
Abstract
Spatial resolution is a key factor of quantitatively evaluating the quality of magnetic resonance imagery (MRI). Super-resolution (SR) approaches can improve its spatial resolution by reconstructing high-resolution (HR) images from low-resolution (LR) ones to meet clinical and scientific requirements. To increase the quality of brain MRI, we study a robust residual-learning SR network (RRLSRN) to generate a sharp HR brain image from an LR input. Due to the Charbonnier loss can handle outliers well, and Gradient Difference Loss (GDL) can sharpen an image, we combined the Charbonnier loss and GDL to improve the robustness of the model and enhance the texture information of SR results. Two MRI datasets of adult brain, Kirby 21 and NAMIC, were used to train and verify the effectiveness of our model. To further verify the generalizability and robustness of the proposed model, we collected eight clinical fetal brain MRI 2D data for evaluation. The experimental results have shown that the proposed deep residual-learning network achieved superior performance and high efficiency over other compared methods.
Similar content being viewed by others

Introduction
Spatial resolution is a key factor of evaluating the quality of magnetic resonance imaging (MRI). Images having high spatial resolution produce rich structural details, enabling accurate image analysis and detailed anatomical information for accurate quantitative analysis1. The recent development of fast MRI slice acquisition techniques has enabled MRI to be used for fetal imaging. MRI can be used to assess brain disease and diagnose fetal congenital brain malformations. High-quality and HR slices can be obtained through fast slice acquisition techniques such as half-Fourier acquisition single shot fast spin echo (SSFSE)2. The slices are acquired as snapshots in fractions of a second, thus freezing the motion of the subject. Therefore, MRI is one of examination methods for prenatal screening and has a broad application prospect. Although high-quality slices are frequently acquired by these techniques, due to the interference of amniotic fluid, placenta, maternal pelvis, and fetal skull, limitations of the equipment’s component performance, fetal motion and other factors, fetal brain slices can’t reach the quality of neonatal imaging. Especially, MRI needs to be done quickly to avoid motion artifacts, one way to speed up is to acquire the lower resolution image. Overall, the above limitations of the component performance of equipment, uncooperative patients, and other factors, improvements to 2D MRI quality are necessary3.

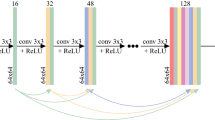
(a) When we use fetal data, we label and segment fetal brains under professional guidance. (b) The proposed RRLSRN architecture for brain MRI SR.
With conventional medical image processing, bicubic or spline interpolation is usually adopted as standard image-processing techniques to be more convenient to match the resolution of internal atlases for a volume input with thicker slices. This interpolation method negatively affects image accuracy4. Therefore, coherently recovering the missing information during the acquisition of medical images and better reconstructing the high-resolution (HR) image is a fundamental problem in the field.
Convolutional neural networks (CNN) have been widely used for natural images, and CNN-based super-resolution (SR) algorithms have been extended to MRI5,6,7,8,9,10,11,12,13,14,15,16,17,18. Many SR algorithms are based on SR combined with CNNs (SRCNN). Zeng et al.12 proposed a model that simultaneously performed single- and multi-contrast SR reconstruction. To capture the cubic spatial feature of the MRI, Du et al.11 exploited 3D dilated convolution as encoder to extract high-frequency features, resulting in good performance. Based on this model, Pham et al.6 developed a SRCNN algorithm which employed 3D covolutions for brain MRI SR, and the network performed excellently.
The input to above SRCNNs must be a bicubic low-resolution (LR) image. To reduce the computational cost, Fast SRCNN19 adopted a deconvolutional layer to reconstruct HR images from LR features. Shi et al.20 proposed an efficient sub-pixel CNN. When the redundant nearest-neighbor interpolation was replaced with the interpolation, the deconvolutional layer was simplified into a sub-pixel convolution. This interpolation was more efficient than the nearest-neighbor interpolation.

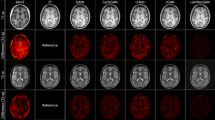
Illustration of SR results with upsampling (scale factor is 2): (a) Kirby 21; (b) NAMIC; (c) clinical fetal brain MR images.

