumulated more than single copy events and that triple copy events accumulated more than double copy events, with accumulation for the triple copy events being approximately eight percent of total fatty acids (EPA and DHA combined, with 1 .6% accumulation of total fatty acids being DHA). The highest amount accumulated was approximately fifteen percent of the total fatty acid content in the seed being EPA and DHA combined, with 3 percent of the total seed fatty acid content being DHA, see Table 133. The aerial phenotype of this construct in the TO plant and T1 seed showed less variation than that seen in examples 16 or 17.
5

indicated in the first column as described in Table 131. The number of TO plants/events fullfilling these criteria are displayed in parentheses. seed batch a random selection of -30 seed was measured in two technical repeats.

Table 133: Fatty acid profiles of T1 seeds harvested from TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LTM593-1qcz rc. Considering each event was in this generation represented by only 1 plant, all events have been grouped into the catego 5 indicated in the first column as described in Table 131. For each category, the fatty acid profile of the plant/event having the highest EPA+ levels was shown. Per seed batch a random selection of -30 seed was measured in two technical repeats.

Table 134: Phenotypic rating of TO plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmid VC-LTM593-1qc Considering each event was in this generation represented by only 1 plant, all events have been grouped into the categories indicated in the 10 column as described in Table 131. The number of TO plants/events fullfilling these criteria are displayed in parentheses. DFF: days to first flo
(days), DF: deformed flower (1 =deformed, 9=normal), DL: deformed leaf (1=deformed, 9=normal), DP: deformed plant (1 =deformed, 9=normal), deformed silique (1 =deformed, 9=normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3=no dentation, 7=str dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes (#), PH: plant height (cm), T thousand kernel weight (g), SC: seed quality (1 =good, 9=bad), Oil: oil content (% of seed weight), Protein: Protein content (% of seed cake wit 5 oil

Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNAs of plasmids VC-LTM593-1qcz rc cultivated in greenhouses during winter
Specific events were examined further for copy number and displayed a variation in insertion number for the T-DNA from single insertion to partial double insertions along with double insertions. Additionally there were some variations in gene copy number (corresponding to the partial insertions and possible deletions), see Table 135, Table 136 and Table 137. The fatty acid profile data shown on Table 138 and Table 139 indicate an upper range of accumulation of combined EPA and DHA of eighteen percent of the total seed fatty acid content (event LBFDAU). In the event LBFDAU the percent of total seed fatty acid content being EPA is 15% and total seed fatty acid content being DHA is 3% in the T1. LBFDAU was analysed with a copy number indicative of a partial double copy. Another example of specific events having higher levels of EPA and DHA was LBFGKN with approximately 12 percent of the total seed fatty acid content being EPA and DHA, with 10 percent of the total seed fatty acid content being EPA and 2% being DHA. The T1 generation LBFGKN had only a single copy insertion event for VC-LTM593-1 qcz rc, though data on Table 140, Table 141 and Table 142 indicate that double copy double locus events tended to accumulate more EPA and DHA combined than other copy and locus numbers with respect to the T2 seed fatty acid profile. This observation likely reflects the nature of insertion site effects and the various factors that affect the generation of elite events. Table 142 indicates that with respect to the aerial phenotype of the plants there was a range of flowering times, as indicated by DFF (days to the first flower) from 36-48. Event LBFDAU did not vary significantly from the majority of other events with a DFF value of 43, thus showing no significant effect on the aerial phenotype or significant impact on total oil or protein accumulation in the seed in the T1 plant and T2 seed.
Table 135: Copy number measurement of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LTM 1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where measured per event. The T1 plants under a selection from 250 segregating T1 seedlings, using zygocity analysis as illustrated in Table 137, keeping only plants that are homozygous for desired number of loci (which are indicated in the last column of Table 137). A copy number of ~2 therefore was indicative for one homozyg copy, a copy number of ~4 indicative for two homozygous copies (located either at on or at two different loci) and so forth. Odd results of 3, 5, etc indicate that at least some of the selected T1 plants carry at least one heterozygous locus. Homozygocity was indicated if the average resu the selected T1 plants was about two fold higher than the the result observed in the TO generation (indicated in parentheses). For some events
was not the case because during selection of T1 plants, undesired loci have been segregated out while retaining only desired loci in a homozyg state.













Table 138: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LTM593-1qcz rc. The events are indicated in the first column, along with the number of T2 seed batches that were measured per event. seed batch a random selection of -30 seed was measured in two technical repeats.





Table 139: Fatty acid profiles of one T2 seed batch per event harvested from T1 plants cultivated in the greenhouse of canola events containing T-DNAs of plasmids VC-LTM593-1qcz rc. The events are indicated in the first column. Fatty acid profiles of T2 seed batches having the hig EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in two technical repeats.



5

of Table 140. For each category, the fatty acid profile of the plant having the highest EPA+DHA levels was shown. Per seed batch a random sele of -30 seed was measured in two technical repeats.

Table 142: Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LTM593-1qc The events are indicated in the first column, along with the number of T1 plants that where rated per event. DFF: days to first flower (days), deformed flower (1=deformed, 9=normal), DL: deformed leaf (1=deformed, 9=normal), DP: deformed plant (1=deformed, 9=normal), DS: defor silique (1=deformed, 9=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3=no dentation, 7=strong dentati



Table 143: Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LTM593-1qc Plants of all events combined have been grouped into the categories indicated in the first column as defined in the description of Table 140. number of T1 plants fulfilling these criteria are displayed in parentheses. DFF: days to first flower (days), DF: deformed flower (1 =defor
9=normal), DL: deformed leaf (1 =deformed, 9=normal), DP: deformed plant (1=deformed, 9=normal), DS: deformed silique (1=deformed, 9=nor
5 FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3=no dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=opti
7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes (#), PH: plant height (cm), TKW: thousand kernel weight (g), SC: seed qu
(1 =good, 9=bad), Oil: oil content (% of seed weight), protein: Protein content (% of seed cake without oil)

Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNAs of plasmids VC-LTM593-1qcz rc cultivated in field trials in USDA growth zone 1 1 during winter.
Certain events that had higher levels of EPA and DHA were tested in the field and examined for fatty acid profile, aerial phenotype (if any) and copy number in the T1 generation. A variety of constructs were examined including those with partial double copy insertions, single copy insertions and double copy insertions being represented (see Table 144). Table 145 indicates that LBFDAU had an EPA content of ca. 13% and a DHA content of ca. 3% of the total seed fatty acid content, and a maximum content for DHA of 3.6% and EPA of 17% of total seed fatty acids (Table 146). Measurements of single seeds from LBFDAU had as much as 26% EPA and 4.6% DHA, see Table 147. Overall the field performance of LBFDAU matched or exceeded that of the greenhouse.
Table 144: Copy number measurement of T1 plants cultivated in field, corresponding to USDA growth zone 11 , during the winter for field trial canola events containing the T-DNAs of plasmids VC-LTM593-1qcz rc. The events are indicated in the first column, along with the number o plants that where measured per event. The T1 plants underwent a selection from -80 segregating T1 seedlings, using zygocity analysis simil the selection performed in the greenhouse (which was illustrated in Table 137), keeping only plants that are homozygous for the desired numb 5 loci. A copy number of ~2 therefore was indicative for one homozygous copy, a copy number of ~4 indicative for two homozygous copies (loc either at on or at two different loci) and so forth. Odd results of 3, 5, 7, 9 etc indicate that at least some of the selected T1 plants carry at least heterozygous locus. Homozygocity was indicated if the average result of the selected T1 plants was about two fold higher than the the result obe in the TO generation (indicated in parentheses). For some events this was not the case because during selection of T1 plants, undesired loci h been segregated out while retaining only desired loci in a homozygous state.
10

Table 145: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the field, corresponding to USDA growth zone 11, during wint canola events containing the T-DNAs of plasmids VC-LTM593-1qcz rc. The events are indicated in the first column, along with the number o seed batches that were measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.










Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LTM593-1qcz rc cultivated in greenhouses during the summer
The data in Table 148 indicate the copy number of the selected events was a single insertion which was homozygous in the T3 seed. Fatty acid profile measurements, see Table 149 and Table 150, indicated the combination of T-DNA from VC-LTM593-1 qcz rc are capable of bringing in the VLC-PUFA pathway to successfully accumulate ARA, EPA and DHA. The data on Table 151 show that there was no significant impact on the aerial portion of the plant caused by VC- LTM593-1 qcz rc.

Table 149: Fatty acid profiles of T3 seeds harvested from T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of pla VC-LTM593-1qcz rc. The events are indicated in the first column, along with the number of T3 seed batches representing a plant measure event. Per seed batch a random selection of -15 seed was measured in five technical repeats.

Table 150: Fatty acid profiles of one T3 seed batch per event harvested from T2 plants cultivated in the greenhouse of canola events containing T-DNAs of plasmid VC-LTM593-1qcz rc. The events are indicated in the first column. Fatty acid profiles of T3 seed batches having the hig EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in two technical repeats.

5 Table 151 : Phenotypic rating of T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LTM593-1qc
The events are indicated in the first column, along with the number of T2 plants that where rated per event. DFF: days to first flower (days), deformed flower (1 =deformed, 9=normal), DL: deformed leaf (1=deformed, 9=normal), DP: deformed plant (1 =deformed, 9=normal), DS: defor silique (1 =deformed, 9=normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3=no dentation, 7=strong dentati
LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobes (#), PH: plant height (cm), TKW: thous kernel weight (g), SC: seed quality (1 =good, 9=bad), Oil: oil content (% of seed weight), protein: Protein content (% of seed cake without oil)

Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LTM593-1qcz rc cultivated in field trials in USDA growth zones 3a-4b and 5a during the summer
Field data for the T3 seed from the events carrying the T-DNA from VC-LTM593-1 qcz rc, shown in Table 152 and Table 153, indicate that the plants are capable of making VLC-PUFAs in the field (ARA, EPA and DHA), though not at the level observed in the greenhouse. ANOVA was conducted with using the software JMP 1 1.0. Analysis was conducted at the 95% confidence level using Tukey test. To compensate for unbalance in the data obtained from the field trial (e.g. due to e.g. weather), Least Square menas instead of means where used in the statistical analysis. Common letters in the Table 154, Table 155and Table 156 indidcate no significant difference of the least square means. Table 154 shows the statistical analysis of agronomical parameters.
There was a difference in seed oil content observed compared to the greenhouse (e.g. comparing Table 154 with Table 151 ), indicating oil content and the fatty acid profile could be linked. These observations are in agreement with previous examples (Examples 10, 1 1 , and 13) where it was observed that increased oil contents in the field grown plants concomitant with a decrease in VLC- PUFAs, in particular EPA, DHA and ARA. A more detailed description of the observations regarding oil content and VLC-PUFAs is given in Example 20. The % of EPA and DHA (% w/w for each fatty acid compared to the total weight of fatty acids) in Table 152 can be combined with the oil amount in Table 154 to calculate the mg EPA+DHA /g seed produced in the transgenic events. Using this calculation, bulked seeds from event LBFGKN were determined to have 25.7 mg EPA+DHA/g seed and bulked seeds from event LBFDAU was determined to have 47.4 mg EPA+DHA/g seed.
For seed yield (kg per ha, Figure 88), no statisticaly relevant difference was found comparing the events against wildtype Kumily when grown in the field with or without treatment with imidazolinone herbicide (tested using Tukey, 0.05% level). Thus, in one embodiment, the present invention relates to one or more transgenic plants, preferably B. napus plant(s), producing EPA and DHA, according to the present invention whereby the seed yield of the plant is 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or more identical to a control plant. Preferably, the seed yield of the plant is 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or more identical to a control grown without treatment with imidazolinone herbicide whereas the plant of the invention is grown with an imidazoline herbicide treatment.
In one embodiment, the harvesting bulk seed from the plants of the invention, preferably from the plants grown in a field, has a measured yield (kg seed/ha) that is 15%, 8%, 4%, or preferably 1 % or less lower than the yield of a control plant. Preferably, the harvested bulk seed yield of the plant is 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or more identical to a control grown without treatment with imidazolinone herbicide whereas the plant of the invention is grown with an imidazoline herbicide treatment.
Thus, a transgenic B. napus plant of the invention is able to produce more than 1 % EPH + DHA in the oil in the bulk seed, preferably, it produces more than 2%, e.g. more than 3%, 4%, 5%, 6%, 7%, 8%, 9% or more than 10% oil in the bulk seed. Preferably, the oil in the bulk seed of the plant of the invention is 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or more identical to a control plant grown without treatment with imidazolinone herbicide whereas the plant of the invention is grown with an imidazoline herbicide treatment. The contents are expressed as percentage (weight of EPA + DHA) of the total weight of all fatty acids (present in the oil or lipid). The contents are thus, preferably given as weight percentage (% w/w). A control plant is preferably a plant that is at least genetically 90%, 95%, 96%, 97%, 98%, or preferably 99% or 99,5% or more identical to the plant of the invention, e.g. to the plants described in the examples, but does not produce any VLC-PUFA grown under the same conditions, e.g. a wild type grown under the same conditions. Herbicide treatment also did not have a consistent effect on EPA and DHA (Figure 89), oil (Figure 90), or protein (Figure 91 ) content in seeds compared to plants that were not sprayed with imidazolinone. Thus, in one embodiment, the present invention relates to one or more transgenic plants, preferably B. napus plant(s), producing EPA and DHA, according to the present invention whereby the oil (Figure 90), or protein (Figure 91 ) content of the plant is 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or more identical to a control plant.
A control plant is preferably a plant that is at least genetically 90%, 95%, 96%, 97%, 98%, or preferably 99% or 99,5% or more identical to the plant of the invention, e.g. to the plants described in the examples, but does not produce any VLC-PUFA, in particular a control plant grown without treatment with imidazolinone herbicide whereas the plant of the invention is grown with a imidazoline herbicide treatment.
Thus, in one embodiment, the bulk seed of the transgenic plant of the invention comprises a seed oil that contains EPA and DHA, wherein the the content of EPA and DHA in the seed oil is more than 2%, 3, %, 4%, 5%, 5.9%, 6%, 7%, 8%, 9%, 10%, 12%, 15% of the total fatty acid content in seed oil, even after treatment with imidazolinone herbicide
Fertility of plants in the field was assessed by rating the percent of sterile pods on mulitple plants from each plot. Fertility was assessed for WT Kumily, and for events LBFDGG, LBFGKN, LBFIDT, LBFIHE, LBFLDI, and LBFPRA. On a scale of 0 to 10, a score of 0 means that 0% of pods were sterile, 1 means that 10% of pods were sterile, 2 means that 20% of pods were sterile, and so on up to 10, which means that 100% of pods were sterile. The mean fertility score for wild type Kumily control plants across all plots was 0.17, meaning that 1 .7% of pods were sterile. The mean score for the transgenic events ranged from 0.33 to 0.63, meaning that 3.3 to 5.3% of pods were sterile.
Interestingly, expression of the polynucleotides encoding the desaturases or elongases as referred to herein did not significantly affect the fertility of the generated plants. As compared to control plants (wild-type plants), the fertility was only slighty decreased.
Thus, the present invention relates in one embodiment to a a transgenic plant, preferably to a transgenic B. napus plant seed containing more than 2%, 2,5%, 3%, 4%, 5%, 6%, 7%, 8%; 9%, 10%, 12% or more EPA and DHA in the seed oil when grown in field conditions. The average plant fertility as measured by selecting at random a number of plants then observing percent plants with one or more sterile pods/bud is 30% or less, or is 20% or less, or is about 10% or less or is 5% or less or is 4% or less or is 3,3% or less, preferably is between 1 % and 10%, more preferred between 3% and 7%, e.g. between 3.3% and 5.3% of the same measure observed in a control plant, e.g. in a wild type plant grown under the same conditions. Preferably, a control plant is preferably a plant that at least genetically 90%, 95%, 96%, 97%, 98%, or preferably 99% or 99,5% or more identical to the plant of the invention, e.g. to the plants described in the examples, but does not produce any VLC-PUFA.
In one embodiment, the plant of the invention was transformed with a medium (>10,000 base pairs) or large (>30,000 base pairs) T-DNA insert, e.g. a T-DNA described in the Examples. In one embodiment, the T-DNA is consists of 1000bps to 10,000 bps, e.g. between 3000bps and 9000bps, preferably between 4000bps and 8500bps.
Table 152: Fatty acid profiles of T3 seeds harvested from T2 plants cultivated in the field, corresponding to USDA growth zones 3a-4b and 5a field trials of canola events containing the T-DNAs of plasmid VC-LTM593-1qcz rc. The events are indicated in the first column, along with
number of T3 seed aliquots representing a plot where measured per event. For event LBFGKN, 36 plots and 60 single plants from those plots w measured. Per seed batch a random selection of -15 seed was measured in five technical repeats.


Table 153: Fatty acid profiles of one T3 seed batch per event harvested from T2 plants cultivated in USDA growth zones 3a-4b and 5a for field t of canola events containing the T-DNAs of plasmid VC-LTM593-1qcz rc. The events are indicated in the first column. Fatty acid profiles of T3 s
5

appear healthy), Plant Height: the average height (cm) of five plants in a plot measured from soil level to the top of the plant at GS 69 (cm), Lodg rating of the average standability of plants in a plot at GS 83 (30% of pods ripe, 1 =0 - 10% average lean of plants in plot from horizontal (stan erect), 9=81 %+ average lean of plants in plot from horizontal (nearly prostrate)), Shatter: rating of the ability of plants to retain seed in the pod at
89 (all pods fully ripe, 1 =0 - 10% perished pods, 9=81 %+ perished pods), Agron Score: scale of 1-5 with 1 being the best, 5 the worst rankin
5 plant phenotype (measurements occurred post flower during pods formation and seed development), Moisture (% of seed weight), TKW: thous kernel weight (g), Oil: oil content (% of seed weight), protein: Protein content (% of seed cake without oil).
Table 155: Compositional analysis of T3 seeds of T2 plants cultivated in USDA growth zones 3a-4b and 5a for field trials of canola events contai the T-DNAs of plasmid VC-LTM593-1qcz rc. The events are indicated in the first column. The analysis has been done on 4 BULK, whereby e 10 BULK is a representative sample of all seeds harvedted from 4 different geographic reagions. Alpha-Tocopherol (mg/100g seed), Beta-Tocoph (mg/100g seed), Delta-Tocopherol (mg/100g seed), Gamma-Tocopherol (mg/100g seed), Tocopherol (mg/100g seed), Sinapine (pg/g (pp
Phytate (% of seed weight (w/w)), Ash (% of seed weight (w/w)), Crude Fiber (% of seed weight (w/w)), ADF: acid detergent fiber (% of seed we (w/w)), NDF: neutral detergent fiber (% of seed weight (w/w)). All results have been normalized to the seed weight of seeds having 0% moistur

Table 156: Herbicde tolerance of T2 plants cultivated in USDA growth zones 3a-4b and 5a for field trials of canola events containing the T-DN plasmid VC- VC-LTM593-1qcz rc. The events are indicated in the first column. IMI Injury: injury according to the scale detailed in Table 157 (D days after treatment). Herbicide imazamox was aplied at a 2x rate of 70 g imazamox /ha. Brassica napus cv Kumily, which is the non-transge comparator line that is otherwise isogenic to the events, was rated at 6 to 7, and was removed from the statistical analysis to make the Tukey 5 more sensitive to detect significant differences between events that are very similar in their tolerance.

Table 157: Canola rating scale for herbicide

Example 19: Gene copy number effects on observed conversion efficiencies at each pathway step.
When analysing the VLC-PUFA levels of the various constructs listed in this invention, distinct differences were observed in conversion efficiency at the pathway steps when the T-DNA copy number increased. This was observed when comparing the VLC-PUFA levels of (1 ) events having a single copy T-DNA insertion vs a double copy T-DNA insertion, (2) heterozygous plants vs homozygous plants, and (3) when analysing segregating single seeds as described in Example 9 and shown in Figure 22 and Figure 23. This demonstrates a relationship between 'gene dosage', that is the number of T-DNA copies present in the genome, and VLC-PUFA levels. Upon further investigation it is clear that certain genes/steps of the VLC-PUFA pathway benefit more in terms of impact on the pathway when the gene number and/or expression level of the gene or activity at that step is increased. While the contribution from each gene present, when multiple genes which encode enzymes with identical activities are present, are difficult to assess (e.g. two different omega-3-desaturases are technically difficult to assess), it was possible to calculate conversion efficiencies for each pathway step, by using the equations shown in Figure 2. These conversion efficiencies for each pathway step were calculated for various populations of plants that represent a certain gene dosage, in order to investigate if the observed increase in conversion efficiency can be assigned to one or more individual pathway steps (e.g. increasing conversion efficiency due to increased gene dosage at one early step in the pathway may increase conversion efficiency at a later step simply be providing more of a limiting substrate).
The conversion efficiencies are sometimes referred to as "apparent" conversion efficiencies because for some of the calculations it is recognized that the calculations do not take into account all factors that could be influencing the reaction. As an example of factors that may be influencing a reaction but are not taken into account during the conversion efficiency calculation; the substrates of the delta-6-desaturase are produced while bound at the sn-2 positions of phospholipids, whereas the product of the delta-6-desaturase is formed while the fatty acid is bound to CoA. It is therefore not immediately clear if the lower delta-6-desaturase conversion efficiencies shown in Figure 33 are due to inefficient provision of substrate to the delta-6- desaturase via trans-esterification from PC (phosphatidylcholine) bound LA/ALA to CoA bound LA/ALA, or whether the delta-6-desature had low activity/low conversion efficiency.
For the interpretation of the conversion efficiencies it was also important to note that any catalyzed conversion of substrate to product was dependent on the substrate concentration, catalyst (enzyme) concentration, and product concentration.
Analysing the data pathway step by pathway step, the following observations can be made in Figure 32 to Figure 39:
Conversion efficiency of delta- 12-desaturation
The delta-12-desaturase conversion efficiency encompasses all steps that influence substrate concentration, product concentration, and enzyme concentrations. From the data in example 21 it is evident that the delta-12-desaturase, c-d12Des(Ps_GA), enzymatically produces phosphatidylcholine bound 18:2n-6 (Figure 26, Panel A), which implies the substrate was
phosphatidylcholine bound 18:1 n-9. The primary flux of newly formed 18:1 n-9 was derived from plastid produced 18:1 n-9, which was exported into the cytosol, where it was bound to CoA. Therefore, a prerequisite of delta-12-desaturation was the incorporation of CoA-bound 18:1 n-9 into the sn2 position of phosphatidylcholine via LPCAT (Lysophosphatidylcholine acety transferase EC 2.3.1.23), or via LPAAT (Lysophosphatidic acid acyltransferase E.C. 2.3.1.51 ), with subsequent conversion of the formed (sn2)18:1 n-9-phosphatidic acid into (sn2)18:1 n-9-DAG (DAG is an abbreviation for diacylglycerol), whereby (sn2)18:1 n-9-DAG was either directly converted into (sn2)18:1 n-9-PC (PC is an abbreviation for phosphatidylcholine) substrate for the delta-12-desaturases via PDCT (phosphatidylcholine diacylglycerol cholinephosphotransferase EC 2.7.8.2), or obtains a phosphocholine headgroup via CPT (CPT is an abbreviation for sn-1 ,2-diacylglycerol:cholinephosphotransferase EC 2.7.8.2) to be converted into (sn2)18:1 n-9-PC. The efficiency of this incorporation of plastid synthesized 18:1 n- 9 directly affects delta-12-desaturase substrate concentration. As mentioned already, PC is converted by PDCT into DAG, which was subsequently converted into TAG. The amount of PC bound delta-12-desaturase substrate and product that was part of the delta-12-desaturase reaction was therefore also directly linked to the substrate specificity of PDCT.
There was a strong correlation of the delta-12-desaturation conversion efficiency with the copy number of the delta-12-desaturase (Figure 32). This was evident when comparing the average conversion efficiency of TO single copy plants (across all events per construct), with the average conversion efficiency of TO double copy plants (across all events per construct). The same correlation can be seen in the T1 generation. The strong correlation of the delta-12-desaturation conversion efficiency with the copy number of the delta-12-desaturase was also seen when comparing copy number differences due to heterozygous vs homozygous T-DNA integrations: The TO generation always consist of heterozygous plants, whereas the T1 generation largely consists of homozygous plants due to the selection applied in Example 10 through Example 18. The delta-12-desaturation conversion efficiency increases when comparing the average conversion efficiency of TO single copy plants (across all events per construct), with the average conversion efficiency of T1 single copy plants (across all events per construct). Similarly, the delta-12-desaturation conversion efficiency increases when comparing the average conversion efficiency of TO double copy plants (across all events per construct), with the average conversion efficiency of T1 double copy plants (across all events per construct). The only exceptions are:
1 ) TO single copy events vs TO double copy events containing the T-DNAs of VC-LJB2197-1 qcz and VC-LLM337-1 qcz rc: while not as pronounced as for VC-LJB2197-1 qcz and VC-LLM306- 1 qcz rc, there are also subtle differences here in delta-12-desaturase conversion efficiencies. The slight differences are due to insufficient data in the TO generation to accurately assign the events to the two copy number categories for events containing the T-DNAs of construct VC-LJB2197- 1 qcz and VC-LLM337-1 qcz rc, and
2) TO single copy events vs TO double copy events containing the T-DNAs of VC-LJB2197-1 qcz and VC-LLM338-3qcz rc: while not as pronounced as for VC-LJB2197-1 qcz and VC-LLM306-
1 qcz rc, also here the subtle differences in delta-12-desaturase conversion efficiencies are due to insufficient data in the TO generation to accurately assign the events to the two copy number
categories for events containing the T-DNAs of construct VC-LJB2197-1 qcz and VC-LLM338- 3qcz rc, and
3) T1 single copy events vs T1 single copy (single locus) events containing the construct VC- LTM593-1 qcz rc: there was no effect on the conversion efficiency due to the 2-fold copy number difference between these groups. The group of single copy (single locus) events is affected by an additional phenomenon whereby the average VLC-PUFA level in T2 seeds of T1 plants of this homozygous group decreases instead of increasing compared to segregating T1 seeds of heterozygous TO plants. A further indication that this group was an outlier group can be seen in Figure 35, where it was evident that the delta-5-desaturase conversion efficiency was significantly lower in homozygous plants compared to heterozygous plants.
Considering the high conversion efficiency of the delta-12-desaturase, it is likely that the provision of substrate via LPCAT is not a bottleneck. Also, the data suggest that efficient removal of delta- 12-desaturase products contributes to the high conversion efficiency. However; taking into account the high levels of 18:2n-6 accumulated in the oil and the low delta-6-conversion efficiency, it was evident that not all delta-12-desaturated 18:2n-6 was removed from PC via trans- esterifi cation to CoA (the site of action for the next pathway step). With respect to the fate of 18:2n-6; our observations indicate that the delta-12-desaturated 18:2n-6 was likely removed by the direct conversion of unsaturated PC into DAG via PDCT as discussed by Bates et al. (2012) Plant Physiology 160: 1530-1539. This activity of PDCT strongly supports a high delta-12- desaturase conversion efficiency by providing fresh 18:1 n-9-PC substrate to the delta-12- desaturase, while simultaneously removing 18:2n-6-PC product (by conversion into DAG). However, the latter activity poses a strong bottleneck for the continuation of the pathway, which is evident by the low delta-6-desaturase conversion efficiencies. This effect of increased conversion efficiency of the delta-12-desaturase has been observed when analyzing the PUFA profile of more than 6.000 plants that have been obtained by transforming more than 300 multi-gene constructs into Canloa and Arabidopsis, whereby all of these constructs carried genes having the essential activities required for Arachidonic acid synthesis. Across these more then 300 constructs, more than 10 different delta-12-desaturase enzymes have been investigated.
Conversion efficiency of delta-6-desaturation
For the delta-6-desaturation, it was of particular importance to highlight that conversion efficiencies observed for this step are dependent on the substrate concentration (which was CoA bound linoleic acid), catalyst concentration (which was the delta-6-desaturase), and product concentration. It was, that PC bound 18:2n-6 produced by the delta-12-desaturase needs to be trans-esterified to CoA before delta-6-desaturation can take place. The absence of accumulation of 18:3n-6 and 18:4n-3 in the examples 10 -18 strongly indicates that CoA-bound 18:3n-6 and CoA-bound 18:4n-3 was efficiently converted by the delta-6-elongase, effectively preventing any significant accumulation of 18:3n-6 and 18:4n-3. In general, delta-6-desaturase conversion efficiencies are low for all constructs. Considering efficient removal of product was not a bottleneck, the low conversion efficiencies can be either due to low activity of the delta-6- desaturase enzyme, or because of inefficient conversion of PC-bound substrate into CoA-bound
substrate. Regardless of this, there was a clear correlation of the delta-6-desaturation conversion efficiency with the copy number of the delta-6-desaturase. In a manner similar to that of the delta- 12-desaturase, this was seen regardless of the reason for the copy number increases (heterozygous vs homozygous, single copy genomic integrations vs double copy genomic integrations). In fact, plants of the construct combination VC-LJB2197-1 qcz and VC-LLM306-1 qcz rc contain an additional copy of the delta-6-desaturase on the T-DNA. It was therefore consistent that the group of 22 double copy T1 plants would have in the T2 seeds the highest delta-6- desaturase conversion efficiencies of all similar double copy groups of different constructs. For the delta-6-desaturase, the same exceptions to this copy number effect as for the delta-12- desaturase are seen. The same for the interpretation mentioned for the delta-12-desaturase of why these exceptions are observed are assumed to be the reasons for the delta-6-desaturase also applies in this case. The exceptions are:
1 ) TO single copy events vs TO double copy events containing the T-DNAs of VC-LJB2197-1 qcz and VC-LLM306-1 qcz rc, and
2) TO single copy events vs TO double copy events containing the T-DNAs of VC-LJB2197-1 qcz and VC-LLM337-1 qcz rc, and
3) TO single copy events vs TO double copy events containing the T-DNAs of VC-LJB2197-1 qcz and VC-LLM338-3qcz rc, and
4) T1 single copy events vs T1 single copy(single locus) events containing the construct VC- LTM593-1 qcz rc.
As demonstrated for the delta-12-desaturase, the amount of delta-12-desaturase product increases with increasing copy number of the delta-12-desaturases, which implies an increased amount of substrate for the delta-6-desaturase. As both the delta-12-desaturases and the delta- 6-desaturase are contained on the same T-DNA in all examples 10 to 18, the copy number of the delta-6-desatuases will also increase when copy number of the delta-12-desaturase increases, with the exceptions of events where truncated insertion of the T-DNA contain either the delta-12- desaturase and not the delta-6-desaturases, or vice versa.
In summary, not only was the effect of the gene copy duplication of the delta-12-desaturase surprising, but it was also unexpected that the increased copy number of delta-6-desaturase led to an increased amount of delta-6-desaturase protein, and this increased amount of protein can convert the additional amount of delta-12-desaturated fatty acids with an increased conversion rate. To illustrate the effect, here as an example of the comparison of two groups shown in examples 10 to 18 that have a gene copy number difference of "four":
Group A: All 275 heterozygous TO plants containing a single copy of the T-DNA of construct VC- LTM593-1 qcz rc
Group B: All 64 homozygous T1 plants containing two copies the T-DNA of of construct VC- LTM593-1 qcz rc at two different chromosomal loci.
In group A, the total sum of fatty acid that contain a double bond due to the activity of the delta- 12-desaturase was 47.3% and total sum of fatty acids that contain a double bond due to the activity of the delta-6-desaturase was 1 1 .2%. Consequently, 23.7% of all fatty acids that underwent delta-12-desaturation also underwent delta-6-desaturation.
In group B, the total sum of fatty acid that contain a double bond due to the activity of the delta- 12-desaturase was 61 % and total sum of fatty acid that contain a double bond due to the activity of the delta-6-desaturase was 23.7%. Consequently, 38.8% of all fatty acids that underwent delta- 12-desaturation also underwent delta-6-desaturation.
As a result of that, the sum of all fatty acids downstream of the delta-6-desaturase in the pathway more than doubled in group B versus group A.
This effect of increased conversion efficiency of the delta-6-desaturase has been observed when analyzing the PUFA profile of more than 6.000 plants, that have been obtained by transforming more than 300 multi-gene constructs into Canloa and Arabidopsis, whereby all of these constructs caried genes having the essential activities required for Arachidonic acid synthesis. Across these more then 300 constructs, more than 5 different delta-6-desaturase enzymes have been investigated.
Conversion efficiency of delta-6-elongation
As was evident in Figure 34, the conversion efficiency of the delta-6-elongation was very high regardless of the copy number. Because of that, copy number mediated effects on the conversion efficiency are sometimes insignificant, but are sometimes clearly observed. E.g. the events obtained for the construct combinations VC-LJB2755-2qcz rc + VC-LLM391 -2qcz rc and for the combination LJB2755-2qcz rc and VC-LTM217-1 qcz rc contain the lowest delta-6-elongation conversion efficiencies of all constructs, which can be attributed to the fact that these construct combinations encode just one delta-6-elongation enzyme [c-d6Elo(Tp_GA2)], instead of two [(c- d6Elo(Tp_GA2), c-d6Elo(Pp_GA2)].
Conversion efficiency of delta-5-desaturation
The data in Figure 35 do not indicate a consistent construct independent copy number dependence of the delta-5-desaturase. Conversion efficiency of omega-3-desaturation
Figure 36 shows the omega-3-desaturase conversion efficiencies that have been calculated by excluding the C18 substrates and products shown in Figure 2, thereby excluding the delta-15- desaturase specific activity of omega-3-desaturases. Figure 37 shows the omega-3-desaturase conversion efficiencies that have been calculated by including the C18 substrates and products, thereby including the delta-15-desaturase specific activity of omega-3-desaturases. As both omega-3-desaturases used in the invention have virtually no delta-15-desaturase activity, conclusions on the effect of copy number on the omega-3-desaturase are best drawn from Figure 36. While not as pronounced as observed for the delta-12-desaturase or delta-6-desaturase, there is, in many cases, a clear link between omega-3-desaturase copy number and the omega-3- desaturase conversion efficiency. This was particularly evident as plants of the construct combination as VC-LJB2197-1 qcz + VC-LLM338-3qcz rc display the lowest omega-3-desaturase conversion efficiency of all other constructs, which can be attributed to the fact that this construct combination encodes just one omega-3-desaturase enzyme [c-o3Des(Pi_GA2)j, instead of two
[(c-o3Des(Pi_GA2), c-o3Des(Pir_GA)]. Exceptions to the copy number dependence of the omega-3-desaturase conversion efficiency are:
1 ) Plants containing the T-DNAs of construct RTP10690-1 qcz_f, and
2) Plants containing the T-DNAs of construct VC-LTM595-1 qcz rc, and
3) Plants containing the T-DNAs of VC-LJB2197-1 qcz and VC-LLM338-3qcz rc, and
Conversion efficiency of delta-5-elongation
The complex interdependency of all the pathway step conversion efficiencies between each other can be seen by comparing Figure 38 with Figure 35: the high delta-5-elongation conversion efficiency for two groups of plants containing the T-DNAs of construct VC-LTM593-1 qcz rc (813 T1 plants of the double copy group, 700 plants of the double copy/single locus group) was in fact not due to a high delta-5-elongation conversion efficiency, but rather due to an inefficient supply of substrate to the delta-5-elogase at the delta-5-desaturase pathway step. Similar to the omega- 3-desaturase, while not as pronounced as for the delta-12-desaturase or delta-6-desaturase, there was a link between delta-5-elongase copy number and the delta-5-elongase conversion efficiency.
Conversion efficiency of delta-4-desaturation
As can be seen in Figure 39, there was no direct evidence for a dependence of delta-4-desaturase conversion efficiency on delta-4-desaturase copy number. The highest delta-4-desaturase conversion efficiency has been observed for plants containing the T-DNAs of construct LJB2755- 2qcz rc and VC-LTM217-1 qcz rc. This construct combination differs only from the combination VC-LJB2755-2qcz rc + VC-LLM391 -2qcz rc in replacing the d4Des(Eg) by the c-d4Des(PI_GA)2. As a conclusion of the plant data shown in Example 10 to 18 and the yeast data shown in Example 22, it can be clearly seen that the delta-4-desaturation conversion efficiency reaches an upper limit using the genes c-d4Des(Tc_GA) and d4Des(Eg), that cannot be overcome by increased gene copy numbers. All constructs that encode the c-d4Des(PI_GA)2 instead of d4Des(Eg) have a higher delta-4-desaturation conversion efficiency, and the only exception to that are plants containing the construct RTP10690-1 qcz_F. As shown in Example 25, this was due to very low expression of both delta-4-desaturases. This in turn highlights that the conversion efficiency does depend on the gene expression, but cannot overcome an upper limit.
Example 20: Environmental effects on VLC-PUFA levels. Correlation between oil content, VLC- PUFA levels, and observed conversion efficiencies at each pathway step
Analysing the VLC-PUFA levels presented in the Examples 10 to 18, we have oberserved that there is, in most cases, a level of variability, within a genetically identical population of plants (e.g. a genetically stable event where all plants are genetically identical), even when these plants are grown in a controlled greenhouse environment. To illustrate the effect more clearly, VLC-PUFA profiles of seed batches having highest EPA+DHA levels among several type of plant populations are shown in the examples 10 to 18. Such plant populations are (1 ) either genetically identical due to the T-DNA integrations (i.e. all plants of the same event, where either all or at least most are homozygous for all T-DNA integrations in those events), or (2) identical related to the T-DNA
copy number, and these populations have been grown in the same environment. For example, out of 249 segregating T1 seedlings, 10 T1 plants for event LBFDAU (see Example 18) have been identified in the greenhouse to be identical in having one complete T-DNA integration, and one truncated T-DNA integration, whereby both T-DNA insertions where found to be homozygous (Table 135). In a field trial conducted in parallel, out of about segregating T1 seedlings, 4 plants have been identified as being homozygous for both T-DNA insertions (Table 144). The average EPA+DHA content measured in randomly selected seed from seed batches of these 10 greenhouse grown plants was found to be 13.9% EPA + 2.6% DHA. Similarly, the EPA+DHA content of the 4 field grown plants was found to be 13.4% EPA + 2.7% DHA. Among the 10 greenhouse grown plants was a plant that produced up to 15.1 % EPA + 3.0% DHA (Table 139). Similarly, among the 4 field grown plants was a plant that produced up to 17.6% EPA + 3.6% DHA (Table 146). Analysing single seed of this field grown plant, single seeds having up to 26.2% EPA + 4.9% DHA, or 23.6%EPA + 5.8% DHA where found (Table 147). The lowest EPA+DHA content found among these 95 seed contained 13.5% EPA and 2.5% DHA, and the average content among these seed was 18.2% EPA and 3.7% DHA, which matched the content measured in the random selection of twice 15 seed as shown in Table 146 (17.6% EPA + 3.6% DHA). This event LBFDAU is just a representative example to illustrate that for every event, and for all constructs, there is plant-to-plant variability, and seed-to-seed variability. The extent of the plant to plant variability is shown in the examples 10 to 18, where it is shown that the average PUFA profile of a certain population (e.g. all plants belonging to the same event and are genetically identical, or all plants are single copy, heterozygous) is always different than the profile observed in individual plants. To illustrate the magnitude of this variability, examples 10 to 18 show the average PUFA profile of such populations and also the profile of the single plant having the highest EPA+DHA levels.
While the event LBFDAU was capable of producing in a genetically identical plant population ~13.5% EPA + 2.6% DHA in a given environment, there are individual plants within this population that produce up to -18% EPA + 3.7% DHA as an average of all seeds produced by this plant, and single seed of this plant can reach up to -26% EPA and -5% DHA. These differences in EPA+DHA levels are due to the interaction of the genetic constituents of the event with the environment. However, it was consistently observed that comparable populations yield higher VLC-PUFA levels in the greenhouse compared to the field. This trend usually correlates with lower oil content in the greenhouse, compared to the field. To investigate this observation in more detail, oil content measured in all homozygous seed batches of the single copy event LANPMZ (event described in example 1 1 ) was plotted in Figure 40 against the sum of all VLC-PUFA that are downstream of the delta-12-desaturase (see Figure 2) measured in the same seed batches. The same has been done for event LAODDN (event described in example 13), and is plotted Figure 41. This analysis was also done for two events described in example 18, namely for event LBFGKN (Figure 42), and for event LBFLFK (Figure 43). What was observed is a strong correlation between these two parameters. The same analysis for wildtypes (Figure 72) reveals no such correlation, instead, Figure 72 shows a difference between greehouse grown and field grown wildtype plants, in that field grown wildtype plants have higher levels of 18:2n-6 and 18:3n- 3 and lower 18:1 n-9 compared to greenhouse grown wildype plants.
To analyse in detail if this correlation depicted for event LANPMZ in Figure 40 can be attributed to certain pathway steps, conversion efficiencies for each pathway step and for each seedbatch analysed in Figure 40 have been calculated, and plotted in Figure 44, Figure 48, Figure 52, Figure 56, Figure 60, Figure 64, and Figure 68. The same analysis has been done for event LAODDN, and is plotted in Figure 45, Figure 49, Figure 53, Figure 57, Figure 61 , Figure 65 and Figure 69. The same analysis was also been done for event LBFGKN, (plotted in Figure 46, Figure 50, Figure 54, Figure 58, Figure 62, Figure 66 and Figure 70), and for event LBFLFK (Figure 47, Figure 51 , Figure 55, Figure 59, Figure 63, Figure 67 and Figure 71 ). Comparing all these figures, one can see that the correlation observed in Figure 40 and Figure 41 is largely attributed to the delta-12- desaturase pathway step (Figure 44 to Figure 47), the delta-6-desaturase pathway step (Figure 48 to Figure 51 ), and the delta-4-desaturase pathway step (Figure 68 to Figure 71 ): in these figures, there is a construct and event independent negative correlation between the pathway steps and the seed oil content visible, which cannot be observed for the other pathway steps. The negative correlation of the delta-12-desaturase pathway with seed oil content in event LANPMZ was observed in wild type plants, as shown in Figure 72. Moreover, Figure 72 shows that field grown wildtype plants have higher levels of 18:2n-6 and 18:3n-3 and lower 18:1 n-9 compared to greenhouse grown wildype plants. This can most likely be explained with previous observations (Xiao et al. 2014), in that the native Canola endogenous delta-12-desaturase was regulated by temperature and that temperature regulation of delta-12-desaturase at the transcript level and protein level is a recurring theme in plants (Kargiotidou et al. 2008, Tang et al. 2005, Sanchez-Garcia et al. 2004), whereby under field conditions the delta-12-desaturase would be up-regulated compared to greenhouse conditions. However, it can be concluded that there was no regulation of the delta-12-desaturase in dependance of the oil content observed in wildtype canola plant. Consequently comparing Figure 72 with Figure 40 to Figure 43), it can furthermore be concluded that only the introduced transgeneic delta-12-desaturase was subject to a regulation that was seed oil content dependent.
A further observation is that field grown transgenic plants do not have a higher delta-12- desaturase conversion efficiency compared to greenhouse grown plants, even though this was clearly oberved for wildtype plants in Figure 72. It can be concluded that the endogenous native delta-12-desaturase does not significantly contribute to the overall observed delta-12-desaturase conversion efficiency in the transgenic plants of the invention.
In addition to plotting pathway step conversion efficiencies vs seed oil content, levels of some key fatty acids have been plotted agains seed oil content (Figure 81 , Figure 82, Figure 83, Figure 84). The data have been fitted in those figures by using all datapoints of all depicted events to determine the slope of the regression, and by subsequently using all datapoints for single events to determine the intercept of the regression line with the x-axis (0% oil content) of the regressions shown in (Figure 81 , Figure 82, Figure 83, Figure 84). The results of this analysis are shown in Table 158.
Table 158: Regression equations of fitting the data in Figure 81 , Figure 82, Figure 83, Figure 84 as described in example 20. Listed are the parameters for the equation (Fatty acid) = (seed oil content) * Slope + Intercept.

Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast
Expression of desaturases and elongases was accomplished in Saccharomyces cerevisiae. Briefly, yeast strains containing the appropriate plasmid were grown overnight at 30 °C (in SD- medium-uracil + raffinose) and then used to inoculate a larger culture at a starting OD6oo = 0.2 (in SD-medium-uracil+raffinose+galactose). After 24 hours at 30 °C the culture (typically Οϋβοο = 0.6- 0.8) was harvested by centrifugation and washed once in 25 mM Tris Buffer (pH 7.6). Preparation of crude extracts and microsomes from yeast expressing genes encoding desaturases and elongases was accomplished using standard procedures. Briefly, cells expressing desaturases were resuspended in 2 ml Desaturase Disruption Buffer (0.1 M potassium phosphate pH 7.2, 0.33 M sucrose, 4 mM NADH, 1 mg/ml BSA (fatty acid free), 4000 U/ml catalase and protease inhibitors (Complete EDTA-free (Roche)) and disrupted using silica/zirconium beads in a BeadBeater. The crude extract was clarified by centrifugation twice at 8,000xg, 4 °C). After an additional centrifugation at 100,000xg (30 minutes at 4 °C) the microsomes were pelleted and ultimately resuspended in Desaturase Disruption Buffer (300 microliters). Protein concentrations in both the crude extract and microsomes were measured using the bicinchoninic acid (BCA) procedure (Smith, P. K., et al (1985) Anal. Biochem. (150): 76-85).
General Desaturase Activity Assays:
In the desaturase assay a [14C]-labeled acyl-CoA was provided as a substrate and after the reaction the acyl-CoAs (and phospholipids) were hydrolyzed and methylated to fatty acid methyl esters (FAMEs), which were analyzed using argentation-TLC. The general assay conditions were modified from Banas et al. (Banas et al. (1997) Physiology, Biochemistry and Molecular Biology of Plant Lipids (Williams, J. P., Khan, M.U. and Lem, N.W. eds.) pp. 57-59).
The assay contained: 1 mg enzyme (crude extract) or 150 micro-g (microsomal fraction), 10 nmol [14C]-acyl-CoA (3000 dpm/nmol), 7.2 mM NADH (total), 0.36 mg BSA (total) in a buffer comprised of 0.1 M K-phosphate pH 7.2, 0.33 M sucrose, 4 mM NADH, 1 mg/ml BSA and protease inhibitors in a total volume of 200 micro-l. After incubation at 30 °C for the desired time, 200 micro-l of 2 M KOH in MeOH:H20 (1 :4) was added and incubated for 20 minutes at 90 °C. Fatty acids were extracted by addition of 3 M HCI (200 micro-l), 1 .5 ml of MeOH:CHCI3 (2:1 ) and CHCI3 (500 micro- I). The chloroform phase was recovered, dried under N2(g) and fatty acids were methylated by addition of 2 ml MeOH containing 2% H2SO4 and incubation of 30 minutes at 90 °C. FAMEs were extracted by addition of 2 ml H2O and 2 ml hexane and separated by AgNC -TLC and Heptane:Diethyl ethenAcetic Acid (70:30:1 ) as a solvent. The radioactive lipids were visualized and quantified by electronic autoradiography using Instant Imager.
Delta-12 desaturase (Phytophthora sojae), c-d12Des(Ps_GA) Enzyme Activity: Enzyme assays were performed using re-suspended microsomes isolated from a yeast strain expressing the c- d12Des(Ps_GA) protein and compared to microsomes isolated from a control yeast strain containing an empty vector (LJB2126). In the presence of [14C]18:1 n-9-CoA, 16:0- lysphosphatidylcholine (LPC), and NADH membranes containing c-d12Des(Ps_GA) form an [14C]18:2-fatty acid that can be isolated as a methyl ester and resolves on AgNO-3-TLC [heptane:diethyl ether (90:10)] similar to known synthetic standards. This enzyme activity requires NADH and was not observed in membranes isolated from the empty vector control strain. Control assays without 16:0-LPC contain a small-amount of activity, presumably due to endogenous 16:0- LPC found in yeast microsomes. Furthermore, separation of the phospholipids from the free-fatty acids after the enzymatic reaction and characterization of the isolabled fatty acid methyl esters demonstrated that all of the c-d12Des(Ps_GA) enzymatically produced 18:2n-6-fatty acid methyl ester (FAME) was found in the phosphatidylcholine fraction.
c-d12Des(Ps_GA) enzyme activity may also be demonstrated using other [14C]acyl-CoA's which may include, but are not limited to: [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [ C]22:5n-3-CoA.
Delta-6 desaturase (Ostreococcus tauri), c-d6Des(Ot_febit) Enzyme Activity: c-d6Des(Ot_febit) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d6Des(Ot_febit) protein using an [14C]acyl-CoA in the general assay described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9-CoA, [14C]18:2n-6-CoA, [ C]20:3n-6-CoA, [ C]20:4n-6-CoA, [ C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using AgNO-3-TLC and Heptane:Diethyl ethenAcetic Acid (70:30:1 ) as a solvent. Furthermore, the c-d6Des(Ot_febit) enzyme can be shown to directly desaturate an acyl-CoA substrate, as described in "Desaturase
Headgroup (CoA vs PC) Preference", as suggested in previous reports (Domergue et al. (2005) Biochem. J. 389: 483-490).
Delta-5 desaturase { Thraustochytrium ssp.), c-d5Des(Tc_GA2) Enzyme Activity: c- d5Des(Tc_GA2) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d5Des(Tc_GA2) protein using an [14C]acyl-CoA general assay as described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n- 9-CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-18) and acetonitrile (100%) as a solvent.
Omega-3 desaturase {Phytophthora infestans), c-o3Des(Pi_GA2) Enzyme Activity: c- o3Des(Pi_GA2) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-o3Des(Pi_GA2) protein using [14C]acyl-CoA in the general assay described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9- CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-18) and acetonitrile (100%) as a solvent. Omega-3 desaturase {Pythium irregulare), c-o3Des(Pir_GA) Enzyme Activity: c-o3Des(Pir_GA) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-o3Des(Pir_GA) protein using an [14C]acyl-CoA in the general assay described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9-CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-18) and acetonitrile (100%) as a solvent.
Delta-4 desaturase { Thraustochytrium ssp.), c-d4Des(Tc_GA) Enzyme Activity: c-d4Des(Tc_GA) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d4Des(Tc_GA) protein using an [14C]acyl-CoA in the general assay described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9-CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-18) and acetonitrile (100%) as a solvent.
Delta-4 desaturase {Paylova lutherl), c-d4Des(PI_GA)2 Enzyme Activity: c-d4Des(PI_GA)2 enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d4Des(PI_GA)2 protein using an [14C]acyl-CoA in the general assay described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9-CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-.18) and acetonitrile (100%) as a solvent.
Delta-4 desaturase {Euglena gracilis), c-d4Des(Eg) Enzyme Activity: c-d4Des(Eg) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d4Des(Eg) protein using an [14C]acyl-CoA in the general assay described above.
[14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9-CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [ C]20:4n-6-CoA, [ C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-18) and acetonitrile (100%) as a solvent.
Desaturase Activity in Microsomes isolated from Transgenic Brassica napus.
Microsomes containing recombinant desaturases and elongases capable of synthesizing docosahexaenoic acid (22:6n-3) were isolated from immature seeds from transgenic B. napus using a procedure adopted from Bafor, M. et al. Biochem J. (1991 ) 280, 507-514. Briefly, immature seeds were first seperated from canola pods and then the developing embryos were isolated from the seed coat and transferred to ice-cold 0.1 M Phosphate buffer (pH 7.2). The developing embryos were then washed with fresh Phosphate buffer, transferred to an ice-cold mortar, and ground to a homogenous solution in Extraction Buffer (0.1 M Phosphate, pH 7.2, 0.33 M sucrose, 1 mg/ml BSA (essentially fatty acid free), 4000U/ml catalase, 4 mM NADH and protease inhibitor-Complete EDTA-free (Roche)). The lysed developing embryo's were diluted 20-fold with additional Extraction Buffer and passed through 2 layers of Miracloth into a centrifuge tube. Following centrifugation at 18,000 x g for 10 minutes at 4 °C, the clarified supernatant was passed through Miracloth into an ultracentrifuge tube. Following centrifugation at 105, 000 xg for 60 minutes at 4 °C, the supernatant was removed from the microsomal pellet, which was then washed once with Extraction Buffer, and then using a Dounce homogenizer resuspended as a homogenous solution in Extraction Buffer (about 1 ml per 500 embryo's).
Enzyme activity can be demonstrated for the desaturases using the assays described above in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast" for microsomes isolated from yeast expression strains.
In summary in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeasfwe have provided a method that allows unambiguous demonstration of fatty acyl desaturase enzyme activity. We provide data demonstrating that: (1 ) gene c-d12Des(Ps_GA) encodes a delta-12 desaturase protein from Phytophthora sojae (c-d12Des(Ps_GA) that desaturates oleic acid (18:1 n-9) to form linoleic acid (18:2n-6) in both microsomes isolated from a transgenic yeast (Figure 24, panel A) and from a transgenic B. napus event (Figure 25, panel A) expressing this protein, (2) gene c-o3Des(Pi_GA2) encodes a protein from Phytophthora infestans (c- o3Des(Pi_GA2)) that desaturates arachidonic acid (20:4n-6) to form eicosapentaenoic acid (20:5n-3) in microsomes isolated from a transgenic yeast (Figure 24, panel B) expressing this protein, (3) gene c-o3Des(Pir_GA) encodes an omega-3 desaturase protein from Pythium irregulare (c-o3Des(Pir_GA)) that desaturates arachidonic acid (20:4n-6) to form eicosapentaenoic acid (20:5n-3) in microsomes isolated from a transgenic yeast (Figure 24, panel B) expressing this protein, (4) a transgenic B. napus event containing genes encoding omega-3
desaturase proteins from both Phytophthora infestans (c-o3Des(Pi_GA2)) and Pythium irreguiare (c-o3Des(Pir_GA)) that contains at least one enzyme, localized to the microsomes, capable of desaturating arachidonic acid (20:4n-6) to form eicosapentaenoic acid (20:5n-3) (Figure 85, Panel C), (5) gene c-d4Des(Tc_GA) encodes a delta-4 desaturase protein from Thraustochytrium sp. (c-d4Des(Tc_GA)) that desaturates docosapentaenoic acid (22:5n-3) to form docosahexaenoic acid (22:6n-3) in microsomes isolated from a transgenic yeast (Figure 24, panel C) expressing this protein, (6) gene c-d4Des(PI_GA)2 encodes a delta-4 desaturase protein from Pavlova lutheri (c-d4Des(PI_GA)2 that desaturates docosapentaenoic acid (22:5n-3) to form docosahexaenoic acid (22:6n-3) in microsomes isolated from a transgenic yeast (Figure 24, panel D), (7) a transgenic B. napus even\ containing both the gene encoding the delta-4 desaturase protein from Thraustochytrium sp, gene c-d4Des(Tc_GA), and the gene c-d4-Des(PI_GA) from Pavlova Luthen contains at least one enzyme, localized to the microsomes, capable of desaturating docosapentaenoic acid (22:5n-3) to form docosahexaenoic acid (22:6n-3) (Figure 25, panel C), (8) a transgenic B. napus event containing the gene encoding a delta-6 desaturase protein from Ostreococcus tauri (c-d6Des(Ot_febit), capable of desaturating linoleic acid (18:2n-6) to form gamma-linolenic acid (18:3n-6) (Figure 85, Panel A), and (9) a transgenic B. napus event containing the gene encoding a delta-5 desaturase protein from Thraustachytrium ssp. (c- d5Des(Tc_GA2), capable of desaturating dihomo-gamma-linolenic acid (20:3n-6) to form arachidonic acid (20:4n-6) (Figure 85, Panel B). Except for the c-d12Des(Ps_GA), which has a known endogenous enzyme in Brassica, all other examples presented contain no detectable endogenous desaturase activity in microsomes isolated from either control yeast strains (Figure 24) or control Brassica lines (Figure 25 and Figure 85).
Using the methods described in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast" for desaturase proteins the level of expression or detected enzyme activity may be influenced by the presence or absence of fusion tags to the native protein. Fusion tags or proteins to the desaturases may be attached the amino-terminus (N-terminal fusions) or the carboxy-terminus (C-terminal fusions) of the protein and may include but are not limited to: FLAG, hexa-Histidine, Maltose Binding Protein, and Chitin Binding Protein.
We have provided methods to establish enzyme catalyzed desaturation reactions required in an engineered pathway to biosynthesize docosohexaenoic acid (DHA, 22:6n-3) from oleic acid (18:1 n-9) in canola. The methods presented in Example 21 , "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast" were developed to demonstrate desaturase activity in yeast strains expressing individual desaturases and can be further used to confirm the respective desaturase enzyme activities in transgenic canola, as described and demonstrated in Example 21 , "Desaturase Activity in Microsomes Isolated from Transgenic Brassica napus". Furthermore these methods can be incorporated, by one skilled in the art, to measure desaturase enzyme activities in other organisms including, but not limited to: Saccharomyces cerevisiae, Arabidopsis thaliana, Brassica spp., Camelina sativa, Carthamus tinctorius, and Salvia hispanica.
Desaturase Headgroup (CoA vs PC) Preference
Fatty acid desaturases catalyze the abstraction of two hydrogen atoms from the hydrocarbon chain of a fatty acid to form a double bond in an unsaturated fatty acid and can be classified according to the backbone that their substrate was connected to: an acyl-CoA, an acyl-ACP (ACP, acyl carrier protein) or an acyl-lipid. To date a few examples exist where the acyl-CoA substrate has been confirmed. These involve purified enzymes and examples include a Linoleoyl- CoA Desaturase (Okayasu et al. (1981 ) Arch. Biochem. Biophys. 206: 21 -28), a stearoyl-CoA desaturase from rat liver (Strittmatter et al (1974) Proc. Nat. Acad. Sci. USA 71 : 4565-4569), and a Stearoyl-ACP desaturase from avocado (Shanklin J and Somerville C (1991 ) Proc Natl Acad Sci USA 88:2510-2514).
Alternatively, Heinz and coworkers have reported a strategy employing in vivo feeding of substrates to yeast strains expressing desaturases to examine substrate specificity of desaturases (Domergue et al. (2003) J. Biol. Chem. 278: 351 15-35126 , Domergue et al. (2005) Biochem. J. 389: 483-490). In these studies predictions of a desaturases's preference for acyl- lipid substrates were based on data obtained from a thorough analysis of the desaturated products in the CoA, phospholipid and neutral lipid pools over a growth time course. However, highly active endogenous acyltransferases which transfer acyl-groups between various pools (e.g. CoA, ACP, and lipid) may influence or convolute these data (Domergue et al. (2005) Biochem. J. 389: 483-490, Meesapyodsuk, D., Qui, X. (2012) Lipids 47: 227-237). Therefore this approach was still limited by the absence of direct evidence, such as obtained from in vitro assays, needed for conclusive determination of the substrate backbone utilized by the desaturase of interest. Herein, we provide a previously unreported method to distinguish between enzymes that desaturate acyl-CoA fatty acids from enzymes that desaturate phospholipid linked fatty acids using microsomal preparations of proteins. We have improved upon initial reports of strategies to generate [14C]-phosphatidylcholine analogs in situ (Stymne, S., and Stobart, A. K. (1986) Biochem. J. 240: 385-393, Griffiths, G., Stobart, A. K., and Stymne, S. (1988) Biochem. J. 252: 641 -647) by: (1 ) monitoring the initial acyl-transfer reaction catalyzed by lysophosphatidyl choline acyl transferase (LPCAT) to establish that all of the [14C]-acyl-CoA has been consumed, and (2) including exogenous lysophosphatidyl choline (LPC). Our improvements therefore establish that only [14C]-phosphatidylcholine analogs are present upon initiation of the desaturase assay and allow for testing of other phospholipids by adding their corresponding lysolipid. Furthermore, the assays testing for desaturation of acyl-phospholipid substrates, described in Demonstration of Phosphatidylcholine Specificity, can be complemented by testing in an assay developed to monitor desaturation of the substrate in the acyl-CoA form. Specifically, we have devised a strategy, described in Demonstration of acyl-CoA Specificity, in which the substrate to be tested remains in its acyl-CoA form and is not incorporated into phospholipids (e.g. phosphatidylcholine) by lysophosphatidyl choline acyl transferase (LPCAT). By comparing the relative desaturase activity, observed in assays where the substrate is in the acyl-phospholipid form compared to the acyl-CoA form, the actual backbone (e.g. phosphatidylcholine or CoA) covalently bound to the desaturated fatty acid product can be determined.
Demonstration of Phosphatidylcholine Specificity:
To test if a desaturase accepts an acyl-lipid (e.g. a phospholipid) substrate the enzyme reaction was performed as described above " "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast", but after a pre-incubation in the presence of exogenous lysophosphatidyl choline (LPC). The microsomal fraction of the yeast strain expressing the enzyme of interest was pre-incubated with a [14C]-labelled acyl-CoA substrate in the presence of 16:0-lysophosphatidyl choline, which was typically 50 micro-M but may vary from 0 - 500 micro-M. During the preincubation endogenous lysophosphatidyl choline acyl transferase (LPCAT), present in the microsomes, transfers the [14C]fatty acid from CoA to 16:0-LPC generating, in situ, a [14C]fatty acid-phosphatidylcholine (PC) (Jain et al. (2007) J. Biol. Chem. 282:30562-30569, Riekhof et al. (2007) J. Biol. Chem. 282:36853-36861 , Tamaki et al. (2007) J. Biol. Chem. 282:34288-34298)). After a pre-incubation (typically 15 minutes, but may vary from 1 - 300 minutes) essentially all of the [14C]-labelled acyl-CoA substrate was consumed, as measured by scintillation counting and TLC analysis of the aqueous phase.
The reaction was stopped and lipids were extracted using the method of Bligh and Dyer (Bligh, E. G., and Dyer, J. J. (1959) Can J. Biochem. Physiol. 37: 91 1 -918), by addition of 200 micro-l 0.15 M acetic acid and 1 ml MeOH:CHCI3 (1 :1 ). Part (about 10%) of the CHCI3 phase (containing phosphatidyl choline (PC) and free fatty acids (FFA's)) was analyzed by scintillation counting and the rest was applied to a silica thin layer chromatography (TLC) plate. The plate was first developed in a polar solvent [CHCl3:MeOH:acetic acid (90:15:10:3) and then in Heptane:diethylether:acetic acid (70:30:1 ) to measure incorporation into PC and the amount of FFA's (likely generated by thioesterases). PC and FFA's were scraped off the plate and methylated by addition of MeOH containing 2% H2SO4 at 90 °C for 30 minutes. The methyl esters were extracted in hexane and analyzed as described above for the respective enzymes (Example 21 , "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast"). The upper (aqueous) phase of the reaction mixture extraction contains acyl-CoA's and was hydrolyzed by addition of an equal volume of 2 M KOH in MeOH:H20 (1 :4) and incubated for 20 minutes at 90 °C. Part of the aqueous phase was then analyzed by scintillation counting before fatty acids were extracted by addition of 3 M HCI (0.7 ml), 1.4 ml of MeOH) and CHCI3 (1.9 ml). The chloroform phase was recovered, dried under N2(g) and fatty acids were methylated by addition of 2 ml MeOH containing 2% H2SO4 and incubation of 30 minutes at 90 °C. FAMEs were extracted by addition of 2 ml H2O and 2 ml hexane and separated by AgN03-TLC and Heptane:Diethyl ether:acetic acid (70:30:1 ) as a solvent or Reverse Phase-TLC (Silica gel 60 RP-18 using acetonitrile (100%)). The radioactive lipids were visualized and quantified by electronic autoradiography using Instant Imager.
Delta-12 desaturase {Phytophthora sojae), c-d12Des(Ps_GA) Substrate Preference: The c- d12Des(Ps_GA) enzyme activity demonstrated in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeasfcan be further characterized to establish the backbone of the oleic acid substrate. In the desaturase assay described in "Desaturase Headgroup (CoA vs PC) Preference" containing 16:0-lysphosphatidylcholine (LPC) substantial desaturation was observed. A significantly reduced, but detectable, desaturase activity was observed in control
reactions lacking 16:0-LPC which likely results from acylation of endogenous LPC present in the yeast microsomes containing the d12Des(Ps_GA) protein. However, a preincubation with 20:1 n- 9-CoA results in PC saturated with 20:1 n-9, thus precluding incorporation of [14C]-18:1 n-9 into PC (described in "Demonstration of Acyl-CoA Specificity"). Additionally, separation of the phospholipids from the free-fatty acids after the enzymatic reaction and characterization of the isolable fatty acid methyl esters demonstrated that all of the d12Des(Ps_GA) enzymatically produced 18:2n-6-fatty acid methyl ester (FAME) was found in the phosphatidylcholine fraction (Figure 26, Panel A and Figure 86, Panel A). Furthermore, the d12Des(Ps_GA) activity was negligible in the assay for demonstration of acyl-CoA specificity (Figure 86, Panel B), showing that 18:1 n-9-acyl-CoA is not a preferred substrate for the delta-12 desaturase (Phytophthora sojae). In conclusion, delta-12 desaturase {Phytophthora sojae) clearly desaturates 18:1 n-9 covalently bound to PC, but not an 18:1 n-9-acyl CoA substrate.
Delta-4 desaturase { Thraustochytrium ssp.), c-d4Des(Tc_GA) Substrate Preference: The c- d4Des(Tc_GA) enzyme activity demonstrated in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeasfcan be further characterized to establish the backbone of the docosopentaenoic acid substrate. In the desaturase assay described in "Desaturase Headgroup (CoA vs PC) Preference" without additional 16:0-lysphosphatidylcholine (LPC), desaturation was observed (Figure 26, Panel B), and likely results from the presence of endogenous 16:0-LPC present in the membranes containing the c-d4Des(Tc_GA) protein. The c-d4Des(Tc_GA) desaturase activity was dramatically stimulated by including additional 16:0-LPC in the assay (Figure 26, Panel B), consistent with the observation endogenous lysophosphatidyl choline acyl transferase (LPCAT), present in the microsomes, transfers the [14C]22:5n-3 from CoA to 16:0- LPC generating a [14C]22:5n-3-phosphatidylcholine (PC) that was desaturated. Additionally, separation of the phospholipids from the free-fatty acids after the enzymatic reaction and characterization of the isolable fatty acid methyl esters demonstrated that essentially all of the c- d4Des(Tc_GA) enzymatically produced 22:6n-3-fatty acid methyl ester (FAME) was found in the phosphatidylcholine fraction (Figure 26, Panel B and Panel C). Demonstration of Acyl-CoA Specificity:
The assay conditions were as described above in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast". The microsomal fraction of the yeast strain expressing the enzyme of interest was pre-incubated with 10 nmol 20:1 n-9-CoA (50 μΜ) and 0.5 mM DTNB (5,5'- dithiobis-(2-nitrobenzoic acid) for 10 min before addition of NADH and [14C]labelled acyl-CoA substrate. The preincubation with 20:1 n-9-CoA minimizes the incorporation of [14C]labelled substrate into PC. DTNB prevents the reverse reaction of LPCAT and thereby the entering of acyl-CoA into PC via acyl exchange. This assay may also include alternative acyl-CoA's such as: 18:1 n-9-CoA, 18:2n-6-CoA, 20:3n-6-CoA, 20:4n-6-CoA, 22:5n-3-CoA. The reaction was stopped and lipids were extracted using the method of Bligh and Dyer (Bligh, E. G., and Dyer, J. J. (1959) Can J. Biochem. Physiol. 37, 91 1-918), by addition of 200 micro-l 0.15 M acetic acid and 1 ml MeOH:CHCI3 (1 :1 ). Part (about 10%) of the CHCI3 phase (containing phosphatidyl choline (PC) and free fatty acids (FFA's)) was analyzed by scintillation counting and the rest was applied to a silica thin layer chromatography (TLC) plate. The plate was first developed in a polar solvent
[CHCI3:MeOH:acetic acid (90:15:10:3) and then in Heptane:diethylether:acetic acid (70:30:1 ) to measure incorporation into PC and the amount of FFA's (likely generated by thioesterases). PC and FFA's were scraped off the plate and methylated by addition of MeOH containing 2% H2SO4 at 90 °C for 30 minutes. The methyl esters were extracted in hexane and analyzed as described above for the respective enzymes "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast". The upper (aqueous) phase of the reaction mixture extraction contains acyl- CoA's and was hydrolyzed by addition of an equal volume of 2 M KOH in MeOH:H20 (1 :4) and incubated for 20 minutes at 90 °C. Fatty acids were extracted by addition of 3 M HCI (0.7 ml), 1 .4 ml of MeOHand CHCI3 (1 .9 ml). The chloroform phase was recovered, dried under N2(g) and fatty acids were methylated by addition of 2 ml MeOH containing 2% H2SO4 and incubation of 30 minutes at 90 °C. FAMEs were extracted by addition of 2 ml H20 and 2 ml hexane and separated by AgNC>3-TLC and Heptane:Diethyl ether:acetic acid (70:30:1 ) as a solvent or Reverse Phase- TLC (Silica gel 60 RP-18 using acetonitrile (100%)). The radioactive lipids were visualized and quantified by electronic autoradiography using Instant Imager.
To demonstrate acyl-CoA dependency both methods are tested. If desaturation does not occur in the method for determining PC-specificity (LPC addition and preincubation before adding NADH) and the method for determining acyl-CoA specificity (20:1 -CoA and DTNB addition) leads to the desaturated product in the FbO-phase (or product in any of the lipid pools PC/FFA/H2O since PC-dependent enzymes cannot be active if the substrate is not incorporated into PC (see Figure 86, Panel B), it can be concluded that the enzyme was acyl-CoA dependent (see Figure 27 and Figure 87, Panels A and B). Similarly if a desaturase demonstrates activity in the PC- specific assay, but not in the assay where the substrate is presented as an acyl-CoA, then it can be concluded the enzyme utilizes a fatty acid covalently attached to phosphatidylcholine as a substrate.
Delta-9 desaturase {Saccharomyces cerevisiae), d9Des(Sc) Substrate Preference:
Analysis of the [14C]-distribution during of the d9Des(Sc) reaction, in the assay for demonstration of acyl-CoA dependency, shows that greater than 95% of the radioactivity (substrate and product) is present in the H2O (CoA) and FFA-pools (data not shown), indicating incorporation into PC was insignificant. During the reaction, product (16:1 n-9) in the acyl-CoA pool increases linearly up to 60 minutes, showing that the enzyme preferentially converts 16:0 covalently bound to CoA (Figure 87, Panel B). The amount of 16:1 n-9 in the H2O fraction then levels out or slightly decreases, while the 16:1 n-9 in the FFA pool increases, due to degradation of acyl-CoA by thioesterases present in the isolated membranes.
In the assay for demonstrating PC specificity, the d9Des(Sc) showed no activity (Figure 87, Panel A), which indicates that when16:0 fatty acid is attached to PC (or a FFA) it is not a preferred substrate. The clear presence of desaturase activity in the "Acyl-CoA Specific" assay compared to the absence of activity in the "Phosphatidylcholine Specific" assay demonstrates that the delta-9 desaturase {Saccharomyces cerevisiae) utilizes 16:0 covalently attached to Coenzyme A. Interestingly, recent crystal structures of both the human and mouse stearoyl-coenzyme A
desaturases have been reported with bound stearoyl-CoA confirming that this desaturase utilizes a coenzyme A substrate (Wang et al (2015) Nat Struct Mol Bio 22: 581 -585 and Bai et al (2015) Nature 524: 252-257). In summary, we presented a previously unreported method to distinguish between enzymes that desaturate acyl-CoA fatty acids from enzymes that desaturate phospholipid linked fatty acids. This embodment of the invention t uses microsomal preparations of enzymes and does not, as in previous examples, require purification of the enzyme of interest. Furthermore, this embodiment allows isolation of the intact desaturated enzymatic product, allowing characterization of the backbone to which it was linked (e.g. lipid-, CoA-, or free fatty acid). An important consideration was that the endogenous lysophosphatidyl choline acyl transferase (LPCAT) present in yeast- derived microsomes can utilize a broad range of acyl-CoA's (Jain et al. (2007) J. Biol. Chem. 282:30562-30569, Riekhof et al. (2007) J. Biol. Chem. 282:36853-36861 , Tamaki et al. (2007) J. Biol. Chem. 282:34288-34298)) making it suitable for generating an extensive variety of different phosphatidylcholine derivatives for assaying desaturase enzymes. LPCAT is able to accept 18:1 n-9-CoA and 20:4n-6-CoA and this enzyme can acylate LPC with 22:5n-3-CoA.. Microsomes isolated from any cells or tissue can be used in this embodiment of the invention, including but not limited to bacterial cells (e.g. Escherichia coil, Psuedomonas aeruginosa, Bacillus thuringiensis), mammalian tissue (e.g. liver) and plant tissue (e.g. leafs, roots, seeds, and pods) and could use exogenously supplied lysophosphatidyl choline acyl transferase from Saccharomyces cerevisiae, if necessary. Slight modifications to the general method presented here may include a pre-incubation with alternate acyl-CoA's, not the potential desaturase substrate, which could reduce the observed background due to endogenous LPC present in the membranes and also minimize thioesterase degradation of enzyme substrate or product acyl- CoA's.
Elongase Activity.
Expression of elongase enzymes in yeast was performed as described above for the desaturase enzymes in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast". Isolation of microsomes containing expressed elongases was generally as described above in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast" and by Denic (Denic, V. and Weissman (2007) Cell 130, 663-677). Briefly, cells from a yeast expression culture (50 ml) were resuspended in 1 ml of Elongase Disruption Buffer (20 mM Tris-HCI, pH 7.9, 10 mM MgC , 1 mM EDTA, 5% glycerol, 0.3 M ammonium sulfate, protease inhibitor), mixed with 1 ml silica/zirconium beads (0.5mm) and disrupted in a BeadBeater. After centrifugation (two times for 5 minutes at 8000xg, 4 °C) the crude extract was recovered and after a second centrifugation (100,000xg, 2 hours at 4 °C), the microsomal fraction was resuspended in 500 micro-l of assay buffer (50 mM HEPES-KOH pH 6.8, 150 mM KOAc, 2 mM MgOAc, 1 mM CaCI2, protease inhibitor). The protein concentrations in the microsomes were measured according to the BCA method. Resuspended microsomes were aliquoted and frozen in N2 ) and stored at -80 °C.
In the elongase assay [14C]-labeled malonyl-CoA and non-labeled acyl-CoA were provided as substrates. After the reaction has proceeded an appropriate time, which may vary between 0 - 300 minutes depending on the purpose of the experiment, the reaction mixture was subjected to hydrolysis and methylation and the FAMEs were analyzed by RP-TLC combined with by electronic autoradiography using Instant Imager.
The assay contains about 170 micro-g microsomal protein, 7.5 nmol [14C]malonyl-CoA (3000 dpm/nmol), 5 nmol acyl-CoA in a total volume of 100 micro-l. After incubation for the desired time at 30 °C, the reaction was stopped with the addition of 100 micro-l of 2 M KOH in MeOH (1 :4) followed by a 20 minute incubation at 90 °C. Fatty acids were extracted by addition of 3 M HCI (100 micro-l), 0.75 ml of MeOH:CHCI3 (2:1 ) and CHCI3 (250 micro-l). The chloroform phase was recovered, dried under N2(g), and fatty acids were methylated by addition of 2 ml MeOH containing 2% H2SO4 and incubation of 30 minutes at 90 °C. FAMEs were extracted by addition of 2 ml H2O and 2 ml hexane and separated by Reverse Phase-TLC (Silica gel 60 RP-18) using a solvent of acetonitrile:tetrahydrofuran (85:15). The radioactive lipids were visualized and quantified by electronic autoradiography using Instant Imager.
Furthermore, assays may include additional components (e.g. 1 mM NADPH, 2 mM MgC , and 100 micro-M cerulenin) to complete the fatty acid reduction cycle by endogenous yeast enzymes, but limit further elongation of the acyl- CoA.
Delta-6 Elongase ( Thalassiosira pseudonana), c-d6Elo(Tp_GA2) Enzyme Activity: c- d6Elo(Tp_GA2) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d6Elo(Tp_GA2) protein using [14C]malonyl-CoA and an acyl-CoA in the general elongase assay described above. Acyl-CoA's may include, but are not limited to: 18:1 n-9-CoA, 18:2n-6-CoA, 18:3n-6-CoA, 20:3n-6-CoA, 20:4n-6-CoA, 20:5n-3-CoA, 22:5n-3-CoA.
Delta-6 Elongase {Physcomitrella patens), c-d6Elo(Pp_GA2) Enzyme Activity: c-d6Elo(Pp_GA2) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d6Elo(Tp_GA2) protein using [14C]malonyl-CoA and an acyl-CoA in the general elongase assay described above. Acyl-CoA's may include, but are not limited to: 18:1 n-9-CoA, 18:2n-6-CoA, 18:3n-6-CoA, 20:3n-6-CoA, 20:4n-6-CoA, 20:5n-3-CoA, 22:5n-3- CoA.
Delta-5 Elongase (Ostreococcus taun), c-d5Elo(Ot_GA3) Enzyme Activity: c-d5Elo(Ot_GA3) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d5Elo(Ot_GA3) protein using [14C]malonyl-CoA and an acyl-CoA in the general elongase assay described above. Acyl-CoA's may include, but are not limited to: 18:1 n-9-CoA, 18:2n-6-CoA, 18:3n-6-CoA, 20:3n-6-CoA, 20:4n-6-CoA, 20:5n-3-CoA, 22:5n-3- CoA.
In the presence of NADPH and [14C]malonyl-CoA, 18:3n-6-CoA was elongated to 20:3 n-6-CoA by the delta-6 Elongases isolated from Thalassiosira pseudonana (Tp) and Physcomitrella patens (Pp) as shown if Figure 28, panels A and B. In both delta-6 elongase reactions the observed FAME-product co-migrates with 20:3n-6-methyl ester standards and was radioactive, consistent with transfer of two-carbons from [14C]-malonyl-CoA to 18:3n-6-CoA. In the presence of NADPH the fatty acid reduction cycle was completed resulting in a saturated enzymatic product. However in the absence of NADPH a derivative of the direct enzymatic product, 3-keto-20:3n-6-CoA, was isolated as a FAME. The isolated enzymatic product was decarboxylated and converted to the 2- keto-19:3n-6-FAME as described previously (Bernert, J.T and Sprecher, H. (1977) J. Biol. Chem. 252:6736-6744 and Paul et al (2006) J. Biol. Chem. 281 : 9018-9029). Appropriate controls demonstrate that this elongation reaction was dependent upon either the Delta-6 Elo (Tp) or the Delta-6 Elo (Pp) and not catalyzed by endogenous yeast enzymes.
In the presence of NADPH and [14C]malonyl-CoA , 20:5n-3-CoA was elongated to 22:5 n-3-CoA by the c-d5Elo(Ot_GA3), and containing either an N-terminal FLAG tag or a C-terminal FLAG tag, as shown in Figure 28, panel C. In the Delta-5 elongase reaction the observed FAME-product co- migrates with a 22:5n-3-methyl ester standard and was radioactive, consistent with transfer of two-carbons from [14C]-malonyl CoA to 20:5n-3-CoA. In the presence of NADPH the fatty acid reduction cycle was completed resulting in a saturated enzymatic product. However in the absence of NADPH a derivative of the direct 3-keto-22:5n-3-CoA product was isolated as a FAME. The isolated enzymatic product was decarboxylated and a 2-keto-21 :5n-3-FAME as described previously (Bernert, J.T and Sprecher, H. (1977) J. Biol. Chem. 252:6736-6744 and Paul et al (2006) J. Biol. Chem. 281 : 9018-9029). Appropriate controls demonstrate that this elongation reaction was dependent upon the Delta-5 Elo (Ot) and not catalyzed by endogenous yeast enzymes.
Herein, using a highly sensitive elongase assay, we have demonstrated the enzyme activities of the Delta-6 Elongases used (Figure 28, panel A and B) and a Delta-5 Elongase (Figure 28, panel C), enzymes that are central to engineering canola to biosynthesize docosahexaenoic acid. For each of these elongases we have shown that in the presence of [14C]malonyl-CoA and the appropriate fatty-acyl CoA ester substrate these enzymes can transfer two-carbons (containing [14C]) from malonyl-CoA to the appropriate fatty-acyl-CoA ester to synthesize a new fatty acid which has been elongated by two carbons. In some cases a derivative (decarboxylated 2-keto compound) of the direct enzymatic product (3-Keto-acylCoA ester) of the elongase was observed, however in the absence of NADPH only this decarboxylated 2-keto compound was observed, consistent with previous observations by Napier (Bernert, J.T and Sprecher, H. (1977) J. Biol. Chem. 252:6736-6744 and Paul et al (2006) J. Biol. Chem. 281 : 9018-9029).
In summary we have provided a method that allows unequivocal demonstration of fatty acyl elongation enzyme activity. We provide data demonstrating that: (1 ) gene c-d6Elo(Tp_GA2) encodes a delta-6 elongase protein from Thalassiosira pseudonana (c-d6Elo(Tp_GA2)) that converts 18:3n-6-CoA to 20:3n-6-CoA in microsomes isolated from a transgenic yeast (Figure 28, panel A), (2) gene c-d6Elo(Pp_GA2) encodes a delta-6 elongase protein from Physcomitrella
patens (c-d6Elo(Pp_GA2)) that converts 18:3n-6-CoA to 20:3n-6-CoA in microsomes isolated from a transgenic yeast (Figure 28, panel B), (3) a transgenic B. napus event containing both the gene encoding for the delta-6 elongase protein from Thalassiosira pseudonana, gene c- d6Elo(Tp_GA2), and the gene encoding for the gene the delta-6 elongase protein from Physcomitrella patens, gene c-d6Elo(Pp_GA2), contains at least one enzyme, localized to the microsomes, capable of elongating 18:3n-6-CoA to 20:3n-6-CoA (Figure 28, panel A) (4) gene c- d5-Elo(Ot_GA3) encodes a delta-5 elongase protein from Ostreococcus taun c-dbE\o{Ot_G>k2>)) that converts 20:5n-3-CoA to 22:5n-3-CoA in microsomes isolated from both a transgenic yeast (Figure 28, Panel C) and transgenic B. napus event (Figure 29, Panel B). In all examples presented no endogenous elongase activity was detected in microsomes isolated from either control yeast strains (Figure 28) or control Brassica lines (Figure 29).
Using the methods described in "Elongase Activity" for elongase proteins the level of expression or detected enzyme activity may be influenced by the presence or absence of fusion tags to the native protein. Fusion tags or proteins to the desaturases may be attached the amino-terminus (N-terminal fusions) or the carboxy-terminus (C-terminal fusions) of the protein and may include but are not limited to: FLAG, hexa-Histidine, Maltose Binding Protein, and Chitin Binding Protein.
We have provided methods to establish enzyme catalyzed elongase reactions required in an engineered pathway to biosynthesize docosohexaenoic acid (DHA, 22:6n-3) from oleic acid (18:1 n-9) in canola. The methods presented in Example 21 were developed to demonstrate elongase activity in yeast strains expressing individual elongases and can be further used to confirm the respective elongase enzyme activities in transgenic canola. Furthermore these methods can be incorporated, by one skilled in the art, to establish elongase enzyme activities in other organisms including, but not limited to: Saccharomyces cerevisiae, Arabidopsis thaliana, Brassica spp., Camelina sativa, Carthamus tinctorius, and Salvia hispanica.
Example 22: In vivo demonstration of mode of action: substrate specificity, substrate selectivity
Cloning of Genes into Yeast Expression Vectors:
For single gene expression, the yeast expression vector pYES2.1 A 5-His-TOPO (Invitrogen) was used. Flanking primers were designed according to the manufacturer's instructions, and genes were amplified from plant expression vectors using the proof-reading polymerase Phusion high- fidelity polymerase (New England Biolabs). After agarose gel electrophoresis PCR fragments were cut out and purified using an EZ-10 spin column gel extraction kit (Bio Basic Inc.), cloned into the yeast expression vector pYES2.1 A 5-His-TOPO (Invitrogen), transformed into E. coli, and gene orientation was checked by PCR. For co-expression of multiple genes, genes were cloned into pESC yeast expression vectors (Stratagene) under the control of the GAL1 promoter. To do this, appropriate restriction sites were introduced upstream and downstream of coding regions via PCR, followed by fragment isolation, TA-cloning into the pGEM-T vector, release of the gene fragment by enzyme digestion, and ligation into the pESC vector. For all constructs plasmids were isolated using an EZ-10 spin column plasmid DNA miniprep kit (Bio Basic Inc.). All constructs were sequenced prior to yeast transformation. After sequencing, plasmids were transformed into Saccharomyces cerevisiae (yeast) strain INVSd (Invitrogen), using the Sc EasyComp
Transformation Kit (Invitrogen) according to the manufacturer's protocol, and selected on plates lacking the appropriate amino acids.
Expression of Heterologous Genes in Yeast:
Yeast cultures were grown overnight at 30°C in drop out base (DOB-URA: 1.7 g/L yeast nitrogen base, 5 g ammonium sulfate, and complete supplement mixture minus appropriate amino acids for selection) containing 2 % glucose. The OD600 of the overnight yeast cultures were obtained and culture concentrations were standardized between samples. The samples were washed with DOB-URA containing 2 % galactose and expression was carried out for 3 days at 20 °C in the same media supplemented with exogenous fatty acids and 0.01 % tergitol. For exogenous fatty acid feeding, cells were fed with 0.25 mM of the appropriate fatty acids, except where indicated otherwise. Fatty acid substrates and FAME standards were purchased from Nu-Chek Prep Inc (Elysian, MN). Fatty Acid Analysis by Gas Chromatography:
5 ml. cultures were precipitated by centrifugation and washed once with induction buffer and once with water. The supernatant was removed, and 2 ml. of 3N methanolic-HCI (Supelco) was added to the cell pellet. After gentle mixing, the mixture was incubated at 80°C for 40 min, cooled to room temperature, and 1 ml. 0.9% NaCI plus 2 ml. hexane was added. The sample was vortexed and centrifuged, and the hexane phase was removed and dried under nitrogen gas. Fatty acid methyl esters (FAMEs) were resuspended in 100 μΙ hexane and analyzed by gas chromatography using an Agilent 6890N gas chromatograph equipped with a DB-23 column. The thermal program used was 160 °C for 1 min, then temperature was increased to 240 °C at a rate of 4 °C/min. FAMEs were identified based on known standards and the conversion percent was calculated as: [(Product)x100%]/(Substrate + Product).
Time Course Studies:
Samples were grown overnight at 30°C, sample concentrations were standardized prior to feeding, and cultures were induced at 20°C. For some time course studies, samples were pre- induced overnight prior to feeding as indicated in results. Samples (1 ml of culture) were collected at the indicated time intervals, washed once with 0.5% tergitol and once with double distilled water, and pellets were stored at -80°C until the completion of the time course. Fatty acid extraction and GC analysis basically followed methods described for "Fatty Acid Analysis by Gas Chromatography", however 1 ml. methanolic HCI and 0.5 ml. 0.9% NaCI and 1 ml_ hexane were used for fatty acid extraction, and the final resuspension was performed in 100 μΙ_ hexane.
Feeding Studies with Individual Fatty Acids:
Samples were grown overnight at 30°C, sample concentrations were standardized prior to feeding, and cultures were induced at 20°C for 3 days. Measurements from at least 3 clones were used to calculate averages.
Feeding Studies with Multiple Fatty Acids:
Fatty acids for co-feeding were selected based on results from experiments described above where cells expressing each construct were fed with all possible substrates. The positive
substrates for a given enzyme were fed together, however, if one substrate formed a product that also was a known substrate (for example, with certain elongases), separate mixtures were used. For omega-3-desaturases, two mixtures, each containing SDA as a standard, were used for feeding. Initially, cultures were fed mixtures containing 0.25 mM total fatty acid substrate. However, due to differences in uptake, it was necessary to optimize fatty acid mixtures so that the levels of Substrate A + Product A was equal to Substrate B + Product B within ± 5%. The final fatty acid mixtures used were also subjected to GC to obtain an estimation of relative uptake. After appropriate fatty acid mixtures were obtained, induction and feeding was performed as described above (Expression of Heterologous Genes in Yeast). After induction, yeast cells were induced for 3 days at 20 °C before harvesting of cells and GC analysis as described above (Expression of Heterologous Genes in Yeast and Fatty Acid Analysis by Gas Chromatography). All experiments were replicated three times.
Co-expression Heterologous Genes in Yeast:
Protocols for co-expression of genes basically followed those provided for single gene expression experiments. Cultures were grow overnight at 30°C, sample concentrations were standardized prior to feeding, and cultures were induced at 20°C for 3 days. The following sets of genes were co-expressed (pY = pYES2.1/V5-His-TOPO ; pT= pESC-Typ, pL=pESC-Leu):
1 ) pY-c-d12Des(Ps_GA) /pT-c-d6Des(Pir_GA)
2) pY-c-d12Des(Ps_GA)/pT-c-d6Des(Ot_febit)
3) pY-c-d6Elo(Tp_GA2)/pT-c-d6Des(Ot_febit)
4) pY-c-d6Elo(Tp_GA2)/pT-c-d6Des(Pir_GA)
5) pL- c-d6Elo(Tp_GA2)/pY-c-d5Des(Tc_GA2)
6) pL-c-d8Des(Eg) /pY-c-d5Des(Tc_GA2)
7) pL- c-d6Elo(Tp_GA2)/pY-c-d5Des(Sa)
8) pL-c-d8Des(Eg)/pY-c-d5Des(Sa)
Isolation and Analysis of Lipids:
For expression of desaturases or elongases, yeast cultures were grown overnight at 30°C in drop out base (DOB-ura) containing 2% glucose. The samples were washed with induction media (DOB-ura) containing 2% galactose and expression was induced for 3 days at 20 °C in the same media supplemented with the appropriate fatty acids and 0.01 % tergitol (NP-40). After 3 days of incubation, yeast cells were collected by centrifugation and washed twice with distilled water. Fifteen ml. of chloroform:methanol (1 :1 ) was added to the collected yeast pellet and the sample was incubated at room temperature with shaking for 3 hr. After the 3 hr incubation, the sample was centrifuged and the aqueous phase was collected and stored at -20°C. Chloroform:methanol (2:1 ) was added to the pellet, and it was incubated overnight at 4°C, then subjected to centrifugation. The aqueous phase was collected and pooled with the aqueous phase collected previously. Nine ml. of 0.45% NaCI was added to the pooled aqueous phase, the sample was vortexed and the organic phase was collected after separated by centrifugation at 1500 x g for 3 min. The organic phase was dried under nitrogen gas and resuspended in 100 uL of chloroform to give the total fatty acid fraction. 5 uL of the total fatty acid fraction was analyzed by GC, and the remainder was separated by TLC as described below.
TLC plates were heat activated for at least 3 hrs at 120°C before use. The mobile phase used to separate the fatty acids consisted of chloroform : methanol : acetic acid (65:35:8) and primuline (5mg in 100ml_ acetone : water, 80:20) was used to visualize the separated lipid fractions under UV light. The individual lipid fractions (PC, PE, PI+PS, and neutral lipids) were identified using standards and removed separately from the TLC plate. To extract the lipids from the silica, 400 uL water, 2 ml. chloroform and 2 ml. methanol were added, the sample was vortexed vigorously, and 2 ml. of 0.2 M H3PO4/ 1 M KCI was added. The lower organic phase was collected and the remaining aqueous phase was re-extracted by adding 2 ml. of chloroform. The pooled organic phase was dry under nitrogen gas, and the fatty acid profile of individual lipid fractions was analyzed by gas chromatography. GC was performed by adding 2 ml. of 3N methanolic HCI, followed by incubation at 80 °C for 40 min, then adding 1 ml of 0.9% NaCI and 2 ml. of hexane and vortexing. The hexane phase was collected, dried under nitrogen gas, and resuspended in 100 μΙ_ of hexane for GC analysis. Gas chromatography was performed using an Agilent 6890N gas chromatograph equipped with a DB-23 column and a thermal program consisting of: 160 °C for 1 min, then temperature was increased to 240 °C at a rate of 4 °C/min. After the initial GC analysis, samples with low concentrations were re-suspended in 40μΙ_ of hexane and re-analyzed.
Time Course studies:
Initially, a range of conditions were tested with the c-d5Des(Tc_GA2) (Figure 30). When cultures were fed with 0.25 mM exogenous substrate at the beginning of induction the amounts of product and substrate and the desaturation percentage remained steady from approximately 48-92 hours (Figure 30, Panel A). Therefore, these conditions were used for further time course experiments.
To determine if these conditions were acceptable for all gene constructs, time courses were conducted with yeast cultures expressing all 10 genes individually. The preferred substrate for each enzyme was supplied exogenously (Figure 31 ).
Although the rate of uptake of fatty acids and the activity of enzymes varied, the levels of product, substrate and percent elongation or desaturation was relatively stable at the 72 hour time point (Figure 31 ). Therefore data collection at 72 hours was used in all further experiments, except where noted otherwise.
Analysis of all enzymes with all fatty acids:
The major activity of each desaturase and elongase used in the plant construct was determined upon gene isolation. However, many desaturases and elongases have secondary activities. When all enzymes are present together, such secondary activities affect the overall production rates of desired fatty acids, or lead to the production of side-products. In this experiment, we tested all enzymes with all fatty acids that might be expected to be present in a plant expressing all 10 genes. The enzymes and fatty acids used in this experiment are listed below:

Although we saw some side activities with the desaturases, such as the conversion of GLA to SDA by the c-d5Des(Tc_GA2) and conversion of DHGLA to ARA by the c-d4Des(Tc_GA), these activity levels were low and produce fatty acids that would be expected in the DHA synthesis pathway (Table 159).
We also analyzed the substrate profile of single point mutants of c-d12Des(Ps_GA) and c- d4Des(PI_GA)2. The single nucleotide change leading to the F83L mutation in c-d12Des(Ps_GA) did not lead to any significant change in either the substrate preference or efficiency of desaturation relative to the wild-type version of c-d12Des(Ps_GA) (data shown in Table 159). Similarly, a single nucleotide change leading to the A102S mutation in d4Des(PI_GA)2) did not lead to any significant change in either the substrate preference or efficiency of desaturation relative to the wild-type version of d4Des(PI_GA)2 (data shown in Table 159).


