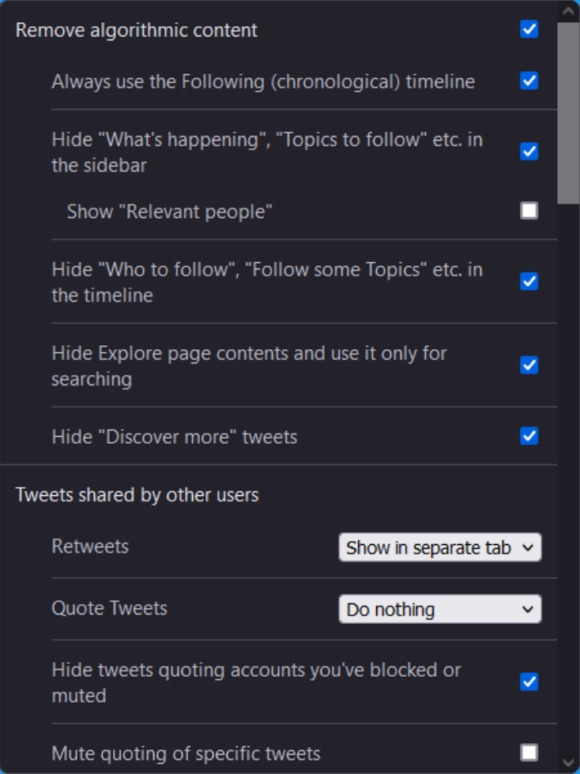
At Mozilla, we know we can’t create a better future alone, that is why each year we will be highlighting the work of 25 digital leaders using technology to amplify voices, effect change, and build new technologies globally through our Rise 25 Awards. These storytellers, innovators, activists, advocates, builders and artists are helping make the internet more diverse, ethical, responsible and inclusive.
This week, we chatted with Keoni Mahelona, a builder behind technologies that aim to protect and promote Indigenous languages and knowledge. We talked with Keoni about his current work at Te Hiku Media, the challenges of preserving Indigenous cultures, big tech and more.
So first off, what inspired you to do the work you’re doing now with Te Hiku Media?
Mahelona: I sort of started at the organization cause my partner, who’s the CEO, needed help with doing a website. But then the website turned into an entire digital platform, which then turned into building AI to help us do the work that we have to do, but I guess the most important thing is the alignment of values with like me as a person and as a native Hawaiian with the values of the community up here — Māori community and the organization. Having the strong desire for sovereignty for our land, which has been the struggle we’ve been having now for hundreds of years. We’re still trying to get that back, both in Aotearoa and in Hawaii, but also sovereignty for our languages and our data, and pretty much everything that encompasses us in our communities. And it was really clear that the work that we do at Te Hiku is very important for the community, but also that we needed to maintain sovereignty over that work. And if we made the wrong choices with how we store our data, where we put our data, what platforms we use, then we would cede some of that sovereignty over and take us further back rather than forward.
What were (and are) some of those challenges that you guys had to overcome to be able to create those tools? I feel like a lot of people might not know those challenges and how you have to persevere through those things to create, to preserve.
Sure, the lack of data is a challenge that big tech seem to overcome quite easily with their billions of dollars, whether they’re stealing it at scale or paying people for it at scale. They have the resources to do that and litigate if they need to, because of theft, and they’re just doing what America did right? Stole our land at scale. So for us, actually, we knew that the data would be the hardest part, but not so much like getting the data, or whether the data existed — there’s a vibrant community of language speakers here — the hard part was going to be, how do we protect the data that we collect? And even now, I worry because there’s just so many bots online scraping stuff, and we see bots trying to sort of log into our online forms. And I’m thinking hopefully these are just bots trying to log into a form because it sees the form, versus someone who knows that we’ve got some valuable data here, and if they can get in, they could use that data to add Māori to their models and profit off of that. When you have organizations like Microsoft and Google making hundreds of millions off of selling services to education and government in this country, you know that would be a valuable corpus for them — I’m not saying that they would sort of steal, I don’t know, I’d hope not, but I feel like OpenAI would probably do something like that.
And how do we overcome that? We just tried. We did the best we could do, given the resources we had to ensure that things are safe, and we think they’re relatively safe, although I still get anxiety about it. Some of the other challenges we face are being a bunch of brown people from a community, so there’s the stereotype associated with the area with anyone who might maybe sort of associates to this place. So there were people like, “Ha, you guys can’t do this.” And we proved them wrong. They were even funders who were Māori, who actually thought, “These guys are crazy, but you know what, this is exactly what we need to find. We need to find like people who are crazy and who might actually pull this off because it would be quite beneficial.”
We’ve had other people inquire as to why our organization got science funding to do science research. I actually have a master’s in science — I actually have two masters in science, although one’s a business science degree, whatever that means — but there was this quite racist media organization on the south island of this country who did an official Information Act request on our organization, saying, “Why is this Māori media company getting science-based funding? They don’t know anything about science.” We actually had a scientist at our organization, and they didn’t, so this is some of the more interesting challenges that we’ve come across in this journey of going from radio broadcasting and television broadcasting to actually being a tech company and doing science and research. So it’s the racism and the discrimination that we’ve had to overcome as well. In some cases, we think we’ve been denied funding because our organization is Māori, and we’ve had to often do the hard work first off the smell of an oily rag, as they say here, to prove that we are capable of doing the work for people to recognize that, yeah, they can actually fund us. And that we can deliver results based on the stipulations of the fund or whatever when you’re getting science-based funding grants and stuff like that. I think we’ve shown the government that you don’t need to be a large university to actually do good research and have an impact in the science community. But it certainly hasn’t been easy.
 <figcaption class="wp-element-caption">Keoni Mahelona at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Keoni Mahelona at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>I imagine even with how long you’ve been there and how long you guys have been doing this, that there’s still an ongoing feeling of anxiety that’s extremely frustrating.
We’re a nonprofit, so a lot of our money comes from government funding, and we’re also a broadcaster, so we have public broadcasting funding that fades some of the work we do and then you science-based funding.
The New Zealand political environment right now is absolutely terrible. There have been hundreds, probably thousands, of job cuts in the government. The current coalition government needs to raise something like three billion dollars for tax cuts for landlords, and in order to do that, they’re just slashing a lot of funding and projects and people’s jobs in government. There’s this rhetoric that’s been peddled that the government is quite inefficient, and we’re just hemorrhaging money and all these stupid positions and things like that. So that also gives us an anxiety, because a changing government might affect funding that is available to our organization. So we also have to deal with that as being a charity and not sort of being a capitalist organization.