The error maps of SR results: (a) Kirby 21; (b) NAMIC; (c) clinical fetal brain MR images.
Although these models demonstrated promising results, they all required upscaled input images at the desired spatial resolutions via bicubic interpolation prior by applying the network, and these models did not use low-level feature information. To cope with these limitations, some SR algorithms have adopted residual learning5,7,8,9,13,21,22, showing effective improvements.
In this work, there are three aspects of our contributions: (1) To address the computational-cost problem and avoid generating fake features, we adopted a deep residual network to train residuals in a coarse-to-fine fashion. (2) In order to sharpen the SR image, we combined Gradient Difference Loss (GDL)23 and the robust Charbonnier loss function, this way can deal with outliers and improve reconstruction accuracy. (3) We collected eight clinical fetal-brain MRIs for further evaluating the generalizability and robustness of the proposed model.
Experimental results
Figure 2 has shown the HR example slices for the different algorithms: cubic spline interpolation and non-local means up-sampling (NMU)24 , low-rank total variation (LRTV)25, and SRCNN26 for visual inspection with the ground-truth MR image and LR image on Kirby 21, NAMIC1, and clinical fetal MR images, respectively. All the figures in our paper were drawn by Microsoft Office PowerPoint 2016 (https://www.office.com/). It can be seen that our approach recovered fine details and preserved the edges.
The SR deep-learning technique was not very limited by MRI parameters and could therefore be further migrated to the fetal brain. Thus, we applied our model to fetal MRIs, which were provided by the First Affiliated Hospital of Xi’an Jiaotong University. We labeled the fetal brain on the MRI and extract the fetal brain. The MRIs of each fetus were cut into 10–20 slices. We tested all slices of each fetus. Figure 2c shows the SR example slices of different algorithms on a subject. The reconstructed MR images by our network provided more details than did the other algorithms. The error maps Fig. 3 can make it easier to identify differences between the methods.
For a quantitative comparison, the average peak signal-to-noise ratio and structural similarity27 were used to evaluate the performance of each algorithm. Tables 1, 2 and 3 provided a summary of the quantitative evaluation within a scale factor of two, include Mean, Standard Deviation (SD) and confidence interval (CI) which confidence level is \(95\%\)of PSNR and SSIM. The reported results tend to show that CNN-based approaches (e.g., SRCNN and our RRLSRN model) achieved better performance than did cubic spline, NMU, and LRTV. Our experiments also showed that residual learning approaches were more effective than SRCNN.
In our model, we combined the Charbionner loss and GDL to train our model. To verify the effect of GDL on SR results, we compared the PSNR of model without GDL on 8 clinical fetal brain MR images, the results are shown as Table 4. All PSNR of 8 fetal MR images with the GDL are higher than without GDL. The results demonstrate that GDL is helpful to improve the quality of images.
Our experiment has shown that the proposed model with GDL can enhance the brain’s edge of MRI. And we show the visual difference between our model with GDL and without GDL on the clinical fetal brain MRI dataset as Fig. 4. As shown by the yellow arrow , the reconstruction result of our model with GDL has sharper edges and is similar with HR image than the model without GDL.

Visual difference between our model with GDL and without GDL on the clinical fetal brain MRI dataset.
We trained the model without the transpose convolution at the bottom of our model to demonstrate the effect of transpose convolution. We compared the PSNR on 8 clinical fetal brain MR images, the results have been shown as Table 5. The experimental results show that transpose convolution at the bottom is helpful to improve the accuracy of the results. Residual learning is beneficial to the model.
To verify the efficiency of our algorithm, we separately calculated the test time of our Kirby 21, NAMIC, and the fetal MR image methods. We then compared the spending time of other methods. The results are shown in Table 6. The average speed of our model was faster than those of the NMU, LRTV, SRCNN (faster version)19 on three datasets.