The elongases generally showed a higher level of side activities (Table 160, Table 161 ). While the two delta-6 elongases showed similar conversion percentages for the main substrates GLA and SDA, the P. patens enzyme showed higher levels of activity on LA and ALA, and only the P. patens delta-6 elongases showed detectable activity of ARA and EPA. Nonetheless, activity levels were substantially higher with GLA and SDA, suggesting that if these fatty acids, which were expected to be available in the pathway, would be the preferred substrate of the enzyme.
Table 160. Conversion percentages of exogenous fatty acids by Delta-6 Elongases

Table 161. Conversion percentages of exogenous fatty acids by c-d5Elo(Ot_GA3) elongase. Substrate and Product values represent % of total fatty acids.

Since 20:4n-3 was not commercially available it was generated in vivo by co-expression of c- d6Elo(Tp_GA2) with each of the other desaturases or elongases. Therefore upon supplying exogenous SDA, 20:4n-3 was produced by the c-d6Elo(Tp_GA2) and the efficiency of conversion of this fatty acid by the second enzyme was measured.


The c-d4Des(Tc_GA), the c-d5Des(Tc_GA2), the c-d6Des(Ot_febit), and the c-d5Elo(Ot_GA3) were able to use 20:4n-3 as a substrate (Table 162). The c-d5Des(Tc_GA2) showed the highest conversion percentage, which would be expected as 20:4n-3 was a known substrate for delta-5 desaturases. The c-d5Elo(Ot_GA3) was also able to efficiently produce 22:4n-3. When using two delta-6 elongases in one construct, a gene dosage effect was observed; the delta-6 elongase activity increased in the presence of two c-d6Elo(Tp_GA2), or a gene pair consisting of a c- d6Elo(Tp_GA2) and a c-d6Elo(Pp_GA2).
Fatty acid specificity of desaturases and elongases of this invention
Enzymes were provided with mixtures of fatty acids to allow comparisons of relative activity when two substrates were present concurrently; an enzyme may be more active on substrate A than substrate B when they are supplied individually, but when they are supplied at the same time the relative activity of the enzyme on each substrate could change. Fatty acids of the same length were preferably provided at the same time, since they would be most likely to be present in the plant concurrently. Mixtures of fatty acids were adjusted so that the level of (substrate 1 + product 1 ) = (substrate 2 + product 2) within ± 5%.


As described in Table 163 the relative activities of the omega-3 desaturases follow the same order as described earlier (Table 159), but that the activity of both omega-3 desaturases was lower on DTA when DHGLA and ARA were available. Both delta-4 desaturases showed a preference for
the omega-3 substrate when the omega-3 and omega-6 substrates were present in equal amounts. The preference of the c-d6Des(Ot_febit) for the omega-3 substrate was also increased when both substrates are available (Table 163). For the delta-5 elongase, the relative elongation of secondary substrates generally dropped when the primary, or preferred substrate was available (Table 163).
Additive enzyme activity supporting MoA (CoA vs PC)
The delta-5 desaturase genes from S. arctica and Thraustochytrium sp. were cloned into the pYES2.1A 5-His-TOPO expression vector, and both the c-d6Elo(Tp_GA2) and the c-d8Des(Eg) were cloned into the pESC-Leu expression vector. Yeast was transformed with the appropriate vector pairs and selection on DOB-uracil-leucine. Positive cultures were grown and induced and GC analysis was conducted as described above in Example 23. All cultures were grown concurrently. Table 164. Deduced mode of action of the Delta-5 desaturases.

As described in Table 164, the delta-5 desaturase activity of the c-d5Des(Sa) on DHGLA was similar regardless if the DHGLA was derived from elongation in the coenzyme A (CoA) pool or desaturation in the phosphatidylcholine (PC) pool. Conversely, Table 164 also shows that the delta-5 desaturase activity of the c-d5Des(Tc_GA2) was much higher if the DHGLA substrate was derived from elongation in the CoA pool. In combination with data from lipid analysis by TLC, this suggests that the c-d5Des(Tc_GA2) was capable of desaturating substrates in the CoA pool, although it does not indicate that desaturation was limited to this pool. The level of delta-6-elongation following desaturation by a desaturase active in the PC pool (c- d6Des(Pir_GA)) and a desaturase thought to be active in the CoA pool (c-d6Des(Ot_febit)) was determined. Since elongation takes place in the acyl-CoA pool, more efficient elongation can occur following desaturation by an acyl-CoA dependent desaturase. The two desaturases were also expressed in the presence of a delta -12 desaturase that was active on PC substrates, to allow the efficiency of subsequent delta -6 desaturation to be compared. Finally, the effects of
individual desaturase genes and pairs of desaturase genes on elongase and desaturase activity were compared to determine dosage effects.
Table 165. Effects of various delta-6 desaturases on subsequent delta-6 elongation*.

* Cultures were fed with LA and production of GLA (delta-6 desaturation) and DHGLA (delta-6 elongation) were measured. pY: pYES2.1A/5-His-TOPO expression vector pT: pESC-trp expression vector. All genes were under the control of the Gall promoter.
Table 166. Effects of delta-12 desaturation on subsequent delta-6 elongation*.

* Cultures were supplied with exogenous 18:1 n-9. The production of LA (delta-12 desaturation) and GLA (delta-6 desaturation) were measured. pY: pYES2.1A/5-H is-TOPO expression vector pT: pESC-trp expression vector. All genes were under the control of the Gall promoter.
GLA conversion by the c-d6Elo(Tp_GA2) was higher with GLA derived from desaturation by the c-d6Des(Ot_febit) compared to GLA derived by desaturation with the c-d6Des(Pir_GA) (Table 165). This shows that c-d6Des(Ot_febit) acts in the acyl-CoA pool, making the resulting substrate more readily available for the delta-6 elongase, and therefore resulting in a higher elongase activity. Correspondingly, the delta-6 desaturase activity of the c-d6Des(Ot_febit) was reduced by almost half if the substrate was derived from delta-12 desaturation in the PC pool (Table 165 and Table 166), whereas the the delta-6 desaturase activity of the c-d6Des(Pir_GA) was similar whether the substrate (LA) was derived from delta-12-desaturation of OA in the PC pool, or was supplied exogenously (Table 165 and Table 166). Exogenously supplied substrate was believed to enter the yeast cell in the form of acyl-CoA. In combination with data from lipid analysis by TLC, this data suggests that the c-d6Des(Ot_febit) was acyl-CoA-dependent enzyme, consistent with a previous prediction (Domergue et al. (2005) Biochem. J. 389: 483-490).
Table 167. Effect of substrate pool and gene dosage on delta-6-desaturation and subsequent delta-6-elongation of ALA.

* Cultures were fed with ALA and production of SDA (delta-6 desaturation) and 20:4n-3 (delta-6 elongation) was measured. pY: pYES2.1/V5-His-TOPO expression vector; pL: pESC-Leu expression vector; pT: PESC-trp. All regulated by Gall promoter. N/A: not applicable; DES: desaturation conversion percent. Data from at least 3 clones were used for each measurement.
Table 168. Effect of substrate pool and gene dosage on delta-6-desaturation and subsequent delta-6-elongation of LA.

* Cultures were fed with LA and production of GLA (delta-6 desaturation) and DHGLA (delta-6 elongation), three repeats were measured. pY: pYES2.1/V5-His-TOPO expression vector; pL: pESC-Leu expression vector; pT: PESC-trp. All genes were placed under the control of the Gall promoter. N/A: not applicable; DES: desaturation conversion percent.
When co-expressing the c-d6Elo(Tp_GA2) and the c-d6Des(Ot_febit) (CoA), a higher elongase conversion efficiency was achieved compared to co-expressing the c-d6Elo(Tp_GA2) and the c- d6Des(Pir_GA) (PC), regardless of whether n-3 or omega-6 substrate was supplied exogenously (Table 167, Table 168). This was observed whether the relevant desaturase gene was cloned into the pYes vector or the pESC-trp vector. A slight increase in desaturation efficiency was observed in the presence of two desaturase genes, particularly in cultures supplied with the omega-3 substrate ALA. Compared to cultures carrying a single c-d6Des(Ot_febit), the proportion
of substrate elongated was only slightly enhanced in the presence of two acyl-CoA dependent c- d6Des(Ot_febit), or in the presence of both desaturases. Co-expression of the c-d6Elo(Tp_GA2) with two copies of c-d6Des(Pir_GA) (PC) resulted in the lowest elongation conversion level among the cultures carrying two desaturases. The presence of the with acyl-CoA dependent delta-6 desaturase contributed to a higher delta-6 elongation activity whether it was expressed alone or along with a second desaturase, further indicating the usefulness of this gene for VLC-PUFA synthesis.
The effect of substrate pool for various delta-4 desaturases was determined in the presence of a helper enzyme, the c-d5Elo(Ot_GA3), which was known to work in the CoA pool. The gene dosage effect of delta-4 desaturase genes was also determined.
Table 169. Effect of substrate pool and gene dosage effect for delta-4 desaturases (exogenous EPA supplied).

* Cultures were fed with EPA and production of DPA (delta-5 elongation) and DHA (delta-4 desaturation) was measured for at least three samples. pY: pYES2.1A 5-His-TOPO expression vector; pL: pESC-Leu expression vector; pT: PESC-trp. All genes were placed under the control of the Gall promoter. N/A: not applicable. Dosage effect: number in brackets = conversion efficiency of two-desaturase construct/ (conversion efficiency of single gene A construct + conversion efficiency of single gene B construct).
Table 170. Effect of substrate pool and gene dosage effect for delta-4 desaturases (exogenous ARA supplied).

*Cultures were fed with ARA and production of DTA (delta-5 elongation) and DPAn-6 (delta-4 desaturation) were measured. pY: pYES2.1/V5-His-TOPO expression vector; pL: pESC-Leu expression vector; pT: PESC-Trp expression vector. All genes were placed under control of the Gall promoter. N/A: not applicable. Dosage effect: number in brackets = conversion efficiency of two-desaturase construct/ (conversion efficiency of single gene A construct + conversion efficiency of single gene B construct). The desaturation levels achieved by the P. lutheri and c-d4Des(Tc_GA)s were similar. When two delta-4 desaturases were used, a significant gene dosage effects only observed with the P. lutheri/Thraustochyrium sp. pair, and the lowest with two copies of the Thraustocytrium sp desaturase. These trends were observed in the presence of elongated ARA (Table 170) and EPA (Table 169). However, with the n-6 elongation substrate (ARA), the desaturation conversion percentage was generally slightly lower compared to the omega-3 substrate (EPA).
Example 23: Spacer Regions Containing Transcription Factor Binding Motifs
As indicated in examples 3 and 4, between each expression cassette in the constructs used in the invention there is a spacer region of 100-200 base pairs. For the BiBAC T-DNAs, the short stretches of sequence in between the gene cassettes, which had been multi-cloning sites and Gateway site sequences in the co-transformation vectors, were subjected to randomization to
maintain the GC content and to remove multiple repeats of identical sequence. The skilled worker would recognize that the presence of multiple repeats within a construct, in particular large multi- gene constructs, could result in internal deletions and rearrangements as the plasmid was cloned into Escherichia co/iand passaged through the Agrobacterium strain/species used. After removal of repeats and adjustment of GC content, the sequences of the spacer regions were then examined for any possible binding sites for transcription factors and other DNA interacting proteins. The spacer region sequences used are RTP1069CM through RTP1069CM2, including the AtAHAS promoter and terminator, RTP10690_5', LJB2197_5' and LJB2197_1 through LJB2197_4. The underscore numbers also represent the order in which that spacer region appears in the cassette reading from the right border towards the left border, in the sense orientation of the GOI in the proceeding cassette. For example, RTP10690_1 was the sequence after the terminator of the first cassette and before the promoter of the second cassette in the construct VC-RTP10690-1 qcz_F. The terminator of the AHAS selection cassette and the 5' region of the first cassette were also examined.
>RTP10690_1
TTAATTCAGCTAGCTAGCCTCAGCTGACGTTACGTAACGCTAGGTAGCGTCACGTGACGTT AG CTAACG CTAG GTAG CGTCAG CTG AG CTTACGTAAG CG CTTAG CAGATATTT >RTP10690_2
TTACTGATTGTCTACGTAGGCTCAGCTGAGCTTACCTAAGGCTACGTAGGCTCACGTGACG TTACGTAAGGCTACGTAGCGTCACGTGAGCTTACCTAACTCTAGCTAGCCTCACGTGACCT TAGCTAACACTAGGTAGCGTCAGCTCGACGGCCCG >RTP10690_3
GGCGGAGTGGGGCTACGTAGCGTCACGTGACGTTACCTAAGCCTAGGTAGCCTCAGCTGA CGTTACGTAACGCTAGGTAGGCTCAGCTGACACGGGCAGGACATAG
>RTP10690_4
GAATGAAACCGATCTACGTAGGCTCAGCTGAGCTTAGCTAAGCCTACCTAGCCTCACGTGA GATTATGTAAGGCTAGGTAGCGTCACGTGACGTTACCTAACACTAGCTAGCGTCAGCTGAG CTTAGCTAACCCTACGTAGCCTCACGTGAGCTTACCTAACGCTACGTAGCCTCACGTGACT AAGGATGACCTACCCATTCTT >RTP10690_5
GCGGCCGCTAGCTAGCCTCAGCTGACGTTACGTAACGCTAGGTAGCGTCACGTGACGTTA
GCTAACGCTAGGTAGCGTCAGCTGAGCTTACGTAAGCGCCACGGGCAGGACATAGGGACT
ACTACAA >RTP10690_6
CGAATGAAACCGATCTACGTAGGCTCAGCTGAGCTTACCTAAGGCTACGTAGGCTCACGT
GACGTTACGTAAGGCTACGTAGCGTCACGTGAGCTTACCTAACTCTAGCTAGCCTCACGTG
ACCTTAGCTAACACTAGGTAGCGTCAGCTTAGCAGATAT
>RTP10690_7
CCGTTCAATTTACTGATTGTCTACGTAGCGTCACCTGACGTTACGTAAGGCTACCTAGGCT CACGTGACGTTACGTAACGCTACGTAGCGTCAGGTGAGGTTAGCTAACGCTAGCTAGCCT CACCTGACGTTAGGTAAGGCTACGTAGCGTCACCTGAGATTAGCTAAGCCTACCTAGACTC ACGTGACCTTAGGTAACGCTACGTAGCGTCAAAGCTTTACAACGCTACACAAA
>RTP10690_8
TTACCTAACTTAGAACTAAAATCAACTCTTTGTGACGCGTCTACCTAGAGTCAGCTGAGCTT AGCTAACGCTAGCTAGTGTCAGCTGACGTTACGTAAGGCTAACTAGCGTCACGTGACCTTA CGTAACGCTACGTAGGCTCAGCTGAGCTTAGCTAACCCTAGCTAGTGTCACGTGAGCTTAC GCTACTATAGAAAATGTGTTATAT
>RTP10690_9
TTCAGTCTAAAACAACTACGTAGCGTCACGTGACGTTACCTAAGCCTAGGTAGCCTCAGCT GACGTTACGTAACGCTAGGTAGGCTCAGCTGACTGCAGCAAATTTACACATTGCCA
>RTP10690_10
TAATTCGGCGTTAATTCAGCTACGTAGGCTCAGCTGAGCTTACCTAAGGCTACGTAGGCTC ACGTGACGTTACGTAAGGCTACGTAGCGTCACGTGAGCTTACCTAACTCTAGCTAGCCTCA C GTG ACCTTAG CTAACACTAG GTAG CGTC AG CACAG ATGAATACTAG CTGTTGTTCA
>RTP10690_1 1
ATCATGATGCTTCTCTGAGCCGTGTTTGCTAGCTAGCCTCAGCTGACGTTACGTAACGCTA GGTAGCGTCACGTGACGTTAGCTAACGCTAGGTAGCGTCAGCTGAGCTTACGTAAGCGCA CAGATGAATACTAGCTGTTGTTCACA
>RTP10690_12
CTTCTCTGAGCCGTGTTTGCTAGCTAGCCTCAGCTGACGTTACGTAACGCTAGGTAGCGTC ACGTGACGTTAGCTAACGCTAGGTAGCGTCAGCTGAGCTTACGTAAGCGCTTAATTAAAGT ACTGATATCGGTACCAAATCGAATCCAAAAATTACGGATATGAATAT
>RTP10690_5'
ATTACAACGGTATATATCCTGCCAGTCAGCATCATCACACCAAAAGTTAGGCCCGAATAGTT TGAAATTAGAAAGCTCGCAATTGAGGTCTACAGGCCAAATTCGCTCTTAGCCGTACAATATT ACTCACCGGTGCGATGCCCCCCATCGTAGGTGAAGGTGGAAATTAATGGCGCGCCTGATC ACTGATTAGTAACTATTACGTAAGCCTACGTAGCGTCACGTGACGTTAGCTAACGCTACGT AGCCTCAGCTGACGTTACGTAAGCCTACGTAGCGTCACGTGAGCTTAGCTAACGCTACCTA GGCTCAGCTGACGTTACGTAACGCTAGCTAGCGTCACTCCTGCAGCAAATTTACACA >t-AtAHASL
GAGATGAAACCGGTGATTATCAGAACCTTTTATGGTCTTTGTATGCATATGGTAAAAAAACT TAGTTTGCAATTTCCTGTTTGTTTTGGTAATTTGAGTTTCTTTTAGTTGTTGATCTGCCTGCT TTTTGGTTTACGTCAGACTACTACTGCTGTTGTTGTTTGGTTTCCTTTCTTTCATTTTATAAAT
AAATAATCCGGTTCGGTTTACTCCTTGTGACTGGCTCAGTTTGGTTATTGCGAAATGCGAAT GGTAAATTGAGTAATTGAAATTCGTTATTAGGGTTCTAAGCTGTTTTAACAGTCACTGGGTT AATATCTCTCGAATCTTGCATGGAAAATGCTCTTACCATTGGTTTTTAATTGAAATGTGCTCA TATGGGCCGTGGTTTCCAAATTAAATAAAACTACGATGTCATCGAGAAGTAAAATCAACTGT GTCCACATTATCAGTTTTGTGTATACGATGAAATAGGGTAATTCAAAATCTAGCTTGATATG CCTTTTGGTTCATTTTAACCTTCTGTAAACATTTTTTCAGATTTTGAACAAGTAAATCCAAAAA AAAAAAAAAAAATCTCAACTCAACACTAAATTATTTTAATGTATAAAAGATGCTTAAAACATTT GGCTTAAAAGAAAGAAGCTAAAAACATAGAGAACTCTTGTAAATTGAAGTATGAAAATATAC TGAATTGGGTATTATATGAATTTTTCTGATTTAGGATTCACATGATCCAAAAAGGAAATCCAG AAGCACTAATCAGACATTGGAAGTAGG
>LJB2197_5'
AC ATAC AAATG G AC G AAC G G AT AAAC CTTTT C AC G C C CTTTTAAATATC C G ATTATTCTAATA AACGCTCTTTTCTCTTAGGTTTACCCGCCAATATATCCTGTCAAACACTGATAGTTTAAACT GAAGGCGGGAAACGACAATCTGATCACTGATTAGTAACTAAGGCCTTTAATTAATCTAGAG GCGCGCCGGGCCCCCTGCAGGGAGCTCGGCCGGCCAATTTAAATTGATATCGGTACATC GATTACGCCAAGCTATCAACTTTGTATAGAAAAGTTGCCATGATTACGCCAAGCTTGGCCA CTAAGGCCAATTTCGCGCCCTGCAGCAAATTTACACA
>LJB2197_1
CAATTTACTGATTGTGTCGACGCGATCGCGTGCAAACACTGTACGGACCGTGGCCTAATAG GCCGGTACCCAAGTTTGTACAAAAAAGCAGGCTCCATGATTACGCCAAGCTTGGCCACTAA GGCCAATTTAAATCTACTAGGCCGGCCATCGACGGCCCGGACTGTA
>LJB2197_2
GGCGGAGTGGGGGGCGCCTACTACCGGTAATTCCCGGGATTAGCGGCCGCTAGTCTGTG CGCACTTGTATCCTGCAGGTTAGGCCGGCCACACGGGCAGGACATAGGG
>LJB2197_3
AAACCGAATGAAACCGATGGCGCCTACCGGTATCGGTCCGATTGCGGCCGCTTAAAGGGC GAATTCGTTTAAACACTGTACGGACCGTGGCCTAATAGGCCGGTACCACCCAGCTTTCTTG TACAAAGTGGCCATGATTACGCCAAGCTTGGCCACTAAGGCCAATTTAAATCTACTAGGCC GGCCATAAGGATGACCTACCCATTCTT
>LJB2197_4
TTAATTCAGGGCCGGCCAAAGTAGGCGCCTACTACCGGTAATTCCCGGGATTAGCGGCCG CTAGTCTGTGCGCACTTGTATCCTGCAGGTTAGGCCGGCCATTAGCAGATATTT
Table 171 : Cassettes contained in the constructs VC-RTP10960-1 qcz_F and VC-LJB2197-1qcz and the spacer regions in front of them, which was 5' of the promoter region. The bold lettering indicates the spacer, which corresponds to the Seq ID's listed above above.


Transcription factors are known to bind certain sequences of DNA and from this point of interaction with the chromosome they regulate transcription of a certain gene or subset of genes. The specific sequences which are bound by the transcription factor are referred to as DNA binding motifs and can be in the range of tens of base pairs to as few as four base pairs. The majority of
DNA binding motifs consist of less than ten base pairs but those motifs have been documented to be necessary and sufficient for up (or down) regulation of transcription by the transcription factor binding to them. For examples of transcription factor motifs and the enabling data that are used to support the motifs see; Hattori et al., 2002, Keller et al., 1995, Kim et al., 2014, Lopez et al., 2013, Machens et al., 2014, Muino, 2013, Sarkar, 2013, Dubos et al., 2014). Identified motifs have been curated and archived in various data bases, such as PLACE (Higo et al., 1999), which can be accessed and queried by the public. While certain characterized promoters are used as the primary means to regulate expression of a given transgene in the invention, it was possible that alternative regulation of a transgene was occurring in the plants described in the invention due to the presence of one or more active transcription factor binding motifs in the spacer region. Examples of artificial/synthetic promoters in the public literature support this line of reasoning; see Kong et al. (2014), Nishikata et al. (2013), and Brown et al. (2014) for examples of promoters made by random assembly of nucleotides and iterative testing as well as specific fragments of known transcriptional activity assembled to make an artificial promoter. Thus the regulatory region of a given transgene in the invention also includes, in addition to the intron, terminator and the promoter used, the spacer region in front of the cassette containing the transgene.
Table 172: lists the spacer region and the transcription factor binding motif present in the region and the nucleotide sequence. Upper case letters denote the motif while surrounding bases indicate examples of sequences that might neighbor the predicted motif but are not necessary for the motif to function in the regulation of transcription










































Example 24 Gene Expression, Copy number determination and event detection
Plant material representing wild type, the BiBAC VC-RTP10690-1 qcz_F, and the co- transformation constructs: VC-LJB2197-1 qcz with VC-LLM337-1 qcz rc, VC-LJB2755-2qcz rc with VC-LLM391-2qcz rc and VC-LJB2755-2qcz rc with VC-LTM217-1 qcz rc were harvested according to the date after pollination. Construct details (genes and promoters) are found in Table 1 , Table 2, Table 4, Table 6, Table 7 and Table 8. Based on the day after pollination, which correlated with developmental stage under the growth conditions employed, the seeds were combined into pools. The pooled seeds were immediately frozen in liquid nitrogen and subsequently stored at -80° C. A third of the frozen immature seeds were homogenized using the Precelly®24-Dual technology in 7ml tubes and two ceramic beads (6500Hz, 2-3 times, 20sec). From each pool three aliquots of 50-70mg of tissue were used to isolate the RNA. Frozen tissue was ground to a fine powder and extracted following basic procedures familiar to one who was skilled in the art (see Ruuska et al. 2000 and Focks and Benning, 1998 as well as Sambrook et al.1989 for an overview on RNA extraction from immature seeds and sample and RNA handling). RNA was extracted according to the protocol "SG-MA_0007-2009 RNA isolation" using Spectrum Plant Total RNA-KIT part number STRN50 (SIGMA-ALDRICH GmbH, Munich, Germany). In average the concentration of total RNA was about 450ng^l. The 260/280 ratio was at 2.2 and the 260/230 ratio at 2.3.
For cDNA synthesis for qPCR 1 g of total RNA was treated with DNAsel (DEOXYRIBU NUCLEASE I (AMP-D1 , Amplification Grade from SIGMA-Aldrich, GmbH) according to the supplier's protocol. After DNAsel treatment, the reverse transcription reaction was performed with the Superscript™ III First-Strand Synthesis SuperMix for qRT-PCR (Invitrogen, Cat. No. 1 1752-250) and with a combination of oligo dT and random hexamers to ensure thorough and even representation of all transcripts, regardless of length.
Quantitative real time per protocol
Transcript measurement by quantitative real time PCR was carried out using procedures considered standard to those skilled in the art; see Livak and Schmittgen (2001 ). The qPCR reactions were done as simplex TaqMan reactions. The endogenous reference gene was isolated in house and used due to predicted stability of the transcript based on the observed stability of the transcript corresponding to the orthologue in Arabidopsis thaliana during development. The canola ortholog was isolated and the gene, SEQ ID, was part of the glycosyl-phosphatidylinositol aminotransferase pathway (GPI). The cDNA reactions, described above, were diluted 1 :4. 2μΙ cDNA, which corresponded to 25ng of total RNA, was used per 10μΙ qPCR reaction with JumpStart TAQ ReadyMix (P2893-400RXN Sigma-Aldrich, GmbH). Primer/probe concentrations were 900 nmol for forward and reverse primer and l OOnmol TaqMan probe. The TaqMan probes for targets of interest were labeled with FAM/BHQ1 , and the reference gene was labeled with Yakima Yellow/BHQ1. Each qPCR assay included a 1 :1 dilution curve (5 dilution steps) with cDNA from the pool VC- RTP10690-1 qcz_F, a no template control, three -RT controls (VC-RTP10690-1 qcz_F, VC- LTM593-1 qcz rc (~4w) and co-transformation VC-LJB2197-1 qcz + VC-LLM337-1 qcz rc). From each pool three independent aliquots of cDNA were measured as technical repeats. The ABI PRISM® 7900 sequence detection system (Applied Biosystem) was used with the following PCR Conditions:
Initial denaturation 95°C for 300 seconds 1 cycle
Amplification 95°C for 15 seconds/60°C for 60 seconds repate for 40 cycles The raw data were the Ct values for the target and the endogenous reference gene, respectively. The dCt values were calculated by subtraction: Ct(GOI)-Ct(Ref). The Reference dCt value was set to equal zero, which was interpreted as meaning that if there was no difference between GPI and the gene of interest (dCt = 0) the expression was = 1. The fold expression was equal to 2-dCt (where the dCt = (Ct(GOI)-Ct(Ref)-0)). Three samples from each pool were taken and the geomean as well as the geometric positive and negative deviation were calculated. The slopes of dilution curves were calculated for each gene of interest and the endogenous reference gene (GPI) as a measure for the amplification efficiency. Table 173,
Table 174 and Table 175 indicate the probes and primers used to amplify the genes for qPCR assays.



Transcript analysis of a time course for gene expression of the BiBAC and co- transformations.
Transformants from four constructs were assayed as described above and transcript abundance relative to a single standard was measured as described, following standard protocols known to those skilled in the art as well as instructions provided with the kits employed. The graphs in Figure 16, Figure 17, Figure 18, Figure 19, Figure 20 and Figure 21 represent abundance of the gene listed over time with the error represented by the geometric positive and negative deviation. The time was listed on the abscissa and represents days after pollination and the ordinate contains the expression of the gene of interest relative to an internal standard (canola GPI). Lines with two constructs listed represent co-transformation events.
The gene o3Des(Pi_GA2) driven by the VfUSP promoter with the CaMV35S terminator was present in VC-LJB2755-2qcz, VC-LLM337-1 qcz rc and VC-RTP10960-1 qcz_F. One observes in Figure 16 that VC-RTP10960-1 qcz_F has relatively low transcript accumulation while the co- transformation combination of VC-LJB2755-2qcz and VC-LLM391-2qcz rc contains the highest accumulation of transcript from the gene o3Des(Pi_GA2). The overall trend for this transcript with the promoter, terminator, intron and spacer region in front of the promoter was to increase over seed development.
The gene d4Des(PI_GA)2 driven by the LuCnl promoter with the AgrOCS 192bp[LED12] terminator was present in both VC-LTM217-1 qcz rc and in VC-RTP10960-1 qcz_F. One observes in Figure 19 for both constructs that the accumulation relative to the GPI reference was in the range of 4-12 fold with gradual accumulation over seed development, with VC-RTP10960-1 qcz_F accumulating less than VC-LTM217-1 qcz rc.
The o3Des(Pir_GA) gene was present in VC-LJB2755-2qcz and VC-RTP10960-1 qcz_F driven by the LuCnl promoter with the AtPXR 400bp[LLL823] terminator while it was present in VC-LLM337- 1 qcz rc driven by the VfSBP_perm3 promoter with the StCATHD-pA terminator. Within error it was difficult to ascribe a pattern to any of the constructs, but as shown in Figure 17, single copy events of the construct combination VC-LJB2755-2qcz and VC-LLM391 -2qcz had a peak towards seed maturation that was not observed with any of the other constructs. An additional copy of the gene driven by the BnSETL promoter and terminated by the BnSETL terminator was present in RTP10960-1 qcz_F. However, similar to the d5Des(Tc_GA2) gene controlled by the same set of control elements, the o3Des(Pir_GA) copy under control of the p-BnSETL promoter was expressed at lower levels than the other genes with different control elements (Figure 18).
The gene d4Des(Tc_GA) was contained in VC-LLM337-1 qcz rc, RTP10960-1 qcz_F and VC- LTM217-1 qcz rc and was driven by the ARC5_perm1 promoter with the pvarc terminator. A single point mutant of this gene; d4Des(Tc_GA)_T564G was contained in VC-LLM391 -2qcz rc and regulated by the ARC5_perm1 promoter with the pvarc terminator. The overall trend of expression with this spacer region, promoter and terminator combination was an increase over seed development and then a decrease towards seed maturation, as depicted in Figure 20. Interestingly, the construct pair VC-LJB2755-2qcz with VC-LLM391 -2qcz rc did not adhere to this trend but rather continued to increase over seed development and had a more robust expression than the other constructs and construct combinations. As previously observed VC-RTP 10960- 1 qcz_F had the lowest level of expression.
VC-LLM337-1 qcz rc and VC-LLM391-2qcz rc contain d4Des(Eg_GA) driven by the LuCnl promoter with the AgrOCS 192bp[LED12] terminator. It can be seen in Figure 21 , that similar expression levels that increased during seed development where observed of single copy events containing either one of these two constructs.
Copy Number
To assess whether the entire pathway for PUFA biosynthesis was being brought into the plant and to what extent duplication and/or deletion was occurring in selected events; copy number analysis of certain genes along the T-DNA was carried out.
DNA extraction
Brown spotted immature seeds from three events were analyzed, in addition to cotyledons of germinating seedlings of two further events. The gDNA was isolated according to standard protocols consistent with Sambrook et al., 1982. To isolate plant tissue DNA the Wizard Magnetic 96 DNA Plant System was used (Promega, Madison, Wl USA part number FF3760). The supplied
protocols were followed with the listed changes being implemented in order to increase the amount of extracted DNA: the volume of the extraction buffer was increased to two hundred microliters and the volume of beads used was increased to ninety microliters with the volume of elution buffer being decreased to twenty microliters.
Duplex qPCR reactions were performed using JumpStart TaqReadyMix for Quantitative PCR (Sigma, D7440). qPCR assays were validated according to standard protocols for qPCR, see Demeke and Jenkins (2010) and Livak and Schmittgen (2001 ). The genomic copy numbers were calculated with the ddCt method based on the mean of the reference dCt value of a pool of known single copy events. Using the Excel function "frequency", groups of 0, 1 , 2, 3, >4 were counted both target and event wise. A Chi-square test was performed for testing the hypothesis the family was segregating for a single T-DNA. The cutoff of P value was set at > 0.0499 for a single T-DNA segregation. PCR for copy number analysis was carried out using the primers and probes listed and according to standard protocols used by those skilled in the art, see Livak and Schmittgen (2001 ) and Demekes T. and Jenkins RG (2010).
The primer pairs and probes are listed by name below and sequences can be found in the sequence listing:



Isolation of genomic flanking sequences from transgenic events
Genomic DNA sequences flanking each T-DNA insertion in events LANBCH, LBFDGG, LBFDHG, LBFGKN, LBFIHE, LBFLFK, LBFPRA, and LBFDAU were determined. Leaf samples from greenhouse grown plants were harvested and frozen. The leaf tissue was ground and genomic DNA was extracted using standard protocols for plant genomic DNA extraction. An aliquot amount of genomic DNA from each event was then used to isolate flanking sequences by adapter ligation- mediated PCR as described in O'Malley et al. 2007 Nature Protocols 2(1 1 ):2910-2917. Using this technique, PCR products were generated that contained sequence of the T-DNA border and adjacent genomic DNA. For each event distinct PCR products were obtained corresponding to the left and right border of each T-DNA locus. Individual PCR products were isolated and were sequenced using standard DNA sequencing protocols to determine sequence of the flanking regions. The flanking sequences of event LANBCH are SEQ ID NO: 212, SEQ ID NO: 213, SEQ ID NO: 214, SEQ ID NO: 215, SEQ ID NO: 216, and SEQ ID NO: 217. The flanking sequences of event LBFDGG are SEQ ID NO: 218 and SEQ ID NO: 219. The flanking sequences of event LBFDHG are SEQ ID NO: 220, SEQ ID NO: 221 , SEQ ID NO: 222, and SEQ ID NO: 223. The flanking sequences of event LBFGKN are SEQ ID NO: 224 and SEQ ID NO: 225. The flanking sequences for event LBFIHE are SEQ ID NO: 226 and SEQ ID NO: 227. The flanking sequences for event LBFLFK are SEQ ID NO: 228, SEQ ID NO: 229, SEQ ID NO: 230, and SEQ ID NO: 231 . The flanking sequences for event LBFPRA are SEQ ID NO: 232, SEQ ID NO: 233, SEQ ID NO: 234, SEQ ID NO: 235, and SEQ ID NO: 236. The flanking sequences for event LBFDAU are SEQ ID NO: 237, SEQ ID NO: 238, SEQ ID NO: 239, and SEQ ID NO: 240. The flanking sequences are useful for determining the genomic location of T-DNA inserts and the integrity of the genomic DNA surrounding the insertion. For example, event LBFGKN contains a single T-DNA insertion of plasmid VC-LTM593-1 qcz rc. A DNA sequence alignment of SEQ ID NO: 224 and SEQ ID NO: 3 can be used to reveal the portion of the flanking sequence that corresponds to the T-DNA right border. The portion of the flanking sequence that is not identical to the T-DNA thus corresponds to the genomic DNA that is adjacent to the T-DNA right border. Likewise, the SEQ ID NO: 225 and SEQ ID NO:3 can be aligned to identify the genomic DNA sequence that is adjacent to the T-DNA left border. For event LBFGKN, the genomic DNA fragments adjacent to the right and left border of the T-DNA can be mapped to Chromosome C04 of the B. napus Darmor reference genome. Based on annotation of the B. napus reference genome, the T-DNA of event LBFGKN is inserted more than 5000 bp away from any predicted genes or coding regions. In addition, the
portions of the flanking sequences corresponding to genomic DNA indicate no rearrangements of the genomic DNA around the T-DNA insert.
Thus, in one embodiment, the plant of the invention is a transgenic plant, preferably a transgenic B. napus plant of the invention producing EPA and/or DHA, preferably EPA and DHA, comprising one or more T-DNAs for the expression of one or more genes for the production of EPA and/or DHA, whereby each T-DNA copy inserted does not disrupt any gene, e.g. no endogenous or no transgenic gene is disrupted. Preferably, the EPA and DHA content in the bulked seed is 10 mg, 15mg, 20mg, 24mg, 30mg, 31 mg, 35mg, 38 mg, or more EPA and DHA / g seed. In one embodiment, the EPA and DHA content in the bulked seed is between 10mg and 70mg, between 15mg and 60mg, 20mg and 50mg, or between 24mg and 38mg.
In one embodiment the genetic insertion of the T-DNA is located >5000 base pairs away from any endogenous gene.
The plant of the invention can comprise one or more copies one T-DNA. In one embodiment, the plant is homozygous with one copy of the T-DNA integrated in each of the homozygous loci, in another embodiment, it is homozygous with two copies of the T-DNA integrated in each of the homozygous loci. Further, the plant of the invention can by heterozygous, e.g. one or two copies of the T-DNA are integrated in one herterozygous locus. Event Specific Detection
The flanking sequences isolated from events LANBCH, LBFDGG, LBFDHG, LBFGKN, LBFIHE, LBFLFK, LBFPRA, and LBFDAU were used for the design of event specific detection assays to test for the presence T-DNA insertions. Specific primer pairs are provided in this example, but the disclosed flanking sequences could be used to design different primer pairs for producing diagnostic amplicons for each locus of each event. Endpoint Taqman qPCR assays for locus detection were developed and are described in this example. Other methods may be known and used by those skilled in the art for the detection of events LANBCH, LBFDGG, LBFDHG, LBFGKN, LBFIHE, LBFLFK, LBFPRA, and LBFDAU. Oligonucleotide primers used for the assays are listed in Table 176. Detection of each locus from LBFDAU and LBFLFK requires the use of a specific combination of forward primer, reverse primer, and probe. The TaqMan probes for targets of interest were labeled with FAM/BHQ1. The method described here is optimized for the Quantstudio™ 12K Flex Real-Time PCR system from Life Technologies, although methods can be adapted to other systems with minor modification known to those skilled in the art. Endpoint Taqman qPCR assays were carried out with JumpStart TaqReadyMix (Sigma, P2893) in a 384- well plate (Life technologies, catalogue number 4309849) in a total volume of 10 microliters per well. Per reaction, 2μΙ of template DNA is mixed with 8 microliters of qPCR reaction mixture. The plates were sealed with MicroAmp® Optical Adhesive Film (Life Technologies, catalogue number 431 1971 ). For event specific detection qPCR reaction mixture was prepared as follows:
I Taqman endpoint qPCR reaction components I
PCR Component Amount (μΙ) per reaction
2X Jumpstart Taq Readymix 5
25mM MgS04 0.4
ROX (Sulforhodamine 101 , 12 μΜ) 0.1 5
Forward Primer (10 μΜ) 0.9
Reverse Primer (10 μΜ) 0.9
Probe (10 μΜ) 0.1 gDNA (15-60ng/pl) 2
Nuclease free water 0.6 10 volume final 10 μΙ
The qPCR reactions were carried out as follows:


Pooled seed material from four week old siliques was used for protein extraction. To enrich the membrane proteins and reduce the background signal, microsomes isolated from ground seed tissue were used to analyze protein levels for the following enzymes: c-o3Des(Pi_GA2), c- o3Des(Pir_GA), d4Des(Eg), c-d4Des(PI_GA)2, and c-d6Elo(Tp_GA2). For c-o3Des(Pir_GA) and c-d6Elo(Tp_GA2), the microsomes were further extracted with detergent and used for ELISA. The various versions of a given gene (denoted as GA, GA2 etc.) all encoded an identical protein corresponding to the gene listed. Initially, in a mortar cooled with liquid nitrogen, seeds were ground to a fine powder in Extraction buffer (25 mM Tris, pH 7.4; 140 mM NaCI; 3 mM KCI; 3 mM DTT; 200 mM Sorbitol; and EDTA- free Protease inhibitors (Roche)) at a ratio of 1 g seed/4 ml buffer. The plant cell-debris was removed by centrifugation (5000 x g, 10 minutes, 4 °C), re-extracted by grinding a second time as described above with 1.5 ml of Extraction Buffer, and then again separated by centrifugation (5000 x g, 10 minutes, 4 °C). The supernatant from these two extractions was combined and represents the cell-free extract (typically 3.5 ml/g seed). Microsomal pellets were obtained from the cell-free extracts by ultra-centrifugation (100,000 x g, 60 minutes, 4 °C). For the c- o3Des(Pi_GA2), d4Des(Eg), c-d4Des(PI_GA)2, enzymes the microsomal pellets were suspended in Suspension Buffer (1xTBST+1 %TritonX-100). 1 X TBST consists of 50 mM Tris, 150 mM NaCI, 0.05% tween 20 detergent with a final pH of 7.6 at 4 °C.
For c-o3Des(Pir_GA) and c-d6Elo(Tp_GA2) the microsomal fractions were isolated as described above, and proteins were solubilized with 1X TBST buffer and detergent of choice (For details, please see the table below). For c-d4Des(Tc_GA), c-d5Elo(Ot_GA3), c-d5Des(Tc_GA2), c- d6Des(Ot_febit), c-d6Elo(Pp_GA2), c-d12Des(Ps_GA), the seed powder was further ground in liquid nitrogen and extracted with 1xTBST+1 %Triton X100+Protease Inhibitor at 1 :3 W/V ratio. The supernatant was cleared at 13,000g for 20 minutes at 4°C using a micro-centrifuge and followed by a 10 minute spin at 13,000g. The clarified supernatant was used for ELISA and total protein assay.
Antibody/antigen hybridization conditions: Plates were blocked with 300 μΙ/well of freshly made blocking solution. The plates were sealed and incubated for 1 hour with continuous shaking. After 1 hour of incubation, the plates were washed twice with 1X TBST.
The extract from above was used in the ELISA assay. The plate was incubated with 100 μΙ of standards or sample extract at 4 °C for overnight, without shaking. Standards were serial diluted 1 :3. The plates were sealed and incubated overnight at 4 °C. After the plates were incubated overnight, the plates were washed five times with 1 X TBST. After the wash the plates were incubated with 100 μΙ of detecting antibody in blocking solution for 1 hour, sealed with continuous shaking. The plates were washed five times with 1X TBST at the end of the one hour incubation step. The plates were then incubated with 100 ml of HRP-conjugated donkey anti-animal of the detecting antibody secondary antibody (1 :10,000) in blocking solution for 1 hour, in a sealed plate with continuous shaking. The plates were then washed five times with 1 X TBST at the end of the blocking step. 100 μΙ of 1-step TMB was then added and the plates incubated at room temperature
for 20 minutes, sealed with continuous shaking. After the twenty minutes, 100 μΙ of a 1 M HCI solution was added and the plates read at 450 nm.
For c-d6Elo(Tp_GA2) only: all steps were the same as for the other proteins but in place of the HRP conjugated donkey anti-body system used for the others, 100 μΙ of biotin-conjugated donkey anti-rabbit IgG diluted 1 :40,000 in 2% BSA/1X TBST was used. The plate was sealed and shaken continuously during this incubation step, which was done for one hour. The plate was washed five times with 1X TBST at the end of this step. To read this plate, the plate was incubated with 100 μΙ extravidin-peroxidase diluted 1 :40,000 in 2% BSA/1X TBST, sealed and incubated for 1 hour with continuous shaking. The plate was then washed five times with 1X TBST. The plate was read at 450 nm.
Table 177: Overview of hybridization for protein detection and quantification. TMB (3, 3', 5,5'- tetramethylbenzidine) was the substrate for the horse radish peroxidase employed to visualize protein bands, supplied by Sigma-Aldrich T-0565 and used according to the instructions of the manufacturer.