The other thing that gives us anxiety is the inevitable, right? I actually think it’s inevitable, unfortunately, that these big tech companies will eventually be able to sort of replicate our languages. They won’t be good. They’ll never be good and good to the point where it will truly benefit and move our people forward. But they will be good enough that they will be able to profit from it. It profits by giving it that reputation of providing that service, ensuring you continue to go to Google, where you’re then served ads, and so they’re not selling the translation, but they are selling ads alongside it for profit, right? We see this essentially happening with a lot of Indigenous languages, where there is enough data being put online that these mostly American big tech corporations will profit from. And the sad thing is that it was the Americans in the first place and these other colonial nations that fought to make our languages extinct. And now their corporations stand to profit from the languages that they tried to make extinct. So it’s really terrible.
How do you think some of these bigger corporations can be more respectful, inclusive, and supportive of Indigenous communities?
That’s an interesting question. I guess the first question is, should they be inclusive? Because sometimes the best thing to do is just stay away and let us get on with it. We don’t need your help. The unfortunate reality is that so many of our people are on Facebook and are on Google, or whatever — the platforms are so dominating or imperialist that we have to use them in some cases, and because English is the dominant language on these platforms, especially for many Indigenous communities where they are colonized by English-speaking nations, it means that you’re just going to continue to be bombarded with English and not have a space if you don’t go out of your way to make a space and to sort of speak your language. It’s a bit of a catch-22, but I think it’s up to the communities to figure that one out because we could collectively come together as community and be like, “We’re not. We never expect Facebook or whatever to support our language and all these other tech companies and platforms.” And that’s fine, let’s go out into our own environment in our own communities and speak in languages rather than trying to rely on these tech companies to sort of do it for us, right?
There are ways that they can actually just kind of help, but like, stay out of our business.
And that’s the better way to do it, because this sort of outsider coming in trying to save us, it just doesn’t work. I’ve been advocating that you have to support these communities to lead the solutions and what they see is best for their people, because Google doesn’t know what’s best for these communities. So they need to support the communities, and I don’t mean by like building the language technologies themselves and selling it back to them, that is not the support I’m talking about. The support is staying away or giving them discounts on resources or giving them resources so that they can build, and they can lead, because then you’re also upskilling them.
What do you think is the biggest challenge that we face in the world this year on and offline? And how do we combat it?
I see stuff happening to the Fediverse, which is interesting. Something that happened recently was some guy who very much knows and in his blog post identified as a tech bro from Silicon Valley, made the universal decision that the best thing to do for everybody is to hook up Threads and the Fediverse, so that people in Threads can access stuff in Mastodon etc., and then likewise the other way around. And this is like a single dude who apparently had talked to people and decided it was his duty or mission to connect Threads to the Fediverse, and it was just like, are you joking? And then there’s this other thing going on now, where there are these similar types of dudes getting angry at some instances for blocking other instances because they have people who are like racist or misogynist, and they’re getting angry at these moderators who are doing what the point of the Fediverse is, right? Where you can create a safe space and decide who gets to come in and who doesn’t. What I’m getting at is, I think that as the Fediverse kind of grows, it’s going to be interesting to see what sort of problems comes and how the things that we wanted to escape by leaving Twitter and jumping on Mastodon are kind of coming in. And I think that’s going to be interesting to see how we deal with that.
This is again where the incompatibility of capitalism and general communities sort of comes to play because if we have for-profit companies trying to do Fediverse stuff, then essentially, we’re going to get what we already have, because ultimately, at the end of the day you’re trying to maximize for profit. So long as the internet is a place where we have dominating companies trying to maximize for profit, we’re just always going to have more problems, and it’s absolutely terrible and frightening.
But yeah, politics and I think the evolution of the Fediverse are probably the thing that I would be most concerned about. Then there’s also the normal stuff, which is just the theft of data and privacy.
What is one action that you think everybody should take to make the world and our online lives a little bit better?
I think they should just be more cognizant of the data they decide to put online and don’t just think about how that data affects you as an individual, but how does it affect those who are close to you? How does it affect the communities to which you belong? And how does it affect other people who might be similar to you in that way?
People need to be respectful of the data and others data and think about their actions online in respect to being good stewards of all data — their own data from their communities, data of others. And whether you should download this thing or steal that thing or whatever. And that’s essentially what I think is my message, for everyone, is to be respectful, but think about data as you would think about your environment and taking care of it and respecting.
We started Rise25 to celebrate Mozilla’s 25th anniversary. What do you hope that people are celebrating in the next 25 years?
The fall of capitalism, I guess. The restoration of the Hawaiian nation — I can continue. Ultimately, I think a lot of problems come back to some very fundamental ways in which society has structured itself.
What gives you hope about the future of our world?
I think actually this younger generation. I had this impression coming out of high school going to university and then kind of seeing the new generation coming through and being confused having perceptions through your generations. When we live stream high school speeches … just the stuff that these kids talk about is amazing. And even sometimes you’re like having a bit of a cry, because it’s so good in terms of the topics they talk about. But to me, that gives me hope there are actually like some really amazing people and young people who will someday fill our shoes and be politicians. That gives me hope that these people still exist despite all the negative stuff that we see today. That’s what I’m hopeful for.
Get Firefox
Get the browser that protects what’s importantThe post Keoni Mahelona on promoting Indigenous communities, the evolution of the Fediverse and data protection appeared first on The Mozilla Blog.