Discussion
In this work, we proposed a network-based algorithm to learn the residual information between upsampled MR images and HR MR images. Our approach adpoted the robust Charbonnier loss function and GDL which are helpful to train our model. In order to demonstrate the potential of SR methods for enhancing the quality of LR images, we have presented an experiment with image quality transfer from HR experimental dataset to LR images. The results based on two brain MR image datasets have shown that our algorithm outperforms cubic spline, NMU, LRTV and SRCNN in this study. RRLSRN network effectively learned the residual information between upsampled LR MRI and HR MRI, the model can not only improve the accuracy of network SR results, but also greatly reduce the computational cost. Then we applied the model on the clinical fetal MR images. The fetal SR results of the proposed RRLSRN are better than above listed methods. The texture of SR results become detailed.
In terms of the processing speed, we observed that our method trained \(\times 2\) faster than NMU, LRTV and SRCNN on both Kirby 21 and NAMIC datasets. Overall, our algorithm performed well in terms of speed.
Our SR method has shown clear improvement over other listed methods, which is the standard technique to enhance image quality from visualization, quantitative evaluation and computational efficiency. Our model is currently SR on the scale of \(\times 2\) of 2D MR slices, it can also be extended to \(\times 4\) or \(\times 8\) times for SR reconstruction by cascading. In future work, we will improve our residual learning based SR framework to obtain better accuracy, meanwhile reduce computational complexity. In addition, we will further apply the SR technology to improve the accuracy and validity of the clinical diagnosis by combining the equipment.
Methods
MR image super-resolution framework
We proposed RRLSRN to generate an HR brain image from its LR input. Our network is made up of the feature extraction and image reconstruction parts. The image reconstruction part estimates a raw HR output and extracts useful representations from LR MRI. We up-sampled LR MRI and learned the residual information between the HR MRI and the up-sampled MRI. Our LR MRI is derived from the HR MRI via bicubic interpolation.
where x and y represent the LR and HR images, respectively. \(\kappa\) is the down-sampling operator. r is the residual information between the HR MRI and the bicubic-interpolated MRI. u represents the up-sampling operator. The model can learn the residual feature and up-sampling feature with normal and transposed convolutional layers. The network architecture used in this study is illustrated in Fig. 1b. When using fetal data, we segmented and extracted fetal brains as shown Fig. 1a.
The main architecture of the network for feature extraction consisted of 13 convolutional layers and two transposed convolutional layers to up-sample the extracted features using a scale of two. Because the fetal MRI slice sequence did not enable 3D representation, we designed our model with 2D convolution. The convolution kernel size was \(3 \times 3 \times 64\). The transpose convolutions were \(4 \times 4 \times 1\). Our model performed feature extraction at a coarse resolution and generated feature maps with finer details by using the transposed convolutional layer. Compared to the listed networks, our network can reduce computational complexity significantly.
Loss function
This approach can learn the information lost in the image by interpolation, and it can also reduce computational complexity. We optimized the network with a Charbonnier loss4, as stated in the following formulation:
Let x be the input. We denote the ground-truth HR MRI slice by y, generating the corresponding HR MRI slice by \(\hat{y}\), and the residual information of MRI by r. The overall Charbonnier loss function is:
Where s represents the number of training samples. \(\varepsilon\) is a very small constant. \(\varepsilon\) is empirically set as \(1e {-3}\). We utilized our model with the Charbonnier loss function instead of the \(L_2\) loss to cope with outliers and improve MRI SR result accuracy, due to the loss is robust.
We also combined the GDL, which can directly penalize the differences of image gradient to sharpen the SR result. The GDL function is defined as follows:
The overall GDL loss function is:
Where |.| denotes the absolute value function.
Then the final combined loss is:
Dataset and training details
To verify the ability to reconstruct HR MRI slices of the brain, we applied our method on two adult-brain datasets (Kirby 21 and NAMIC) and eight clinical fetal MRIs.
Dataset
Kirby 21 dataset
The Kirby 21 dataset1 contains the data of 21 volunteers who were all healthy, had no history of neurological conditions, and the dataset contained T1-weighted MRIs. The dataset was obtained using a 3-T MRI scanner (Achieva, Philips Healthcare, Best, Netherlands) with a sagittal view (FoV) of \(240\times 204\times 256\ \hbox {mm}\) and a resolution of \(1.0\times 1.0\times 1.2\ \hbox {mm}^3\).