Example 26: Desaturase and Elongase substrate specificity and selectivity observed in yeast compared with fatty acid profiles observed in canola events expressing these enzymes As shown in Examples 10-18, the engineering of canola to convert endogenous fatty acids, such as oleic acid (18:1 n-9) and LA (18:2n-6) to 20:5n-3 and 22:6n-3 requires the introduction of several desaturases and elongases. Although bioinformatics is useful for predicting the function of large, well-studied classes of enzymes, for example a delta-12 desaturase, the precise substrate tolerance of an enzyme must be determined empirically. We therefore, as shown in Examples 21 and 22, determined the substrate tolerance for each desaturase and elongase that was introduced into canola (Examples 10-18). Understanding the substrate profile for each of the introduced enzymes allowed optimal engineering of canola to produce EPA and DHA by:
(1 ) Conversion of the three most predominant canola endogenous fatty acids (OA, LA, and
ALA, see Kumily profiles in Examples 10-18) to EPA and DHA,
(2) Minimizing generation of side reactions, and
(3) Providing a proof-reading mechanism that re-routes side-products back into the biosynthesis of EPA and DHA.
Examples provided herein further detail how the deduced specificity of the introduced desaturases and elongases allowed optimal engineering of canola to produce oil enriched in EPA and DHA.
Delta-6-desaturase:
Yeast feeding studies (Table 159 and Table 163) show that the delta-6-desaturase {Ostreococcus taun) can readily accept substrates containing, LA (18:2n-6) and ALA (18:3n-3). As shown in Tables 148-152, the resulting GLA (18:3n-6) delta-6-desaturase {Ostreococcus tauri) product can be processed by either of the delta-6-elongases {Physcomitreiia patens or Thaiassiosira pseudonana), followed by the delta-5-desaturase { Thraustochytrium sp. ATCC21685), either of the omega-3-desaturases {Phythophthora infestans or Pythium irregulare), the delta-5-elongase {Ostreococcus taun) and finally either of the delta-4-desaturases { Thraustochytrium sp.and Pavlova luthen) to yield DHA (22:6n-3). The resulting ALA desaturation product, SDA (18:4n-3), can be converted by either of the delta-6-elongases {Physcomitreiia patens or Thaiassiosira pseudonana) to a 20:4n-3 containing fatty acid (see Table 160), which can be accepted by the delta-5-desaturase ( Thraustochytrium sp. ATCC21685) to generate an EPA (20:5n-3) linked fatty acid as shown in Table 162. The fatty acid analysis data presented for the engineered canola lines in Examples (10-18) show significantly lower levels of ALA relative to non-transgenic Kumily controls, consistent with the engineered conversion of ALA to 20:5n-3 and 22:6n-3. Delta-6-elongases:
Yeast feeding studies (Table 160 and Table 163) show that both of the delta-6-elongases, Physcomitreiia patens and Thaiassiosira pseudonana, accept 18-carbon chain substrates but prefer molecules desaturated at carbon-6 (see GLA (18:3n-6) and SDA (18:4n-3) vs. LA (18:2n- 6) and ALA (18:3n-3). The delta-6-elongase from Thaiassiosira pseudonana is much more stringent than the one from Physcomitreiia patens in recognizing the delta-6-desaturated fatty acids. In the fatty acid analysis of the engineered canola lines presented in Examples (10-18) 20:2n-6 and 20:3n-3, resulting from desaturation of LA and ALA respectively, are detected. The inclusion of these specific elongases from Physcomitreiia patens and Thaiassiosira pseudonana allowed preferred conversion of fatty acids desaturated at carbon-6 thus, providing maximum conversion of of EPA and DHA from GLA and SDA. Fatty acid profiles of the LTM593 (Example 18) line show levels of 20:2n-6 and 20:3n-3 that are about the same as found in wild-type Kumily confirming the specificity of the delta-6 elongases from Physcomitreiia patens and Thaiassiosira pseudonana upon introduction into canola. Delta-5-desaturase:
Yeast feeding studies (Table 159 and Table 162 and Table 163) show that the delta-5-desaturase ( Thraustochytrium sp. ATCC21685) accepts DHGLA (20:3n-6) and 20:4n-3. As described above (Example 26 (this section), Delta-6-desaturase), the ability of the delta-5-desaturase ( Thraustochytrium sp. ATCC21685) to desaturate 20:4n-3 is important for the conversion of ALA and SDA into 20:5n-3 and 22:6n-3.
Omega-3-desaturases:
Yeast feeding studies show that both omega-3-desaturases, {Phythophthora infestans and Pythium irregulare) can accept ARA (20:4n-6), DTA (22:4n-6), and DHGLA (20:3n-6). These omega-3-desatu rases prefer molecules with 4 double bonds. In the transgenic canola lines described in Examples (10-18), the ability of these omega-3-desaturases to utilize 22:4n-6 as a substrate, as shown in Table 163, allows re-direction of ARA (20:4n-6) that has been elongated by the delta-5-elongase {Ostreococcus taun) back into the pathway as 22:5n-3 (a substrate for the engineered delta-4 desaturases) for synthesis of DHA (22:6n-3). Fatty acid profiles of the LTM593 (Example 18) line show detectable, but low levels of 22:4n-6 consistent with this fatty acid being converted to 22:5n-3 in vivo the described canola that was engineered to synthesize DHA.
Delta-5-elongase:
Yeast feeding studies show (Table 161 and Table 163) that the delta-5-elongase {Ostreococcus taun) prefers 20-carbon chain substrates, EPA (20:5n-3) and ARA (20:4n-6), but can also extend lipids containing 18-carbon chains, like SDA (18:4n-3) and ALA (18:3n-3). In the engineered canola (Examples 10-18) the presence of the omega-3-desaturases, {Phythophthora infestans and Pythium irregulare), allows the 22:4n-6 product, resulting from the elongation of ARA, to be converted to 22:5n-3 and which is then desatu rated by the delta-4-desaturases ( Thraustochytrium sp.and Pavlova luthen) to produce the final product, 22:6n-3. Fatty acid analysis of the transgenic canola lines described in Examples 10-18 shows minor levels of 22:4n-6, likely due to the ability of the omega-3 desaturases to redirect this lipid back into the biosynthesis of 22:6n-6. The 20:4n- 3 produced from the extension of SDA is a substrate recognized by the delta-5-desaturase { Thraustochytrium sp. ATCC21685) and can be converted to 20:5n-3, the preferred substrate of the delta-5-elongase {Ostreococcus taun).
Delta-4-desaturases:
Yeast feeding studies (Table 159 and Table 163) show that both delta-4-desaturases, { Thraustochytrium sp.and Pavlova lutheri) can accept 22:5n-3 and DTA (22:4n-6) with a slight preference for 22:5n-3.
Example 27: Using differentially labeled heavy peptides to monitor digestion efficiency in quantitative LC-MS.
The described method provides an avenue for quantitating digestion efficiency in targeted proteomics experiments. In most MRM LC-MS applications, measuring digestion efficiency relies on an indirect measurement which examines a peptide profile of the sample by comparing the number of missed cleavage peptides detected to the number of completely digested peptides detected in a separate LC-MS experiment. While providing an overall perspective of the trypsin efficiency within the experiment, the data does little to address specific digestion of the target sequence being monitored in the MRM experiment. Measuring global digestion efficiency does not address possible sequence specific biases in trypsin activity and may result in misrepresentation of target quantity. Indeed, there was a growing appreciation that trypsin digestion kinetics was strongly influenced by sequence context (Proc J. et al. 2010. Journal of Proteome Res. 9:5422-5437, and Lowenthal M. et al. 2014. Anal Chem. 86:551-558). In order to
measure sequence specific digestion efficiency we use two differentially-labeled heavy peptides to obtain a ratio for digestion efficiency (scheme 1 ). Peptide three includes the correct sequence context for the target by including four amino acids both amino and carboxyl to the two trypsin cleavage sites that generate the native peptide. In general, three amino acids were considered sufficient for trypsin to identify its cleavage site (Makriyannis T. and Y. Clonis. 1997. Biotech Bioeng. 53:49-57) and hydrolysis rates were only affected by the closest two amino acids (Lowenthal M. et al. 2014. Anal Chem. 86:551-558). This scheme allows us to simultaneously assess specific digestion efficiency and also obtain quantitation data for the target molecule. In this design, the two peptides were spiked at equimolar concentrations into the test sample prior to digestion. During sample analysis, transitions were monitored for the target peptide and the two heavy peptide products. Peak intensities obtained from the two heavy peptides were compared to get a ratio for digestion efficiency and the target peptide intensities were used for quantitation. Scheme 1
Example protein: 03D (Pir)
Sequence:
MASTSAAQDAAPYEFPSLTEIKRALPSECFEASVPLSLYYTARSLALAGSLAVALSYARALPLVQ ANALLDATLCTGYVLLQGIVFWGFFTVGHDCGHGAFSRSHVLNFSVGTLMHSIILTPFESWKLS HRHHHKNTGNIDKDEIFYPQREADSHPVSRHLVMSLGSAWFAYLFAGFPPRTMNHFNPWEAM YVRRVAAVIISLGVLFAFAGLYSYLTFVLGFTTMAIYYFGPLFIFATMLWTTFLHHNDEETPWYA DSEWTYVKGNLSSVDRSYGALIDNLSHNIGTHQIHHLFPIIPHYKLNDATAAFAKAFPELVRKNA APIIPTFFRMAAMYAKYGWDTDAKTFTLKEAKAAAKTKSS
target peptide (underlined), native sequence contained in synthetic peptide for digestion efficiency (redouble underlined)
Peptides
DEIFYPQR (native peptide measured from sample)
DEI FYPQ(15N13CR) (for standard curve, and normalization)
NIDKDEIFY(15N13CP)Q(15N13CR)EADS (for digestion efficiency)
Standard peptides (2) (3) were spiked into the test sample at the same concentration prior to proteolysis. After proteolysis the transitions for the product peptides, (2) and DEIFY(15N13CP)Q(15N13CR) were compared in product ion intensity in order to determine the digestion efficiency of the targeted sequence within the context of its native sequence according to the following equation:
peak intensity DEIFY(15N13CP)Q(15N13CR)
% diqestion efficiency = - — * 100
w " y peak intensity DEIFYPQ(15N13CR)
The % digestion efficiency is therefore measured in the test sample directly and can be used to assess the impact on detected target concentration.
Example 28: Use of different germplasm to optimize production of VLC-PUFA
It appears that expression of the same or very similar gene sets in different host plants, such as Camelina sativa (Ruiz-Lopez et al., 2014), results in a larger yield of VLC-PUFA than has been attainable in Brassica napus. This notion is illustrated by the data in Table 179. Table 179 contains fatty acid data from seeds of transgenic B. napus (LBJ1671 ) and transgenic C. sativa (RRes_EPA_line) transformed with nearly identical T-DNAs and the respective wild type controls. The only difference between the constructs used to make the two transgenic lines is that the TDNA used to make the transgenic B. napus (LBJ1671 ) has an extra GFP expression cassette adjacent to the right border. When comparing transgenic B. napus (LJB1671 ) to the WT Kumily control, there is a decrease in the amount of 18:1 and increases in the amounts of 18:2 and 18:3 fatty acids. The 18:2 and 18:3 fatty acids are intermediates of the pathway introduced by LJB1671 , and therefore the elongation of 18:2 and 18:3 fatty acids into 20C fatty acids can be considered a bottleneck reaction in B. napus. On the other hand, when comparing transgenic C. sativa (RRes_EPA_line) to the WT control, there is a decrease in 18:1 and also in 18:2 and 18:3 fatty acids. Therefore, the elongation of 18:2 and 18:3 fatty acids is not a bottleneck in C. sativa. The absence of this bottleneck in C. sativa results in 10-fold higher 20:5n-3 (EPA) content compared to the transgenic B. napus.
The conversion of 18:1 to 18:2 and of 18:2 to 18:3 occurs largely in the phospholipid membrane, while the elongation of 18C fatty acids to 20C fatty acids occurs strictly in the acyl-CoA pool. This difference in substrate specificity means that 18C fatty acids must be released from membrane phospholipids in order to be elongated. This release is apparently a bottleneck in B. napus, but not in C. sativa. The difference in flux of 18:2 from PC into the CoA pool between these two species could be due to differences in the activities of numerous enzymes, including: 1 ) phospholipases, 2) acyl-CoA synthetases, 3) lyso-PC acyltransferases, 4) phospholipid- diacylglycerol choline transferases, 5) phospholipid-diacylglycerol acyl transferases, and others. As a consequence of these observations, transforming any of the constructs from example 1 1 to example 18 into variety of species and germplasms (such as other Brassica germplasms in the so called Triangle of U), would result in a prefered embodiement of the present invention (e.g. higher amounts of EPA and DHA, and/or lower amounts of 18:2n-6).
Table 179: Introduction of a construct that was isogenic for all genes involved in VLC-PUFA synthesis into Brassica napus cv Kumily and Camelina sa/VVaAverage fatty acid data of segregating T1 seed of 26 events containing the T-DNA of LJB1671 and wild type (WT) Brassica n cv Kumily are shown in the top two rows of data. For line RRes_EPA, fatty acid profiles of T3 homozygous seeds of selected insertion events, of the respective WT control, are shown. RRes_EPA line and WT Camelina sativa data were taken from supplemental table S1 of Ruiz-Lopez e 5 2014. n.d, not determined.

Example 29: Fatty acid analysis of canola oils and commercial oil and solid samples (Total FAME analysis)
Canola seeds:
10-15 canola seeds were transferred into tubes on a 96-format rack and closed with cap strips. Seeds were ground in a swing mill using 3 mm beads for 2 x 2 min at 30 Hz. The rack was then centrifuged for 5 min at 4000 rpm to remove powder from the lid. Extraction of oil was carried out by adding 800 μΙ_ of methyl fe -butyl ether (MTBE) to the samples followed by extraction in a swing mill for 2 x 30 sec at 30 Hz. After centrifugation at 4000 rpm for 10 min, 40 μΙ_ of the clear supernatant was transferred into a 96-well micro rack and diluted using 260 μΙ_ MTBE. Lipids were derivatized into fatty acid methyl esters (FAMEs) by adding 20 μί trimethylsulfonium hydroxide solution (TMSH, 0.2 M in methanol) into each sample. The rack was closed using silicone/PTFE cap mats and incubated for 20 min at room temperature. Arabidopsis seeds:
20 mg of seeds were transferred into tubes on a 96-format rack. The canola seed protocol was followed in all further steps.
Canola oils and commercial oil samples:
20 μί of oil was transferred into a glass vial and diluted using 1 ml. MTBE. 20-80 μΙ_ of the sample- solutions were transferred into into a 96-well micro rack and diluted using 260 μΙ_ MTBE. Lipids were derivatized into FAMEs by adding 20 μί trimethylsulfonium hydroxide solution (TMSH, 0.2 M in methanol) into each sample. The rack was closed using silicone/PTFE cap mats and incubated for 20 min at room temperature.
Commercial solid samples:
Solid samples were lyophilized prior to analysis. 20 mg of solid samples were transferred into tubes on a 96-format rack. The canola seed protocol was followed in all further steps.
An overview on the samples is provided in the following Table.
Table 180: Samples description


GC analysis:
An Agilent 7890A gas chromatograph coupled to Agilent flame ionization detector was used for FAME analysis. Separation of FAMEs was carried out on a DB-225 capillary column (20 m x 180 μηη x 0.2 μηη, Agilent) using h as carrier gas with a flow rate of 0.8ml_/min. The GC was operated in split mode using a split ratio of 1 :50 at an injector temperature of 250 °C, injection
volume was 1 μΙ_. Oven temperature was held at 190 °C for 3 min and increased to 220 °C with 15 °C min-1. Temperature was held at 220 °C for another 6 min. Peak detection and integration was carried out using Agilent GC ChemStation software (Rev. B.04.02 SP1 ).



The commercially available Supelco® 37 Component FAME Mix was used to identify retention times of 22 from 34 target fatty acids, 10 further fatty acids were spiked into the mix or analyzed separately to obtain retention times. For two of the target FAs, no commercial standard was available.
Peak areas of the detected target fatty acids were added up to yield the total peak area. The fatty acid profile and percentage of individual fatty acids was then calculated as peak area percent of total peak area.
The results are shown in the table 182. In all cases, oil data are data from bulk seed collected from field grown plants, rather than from single seed from a greenhouse environment.
20:3 n-6 (DHGLA) ranges from 1 .6-3.1 % in our transgenic canola samples. However, other EPA DHA containing samples, such as transgenic Arabidopsis seeds, fish oil, and algal oil (with more than 1 % combined EPA and DHA), do not contain more than 1.1 % DHGLA. DHGLA is the product of a delta-6-elongase acting on GLA.
20:3 n-9 (Mead acid) ranges from 0.05-0.23% in our transgenic canola. We also observe 20:3 n- 9 in transgenic Arabidopsis and in egg yolk. However, other EPA DHA containing samples, such as fish oil and algal oil (with more than 1 % combined EPA and DHA), do not contain mead acid. Therefore, the accumulation of mead acid does not always accompany EPA DHA production. The production of mead acid is the result of delta-6-desaturase activity on 18:1 n-9, followed by the activities of the delta-6-elongase and delta-5-desaturase, and it is the combined properties of our enzymes that result in the production of mead acid.
22:5 n-3 (DPA) ranges from 1 .9-4.1 % in the transgenic canola samples. The amount of DPA does reach 3.3% in one of the algal oil samples, but transgenic Arabidopsis only accumulates 0.1 % DPA. DPA accumulation is typically below 2% in transgenic camelina and canola engineered to produce EPA and DHA (Petrie et al. 2014 PLoS One 9(1 ) e85061 , and WO 2015/089587). DPA accumulation above 2% is only achieved when the delta-4-desaturase has been inactivated (and
no DHA is produced) in transgenic brassica napus. In the events examined in this example, there are two copies of the delta-4-desaturase, and we produce DHA, so it is surprising that DPA accumulates. The total amount of saturated fatty acids in our transgenic canola is low. 16:0 ranges from 4.4 to 5.2% and 18:0 ranges from 2.5 to 2.7%.
18:4 n-3 (SDA) ranges from 0.1 to 0.4% in the transgenic canola samples. This level of SDA is surprisingly low since our delta-6-desaturase has slightly higher activity with ALA than with LA (Table 163).
There are a variety of VLC-PUFA that occur in the transgenic events that do not occur in WT Kumily plants. These fatty acids include 18:2n-9, GLA, SDA, 20:2n-9, 20:3n-9, 20:3 n-6, 20:4n- 6, 22:2n-6, 22:5n-6, 22:4n-3, 22:5n-3, and 22:6n-3. The combined amount of these fatty acids ranged from 15.1 % to 24.8% in transgenic canola samples.




Example 30: Lipid Profiling of canola oils and commercial oil samples: Canola seeds:
12-15 canola seeds were transferred into micro tubes on a 96-format rack and closed with cap strips. Seeds were ground in a swing mill using 3 mm beads for 2 x 2 min at 30 Hz. The rack was then centrifuged for 5 min at 4000 rpm to remove powder from the lid. Extraction of oil was carried out by adding 800 μΙ_ of dichloromethane/methanol (DCM/MeOH, 2:1 to the samples followed by extraction in a swing mill for 2 x 30 sec at 30 Hz. After centrifugation at 4000 rpm for 10 min, 100 μΙ_ of the clear supernatant was transferred into glass vials and dried to remove the solvent.
Arabidopsis seeds:
20 mg of seeds were transferred into tubes on a 96-format rack. The canola seed protocol was followed in all further steps. Canola oils and commercial oil samples:
200 μΙ_ of oil was transferred into into micro tubes on a 96-format rack and closed with cap strips. Extraction of oil was carried out by adding 800 μΙ_ of dichloromethane/methanol (DCM/MeOH, 2:1 v/v) to the samples followed by extraction in a swing mill for 2 x 30 sec at 30 Hz. After centrifugation at 4000 rpm for 10 min, 100 μΙ_ of the clear supernatant was transferred into glass vials and dried to remove the solvent.
Normal Phase Fractionation:
The dry residues were resuspended in 100 μΙ_ 2,2,4-trimethylpentane and isopropyl alcohol (TMP/IPA (9:1 , v/v)) and vortexed thoroughly. The krill oil sample was further diluted 1 :30 using TMP/IPA. For triacylglycerol (TAG) isolation, the oil samples were resuspended in 500 μΙ_ TMP/IPA prior to fractionation Separation of lipid classes was performed using normal phase HPLC that leads to interaction of lipids and stationary phase based on lipid species (e.g. head group in case of phospholipids) rather than length of fatty acid chain. An Agilent 1200 series HPLC was used that comprised G1322A degasser, G131 1A quaternary pump, G1310A isocratic pump, G1316A thermostatted column compartment (TCC), G1367B HiP autosampler, G1330B FC/ALS Thermostat and G1364 Fraction Collector (all Agilent) coupled to and Alltech 3300 evaporative light scattering detector (ELSD, Grace). A quaternary gradient from TMP, MTBE, acetonitrile (MeCN), DCM, formic acid (FA), ammonium formiate (0.5 M) and water was used for separation of lipid species on a PVA-Sil column (150 mm x 3 mm x 5 μηη, YMC) with an initial flow rate of 0.4 mL/min. The injection volume was 50 μΙ_. Fractions of triacylglycerol (TAG), diacylglycerol (DAG), monoacylglycerol (MAG), phosphatidylcholine (PC), phosphatidylethanolamine (PE) were collected in glass vials. The solvent was removed and the residue was resuspended in 100 μΙ_ toluene. Derivatization of lipid species into FAMEs for subsequent fatty acid profiling was carried out using 20 μΙ_ TMSH. FAME analysis was performed as described previously for Example 29 with an injection volume of 2 μΙ_.
The results are shown in the tables 183 to 187.
Comparing the data in Table 183, 184, and 185, it is evident that the transgenic canola plants have higher percentages of EPA and DHA in DAG compared to TAG or MAG. For LBFLFK oil, the ratio of EPA in DAG to MAG is 1 .6, and in LBFDAU oil the ratio is 1 .5. The fact that DAG has more EPA than MAG and TAG is surprising, especially given previous reports showing that EPA and DHA are less likely to be present in the sn-2 position, at least in camelina (Ruiz-Lopez et al 2013 The Plant Journal 77, 198-208, and Petrie et al 2014 PLoS One 9(1 ) e85061 ). DAG having more EPA DHA than MAG or TAG could be taken to indicate that there is more EPA DHA at the sn-2 position of DAG.
The data in Table 186 and 187 show that PC and PE, respectively, have a higher concentration of DHA than does TAG in transgenic canola. In event LANPMZ there is 8.53% DHA in PC (and 8.5% in PE) compared to just 1 % in TAG, whereas for event LBFLFK there is 3.3% DHA in PC compared to 1.2% in TAG. The more efficient accumulation of DHA in TAG relative to PC in the event LBFLFK compared to LANPMZ could be the result of having one delta-4-desaturase that is phospholipid-dependent (d4Des(Tc)) and one that is CoA-dependent (d4Des(PI)) rather than two phospholipid-dependent enzymes in event LANPMZ.
The data in Tables 183 to 187 also show differences in the ratios between DPA and DHA for the transgenic canola samples. For all transgenic canola samples, there is more DPA than DHA in neutral lipids (MAG, DAG, and TAG), while there is more DHA than DPA in polar lipids (PC and PE).
The data in Tables 183 to 187 show that for transgenic canola samples the ratio of EPA to DHA is higher in neutral lipids (MAG, DAG, and TAG) than the ratio of EPA to DHA in polar lipids (PC, PE). There is more EPA than DHA in neutral lipids, but more DHA than EPA in polar lipids.










Example 31 : Phospholipid species profiling
Diluted extracts from Example 30 were used for phospholipid species analysis PC species profiling
Phosphatidylcholine (PC) species separation was carried out on a 1290 Agilent HPLC coupled to API5500 triple quadrupole MS (ABSciex). HPLC comprised of G4227A Flex Cube, G4226A autosampler, G1330B thermostat and G4220A binary pump. PC species separation was carried out on a Phenomenex Kinetex C8 column (150 mm x 2.1 mm x 1 .7 μηη). The mobile phase consisted of H20/MeOH/sodium acetate (50 mM) as solvent A and MeOH/sodium acetate (50 mM) as solvent B with a flow rate of 0.5 mL/min. The initial conditions were 40% A followed by a linear gradient to 25% A in a total run time of 7 min. MS was operated in positive ESI mode with a source temperature of 550 °C using scheduled multiple reaction monitoring (sMRM) and an injection volume of 1 μί. Data acquisition was carried out using Analyst 1.5.1 whereas data analysis was done in Multiquant 3.0.1 (AB Sciex). All theoretical [M+Na]+ from phosphatidylcholine species containing C14:0, C16:0, C16:1 , C18:0, C18:1 , C18:2, C18:3, C20:3, C20:4, C20:5, C22:5 and C22:6 fatty acids were calculated resulting in a total of 78 PC species. In sMRM-mode, the neutral loss of fatty acids was monitored. MRMs of PC species not present in a representative set of test samples from different canola, fish and algae oil sources were removed from the transition list.
All peak areas of target PC species were added to a total peak area. Species with peak areas lower than 10.000 counts were not included in the calculation as they were considered below limit of quantitation having a poor signal-to-noise ratio. PC species profile was then calculated as PC species percent of total PC species.
LPC species profiling
Lysophosphatidylcholine (LPC) species separation was carried out on a 1290 Agilent HPLC coupled to API5500 triple quadrupole MS (ABSciex). HPLC comprised of G4227A Flex Cube, G4226A autosampler, G1330B thermostat and G4220A binary pump. LPC species separation was carried out on a Phenomenex Kinetex C8 column (150 mm x 2.1 mm x 1.7 μηη). The mobile phase consisted of H20/MeOH/formic as solvent A and MeOH as solvent B with a flow rate of 0.5 mL/min and a linear gradient from 80% A to 0% A over a total run time of 4 min. MS was operated in positive ESI mode with a source temperature of 550 °C using multiple reaction monitoring (MRM) and an injection volume of 1 μί. Data acquisition was carried out using Analyst 1.5.1 whereas data analysis was done in Multiquant 3.0.1 (AB Sciex). All theoretical [M+H]+ from LPC species containing C14:0, C16:0, C16:1 , C18:0, C18:1 , C18:2, C18:3, C20:3, C20:4, C20:5, C22:5 and C22:6 fatty acids were calculated. In sMRM-mode, the neutral loss of fatty acids was monitored.
All peak areas of target LPC species were added to a total peak area. Species with peak areas lower than 12.500 counts were not included in the calculation as they were considered below limit
of quantitation having a poor signal-to-noise ratio. LPC species profile was then calculated as LPC species percent of total LPC species.
PE/LPE species profiling
Phosphatidylethanolamine (PE) and lysophosphatidylethanolamine (LPE) species separation was carried out on a 1290 Agilent HPLC coupled to API5500 triple quadrupole MS (ABSciex). HPLC comprised of G4227A Flex Cube, G4226A autosampler, G1330B thermostat and G4220A binary pump. PE/LPE species separation was carried out on a Phenomenex Kinetex C8 column (150 mm x 2.1 mm x 1.7 μηη). The mobile phase consisted of H20/MeOH/ammonium formate as solvent A and MeOH/ ammonium formate as solvent B with a flow rate of 0.5 mL/min. The initial conditions were 100% A followed by a linear gradient to 0% A over a total run time of 16 min. MS was operated in negative ESI mode with a source temperature of 550 °C using scheduled multiple reaction monitoring (sMRM) and an injection volume of 1 μί. Data acquisition was carried out using Analyst 1.5.1 whereas data analysis was done in Multiquant 3.0.1 (AB Sciex). All theoretical [M-H]- from PE and LPE species containing C14:0, C16:0, C16:1 , C18:0, C18:1 , C18:2, C18:3, C20:3, C20:4, C20:5, C22:5 and C22:6 fatty acids were calculated resulting in a total of 78 PE species and 12 LPE species. MRMs of PE/LPE species not present in a representative set of test samples from different canola, fish and algae oil sources were removed from the transition list.
All peak areas of target PE species and LPE species were added to a total peak area separately. The peak area cut-off for LPE not included into the calculation due to poor signal-to-noise was 2000 counts, for PE it was 5000 counts. PE and LPE species profile were then calculated as PE species percent of total PE species and LPE species percent of total LPE species.
The results are shown in Tables 188 to 191.
Many more phospholipid species were detectable in seed samples than in oil samples. This is probably due to the fact that phospholipids are removed during oil refinement. Tables 186 and 187 showed that for transgenic canola samples PC contains the most DHA of any lipid fraction. For all transgenic canola samples the most abundant PC species containing DHA is PC 18:2 22:6 and the most abundant PC species containing EPA is PC 18:2 20:5 (Table 188). DHA was found in the PC of fish oil and algal oil samples, but only in PC 18:3 22:6. One exception was krill oil, but PC 18:2 22:6 totalled just 0.1 % of PC species. The most abundant PE species containing DHA is PE 18:2 22:6 (Table 190). The PC species that decreased the most in transgenic canola samples was PC 18:1 18:1 , where PC 18:2 18:2 is the species that increased the most. Accordingly, LPC 18:2 is the most abundant lysoPC species in transgenic canola samples.






Table 191 : Lysophosphatidylethanolamine species profile of occurring LPE species comprising 12 target fatty acids from DCM/MeOH (2:1) extr analyzed by -ESI-HPLC-MS/MS in sMRM mode. Data are mean, n=2-3 expressed as relative abundance of species. Species that were not dete in any samples were removed from the table

Z£99/.0/£lOZd3/I3d _.Z££/.0/9lOZ OAV
809
Example 32: TAG species analysis
Diluted extracts from Example 29 were used for TAG (triacylglycerol) species analysis. TAG species analysis was carried out on a 1290 Agilent HPLC coupled to API5500 triple quadrupole MS (ABSciex). HPLC comprised of G4227A Flex Cube, G4226A autosampler, G1330B thermostat and G4220A binary pump. TAG species separation was carried out on a Thermo Accucore C30 column (250 mm x 2.1 mm x 2.6 μηη). The mobile phase consisted of MeCN/lPA as solvent A and IPA as solvent B with a flow rate of 0.4 mL/min. Starting conditions were 100% followed by a linear gradient to 20% A with a total run time of 30 min. The Injection volume was 1 μΙ_. The mass spectrometer was operated in positive APCI mode with ion source temperature of 300 °C using scheduled multiple reaction monitoring (sMRM). Data acquisition was carried out using Analyst 1.5.1 whereas data analysis was done in Multiquant 3.0.1 (AB Sciex). All theoretical [M+H]+ from TAG species containing C14:0, C16:0, C16:1 , C18:0, C18:1 , C18:2, C18:3, C20:3, C20:4, C20:5, C22:5 and C22:6 fatty acids were calculated resulting in a total of 364 TAG species. In MRM-mode, the neutral loss of fatty acids was monitored, therefore all theoretical product ions were calculated as well. The first quadrupole was set to filter only those [M+H]+ of target TAG species that were subsequently fragmented in the second quadrupole which led to the loss of fatty acid. For TAG species containing three different fatty acids, three product ions were monitored in the third quadrupole whereas those species with two different fatty acids led to two product ions. In case of TAG species with only one fatty acid, only one transition could be monitored.
Single and mixed standards of TAGs (16:0/16:0/16:0), (16:1/16:1/16:1 ), (17:0/17:0/17:0), (18:0/18:0/18:0), (18:1/18:1/18:1 ), (18:2/18:2/18:2), (18:3/18:3/18:3), (20:5/20:5/20:5), (22:6/22:6/22:6), (16:0/16:0/18:1 ), (16:0/18:0/18:2), (16:0/18:1/18:1 ), (16:0/18:2/18:2), (18:0/18:0/18:2), (18:0/18:1/18:1 ), (18:0/18:1/18:2), (18:1/18:1/18:3) and (18:1/18:2/18:2) were run to identify retention time patterns among TAG species. MRMs of TAG species not present in a representative set of test samples from different canola, fish and algae oil sources were removed from the transition list. For all other species, a retention time was identified to allow for scheduled monitoring of MRM in a given time window which allows for more data points per transition thus leading to a better quality of data.
Baseline separation of all TAG species could not be achieved within a reasonable runtime, therefore peak heights were used instead of peak areas. The sums of all transitions with were used to calculate a total peak height. Species with peak height lower than 1000 counts were not included in the calculation as they were considered below limit of quantitation having a poor signal-to-noise ratio. TAG species profile was then calculated as TAG species percent of total TAG species. The results are shown in Table 192.
The five most abundant TAG species in Kumily oil are TAG 181 181 183, TAG 181 182 183, TAG 181 181 182, TAG 181 181 181 , and TAG 181 182 182. Together, these account for 64.5% of all TAG species. These species are specifically reduced in the transgenic canola samples, where
there sum total ranges from 14.3 to 21.2%. Instead, the most abundant single TAG species in the transgenic canola lines is TAG 181 182 205, followed by TAG 181 181 205 and TAG 182 182 205. Together, these three species make up 20.6 to 25.5% of the total TAG species observed in transgenic canola samples. The two most abundant DHA containing TAG species in the transgenic canola samples are TAG 181 182 226 and TAG 182 182 226, which together represent from 1 .5 to 3.3% of all TAG species. It is notable that EPA and DHA are found most frequently esterified to TAG together with 18:1 and 18:2. This makeup is likely to be more oxidatively stable that TAG species containing multiple PUFAs. In the transgenic canola samples, the sum of all TAG species with a single EPA, DPA, or DHA is 42.3 to 50.3%, whereas the sum of all TAG species with more than one EPA, DPA, and/or DHA is 3.4 to 6.6%. In fish and algal oils, the sum of all TAG species with more than one EPA, DPA, and/or DHA ranges from 21.1 to 60.3%. Therefore, the transgenic canola samples have the highest proportion of oxidatively stable TAG species. The transgenic canola samples also have a low abundance of TAG 183 183 205 and TAG 183 183 226, with a range of just 0.2 to 0.6% of total TAG species.










Table 193 shows the sequences of the invention by their name, and the associated SEQ-ID number of the sequence lisiting. Further sequences of the present invention are included in the sequence listing.





EXAMPLES (for Section B only)
The following Examples, Examples B1 to B4, are for the invention described in Section B. Example B1 : Construction of BiBAC T-plasmid VC-LTM593-1qcz rc
For synthesis of VLC-PUFA in seeds of Brassica napus events LBFLFK and LBFDAU, the set of genes encoding the proteins of the metabolic VLC-PUFA pathway were combined with expression elements (promoter, terminators and introns) onto a single binary T-plasmid designated VC-LTM593-1 qcz rc (Figure 92). The binary BAC (BiBAC) vector, suitable for transforming large T-DNAs into plants, is described in U.S. Pat. Nos. 5,733,744 and 5,977,439. Synthesis used in the construction of plasmid VC-LTM593-1 qcz rc was performed by Life Technologies using the Geneart® technology described in WO2013049227. Plasmid VC- LTM593-1 qcz rc (SEQ ID NO:279) has a total size of ~61 .000bp, and its structure is given in Table B2, which lists are the names of the elements, the nucleotide position in SEQ ID NO:279 (note: start position is larger than the stop position for elements encoded by the complementary strand of VC-LTM593-1 qcz rc), the function and source of the element. The T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleotides 59895 to 148 of VC-LTM593-1 qcz rc) and a left border (nucleotides 43830 to 43695 of VC-LTM593-1 qcz rc). Elements outside of that region (=vector backbone) are required for cloning and stable maintenance in E. co// and/or agrobacteria.
The genetic elements of VC-LTM593-1 qcz rc and the function of each element are listed in Table B2. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC-LTM593-1 qcz rc that are required for EPA and DHA synthesis are additionally listed Table B3.








Example B2: Production and selection of B. napus events LBFLFK and LBFDAU
The LBFLFK and LBFDAU events were generated using a modified protocol according to DeBlock et al. 1989, Plant Physiology, 91 :694-701 ). The binary vector VC-LTM593-1 qcz rc (SEQ ID NO:279) was transformed into Agrobacterium rhizogenes SWN M (WO2006024509), and co- cultivated with Brassica var. Kumily explants. Imidazolinone-tolerant plants were regenerated from transformed tissue.
Approximately 1543 hemizygous TO transformation events were obtained, 68% of which contained the AHAS imidazolinone resistance selectable marker. In the TO generation 335 events were screened for transgene copy number by qPCR and for EPA/DHA profile. Of these TO events, 275 contained a single copy of VC-LTM593-1 qcz rc, 49 contained two copies, and 1 1 contained three copies of the vector.
In the T1 generation, 57 events were screened for copy number and EPA/DHA profile. Approximately 250 seeds from each event were destructively assayed for copy number at three locations on the T-DNA. The copy number segregation patterns were used to determine the number of T-DNA loci for each event. Both LBFLDK and LBFDAU were determined to have two independent T-DNA loci. A more extensive analysis was performed on additional plants for each event, where each gene in the T-DNA was assayed for copy number. The copy number results suggested that one T-DNA from LBFDAU was missing the genes c-AHAS and j-i-Atss1_c-
d5Elo(Ot_GA3). Event LBFLFK has two full copies of the T-DNA. The results from the T1 generation were compared with the copy number results for the TO generation in order to identify homozygous plants for each event. Homozygous T1 plants from all events were cultivated in the greenhouse and phenotypic observations were recorded including days to first flower, deformed flower rating, deformed leaf rating, deformed plant rating, deformed silique rating, flower color, leaf dentation, leaf color, fertility, number of leaf lobes, plant height. T2 seeds were collected from self-pollinated plants and thousand kernel weight, seed quality, oil content, protein content, and EPA and DHA content were measured (Figure 97 and Figure 98). Events LBFLFK and LBFDAU did not have any significant differences in the aerial phenotypes of T1 plants or a significant impact on total oil or protein accumulation in the T2 seed when compared to the WT Kumily controls. Both LBFDAU and LBFLFK were capable of synthesizing EPA and DHA in their seeds (Figure 97 and Figure 98), as determined by analysis of fatty acid methyl esters by gas chromatography.
Certain events that had higher levels of EPA and DHA in the greenhouse, including LBFLFK and LBFDAU, were cultivated in field trials in USDA growth zone 1 1 during winter 2013 and examined for fatty acid profile, aerial phenotype (if any) and copy number in the T1 generation. There were no phenotypic or copy number abnormalities observed for LBFLFK and LBFDAU. EPA and DHA content in T2 seeds was roughly equal to EPA and DHA production in the greenhouse (Figure 97 and Figure 98). Single T2 seeds from a single plant of event LBFDAU were subjected to fatty acid analysis. The results indicate that there is a wide range of EPA/DHA content in the seeds of a single plants, but that all of the seeds contain at least some EPA and DHA, and some of the single seeds contain more than double the EPA/DHA seen in bulk seed batches (Figure 99).
In the T2 generation, ten events were screened in the greenhouse. For each event, T2 seedbatches of two homozygous T1 plants where selected for seeding. Copy number analysis was performed on each T2 plant and the results confirmed that the T2 seed were indeed homozygous. T2 plants were observed in the greenhouse, and as with T1 plants, there was no significant impact on the phenotype of LBFLFK and LBFDAU T2 plants caused by the presence of the inserted T-DNA. Additional molecular characterization was performed on T2 plants grown in the greenhouse. qPCR and Southern blot analysis were used to confirm the absence of vector backbone. LBFLFK and LBFDAU were found to be free of vector backbone. T3 seed was collected from greenhouse-grown plants and EPA and DHA content were measured (Figure 97 and Figure 98).
Certain T2 events were also cultivated in field trials in USDA growth zones 3a-4b and 5a during the summer of 2014. Phenotypic ratings such as stand count, emergence vigor, days to first flower, days to last flower, days to seed maturity, plant height, lodging, and pod shatter were recorded. Some plants of event LBFLFK were slightly less vigorous and flowered two days later than WT Kumily, but was otherwise indistinguishable. The events grown in the field were also screened for imidazolinone tolerance. Table B4 shows the injury incurred by plants sprayed with imidazolinone herbicide. The events are indicated in the first column. IMI Injury: injury according to the scale detailed in Table B5 (DAT= days after treatment). Herbicide imazamox was applied at a 2x rate of 70 g imazamox /ha. Brassica napus cv Kumily, which is the non-transgenic
comparator line that is otherwise isogenic to the events, was rated at 6 to 7, and was removed from the statistical analysis. ANOVA was conducted using the software JMP 1 1 .0. Analysis was conducted at the 95% confidence level using Tukey test. Common letters between events in Table B4 indicate no significant difference in herbicide tolerance. T3 seeds were harvested from the field and were used for fatty acid analysis. Figure 97 and Figure 98 show that field produced T3 seed from LBFLFK and LBFDAU, respectively, are capable of EPA and DHA synthesis to the same levels observed for GH produced T3 seed.
A selection of events were cultivated in field trials in USDA growth zones 3a-4b and 5a during the summer. Homozygous T4 seeds were sown and the resulting T5 seeds were harvested and subjected to fatty acid analysis. T5 seeds of LBFLFK and LBFDAU maintained the ability to produce EPA and DHA (Figure 97 and Figure 98). Events LBFLFK and LBFDAU were selected based on EPA/DHA profile and imidazolinone tolerance.
Table B4: Herbicide tolerance of LBFLFK and LBFDAU T2 plants cultivated in USDA growth zones 3a-4b and 5a field trials


Example B3: Isolation of genomic flanking sequences from transgenic events
Genomic DNA sequences flanking each T-DNA insertion in events LBFLFK and LBFDAU were determined. Leaf samples from greenhouse grown plants of events LBFLFK and LBFDAU were harvested and frozen. The leaf tissue was ground and genomic DNA was extracted using standard protocols for plant genomic DNA extraction. An aliquot amount of genomic DNA from each event was then used to isolate flanking sequences by adapter ligation-mediated PCR as described in O'Malley et al. 2007 Nature Protocols 2(1 1 ):2910-2917. Using this technique, PCR products were generated that contained sequence of the T-DNA border and adjacent genomic DNA. For each event, four distinct PCR products were obtained corresponding to the left and right border of each T-DNA locus. Individual PCR products were isolated and were sequenced using standard DNA sequencing protocols to determine sequence of the flanking regions. The flanking sequences were used to isolate and sequence the entire T-DNA insert from each locus of events LBFLFK and LBFDAU. A combination of methods known to those skilled in the art, such as long
range PCR and Sanger sequencing, were used for this purpose. Figures 93-96 illustrate the T- DNA structure at each locus of events LBFLFK and LBFDAU.
The flanking sequence that extends into the right border of the T-DNA at Locus 1 in event LBFLFK is SEQ ID NO: 284, where nucleotides 1-570 are genomic DNA (Figure 93). The flanking sequence that extends into the left border of the T-DNA at Locus 1 in event LBFLFK is SEQ ID NO: 285, where nucleotides 229-81 1 are genomic DNA (Figure 93). A 44910 bp contig (SEQ ID NO: 280) was generated by aligning these flanking sequences with the sequence of the entire T- DNA insert at Locus 1 of event LBFLFK.
The flanking sequence that extends into the right border of the T-DNA at Locus 2 in event LBFLFK is SEQ ID NO: 293, where nucleotides 1-2468 are genomic DNA (Figure 94). The flanking sequence that extends into the left border of the T-DNA at Locus 2 in event LBFLFK is SEQ ID NO: 294, where nucleotides 242-1800 are genomic DNA (Figure 94). A 47800 bp contig (SEQ ID NO: 289) was generated by aligning these flanking sequences with the sequence of the entire T-DNA insert at Locus 2 of event LBFLFK (SEQ ID NO: 290).
The flanking sequence that extends into the right border of the T-DNA at Locus 1 in event
LBFDAU is SEQ ID NO: 302, where nucleotides 1 -1017 are genomic DNA (Figure 95). The flanking sequence that extends into the left border of the T-DNA at Locus 1 in event LBFDAU is SEQ ID NO: 303, where nucleotides 637-1677 are genomic DNA (Figure 95). A 45777 bp contig (SEQ ID NO: 299) was generated by aligning these flanking sequences with the sequence of the entire T-DNA insert at Locus 1 of event LBFDAU (SEQ ID NO: 299).
The flanking sequence that extends into the right border of the T-DNA at Locus 2 in event LBFDAU is SEQ ID NO: 31 1 , where nucleotides 1 -1099 are genomic DNA (Figure 96). The flanking sequence that extends into the left border of the T-DNA at Locus 2 in event LBFDAU is SEQ ID NO: 312, where nucleotides 288-1321 are genomic DNA (Figure 96). A 39620 bp contig (SEQ ID NO: 307) was generated by aligning these flanking sequences with the sequence of the entire T-DNA insert at Locus 2 of event LBFDAU (SEQ ID NO: 308).
Each flanking sequence from events LBFLFK and LBFDAU comprises the actual junction of the T-DNA borders with the adjacent genomic DNA. These junction regions can be described with 20bp DNA sequences, where 10bp of DNA corresponds to the right or left border, and the other 10bp corresponds to the adjacent genomic DNA (Table B6).