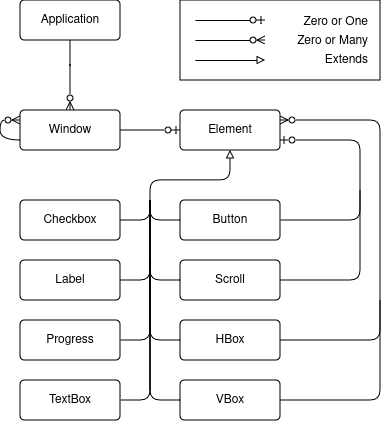
 . As said on the related MDN page:
. As said on the related MDN page: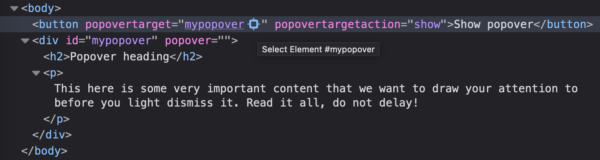 <figcaption class="wp-element-caption">Inspector displayed on
<figcaption class="wp-element-caption">Inspector displayed on 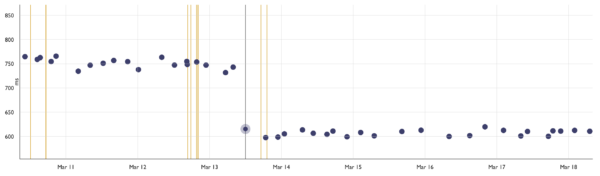 <figcaption class="wp-element-caption">Performance test duration going from ~750ms to ~600ms</figcaption>
<figcaption class="wp-element-caption">Performance test duration going from ~750ms to ~600ms</figcaption>