NAMIC brain multimodality dataset
The NAMIC dataset (http://hdl.handle.net/1926/1687) was acquired using a 3-T General Electric (GE) device at Brigham and Women’s Hospital in Boston, MA. An eight-channel coil was employed to perform parallel imaging by using array spatial sensitivity encoding techniques1. The parameters of structural MRI were as follows: \(\hbox {TR} = 7.4\ \hbox {ms}\), \(\hbox {TE} = 3\ \hbox {ms}\), \(25.6\ \hbox {cm}^2\ \hbox {FoV}\), and \(\hbox {matrix} =256 \times 256\).
Clinical fetal MRI dataset
The eight clinical fetal MRI data was provided by the First Affiliated Hospital of Xi’an Jiaotong University. Images were continuously collected from September 2017 to October 2018 using GE 3.0-T MRI scanner (Discovery 750W; GE Medical system, Milwaukee, WI; \(240\times 204\times 256\ \hbox {mm}\) FoV; 4-mm slice thickness; \(\hbox {TE}=85\) ms) for fetal-head MRI. Eight pregnant volunteers used silent sequences, which contained silent T2 half-Fourier acquisition single-shot fast-spin-echo axial, sagittal, and coronal. These eight women underwent MRI scans because of health concerns. We performed the experiments by following the safety guidelines for MRI research. All patients signed informed consent forms, and the clinical protocol was approved by the Institutional Review Board of the First Affiliated Hospital of Xi’an Jiaotong University in Xi’an Shaanxi, China on February 25, 2019. The experimental data were completely de-identified, so that any related information of the subject cannot be retrieved.
Training details
In order to validate our model, one tenth of the sections from each sequence of MRI were selected as validation data. We sliced Kirby21 and NAMIC datasets into 2D images. The total number of images is 1921. The whole images are split into 7:1:1:1 ratio as 1345 training, 192 for optimizing network weights, 192 for choosing hyper-parameters, and 192 for testing. We chose data from KKI2009-06 to KKI2009-42 in Kirby 21 to train the model. KKI2009-01, KKI2009-02, KKI2009-03, KKI2009-04, and KKI2009-05 were used for testing. We tested the model from case01011 to case01034 NAMIC. The remaining images were used for training. All eight fetal brain MRIs were used for testing. LR images were generated using a scale factor of two.
We initialized the network using the model of Lai4. The slope of leaky rectified linear units was \(-0.2\). We padded zeros to make sure that the size of the feature map for each layer is the same as the input. And we trained the model by randomly sampling 64 patches whose sizes were all \(128\times 128\). We set the momentum parameter to 0.9 and the weight decay to \(1e{-4}\). The learning rate was initialized to \(1e{-5}\) and decreased by a factor of two at every 50 epochs. We trained the original codes of the compared methods to calculate the runtime on the same computer with an Intel i7 processor (64-GB RAM) and Nvidia Tesla V100 graphics processor (16-GB Memory).
References
Landman, B. A. et al. Multi-parametric neuroimaging reproducibility: a 3-t resource study. Neuroimage 54, 2854–2866 (2011).
Tourbier, S. et al. An efficient total variation algorithm for super-resolution in fetal brain MRI with adaptive regularization. Neuroimage 118, 584–597 (2015).
Shi, F., Cheng, J., Wang, L., Yap, P.-T. & Shen, D. Lrtv: Mr image super-resolution with low-rank and total variation regularizations. IEEE Trans. Med. Imaging 34, 2459–2466 (2015).
Lai, W.-S., Huang, J.-B., Ahuja, N. & Yang, M.-H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition, 624–632 (2017).
Oktay, O. et al. Multi-input cardiac image super-resolution using convolutional neural networks. In International conference on medical image computing and computer-assisted intervention, 246–254 (Springer, 2016).
Pham, C.-H., Ducournau, A., Fablet, R. & Rousseau, F. Brain mri super-resolution using deep 3d convolutional networks. In 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), 197–200 (IEEE, 2017).