Example B4: Event-Specific Detection and Zygosity Assays
The flanking sequences isolated in Example B3 (SEQ ID NO: 284 and SEQ ID NO: 285 for LBFLFK Locus 1 , SEQ ID NO: 293 and SEQ ID NO: 294 for LBFLFK Locus 2, SEQ ID NO: 302 and SEQ ID NO: 303 for LBFDAU Locus 1 , and SEQ ID NO: 31 1 and SEQ ID NO: 312 for LBFDAU Locus 2) were used for the design of event specific detection assays to test for the presence of events LBFLFK and LBFDAU. Specific primer pairs are provided in this example, but the disclosed flanking sequences could be used to design different primer pairs for producing diagnostic amplicons for each locus of each event. Any primer pair that can be used to produce an amplicon including at least 1 1 consecutive bp of the junction sequences represented by SEQ ID NO: 282 and SEQ ID NO: 283 for LBFLFK Locus 1 , SEQ ID NO: 291 and SEQ ID NO: 292 for LBFLFK Locus 2, SEQ ID NO: 300 and SEQ ID NO: 301 for LBFDAU Locus 1 , and SEQ ID NO: 309 and SEQ ID NO:310 for LBFDAU Locus 2 can be used for the detection of events LBFLFK or LBFDAU and are within the scope of this invention.
Endpoint Taqman qPCR assays for locus detection were developed and are described in this example. Other methods may be known and used by those skilled in the art for the detection of events LBFLFK and LBFDAU. Oligonucleotide primers used for the assays are listed in Table B7 and endpoint Taqman qPCR assay conditions are provided in Table B8 and Table B9.
Detection of each locus from LBFDAU and LBFLFK requires the use of a specific combination of forward primer, reverse primer, and probe. The TaqMan probes for targets of interest were labeled with FAM/BHQ1. The method described here is optimized for the Quantstudio™ 12K Flex Real- Time PCR system from Life Technologies, although methods can be adapted to other systems with minor modification known to those skilled in the art. Endpoint Taqman qPCR assays were carried out with JumpStart TaqReadyMix (Sigma, P2893) in a 384-well plate (Life technologies, catalogue number 4309849) in a total volume of 10 microliters per well. Per reaction, 2μΙ of template DNA is mixed with 8 microliters of qPCR reaction mixture according to Table B8 below. The plates were sealed with MicroAmp® Optical Adhesive Film (Life Technologies, catalogue number 431 1971 ). The reactions were conducted using the cycling parameters described in Table B9.
Table B7: Primers and Probes for event specific detection using endpoint Taqman qPCR assays.


Table B9. Endpoint Taqman qPCR cycling parameters
The exemplified diagnostic amplicon for LBFLFK Locus 1 contains the junction sequence represented by SEQ ID NO: 283. The exemplified

diagnostic amplicon for LBFLFK Locus 2 contains the junction sequence represented by SEQ ID NO: 292. The exemplified diagnostic amplicon for LBFDAU Locus 1 contains the junction sequence represented by SEQ ID NO: 301. The exemplified diagnostic amplicon for LBFDAU Locus 2 contains the junction sequence represented by SEQ ID NO: 310. In endpoint Taqman qPCR assay, the amplicons are detected by hybridization of the probe with its target amplicon, resulting in the release of a fluorescence signal. The controls for this analysis should include a positive control from a plant known to contain one or more loci of event LBFLFK or event LBFDAU DNA, a negative control from non-transgenic plant and a negative control that contains no template DNA.
Zygosity of transgenic plants can be determined by performing the endpoint Taqman qPCR assays described above concomitantly with PCR reactions that amplify the non-transgenic genomic insertion sites corresponding to each locus of events LBFLFK and LBFDAU. Oligonucleotide primers are listed in Table B10 along with the name of the polymerase and cycling conditions that should be used for each primer pair. PCR reaction components and cycling parameters are listed in Table B1 1 , Table B12, and Table B13. Reactions were optimized to be carried out using either KOD Hot Start Polymerase (EMD Millipore 71086) or Phusion Hot Start DNA Polymerase (New England Biolabs M0535). Reaction volumes were 50 μί and were set up according to Tables B1 1 and B12. Cycling parameters to be used described in Table B13. The name of the cycling condition to use for each primer pair is listed in Table B10. PCR products can be visualized by a variety of methods known to those skilled in the art, such as agarose gel electrophoresis. The expected amplicon size for LBFDAU Locus 1 is about 592 bp. The expected
amplicon size for LBFDAU locus 2 is about 247 bp. The expected amplicon size for LBFLFK locus 1 is about 542 bp. The expected amplicon size for LBFLFK locus 2 is about 712 bp.
Table B10: Primers used for zygosity testing using PCR.


For a given locus, zygosity was determined by comparing the results of endpoint Taqman qPCR reactions using primers in Table B7 with the results of PCR reactions using primers corresponding to the same locus in Table B10. For a given locus, a positive result for the endpoint Taqman qPCR assay combined with a negative result for the PCR indicates a homozygous transgenic plant. A positive result for the endpoint Taqman qPCR assay combined with a positive result for the PCR is indicative of a hemizygous plant for that specific locus. A negative result for the endpoint Taqman qPCR assay combined with a positive result for the PCR is indicative of a plant that is non-transgenic at that locus. Using these methods one can independently determine the zygosity of each T-DNA locus in events LBFLFK and LBFDAU in any plant.
EXAMPLES (for Section C only)
The following Examples, Examples C1 and C2, are for the invention described in Section C.
Example C1 : Materials and Methods
A. General cloning methods
Cloning methods as e.g. use of restriction endonucleases to cut double stranded DNA at specific sites, agarose gel electrophoreses, purification of DNA fragments, transfer of nucleic acids onto nitrocellulose and nylon membranes, joining of DNA-fragments, transformation of E. co/iceWs and culture of bacteria were performed as described in Sambrook et al. (1989) (Cold Spring Harbor Laboratory Press: ISBN 0-87965-309-6). Polymerase chain reaction was performed using Phusion™ High-Fidelity DNA Polymerase (NEB, Frankfurt, Germany) according to the manufacturer's instructions. In general, primers used in PCR were designed such that at least 20 nucleotides of the 3' end of the primer anneal perfectly with the template to amplify. Restriction sites were added by attaching the corresponding nucleotides of the recognition sites to the 5' end of the primer. Fusion PCR, for example described by K. Heckman and L. R. Pease, Nature Protocols (2207) 2, 924-932 was used as an alternative method to join two fragments of interest, e.g. a promoter to a gene or a gene to a terminator. Gene Synthesis, as for example described by Czar et al. (Trends in Biotechnology, 2009, 27(2): 63-72), was performed by Life Technologies using their Geneart® service. The Geneart® technology, described in WO2013049227 allows production of genetic elements of a few basepair (bp) in length, and was used in this invention to produce entire plasmids of about 60,000bp. Chemical synthesis of nucleotides to polynucleotides was employed for short DNA fragments, which were then combined in a sequential, modular fashion to fragments of increasing size using a combination of conventional cloning techniques as described in WO2013049227.
B. Different types of plant transformation plasmids suitable to transfer of multiple expression cassettes encoding multiple proteins into the plant genome.
For agrobacteria based plant transformation, DNA constructs preferably meet a number of criteria: (1 ) The construct carries a number of genetic elements that are intended to be inserted into the plant genome on a so called Transfer DNA (T-DNA) between a T-DNA Left Border' (LB) and T-DNA Right Border' (2) The construct replicates in E.coli, because most cloning steps require DNA multiplication steps in E.coli. (3) The construct replicates in Agrobacterium (e.g. A. tumefaciens or A. rhizogenes), because the plant transformation methods rely on using Agrobacterium to insert the genetic elements of interest into the plant genome of a cell that was infected by Agrobacterium. (4) The construct contains supporting genetic elements that encode proteins which are required for infection of the plant cell, and for transfer and integration of desired genetic elements into the plant genome of an plant cell infected by the Agrobacterium, or the construct was used in combination with a second construct containing such supporting genetic elements that was present in the same Agrobacterium cell. (5) The constructs can contain selection markers to facilitate selection or identification of bacterial cells that contain the entire
construct, and of a plant cell(s) that contains the desired genetic elements. An overview of available plasmids was given in Komori et al (2007).
C. Assembly of genes required for EPA and DHA synthesis within BiBAC T-plasmids containing the F factor / pRI origin of replication
For synthesis of VLC-PUFA in Brassica napus seeds, the set of genes encoding the proteins of the metabolic VLC-PUFA pathway were combined with expression elements (promoter, terminators and introns) and transferred into a binary t-plasmid that was used for agrobacteria mediated transformation of plants. All expression cassettes have been combined onto a single binary T-plasmid. The advance of DNA synthesis allows numerous companies to offer services to use a combination of chemical synthesis and molecular biological techniques to synthesize de novo, without an initial template, polynucleotides up to the size of microbial genomes. Synthesis used in the construction of the plasmid described in this example was performed by Life Technologies using their Geneart® service. The Geneart® technology, described in WO2013049227 allows production of genetic elements of a few basepair (bp) length, and was used in this invention to produce the binary T-plasmid for plant transformation VC-LTM593-1 qcz rc having a total size of -61 .000bp. The structure of the plasmid VC-LTM593-1 qcz rc is given in Table d . Table C1 : Genetic Elements of plasmid VC-LTM593-1qcz rc. Listed are the names of the elements, the position in VC-LTM593-1qcz rc (nucleotide number, note: start position was larger than stop position for elements encoded by the complementary strand of VC-LTM593-1qcz rc), the function and source of the element. The T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleotides 59895 to 148 of VC-LTM593- 1qcz rc) and a left border (nucleotides 43830 to 43695 of VC-LTM593-1qcz rc). Elements outside of that region (=vector backbone) are required for cloning and stable maintenance in E. co/Zand/or agrobacteria. The sequence of this vector is shown in SEQ ID NO: 3. The locations (of the e.g. of promoters, genes, introns, terminators and separators) in SEQ ID NO: 3 are indicted in the second and third column.






D. Procedure for production of transgenic plants using BiBACs
In general, the transgenic rapeseed plants were generated by a modified protocol according to DeBlock et al. 1989, Plant Physiology, 91 :694-701 ). Overnight cultures of the strain intended to be transformed was prepared in YEB medium with antibiotics (20 mg/L chloramphenicol, 5 mg/L tetracycline, 50 mg/L kanamycin) and grown at 28°C. On the next day the optical density of the culture was checked at 600 nm wave length. It reached about 1.0. Cultures of lower optical density were extended in cultivation period. Cultures with an optical density of above 1.3 were diluted with YEB medium to an OD of approximately 0.2 and cultured until they reached an OD of 1.0. Cultures were pelleted at about 4000 g and re-suspended in liquid MS medium (Murashige and Skoog 1962), pH 5.8, 3% sucrose with 100 mg/L Acetosyringone to reach an OD6oonm of 0.1. The Agrobacterium suspensions were used for inoculation of hypocotyl segments prepared from 5 days old etiolated seedlings.
Seeds were germinated for five days under low light conditions (< 50 using MSB5 medium from Duchefa (Duchefa Biochemie, PO Box 809 2003 RV Haarlem, Netherlands), pH 5.8, 3% sucrose and 0.8% Oxoid agar. Germination under light conditions produces explants,
which are more stable and easier to handle compared to etiolated hypocotyls. Hypocotyl segments of 4 to 7 mm length were inoculated in a bath of Agrobacterium cells under gentle shaking up to 4 min and sieved after the incubation. . Infected explants were transferred to petri dishes with co-cultivation medium (MS medium, pH 5.6, 3% sucrose, 0.6 g/L MES (2-(N- Morpholino)ethanesulfonic acid), 18 g/L mannitol, 0.7% phytoagar (Duchefa Biochemie, PO Box 809 2003 RV Haarlem, Netherlands, part number SKU:P1003), 100 mg/L Acetosyringone, 200 mg/L L-Cysteine, 1 mg/L 2,4D (2,4-Dichlorophenoxyacetic acid)) carrying one layer of Whatman filter paper on its surface. Petri dishes were sealed with tape and incubated at 23 C under long day conditions (16 h light/8 h darkness) for three days. After the three days co-cultivation period explants were transferred to MS medium, pH 5.6, 3% sucrose, 0.6 g/L MES, 18 g/L mannitol, 07% Phytoagar, 1 mg/L 2,4D and 500 mg/L Carbenicillin to prevent Agrobacterium growth and incubated for a recovery period under the same physical conditions as for the co-cultivation for 7 days.
For selective regeneration explants were transferred after the recovery period to MS medium, pH 5.8, 3% sucrose, 0.7% Phytoagar, 2.5 mg/L AgN03, 3 mg/L BAP (6-Benzylaminopurine), 0.1 mg/L GA (Gibberellic acid), 0.1 mg/L NAA (1-Naphthaleneacetic acid), 500 mg/L Carbenicillin, 100 nM Imazethapyr (Pursuit) and cultured for two weeks under long day conditions as described above. Sub-cultivation takes place every two weeks. Hormones were stepwise reduced as follows: BAP 3 to 0.5 to 0.05 mg/L; GA (Gibberellic acid) 0.1 to 0.25 to 0.25 mg/L; NAA 0.1 to 0 to 0 mg/L. Developing shootlets could be harvested after the second cycle of selective regeneration. Shootlets were cut and transferred to either Elongation/rooting medium (MS medium, pH 5.8, 2%sucrose, 100 mg/L myo-inositol, 40 mg/L Adenine sulphate, 500 mg/L MES, 0.4% Sigma Agar, 150 mg/L Timentin, 0.1 mg/L IBA (lndole-3-butyric acid)) or to rock wool/stone wool or foam mats (Grodan, GRODAN Group P.O. Box 1 160, 6040 KD Roermond The Netherlands, or Oasis, 919 Marvin Street, Kent, OH 44240 USA) watered with 1/10 Vol. of MS medium, pH 5.8 without sucrose under ex vitro long day conditions in covered boxes.
Shoots were elongated and rooted in in vitro medium and were transferred directly to soil. Either in vitro shoots or GH adapted shoots were sampled for molecular analysis.
Medium were used either autoclaved (except antibiotics, hormones, additives such as L-cysteine, Acetosyringon, imidazolinone components) or filter sterilized prepared (Agar component autoclaved, allowed to cool to 42 C and then used).
E. Seed Germination and Plant Growth in the Greenhouse and Field
Transformed plants were cultivated for seed production and phenotypic assessment in both the greenhouse and in the field. Greenhouse growth conditions were a sixteen hour light period followed by an eight hour dark period. The temperature was 20 degrees celsius during the light period (also called the day period) with a level of light corresponding to 200-300 micromoles of photons m-2 s-1 (this is the incident of light at the top of the plant and lights were adjusted in terms of distance from the plant to achieve this rate). During the day period the range of light in the greenhouse varied between 130 and 500 micromoles of photons m-2 s-1 . Getting out of the
day range just cited triggered either the use of artificial light to bring the level up to 200-300 micromoles of photons m-2 s-1 or shading and/or shut off of lights to bring the level back to 200- 300 micromoles of photons m-2 s-1 . The dark period (also referred to as the night period) temperature was 18 C. Four hours before the light period began the temperature was lowered to 15 C for the remainder of the dark period. Plants were irrigated and treated for insects as necessary. The soil type was 50 % Floradur B Seed + 50 % Floradur B Cutting (including sand and perlite) provided by Floragard (Oldenburg, Germany). Plant growth was enhanced by nutrient supplementation. Nutrients were combined with the daily watering. A 0.1 % (w/v) fertilizer solution (Hakaphos Blue 15(N) -10 (P) - 15(K), Compo GmbH & Co KG, Munster, Germany) was used to water the plants. Water was supplied on demand (e.g. depending on plant growth stage, water consumption etc.). To avoid cross-pollination, plants were bagged at the time when the first flowers opened. Plants were checked daily in order to ensure that all open flowers were covered by the bags. Open flowers that were not covered properly were removed.
For field grown plants, the plants were grown in six locations which correspond climatically to USDA growth zones 3a-4b and 5a.The plants grown in the regions corresponding to USDA growth zones 3a-4b and 5a were grown in the summer. Standard horticultural practices for canola were followed. Netting and other measures to protect from birds and insects were used as deemed necessary by the growers, as were herbicides and fertilizer applications. The planting density for all locations was eighty seeds per square meter.
F. Lipid extraction and lipid analysis of plant oils
The results of genetic modifications in plants or on the production of a desired molecule, e.g. a certain fatty acid, were determined by growing the plant under suitable conditions, e.g. as described above, and analyzing the growth media and/or the cellular components for enhanced production of the desired molecule, e.g. lipids or a certain fatty acid. Lipids were extracted as described in the standard literature including Ullman, Encyclopedia of Industrial Chemistry, Bd. A2, S. 89-90 und S. 443-613, VCH: Weinheim (1985); Fallon, A., et al., (1987) "Applications of HPLC in Biochemistry" in: Laboratory Techniques in Biochemistry and Molecular Biology, Bd. 17; Rehm et al. (1993) Biotechnology, Bd. 3, Kapitel III: "Product recovery and purification", S. 469- 714, VCH: Weinheim; Belter, P.A., et al. (1988) Bioseparations: downstream processing for Biotechnology, John Wiley and Sons; Kennedy, J.F., und Cabral, J. M.S. (1992) Recovery processes for biological Materials, John Wiley and Sons; Shaeiwitz, J.A., und Henry, J.D. (1988) Biochemical Separations, in: Ullmann's Encyclopedia of Industrial Chemistry, Bd. B3; Kapitel 1 1 , S. 1 -27, VCH: Weinheim; and Dechow, F.J. (1989) Separation and purification techniques in biotechnology, Noyes Publications.
It is acknowledged that extraction of lipids and fatty acids can be carried out using other protocols than those cited above, such as described in Cahoon et al. (1999) Proc. Natl. Acad. Sci. USA 96 (22): 12935-12940, and Browse et al. (1986) Analytic Biochemistry 152:141 -145. The protocols used for quantitative and qualitative analysis of lipids or fatty acids are described in Christie, William W., Advances in Lipid Methodology, Ayr/Scotland: Oily Press (Oily Press Lipid Library; 2); Christie, William W., Gas Chromatography and Lipids. A Practical Guide - Ayr, Scotland: Oily
Press, 1989, Repr. 1992, IX, 307 S. (Oily Press Lipid Library; 1 ); "Progress in Lipid Research, Oxford: Pergamon Press, 1 (1952) - 16 (1977) u.d.T.: Progress in the Chemistry of Fats and Other Lipids CODEN. To generate transgenic plants containing the genetic elements described in Example C1 C for production of EPA and DHA in seeds, rapeseed (Brassica napus) was transformed as described in C1 D. Selected plants containing the genetic elements were grown until development of mature seeds under the conditions cited in Example C1 E. Fatty acids from harvested seeds were extracted as described above and analyzed using gas chromatography as described above. The content (levels) of fatty acids is expressed throughout the present invention as percentage (weight of a particular fatty acid) of the (total weight of all fatty acids) contained in the oil of seeds. Seed oil content is expressed throughout the present invention as percentage of (oil weight) of the (total oil weight of seeds). G. Compositional analysis of plant seed samples
The effect of genetic modification on seed composition was determined by growing plants under suitable conditions, e.g. as described above, and analyzing seed tissue for specific compositional parameters. Mature seed samples were milled into fine powder using a Foss Knifetec 1095 Sample Mill and provided to Eurofins Nutrition Analysis Center (ENAC). Specifically, Vitamin E (tocopherol) content was measured by in milled seeds samples by ENAC using methods MET- VT-008 and MET-VT-030, both of which refer to the Association Of Analytical Communities method AOAC 971.30, and involve HPLC separation and quantification.
Example C2: Plants containing the T-DNA of plasmid VC-LTM593-1qcz rc for enhanced production of tocopherol, and EPA and DHA in seeds
All genetic elements described in this example were transferred on a single T-DNA using a BiBAC plasmid into the plant genome. To this end, the plasmid VC-LTM593-1 qcz rc was cloned into agrobacteria, and plant tissue was incubated according to Example C1 with this agrobacterial culture. The genetic elements of VC-LTM593-1 qcz rc and the function of each element are listed in Table C1. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC-LTM593-1 qcz rc are additionally listed Table C2. In an embodiment, the plant, plant part (in particular seed), T-DNA, or construct of the present invention comprises some desaturases and/or elongases, or all desaturases and/or elongases as disclosed in the following Table.

The same T3 seeds described in Table C3 were submitted for compositional analysis as described in Example C1 . To analyze the data, ANOVA was conducted using the software JMP 1 1.0. Analysis was conducted at the 95% confidence level using Tukey test. To compensate for unbalance in the data obtained from the field trial (e.g. due to e.g. weather), Least Square means instead of means where used in the statistical analysis. Common letters in Table C3 indicate no significant difference of the least square means. Based on this statistical analysis, one event, LBFDAU, contains higher gamma tocopherol and total tocopherol than the untransformed Kumily control, while all other events tend to have higher gamma- and total tocopherol levels than Kumily, with the exception of event LBFIHE.
The transgenic events described in Tables C3 and C4 all have decreased 18:1 +18:2 content relative to untransformed Kumily (18:1 +18:2 = 80%). However, we did not observe any significant decrease in alpha-tocopherol content as would have been predicted based on Li et al. (2013) J Agric Food Chem 61:34-40. Instead, we observe increases in gamma-tocopherol and total tocopherol content, with the largest increase occurring in event LBFDAU that produces the most combined EPA+DHA. A correlation analysis was performed to reveal correlations between VLC- PUFA and tocopherols (Table C5). There we no significant correlations between ARA (an n-6 fatty acid) and any tocopherol components. On the other hand, significant positive correlations were observed between various tocopherols and EPA and DHA. Correlations coefficients were determined for the sum of all n-3 or all n-6 fatty acids 20 carbons in length or greater. The correlation between tocopherol of VLC-PUFA content is specific to n-3 fatty acids. The highest correlations were observed between n-3 fatty acids 20 carbon in length or greater and gamma-, delta-, and total tocopherols. Therefore, introduction of a biosynthetic pathway that synthesizes the 20 and 22 carbon n-3 VLC-PUFAs EPA, DPA, and DHA into plants also results in an increase in vitamin E content.

Table C4: Compositional analysis of T3 seeds of T2 plants cultivated in USDA growth zones 3a- 4b and 5a for field trials of canola events containing the T-DNAs of plasmid VC- VC-LTM593- 1qcz rc. The events are indicated in the first column. The analysis has been done on 4 BULK, whereby each BULK is a representative sample of all seeds harvedted from 4 different geographic regions. Alpha-Tocopherol (mg/100g seed), Beta-Tocopherol (mg/100g seed), Delta-Tocopherol (mg/100g seed), Gamma-Tocopherol (mg/100g seed), Total Tocopherol (mg/100g seed). All results have been normalized to the seed weight of seeds having 0% moisture. Values are the least square means. Means that are not sharing a letter are significantly different at the 95% confidence level.

*Controls 1 and 2 are not Kumily backgrounds
Table C5: Pearson correlation coefficients between fatty acids and tocopherols from T3 seeds of T2 plants cultivated in USDA growth zones 3a-4b and 5a for field trials of canola events containing the T-DNAs of plasmid VC- VC-LTM593-1qcz rc. Correlations that are significant are indicated with *** (p<0.05) or with * (p<0.10).


EXAMPLES (for Section D only)
The following Examples, Examples D1 to D6, are for the invention described in Section D. EXAMPLES
Example D1 : Materials and Methods
General Cloning Methods
Cloning methods as e.g. use of restriction endonucleases to cut double stranded DNA at specific sites, agarose gel electrophoreses, purification of DNA fragments, transfer of nucleic acids onto nitrocellulose and nylon membranes, joining of DNA-fragments, transformation of E. co/iceWs and culture of bacteria were performed as described in Sambrook et al. (1989) (Cold Spring Harbor Laboratory Press: ISBN 0-87965-309-6). Polymerase chain reaction was performed using Phusion™ High-Fidelity DNA Polymerase (NEB, Frankfurt, Germany) according to the manufactures instructions. In general, primers used in PCR were designed such, that at least 20 nucleotides of the 3' end of the primer anneal perfectly with the template to amplify. Restriction sites were added by attaching the corresponding nucleotides of the recognition sites to the 5' end of the primer. Fusion PCR, for example described by K. Heckman and L. R. Pease, Nature Protocols (2207) 2, 924-932 was used as an alternative method to join two fragments of interest, e.g. a promoter to a gene or a gene to a terminator. Gene Synthesis, as for example described by Czar et al. (Trends in Biotechnology, 2009, 27(2): 63-72), was performed by Life Technologies using their Geneart® service. The Geneart® technology, described in WO2013049227 allows production of genetic elements of a few basepair (bp) in length, and was used in this invention to produce entire plasmids of about 60,000bp. Chemical synthesis of nucleotides to polynucleotides was employed for short DNA fragments, which were then combined in a sequential, modular fashion to fragments of increasing size using a combination of conventional cloning techniques as described in WO2013049227.
Different types of plant transformation plasmids suitable to transfer of multiple expression cassettes encoding multiple proteins into the plant genome.
For agrobacteria based plant transformation, DNA constructs preferably meet a number of criteria: (1 ) The construct carries a number of genetic elements that are intended to be inserted into the plant genome on a so called Transfer DNA (T-DNA) between a T-DNA Left Border' (LB) and T-DNA Right Border' (2) The construct replicates in E.coli, because most cloning steps require DNA multiplication steps in E.coli. (3) The construct replicates in Agrobacterium (e.g. A. tumefaciens or A. rhizogenes), because the plant transformation methods rely on using Agrobacterium to insert the genetic elements of interest into the plant genome of a cell that was infected by Agrobacterium. (4) The construct contains supporting genetic elements that encode proteins which are required for infection of the plant cell, and for transfer and integration of desired genetic elements into the plant genome of an plant cell infected by the Agrobacterium, or the construct was used in combination with a second construct containing such supporting genetic elements that was present in the same Agrobacterium cell. (5) The constructs can contain
selection markers to facilitate selection or identification of bacterial cells that contain the entire construct, and of a plant cell(s) that contains the desired genetic elements. An overview of available plasmids was given in Komori et al (2007).
Agrobacteria mediated transformation results in an almost random integration (with some bias induced by a number of factors) of the desired genetic element into chromosomes of the plant cell. The goal of the transformation was to integrate the entire T-DNA from T-DNA Left border to T-DNA Right border into a random position of a random chromosome. It can also be desirable to integrate the entire T-DNA twice or three times into the genome, for example to increase the plant expression levels of genes encoded by the T-DNA. To avoid complex Mendelian segregation of multiple integrations, it was preferred to have all T-DNA insertions at one genomic location, ('locus'). Inserting more than 25,000 bp T-DNA into plant genomes has been found to be a particular challenge in the current invention. In particular, it has been found in this invention plasmids carrying a ColE1/pVS1 origin of replication for plasmid replication in E.coii and/or Agrobacterium, are not stable above -25,000 bp. Such plasmids of the invention are described in Example D3. Because of this limitation, not more than ~4 to 5 gene expression cassettes can be transferred on one T-DNA containing plasmid into the plant genome. However, for the current invention up to 13 gene expression cassettes having a combined size of about 44,000 bp needed to be transferred into the plant genome. In contrast to plasmids containing the ColE1/pVS1 origin of replication for high copy plasmid replication in E.coii and/or Agrobacterium, BiBAC plasmids (Hammilton 1997) containing the F factor / pRi origin of replication for single copy plasmid replication in Eco/i and/or Agrobacterium where found to be stable in this invention up to a size of -60,000 bp. Such plasmids of the invention are described in Example D4. Both approaches described above were followed in the current invention. Assembly of genes required for EPA and DHA synthesis within T-plasmids containing the ColE1/pVS1 origin of replication
For synthesis of VLC-PUFA in Brassica napus seeds, the set of genes encoding the proteins of the metabolic VLC-PUFA pathway were combined with expression elements (promoter, terminators, Introns) and transferred into binary t-plasmids that were used for agrobacteria mediated transformation of plants. Attributed to the large number of expression cassettes promoting expression of one protein each, two binary t-plasmids T-DNA where used for cloning of the complete set of proteins required for EPA and DHA synthesis. To this end, the general cloning strategy depicted in Figure 3 was employed. While Figure 3 depicts the general strategy, cloning of the final plant expression vectors described in example 10 to 14 was not restricted to this strategy; specifically a combination of all methods known to one skilled in the art, such as cloning, the use of restriction endonucleases for generation of sticky and blunt ends, synthesis and fusion PCR has been used. Following the modular cloning scheme depicted in Figure 3, genes were either synthesized by GeneArt (Regensburg) or PCR-amplified using Phusion™ High-Fidelity DNA Polymerase (NEB, Frankfurt, Germany) according to the manufactures instructions from cDNA. In both cases an Nco I and/or Asc I restriction site at the 5' terminus, and a Pac \ restriction site at the 3' terminus (Figure 3A) were introduced to enable cloning of these genes between functional elements such as promoters and terminators using these restriction
sites (see below in this example). Promoter-terminator modules or promoter-intron-terminator modules were created by complete synthesis by GeneArt (Regensburg) or by joining the corresponding expression elements using fusion PCR as described in example D1 and cloning the PCR-product into the TOPO-vector pCR2.1 (Invitrogen) according to the manufactures instructions (Figure 3B). While joining terminator sequences to promoter sequences or promoter- intron sequences either via synthesis of whole cassettes or using fusion PCR, recognition sequences for the restriction endonucleases depicted in Figure 3 were added to either side of the modules, and the recognition sites for the restriction endonucleases Nco \, Asc \ and Pac \ were introduced between promoter and terminator or between introns and terminator (see Figure 3B). To obtain the final expression modules, PCR-amplified genes were cloned between promoter and terminator or intron and terminator via Nco I and/or Pac I restriction sites (Figure 3C). Employing the custom multiple cloning site (MCS) up to three of those expression modules were combined as desired to expression cassettes harbored by either one of pENTR/A, pENTR/B or pENTR/C (Figure 3D). Finally, the Multi-site Gateway™ System (Invitrogen) was used to combine three expression cassette harbored by pENTR/A, pENTR/B and pENTR/C (Figure 3E) to obtain the final binary pSUN T-plasmids for plant transformation VC-LJB2197-1 qcz, VC-LJB2755-2qcz rc, VC-LLM306-1 qcz rc, VC-LLM337-1 qcz rc, VC-LLM338-3qcz rc and VC-LLM391 -2qcz rc. An overview of binary vectors and their usage was given by Hellens et al, Trends in Plant Science (2000) 5: 446-451 .
The structure of the plamsids VC-LJB2197-1 qcz, VC-LJB2755-2qcz rc, VC-LLM337-1 qcz rc, and VC-LLM391 -2qcz rc is given in the Table D1 , Table D2, Table D4, and Table D6.
Nomeclature of genetic elements:
j- indicates a junction between two genetic elements
c- coding sequence
t- terminator
p- promotor
i- intron
T-DNA Transferred DNA
RB Right Border of the T-DNA
LB Left Border of the T-DNA



• Table D2: Genetic Elements of plasmid VC-LJB2755-2qcz rc. Listed are the names of the elements, the position in VC-LJB2755-2qc (note: start position was larger than stop position for elements encoded by the complementary strand of VC-LJB2755-2qcz rc), the function source of the element. The T-DNA integrated into the plant genome during the transformation process was flanked by a right border (nucleoti 148 to 4 of VC-LJB2755-2qcz rc) and a left border (nucleotides 261 17 to 25990 of VC-LJB2755-2qcz rc). Elements outside of that region (=ve 5 backbone) are required for cloning and stable maintenance in Eco/Zand/or agrobacteria.



(nucleotides 148 to 4 of VC-LLM337-1qcz rc) and a left border (nucleotides 16953 to 16826 of VC-LLM337-1qcz rc. Elements outside of that re (=vector backbone) are required for cloning and stable maintenance in E.coli &c\6l or agrobacteria.

• ( t ( r


5
10

5





Table D13 compares the order of the gene expression cassettes among all the different constructs and the construct combinations, using short te for these expression cassettes, see Table D12 for definitions. The data in Examples 10 to 19 demonstrate significant differences among the diffe construct or construct combinations in terms of the PUFA profile measured in transgenic seed. The differences between constructs and the const 5 combinations were evident even when eliminating all other sources that affect PUFA levels (e.g. different environments, plant-to-plant variab seed oil content, T-DNA copy number). For example VC-RTP10690-1 qcz_F and VC-LMT593-1 qcz rc are isogenic, i.e. the two constructs contai exactly the same gene expression cassettes. Because of the similarity between RTP10690-1 qcz_F and VC-LMT593-1 qcz one would expect ex the same pathway step conversion efficiencies e.g. when comparing the average conversion efficiencies of all single copy events. However, Fi 39 shows that VC-RTP10690-1 qcz_F had a Delta-4 DESATURASE conversion efficiency of 32%, (average of T1 seeds of 52 single copy TO eve
10 wheras VC-LMT593-1 qcz rc had a Delta-4 DESATURASE conversion efficiency of 47% (average of T1 seeds of 241 single copy TO events). was not expected, and can be explained by transcript levels, which in turn determine protein levels. The transcript levels are affected by the gen elements that flank the Delta-4 DESA TURASE cassettes in VC-LMT593-1 qcz rc. The observations between the two constructs is an unexpe finding and indicates that not only the genome but also the T-DNA itself impacts the Delta-4 DESATURASE conversion efficiency, that was depen on "gene dosage" as described in Example 19. Furthermore, the data in Example 10 to 19 demonstrate that it was possible to insulate expres
15 cassettes from such effects. As can be seen in those Examples 10-19 all single copy events were capable of producing almost exactly the s VLC-PUFA levels when eliminating all other sources that affect PUFA levels (e.g. different environments, plant-to-plant variability, seed oil cont This was particularly striking when comparing all the single copy events in Example 18. Comparing the total C20+C22 VLC-PUFA content, w was largely only controlled by how much was converted by the delta-12 desaturase and by the delta-6 desaturase, it was striking to observe t was virtually no difference between e.g. the single copy event LANPMZ obtained from the contruct combination VC-LJB2197-1 qcz + VC-LLM
20 1 qcz rc, and all single copy events listed in Example 18. To this end, it is important to note that one side of the T-DNA that encodes either the e pathway (Example 15 to 18) or at least the first steps of the pathway up to ARA and EPA production (Example 10 to 14) always contains the A gene which confers herbicide tolerance but was not involved in the VLC-PUFA pathway. The other side of the T-DNA encodes either the e pathway (Example 15 to 18) or at least the first steps of the pathway up to ARA and EPA production (Example 10 to 14) in most cases the De ELONGASE from Physcomitralla patens (except in Example 13 and 14). As described in Example 19, the Delta-6 ELONGASE protein encode
the Physcomitrella patens gene works close to maximum conversion efficiency (>90%), thus any increase in delta-6 elongase enzyme levels du any effect that increases transcript levels will have virtually no effect on the C20 and C22 VLC-PUFA levels. Effectively, the T-DNA determining total level of VLC-PUFA accumulation are flanked on both sides by genes where expression level differences will have no impact on the VLC-P accumulation. As these two genes were encoded by expression cassettes that were several thousand bp in size, it appears the genes inside th 5 DNA were shielded/insulated from any effects the genomic environment could have on the expression level of those genes (e.g. the delta desaturase, compare with Example 19). This effect was consistent with the observation that double copy events differ considerably more in total and C22 VLC-PUFA levels: As in many cases the additional T-DNA insertions are not complete (see Example 10 to 18), resulting in exporsure DNA internal genes are expoed to the genome. When these genes are susceptible to gene-dosage effects (the conversion efficiency of those ge depends on the amount of transcript and the derived amount of enzyme, compare with Example 19), then in some genomic locations the gen 10 envorinment boosted the transcript level.





Procedure for production of transgenic plants using a Co-Transformation approach
In general, the transgenic rapeseed plants were generated by a modified protocol according to DeBlock et al. 1989, Plant Physiology, 91 :694-701 ). For the generation of rapeseed plants transgenic for two different T-DNAs, the binary vectors described in example D3 were transformed into Agrobactenum rhizogenes SHA001 (see WO2006024509 A2 for full description of the Agrobacterium used). For the transformation of rapeseed plants (cv. Kumily), a co-transformation strategy was used. Transformation was performed with two different agrobacteria strains harbouring one of the two different plasmids listed in Table D14 and described in detail in Example D3, Example D4, Example D6 and/or Example 7
• Table D14: Overview of combinations used in Co-transformation Strategy described in Example D3 for generation of plants harboring two different T-DNAs

Cultures were pelleted at about 4000 g and re-suspended in liquid MS medium (Murashige and Skoog 1962), pH 5.8, 3% sucrose with 100 mg/L Acetosyringone to reach an OD6oonm of 0.1 . The Agrobacterium suspensions corresponding to each of the two constructs to be co- transformed were mixed in equal parts and used for inoculation of hypocotyl segments prepared from 5 days old etiolated seedlings.
Germination took place on half concentrated MS medium, pH 5.6 - 5.8, 1 % sucrose, at 23°C in the dark for 5 days. Hypocotyl segments of 4 to 7 mm length were inoculated by dipping. Infected explants were transferred to petri dishes with co-cultivation medium (MS medium, pH 5.6, 3% sucrose, 0.6 g/L MES (2-(N-Morpholino)ethanesulfonic acid), 18 g/L mannitol, 0.7% phytoagar (Duchefa Biochemie, PO Box 809 2003 RV Haarlem, Netherlands, part number SKU:P1003), 100 mg/L Acetosyringone, 200 mg/L L-Cysteine, 1 mg/L 2,4D (2,4-Dichlorophenoxyacetic acid)) carrying one layer of Whatman filter paper on its surface. Petri dishes were sealed with tape and incubated at 23 C under long day conditions (16 h light/8 h darkness) for three days. After the three days co-cultivation period explants were transferred to MS medium, pH 5.6, 3% sucrose, 0.6 g/L MES, 18 g/L mannitol, 07% Phytoagar, 1 mg/L 2,4D and 500 mg/L Carbenicillin to prevent Agrobacterium growth and incubated for a recovery period under the same physical conditions as for the co-cultivation for 7 days.
For selective regeneration explants were transferred after the recovery period to MS medium, pH 5.8, 3% sucrose, 0.7% Phytoagar, 2.5 mg/L AgN03, 3 mg/L BAP (6-Benzylaminopurine), 0.1 mg/L GA (Gibberellic acid), 0.1 mg/L NAA (1-Naphthaleneacetic acid), 500 mg/L Carbenicillin, 100 nM Imazethapyr (Pursuit) and cultured for two weeks under long day conditions as described above. Sub-cultivation takes place every two weeks. Hormones were stepwise reduced as follows: BAP 3 to 0.5 to 0.05 mg/L; GA (Gibberellic acid) 0.1 to 0.25 to 0.25 mg/L; NAA 0.1 to 0 to 0 mg/L. Developing shootlets could be harvested after the second cycle of selective regeneration. Shootlets were cut and transferred to either Elongation/rooting medium (MS medium, pH 5.8, 2%sucrose, 100 mg/L myo-inositol, 40 mg/L Adenine sulphate, 500 mg/L MES, 0.4% Sigma Agar, 150 mg/L Timentin, 0.1 mg/L IBA (lndole-3-butyric acid)) or to rock wool/stone wool or foam mats (Grodan, GRODAN Group P.O. Box 1 160, 6040 KD Roermond The Netherlands, or Oasis, 919 Marvin Street, Kent, OH 44240 USA) watered with 1/10 Vol. of MS medium, pH 5.8 without sucrose under ex vitro long day conditions in covered boxes.
Shoots were elongated and rooted in in vitro medium and were transferred directly to soil. Either in vitro shoots or GH adapted shoots were sampled for molecular analysis.
The following modifications were successfully tested for transformation and were alternatively used to the above described protocol, once they had been worked out.
Seeds were germinated under low light conditions (< 50 μΜοΙΛη^) using MSB5 medium from Duchefa (Duchefa Biochemie, PO Box 809 2003 RV Haarlem, Netherlands), pH 5.8, 3% sucrose and 0.8% Oxoid agar. Germination under light conditions produces explants, which are more stable and easier to handle compared to etiolated hypocotyls.
The inoculation method can vary but the method used in the invention was inoculating explants in a bath of Agrobacterium cells under gentle shaking up to 4 min and sieving the explants after the incubation with shaking. Under this condition the OD6oonm can be reduced up to 0.01 .
Medium were used either autoclaved (except antibiotics, hormones, additives such as L-cysteine, Acetosyringon, imidazolinone components) or filter sterilized prepared (Agar component autoclaved, allowed to cool to 42 C and then used).
Procedure for production of transgenic plants using BiBACs
For BiBAC transformation the same protocol as described for the co-transformation approach was used except that only one construct was used. According to the prokaryotic kanamycin resistance gene of binary plasmid 50 mg/L kanamycin was used instead of Spectinomycin for Agrobacterium growth. It was observed during the course of this work that Agrobacterium carrying BiBACs grow very slowly, often taking 18 hours to reach a liquid culture OD6oonm considered optimal for use in plant transformation.
The table below gives an example for some key data documented during the transformation of the construct LTM593

• Table D15: Statistics of single and double copy events with and without vector backbone in transformation experiments performed with the two BiBAC strains VC-LTM593-1qcz rc and VC-LTM595-1qcz rc

One important key finding for successful transformation was the choice of Agrobacterium strain. While the original method (see De Block et al. (1989) Plant Physiology 91 :694-701 ) used the Agrobacterium tumefaciens strain C58C1 pMP90, the described method was based on the Agrobacterium rhizogenes strain SHA001 (see WO2006024509 A2 for SHA001 and SHA017). Even within Agrobacterium rhizogenes strains we have realized a clear response of transformation success to the strain and construct used (seeTable D16).
• Table D16: Impact of Agrobacterium rhizogenes strains on transformation success of BiBACs


Seed Germination and Plant Growth in the Greenhouse and Field
Transformed plants were cultivated for seed production and phenotypic assessment in both the greenhouse and in the field. Greenhouse growth conditions were a sixteen hour light period followed by an eight hour dark period. The temperature was 20 degrees celsius during the light period (also called the day period) with a level of light corresponding to 200-300 micromoles of photons m-2 s-1 (this is the incident of light at the top of the plant and lights were adjusted in terms of distance from the plant to achieve this rate). During the day period the range of light in the greenhouse varied between 130 and 500 micromoles of photons m-2 s-1 . Getting out of the
day range just cited triggered either the use of artificial light to bring the level up to 200-300 micromoles of photons m-2 s-1 or shading and/or shut off of lights to bring the level back to 200- 300 micromoles of photons m-2 s-1 . The dark period (also referred to as the night period) temperature was 18 C. Four hours before the light period began the temperature was lowered to 15 C for the remainder of the dark period. Plants were irrigated and treated for insects as necessary. The soil type was 50 % Floradur B Seed + 50 % Floradur B Cutting (including sand and perlite) provided by Floragard (Oldenburg, Germany). Plant growth was enhanced by nutrient supplementation. Nutrients were combined with the daily watering. A 0.1 % (w/v) fertilizer solution (Hakaphos Blue 15(N) -10 (P) - 15(K), Compo GmbH & Co KG, Munster, Germany) was used to water the plants. Water was supplied on demand (e.g. depending on plant growth stage, water consumption etc.). To avoid cross-pollination, plants were bagged at the time when the first flowers opened. Plants were checked daily in order to ensure that all open flowers were covered by the bags. Open flowers that were not covered properly were removed.
For field grown plants, the plants were grown in six locations which correspond climatically to USDA growth zones 3a-4b and 5a, and five locations corresponding climatically to USDA growth zones 8a-9b and 1 1. The plants grown in the regions corresponding to USDA growth zones 3a- 4b and 5a were grown in the summer and the plants grown in the regions corresponding to USDA growth zones 8a-9b and 1 1 were grown in the winter. Standard horticultural practices for canola were followed. Netting and other measures to protect from birds and insects were used as deemed necessary by the growers, as were herbicides and fertilizer applications. The planting density for all locations was eighty seeds per square meter with germination rate of 95 or better percent.
In the case where it was necessary to determine germination rates for the purpose of seed quality assurance or control, or where it was advantageous to germinate seeds to obtain cotyledons or seedling tissues, the following protocol was used:
150 mm by 15 mm petri-plates and Whatman (no. 2) filter paper cut into 120 mm disks were used. The filter paper was pre-moistened with sterile deionized water. One hundred seeds of the appropriate line were obtained and spread evenly across the pre-moistened filter paper.
Clean and sterile tweezers were used to spread the seeds to obtain the uniform pattern as shown above. Additional sterile water was added to ensure the seeds and paper were wetted, but not floating (see above image). The total amount of water used per petri-plate was approximately 20 milliliters. Three plates were done for each genotype tested. The plates were sealed with surgical tape, VWR (1050 Satellite Blvd.
Suwanee, GA 30024 USA) catalog number 56222-1 10. After the plates were sealed, they were then incubated in a germination chamber set to 90% humidity, set to a sixteen hour photoperiod with 20 degrees Celsius day temperature and 15 degrees Celsius night temperature. The light intensity was 90-120 micro-moles per square meter per second. Germination was scored twice, once at four days after placing the plates into the growth chamber and again at eight days after incubation.
Lipid extraction and lipid analysis of plant oils
The results of genetic modifications in plants or on the production of a desired molecule, e.g. a certain fatty acid, were determined by growing the plant under suitable conditions, e.g. as described below, and analyzing the growth media and/or the cellular components for enhanced production of the desired molecule, e.g. lipids or a certain fatty acid. Lipids were extracted as described in the standard literature including Ullman, Encyclopedia of Industrial Chemistry, Bd. A2, S. 89-90 und S. 443-613, VCH: Weinheim (1985); Fallon, A., et al., (1987) "Applications of HPLC in Biochemistry" in: Laboratory Techniques in Biochemistry and Molecular Biology, Bd. 17; Rehm et al. (1993) Biotechnology, Bd. 3, Kapitel III: "Product recovery and purification", S. 469- 714, VCH: Weinheim; Belter, P.A., et al. (1988) Bioseparations: downstream processing for Biotechnology, John Wiley and Sons; Kennedy, J.F., und Cabral, J. M.S. (1992) Recovery processes for biological Materials, John Wiley and Sons; Shaeiwitz, J.A., und Henry, J.D. (1988) Biochemical Separations, in: Ullmann's Encyclopedia of Industrial Chemistry, Bd. B3; Kapitel 1 1 , S. 1 -27, VCH: Weinheim; and Dechow, F.J. (1989) Separation and purification techniques in biotechnology, Noyes Publications.
It is acknowledged that extraction of lipids and fatty acids can be carried out using other protocols than those cited above, such as described in Cahoon et al. (1999) Proc. Natl. Acad. Sci. USA 96 (22): 12935-12940, and Browse et al. (1986) Analytic Biochemistry 152:141 -145. The protocols used for quantitative and qualitative analysis of lipids or fatty acids are described in Christie, William W., Advances in Lipid Methodology, Ayr/Scotland: Oily Press (Oily Press Lipid Library; 2); Christie, William W., Gas Chromatography and Lipids. A Practical Guide - Ayr, Scotland: Oily Press, 1989, Repr. 1992, IX, 307 S. (Oily Press Lipid Library; 1 ); "Progress in Lipid Research, Oxford: Pergamon Press, 1 (1952) - 16 (1977) u.d.T.: Progress in the Chemistry of Fats and Other Lipids CODEN.
To generate transgenic plants containing the genetic elements described in examples D3 and D4 for production of EPA and DHA in seeds, rapeseed (Brassica napus) was transformed as described in examples D5 and D6. Selected plants containing the genetic elements described in examples D3 and D4 were grown until development of mature seeds under the conditions cited in Example 7. Fatty acids from harvested seeds were extracted as described above and analyzed using gas chromatography as described above. The content (levels) of fatty acids is expressed throughout the present invention as percentage (weight of a particular fatty acid) of the (total weight of all fatty acids). Seed oil content is expressed throughout the present invention as percentage of (oil weight) of the (total oil weight of seeds).
• Table D18: Fatty acids analyzed using gas chromatography