 <figcaption class="wp-element-caption">Julia Janssen at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Julia Janssen at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>



 <figcaption class="wp-element-caption">Abbie Richards at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Abbie Richards at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>


 The new open ecosystem of extensions on Firefox for Android
The new open ecosystem of extensions on Firefox for Android 










 <figcaption class="wp-element-caption">Finn Lützow-Holm Myrstad at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Finn Lützow-Holm Myrstad at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>

 <figcaption class="wp-element-caption">Marek Tuszynski at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Marek Tuszynski at Mozilla’s Rise25 award ceremony in October 2023.</figcaption> <figcaption>protip: use cowsay(1) to alert the user to errors in Makefile before restarting</figcaption>
<figcaption>protip: use cowsay(1) to alert the user to errors in Makefile before restarting</figcaption>  <figcaption>screenshot of several fake Facebook profiles, all using the same two photos of retired US Army General Mark Hertling</figcaption>
<figcaption>screenshot of several fake Facebook profiles, all using the same two photos of retired US Army General Mark Hertling</figcaption>  <figcaption>In AIC polls, confidence in Amazon, Meta, and Google has fallen since 2018.</figcaption>
<figcaption>In AIC polls, confidence in Amazon, Meta, and Google has fallen since 2018.</figcaption>  <figcaption class="wp-element-caption">Rachel Hislop at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Rachel Hislop at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>

 ) for us to reproduce the issue and come up with a
) for us to reproduce the issue and come up with a 








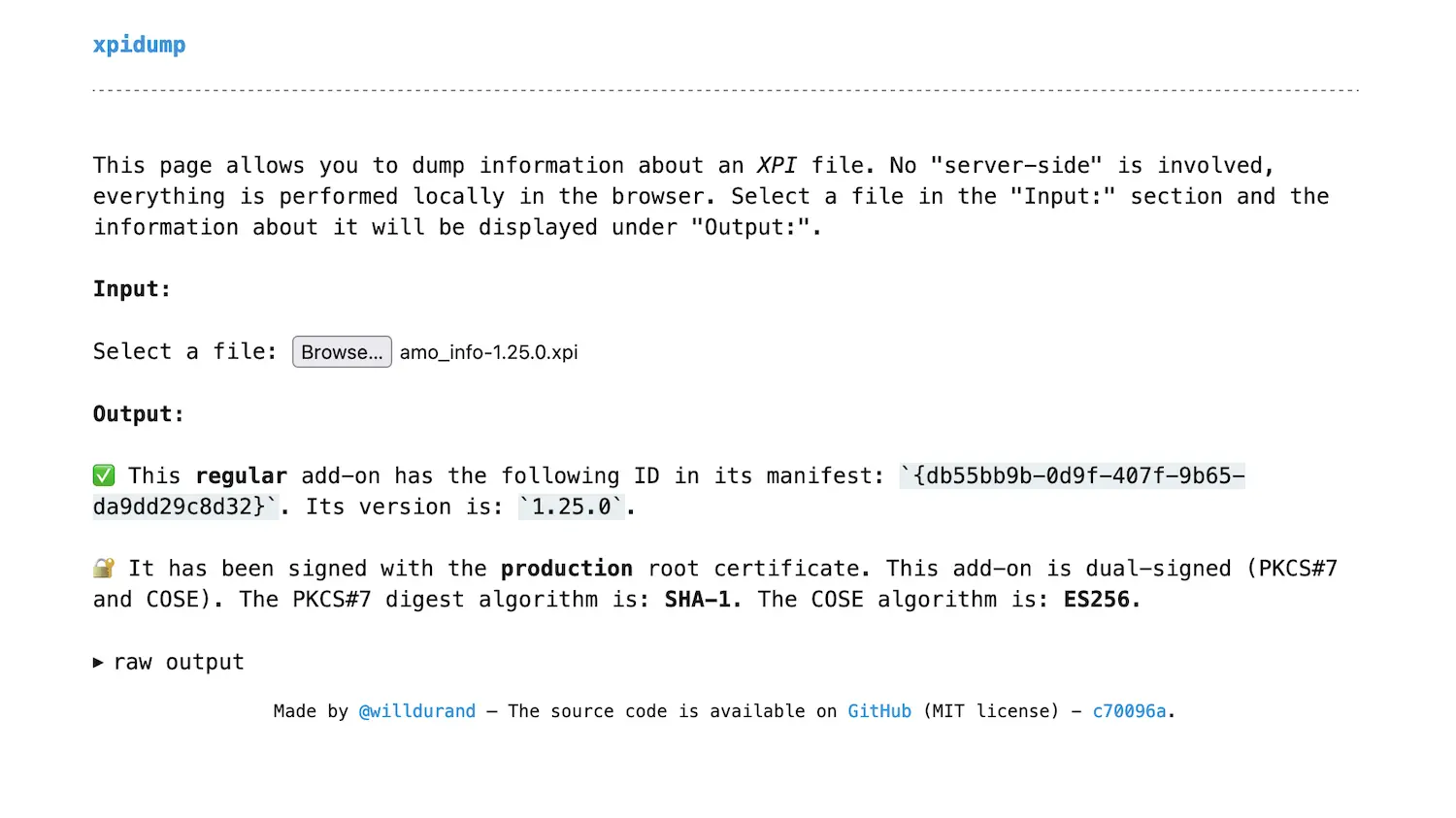 xpidump is available in the browser thanks to WebAssembly!
xpidump is available in the browser thanks to WebAssembly!