McDonagh, S. et al. Context-sensitive super-resolution for fast fetal magnetic resonance imaging. In Molecular Imaging, Reconstruction and Analysis of Moving Body Organs, and Stroke Imaging and Treatment, 116–126 (Springer, 2017).
Giannakidis, A. et al. Super-resolution reconstruction of late gadolinium enhancement cardiovascular magnetic resonance images using a residual convolutional neural network.
Feng, C.-M. et al. Coupled-projection residual network for mri super-resolution. arXiv preprintarXiv:1907.05598 (2019).
Li, Z. et al. Deepvolume: Brain structure and spatial connection-aware network for brain mri super-resolution. IEEE Trans. Cybern. (2019).
Du, J. et al. Brain mri super-resolution using 3d dilated convolutional encoder-decoder network. IEEE Access 8, 18938–18950 (2020).
Zeng, K. et al. Simultaneous single-and multi-contrast super-resolution for brain mri images based on a convolutional neural network. Comput. Biol. Med. 99, 133–141 (2018).
Shi, J. et al. Mr image super-resolution via wide residual networks with fixed skip connection. IEEE J. Biomed. Health Inform. 23, 1129–1140 (2018).
Tanno, R. et al. Bayesian image quality transfer with cnns: exploring uncertainty in dmri super-resolution. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 611–619 (Springer, 2017).
Goodfellow, I. et al. Generative adversarial nets. In Advances in neural information processing systems, 2672–2680 (2014).
Chen, Y. et al. Mri super-resolution with gan and 3d multi-level densenet: Smaller, faster, and better. arXiv preprintarXiv:2003.01217 (2020).
Sánchez, I. & Vilaplana, V. Brain mri super-resolution using 3d generative adversarial networks. arXiv preprintarXiv:1812.11440 (2018).
Liu, J., Chen, F., Wang, X. & Liao, H. An edge enhanced srgan for mri super resolution in slice-selection direction. In Multimodal Brain Image Analysis and Mathematical Foundations of Computational Anatomy, 12–20 (Springer, 2019).
Dong, C., Loy, C. C. & Tang, X. Accelerating the super-resolution convolutional neural network. In European conference on computer vision, 391–407 (Springer, 2016).
Shi, W. et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1874–1883 (2016).
Ledig, C. et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4681–4690 (2017).
Lim, B., Son, S., Kim, H., Nah, S. & Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 136–144 (2017).
Mathieu, M., Couprie, C. & LeCun, Y. Deep multi-scale video prediction beyond mean square error. arXiv preprintarXiv:1511.05440 (2015).
Manjón, J. V. et al. Non-local mri upsampling. Med. Image Anal. 14, 784–792 (2010).
Milanfar, P. Super-resolution imaging (CRC Press, 2010).
Dong, C., Loy, C. C., He, K. & Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 28, 295–307 (2015).
Wang, Z., Bovik, A. C., Sheikh, H. R. & Simoncelli, E. P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13, 600–612 (2004).
Acknowledgements
This work was partially supported by the National Natural Science Foundation of China (No. 61671367), National Natural Science Foundation of China (No. 42101380), Natural Science Foundation of Shaanxi Province (No. 2021zjQ-324), the Open Research Fund of National Earth Observation Data Center (No. NODAOP2021007), the Research Foundation of Key laboratory of Biomedical Spectroscopy of Xi’an, Autonomous Deployment Project of Xi’an Institute of Optics and Precision Mechanics of Chinese Academy of Sciences (Nos. Y855W31213, Y955061213).
Author information
Authors and Affiliations
Contributions
L.S. designed the study, developed methods, analysed the data, drafed and led in revision of the manuscript for all the content. Q.W. designed the study, developed methods, analysed the data, drafed and led in revision of the manuscript for all the content. T.L. and J.Y. collected the data and performed preprocessing. H.L. designed study, developed methods and revised the manuscript. J.F. and L.H. supported design of the study, and revised the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Song, L., Wang, Q., Liu, T. et al. Deep robust residual network for super-resolution of 2D fetal brain MRI. Sci Rep 12, 406 (2022). https://doi.org/10.1038/s41598-021-03979-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-03979-1
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