Non-destructive analysis of lipids in single cotyledons of seedlings Transformation of plants according to the methods described in Example D5 and Example D6 results in a random integration of the T-DNA into the genome. It was known that such integrations can also occur in a partial manner, furthermore multiple integrations of complete and partial T- DNAs can occur. A diploid plant contains one haploid chromosome set inherited from the ovule containing progenitor (for simplicity called the mother or female parent), and one haploid chromosome set inherited from the pollen donating progenitor (for simplicity called the father or male parent). In transformation of the TO plant the T-DNA integrates into random position(s) of
random chromosomes and will result in the maternal chromosome carrying the integration(s), and the corresponding paternal chromosome will not carry this integration, resulting in a seed heterozygous for the integration(s). Growing the TO seed up results in a plant heterozygous for the T-DNA insert(s) and subsequent gametogenesis will result in both pollen and ovules that contain the T-DNA integration and in some pollen and ovules that do not carry the T-DNA insert(s), according to random segregation, as observed by Gregor Mendel (Mendel, 1866). Self pollination of the plant will result in seeds which will be segregating for the T-DNA insertion(s) according to the ratios observed by Gregor Mendel (Mendel, 1866) and which are now part of the basic general knowledge in the life sciences. Due to the Mendelian segregation; for each integration of the T-DNA, one quarter (-25%) of the T1 seed have lost the integration. 50% of the T1 seed will carry the T-DNA integration either on the maternal chromosome (25%), or paternal chromosome (25%); these seeds are 'heterozygous' or 'hemizygous' related to the T-DNA integration. The remaining quarter (-25%) of the T1 seed will carry the T-DNA on the maternal and paternal chromosome; these seeds are 'homozygous' related to the T-DNA integration. For plants that follow such a sexual propagation, it is essential to genetically fix the T-DNA integration(s), by selecting progenies that are homozygous for the T-DNA integration(s); otherwise the T-DNAs insertion(s) and the trait conferred by the T-DNA insertion(s) will continue to segregate and might be lost over a number of generations.
In order to identify T1 seedlings where each T-DNA integration that was essential for the trait was present, ideally homozygous, one can perform quantitative PCR to measure the copy number of the T-DNA integration(s) directly. Alternatively one can analyse the trait conferred by the presence of the T-DNAs, which at least enables the identification of all seeds that do not contain all T-DNA of interest (null-segregants). For all constructs described in Example 10 to Example 14, and where indicated, a non-destructive analysis of VLC-PUFA production was performed. To this end, T1 seeds were germinated in the dark for three days on wet filter paper. After three days, one of the two cotyledons was cut off to subject it to lipid analysis as described in Example 8: Lipid extraction and lipid analysis of plant oils, the other cotyledon, including the hypocotyl and root, was planted in soil. As an example, the result from the lipid content analysis of these cotyledons from segregating T1 seedlings of event LANPMZ obtained from the construct combination described in Example 1 1 are shown in Figure 22; the results of event LBDI HN obtained from the construct combination described in Example 15 are shown in Figure 23. In both of these figures, it is observed that one quarter of the seed produce a significant amount of VLC-PUFA, while producing wildtype levels of Oleic acid. One can furthermore see in both figures two additional clusters of seedlings, see Figure 23. Counting the number of seed in these respective clusters, a 1 :2:1 segregation ratio was observed for the clusters that produce (-0 VLC-PUFA): (medium level of VLC-PUFAs): (high level of VLC-PUFAs). The observations demonstrate a relationship between 'gene dosage', that was the number of T-DNA copies present in the genome, and VLC- PUFA levels. For all constructs described in Example 10 to Example 13, and where indicated, this relationship was exploited to identify T1 plants where at least one T-DNA locus has become homozygous, or where multiple T-DNA integration loci are at least present, or some are homozygous while others still segregate. The applicability of this method can be demonstrated for event LANPMZ, see Figure 22, all T1 seeds of event LANPMZ are capable of producing EPA and DHA. As this requires the presence of both T-DNAs, it can be concluded that at least one
copy of the T-DNA of VC-LJB2197-1 qcz and one copy of the T-DNA of VC-LLM337-1 qcz rc have inserted into the genome, likely at the same locus. 13 T1 seedlings of those 288 seedlings of event LANPMZ having the highest VLC-PUFA levels have been selected and have been grown to mature plants. Copy number analysis on those 13 selected plants shown in Table D40 indicates that both T-DNAs are present in a single copy, and comparison of the TO plant copy number results against the average result of the 13 T1 plants demonstrates that these single T-DNA insertions are homozygous (duplicated copy number). All results combined provide the information that the event LANPMZ contains the T-DNAs of construct VC-LJB2197-1 qcz and the T-DNA of construct VC-LLM337-1 qcz rc in one copy each, whereby both T-DNAs co-segregate in a single locus.
For a single T-DNA integration into the genome, 1 out of 4 T1 seed are expected to be homozygous for that T-DNA integration. For each additional T-DNA integration, just one quarter of all seed homozygous for all other T-DNA integrations are homozygous for the additional T- DNA integration, consequently for two T-DNA integration events into the genome 1 out of 16 T1 seed are expected to be homozygous for both T-DNA integration; for three T-DNA integration into the genome 1 out of 64 T1 seed are expected to be homozygous for all three T-DNA integration; for four T-DNA integration into the genome 1 out of 256 T1 seed are expected to be homozygous for all four T-DNA integration; and so forth. All plants Example 10 to Example 14 contain a minimum of two T-DNA insertion events (one from each plasmid) in order for the plant to contain all the necessary genes to generate all the required enzymes to reconstitute the PUFA pathway sufficiently to generate the VLC-PUFAs: DHA and EPA as well as ARA.
Example D2: Plants containing the T-DNAs of plasmid VC-LJB2197-1 qcz and VC-LLM337-1qcz rc (combination B in example D5) for production of EPA and DHA in seeds
In this example, the genetic elements required for EPA and DHA synthesis were transferred into the plant genome on two different T-DNAs. To this end, the two different plasmids VC-LJB2197- 1 qcz and VC-LLM337-1 qcz rc containing two different T-DNAs were cloned into agrobacteria, and plant tissue was incubated according to Example D5 at the same time with these two agrobacterial cultures that were identical apart from containing either VC-LJB2197-1 qcz or VC- LLM337-1 qcz rc. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of VC-LJB2197-1 qcz. Only those plants were kept, that also contained the T-DNA of plasmid VC-LLM337-1 qcz rc as confirmed by PCR, conducted as described in Example 24, which contains PCR protocols for both gene expression and copy number analysis. Only plants containing the T-DNA of plasmid VC-LJB2197-1 qcz as well as the T-DNA of plasmid VC-LLM337- 1 qcz rc combined all the genetic elements required for EPA and DHA synthesis in seeds. The genetic elements of VC-LJB2197-1 qcz and the function of each element were listed in Table D1. The genetic elements of VC-LLM337-1 qcz rc and the function of each element were listed in Table D4. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC-LJB2197-1 qcz and VC-LLM337-1 qcz rc that were required for EPA and DHA synthesis are additionally listed on Table D35.
• Table D35: Combined list of genes essential of EPA and DHA synthesis carried by the T- DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc.

Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc cultivated in greenhouses during winter
The data on Table D39 indicate that the integration of these two T-DNA's (VC-LJB2197-1 qcz and VC-LLM337-1 qcz rc), has occurred in such a way as to introduce copy number variation of individual genes on a given T-DNA (indicating truncations and deletions along with multiple copies being inserted). For example the event LAMABL on Table D39 was segregating for a single copy of AHAS (homozygous), two copies of j-t-StCAT_p2_p-LuPXR (homozygous), possibly three copies of c-d6Elo(Pp_GA) likely homozygous, though it could be three copies which are not homozygous for all three, and three copies of j-i-Atss18_c-d6Elo(Pp_GA2) (homozygous for all three). Data on Table D42 to Table D45 for fatty acid profile indicates some variation among the events, though not large differences. The highest event average for both DHA and EPA for the events listed on Table D41 was LAMRHL which has DHA of 1 .9 and EPA of 10.5 with respect to percent of the total fatty acid content of the seed and contains what was likely a single copy of the T-DNA of of VC-LJB2197-1 qcz still segregating, while VC-LLM337-1 qcz rc seems to be a
single copy homozygous insertion. The event, LANMGC, with the lowest levels of EPA and DHA combined, contained EPA of 3.7 and 0.8 for DHA with respect to percent of the total fatty acid content of the seed. LANMGC appeared to be homozygous single copy for VC-LJB2197 and carried at least two separate integrations of VC-LLM337. For the highest single plant level of EPA and DHA, event LAMRHL had 5 percent of DHA and 13.7 percent of EPA with respect to percentage of total fatty acids in the seed, Table D43. The data indicate that the location of the insertion site is important for EPA and DHA accumulation in this combination of constructs. As seen in previous examples, comparison of single copy insertions versus double copy insertions revealed that between single copy and double copy containing plants there was an increase in VLC-PUFA levels, but between double and triple copy containing plants there was less distinction. Table D46 displays phenotypic scoring/assessment and shows some small differences in aerial phenotype among events and between the transformed plants and untransformed reference.
• Table D40: Copy number measurement of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids LJB2197-1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where measured event. The T1 plants underwent a selection from 250 segregating T1 seedlings using half-kernel analysis, where the correlation of VCL-PUFA le with copy number was employed to select for homozygous plants, or in the case of multilocus events to selecect for plants where one or more are homozygous. A copy number of ~2 therefore was indicative for one homozygous locus, a copy number of ~4 indicative for two homozygous or indicative for one homozygous locus containing two copies of the target gene measured by the assay, and so forth. Odd results of 3 and 5 indi






• Table D42: Fatty acid profiles of T2 seeds harvested from T1 cultivated in the greenhouse of canola events containing the T-DNAs of plas VC-LJB2197-1qcz and VC-LLM337-1qcz rc The events are indicated in the first column, along with the number of T2 seed batches that measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.











column; as defined in Table D41. The number of T1 plants fullfilling these criteria are displayed in parentheses. Per seed batch a random sele of -30 seed was measured in two technical repeats.

• Table D45: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DN plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc. Plants of all events combined have been grouped into the categories indicated in the column; as defined in Table D41. For each category, the fatty acid profile of the plant having the highest EPA+DHA levels was shown. Per s batch a random selection of -30 seed was measured in two technical repeats.

• Table D46: Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where rated per event. days to first flower (days), DF: deformed flower (9=deformed, 1=normal), DL: deformed leaf (9=deformed, 1=normal), DP: deformed p (9=deformed, 1=normal), DS: deformed silique (9=deformed, 1=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf denta
(3=no dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobe PH: plant height (cm), TKW: thousand kernel weight (g), SC: seed quality (1 =good, 9=bad)





Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc cultivated in greenhouses during summer
Table D48 shows the copy number analysis of select events. The events comprised one to two homozygous insertions and some had additional insertions still segregating. For example LANBCH segregated as homozygous for one T-DNA insertions for each construct, while LANPMZ segregated as homozygous for two T-DNA insertions for each construct. LALXOL seems to segregate for one insertion of VC-LLM337-1 qcz rc, not homozygous, and for one homozygous insertion of LJB2197-1 qcz_F with another copy which was not homozygous with the exception of the region around j-t-StCAT_p2_p-LuPXR, which seems to be a double copy event homozygous for each copy. For the T2 events selected, combined DHA and EPA levels were from nine to thirteen percent of the total fatty acids present in the seed. Whereas the selected T3 events had combined DHA and EPA levels varying from eleven to twenty three percent, with LALWPA having a DHA level of five percent and an EPA level of eighteen percent with respect to total fatty acid content in the seed, see Table D50. The selected events exhibited no morphological or anatomical defects relative to one another or to wild type.








• Table D51 : Phenotypic rating of T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where rated per event. days to first flower (days), DF: deformed flower (9=deformed, 1 =normal), DL: deformed leaf (9=deformed, 1 =normal), DP: deformed p 5 (9=deformed, 1 =normal), DS: deformed silique (9=deformed, 1 =normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf denta (3=no dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobe
PH: plant height (cm), TKW: thousand kernel weight (g), SC: seed quality (1=good, 9=bad), Oil: oil content (% of seed weight), Protein: Pro content (% of seed cake without oil)


Fatty acid profiles of T2 plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc cultivated in field trials in USDA growth zones 3a-4b and 5a during summer.
Field data from the T3 seed indicate that field values are lower for EPA and DHA than what was observed in the greenhouse, with values ranging from six to thirteen percent of the total fatty acid content of the seed for EPA and DHA combined. These data show a difference in seed oil content observed in field studies compared to the greenhouse (e.g. comparing Table D54 with Table D51 ), see also Example 10. Results of this analysis are described in Example 20.
Table D52: Fatty acid profiles of T3 seeds harvested from T2 cultivated in the field in field trials, corresponding to USDA zones 3a-4b and zone of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rcThe events are indicated in the first column, with the number of T3 seed aliquots representing a plot were measured per event. Per seed batch a random selection of ~30 seed was meas in two technical repeats.


the first column. Fatty acid profiles of T3 seed batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random sele of -30 seed was measured in two technical repeats.


Fatty acid profiles copy number measurements, and phenotypic observations of T3 plants carrying T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc cultivated in greenhouses during winter
The data indicate that EPA and DHA are still being synthesized by the plant in the seed/generation.
5

5
10

• Table D58: Phenotypic rating of T3 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where rated per event. days to first flower (days), DF: deformed flower (9=deformed, 1 =normal), DL: deformed leaf (9=deformed, 1 =normal), DP: deformed p (9=deformed, 1 =normal), DS: deformed silique (9=deformed, 1 =normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf denta 5 (3=no dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobe PH: plant height (cm), TKW: thousand kernel weight (g), SC: seed quality (1 =good, 9=bad), Oil: oil content (% of seed weight), Protein: Pro content (% of seed cake without oil)

Fatty acid profiles and phenotypes of T3 plants carrying T-DNAs of plasmids VC- LJB2197-1qcz and VC-LLM337-1qcz rc cultivated in field trials in USDA growth zones 8a-9a during winter
The data indicate that in the field the T4 seed are making EPA and DHA, but at lower levels than seen in the summer field trial (Part D). The greenhouse data show higher oil content compared to the summer field trials (Comparison of Table D61 with Table D54). This data was analyzed in detail in Example 20.
• Table D59: Fatty acid profiles of T4 seeds harvested from T3 plants cultivated in the field in USDA growth zones 8a-9a of canola ev containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc The events are indicated in the first column, along with the nu of T4 seed aliquots representing a plot were measured per event. Per seed batch a random selection of -30 seed was measured in two tech repeats.

• Table D60: Fatty acid profiles of one T4 seed batch per event harvested from T3 plants cultivated in the field in USDA growth zones 8 of canola events containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column. F acid profiles of T4 seed batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed measured in two technical repeats.

• Table D61 : Phenotypic rating of T3 plants cultivated in the field in USDA growth zones 8a-9b of canola events containing the T-DNA plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of field plots that w rated per event. Oil: oil content in T4 seeds harvested from T3 plants (% of seed weight), Protein: Protein content in T4 seeds harvested fro 5 plants (% of seed cake without oil)

Fatty acid profiles and phenotypes of T4 plants carrying T-DNAs of plasmids VC- LJB2197-1qcz and VC-LLM337-1qcz rc cultivated in field trials in USDA growth zones 3a-4b and 5a during summer.
The data indicate that through the T5 generation the transformants are still producing EPA and DHA at a level consistent with the field trial in summer 2012 (described in part D). An additional observation is that the oil levels are comparable between these two field trials.
• Table D62: Fatty acid profiles of T5 seeds harvested from T4 plants cultivated in the filed in USDA growth zones 3a-4b and 5a of ca events containing the T-DNAs of plasmids VC-LJB2197-1qcz and VC-LLM337-1qcz rc The events are indicated in the first column, along with number of T4 seed aliquots representing a plot were measured per event. Per seed batch a random selection of -30 seed was measured in technical repeats.

• Table D63: Fatty acid profiles of one T5 seed batch per event harvested from T3 plants cultivated in the field in USDA growth zones 3 and 5a of canola events containing the T-DNAs of plasmids VC-LJB2197-1 qcz and VC-LLM337-1qcz rc. The events are indicated in the first colu Fatty acid profiles of T5 seed batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 s was measured in two technical repeats.

• Table D64: Phenotypic rating of T4 plants cultivated in the field in USDA growth zones 3a-4b and 5a of canola events containing the T-D of plasmids VC-LJB2197-1 qcz and VC-LLM337-1qcz rc. The events are indicated in the first column, along with the number of field plots that
rated per event. Oil: oil content in T4 seeds harvested from T3 plants (% of seed weight), Protein: Protein content in T4 seeds harvested fro plants (% of seed cake without oil)

Example D3: Plants containing the T-DNAs of plasmid VC-LJB2755-2qcz rc and VC-LLM391- 2qcz rc (combination D in example D5) for production of EPA and DHA in seeds
In this example, the genetic elements required for EPA and DHA synthesis were transferred into the plant genome on two different T-DNAs. To this end, the two different plasmids VC-LJB2755- 2qcz rc and VC-LLM391-2qcz rc containing two different T-DNAs where cloned into agrobacteria, and plant tissue was incubated according to example D5 at the same time with these two agrobacterial cultures that are identical apart from containing either VC-LJB2755-2qcz rc or VC- LLM391-2qcz rc. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of VC-LJB2755-2qcz rc. Only those plants where kept, that also contained the T-DNA of plasmid VC-LLM391 -2qcz rc as confirmed by PCR, conducted as described in example D5. Only plants containing the T-DNA of plasmid VC-LJB2755-2qcz rc as well as the T-DNA of plasmid VC-LLM391-2qcz rc combine all the genetic elements required for EPA and DHA synthesis in seeds. The genetic elements of VC-LJB2755-2qcz rc and the function of each element are listed in Table D2. The genetic elements of VC-LLM391-2qcz rc and the function of each element was listed in Table D6. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc that are required for EPA and DHA synthesis are additionally listed Table D70. · Table D70: Combined list of genes essential of EPA and DHA synthesis carried by the T- DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc.


A. Fatty acid profiles, copy number measurements, and phenotypic observations of T1
plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in greenhouses during winter.
The data on Table D75, Table D76, TableD 77, Table D78, Table D79, Table D80, Table D81 and Table D82 demonstrate that this pair of constructs was successful in recapitulating the pathway to generate VLC-PUFA (C20 and C22, including EPA, DHA and ARA). The copy number for each gene varied from homozygous single insertion of the T-DNA to insertions of parts of the T-DNA's and/or deletions of the T-DNA after insertion into the genome. The fatty acid profile indicated that some events (see Table D78, event LAPCSC) were able to accumulate up to 18 percent EPA and DHA combined). Table D75 indicates that LAPCSC was largely homozygous for a single insertion of each T-DNA with the exception of region of j-p-LuPXR_i-Atss15 on construct VC- LJB2755-2qcz, which contained at least four copies of the regions around that marker. The data presented on Table D81 indicate there was no obvious alteration of the phenotype of the plants bearing T-DNA corresponding to the constructs VC-LJB2755-2qcz and VC-LLM391-2qcz rc.
• Table D75: Copy number measurement of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids LJB2755-2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first column, along with the number of T1 plants that were measured event. The T1 plants underwent a selection from 250 segregating T1 seedlings using half-kernel analysis, where the correlation of VCL-PUFA le with copy number was employed to select for homozygous plants, or on case of multilocus events to selecect for plants where one or more loci homozygous. A copy number of ~2 therefore was indicative for one homozygous locus, a copy number of ~4 indicative for two homozygous lo
indicative for one homozygous locus containing two copies of the target gene measured by the assay, and so forth. Odd results of 3 and 5 indi that at least some of the selected T1 plants carry a heterozygous locus.



• Table D77: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DN plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc The events are indicated in the first column, along with the number of T2 seed batche were measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.





• Table D79: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DN plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. Plants of all events combined have been grouped into the categories indicated in the column; as defined in Table D76. The number of T1 plants fulfilling these criteria are displayed in parentheses. Per seed batch a random sele 5 of -30 seed was measured in two technical repeats.

• Table D80: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-DN plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. Plants of all events combined have been grouped into the categories indicated in the column; as defined in Table D76. For each category, the fatty acid profile of the plant having the highest EPA+DHA levels was shown. Per s batch a random selection of -30 seed was measured in two technical repeats.

• Table D81 : Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first column, along with the number of T1 plants that where rated per event. days to first flower (days), DF: deformed flower (9=deformed, 1 =normal), DL: deformed leaf (9=deformed, 1 =normal), DP: deformed p
(9=deformed, 1 =normal), DS: deformed silique (9=deformed, 1 =normal), FC: flower color (1 =white, 3=optimal, 4=orange/yellow), LD: leaf denta (3=no dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobe
PH: plant height (cm), TKW: thousand kernel weight (g), SC: seed quality (1=good, 9=bad), Oil: oil content (% of seed weight), Protein: Pro content (% of seed cake without oil)

• Table D82: Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 2qcz rc and VC-LLM391-2qcz rc. Plants of all events combined have been grouped into the categories indicated in the first column; as define Table D76. The number of T1 plants fullfilling these criteria are displayed in parentheses. DFF: days to first flower (days), DF: deformed flo (9=deformed, 1=normal), DL: deformed leaf (9=deformed, 1=normal), DP: deformed plant (9=deformed, 1=normal), DS: deformed sili (9=deformed, 1=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3=no dentation, 7=strong dentation), LGC: color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes (#), PH: plant height (cm), TKW: thousand ke weight (g), SC: seed quality (1=good, 9=bad), Oil: oil content (% of seed weight), Protein: Protein content (% of seed cake without oil)

B. Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in greenhouses during summer.
The data in Table D83 indicate the copy number of the selected events was a single insertion which was homozygous in the T3 seed. Fatty acid profile measurements, see Table D84 and Table D85, indicated the combination of T-DNAs from VC-LJB2755-2qcz and VC-LLM391 -2qcz rc are capable of bringing in the VLC-PUFA pathway to successfully accumulate ARA, EPA and DHA. The data on Table D86 show that there was no significant impact on the aerial portion of the plant caused by VC-LJB2755-2qcz and VC-LLM391 -2qcz rc.

5

• Table D86: Phenotypic rating of T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first column, along with the number of T1 plants that where rated per event. Oi content (% of seed weight), protein: Protein content (% of seed cake without oil)

C. Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in field trials in USDA growth zones 3a-4b and 5a during the summer
Field data for the T3 seed from the events carrying the T-DNA from VC-LJB2755-2qcz and VC- LLM391-2qcz rc, shown in Table D87 and Table D88, indicate that the plants are capable of making VLC-PUFAs in the field (ARA, EPA and DHA), though not at the level observed in the greenhouse. However, there was also a difference in seed oil content observed compared to the greenhouse (e.g. comparing Table D89 with Table D86). These observations are in agreement with previous examples where it was observed that increased oil contents in the field grown plants concomitant with a decrease in VLC-PUFAs, in particular EPA, DHA and ARA. A more detailed description of the observations regarding oil content and VLC-PUFAs is given in Example 20.


D. Fatty acid profiles, copy number measurements, and phenotypic observations of T3 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in greenhouses during winter.
T4 seed from T3 plants from the event LAODDN, which was homozygous for T-DNA from both VC-LJB2755-2qcz and VC-LLM391-2qcz rc (see Table D90) accumulated VLC-PUFAs (in particular ARA, EPA and DHA, see Table D91 and Table D92). The combination of EPA and DHA was up to approximately ten percent of the total fatty acid content in the seed for this event.

• Table D92: Fatty acid profiles of one T4 seed batch per event harvested from T3 plants cultivated in the greenhouse of canola ev containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first column. Fatty acid profile T4 seed batches having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in technical repeats.

• Table D93: Phenotypic rating of T3 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LJB2 2qcz rc and VC-LLM391-2qcz rc. The events are indicated in the first column, along with the number of T1 plants that where rated per event. days to first flower (days), DF: deformed flower (9=deformed, 1=normal), DL: deformed leaf (9=deformed, 1=normal), DP: deformed p (9=deformed, 1=normal), DS: deformed silique (9=deformed, 1=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf denta (3=no dentation, 7=strong dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes PH: plant height (cm)

E. Fatty acid profiles, copy number measurements, and phenotypic observations of T3 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in field trials in USDA growth zones 8a-9a in the winter.
Field data for T4 seed of two events carrying homozygous T-DNA insertions from VC-LJB2755- 2qcz and VC-LLM391-2qcz rc (see Table D83 and Table D90 and Table D84, Table D87, Table D91 ) indicate these events do accumulate EPA, DHA and ARA when grown in the greenhouse and field, though as consistently observed, the field grown material did not accumulate the VLC- PUFAs (ARA, EPA, DHA) to the extent observed in the greenhouse (see Table D94 and Table D95 in comparison with Table D91 , Table D92, Table D87 and Table D88). As observed in in Example D1 1 part F, higher oil content was observed compared to the summer field trials (Comparison Table D96 with Table D89). This phenomenon is analyzed in detail in Example D20.
• Table D94: Fatty acid profiles of T4 seeds harvested from T3 cultivated in the field corresponding to USDA growth zones 8a-9a for field t of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc The events are indicated in the first colu along with the number of T4 seed aliquots representing a plot were measured per event. Per seed batch a random selection of -30 seed measured in two technical repeats.

• Table D95: Fatty acid profiles of one T4 seed batch per event harvested from T3 plants cultivated in the field corresponding to USDA gr zones 8a-9a for field trials of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. The events indicated in the first column. Fatty acid profiles of T4 seed batches having the highest EPA+DHA levels per event are shown. Per seed batc random selection of -30 seed was measured in two technical repeats.


F. Fatty acid profiles, copy number measurements, and phenotypic observations of T4 plants carrying T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc cultivated in field trials in USDA zones 3a-4b and 5a during the summer.
The data indicate that through the T5 generation the event LAODDN was still producing EPA and DHA at a level consistent with the field trial (described in part D). Also oil content was comparable between these two field trials.
• Table D97: Fatty acid profiles of T5 seeds harvested from T4 cultivated in the field corresponding to USDA growth zones 3a-3b and 5 field trials of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc The events are indicated in the column, along with the number of T4 seed aliquots representing a plot where measured per event. Per seed batch a random selection of -30 s was measured in two technical repeats.

• Table D98: Fatty acid profiles of one T5 seed batch per event harvested from T4 plants cultivated in the field corresponding to USDA gr zones 3a-3b and 5a for field trials of canola events containing the T-DNAs of plasmids VC-LJB2755-2qcz rc and VC-LLM391-2qcz rc. The ev are indicated in the first column. Fatty acid profiles of T5 seed batches having the highest EPA+DHA levels per event are shown. Per seed batc random selection of -30 seed was measured in two technical repeats.


Example D4: Plants containing the T-DNA of plasmid VC-LTM593-1qcz rc for production of EPA and DHA in seeds
All genetic elements required for EPA and DHA synthesis described in this example, were transferred on a single T-DNA using a BiBAC plasmid into the plant genome. To this end, the plasmid VC-LTM593-1 qcz rc where cloned into agrobacteria, and plant tissue was incubated according to example D6 with this agrobacterial culture. Due to the selectable herbicide resistance marker, regenerated plants contained the T-DNA of VC-LTM593-1 qcz rc . The genetic elements of VC-LTM593-1 qcz rc and the function of each element are listed in Table D1 1. For convenience, all enzymes expressed in seeds of plants carrying both T-DNA of VC-LTM593-1 qcz rc that are required for EPA and DHA synthesis are additionally listed Table D130.
• Table D130: List of genes essential of EPA and DHA synthesis carried by the T-DNA of plasmid VC-LTM593-1qcz rc .

Fatty acid Profile in selected T1 seed batches
A. Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNAs of plasmids VC-LTM593-1qcz rc cultivated in greenhouses during winter
Specific events were examined further for copy number and displayed a variation in insertion number for the T-DNA from single insertion to partial double insertions along with double insertions. Additionally there were some variations in gene copy number (corresponding to the partial insertions and possible deletions), see Table D135, Table D136 and Table D137. The fatty acid profile data shown on Table D138 and Table D139 indicate an upper range of accumulation of combined EPA and DHA of eighteen percent of the total seed fatty acid content (event LBFDAU). In the event LBFDAU the percent of total seed fatty acid content being EPA is 15% and total seed fatty acid content being DHA is 3% in the T1 . LBFDAU was analysed with a copy number indicative of a partial double copy. Another example of specific events having higher levels of EPA and DHA was LBFGKN with approximately 12 percent of the total seed fatty acid content being EPA and DHA, with 10 percent of the total seed fatty acid content being EPA and 2% being DHA. The T1 generation LBFGKN had only a single copy insertion event for VC- LTM593-1 qcz rc, though data on Table D140, Table D141 and Table D142 indicate that double copy double locus events tended to accumulate more EPA and DHA combined than other copy and locus numbers with respect to the T2 seed fatty acid profile. This observation likely reflects the nature of insertion site effects and the various factors that affect the generation of elite events. Table D142 indicates that with respect to the aerial phenotype of the plants there was a range of flowering times, as indicated by DFF (days to the first flower) from 36-48. Event LBFDAU did not vary significantly from the majority of other events with a DFF value of 43, thus showing no significant effect on the aerial phenotype or significant impact on total oil or protein accumulation in the seed in the T1 plant and T2 seed.
• Table D135: Copy number measurement of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids
LTM593-1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where measured per event. The T1 pl underwent a selection from 250 segregating T1 seedlings, using zygocity analysis as illustrated in Table D137, keeping only plants that homozygous for the desired number of loci (which are indicated in the last column of Table D137). A copy number of ~2 therefore was indicativ
5 one homozygous copy, a copy number of ~4 indicative for two homozygous copies (located either at on or at two different loci) and so forth. results of 3, 5, 7, 9 etc indicate that at least some of the selected T1 plants carry at least one heterozygous locus. Homozygocity was indicated i average result of the selected T1 plants was about two fold higher than the the result observed in the TO generation (indicated in parentheses).
some events this was not the case because during selection of T1 plants, undesired loci have been segregated out while retaining only desired in a homozygous state.






• Table D136: Expected Mendelian segregation of the genotype in T1 seeds for some possible T-DNA insertion scenarios. Listed are expected copy number segregation ratios for T1 seeds segregating for one or more unlinked genomic loci, which contain one or more linked co of T-DNA insertions, sc: single copy, dc: double copy

5 · Table D137: Observed Medelian segregation of the genotype of T1 seeds of events from construct VC-LTM593-1qcz rc. The segreg has been analysed at three positions of the T-DNA. For each position, the number of seedlings have been counted that have a copy nu (aritmetically rounded) of 0, 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12. The of seedlings counted for each copy number category are separated by c displaying the categories in the following order: 0 : 1 : 2 : 3 : 4 : 5 : 6 : 7 : 8 : 9 : 10 : 11 : 12. Listed are the observed copy number segregation r for T1 seeds segregating for one or more unlinked genomic loci, which contain one or more linked copies of T-DNA insertions. The obse 10 frequencies for each assay have been compared against expected frequencies for various locus configurations listed in Table D136 using Square analysis. The last column displays the total number of loci that are segregating in the genome of a given event. Many events contain trunc insertions, as was evident when some assays indicate single copy insertion at e.g. the left border (e.g. event LBFDAU, LPFPNC), while o positions on the T-DNA clearly indicate a double copy insertion that was either inserted in one locus (e.g. event LBFPNC), or in two loci (e.g. e LBFDAU)






• Table D138: Fatty acid profiles of T2 seeds harvested from T1 cultivated in the greenhouse of canola events containing the T-DN plasmids VC-LTM593-1qcz rc. The events are indicated in the first column, along with the number of T2 seed batches that were measured per Per seed batch a random selection of -30 seed was measured in two technical repeats.




Table D139: Fatty acid profiles of one T2 seed batch per event harvested from T1 plants cultivated in the greenhouse of canola e containing the T-DNAs of plasmids VC-LTM593-1qcz rc. The events are indicated in the first column. Fatty acid profiles of T2 seed batches h the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in two technical repeats.



• Table D140: Fatty acid profiles of T2 seeds harvested from T1 plants cultivated in the greenhouse of canola events containing the T-D of plasmids VC-LTM593-1qcz rc. Plants of all events combined have been grouped into the categories indicated in the first column; as define Table D131. In addition to those categories, the catergory "dc" was sub-divided into the category dc si: all T1 plants where the average of all number assays listed in Table D135 was 3.51-4.49, and the zygocity analysis listed in Table D137 revelead a single locus insertion of both co 5 and into the category dc dl: all T1 plants where the average of all copy number assays listed in Table D135 was 3.51-4.49, and the zygocity anal

description of Table D140. For each category, the fatty acid profile of the plant having the highest EPA+DHA levels was shown. Per seed bat random selection of -30 seed was measured in two technical repeats.

• Table D142: Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LTM 1qcz rc. The events are indicated in the first column, along with the number of T1 plants that where rated per event. DFF: days to first flower (da DF: deformed flower (1=deformed, 9=normal), DL: deformed leaf (1=deformed, 9=normal), DP: deformed plant (1=deformed, 9=normal), deformed silique (1=deformed, 9=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3=no dentation, 7=str dentation), LGC: leaf color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1=low, 9=very high), Nol: number of lobes (#), PH: plant height (cm), T



• Table D143: Phenotypic rating of T1 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids VC-LTM 1qcz rc. Plants of all events combined have been grouped into the categories indicated in the first column as defined in the description of T D140. The number of T1 plants fullfilling these criteria are displayed in parentheses. DFF: days to first flower (days), DF: deformed flo (1=deformed, 9=normal), DL: deformed leaf (1=deformed, 9=normal), DP: deformed plant (1=deformed, 9=normal), DS: deformed sili (1=deformed, 9=normal), FC: flower color (1=white, 3=optimal, 4=orange/yellow), LD: leaf dentation (3=no dentation, 7=strong dentation), LGC:
color (3=yellow, 5=optimal, 7=blueish), LF: fertility (1 =low, 9=very high), Nol: number of lobes (#), PH: plant height (cm), TKW: thousand ke weight (g), SC: seed quality (1=good, 9=bad), Oil: oil content (% of seed weight), protein: Protein content (% of seed cake without oil)

B. Fatty acid profiles, copy number measurements, and phenotypic observations of T1 plants carrying T-DNAs of plasmids VC-LTM593-1qcz rc cultivated in field trials in USDA growth zone 11 during winter.
Certain events that had higher levels of EPA and DHA were tested in the field and examined for fatty acid profile, aerial phenotype (if any) and copy number in the T1 generation. A variety of constructs were examined including those with partial double copy insertions, single copy insertions and double copy insertions being represented (see Table D144). Table D145 indicates that LBFDAU had an EPA content of ca. 13% and a DHA content of ca. 3% of the total seed fatty acid content, and a maximum content for DHA of 3.6% and EPA of 17% of total seed fatty acids (Table D146). Measurements of single seeds from LBFDAU had as much as 26% EPA and 4.6% DHA, see Table D147. Overall the field performance of LBFDAU matched or exceeded that of the greenhouse.
• Table D144: Copy number measurement of T1 plants cultivated in field, corresponding to USDA growth zone 11, during the winter for trials of canola events containing the T-DNAs of plasmids VC-LTM593-1qcz rc. The events are indicated in the first column, along with the nu of T1 plants that where measured per event. The T1 plants underwent a selection from -80 segregating T1 seedlings, using zygocity analysis si to the selection performed in the greenhouse (which was illustrated in Table D137), keeping only plants that are homozygous for the desired nu of loci. A copy number of -2 therefore was indicative for one homozygous copy, a copy number of -4 indicative for two homozygous copies (loc either at on or at two different loci) and so forth. Odd results of 3, 5, 7, 9 etc indicate that at least some of the selected T1 plants carry at least heterozygous locus. Homozygocity was indicated if the average result of the selected T1 plants was about two fold higher than the the result obe
in the TO generation (indicated in parentheses). For some events this was not the case because during selection of T1 plants, undesired loci h been segregated out while retaining only desired loci in a homozygous state.


• Table D145: Fatty acid profiles of T2 seeds harvested from T1 cultivated in the field, corresponding to USDA growth zone 11, during wi of canola events containing the T-DNAs of plasmids VC-LTM593-1qcz rc. The events are indicated in the first column, along with the number o seed batches that were measured per event. Per seed batch a random selection of -30 seed was measured in two technical repeats.


Table D146: Fatty acid profiles of one T2 seed batch per event harvested from T1 plants cultivated in the field, corresponding to USDA gr 1 1 , during winter of canola events containing the T-DNAs of plasmids VC-LTM593-1qcz rc. The events are indicated in the first column. F

• Table D147: Fatty acid profiles of 95 single seeds of the one seedbatch of event LBFDAU shown in Table D146 having highest EPA+ levels .






C. Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LTM593-1qcz rc cultivated in greenhouses during the summer
The data in Table D148 indicate the copy number of the selected events was a single insertion which was homozygous in the T3 seed. Fatty acid profile measurements, see Table D149 and Table D150, indicated the combination of T-DNA from VC-LTM593-1 qcz rc are capable of bringing in the VLC-PUFA pathway to successfully accumulate ARA, EPA and DHA. The data on Table D151 show that there was no significant impact on the aerial portion of the plant caused by VC-LTM593-1 qcz rc.
• Table D148: Copy number measurement of T2 plants cultivated in the greenhouse of canola events containing the T-DNAs of plasmids LTM593-1qcz rc. The events are indicated in the first column, along with the number of T2 plants that where measured per event. For each ev

PAGE INTENTIONALLY LEFT BLANK




D. Fatty acid profiles, copy number measurements, and phenotypic observations of T2 plants carrying T-DNAs of plasmids VC-LTM593-1qcz rc cultivated in field trials in USDA growth zones 3a-4b and 5a during the summer
Field data for the T3 seed from the events carrying the T-DNA from VC-LTM593-1 qcz rc, shown in Table D152 and Table D153, indicate that the plants are capable of making VLC-PUFAs in the field (ARA, EPA and DHA), though not at the level observed in the greenhouse. ANOVA was conducted with using the software JMP 1 1.0. Analysis was conducted at the 95% confidence level using Tukey test. To compensate for unbalance in the data obtained from the field trial (e.g. due to e.g. weather), Least Square menas instead of means where used in the statistical analysis. Common letters in the Table D154, Table D155and Table D156 indidcate no significant difference of the least square means. Table D154 shows the statistical analysis of agronomical parameters.
There was a difference in seed oil content observed compared to the greenhouse (e.g. comparing Table D154 with Table D151 ), indicating oil content and the fatty acid profile could be linked. These observations are in agreement with previous examples where it was observed that increased oil contents in the field grown plants concomitant with a decrease in VLC-PUFAs, in particular EPA, DHA and ARA. A more detailed description of the observations regarding oil content and VLC-PUFAs is given in Example 20. For seed yield (kg per ha, data not shown), no statisticaly relevant difference was found comparing the events against wildtype Kumily (tested using Tukey, 0.05% level).
• Table D152: Fatty acid profiles of T3 seeds harvested from T2 cultivated in the field, corresponding to USDA growth zones 3a-4b and 5a, for field trials of canola events containing the T-DNAs of plasmid VC-LTM593-1qcz rc. The events are indicated in the first column, along with the number of T3 seed aliquots representing a plot where measured per event. For event LBFGKN, 36 plots and 60 single plants from those plots where measured. Per seed batch a random selection of -15 seed was measured in five technical repeats.

• Table D153: Fatty acid profiles of one T3 seed batch per event harvested from T2 plants cultivated in USDA growth zones 3a-4b and 5a for field trials of canola events containing the T- DNAs of plasmid VC-LTM593-1qcz rc. The events are indicated in the first column. Fatty acid profiles of T3 seed batches representing a field plot having the highest EPA+DHA levels per event are shown. Per seed batch, a random selection of -30 seed was measured in two technical repeats.



• Table D155: Compositional analysis of T3 seeds of T2 plants cultivated in USDA growth zones 3a-4b and 5a for field trials of canola events containing the T-DNAs of plasmid VC- VC- LTM593-1qcz rc. The events are indicated in the first column. The analysis has been done on 4 BULK, whereby each BULK is a representative sample of all seeds harvedted from 4 different geographic reagions. Alpha-Tocopherol (mg/100g seed), Beta-Tocopherol (mg/100g seed), Delta-Tocopherol (mg/100g seed), Gamma-Tocopherol (mg/100g seed), Tocopherol (mg/100g seed), Sinapine ( g/g (ppm)), Phytate (% of seed weight (w/w)), Ash (% of seed weight (w/w)), Crude Fiber (% of seed weight (w/w)), ADF: acid detergent fiber (% of seed weight (w/w)), NDF:
neutral detergent fiber (% of seed weight (w/w)). All results have been normalized to the seed weight of seeds having 0% moisture.


• Table D156: Herbicde tolerance of T2 plants cultivated in USDA growth zones 3a-4b and 5a for field trials of canola events containing the T-DNAs of plasmid VC- VC-LTM593-1qcz rc. The events are indicated in the first column. IMI Injury: injury according to the scale detailed in Table D157 (DAT= days after treatment). Herbicide imazamox was aplied at a 2x rate of 70 g imazamox /ha. Brassica napus cv Kumily, which is the non-transgeneic comparator line that is otherwise isogenic to the events, was rated at 6 to 7, and was removed from the statistical analysis to make the Tukey test more sensitive to detect significant differences between events that are very similar in their tolerance.



It was consistently observed that comparable populations yield higher VLC-PUFA levels in the greenhouse compared to the field. This trend usually coincides with lower oil content in the greenhouse compared to the field. To investigate this observation in more detail, oil content measured in all homozygous seed batches of the single copy event LANPMZ (event described in example 1 1 ) was plotted in Figure 40 against the sum of all VLC-PUFA that are downstream of the delta-12-desaturase {i.e. delta-12-desaturase conversion efficiency, see Figure 2). The same has been done for event LAODDN (event described in example 13), and is plotted Figure 41. This analysis was also done for two events described in example 18, namely for event LBFGKN (Figure 42), and for event LBFLFK (Figure 43). For all transgenic events, a negative correlation was observed between oil content and delta-12-desaturase conversion efficiency. This correlation was consistent across all plants, whether grown in the greenhouse or in the field. The same analysis for wildtype Kumily (Figure 72) revealed no such correlation between delta- 12-desaturase conversion efficiency and seed oil content. In addition, Figure 72 shows a difference between greehouse grown and field grown wildtype plants, in that field grown wildtype plants have higher delta-12-desaturase conversion efficiencies compared to greenhouse grown wildype plants, regardless of oil content. Consequently, comparing Figure 72 with Figure 40 through Figure 43, it can be concluded that the introduction of a transgeneic delta-12-desaturase on a non-native, seed-specific promoter reduced the effect of the environment on delta-12- desaturase conversion efficiency. Surprisingly, this effect is dominant over the endogenous delta- 12-desaturase and results in more consistent VLC-PUFA production across environmental conditions.
Example D6: In vitro demonstration of enzyme activity
Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast
Expression of desaturases and elongases was accomplished in Saccharomyces cerevisiae. Briefly, yeast strains containing the appropriate plasmid were grown overnight at 30 °C (in SD- medium-uracil + raffinose) and then used to inoculate a larger culture at a starting Οϋβοο = 0.2 (in SD-medium-uracil+raffinose+galactose). After 24 hours at 30 °C the culture (typically Οϋβοο = 0.6- 0.8) was harvested by centrifugation and washed once in 25 mM Tris Buffer (pH 7.6). Preparation of crude extracts and microsomes from yeast expressing genes encoding desaturases and elongases was accomplished using standard procedures. Briefly, cells expressing desaturases were resuspended in 2 ml Desaturase Disruption Buffer (0.1 M potassium phosphate pH 7.2, 0.33 M sucrose, 4 mM NADH, 1 mg/ml BSA (fatty acid free), 4000 U/ml catalase and protease inhibitors (Complete EDTA-free (Roche)) and disrupted using silica/zirconium beads in a BeadBeater. The crude extract was clarified by centrifugation twice at 8,000xg, 4 °C). After an additional centrifugation at 100,000xg (30 minutes at 4 °C) the microsomes were pelleted and ultimately resuspended in Desaturase Disruption Buffer (300 microliters). Protein concentrations in both the crude extract and microsomes were measured using the bicinchoninic acid (BCA) procedure (Smith, P. K., et al (1985) Anal. Biochem. (150): 76-85). General Desaturase Activity Assays:
In the desaturase assay a [14C]-labeled acyl-CoA was provided as a substrate and after the reaction the acyl-CoAs (and phospholipids) were hydrolyzed and methylated to fatty acid methyl esters (FAMEs), which were analyzed using argentation-TLC. The general assay conditions were modified from Banas et al. (Banas et al. (1997) Physiology, Biochemistry and Molecular Biology of Plant Lipids (Williams, J. P., Khan, M.U. and Lem, N.W. eds.) pp. 57-59).
The assay contained: 1 mg enzyme (crude extract) or 150 micro-g (microsomal fraction), 10 nmol [14C]-acyl-CoA (3000 dpm/nmol), 7.2 mM NADH (total), 0.36 mg BSA (total) in a buffer comprised of 0.1 M K-phosphate pH 7.2, 0.33 M sucrose, 4 mM NADH, 1 mg/ml BSA and protease inhibitors in a total volume of 200 micro-l. After incubation at 30 °C for the desired time, 200 micro-l of 2 M KOH in MeOH:H20 (1 :4) was added and incubated for 20 minutes at 90 °C. Fatty acids were extracted by addition of 3 M HCI (200 micro-l), 1 .5 ml of MeOH:CHCI3 (2:1 ) and CHCI3 (500 micro- I). The chloroform phase was recovered, dried under N2(g) and fatty acids were methylated by addition of 2 ml MeOH containing 2% H2SO4 and incubation of 30 minutes at 90 °C. FAMEs were extracted by addition of 2 ml H20 and 2 ml hexane and separated by AgNO-3-TLC and Heptane:Diethyl ethenAcetic Acid (70:30:1 ) as a solvent. The radioactive lipids were visualized and quantified by electronic autoradiography using Instant Imager.
Delta-12 desaturase (Phytophthora sojae), c-d12Des(Ps_GA) Enzyme Activity: Enzyme assays were performed using re-suspended microsomes isolated from a yeast strain expressing the c- d12Des(Ps_GA) protein and compared to microsomes isolated from a control yeast strain containing an empty vector (LJB2126). In the presence of [14C]18:1 n-9-CoA, 16:0- lysphosphatidylcholine (LPC), and NADH membranes containing c-d12Des(Ps_GA) form an
[14C]18:2-fatty acid that can be isolated as a methyl ester and resolves on AgN03-TLC [heptane:diethyl ether (90:10)] similar to known synthetic standards. This enzyme activity requires NADH and was not observed in membranes isolated from the empty vector control strain. Control assays without 16:0-LPC contain a small-amount of activity, presumably due to endogenous 16:0- LPC found in yeast microsomes. Furthermore, separation of the phospholipids from the free-fatty acids after the enzymatic reaction and characterization of the isolabled fatty acid methyl esters demonstrated that all of the c-d12Des(Ps_GA) enzymatically produced 18:2n-6-fatty acid methyl ester (FAME) was found in the phosphatidylcholine fraction.
c-d12Des(Ps_GA) enzyme activity may also be demonstrated using other [14C]acyl-CoA's which may include, but are not limited to: [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA.
Delta-6 desaturase {Ostreococcus tauri), c-d6Des(Ot_febit) Enzyme Activity: c-d6Des(Ot_febit) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d6Des(Ot_febit) protein using an [14C]acyl-CoA in the general assay described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9-CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using AgNO-3-TLC and Heptane:Diethyl ether:Acetic Acid (70:30:1 ) as a solvent. Furthermore, the c-d6Des(Ot_febit) enzyme can be shown to directly desaturate an acyl-CoA substrate, as described in "Desaturase Headgroup (CoA vs PC) Preference", as suggested in previous reports (Domergue et al. (2005) Biochem. J. 389: 483-490).
Delta-5 desaturase { Thraustochytrium ssp.), c-d5Des(Tc_GA2) Enzyme Activity: c- d5Des(Tc_GA2) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d5Des(Tc_GA2) protein using an [14C]acyl-CoA general assay as described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n- 9-CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-18) and acetonitrile (100%) as a solvent.
Omega-3 desaturase {Phytophthora infestans), c-o3Des(Pi_GA2) Enzyme Activity: c- o3Des(Pi_GA2) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-o3Des(Pi_GA2) protein using [14C]acyl-CoA in the general assay described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9- CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-18) and acetonitrile (100%) as a solvent. Omega-3 desaturase {Pythium irregulare), c-o3Des(Pir_GA) Enzyme Activity: c-o3Des(Pir_GA) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-o3Des(Pir_GA) protein using an [14C]acyl-CoA in the general assay described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9-CoA,
[14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-18) and acetonitrile (100%) as a solvent. Delta-4 desaturase ( Thraustochytrium ssp.), c-d4Des(Tc_GA) Enzyme Activity: c-d4Des(Tc_GA) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d4Des(Tc_GA) protein using an [14C]acyl-CoA in the general assay described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9-CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-18) and acetonitrile (100%) as a solvent.
Delta-4 desaturase {Paylova lutherl), c-d4Des(PI_GA)2 Enzyme Activity: c-d4Des(PI_GA)2 enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d4Des(PI_GA)2 protein using an [14C]acyl-CoA in the general assay described above. [14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9-CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-.18) and acetonitrile (100%) as a solvent.
Delta-4 desaturase {Euglena gracilis), c-d4Des(Eg) Enzyme Activity: c-d4Des(Eg) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d4Des(Eg) protein using an [14C]acyl-CoA in the general assay described above.
[14C]Acyl-CoA's may include, but are not limited to: [14C]18:1 n-9-CoA, [14C]18:2n-6-CoA, [14C]20:3n-6-CoA, [14C]20:4n-6-CoA, [14C]22:5n-3-CoA. Isolated fatty acid methyl esters derived from enzymatic substrates and products can be resolved using Reverse Phase-TLC (Silica gel 60 RP-18) and acetonitrile (100%) as a solvent.
Desaturase Activity in Microsomes isolated from Transgenic Brassica napus.
Microsomes containing recombinant desaturases and elongases capable of synthesizing docosahexaenoic acid (22:6n-3) were isolated from immature seeds from transgenic B. napus using a procedure adopted from Bafor, M. et al. Biochem J. (1991 ) 280, 507-514. Briefly, immature seeds were first seperated from canola pods and then the developing embryos were isolated from the seed coat and transferred to ice-cold 0.1 M Phosphate buffer (pH 7.2). The developing embryos were then washed with fresh Phosphate buffer, transferred to an ice-cold mortar, and ground to a homogenous solution in Extraction Buffer (0.1 M Phosphate, pH 7.2, 0.33 M sucrose, 1 mg/ml BSA (essentially fatty acid free), 4000U/ml catalase, 4 mM NADH and protease inhibitor-Complete EDTA-free (Roche)). The lysed developing embryo's were diluted 20-fold with additional Extraction Buffer and passed through 2 layers of Miracloth into a centrifuge tube. Following centrifugation at 18,000 x g for 10 minutes at 4 °C, the clarified supernatant was passed through Miracloth into an ultracentrifuge tube. Following centrifugation at 105, 000 xg for 60 minutes at 4 °C, the supernatant was removed from the microsomal pellet, which was then
washed once with Extraction Buffer, and then using a Dounce homogenizer resuspended as a homogenous solution in Extraction Buffer (about 1 ml per 500 embryo's).
Enzyme activity can be demonstrated for the desaturases using the assays described above in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast" for microsomes isolated from yeast expression strains.
In summary in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeasfwe have provided a method that allows unambiguous demonstration of fatty acyl desaturase enzyme activity. We provide data demonstrating that: (1 ) gene c-d12Des(Ps_GA) encodes a delta-12 desaturase protein from Phytophthora sojae (c-d12Des(Ps_GA) that desaturates oleic acid (18:1 n-9) to form linoleic acid (18:2n-6) in both microsomes isolated from a transgenic yeast (Figure 24, panel A) and from a transgenic B. napus event (Figure 25, panel A) expressing this protein, (2) gene c-o3Des(Pi_GA2) encodes a protein from Phytophthora infestans (c- o3Des(Pi_GA2)) that desaturates arachidonic acid (20:4n-6) to form eicosapentaenoic acid (20:5n-3) in microsomes isolated from a transgenic yeast (Figure 24, panel B) expressing this protein, (3) gene c-o3Des(Pir_GA) encodes an omega-3 desaturase protein from Pythium irreguiare (c-o3Des(Pir_GA)) that desaturates arachidonic acid (20:4n-6) to form eicosapentaenoic acid (20:5n-3) in microsomes isolated from a transgenic yeast (Figure 24, panel B) expressing this protein, (4) a transgenic B. napus event containing genes encoding omega-3 desaturase proteins from both Phytophthora infestans (c-o3Des(Pi_GA2)) and Pythium irreguiare (c-o3Des(Pir_GA)) that contains at least one enzyme, localized to the microsomes, capable of desaturating arachidonic acid (20:4n-6) to form eicosapentaenoic acid (20:5n-3) (Figure 85, Panel C), (5) gene c-d4Des(Tc_GA) encodes a delta-4 desaturase protein from Thraustochytrium sp. (c-d4Des(Tc_GA)) that desaturates docosapentaenoic acid (22:5n-3) to form docosahexaenoic acid (22:6n-3) in microsomes isolated from a transgenic yeast (Figure 24, panel C) expressing this protein, (6) gene c-d4Des(PI_GA)2 encodes a delta-4 desaturase protein from Pavlova lutheri (c-d4Des(PI_GA)2 that desaturates docosapentaenoic acid (22:5n-3) to form docosahexaenoic acid (22:6n-3) in microsomes isolated from a transgenic yeast (Figure 24, panel D), (7) a transgenic B. napus event containing both the gene encoding the delta-4 desaturase protein from Thraustochytrium sp, gene c-d4Des(Tc_GA), and the gene c-d4-Des(PI_GA) from Pavlova Luthen contains at least one enzyme, localized to the microsomes, capable of desaturating docosapentaenoic acid (22:5n-3) to form docosahexaenoic acid (22:6n-3) (Figure 25, panel C), (8) a transgenic B. napus event containing the gene encoding a delta-6 desaturase protein from Ostreococcus tauri (c-d6Des(Ot_febit), capable of desaturating linoleic acid (18:2n-6) to form gamma-linolenic acid (18:3n-6) (Figure 85, Panel A), and (9) a transgenic B. napus event containing the gene encoding a delta-5 desaturase protein from Thraustachytrium ssp. (c- d5Des(Tc_GA2), capable of desaturating dihomo-gamma-linolenic acid (20:3n-6) to form arachidonic acid (20:4n-6) (Figure 85, Panel B). Except for the c-d12Des(Ps_GA), which has a known endogenous enzyme in Brassica, all other examples presented contain no detectable endogenous desaturase activity in microsomes isolated from either control yeast strains (Figure 24) or control Brassica lines (Figure 25 and Figure 85).
Using the methods described in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast" for desaturase proteins the level of expression or detected enzyme activity may be influenced by the presence or absence of fusion tags to the native protein. Fusion tags or proteins to the desaturases may be attached the amino-terminus (N-terminal fusions) or the carboxy-terminus (C-terminal fusions) of the protein and may include but are not limited to: FLAG, hexa-Histidine, Maltose Binding Protein, and Chitin Binding Protein.
We have provided methods to establish enzyme catalyzed desaturation reactions required in an engineered pathway to biosynthesize docosohexaenoic acid (DHA, 22:6n-3) from oleic acid (18:1 n-9) in canola. The methods presented in Example 21 , "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast" were developed to demonstrate desaturase activity in yeast strains expressing individual desaturases and can be further used to confirm the respective desaturase enzyme activities in transgenic canola, as described and demonstrated in Example 21 , "Desaturase Activity in Microsomes Isolated from Transgenic Brassica napus!'. Furthermore these methods can be incorporated, by one skilled in the art, to measure desaturase enzyme activities in other organisms including, but not limited to: Saccharomyces cerevisiae, Arabidopsis thaliana, Brassica spp., Camel ina sativa, Carthamus tinctorius, and Salvia hispanica.
Desaturase Headgroup (CoA vs PC) Preference
Fatty acid desaturases catalyze the abstraction of two hydrogen atoms from the hydrocarbon chain of a fatty acid to form a double bond in an unsaturated fatty acid and can be classified according to the backbone that their substrate was connected to: an acyl-CoA, an acyl-ACP (ACP, acyl carrier protein) or an acyl-lipid. To date a few examples exist where the acyl-CoA substrate has been confirmed. These involve purified enzymes and examples include a Linoleoyl- CoA Desaturase (Okayasu et al. (1981 ) Arch. Biochem. Biophys. 206: 21 -28), a stearoyl-CoA desaturase from rat liver (Strittmatter et al (1974) Proc. Nat. Acad. Sci. USA 71 : 4565-4569), and a Stearoyl-ACP desaturase from avocado (Shanklin J and Somerville C (1991 ) Proc Natl Acad Sci USA 88:2510-2514). Alternatively, Heinz and coworkers have reported a strategy employing in vivo feeding of substrates to yeast strains expressing desaturases to examine substrate specificity of desaturases (Domergue et al. (2003) J. Biol. Chem. 278: 351 15-35126 , Domergue et al. (2005) Biochem. J. 389: 483-490). In these studies predictions of a desaturases's preference for acyl- lipid substrates were based on data obtained from a thorough analysis of the desaturated products in the CoA, phospholipid and neutral lipid pools over a growth time course. However, highly active endogenous acyltransferases which transfer acyl-groups between various pools (e.g. CoA, ACP, and lipid) may influence or convolute these data (Domergue et al. (2005) Biochem. J. 389: 483-490, Meesapyodsuk, D., Qui, X. (2012) Lipids 47: 227-237). Therefore this approach was still limited by the absence of direct evidence, such as obtained from in vitro assays, needed for conclusive determination of the substrate backbone utilized by the desaturase of interest.
Herein, we provide a previously unreported method to distinguish between enzymes that desaturate acyl-CoA fatty acids from enzymes that desaturate phospholipid linked fatty acids using microsomal preparations of proteins. We have improved upon initial reports of strategies to generate [14C]-phosphatidylcholine analogs in situ (Stymne, S., and Stobart, A. K. (1986) Biochem. J. 240: 385-393, Griffiths, G., Stobart, A. K., and Stymne, S. (1988) Biochem. J. 252: 641 -647) by: (1 ) monitoring the initial acyl-transfer reaction catalyzed by lysophosphatidyl choline acyl transferase (LPCAT) to establish that all of the [14C]-acyl-CoA has been consumed, and (2) including exogenous lysophosphatidyl choline (LPC). Our improvements therefore establish that only [14C]-phosphatidylcholine analogs are present upon initiation of the desaturase assay and allow for testing of other phospholipids by adding their corresponding lysolipid. Furthermore, the assays testing for desaturation of acyl-phospholipid substrates, described in Demonstration of Phosphatidylcholine Specificity, can be complemented by testing in an assay developed to monitor desaturation of the substrate in the acyl-CoA form. Specifically, we have devised a strategy, described in Demonstration of acyl-CoA Specificity, in which the substrate to be tested remains in its acyl-CoA form and is not incorporated into phospholipids (e.g. phosphatidylcholine) by lysophosphatidyl choline acyl transferase (LPCAT). By comparing the relative desaturase activity, observed in assays where the substrate is in the acyl-phospholipid form compared to the acyl-CoA form, the actual backbone (e.g. phosphatidylcholine or CoA) covalently bound to the desaturated fatty acid product can be determined.
Demonstration of Phosphatidylcholine Specificity:
To test if a desaturase accepts an acyl-lipid (e.g. a phospholipid) substrate the enzyme reaction was performed as described above " "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast", but after a pre-incubation in the presence of exogenous lysophosphatidyl choline (LPC). The microsomal fraction of the yeast strain expressing the enzyme of interest was pre-incubated with a [14C]-labelled acyl-CoA substrate in the presence of 16:0-lysophosphatidyl choline, which was typically 50 micro-M but may vary from 0 - 500 micro-M. During the preincubation endogenous lysophosphatidyl choline acyl transferase (LPCAT), present in the microsomes, transfers the [14C]fatty acid from CoA to 16:0-LPC generating, in situ, a [14C]fatty acid-phosphatidylcholine (PC) (Jain et al. (2007) J. Biol. Chem. 282:30562-30569, Riekhof et al. (2007) J. Biol. Chem. 282:36853-36861 , Tamaki et al. (2007) J. Biol. Chem. 282:34288-34298)). After a pre-incubation (typically 15 minutes, but may vary from 1 - 300 minutes) essentially all of the [14C]-labelled acyl-CoA substrate was consumed, as measured by scintillation counting and TLC analysis of the aqueous phase.
The reaction was stopped and lipids were extracted using the method of Bligh and Dyer (Bligh, E. G., and Dyer, J. J. (1959) Can J. Biochem. Physiol. 37: 91 1 -918), by addition of 200 micro-l 0.15 M acetic acid and 1 ml MeOH:CHCI3 (1 :1 ). Part (about 10%) of the CHCI3 phase (containing phosphatidyl choline (PC) and free fatty acids (FFA's)) was analyzed by scintillation counting and the rest was applied to a silica thin layer chromatography (TLC) plate. The plate was first developed in a polar solvent [CHCl3:MeOH:acetic acid (90:15:10:3) and then in Heptane:diethylether:acetic acid (70:30:1 ) to measure incorporation into PC and the amount of FFA's (likely generated by thioesterases). PC and FFA's were scraped off the plate and
methylated by addition of MeOH containing 2% H2SO4 at 90 °C for 30 minutes. The methyl esters were extracted in hexane and analyzed as described above for the respective enzymes (Example 21 , "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast"). The upper (aqueous) phase of the reaction mixture extraction contains acyl-CoA's and was hydrolyzed by addition of an equal volume of 2 M KOH in MeOH:H20 (1 :4) and incubated for 20 minutes at 90 °C. Part of the aqueous phase was then analyzed by scintillation counting before fatty acids were extracted by addition of 3 M HCI (0.7 ml), 1.4 ml of MeOH) and CHCI3 (1.9 ml). The chloroform phase was recovered, dried under N2(g) and fatty acids were methylated by addition of 2 ml MeOH containing 2% H2SO4 and incubation of 30 minutes at 90 °C. FAMEs were extracted by addition of 2 ml H2O and 2 ml hexane and separated by AgN03-TLC and Heptane:Diethyl ether:acetic acid (70:30:1 ) as a solvent or Reverse Phase-TLC (Silica gel 60 RP-18 using acetonitrile (100%)). The radioactive lipids were visualized and quantified by electronic autoradiography using Instant Imager. Delta-12 desaturase {Phytophthora sojae), c-d12Des(Ps_GA) Substrate Preference: The c- d12Des(Ps_GA) enzyme activity demonstrated in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeasfcan be further characterized to establish the backbone of the oleic acid substrate. In the desaturase assay described in "Desaturase Headgroup (CoA vs PC) Preference" containing 16:0-lysphosphatidylcholine (LPC) substantial desaturation was observed. A significantly reduced, but detectable, desaturase activity was observed in control reactions lacking 16:0-LPC which likely results from acylation of endogenous LPC present in the yeast microsomes containing the d12Des(Ps_GA) protein. However, a preincubation with 20:1 n- 9-CoA results in PC saturated with 20:1 n-9, thus precluding incorporation of [14C]-18:1 n-9 into PC (described in "Demonstration of Acyl-CoA Specificity"). Additionally, separation of the phospholipids from the free-fatty acids after the enzymatic reaction and characterization of the isolable fatty acid methyl esters demonstrated that all of the d12Des(Ps_GA) enzymatically produced 18:2n-6-fatty acid methyl ester (FAME) was found in the phosphatidylcholine fraction (Figure 26, Panel A and Figure 86, Panel A). Furthermore, the d12Des(Ps_GA) activity was negligible in the assay for demonstration of acyl-CoA specificity (Figure 86, Panel B), showing that 18:1 n-9-acyl-CoA is not a preferred substrate for the delta-12 desaturase {Phytophthora sojae). In conclusion, delta-12 desaturase {Phytophthora sojae) clearly desaturates 18:1 n-9 covalently bound to PC, but not an 18:1 n-9-acyl CoA substrate.
Delta-4 desaturase { Thraustochytrium ssp.), c-d4Des(Tc_GA) Substrate Preference: The c- d4Des(Tc_GA) enzyme activity demonstrated in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeasfcan be further characterized to establish the backbone of the docosopentaenoic acid substrate. In the desaturase assay described in "Desaturase Headgroup (CoA vs PC) Preference" without additional 16:0-lysphosphatidylcholine (LPC), desaturation was observed (Figure 26, Panel B), and likely results from the presence of endogenous 16:0-LPC present in the membranes containing the c-d4Des(Tc_GA) protein. The c-d4Des(Tc_GA) desaturase activity was dramatically stimulated by including additional 16:0-LPC in the assay (Figure 26, Panel B), consistent with the observation endogenous lysophosphatidyl choline acyl transferase (LPCAT), present in the microsomes, transfers the [14C]22:5n-3 from CoA to 16:0-
LPC generating a [14C]22:5n-3-phosphatidylcholine (PC) that was desaturated. Additionally, separation of the phospholipids from the free-fatty acids after the enzymatic reaction and characterization of the isolable fatty acid methyl esters demonstrated that essentially all of the c- d4Des(Tc_GA) enzymatically produced 22:6n-3-fatty acid methyl ester (FAME) was found in the phosphatidylcholine fraction (Figure 26, Panel B and Panel C).
Demonstration of Acyl-CoA Specificity:
The assay conditions were as described above in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast". The microsomal fraction of the yeast strain expressing the enzyme of interest was pre-incubated with 10 nmol 20:1 n-9-CoA (50 μΜ) and 0.5 mM DTNB (5,5'- dithiobis-(2-nitrobenzoic acid) for 10 min before addition of NADH and [14C]labelled acyl-CoA substrate. The preincubation with 20:1 n-9-CoA minimizes the incorporation of [14C]labelled substrate into PC. DTNB prevents the reverse reaction of LPCAT and thereby the entering of acyl-CoA into PC via acyl exchange. This assay may also include alternative acyl-CoA's such as: 18:1 n-9-CoA, 18:2n-6-CoA, 20:3n-6-CoA, 20:4n-6-CoA, 22:5n-3-CoA. The reaction was stopped and lipids were extracted using the method of Bligh and Dyer (Bligh, E. G., and Dyer, J. J. (1959) Can J. Biochem. Physiol. 37, 91 1-918), by addition of 200 micro-l 0.15 M acetic acid and 1 ml MeOH:CHCI3 (1 :1 ). Part (about 10%) of the CHCI3 phase (containing phosphatidyl choline (PC) and free fatty acids (FFA's)) was analyzed by scintillation counting and the rest was applied to a silica thin layer chromatography (TLC) plate. The plate was first developed in a polar solvent [CHCI3:MeOH:acetic acid (90:15:10:3) and then in Heptane:diethylether:acetic acid (70:30:1 ) to measure incorporation into PC and the amount of FFA's (likely generated by thioesterases). PC and FFA's were scraped off the plate and methylated by addition of MeOH containing 2% H2SO4 at 90 °C for 30 minutes. The methyl esters were extracted in hexane and analyzed as described above for the respective enzymes "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast". The upper (aqueous) phase of the reaction mixture extraction contains acyl- CoA's and was hydrolyzed by addition of an equal volume of 2 M KOH in MeOH:H20 (1 :4) and incubated for 20 minutes at 90 °C. Fatty acids were extracted by addition of 3 M HCI (0.7 ml), 1 .4 ml of MeOHand CHCI3 (1 .9 ml). The chloroform phase was recovered, dried under N2(g) and fatty acids were methylated by addition of 2 ml MeOH containing 2% H2SO4 and incubation of 30 minutes at 90 °C. FAMEs were extracted by addition of 2 ml H2O and 2 ml hexane and separated by AgNO-3-TLC and Heptane:Diethyl ether:acetic acid (70:30:1 ) as a solvent or Reverse Phase- TLC (Silica gel 60 RP-18 using acetonitrile (100%)). The radioactive lipids were visualized and quantified by electronic autoradiography using Instant Imager.
To demonstrate acyl-CoA dependency both methods are tested. If desaturation does not occur in the method for determining PC-specificity (LPC addition and preincubation before adding NADH) and the method for determining acyl-CoA specificity (20:1 -CoA and DTNB addition) leads to the desaturated product in the H20-phase (or product in any of the lipid pools PC/FFA/H2O since PC-dependent enzymes cannot be active if the substrate is not incorporated into PC (see Figure 86, Panel B), it can be concluded that the enzyme was acyl-CoA dependent (see Figure 27 and Figure 87, Panels A and B). Similarly if a desaturase demonstrates activity in the PC- specific assay, but not in the assay where the substrate is presented as an acyl-CoA, then it can
be concluded the enzyme utilizes a fatty acid covalently attached to phosphatidylcholine as a substrate.
Delta-9 desaturase {Saccharomyces cerevisiae), d9Des(Sc) Substrate Preference:
Analysis of the [14C]-distribution during of the d9Des(Sc) reaction, in the assay for demonstration of acyl-CoA dependency, shows that greater than 95% of the radioactivity (substrate and product) is present in the H2O (CoA) and FFA-pools (data not shown), indicating incorporation into PC was insignificant. During the reaction, product (16:1 n-9) in the acyl-CoA pool increases linearly up to 60 minutes, showing that the enzyme preferentially converts 16:0 covalently bound to CoA (Figure 87, Panel B). The amount of 16:1 n-9 in the H2O fraction then levels out or slightly decreases, while the 16:1 n-9 in the FFA pool increases, due to degradation of acyl-CoA by thioesterases present in the isolated membranes.
In the assay for demonstrating PC specificity, the d9Des(Sc) showed no activity (Figure 87, Panel A), which indicates that when 16:0 fatty acid is attached to PC (or a FFA) it is not a preferred substrate.
The clear presence of desaturase activity in the "Acyl-CoA Specific" assay compared to the absence of activity in the "Phosphatidylcholine Specific" assay demonstrates that the delta-9 desaturase {Saccharomyces cerevisiae) utilizes 16:0 covalently attached to Coenzyme A. Interestingly, recent crystal structures of both the human and mouse stearoyl-coenzyme A desaturases have been reported with bound stearoyl-CoA confirming that this desaturase utilizes a coenzyme A substrate (Wang et al (2015) Nat Struct Mol Bio 22: 581 -585 and Bai et al (2015) Nature 524: 252-257).
In summary, we presented a previously unreported method to distinguish between enzymes that desaturate acyl-CoA fatty acids from enzymes that desaturate phospholipid linked fatty acids. This embodment of the invention t uses microsomal preparations of enzymes and does not, as in previous examples, require purification of the enzyme of interest. Furthermore, this embodiment allows isolation of the intact desaturated enzymatic product, allowing characterization of the backbone to which it was linked (e.g. lipid-, CoA-, or free fatty acid). An important consideration was that the endogenous lysophosphatidyl choline acyl transferase (LPCAT) present in yeast- derived microsomes can utilize a broad range of acyl-CoA's (Jain et al. (2007) J. Biol. Chem. 282:30562-30569, Riekhof et al. (2007) J. Biol. Chem. 282:36853-36861 , Tamaki et al. (2007) J. Biol. Chem. 282:34288-34298)) making it suitable for generating an extensive variety of different phosphatidylcholine derivatives for assaying desaturase enzymes. LPCAT is able to accept 18:1 n-9-CoA and 20:4n-6-CoA and this enzyme can acylate LPC with 22:5n-3-CoA.. Microsomes isolated from any cells or tissue can be used in this embodiment of the invention, including but not limited to bacterial cells (e.g. Escherichia coil, Psuedomonas aeruginosa, Bacillus thuringiensis), mammalian tissue (e.g. liver) and plant tissue (e.g. leafs, roots, seeds, and pods) and could use exogenously supplied lysophosphatidyl choline acyl transferase from Saccharomyces cerevisiae, if necessary. Slight modifications to the general method presented here may include a pre-incubation with alternate acyl-CoA's, not the potential desaturase
substrate, which could reduce the observed background due to endogenous LPC present in the membranes and also minimize thioesterase degradation of enzyme substrate or product acyl- CoA's.
Elongase Activity.
Expression of elongase enzymes in yeast was performed as described above for the desaturase enzymes in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast". Isolation of microsomes containing expressed elongases was generally as described above in "Desaturase Enzyme Activity in Microsomes Isolated from Transgenic Yeast" and by Denic (Denic, V. and Weissman (2007) Cell 130, 663-677). Briefly, cells from a yeast expression culture (50 ml) were resuspended in 1 ml of Elongase Disruption Buffer (20 mM Tris-HCI, pH 7.9, 10 mM MgC , 1 mM EDTA, 5% glycerol, 0.3 M ammonium sulfate, protease inhibitor), mixed with 1 ml silica/zirconium beads (0.5mm) and disrupted in a BeadBeater. After centrifugation (two times for 5 minutes at 8000xg, 4 °C) the crude extract was recovered and after a second centrifugation (100,000xg, 2 hours at 4 °C), the microsomal fraction was resuspended in 500 micro-l of assay buffer (50 mM HEPES-KOH pH 6.8, 150 mM KOAc, 2 mM MgOAc, 1 mM CaCI2, protease inhibitor). The protein concentrations in the microsomes were measured according to the BCA method. Resuspended microsomes were aliquoted and frozen in N2 ) and stored at -80 °C.
In the elongase assay [14C]-labeled malonyl-CoA and non-labeled acyl-CoA were provided as substrates. After the reaction has proceeded an appropriate time, which may vary between 0 - 300 minutes depending on the purpose of the experiment, the reaction mixture was subjected to hydrolysis and methylation and the FAMEs were analyzed by RP-TLC combined with by electronic autoradiography using Instant Imager.
The assay contains about 170 micro-g microsomal protein, 7.5 nmol [14C]malonyl-CoA (3000 dpm/nmol), 5 nmol acyl-CoA in a total volume of 100 micro-l. After incubation for the desired time at 30 °C, the reaction was stopped with the addition of 100 micro-l of 2 M KOH in MeOH (1 :4) followed by a 20 minute incubation at 90 °C. Fatty acids were extracted by addition of 3 M HCI (100 micro-l), 0.75 ml of MeOH:CHCI3 (2:1 ) and CHCI3 (250 micro-l). The chloroform phase was recovered, dried under N2(g), and fatty acids were methylated by addition of 2 ml MeOH containing 2% H2SO4 and incubation of 30 minutes at 90 °C. FAMEs were extracted by addition of 2 ml H2O and 2 ml hexane and separated by Reverse Phase-TLC (Silica gel 60 RP-18) using a solvent of acetonitrile:tetrahydrofuran (85:15). The radioactive lipids were visualized and quantified by electronic autoradiography using Instant Imager.
Furthermore, assays may include additional components (e.g. 1 mM NADPH, 2 mM MgC , and 100 micro-M cerulenin) to complete the fatty acid reduction cycle by endogenous yeast enzymes, but limit further elongation of the acyl- CoA.
Delta-6 Elongase ( Thalassiosira pseudonana), c-d6Elo(Tp_GA2) Enzyme Activity: c- d6Elo(Tp_GA2) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d6Elo(Tp_GA2) protein using [14C]malonyl-CoA and
an acyl-CoA in the general elongase assay described above. Acyl-CoA's may include, but are not limited to: 18:1 n-9-CoA, 18:2n-6-CoA, 18:3n-6-CoA, 20:3n-6-CoA, 20:4n-6-CoA, 20:5n-3-CoA, 22:5n-3-CoA. Delta-6 Elongase {Physcomitrella patens), c-d6Elo(Pp_GA2) Enzyme Activity: c-d6Elo(Pp_GA2) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d6Elo(Tp_GA2) protein using [14C]malonyl-CoA and an acyl-CoA in the general elongase assay described above. Acyl-CoA's may include, but are not limited to: 18:1 n-9-CoA, 18:2n-6-CoA, 18:3n-6-CoA, 20:3n-6-CoA, 20:4n-6-CoA, 20:5n-3-CoA, 22:5n-3- CoA.
Delta-5 Elongase (Ostreococcus taun), c-d5Elo(Ot_GA3) Enzyme Activity: c-d5Elo(Ot_GA3) enzyme activity and substrate specificity can be demonstrated in microsomes isolated from a yeast strain expressing the c-d5Elo(Ot_GA3) protein using [14C]malonyl-CoA and an acyl-CoA in the general elongase assay described above. Acyl-CoA's may include, but are not limited to: 18:1 n-9-CoA, 18:2n-6-CoA, 18:3n-6-CoA, 20:3n-6-CoA, 20:4n-6-CoA, 20:5n-3-CoA, 22:5n-3- CoA.
In the presence of NADPH and [14C]malonyl-CoA, 18:3n-6-CoA was elongated to 20:3 n-6-CoA by the delta-6 Elongases isolated from Thalassiosira pseudonana (Tp) and Physcomitrella patens (Pp) as shown if Figure 28, panels A and B. In both delta-6 elongase reactions the observed FAME-product co-migrates with 20:3n-6-methyl ester standards and was radioactive, consistent with transfer of two-carbons from [14C]-malonyl-CoA to 18:3n-6-CoA. In the presence of NADPH the fatty acid reduction cycle was completed resulting in a saturated enzymatic product. However in the absence of NADPH a derivative of the direct enzymatic product, 3-keto-20:3n-6-CoA, was isolated as a FAME. The isolated enzymatic product was decarboxylated and converted to the 2- keto-19:3n-6-FAME as described previously (Bernert, J.T and Sprecher, H. (1977) J. Biol. Chem. 252:6736-6744 and Paul et al (2006) J. Biol. Chem. 281 : 9018-9029). Appropriate controls demonstrate that this elongation reaction was dependent upon either the Delta-6 Elo (Tp) or the Delta-6 Elo (Pp) and not catalyzed by endogenous yeast enzymes.
In the presence of NADPH and [14C]malonyl-CoA , 20:5n-3-CoA was elongated to 22:5 n-3-CoA by the c-d5Elo(Ot_GA3), and containing either an N-terminal FLAG tag or a C-terminal FLAG tag, as shown in Figure 28, panel C. In the Delta-5 elongase reaction the observed FAME-product co- migrates with a 22:5n-3-methyl ester standard and was radioactive, consistent with transfer of two-carbons from [14C]-malonyl CoA to 20:5n-3-CoA. In the presence of NADPH the fatty acid reduction cycle was completed resulting in a saturated enzymatic product. However in the absence of NADPH a derivative of the direct 3-keto-22:5n-3-CoA product was isolated as a FAME. The isolated enzymatic product was decarboxylated and a 2-keto-21 :5n-3-FAME as described previously (Bernert, J.T and Sprecher, H. (1977) J. Biol. Chem. 252:6736-6744 and Paul et al (2006) J. Biol. Chem. 281 : 9018-9029). Appropriate controls demonstrate that this elongation reaction was dependent upon the Delta-5 Elo (Ot) and not catalyzed by endogenous yeast enzymes.
Herein, using a highly sensitive elongase assay, we have demonstrated the enzyme activities of the Delta-6 Elongases used (Figure 28, panel A and B) and a Delta-5 Elongase (Figure 28, panel C), enzymes that are central to engineering canola to biosynthesize docosahexaenoic acid. For each of these elongases we have shown that in the presence of [14C]malonyl-CoA and the appropriate fatty-acyl CoA ester substrate these enzymes can transfer two-carbons (containing [14C]) from malonyl-CoA to the appropriate fatty-acyl-CoA ester to synthesize a new fatty acid which has been elongated by two carbons. In some cases a derivative (decarboxylated 2-keto compound) of the direct enzymatic product (3-Keto-acylCoA ester) of the elongase was observed, however in the absence of NADPH only this decarboxylated 2-keto compound was observed, consistent with previous observations by Napier (Bernert, J.T and Sprecher, H. (1977) J. Biol. Chem. 252:6736-6744 and Paul et al (2006) J. Biol. Chem. 281 : 9018-9029).
In summary we have provided a method that allows unequivocal demonstration of fatty acyl elongation enzyme activity. We provide data demonstrating that: (1 ) gene c-d6Elo(Tp_GA2) encodes a delta-6 elongase protein from Thalassiosira pseudonana (c-d6Elo(Tp_GA2)) that converts 18:3n-6-CoA to 20:3n-6-CoA in microsomes isolated from a transgenic yeast (Figure 28, panel A), (2) gene c-d6Elo(Pp_GA2) encodes a delta-6 elongase protein from Physcomitrella patens (c-d6Elo(Pp_GA2)) that converts 18:3n-6-CoA to 20:3n-6-CoA in microsomes isolated from a transgenic yeast (Figure 28, panel B), (3) a transgenic B. napus event containing both the gene encoding for the delta-6 elongase protein from Thalassiosira pseudonana, gene c- d6Elo(Tp_GA2), and the gene encoding for the gene the delta-6 elongase protein from Physcomitrella patens, gene c-d6Elo(Pp_GA2), contains at least one enzyme, localized to the microsomes, capable of elongating 18:3n-6-CoA to 20:3n-6-CoA (Figure 28, panel A) (4) gene c- d5-Elo(Ot_GA3) encodes a delta-5 elongase protein from Ostreococcus #iy/7'(c-d5Elo(Ot_GA3)) that converts 20:5n-3-CoA to 22:5n-3-CoA in microsomes isolated from both a transgenic yeast (Figure 28, Panel C) and transgenic B. napus event (Figure 29, Panel B). In all examples presented no endogenous elongase activity was detected in microsomes isolated from either control yeast strains (Figure 28) or control Brassica lines (Figure 29).
Using the methods described in "Elongase Activity" for elongase proteins the level of expression or detected enzyme activity may be influenced by the presence or absence of fusion tags to the native protein. Fusion tags or proteins to the desaturases may be attached the amino-terminus (N-terminal fusions) or the carboxy-terminus (C-terminal fusions) of the protein and may include but are not limited to: FLAG, hexa-Histidine, Maltose Binding Protein, and Chitin Binding Protein.
We have provided methods to establish enzyme catalyzed elongase reactions required in an engineered pathway to biosynthesize docosohexaenoic acid (DHA, 22:6n-3) from oleic acid (18:1 n-9) in canola. The methods presented in Example 21 were developed to demonstrate elongase activity in yeast strains expressing individual elongases and can be further used to confirm the respective elongase enzyme activities in transgenic canola. Furthermore these methods can be incorporated, by one skilled in the art, to establish elongase enzyme activities in
other organisms including, but not limited to: Saccharomyces cerevisiae, Arabidopsis thaiiana, Brassica spp., Cameiina sativa, Carthamus tinctorius, and Salvia hispanica.
Print Out (Original in Electronic Form)
(This sheet is not part of and does not count as a sheet of the international application)
 Print Out (Original in Electronic Form)
Print Out (Original in Electronic Form)
(This sheet is not part of and does not count as a sheet of the international application)

Claims
Claims 1. A method for increasing the content of Mead acid (20:3n-9) in a plant relative to a control plant, comprising expressing in a plant at least one polynucleotide encoding a delta-6- desaturase, at least one polynucleotide encoding a delta-6-elongase, and at least one polynucleotide encoding a delta-5-desaturase.
2. The method according to claim 1 , further comprising expression a delta-12-desaturase, omega-3-desaturase, a delta-5-elongase, and/or a delta-4-desaturase.
3. Plant or a seed or part thereof, comprising, integrated in its genome, a heterologous T- DNA of the present invention, wherein the T-DNA comprises the coding sequences of any single genes of the tables given in the examples of Section A, preferably comprising the coding sequences and and promoters of any single of the tables given in the examples, more preferably the coding sequences and promoters and terminators of any single of the tables given in the examples, and most preferably the expression cassettes of any single of the tables of the examples.
4. Plant comprising one or more T-DNA comprising one or more expression cassetts encoding for one or more d5Des, one or more d6Elo, one or more d6Des, one or more o3Des, one or more d5Elo and one or more D4Des.
5. The plant of Embodiment 3 or 4 comprising one or more T-DNAs encoding for at least two d6Des, at least two d6Elo and/or, at least two o3Des.
6. The plant any one of Claims 3 to 5 on or a part thereof comprising a T-DNA encoding for at least one CoA-depenent d4Des and at least one phopho-lipid dependent d4Des.
7 The plant, seed or part thereof any one of Claims 3 to 6 the plant, seed or part thereof further encoding for one or more d12Des. 8. Plant or seed thereof of family Brassicaceae, preferably of genus Brassica, with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from progeny lines prepared by a method comprising the steps of
i) crossing a plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant comprising a T-DNA of any of Claims 1 or 2 and/or part of such T-DNA, with a plant of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, said plant not comprising said T-DNA and/or part thereof, to yield a F1 hybrid,
ii) selfing the F1 hybrid for at least one generation, and
iii) identifying the progeny of step (ii) comprising the T-DNA of the present invention capable of producing seed comprising VLC-PUFA such that the content of all VLC- PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 6%, preferably at least 7,5% (w/w) and/or the content of DHA is at least 0,
8%
(w/w), preferably 1 ,2% of the total seed fatty acid content at an oil content of 40% (w/w).
9. Method for creating a plant with a genotype that confers a heritable phenotype of seed oil VLC-PUFA content, obtainable or obtained from progeny lines prepared by a method comprising the steps of
i) crossing a transgenic plant according to any of Claims 3 or 4 with a plant not comprising a T-DNA according to any of Claims 1 or 2 or part thereof, said latter plant being of family Brassicaceae, preferably of genus Brassica, most preferably of genus Brassica napus, Brassica oleracea, Brassica nigra or Brassica carinata, to yield a F1 hybrid,
ii) selfing the F1 hybrid for at least one generation, and
iii) identifying the progeny of step (ii) comprising the T-DNA of the present invention capable of producing seed comprising VLC-PUFA such that the content of all VLC- PUFA downstream of 18:1 n-9 is at least 40% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w), or preferably the content of EPA is at least 6%, preferably at least 7,5% (w/w) and/or the content of DHA is at least 0,8% (w/w), prerferably 1.2% (w/w) of the total seed fatty acid content at an oil content of 40% (w/w).
10. The method of Embodiment 9 o the plant of Embodiment 8, wherein the T-DNA is homozygous
1 1. Method of plant oil production, comprising the steps of
i) growing a plant according to any of Claims 3 to 8 such as to obtain oil-containing seeds thereof,
ii) harvesting said seeds, and
iii) extracting oil from said seeds harvested in step ii), wherein the oil has a DHA content of at least 1 % by weight based on the total lipid content and/or a EPA content of at least 8% by weight based on the total lipid content.
12. Plant oil comprising a polyunsaturated fatty acid obtainable or obtained by the method of Embodiment 1 1.
13. Method for analysing desaturase reaction specificity, comprising the steps of
i) providing, to a desaturase, a detectably labelled molecule comprising a fatty acid moiety and a headgroup,
ii) allowing the desaturase to react on the labelled molecule, and
iii) detecting desaturation products.
14. Method for analysing elongase reaction specificity, comprising the steps of
i) providing, to an elongase, a detectably labelled elongation substrate and a molecule to be elongated,
ii) allowing the elongase to elongate the molecule to be elongated using the labelled elongation substrate, and
iii) detecting elongation products.
15. Method for optimization of a metabolic pathway, comprising the steps of
i) providing enzymes of a metabolic pathway and one or more substrates to be used by the first enzyme or enzymes of the pathway,
ii) reacting the enzymes and the substrates to produce products, which in turn are also exposed as potential substrates to the enzymes of the pathway, and iii) determining the accumulation of products.
16. Method for determining CoA-dependence of a target desaturase, comprising the steps of i) providing an elongase to produce a substrate for the target desaturase, and determining conversion efficiency of the target desaturase, and
ii) providing a non-CoA dependent desaturase to produce the substrate for the target desaturase, and determining conversion efficiency of the target desaturase, and iii) comparing the target desaturase conversion efficiencies of step i) and ii).
17. Method for determining CoA-dependence of a target desaturase, comprising the steps of i) providing an elongase to elongate the products of the target desaturase, and determining conversion efficiency of the elongase,
ii) providing the elongase to elongate the products of a comparison desaturase known to be non-CoA dependent, and determining conversion efficiency of the elongase,
iii) comparing the elongase conversion efficiencies of step i) and ii).
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP15801706.1A EP3218498A2 (en) | 2014-11-14 | 2015-11-13 | Production of pufas in plants |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201462079622P | 2014-11-14 | 2014-11-14 | |
| US62/079,622 | 2014-11-14 | ||
| US201562234373P | 2015-09-29 | 2015-09-29 | |
| US62/234,373 | 2015-09-29 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2016075327A2 true WO2016075327A2 (en) | 2016-05-19 |
| WO2016075327A3 WO2016075327A3 (en) | 2016-07-14 |
Family
ID=54601758
Family Applications (6)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2015/076608 WO2016075313A1 (en) | 2014-11-14 | 2015-11-13 | Materials and methods for increasing the tocopherol content in seed oil |
| PCT/EP2015/076632 WO2016075327A2 (en) | 2014-11-14 | 2015-11-13 | Production of pufas in plants |
| PCT/EP2015/076630 WO2016075325A1 (en) | 2014-11-14 | 2015-11-13 | Modification of plant lipids containing pufas |
| PCT/EP2015/076596 WO2016075303A1 (en) | 2014-11-14 | 2015-11-13 | Brassica events lbflfk and lbfdau and methods for detection thereof |
| PCT/EP2015/076631 WO2016075326A2 (en) | 2014-11-14 | 2015-11-13 | Materials and methods for pufa production, and pufa-containing compositions |
| PCT/EP2015/076605 WO2016075310A1 (en) | 2014-11-14 | 2015-11-13 | Stabilising fatty acid compositions |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2015/076608 WO2016075313A1 (en) | 2014-11-14 | 2015-11-13 | Materials and methods for increasing the tocopherol content in seed oil |
Family Applications After (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2015/076630 WO2016075325A1 (en) | 2014-11-14 | 2015-11-13 | Modification of plant lipids containing pufas |
| PCT/EP2015/076596 WO2016075303A1 (en) | 2014-11-14 | 2015-11-13 | Brassica events lbflfk and lbfdau and methods for detection thereof |
| PCT/EP2015/076631 WO2016075326A2 (en) | 2014-11-14 | 2015-11-13 | Materials and methods for pufa production, and pufa-containing compositions |
| PCT/EP2015/076605 WO2016075310A1 (en) | 2014-11-14 | 2015-11-13 | Stabilising fatty acid compositions |
Country Status (14)
| Country | Link |
|---|---|
| US (11) | US11033593B2 (en) |
| EP (4) | EP3218499B1 (en) |
| JP (7) | JP7423177B2 (en) |
| KR (2) | KR20170099884A (en) |
| CN (6) | CN107532179B (en) |
| AU (11) | AU2015344993C9 (en) |
| CA (5) | CA2967128A1 (en) |
| CL (4) | CL2017001225A1 (en) |
| EC (3) | ECSP17036764A (en) |
| MX (4) | MX2017006304A (en) |
| MY (1) | MY184649A (en) |
| PH (4) | PH12017500876A1 (en) |
| SG (1) | SG11201703858YA (en) |
| WO (6) | WO2016075313A1 (en) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108690833A (en) * | 2017-03-31 | 2018-10-23 | Toto株式会社 | The production method of recombinant mammalian cells and target substance |
| WO2020168277A1 (en) | 2019-02-14 | 2020-08-20 | Cargill, Incorporated | Brassica plants producing elevated levels of polyunsaturated fatty acids |
| CN113475400A (en) * | 2021-08-03 | 2021-10-08 | 吉安市林业科学研究所 | Artificial cultivation technology of cardamine hirsute |
| WO2022098631A1 (en) | 2020-11-04 | 2022-05-12 | Cargill, Incorporated | Harvest management |
| WO2022204454A1 (en) | 2021-03-25 | 2022-09-29 | Cargill, Incorporated | Fertilizer management |
| WO2023081920A1 (en) | 2021-11-08 | 2023-05-11 | Cargill, Incorporated | High plant pufa fish food |
| US11957098B2 (en) | 2019-04-11 | 2024-04-16 | Basf Plant Science Company Gmbh | Method of cultivating LC-PUFA containing transgenic brassica plants |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| MX2016000225A (en) * | 2013-07-05 | 2016-06-15 | Basf Plant Science Co Gmbh | Gene expression or activity enhancing elements. |
| US11033593B2 (en) | 2014-11-14 | 2021-06-15 | Basf Plant Science Company Gmbh | Brassica events LBFLFK and LBFDAU and methods for detection thereof |
| AR109245A1 (en) | 2016-05-12 | 2018-11-14 | Basf Plant Science Co Gmbh | METHODS TO OPTIMIZE THE PRODUCTION OF METABOLITES IN GENETICALLY MODIFIED PLANTS AND TO PROCESS THESE PLANTS |
| CN110699462B (en) * | 2019-11-06 | 2023-08-18 | 中国科学院南海海洋研究所 | Tridacron oyster microsatellite locus and identification primer |
Citations (60)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4683195A (en) | 1986-01-30 | 1987-07-28 | Cetus Corporation | Process for amplifying, detecting, and/or-cloning nucleic acid sequences |
| EP0249676A2 (en) | 1986-01-28 | 1987-12-23 | Sandoz Ltd. | Method for the expression of genes in plants |
| EP0335528A2 (en) | 1988-03-29 | 1989-11-15 | E.I. Du Pont De Nemours And Company | DNA promoter fragments from wheat |
| EP0388186A1 (en) | 1989-03-17 | 1990-09-19 | E.I. Du Pont De Nemours And Company | External regulation of gene expression |
| WO1991013980A1 (en) | 1990-03-16 | 1991-09-19 | Calgene, Inc. | Novel sequences preferentially expressed in early seed development and methods related thereto |
| WO1993010241A1 (en) | 1991-11-20 | 1993-05-27 | Calgene, Inc. | FATTY ACYL-CoA: FATTY ALCOHOL O-ACYLTRANSFERASES |
| WO1993021334A1 (en) | 1992-04-13 | 1993-10-28 | Zeneca Limited | Dna constructs and plants incorporating them |
| WO1994013814A1 (en) | 1992-12-10 | 1994-06-23 | Nickerson Biocem Limited | Dna encoding 2-acyltransferases |
| WO1995015389A2 (en) | 1993-12-02 | 1995-06-08 | Olsen Odd Arne | Promoter |
| WO1995023230A1 (en) | 1994-02-24 | 1995-08-31 | Olsen Odd Arne | Promoter from a lipid transfer protein gene |
| WO1995027791A1 (en) | 1994-04-06 | 1995-10-19 | Calgene Inc. | Plant lysophosphatidic acid acyltransferases |
| US5504200A (en) | 1983-04-15 | 1996-04-02 | Mycogen Plant Science, Inc. | Plant gene expression |
| WO1996024674A1 (en) | 1995-02-09 | 1996-08-15 | Gene Shears Pty. Limited | Dna sequence encoding plant 2-acyltransferase |
| US5608152A (en) | 1986-07-31 | 1997-03-04 | Calgene, Inc. | Seed-specific transcriptional regulation |
| WO1998045461A1 (en) | 1997-04-09 | 1998-10-15 | Rhone-Poulenc Agro | An oleosin 5' regulatory region for the modification of plant seed lipid composition |
| WO1998054303A1 (en) | 1997-05-27 | 1998-12-03 | Cell Therapeutics, Inc. | Mammalian lysophosphatidic acid acyltransferase |
| WO1998054302A2 (en) | 1997-05-27 | 1998-12-03 | Icos Corporation | Human lysophosphatidic acid acyltransferase |
| WO1998055631A1 (en) | 1997-06-05 | 1998-12-10 | Calgene Llc | Diacylglycerol acyl transferase proteins |
| WO1998055632A1 (en) | 1997-06-05 | 1998-12-10 | Calgene Llc | FATTY ACYL-CoA: FATTY ALCOHOL ACYLTRANSFERASES |
| WO1999016890A2 (en) | 1997-09-30 | 1999-04-08 | The Regents Of The University Of California | Production of proteins in plant seeds |
| WO2000018889A2 (en) | 1998-09-25 | 2000-04-06 | Calgene Llc | Sequenzes of putative plant acyltransferases |
| WO2001059128A2 (en) | 2000-02-09 | 2001-08-16 | Basf Aktiengesellschaft | Novel elongase gene and method for producing multiple-unsaturated fatty acids |
| US6303849B1 (en) | 1998-11-12 | 2001-10-16 | Saskatchewan Wheat Pool | Brassica juncea lines bearing endogenous edible oils |
| WO2002026946A2 (en) | 2000-09-28 | 2002-04-04 | Bioriginal Food & Science Corporation | Fad4, fad5, fad5-2, and fad6, fatty acid desaturase family members and uses thereof |
| US6544734B1 (en) | 1998-10-09 | 2003-04-08 | Cynthia G. Briscoe | Multilayered microfluidic DNA analysis system and method |
| WO2003078639A2 (en) | 2002-03-16 | 2003-09-25 | The University Of York | Transgenic plants expressing enzymes involved in fatty acid biosynthesis |
| WO2003093482A2 (en) | 2002-04-29 | 2003-11-13 | Basf Plant Science Gmbh | Method for producing multiple unsaturated fatty acids in plants |
| US6689880B2 (en) | 2000-09-29 | 2004-02-10 | Monsanto Technology Llc | DNA molecule for detecting glyphosate tolerant wheat plant 33391 and progeny thereof |
| US6733974B1 (en) | 2000-12-01 | 2004-05-11 | Monsanto Technology, Llc | Methods and compositions for detection of specific genetic constructs in plant transformation events |
| US6740488B2 (en) | 2000-10-25 | 2004-05-25 | Monsanto Technology Llc | Cotton event PV-GHGT07(1445) compositions and methods for detection thereof |
| WO2004071467A2 (en) | 2003-02-12 | 2004-08-26 | E. I. Du Pont De Nemours And Company | Production of very long chain polyunsaturated fatty acids in oilseed plants |
| WO2004087902A2 (en) | 2003-03-31 | 2004-10-14 | University Of Bristol | Novel plant acyltransferases specific for long-chained, multiply unsaturated fatty acids |
| WO2004090123A2 (en) | 2003-04-08 | 2004-10-21 | Basf Plant Science Gmbh | Δ-4 desaturases from euglena gracilis, expressing plants, and oils containing pufa |
| US6818807B2 (en) | 2001-08-06 | 2004-11-16 | Bayer Bioscience N.V. | Herbicide tolerant cotton plants having event EE-GH1 |
| US6825400B2 (en) | 2000-06-22 | 2004-11-30 | Monsanto Technology Llc | Corn plants comprising event PV-ZMGT32(nk603) |
| WO2005007845A2 (en) | 2003-07-16 | 2005-01-27 | The University Of York | Transgenic cells |
| WO2005012316A2 (en) | 2003-08-01 | 2005-02-10 | Basf Plant Science Gmbh | Method for the production of multiply-unsaturated fatty acids in transgenic organisms |
| WO2005017181A2 (en) | 2003-05-20 | 2005-02-24 | Investigen, Inc. | System for detecting polynucleotides |
| US6893826B1 (en) | 2000-11-17 | 2005-05-17 | Monsanto Technology Llc | Cotton event PV-GHBK04 (757) and compositions and methods for detection thereof |
| US6900014B1 (en) | 1999-10-29 | 2005-05-31 | Bayer Bioscience N.V | Methods for determining the presence or absence of elite event MS-B2 in Brassica plant material |
| WO2005083093A2 (en) | 2004-02-27 | 2005-09-09 | Basf Plant Science Gmbh | Method for producing polyunsaturated fatty acids in transgenic plants |
| WO2005083053A2 (en) | 2004-02-27 | 2005-09-09 | Basf Plant Science Gmbh | Method for producing unsaturated omega-3 fatty acids in transgenic organisms |
| WO2006008099A2 (en) | 2004-07-16 | 2006-01-26 | Basf Plant Science Gmbh | Method for increasing the content of polyunsaturated long-chained fatty acids in transgenic organisms |
| WO2006024023A2 (en) | 2004-08-24 | 2006-03-02 | Nanomix, Inc. | Nanotube sensor devices for dna detection |
| WO2006024509A2 (en) | 2004-09-02 | 2006-03-09 | Basf Plant Science Gmbh | Disarmed agrobacterium strains, ri-plasmids, and methods of transformation based thereon |
| US20060068398A1 (en) | 2004-09-24 | 2006-03-30 | Cepheid | Universal and target specific reagent beads for nucleic acid amplification |
| WO2006069710A1 (en) | 2004-12-23 | 2006-07-06 | Basf Plant Science Gmbh | Method for producing polyunsaturated fatty acids in transgenic organisms |
| WO2006100241A2 (en) | 2005-03-22 | 2006-09-28 | Basf Plant Science Gmbh | Method for producing polyunsaturated c20 and c22 fatty acids with at least four double bonds in transgenic plants |
| WO2007096387A1 (en) | 2006-02-21 | 2007-08-30 | Basf Plant Science Gmbh | Method for producing polyunsaturated fatty acids |
| WO2008022963A2 (en) | 2006-08-24 | 2008-02-28 | Basf Plant Science Gmbh | Isolation and characterization of a novel pythium omega 3 desaturase with specificity to all omega 6 fatty acids longer than 18 carbon chains |
| US7423198B2 (en) | 2002-05-15 | 2008-09-09 | Viterra, Inc. | High oleic acid Brassica juncea |
| WO2008124495A2 (en) | 2007-04-04 | 2008-10-16 | Basf Plant Science Gmbh | Ahas mutants |
| WO2011161093A1 (en) | 2010-06-25 | 2011-12-29 | Basf Plant Science Company Gmbh | Acyltransferases and uses therof in fatty acid production |
| AU2011289381A1 (en) | 2010-08-11 | 2013-01-24 | E. I. Du Pont De Nemours And Company | Improved aquaculture feed compositions |
| WO2013014585A1 (en) | 2011-07-22 | 2013-01-31 | Basf Plant Science Company Gmbh | Plant transformation method |
| WO2013049227A2 (en) | 2011-09-26 | 2013-04-04 | Geneart Ag | High efficiency, small volume nucleic acid synthesis |
| WO2013185184A2 (en) | 2012-06-15 | 2013-12-19 | Commonwealth Scientific And Industrial Research Organisation | Production of long chain polyunsaturated fatty acids in plant cells |
| US8999411B2 (en) | 2008-02-15 | 2015-04-07 | Monsanto Technology Llc | Soybean plant and seed corresponding to transgenic event MON87769 and methods for detection thereof |
| WO2015089587A1 (en) | 2013-12-18 | 2015-06-25 | Commonwealth Scientific And Industrial Research Organisation | Lipid comprising long chain polyunsaturated fatty acids |
| US20150299676A1 (en) | 2013-11-26 | 2015-10-22 | Dow Agrosciences Llc | Production of omega 3 long chain polyunsaturated fatty acids in oilseed crops by a thraustochytrid pufa synthase |
Family Cites Families (35)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE4228476C2 (en) | 1992-08-27 | 2002-05-02 | Cognis Deutschland Gmbh | Process for the recovery of tocopherol and / or sterol |
| JP3333211B2 (en) | 1994-01-26 | 2002-10-15 | レイリー,マーク・エイ | Improved expandable device for use in a surgical method for bone treatment |
| WO1999064616A2 (en) | 1998-06-12 | 1999-12-16 | Abbott Laboratories | Polyunsaturated fatty acids in plants |
| US6342657B1 (en) * | 1999-05-06 | 2002-01-29 | Rhone-Poulenc Agro | Seed specific promoters |
| WO2001044457A2 (en) * | 1999-12-16 | 2001-06-21 | Monsanto Technology Llc | Dna constructs for expression of heterologous polypeptides in plants |
| GB0031558D0 (en) | 2000-12-22 | 2001-02-07 | Biogemma Uk Ltd | Elongase promoters |
| DE60228272D1 (en) | 2001-06-06 | 2008-09-25 | Bioriginal Food & Science Corp | SEED-SPECIFIC SEQUENCES OF FLAX (LINUM USITATISSIMUM L.) |
| AU2002324856A1 (en) * | 2001-08-29 | 2003-03-10 | Xenon Genetics Inc. | High throughput screening assays using fatty acid synthetic enzymes |
| EP2261312A1 (en) * | 2001-12-12 | 2010-12-15 | Martek Biosciences Corporation | Extraction and Winterization of Lipids from Oilseed and Microbial Sources |
| JP4100494B2 (en) | 2002-02-05 | 2008-06-11 | 独立行政法人理化学研究所 | Late seed maturation and germination stage specific inducible promoters |
| CA2482597C (en) | 2002-04-17 | 2014-09-30 | Sangamo Biosciences, Inc. | Compositions and methods for regulation of plant gamma-tocopherol methyltransferase |
| JP4567047B2 (en) | 2004-02-27 | 2010-10-20 | ビーエーエスエフ プラント サイエンス ゲーエムベーハー | Process for producing polyunsaturated fatty acids in transgenic plants |
| BRPI0511236A (en) * | 2004-06-04 | 2007-11-27 | Fluxome Sciences As | A method for producing four or more double bond polyunsaturated fatty acids, genetically modified saccharomyces cerevisiae which is capable of producing four or more double bond polyunsaturated fatty acids when developed on a substrate other than fatty acid, composition, use of the composition and use of a genetically modified saccharomyces cervisiae |
| WO2006012325A1 (en) | 2004-06-25 | 2006-02-02 | E.I. Dupont De Nemours And Company | Delta-8 desaturase and its use in making polyunsaturated fatty acids |
| CN101098629B (en) * | 2004-11-04 | 2010-10-13 | 孟山都技术公司 | High PUFA oil compositions |
| ES2547067T3 (en) | 2004-11-04 | 2015-10-01 | Monsanto Technology, Llc | Oil compositions with a high content of polyunsaturated fatty acids |
| DE102005038036A1 (en) | 2005-08-09 | 2007-02-15 | Basf Plant Science Gmbh | Process for the preparation of arachidonic acid and / or eicosapentaenoic acid in transgenic crops |
| DE102006008030A1 (en) * | 2006-02-21 | 2007-08-23 | Basf Plant Science Gmbh | Preparation of polyunsaturated fatty acids in transgenic plants, useful e.g. for reducing risk of hypertension and heart disease, includes expressing a codon-optimized sequence for delta5-elongase |
| US7371930B1 (en) | 2006-12-15 | 2008-05-13 | Shamrock Seed Company, Inc. | Lettuce cultivar 21-0406127-B |
| EP2176416B1 (en) | 2007-07-31 | 2016-03-16 | BASF Plant Science GmbH | Elongases and methods for producing polyunsaturated fatty acids in transgenic organisms |
| PL2247736T3 (en) | 2008-02-29 | 2013-10-31 | Monsanto Technology Llc | Corn plant event mon87460 and compositions and methods for detection thereof |
| WO2009130291A2 (en) | 2008-04-25 | 2009-10-29 | Basf Plant Science Gmbh | Plant seed oil |
| CN102066564B (en) | 2008-04-30 | 2015-02-11 | 罗特哈姆斯泰德研究有限公司 | Desaturase and method for the production of polyunsaturated fatty acids in transgenic organisms |
| CA2989798C (en) * | 2008-07-01 | 2019-11-05 | Basf Plant Science Gmbh | Promoters from brassica napus for seed specific gene expression |
| CA2734810C (en) | 2008-08-26 | 2018-06-19 | Basf Plant Science Gmbh | Nucleic acids encoding desaturases and modified plant oil |
| NO2358882T3 (en) | 2008-11-18 | 2017-12-23 | ||
| EP2376638B1 (en) | 2008-12-12 | 2013-08-14 | BASF Plant Science GmbH | Desaturases and process for the production of polyunsaturated fatty acids in transgenic organisms |
| CA3037072C (en) | 2009-07-17 | 2022-07-26 | Basf Plant Science Company Gmbh | Novel fatty acid desaturases and elongases and uses thereof |
| TW201144442A (en) | 2010-05-17 | 2011-12-16 | Dow Agrosciences Llc | Production of DHA and other LC-PUFAs in plants |
| US20140220215A1 (en) * | 2011-05-31 | 2014-08-07 | Cargill, Incorporated | Oxidatively-stabilized fats containing very long-chain omega-3 polyunsaturated fatty acids |
| CA2861817C (en) | 2011-12-30 | 2020-08-11 | Dow Agrosciences Llc | Dha retention during canola processing |
| BR112014025265A2 (en) * | 2012-04-12 | 2017-07-11 | Rothamsted Res Ltd | production of long chain omega-3 polyunsaturated fatty acids |
| AU2013251382A1 (en) | 2012-04-27 | 2014-10-16 | Synthetic Genomics, Inc. | Compositions and methods for modulating the sensitivity of cells to AHAS inhibitors |
| CN102719552B (en) * | 2012-07-16 | 2013-12-04 | 上海市农业科学院 | Qualitative and quantitative PCR (polymerase chain reaction) detection method of strain specificity of transgenic carnation Moonshade |
| US11033593B2 (en) | 2014-11-14 | 2021-06-15 | Basf Plant Science Company Gmbh | Brassica events LBFLFK and LBFDAU and methods for detection thereof |
-
2015
- 2015-11-13 US US15/526,443 patent/US11033593B2/en active Active
- 2015-11-13 AU AU2015344993A patent/AU2015344993C9/en active Active
- 2015-11-13 AU AU2015344992A patent/AU2015344992B2/en active Active
- 2015-11-13 AU AU2015345049A patent/AU2015345049B2/en active Active
- 2015-11-13 US US15/525,463 patent/US11484560B2/en active Active
- 2015-11-13 CN CN201580073394.6A patent/CN107532179B/en active Active
- 2015-11-13 JP JP2017525951A patent/JP7423177B2/en active Active
- 2015-11-13 CA CA2967128A patent/CA2967128A1/en active Pending
- 2015-11-13 CN CN202111139791.2A patent/CN113930442A/en active Pending
- 2015-11-13 WO PCT/EP2015/076608 patent/WO2016075313A1/en active Application Filing
- 2015-11-13 CN CN201580073289.2A patent/CN107580629B/en active Active
- 2015-11-13 MY MYPI2017000707A patent/MY184649A/en unknown
- 2015-11-13 KR KR1020177016137A patent/KR20170099884A/en not_active Application Discontinuation
- 2015-11-13 EP EP15812961.9A patent/EP3218499B1/en active Active
- 2015-11-13 CA CA2967136A patent/CA2967136A1/en active Pending
- 2015-11-13 CN CN201580061517.4A patent/CN107257630A/en active Pending
- 2015-11-13 US US15/526,162 patent/US11260095B2/en active Active
- 2015-11-13 EP EP15801706.1A patent/EP3218498A2/en active Pending
- 2015-11-13 WO PCT/EP2015/076632 patent/WO2016075327A2/en active Application Filing
- 2015-11-13 CA CA2967708A patent/CA2967708A1/en active Pending
- 2015-11-13 CN CN201580073433.2A patent/CN107429256B/en active Active
- 2015-11-13 KR KR1020177015799A patent/KR102580142B1/en active IP Right Grant
- 2015-11-13 SG SG11201703858YA patent/SG11201703858YA/en unknown
- 2015-11-13 EP EP22189970.1A patent/EP4151733A1/en not_active Withdrawn
- 2015-11-13 WO PCT/EP2015/076630 patent/WO2016075325A1/en active Application Filing
- 2015-11-13 CA CA2967132A patent/CA2967132A1/en active Pending
- 2015-11-13 CA CA2967131A patent/CA2967131A1/en active Pending
- 2015-11-13 MX MX2017006304A patent/MX2017006304A/en unknown
- 2015-11-13 WO PCT/EP2015/076596 patent/WO2016075303A1/en active Application Filing
- 2015-11-13 WO PCT/EP2015/076631 patent/WO2016075326A2/en active Application Filing
- 2015-11-13 WO PCT/EP2015/076605 patent/WO2016075310A1/en active Application Filing
- 2015-11-13 US US15/525,768 patent/US10760089B2/en active Active
- 2015-11-13 US US15/526,550 patent/US11613761B1/en active Active
- 2015-11-13 JP JP2017525981A patent/JP7067926B2/en active Active
- 2015-11-13 EP EP15797292.8A patent/EP3218496A1/en not_active Ceased
- 2015-11-13 AU AU2015344980A patent/AU2015344980B2/en active Active
- 2015-11-13 JP JP2017525878A patent/JP6974168B2/en active Active
- 2015-11-13 AU AU2015344977A patent/AU2015344977B2/en active Active
- 2015-11-13 MX MX2017006291A patent/MX2017006291A/en unknown
- 2015-11-13 CN CN202210113594.1A patent/CN115094081A/en active Pending
-
2017
- 2017-05-11 PH PH12017500876A patent/PH12017500876A1/en unknown
- 2017-05-11 PH PH12017500880A patent/PH12017500880A1/en unknown
- 2017-05-12 MX MX2021003966A patent/MX2021003966A/en unknown
- 2017-05-12 CL CL2017001225A patent/CL2017001225A1/en unknown
- 2017-05-12 MX MX2021014752A patent/MX2021014752A/en unknown
- 2017-05-12 CL CL2017001223A patent/CL2017001223A1/en unknown
- 2017-05-12 CL CL2017001221A patent/CL2017001221A1/en unknown
- 2017-05-15 PH PH12017500898A patent/PH12017500898A1/en unknown
- 2017-06-13 EC ECIEPI201736764A patent/ECSP17036764A/en unknown
- 2017-06-14 EC ECIEPI201737217A patent/ECSP17037217A/en unknown
- 2017-06-14 EC ECIEPI201737221A patent/ECSP17037221A/en unknown
-
2018
- 2018-12-06 CL CL2018003505A patent/CL2018003505A1/en unknown
-
2019
- 2019-05-07 US US16/405,440 patent/US10829775B2/en active Active
-
2020
- 2020-11-09 US US17/093,232 patent/US11771728B2/en active Active
- 2020-12-09 PH PH12020552114A patent/PH12020552114A1/en unknown
-
2021
- 2021-06-14 US US17/346,522 patent/US11813302B2/en active Active
- 2021-06-25 AU AU2021204330A patent/AU2021204330A1/en not_active Abandoned
- 2021-08-20 JP JP2021134471A patent/JP2021184744A/en active Pending
- 2021-11-11 AU AU2021266278A patent/AU2021266278A1/en active Pending
-
2022
- 2022-02-10 AU AU2022200870A patent/AU2022200870B2/en active Active
- 2022-02-28 US US17/682,694 patent/US20220184161A1/en not_active Abandoned
- 2022-03-17 JP JP2022042097A patent/JP2022088464A/en not_active Withdrawn
- 2022-03-23 AU AU2022202025A patent/AU2022202025A1/en active Pending
- 2022-04-15 JP JP2022067353A patent/JP2022106787A/en active Pending
- 2022-08-17 AU AU2022100109A patent/AU2022100109A4/en not_active Expired
- 2022-08-19 AU AU2022100112A patent/AU2022100112B4/en not_active Expired
- 2022-10-31 US US18/051,318 patent/US20240041961A1/en active Pending
-
2023
- 2023-01-31 US US18/162,300 patent/US20230293615A1/en active Pending
- 2023-03-01 JP JP2023030778A patent/JP2023081920A/en active Pending
Patent Citations (61)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5504200A (en) | 1983-04-15 | 1996-04-02 | Mycogen Plant Science, Inc. | Plant gene expression |
| EP0249676A2 (en) | 1986-01-28 | 1987-12-23 | Sandoz Ltd. | Method for the expression of genes in plants |
| US4683195B1 (en) | 1986-01-30 | 1990-11-27 | Cetus Corp | |
| US4683195A (en) | 1986-01-30 | 1987-07-28 | Cetus Corporation | Process for amplifying, detecting, and/or-cloning nucleic acid sequences |
| US5608152A (en) | 1986-07-31 | 1997-03-04 | Calgene, Inc. | Seed-specific transcriptional regulation |
| EP0335528A2 (en) | 1988-03-29 | 1989-11-15 | E.I. Du Pont De Nemours And Company | DNA promoter fragments from wheat |
| EP0388186A1 (en) | 1989-03-17 | 1990-09-19 | E.I. Du Pont De Nemours And Company | External regulation of gene expression |
| WO1991013980A1 (en) | 1990-03-16 | 1991-09-19 | Calgene, Inc. | Novel sequences preferentially expressed in early seed development and methods related thereto |
| WO1993010241A1 (en) | 1991-11-20 | 1993-05-27 | Calgene, Inc. | FATTY ACYL-CoA: FATTY ALCOHOL O-ACYLTRANSFERASES |
| WO1993021334A1 (en) | 1992-04-13 | 1993-10-28 | Zeneca Limited | Dna constructs and plants incorporating them |
| WO1994013814A1 (en) | 1992-12-10 | 1994-06-23 | Nickerson Biocem Limited | Dna encoding 2-acyltransferases |
| WO1995015389A2 (en) | 1993-12-02 | 1995-06-08 | Olsen Odd Arne | Promoter |
| WO1995023230A1 (en) | 1994-02-24 | 1995-08-31 | Olsen Odd Arne | Promoter from a lipid transfer protein gene |
| WO1995027791A1 (en) | 1994-04-06 | 1995-10-19 | Calgene Inc. | Plant lysophosphatidic acid acyltransferases |
| WO1996024674A1 (en) | 1995-02-09 | 1996-08-15 | Gene Shears Pty. Limited | Dna sequence encoding plant 2-acyltransferase |
| WO1998045461A1 (en) | 1997-04-09 | 1998-10-15 | Rhone-Poulenc Agro | An oleosin 5' regulatory region for the modification of plant seed lipid composition |
| WO1998054303A1 (en) | 1997-05-27 | 1998-12-03 | Cell Therapeutics, Inc. | Mammalian lysophosphatidic acid acyltransferase |
| WO1998054302A2 (en) | 1997-05-27 | 1998-12-03 | Icos Corporation | Human lysophosphatidic acid acyltransferase |
| WO1998055631A1 (en) | 1997-06-05 | 1998-12-10 | Calgene Llc | Diacylglycerol acyl transferase proteins |
| WO1998055632A1 (en) | 1997-06-05 | 1998-12-10 | Calgene Llc | FATTY ACYL-CoA: FATTY ALCOHOL ACYLTRANSFERASES |
| WO1999016890A2 (en) | 1997-09-30 | 1999-04-08 | The Regents Of The University Of California | Production of proteins in plant seeds |
| WO2000018889A2 (en) | 1998-09-25 | 2000-04-06 | Calgene Llc | Sequenzes of putative plant acyltransferases |
| US6544734B1 (en) | 1998-10-09 | 2003-04-08 | Cynthia G. Briscoe | Multilayered microfluidic DNA analysis system and method |
| US6303849B1 (en) | 1998-11-12 | 2001-10-16 | Saskatchewan Wheat Pool | Brassica juncea lines bearing endogenous edible oils |
| US6900014B1 (en) | 1999-10-29 | 2005-05-31 | Bayer Bioscience N.V | Methods for determining the presence or absence of elite event MS-B2 in Brassica plant material |
| WO2001059128A2 (en) | 2000-02-09 | 2001-08-16 | Basf Aktiengesellschaft | Novel elongase gene and method for producing multiple-unsaturated fatty acids |
| US6825400B2 (en) | 2000-06-22 | 2004-11-30 | Monsanto Technology Llc | Corn plants comprising event PV-ZMGT32(nk603) |
| WO2002026946A2 (en) | 2000-09-28 | 2002-04-04 | Bioriginal Food & Science Corporation | Fad4, fad5, fad5-2, and fad6, fatty acid desaturase family members and uses thereof |
| US6689880B2 (en) | 2000-09-29 | 2004-02-10 | Monsanto Technology Llc | DNA molecule for detecting glyphosate tolerant wheat plant 33391 and progeny thereof |
| US6740488B2 (en) | 2000-10-25 | 2004-05-25 | Monsanto Technology Llc | Cotton event PV-GHGT07(1445) compositions and methods for detection thereof |
| US6893826B1 (en) | 2000-11-17 | 2005-05-17 | Monsanto Technology Llc | Cotton event PV-GHBK04 (757) and compositions and methods for detection thereof |
| US6733974B1 (en) | 2000-12-01 | 2004-05-11 | Monsanto Technology, Llc | Methods and compositions for detection of specific genetic constructs in plant transformation events |
| US6818807B2 (en) | 2001-08-06 | 2004-11-16 | Bayer Bioscience N.V. | Herbicide tolerant cotton plants having event EE-GH1 |
| WO2003078639A2 (en) | 2002-03-16 | 2003-09-25 | The University Of York | Transgenic plants expressing enzymes involved in fatty acid biosynthesis |
| WO2003093482A2 (en) | 2002-04-29 | 2003-11-13 | Basf Plant Science Gmbh | Method for producing multiple unsaturated fatty acids in plants |
| US7423198B2 (en) | 2002-05-15 | 2008-09-09 | Viterra, Inc. | High oleic acid Brassica juncea |
| WO2004071467A2 (en) | 2003-02-12 | 2004-08-26 | E. I. Du Pont De Nemours And Company | Production of very long chain polyunsaturated fatty acids in oilseed plants |
| WO2004087902A2 (en) | 2003-03-31 | 2004-10-14 | University Of Bristol | Novel plant acyltransferases specific for long-chained, multiply unsaturated fatty acids |
| WO2004090123A2 (en) | 2003-04-08 | 2004-10-21 | Basf Plant Science Gmbh | Δ-4 desaturases from euglena gracilis, expressing plants, and oils containing pufa |
| WO2005017181A2 (en) | 2003-05-20 | 2005-02-24 | Investigen, Inc. | System for detecting polynucleotides |
| WO2005007845A2 (en) | 2003-07-16 | 2005-01-27 | The University Of York | Transgenic cells |
| WO2005012316A2 (en) | 2003-08-01 | 2005-02-10 | Basf Plant Science Gmbh | Method for the production of multiply-unsaturated fatty acids in transgenic organisms |
| WO2005083093A2 (en) | 2004-02-27 | 2005-09-09 | Basf Plant Science Gmbh | Method for producing polyunsaturated fatty acids in transgenic plants |
| WO2005083053A2 (en) | 2004-02-27 | 2005-09-09 | Basf Plant Science Gmbh | Method for producing unsaturated omega-3 fatty acids in transgenic organisms |
| WO2006008099A2 (en) | 2004-07-16 | 2006-01-26 | Basf Plant Science Gmbh | Method for increasing the content of polyunsaturated long-chained fatty acids in transgenic organisms |
| WO2006024023A2 (en) | 2004-08-24 | 2006-03-02 | Nanomix, Inc. | Nanotube sensor devices for dna detection |
| WO2006024509A2 (en) | 2004-09-02 | 2006-03-09 | Basf Plant Science Gmbh | Disarmed agrobacterium strains, ri-plasmids, and methods of transformation based thereon |
| US20060068398A1 (en) | 2004-09-24 | 2006-03-30 | Cepheid | Universal and target specific reagent beads for nucleic acid amplification |
| WO2006069710A1 (en) | 2004-12-23 | 2006-07-06 | Basf Plant Science Gmbh | Method for producing polyunsaturated fatty acids in transgenic organisms |
| WO2006100241A2 (en) | 2005-03-22 | 2006-09-28 | Basf Plant Science Gmbh | Method for producing polyunsaturated c20 and c22 fatty acids with at least four double bonds in transgenic plants |
| WO2007096387A1 (en) | 2006-02-21 | 2007-08-30 | Basf Plant Science Gmbh | Method for producing polyunsaturated fatty acids |
| WO2008022963A2 (en) | 2006-08-24 | 2008-02-28 | Basf Plant Science Gmbh | Isolation and characterization of a novel pythium omega 3 desaturase with specificity to all omega 6 fatty acids longer than 18 carbon chains |
| WO2008124495A2 (en) | 2007-04-04 | 2008-10-16 | Basf Plant Science Gmbh | Ahas mutants |
| US8999411B2 (en) | 2008-02-15 | 2015-04-07 | Monsanto Technology Llc | Soybean plant and seed corresponding to transgenic event MON87769 and methods for detection thereof |
| WO2011161093A1 (en) | 2010-06-25 | 2011-12-29 | Basf Plant Science Company Gmbh | Acyltransferases and uses therof in fatty acid production |
| AU2011289381A1 (en) | 2010-08-11 | 2013-01-24 | E. I. Du Pont De Nemours And Company | Improved aquaculture feed compositions |
| WO2013014585A1 (en) | 2011-07-22 | 2013-01-31 | Basf Plant Science Company Gmbh | Plant transformation method |
| WO2013049227A2 (en) | 2011-09-26 | 2013-04-04 | Geneart Ag | High efficiency, small volume nucleic acid synthesis |
| WO2013185184A2 (en) | 2012-06-15 | 2013-12-19 | Commonwealth Scientific And Industrial Research Organisation | Production of long chain polyunsaturated fatty acids in plant cells |
| US20150299676A1 (en) | 2013-11-26 | 2015-10-22 | Dow Agrosciences Llc | Production of omega 3 long chain polyunsaturated fatty acids in oilseed crops by a thraustochytrid pufa synthase |
| WO2015089587A1 (en) | 2013-12-18 | 2015-06-25 | Commonwealth Scientific And Industrial Research Organisation | Lipid comprising long chain polyunsaturated fatty acids |
Non-Patent Citations (50)
| Title |
|---|
| "Agrobacterium protocols", vol. 44, 1995, HUMANA PRESS, article "Methods in Molecular Biology" |
| "Progress in Lipid Research", vol. 1, 1952, PERGAMON PRESS |
| AKERMOUN, BIOCHEMICAL SOCIETY TRANSACTIONS, vol. 28, 2000, pages 715 - 7718 |
| ALTSCHUL, J. MOL. BIOL., vol. 215, 1990, pages 403 - 10 |
| ALTSCHUL, NUCLEIC ACIDS RES., vol. 25, no. 17, 1997, pages 3389 - 3402 |
| B. JENES ET AL.: "Techniques for Gene Transfer, in: Transgenic Plants, vol. 1, Engineering and Utilization", vol. 3, 1993, ACADEMIC PRESS, article "Product recovery and purification", pages: 469 - 714 |
| BAEUMLEIN ET AL., PLANT J., vol. 2, no. 2, 1992, pages 233 - 239 |
| BLOMBACH ET AL., APPLIED AND ENVIRONMENT MICROBIOLOGY, vol. 75, no. 2, 2009, pages 419 - 427 |
| BROWSE ET AL., ANALYTIC BIOCHEMISTRY, vol. 152, 1986, pages 141 - 145 |
| BUZZA: "Plant Breeding, in Brassica Oilseeds: Production and Utilization", 1995, CAB INTERNATIONAL |
| CAHOON ET AL., PROC. NATL. ACAD. SCI. USA, vol. 96, no. 22, 1999, pages 12935 - 12940 |
| CHEN ET AL., GENOME RES., vol. 9, 1999, pages 492 - 498 |
| CHENG ET AL., PROC. NATL. ACAD. SCI. USA, vol. 91, 1994, pages 5695 - 5699 |
| CHRISTIE, WILLIAM W.: "Gas Chromatography and Lipids. A Practical Guide - Ayr", vol. 2, 1989, OILY PRESS LIPID LIBRARY |
| CZAR ET AL., TRENDS IN BIOTECHNOLOGY, vol. 27, no. 2, 2009, pages 63 - 72 |
| DE BLOCK ET AL., PLANT PHYSIOLOGY, vol. 1-3, 1989, pages 694 - 701 |
| DEAL ET AL., CURR OPIN PLANT BIOL., vol. 14, no. 2, April 2011 (2011-04-01), pages 116 - 122 |
| F.F. WHITE: "Transgenic Plants, vol. 1, Engineering and Utilization", vol. 1, 1993, ACADEMIC PRESS, article "Vectors for Gene Transfer in Higher Plants", pages: 15 - 119 |
| FALLON, A. ET AL.: "Applications of HPLC in Biochemistry", LABORATORY TECHNIQUES IN BIOCHEMISTRY AND MOLECULAR BIOLOGY, vol. 17, 1987 |
| FRANCK, CELL, vol. 21, 1980, pages 285 - 294 |
| FUKUDA Y., PLANT MOL BIOL., vol. 39, no. 5, March 1999 (1999-03-01), pages 1051 - 62 |
| GIUSTO, N.M. ET AL., PROG. LIPID RES., vol. 39, 2000, pages 315 - 391 |
| HAYMES ET AL.: "Nucleic Acids Hybridization: A Practical Approach", vol. A2, 1985, IRL PRESS AT OXFORD UNIVERSITY PRESS, pages: 89 - 90,443-613 |
| HELLENS ET AL., TRENDS IN PLANT SCIENCE, vol. 5, 2000, pages 446 - 451 |
| HORROCKS, L.A.YEO, Y.K., PHARMACOL. RES., vol. 40, 1999, pages 211 - 215 |
| INNIS ET AL.: "PCR Protocols: A Guide to Methods and Applications", 1990, ACADEMIC PRESS |
| K. HECKMANL. R. PEASE, NATURE PROTOCOLS, vol. 2, pages 924 - 932 |
| KENNEDY, J.F.CABRAL, J.M.S.: "Recovery processes for biological Materials", 1992, GREENE PUBLISHING AND WILEY-INTERSCIENCE |
| LOKE, PLANT PHYSIOL, vol. 138, 2005, pages 1457 - 1468 |
| MARTINETZ, M., J. PEDIATR., vol. 120, 1992, pages S129 S138 |
| MUHITCH, PLANT PHYSIOL, vol. 83, 1988, pages 23 - 27 |
| NEEDLEMAN, J. MOL. BIOL., vol. 48, 1970, pages 444 - 453 |
| NIKIFOROV ET AL., NUCLEIC ACID RES., vol. 22, 1994, pages 4167 - 4175 |
| O'MALLEY ET AL., NATURE PROTOCOLS, vol. 2, no. 11, 2007, pages 2910 - 2917 |
| POTRYKUS, ANNU. REV. PLANT PHYSIOL. PLANT MOLEC. BIOL., vol. 42, 1991, pages 205 - 225 |
| RICE, P.LONGDEN, I.BLEASBY, A.: "EMBOSS: The European Molecular Biology Open Software Suite", TRENDS IN GENETICS, vol. 16, no. 6, 2000, pages 276 - 277, XP004200114, DOI: 10.1016/S0168-9525(00)02024-2 |
| RUIZ-LOPEZ ET AL., PLANT J., vol. 77, 2014, pages 198 - 208 |
| SCHWENDER ET AL., NATURE, vol. 432, 2004, pages 779 - 782 |
| SHAEIWITZ, J.A.HENRY, J.D.: "Bioseparations: downstream processing for Biotechnology", vol. B3, 1988, VCH: WEINHEIM; AND DECHOW, F.J., article "Biochemical Separations", pages: 1 - 27 |
| SPECTOR, A.A., LIPIDS, vol. 34, 1999, pages S1 S3 |
| STOCKHAUS, EMBO J., vol. 8, 1989, pages 2445 |
| STYMNE, BIOCHEM. J., vol. 223, 1984, pages 305 - 314 |
| TAKENO, APP. ENVIRON. MICROBIOL., vol. 71, no. 9, 2005, pages 5124 - 5128 |
| TUMANEY, BIOCHIMICA ET BIOPHYSICA ACTA, vol. 1439, 1999, pages 47 - 56 |
| TYANGI ET AL., NATURE BIOTECH., vol. 14, 1996, pages 303 - 308 |
| WARD, PLANT. MOL. BIOL., vol. 22, 1993 |
| WIJESUNDRA, LIPID TECHNOLOGY, vol. 20, no. 9, 2008, pages 199 - 202 |
| WINGE, INNOV. PHARMA. TECH., vol. 00, 2000, pages 18 - 24 |
| WOJCIECHRHOADS, NAR, vol. 17, 1989, pages 8543 - 8551 |
| YAMASHITA, JOURNAL OF BIOLOGICAL CHEMISTRY, vol. 276, 2001, pages 26745 - 26752 |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108690833A (en) * | 2017-03-31 | 2018-10-23 | Toto株式会社 | The production method of recombinant mammalian cells and target substance |
| WO2020168277A1 (en) | 2019-02-14 | 2020-08-20 | Cargill, Incorporated | Brassica plants producing elevated levels of polyunsaturated fatty acids |
| CN113423837A (en) * | 2019-02-14 | 2021-09-21 | 嘉吉公司 | Brassica plants producing increased levels of polyunsaturated fatty acids |
| US11957098B2 (en) | 2019-04-11 | 2024-04-16 | Basf Plant Science Company Gmbh | Method of cultivating LC-PUFA containing transgenic brassica plants |
| WO2022098631A1 (en) | 2020-11-04 | 2022-05-12 | Cargill, Incorporated | Harvest management |
| WO2022204454A1 (en) | 2021-03-25 | 2022-09-29 | Cargill, Incorporated | Fertilizer management |
| CN113475400A (en) * | 2021-08-03 | 2021-10-08 | 吉安市林业科学研究所 | Artificial cultivation technology of cardamine hirsute |
| CN113475400B (en) * | 2021-08-03 | 2022-07-12 | 吉安市林业科学研究所 | Artificial culture technology of cardamine bicolor |
| WO2023081920A1 (en) | 2021-11-08 | 2023-05-11 | Cargill, Incorporated | High plant pufa fish food |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230293615A1 (en) | Materials and methods for pufa production, and pufa-containing compositions | |
| US10533183B2 (en) | Oils, lipids and fatty acids produced in transgenic Brassica plant | |
| DE102006008030A1 (en) | Preparation of polyunsaturated fatty acids in transgenic plants, useful e.g. for reducing risk of hypertension and heart disease, includes expressing a codon-optimized sequence for delta5-elongase |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 15801706 Country of ref document: EP Kind code of ref document: A2 |
|
| REEP | Request for entry into the european phase |
Ref document number: 2015801706 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |